
Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism

Abstract
:
1. Introduction
- We target sentiment analysis in the field of Chinese e-commerce product reviews. Based on the ERNIE word embedding model, BiLSTM model, and attention mechanism, we proposed a Chinese e-commerce review sentiment analysis model EBLA, which was tested on the real crawled Jingdong appliance review dataset and achieved good results, the model outperforms many classic deep learning models proposed by other researchers, can provide more accurate reference for consumers and merchants. It has strong practicability in the field of sentiment analysis of Chinese e-commerce reviews.
- Dynamic word embedding model ERNIE was used to obtain the representation of the dynamic word vector of the review text, which effectively solves the polysemy problem in Chinese text. In addition, it addresses the challenge of dimension mapping in the sentiment analysis of e-commerce product reviews.
- Since BiLSTM can fully capture contextual semantic information from the front and rear directions, it was applied to the sentiment analysis problem to solve the sentiment word disambiguation.
2. Related Work
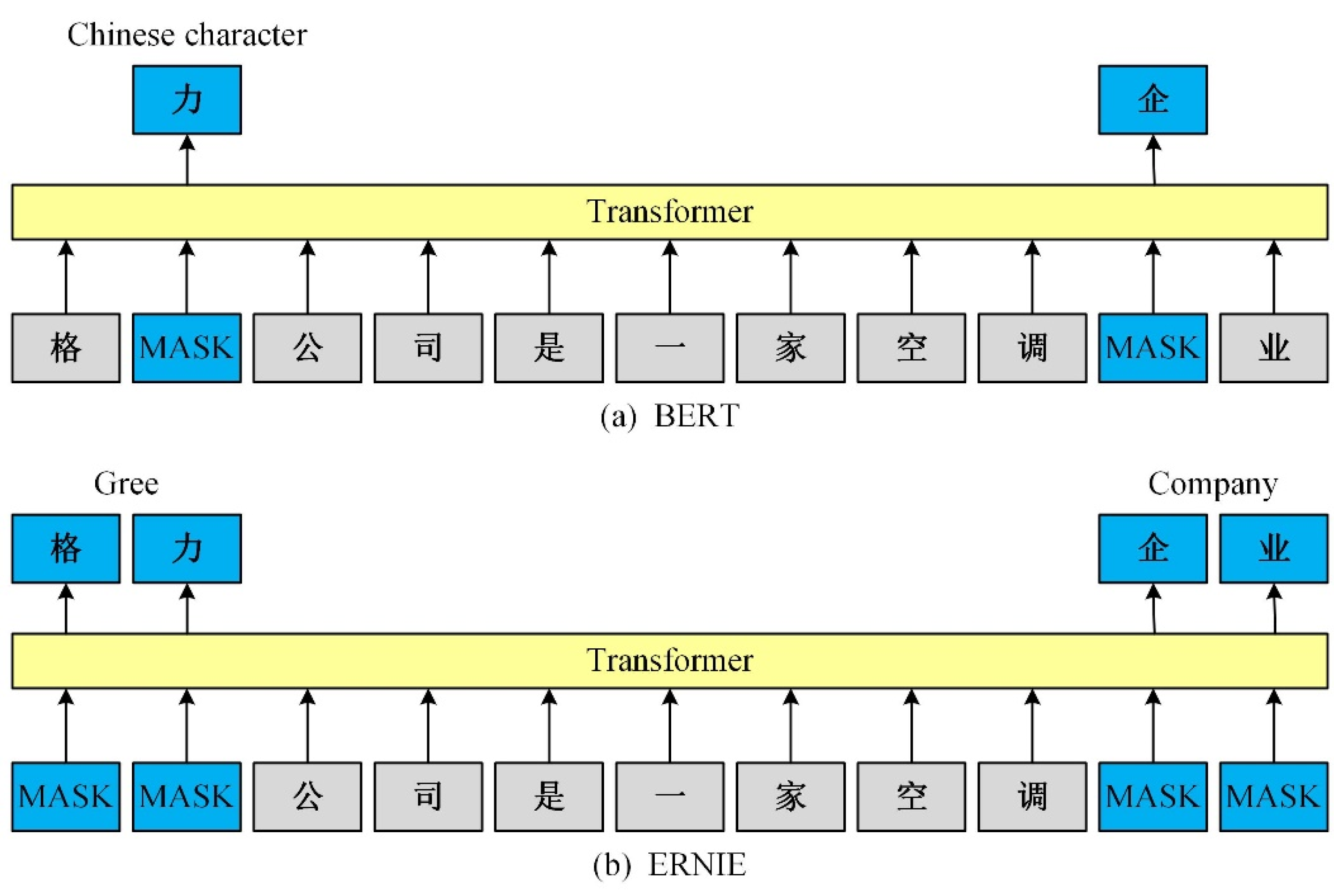
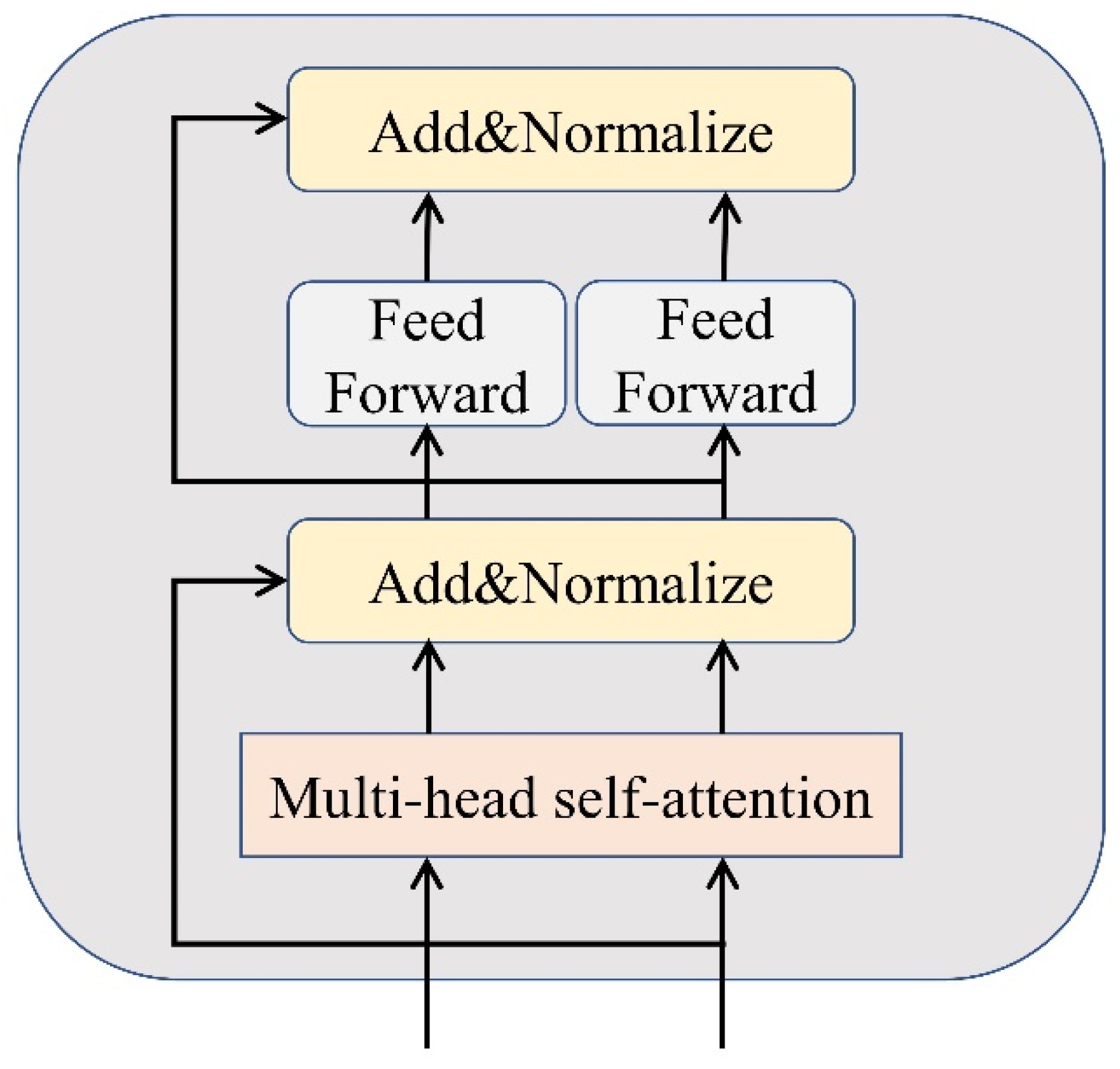
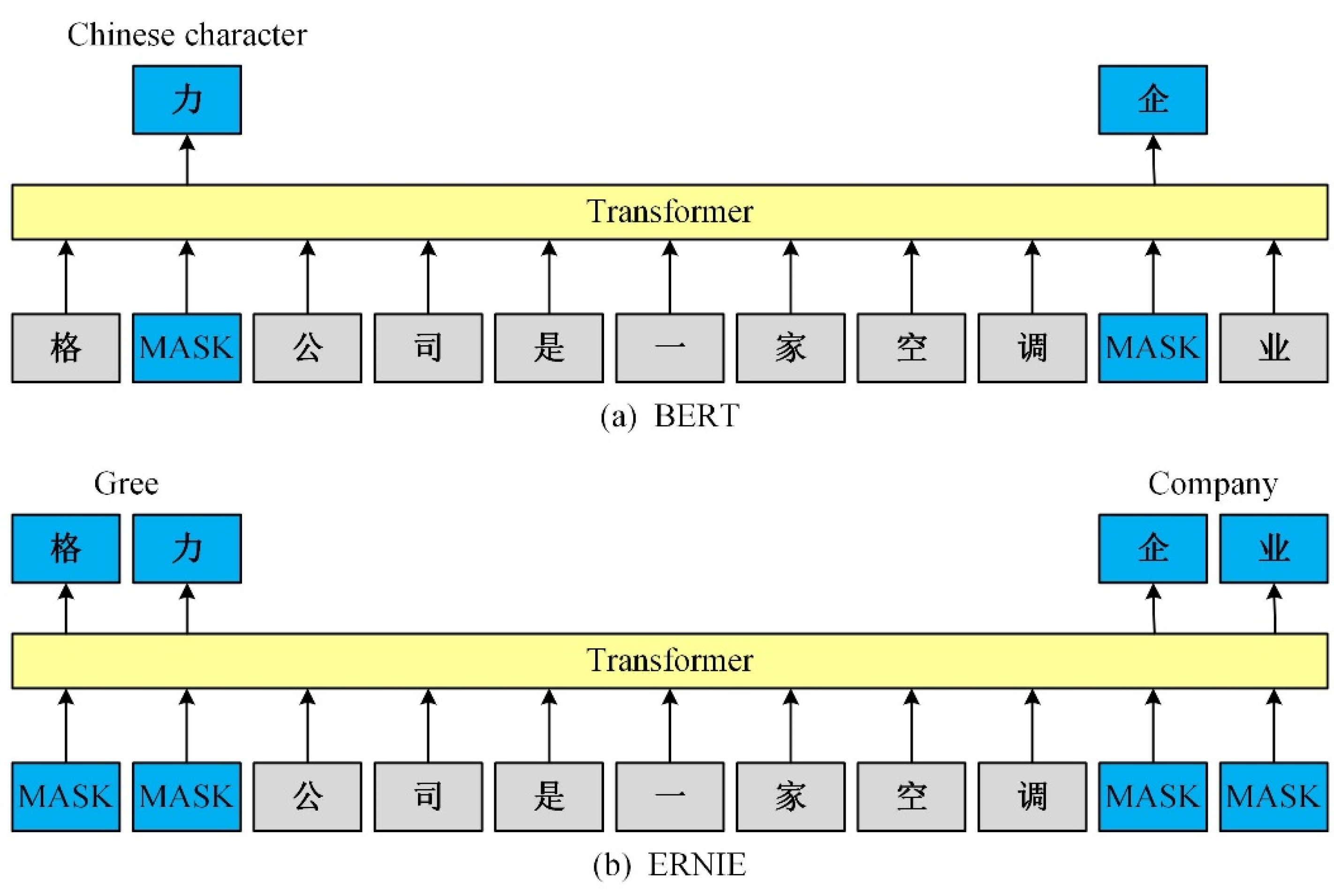
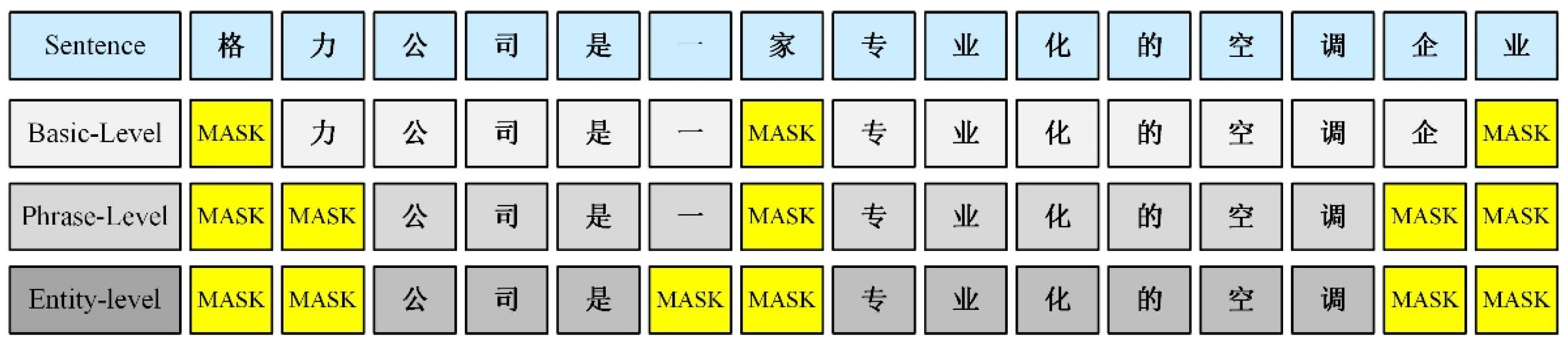
2.1. ERNIE Word Embedding
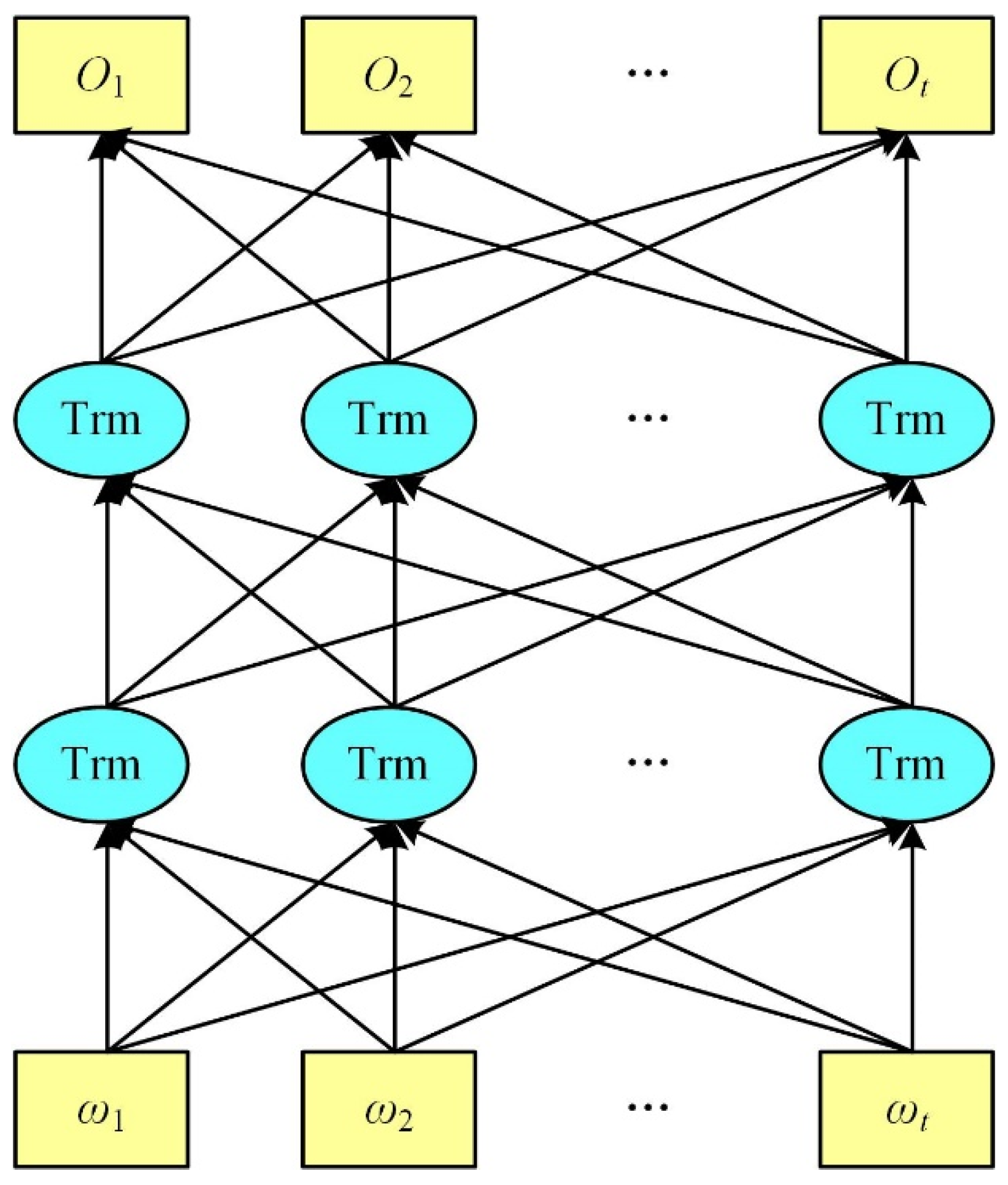
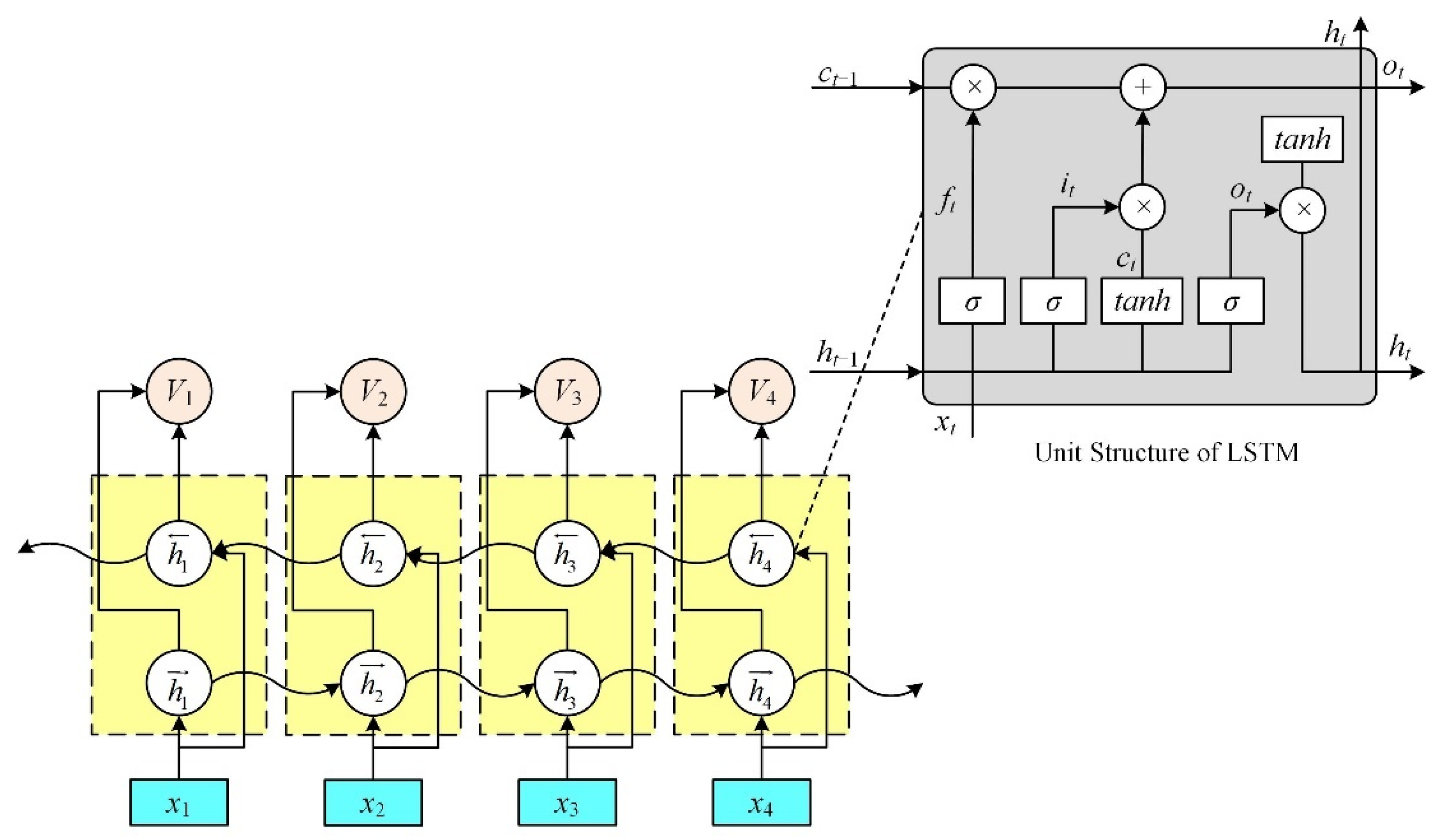
2.2. BiLSTM
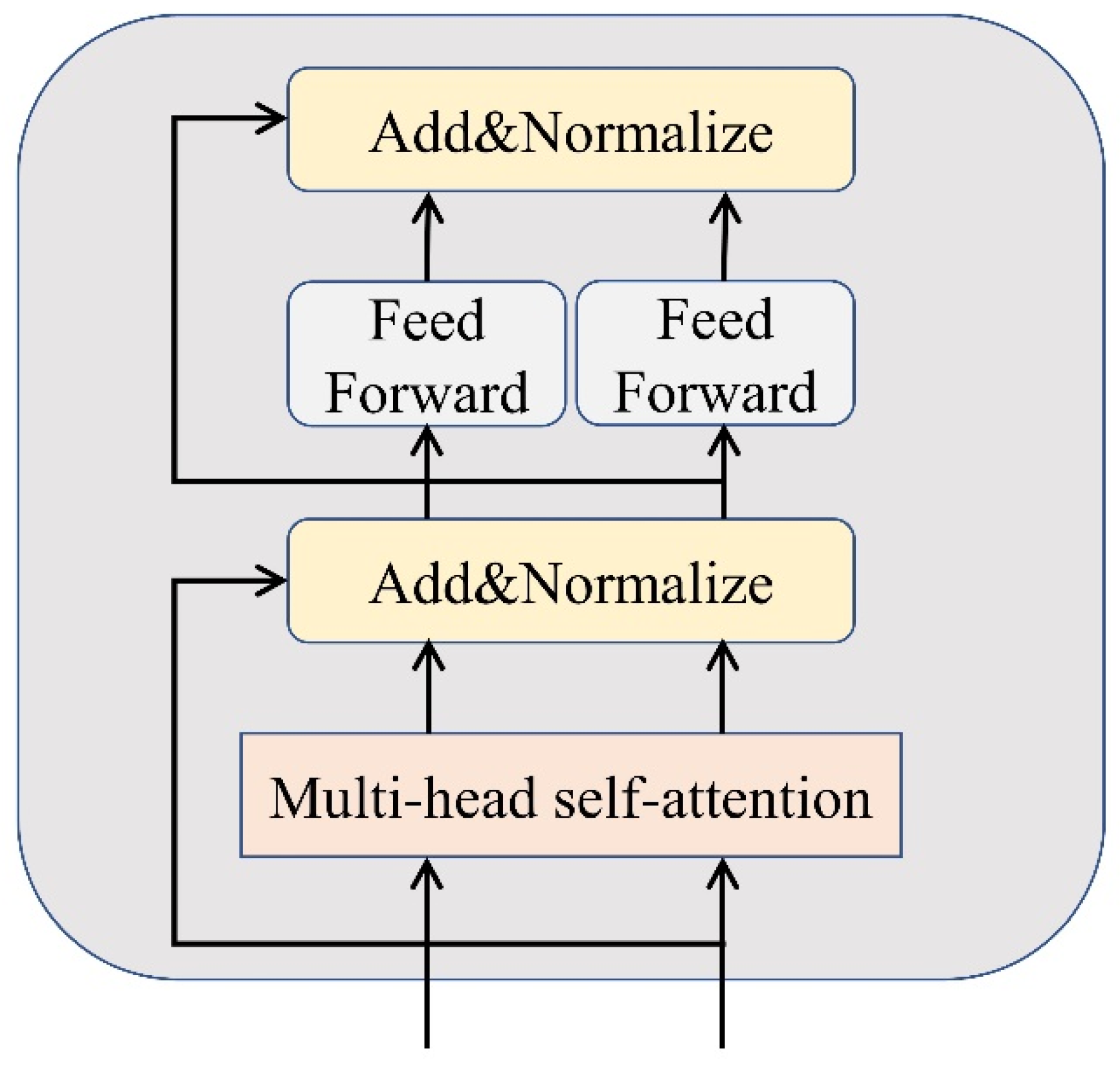
2.3. Attention Mechanism
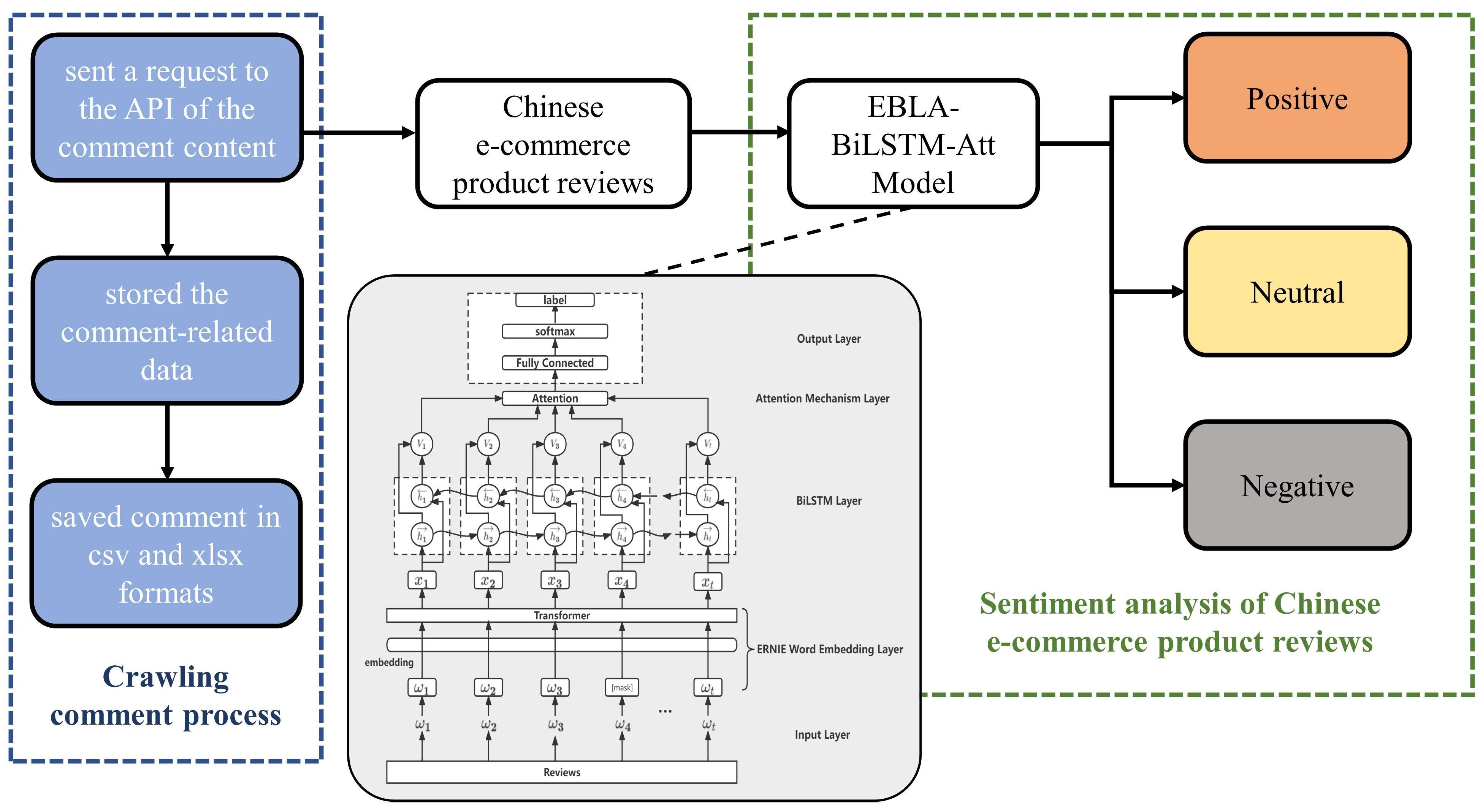
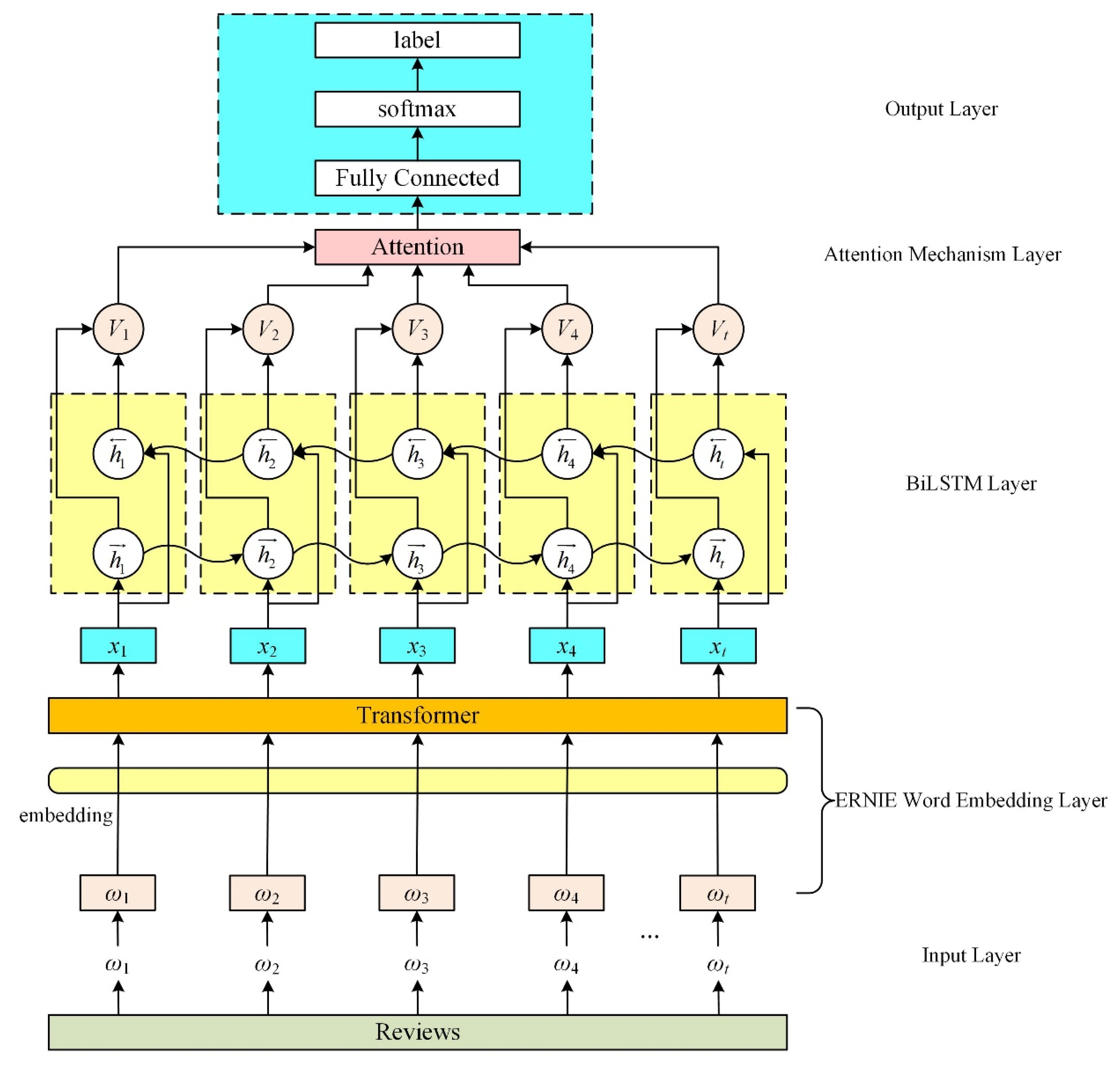
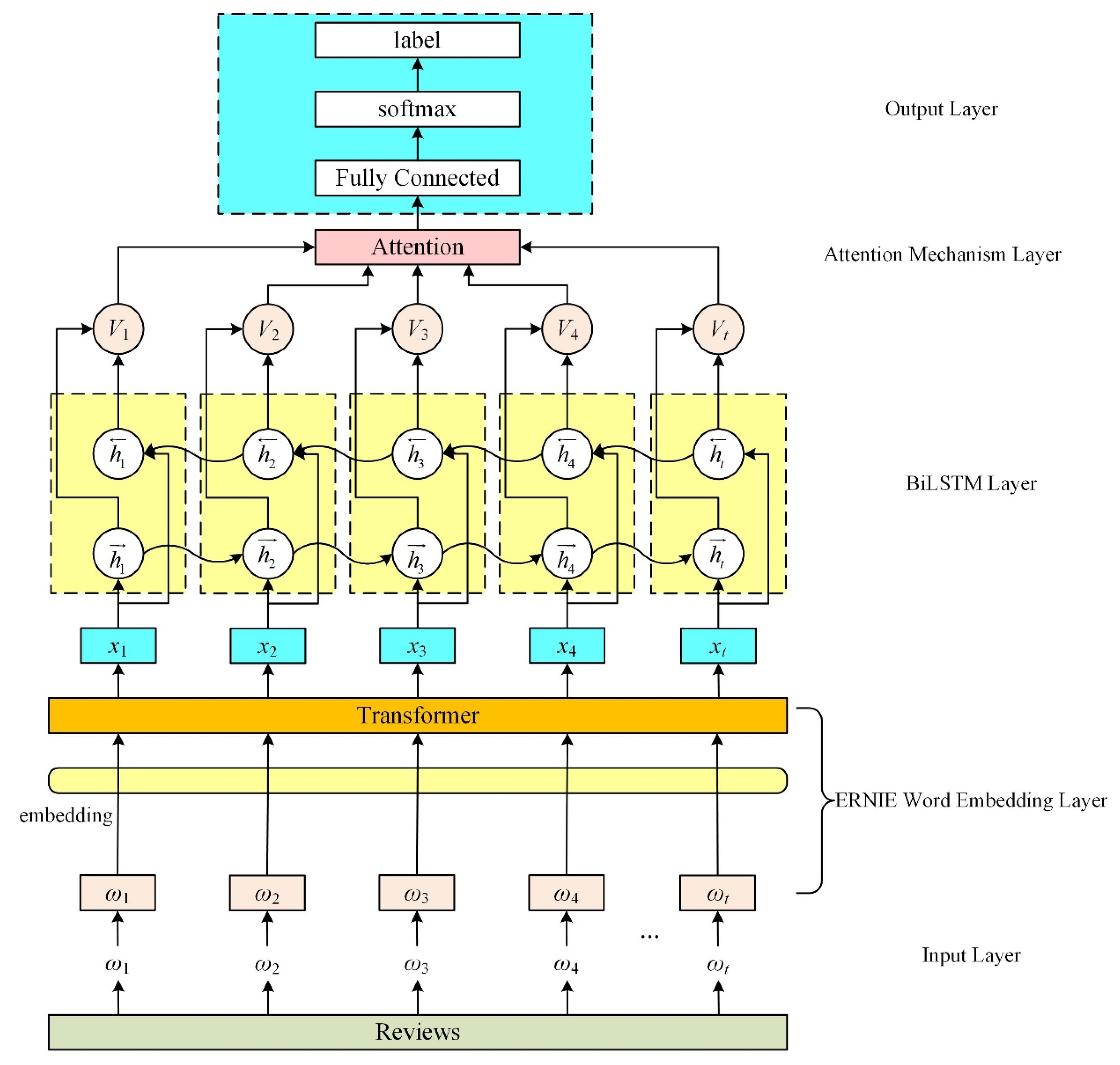
3. Method and Materials
3.1. Input Layer
3.2. ERNIE Word Embedding Layer
3.3. BiLSTM Layer
3.4. Attention Mechanism Layer
3.5. Output Layer
4. Experimental Design and Result Analysis
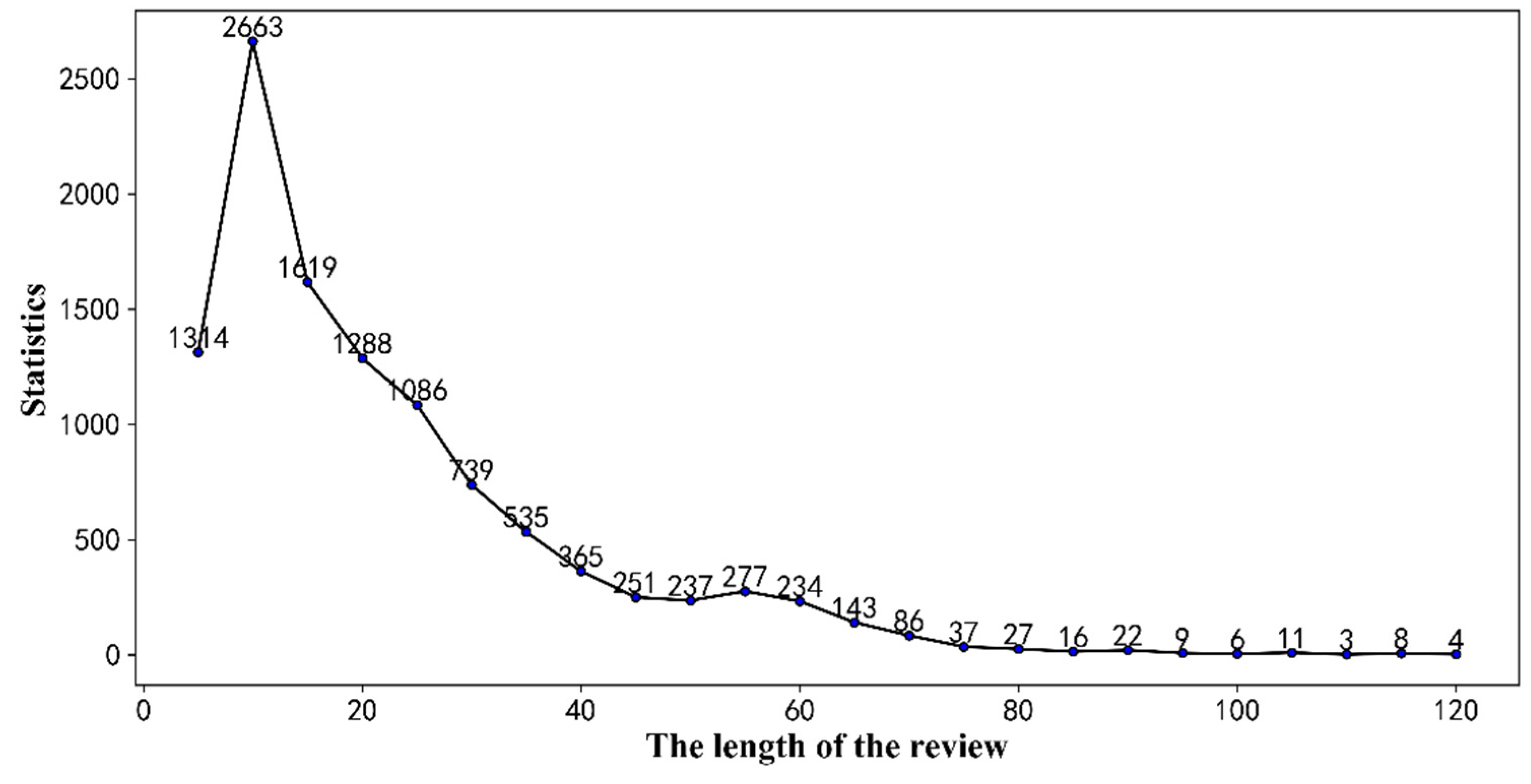
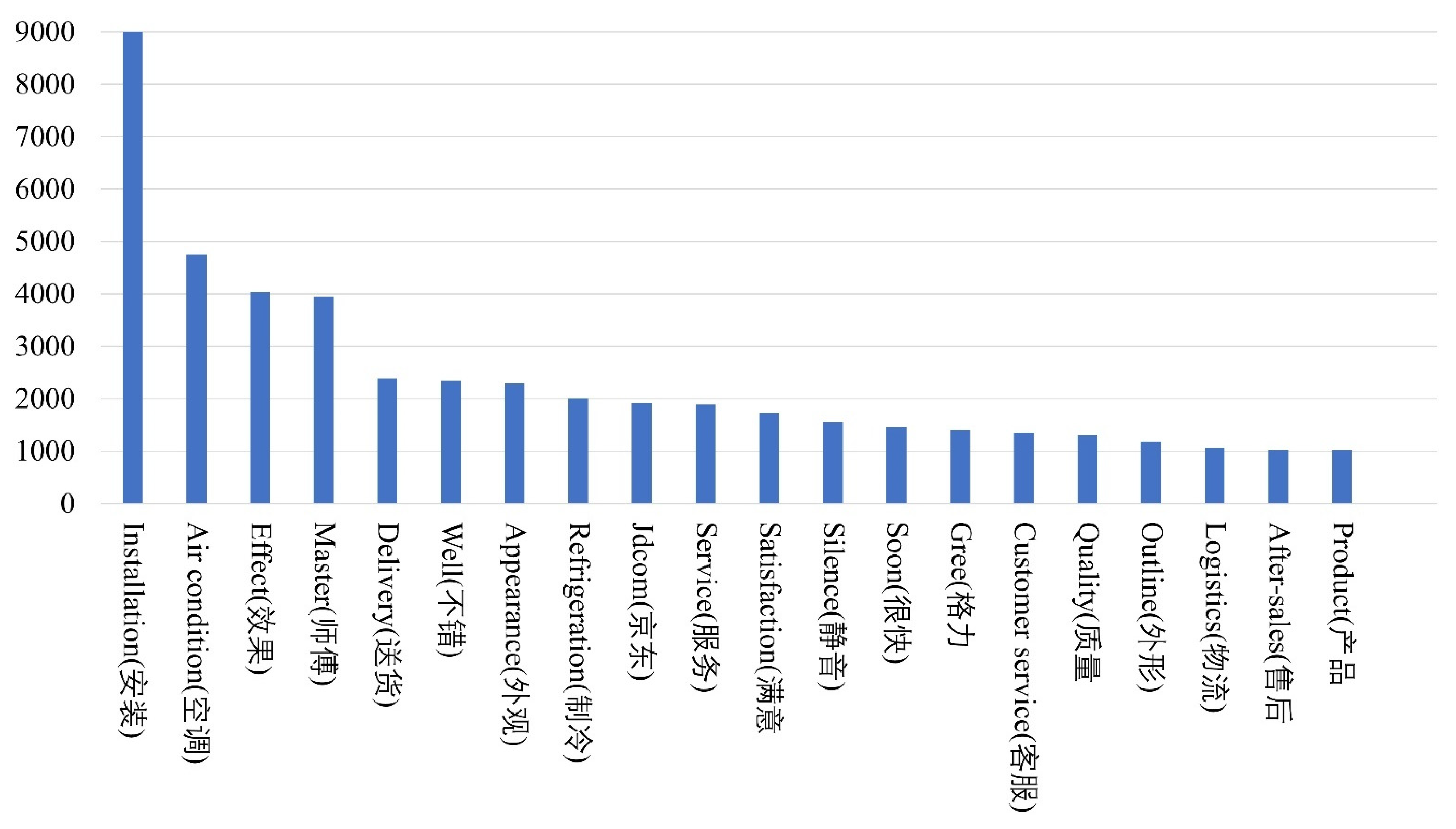
4.1. Dataset
4.2. Analysis of Word Frequency and Word Cloud
4.3. Experimental Parameters
- (1)
- The public parameter settings of the experiment are shown in Table 2:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| require_improvement | 1000 |
| sequence_length | 64 |
| epochs | 30 |
| learning_rate | 4 × 10−5 |
| batch_size | 128 |
| dropout | 0.1 |
- (2)
- The special parameter settings of each model are shown in Table 3:
| Model | Parameters |
|---|---|
| TextCNN | filter_sizes = (2, 3, 4), num_filters = 256 |
| RCNN | hidden_size = 256, num_layers = 1, pooling = Max |
| BiLSTM | hidden_size = 128, num_layers = 2 |
| BiLSTM-Att | hidden_size = 128, num_layers = 2 |
| BERT-CNN | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256 |
| BERT-BiLSTM-Att | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256, rnn_hidden = 768, num_layers = 2 |
| ERNIE-CNN | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256 |
| ERNIE-RCNN | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256, rnn_hidden = 256, num_layers = 2, pooling=Max |
| ERNIE-BiLSTM | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256, rnn_hidden = 768, num_layers = 2 |
| ERNIE-BiLSTM-Att | hidden_size = 768, filter_sizes = (2, 3, 4), num_filters = 256, rnn_hidden = 768, num_layers = 2 |
4.4. Performance Indicators
4.5. Results and Discussion
- (1)
- Comparative Experiment for Different Word Embedding Models
- (2)
- Comparative Experiment of Different Sentiment Analysis Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Att | Attention Mechanism |
| BERT | Bidirectional Encoder Representation from Transformer |
| BiLSTM | Bidirectional Long Short-term Memory |
| CNN | Convolutional Neural Networks |
| ELMo | Embeddings from Language Models |
| ERNIR | Enhanced Representation through Knowledge Integration |
| GloVe | Global Vectors for Word Representation |
| LSTM | Long Short-term Memory |
| MLM | Mask Language Model |
| NNLM | Neural Network Language Model |
| NSP | Next Sentence Prediction |
| RNN | Recurrent Neural Networks |
| RCNN | Recurrent Convolutional Neural Network |
References
- Yang, L.; Li, Y.; Wang, J. Sentiment analysis for E-commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Guo, B.; Li, S.; Wang, H.; Zhang, X.; Gong, W.; Yu, Z.; Sun, Y. Examining Product Reviews with Sentiment Analysis and Opinion Mining. Data Anal. Knowl. Discov. 2017, 12, 1–9. [Google Scholar]
- Ward, J.C.; Ostrom, A.L. The internet as information minefield: An analysis of the source and content of brand information yielded by net searches. J. Bus. Res. 2003, 56, 907–914. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020; pp. 1–2. [Google Scholar]
- Panthati, J.; Bhaskar, J.; Ranga, T.K.; Challa, M.R. Sentiment Analysis of Product Reviews Using Deep Learning. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 2408–2414. [Google Scholar]
- Yan, L.; Zhu, X.; Chen, X. Emotional classification algorithm of comment text based on two-channel fusion and BiLSTM-attention. J. Univ. Shanghai Sci. Technol. 2021, 43, 597–605. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural. Inf. Process Syst. 2017, 30, 5998–6008. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Hinton, G.E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986; p. 12. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. Adv. Neural. Inf. Process Syst. 2000, 13, 1137–1155. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Wu, H. Ernie: Enhanced representation through knowledge integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural. Inf. Process Syst. 2014, 27. [Google Scholar]
- Hu, Y.; Tong, T.; Zhang, X.; Peng, J. Self-attention-based BGRU and CNN for Sentiment Analysis. Comput. Sci. 2022, 49, 252–258. [Google Scholar]
- Araque, O.; Corcuera-Platas, I.; Sánchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert. Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Rev. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, X.; Yu, X. User Preference Analysis Based on Product Review Mining. Inf. Sci. 2022, 40, 58–65. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; pp. 155–156. [Google Scholar]
- Li, S.; Zhao, Z.; Hu, R.; Li, W.; Liu, T.; Du, X. Analogical reasoning on chinese morphological and semantic relations. arXiv 2018, arXiv:1805.06504. [Google Scholar]
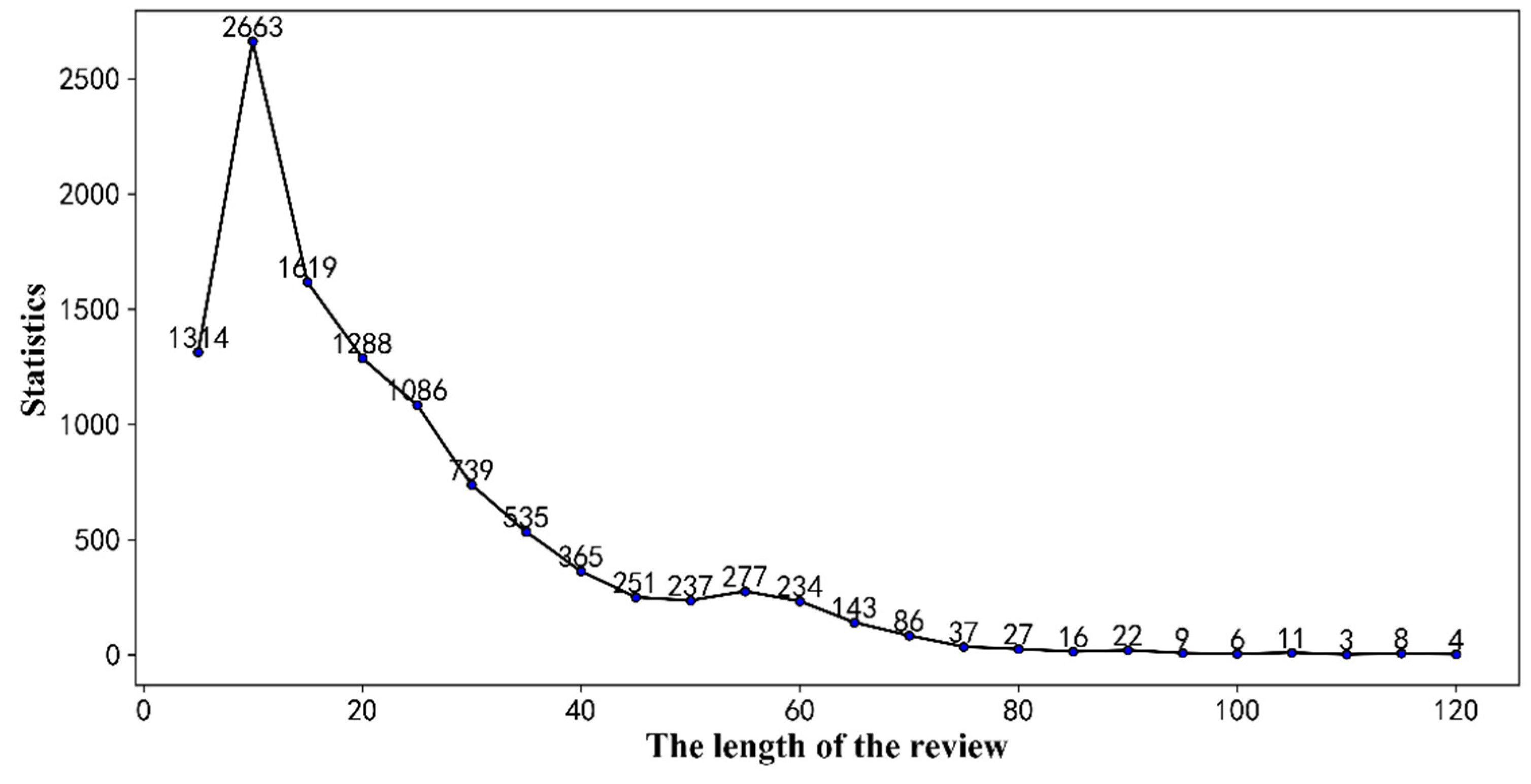
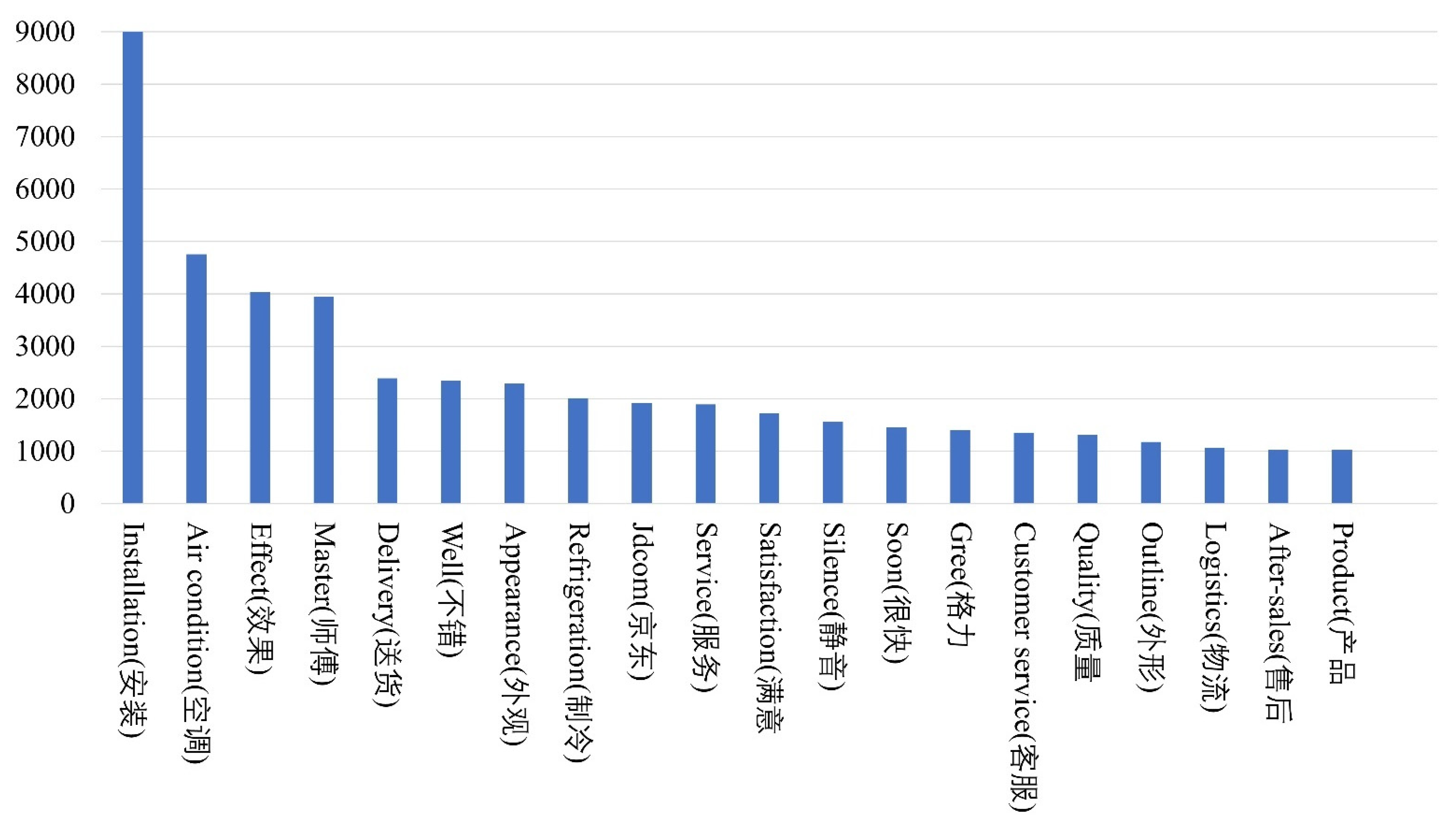

| Positive | Neutral | Negative | Total | |
|---|---|---|---|---|
| Training set | 3600 | 1500 | 1500 | 6600 |
| Test set | 1200 | 500 | 500 | 2200 |
| Validation set | 1200 | 500 | 500 | 2200 |
| Total | 6000 | 2500 | 2500 | 11,000 |
| Model | R | P | F1 |
|---|---|---|---|
| Word2Vec-CNN | 83.21 | 83.59 | 83.33 |
| BERT-CNN | 85.59 | 85.50 | 85.50 |
| ERNIE-CNN | 86.37 | 86.77 | 86.36 |
| Word2Vec-BiLSTM-Att | 81.51 | 82.05 | 81.58 |
| BERT-BiLSTM-Att | 84.80 | 85.14 | 84.77 |
| EBLA | 87.87 | 87.55 | 87.48 |
| Model | R | P | F1 |
|---|---|---|---|
| BiLSTM | 74.72 | 75.73 | 74.44 |
| TextCNN | 83.21 | 83.59 | 83.33 |
| RCNN | 81.29 | 82.09 | 81.35 |
| BiLSTM-Att | 81.51 | 82.05 | 81.58 |
| ERNIE | 86.37 | 86.77 | 86.51 |
| ERNIE-BiLSTM | 86.56 | 86.64 | 86.52 |
| ERNIE-CNN | 86.37 | 86.77 | 86.36 |
| ERNIE-RCNN | 86.81 | 85.77 | 85.01 |
| EBLA | 87.87 | 87.55 | 87.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Lin, M.; Wang, Y. Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism. Appl. Sci. 2022, 12, 7182. https://doi.org/10.3390/app12147182
Huang W, Lin M, Wang Y. Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism. Applied Sciences. 2022; 12(14):7182. https://doi.org/10.3390/app12147182
Chicago/Turabian StyleHuang, Weidong, Miao Lin, and Yuan Wang. 2022. "Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism" Applied Sciences 12, no. 14: 7182. https://doi.org/10.3390/app12147182
APA StyleHuang, W., Lin, M., & Wang, Y. (2022). Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism. Applied Sciences, 12(14), 7182. https://doi.org/10.3390/app12147182