Magnitude Modeling of Personalized HRTF Based on Ear Images and Anthropometric Measurements


Abstract
:1. Introduction
2. Database
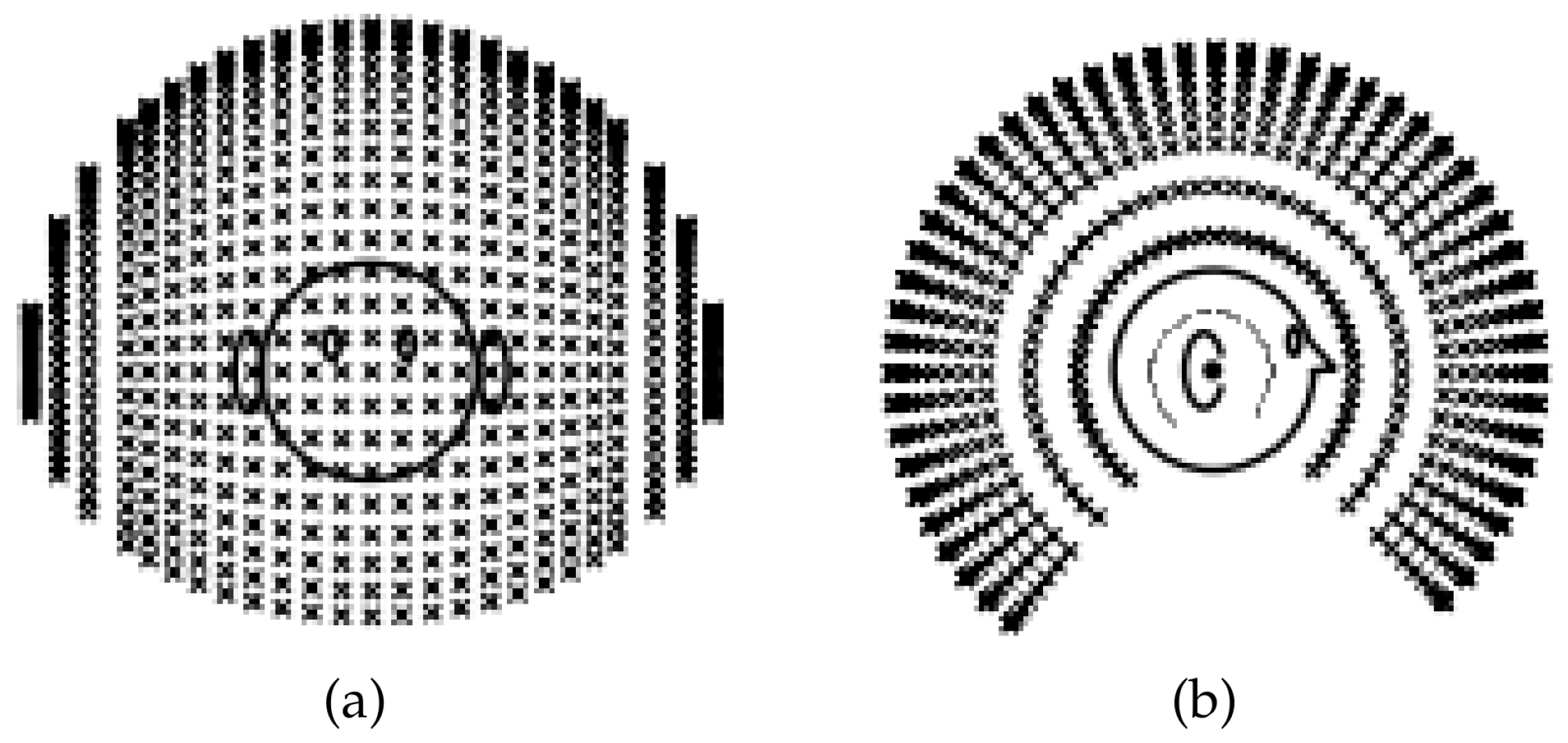
2.1. CIPIC Database
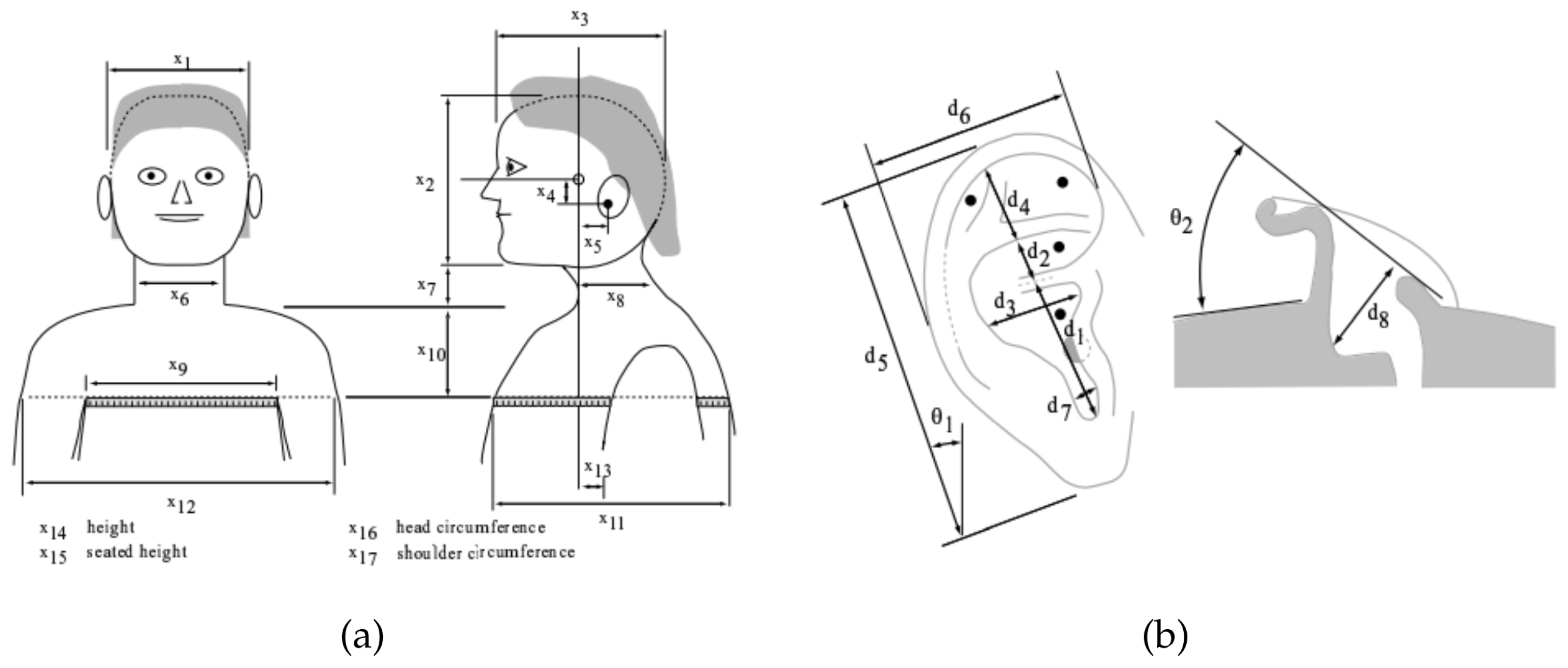
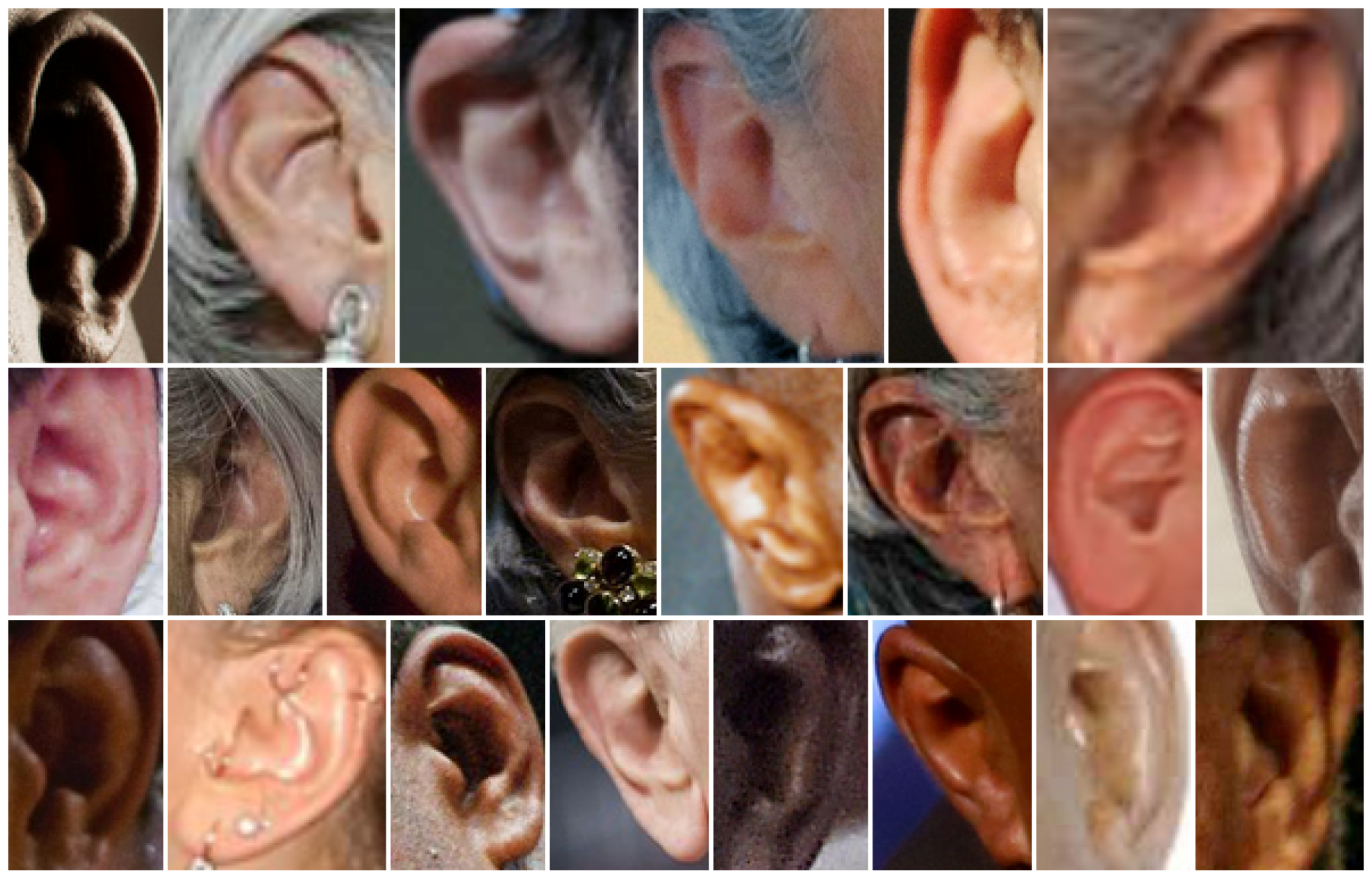
2.2. Ear Image Database
3. Proposed Method
3.1. VGG-Ear Model
3.1.1. Transfer Learning
3.1.2. Ear Data Augmentation
- Add Gaussian noise to the image.
- Rotate the image by −40 to +40 degrees.
- Gaussian blurring the image ( varies from 1 to 4).
- Adjust brightness of the image ( varies from 0.5 to 2).
- Crop and occlude the image by 10% to 40%.
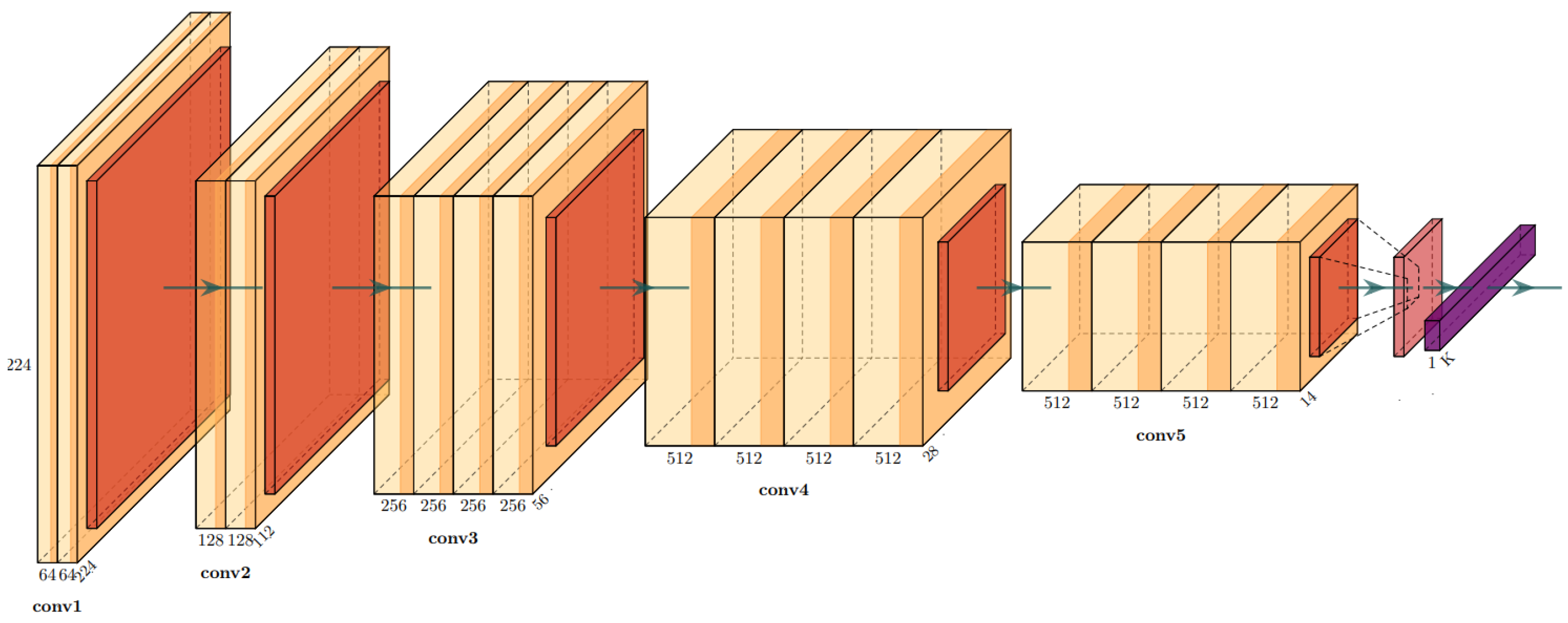
3.1.3. The VGG-Ear Architecture
3.2. Deep Learning Model Design
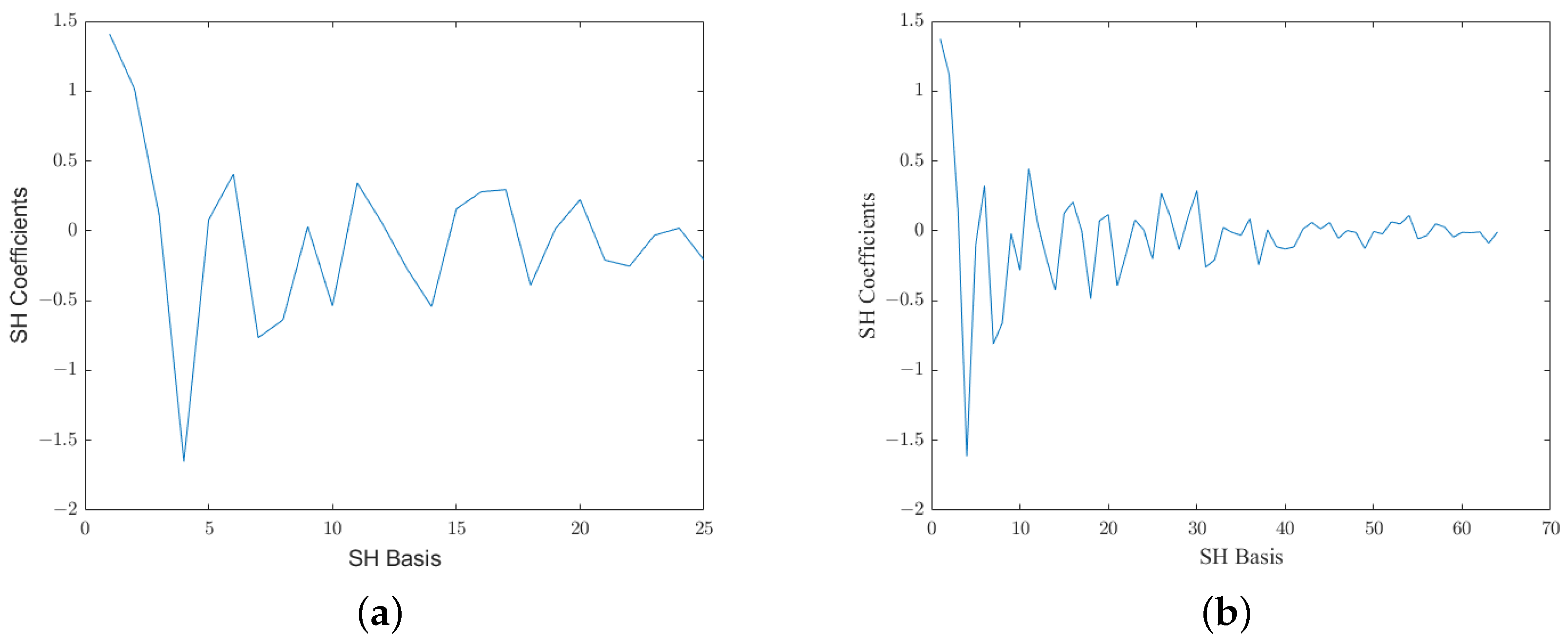
3.2.1. Spherical Harmonic Decomposition
3.2.2. Implementation Details
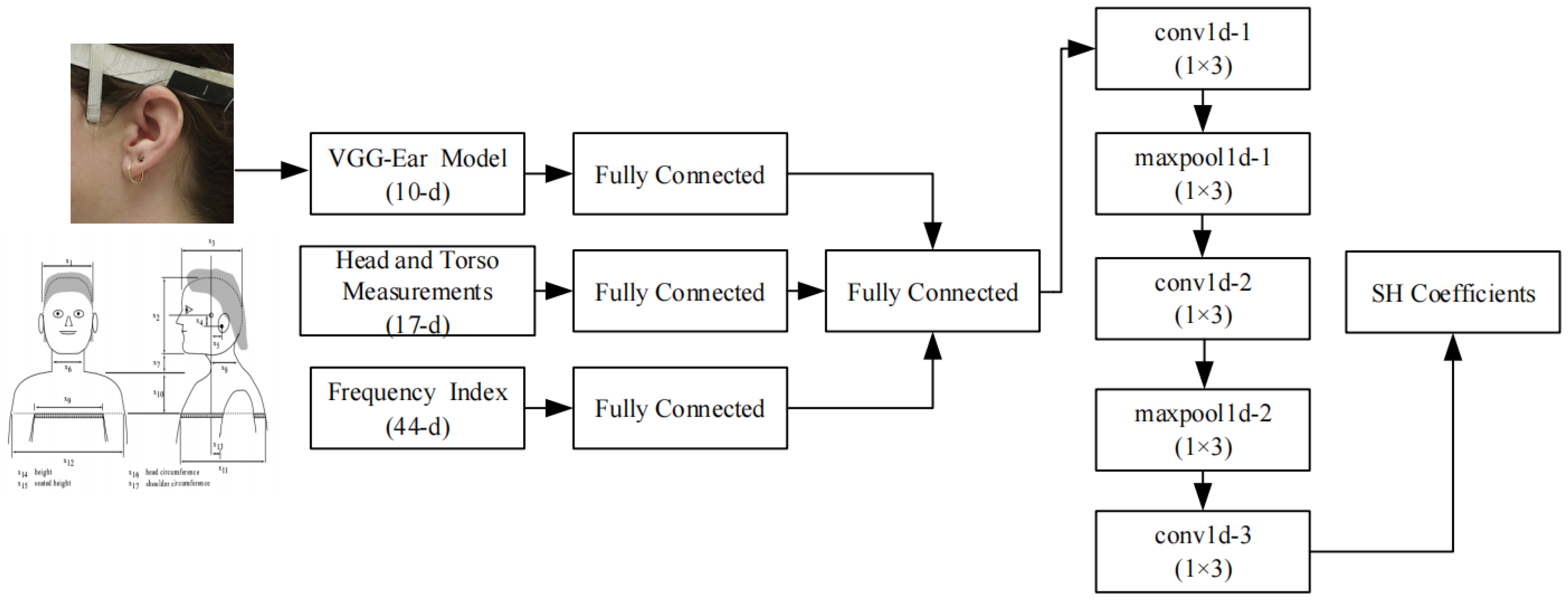
3.2.3. Architecture Used to Obtain SH Coefficients
4. Performance and Evaluation
4.1. Objective Evaluation
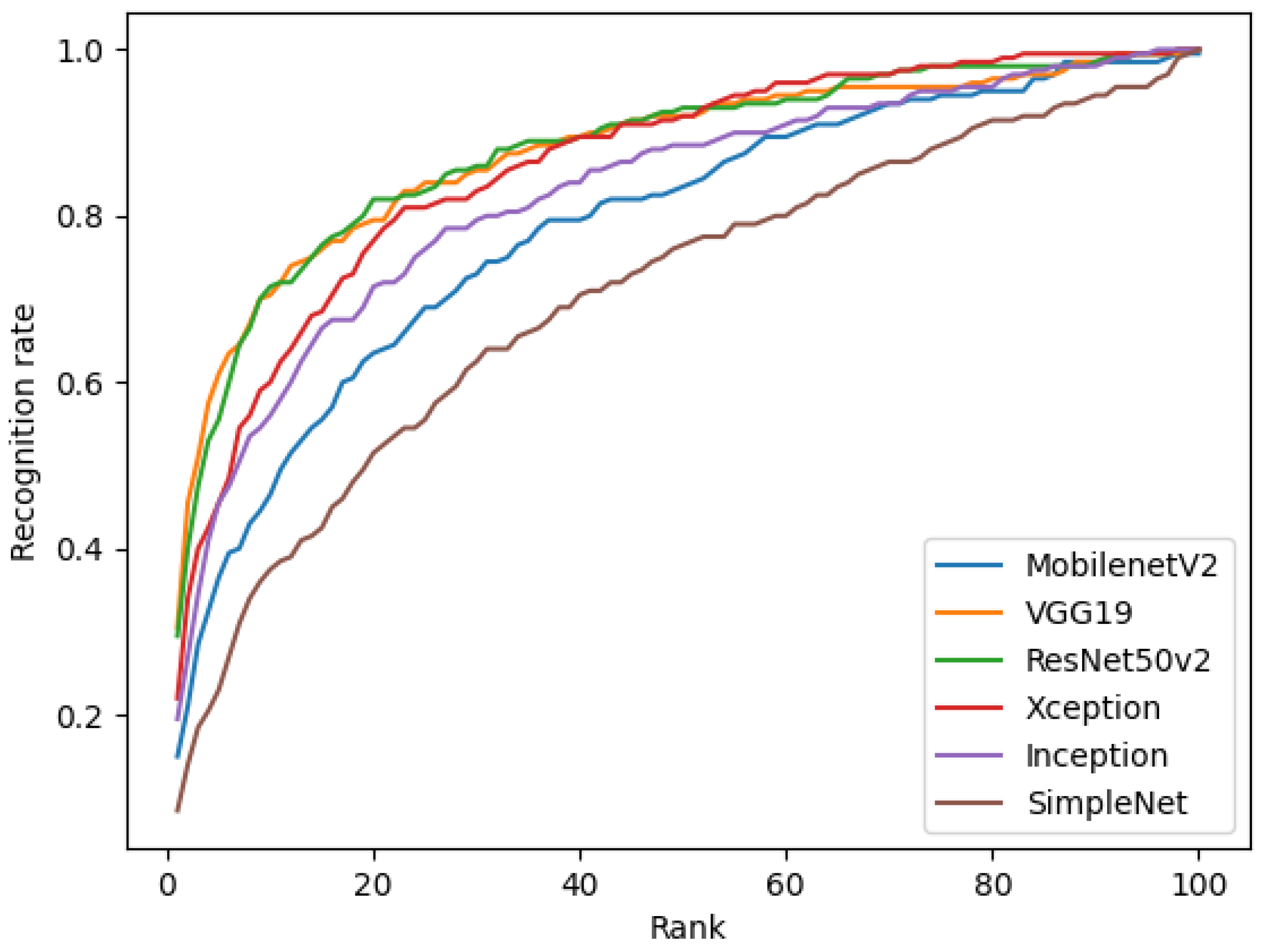
4.2. Ear Model Results
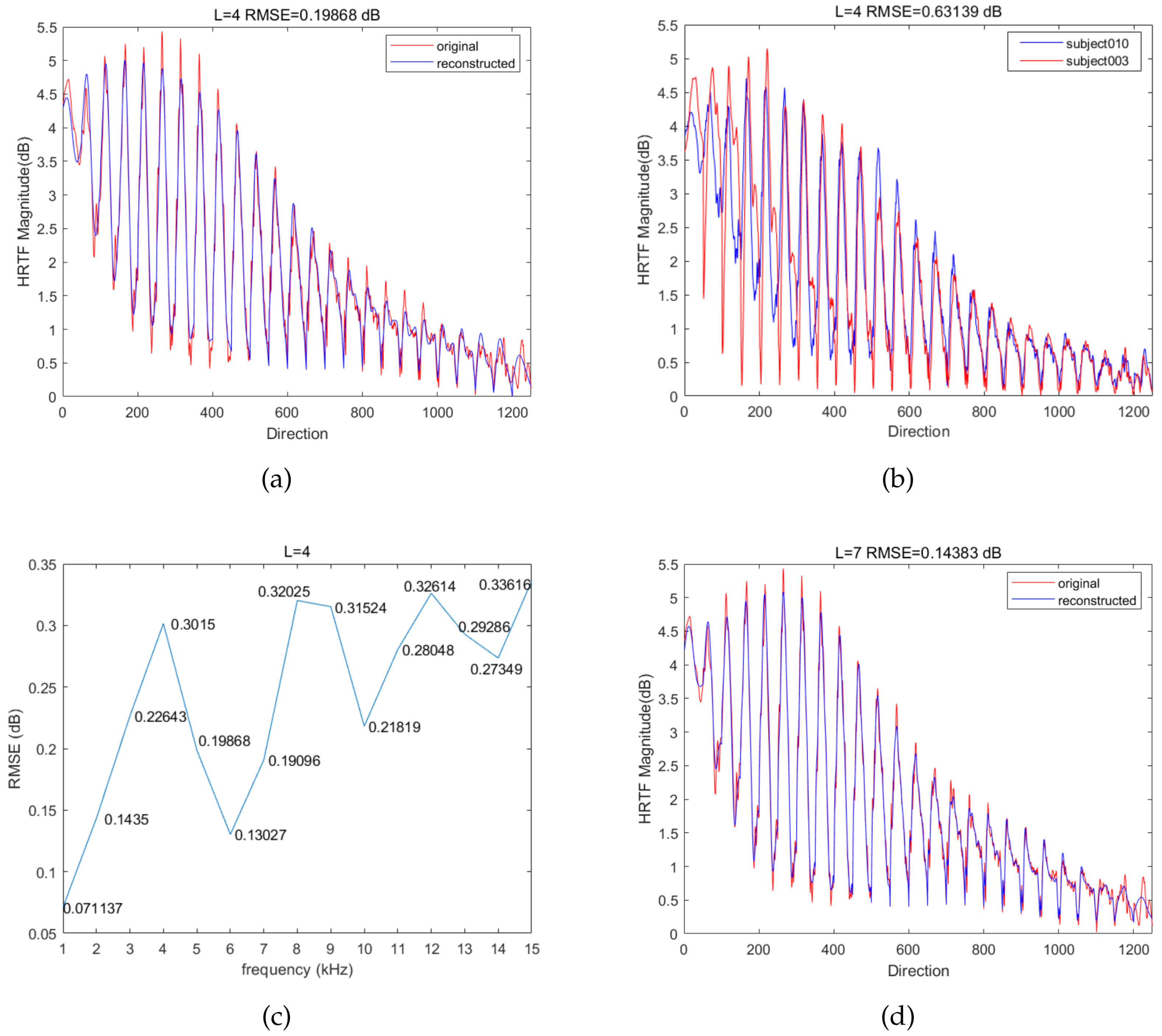
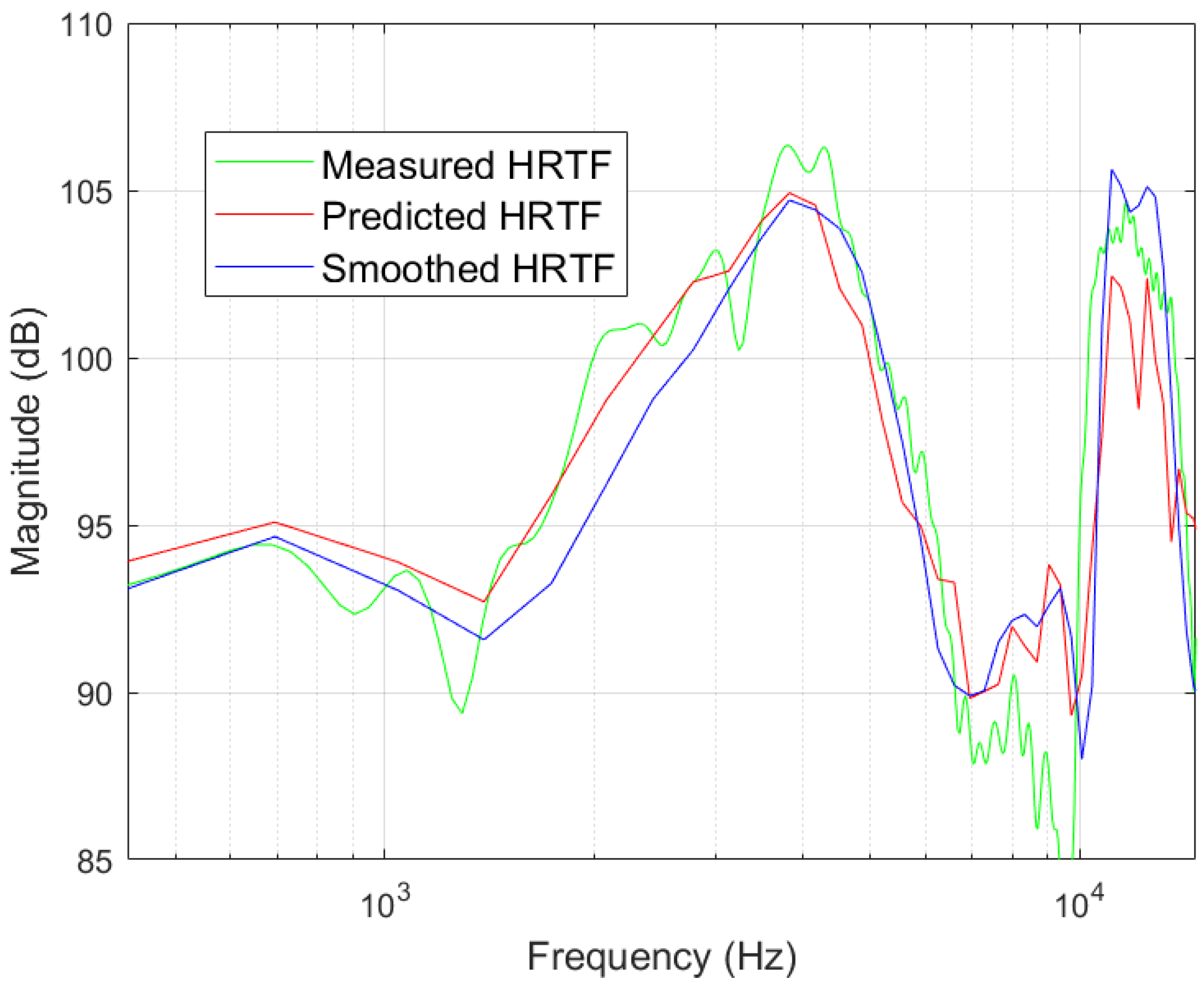
4.3. SHT Reconstruction Results
4.4. HRTF Personalization Results
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, X.; Talagala, D.S.; Zhang, W.; Abhayapala, T.D. Individualized interaural feature learning and personalized binaural localization model. Appl. Sci. 2019, 9, 2682. [Google Scholar] [CrossRef]
- Blauert, J.; Hearing, S. The psychophysics of human sound localization. In Spatial Hearing; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Xie, B. Head-Related Transfer Function and Virtual Auditory Display, 2nd ed.; J. Ross Publishing: Plantation, FL, USA, 2013. [Google Scholar]
- Howard, D.M.; Angus, J. Acoustics and Psychoacoustics, 4th ed.; J. Ross Publishing: Waltham, MA, USA, 2009. [Google Scholar]
- Møller, H.; Sørensen, M.F.; Jensen, C.B.; Hammershøi, D. Binaural technique: Do we need individual recordings? J. Audio Eng. Soc. 1996, 44, 451–469. [Google Scholar]
- Shu-Nung, Y.; Chen, L.J. HRTF adjustments with audio quality assessments. Arch. Acoust. 2013, 38, 55–62. [Google Scholar]
- Gardner, W.G.; Martin, K.D. HRTF measurements of a KEMAR. J. Acoust. Soc. Am. 1995, 97, 3907–3908. [Google Scholar] [CrossRef]
- Majdak, P.; Balazs, P.; Laback, B. Multiple exponential sweep method for fast measurement of head-related transfer functions. J. Audio Eng. Soc. 2007, 55, 623–637. [Google Scholar]
- Li, S.; Peissig, J. Measurement of head-related transfer functions: A review. Appl. Sci. 2020, 10, 5014. [Google Scholar] [CrossRef]
- Zotkin, D.N.; Duraiswami, R.; Davis, L.S.; Mohan, A.; Raykar, V. Virtual audio system customization using visual matching of ear parameters. Object recognition supported by user interaction for service robots. In Proceedings of the 2002 International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 3, pp. 1003–1006. [Google Scholar]
- Torres-Gallegos, E.A.; Orduna-Bustamante, F.; Arámbula-Cosío, F. Personalization of head-related transfer functions (HRTF) based on automatic photo-anthropometry and inference from a database. Appl. Acoust. 2015, 97, 84–95. [Google Scholar] [CrossRef]
- Kahana, Y.; Nelson, P.A.; Petyt, M.; Choi, S. Numerical modelling of the transfer functions of a dummy-head and of the external ear. In Proceedings of the Audio Engineering Society Conference: 16th International Conference: Spatial Sound Reproduction, Rovaniemi, Finland, 10–12 April 1999; Audio Engineering Society: New York, NY, USA, 1999. [Google Scholar]
- Katz, B.F. Boundary element method calculation of individual head-related transfer function. I. Rigid model calculation. J. Acoust. Soc. Am. 2001, 110, 2440–2448. [Google Scholar] [CrossRef]
- Otani, M.; Ise, S. Fast calculation system specialized for head-related transfer function based on boundary element method. J. Acoust. Soc. Am. 2006, 119, 2589–2598. [Google Scholar] [CrossRef] [PubMed]
- Lei, W.; Xiangyang, Z. New method for synthesizing personalized head-related transfer function. In Proceedings of the 2016 IEEE International Workshop on Acoustic Signal Enhancement (IWAENC), Xi’an, China, 13–16 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Grijalva, F.; Martini, L.; Florencio, D.; Goldenstein, S. Deep neural network based HRTF personalization using anthropometric measurements. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 559–570. [Google Scholar] [CrossRef]
- Qi, W.; Su, H. A cybertwin based multimodal network for ecg patterns monitoring using deep learning. IEEE Trans. Ind. Inform. 2022, 18, 6663–6670. [Google Scholar] [CrossRef]
- Chun, C.J.; Moon, J.M.; Lee, G.W.; Kim, N.K.; Kim, H.K. Deep neural network based HRTF personalization using anthropometric measurements. In Proceedings of the Audio Engineering Society Convention 143, New York, NY, USA, 18–21 October 2017; Audio Engineering Society: New York, NY, USA, 2017. [Google Scholar]
- Lee, G.W.; Kim, H.K. Personalized HRTF modeling based on deep neural network using anthropometric measurements and images of the ear. Appl. Sci. 2018, 8, 2180. [Google Scholar] [CrossRef]
- Ben-Hur, Z.; Alon, D.L.; Mehra, R.; Rafaely, B. Binaural reproduction based on bilateral Ambisonics and ear-aligned HRTFs. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 901–913. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Duan, Z.; Bocko, M. Global HRTF Personalization Using Anthropometric Measures. In Proceedings of the Audio Engineering Society Convention 150, Online, 25–28 May 2021; Audio Engineering Society: New York, NY, USA, 2021. [Google Scholar]
- Kulkarni, A.; Colburn, H.S. Role of spectral detail in sound-source localization. Nature 1998, 396, 747–749. [Google Scholar] [CrossRef] [PubMed]
- Romigh, G.D.; Brungart, D.; Stern, R.M.; Simpson, B.D. The role of spatial detail in sound-source localization: Impact on HRTF modeling and personalization. In Proceedings of the Meetings on Acoustics ICA2013, Montreal, QC, Canada, 2–7 June 2013; Acoustical Society of America: Melville, NY, USA, 2013; Volume 19, p. 050170. [Google Scholar]
- Algazi, V.R.; Duda, R.O.; Thompson, D.M.; Avendano, C. The cipic hrtf database. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575), New Platz, NY, USA, 21–24 October 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 99–102. [Google Scholar]
- Emeršič, Ž.; Štruc, V.; Peer, P. Ear recognition: More than a survey. Neurocomputing 2017, 255, 26–39. [Google Scholar] [CrossRef]
- Emeršič, Ž.; Gabriel, L.L.; Štruc, V.; Peer, P. Convolutional encoder–decoder networks for pixel-wise ear detection and segmentation. IET Biom. 2018, 7, 175–184. [Google Scholar] [CrossRef]
- Emeršič, Ž.; Meden, B.; Peer, P.; Štruc, V. Evaluation and analysis of ear recognition models: Performance, complexity and resource requirements. Neural Comput. Appl. 2020, 32, 15785–15800. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 499–515. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Emeršič, Ž.; Playà, N.O.; Štruc, V.; Peer, P. Towards accessories-aware ear recognition. In Proceedings of the 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI), San Carlos, Alajuela, Costa Rica, 18–20 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Ensembles of deep learning models and transfer learning for ear recognition. Sensors 2019, 19, 4139. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML’10: 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Zhi, B.; Zotkin, D.N.; Duraiswami, R. Towards Fast And Convenient End-To-End HRTF Personalization. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 441–445. [Google Scholar]
- Wang, M.; Deng, W. Deep Face Recognition: A Survey. arXiv 2018, arXiv:1804.06655. [Google Scholar] [CrossRef]
- Qi, W.; Aliverti, A. A multimodal wearable system for continuous and real-time breathing pattern monitoring during daily activity. IEEE J. Biomed. Health Inform. 2019, 24, 2199–2207. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Trainable Parameters | Non Trainable Parameters | No. of Layers |
|---|---|---|---|
| VGG19 | 51,813 | 20,024,384 | 19 |
| ResNet50 | 206,949 | 23,587,712 | 50 |
| InceptionV3 | 206,949 | 21,802,784 | 159 |
| Xception | 54,528 | 20,861,480 | 126 |
| MobileNet | 103,525 | 3,228,864 | 28 |
| SimpleNet | 19,392 | 0 | 3 |
| Methods | Global SD |
|---|---|
| Average HRTF | 7.61 dB |
| Full-measurements HRTF | 5.22 dB |
| TFACE HRTF | 5.31 ± 3.154 dB |
| Proposed HRTF | 5.31 dB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Sheng, Z.; Fang, Y. Magnitude Modeling of Personalized HRTF Based on Ear Images and Anthropometric Measurements. Appl. Sci. 2022, 12, 8155. https://doi.org/10.3390/app12168155
Zhao M, Sheng Z, Fang Y. Magnitude Modeling of Personalized HRTF Based on Ear Images and Anthropometric Measurements. Applied Sciences. 2022; 12(16):8155. https://doi.org/10.3390/app12168155
Chicago/Turabian StyleZhao, Manlin, Zhichao Sheng, and Yong Fang. 2022. "Magnitude Modeling of Personalized HRTF Based on Ear Images and Anthropometric Measurements" Applied Sciences 12, no. 16: 8155. https://doi.org/10.3390/app12168155
APA StyleZhao, M., Sheng, Z., & Fang, Y. (2022). Magnitude Modeling of Personalized HRTF Based on Ear Images and Anthropometric Measurements. Applied Sciences, 12(16), 8155. https://doi.org/10.3390/app12168155