1. Introduction
In Saudi Arabia, the future of the country, which has a mostly young population, will depend on the cohesiveness of the communities and on authorities to keep the population living as a cohesive unit. In the future, discrimination will not be tolerated against any part of the population, be it expatriates or nationals with different views politically, socially, economically, and in all other aspects within the community. For Saudi Arabia to prosper in the future, it must be more welcoming to foreigners, tourists, businessmen, and others. However, there will always be a small portion of any community that may disagree and like to spread hate and intolerance against others. Thus, it has become a national security issue to monitor hate speech across the different communication mediums (email, websites, SMS, social media, voice, etc.); currently, there is a need for a fully automated machine learning-based system for Arabic language communication monitoring. To monitor these mediums manually is an impossible task, and to monitor them electronically using conventional means would also yield poor results. In the age of artificial intelligence (AI), smart intelligent systems that can progressively learn to identify hate, racism, and discriminative words, phrases, and sentences will be required. This system will be smart enough to identify these kinds of conversations and able to determine if they are one-time phrases or if they profile a certain pattern for an individual or organization. In addition, the system will be able to alert the authorities when repetitive unacceptable behavior is observed from an individual group or organization. The system will be called a “Peace Monitor” and may also be used to identify bullying on social media. Thus, the motivation for developing an automatic machine learning-based system that is able to detect and identify hate speech is especially needed in countries that are currently progressing to be more inclusive; it will also be useful for the prevention of cyberbullying, particularly in school-aged children with access to social media platforms. A great deal of work has been carried out on the detection of hate speech and cyberbullying in other languages, especially English; however, little work has been completed in Arabic for various reasons, including the complex nature of the Arabic language and the lack of unified large datasets. The aim of this study was to develop a large Arabic language dataset with seven classes that could be used as the basis for the development of an even larger dataset with more classes to be used as a unified dataset for researchers in this field. In addition, this study aimed to develop a modified machine learning algorithm that was able to detect and accurately classify hate speech in Arabic.
Machine learning and deep learning algorithms have gained momentum in the past decade as a means to automate many tasks that have conventionally been performed by humans. For example, machine learning and deep learning algorithms are being explored for the automated diagnosis of many diseases and health conditions [
1,
2,
3,
4]. However, this is just an example, and the use of these algorithms has been researched in relation to all aspects of human life, from self-driving cars to monitoring the quality of food ordered in fast-food restaurants. The fast pace at which technology has advanced to produce high-speed computing machines and the advancement of the Internet of Things (IoT), where sensors are attached to everything and everything is connected to either the cloud or the internet, has increased the availability of big data that can be analyzed to produce results that are productive and ease human life. This has paved the way for machine learning and deep learning algorithms to be explored in all walks of life to automate tasks previously carried out by humans at much faster speeds and with more accuracy [
5,
6]. One of the areas in which these algorithms have been explored is text recognition, whether it is handwritten or typed text [
7].
The main contributions of this research can be summarized as follows:
The final product of such a system has various advantages and uses, and some of the benefits of the final product are as follows:
The proposed system can be used in Arabic-speaking countries to ensure a future that is consistent with peace and tolerance.
The system can be used by the authorities to save lives because it can predict violent behavior before it occurs.
The system can be used in smart cities as a smart feature, which can have several added features to ensure safety and security.
The system can be expanded to include other Arabic dialects and thus can be used in other Arab countries.
The system can be used by western countries for Arabic-speaking populations.
The rest of the paper is organized as follows:
Section 2 includes a literature review of the algorithms explored for text classification and recognition.
Section 3 details the novel methodology proposed in this paper.
Section 4 highlights the experimental results and discussion.
Section 5 highlights the conclusion.
2. Literature Review
A great deal of research has been carried out on hate speech in various languages, especially English. The authors of [
8] proposed the use of a convolutional neural network for the classification of hate speech. The dataset they used divided hate speech into several sections, including racist sentences, sexist sentences, harmful words, and threatening phrases, such as death threats. The database consisted of 6655 tweets: 91 racism tweets, 946 sexism tweets, 18 tweets with both racism and sexism, and 5600 non-hate-speech tweets. Among the different algorithms used, they reported that the best results achieved were a precision of 86.61%, a recall of 70.42%, and an F-score of 77.38%. The authors of [
9] proposed the use of a support vector machine (SVM) for multiclass classification. Their dataset consisted of 14,509 tweets annotated to three categories: hate, offensive, and OK. In these experiments, the authors also proposed surface n-grams, word skip-grams, and Brown clusters as the features to be extracted. The total dataset consisted of 2399 sentences classified as hate, 4836 sentences classified as offensive, and 7274 sentences classified as OK. They reported that the best accuracy of 78% was achieved using a character 4-g model. The authors of [
10] collected 17,567 Facebook posts annotated as no hate, weak hate, and strong hate as a dataset for their proposed system. They proposed the use of two methods to capture and classify hate phrases and speech, which are published daily on one of the largest social networking sites—Facebook. The two methods used in this study were support vector machines (SVM) and long short-term memory (LSTM), which is a recurrent neural network (RNN). The SVM system provides excellent and wide levels for analyzing and classifying linguistic texts, and these features have been used well in polar sentiment classification tasks.
On the other hand, the LSTM system was used to expand the ranges in order to dissect longer sentences that were not observably accurate from the first scan. Among their results, the authors reported the highest accuracy of 80.6% using the SVM classifier. In [
11], the authors proposed the use of an ensemble neural network for the classification of hate speech and used two publicly available datasets. Although accuracy was not reported as a result, the reported mean of the ensemble was 78.62%.
The authors of [
12] used seven publicly available datasets along with a state-of-the-art linear SVM. However, this study concentrated on feature extraction and specifically whether to use the extracted feature or engineer a set of features that might produce better results. The authors concluded that the selection (engineering) of a set of features produced better results than using all the extracted features. Moving away from the English language, the authors of [
13] created a new dataset consisting of 1100 tweets annotated and labeled as hate speech or non-hate speech. The features used in this study were word n-gram with n = 1 and n = 2 and character n-gram with n = 3 and n = 4 plus negative sentiment. Several machine learning algorithms were tested, including naïve Bayes (NB), support vector machine (SVM), Bayesian logistic regression (BLR), and random forest decision tree (RF). The highest F-measure of 93.5% was reported when using RF as a classifier. The authors of [
14] used a publicly available dataset of tweets that were divided into 260 tweets labeled “hate speech” and 445 tweets labeled “non-hate speech”. The five proposed and tested classifiers included NB, K-nearest neighbors (KNN), maximum entropy (ME), RF, and SVM. The authors used two ensemble methods: hard voting and soft voting. They concluded that the best results were achieved using ensemble methods and reported the best result when using soft voting with an F1 measure of 79.8% on an unbalanced dataset and 84.7% on a balanced dataset.
The authors of [
15] developed a dataset consisting of 10,000 tweets divided into the following classes: 1915 offensive tweets, of which 225 were deemed vulgar and 506 were labelled as hate speech, and the remaining 8085 tweets that were deemed clean. They used various classifiers, such as AdaBoost, Gaussian NB, perceptron, gradient boosting, logistic regression (LR), and SVM. They reported the best result with a precision of 88.6% using SVM. In [
16], the authors developed a dataset for Arabic speech collected from various sources, such as Facebook, Instagram, YouTube, and Twitter. They collected a total of 20,000 posts, tweets, and comments. They tested the dataset with 12 machine learning algorithms and two deep learning algorithms. They reported that the highest accuracy of 98.7% was achieved using the RNN. In [
17], the authors responded to a competition, OSACT4, to develop a machine learning algorithm for the classification of Arabic text and the detection of offensive text. They were provided with a dataset of 10,000 tweets. Their proposed method consisted of using ULMFiT, which was originally developed for English language detection. By using forward and backward training and finding the average of the two, they reported an accuracy of 96%.
The authors of [
18] also responded to a competition for the detection of Arabic text that was deemed ironic. The competition was held by the Forum for Information Retrieval (FIRE2019). They provided the contestants with a dataset of 4024 tweets divided into 2091 ironic and 1933 non-ironic tweets. The authors extracted several features, including TF-IDF word n-gram features, bag-of-words features, topic modeling features, and sentiment features. They used three types of ensemble learning: hybrid, deep, and classical. They reported their best F1 score of 84.4 and achieved third place. The authors of [
19] collected 450,000 tweets, of which 2000 were annotated and labeled. They extracted various features from the tweets, including syntactic dependencies between terms, their claim of well-founded/justified discrimination against social groups, and incitement to respond with antagonistic action. They found that the ensemble classification approach was the best at detecting hate speech.
In [
20], the authors used a publicly available dataset of 15,050 comments collected from controversial YouTube videos about Arabic celebrities. After preprocessing, the authors tested the data using the following classifiers: convolutional neural network (CNN), bidirectional long short-term memory (Bi-LSTM), Bi-LSTM and attention mechanisms, and finally a combined CNN-LSTM architecture. They also used Bayesian optimization to tune the hyperparameters of the network models. They reported that their best result was achieved using CNN-LSTM, with a recall of 83.46%.
In [
21], the authors developed a dataset consisting of 3235 tweets concerning religious issues, of which 2590 were labeled as “not hate” and 642 were labeled as “hate speech.” They tested the dataset using many classifiers, including RF, complement NB, decision tree (DT), and CNN. They also employed two deep learning methods: CNN and RNN. CNN with FastText achieved the highest F1 measure of 52%. In [
22], the authors used a publicly available dataset from Fox News user comments consisting of 1528 comments, of which 435 were labeled as hateful. The authors employed the use of LSTM, bidirectional LSTM, bidirectional LSTM with attention, and an ensemble model. They found that the best results were achieved using the ensemble model, with an accuracy of 77.9%.
Table 1 presents a summary of these recent studies on text classification.
In this study, the recent research was thoroughly analyzed for the latest feature extraction methods, such as those listed and detailed in [
23,
24]. In addition, with reference to the preprocessing stage, the literature detailing the syntax and prejudice of text [
25] and that addressing the clash between symbolic AI and ML was thoroughly analyzed [
26].
As can be seen from the literature presented above, Arabic text detection and recognition is still an open area of research that has not received the full attention it deserves. It should be noted here that Arabic is spoken by nearly 422 million people, and 25 countries use Arabic as their official language. This research area is still lacking in having a unified extensive dataset for researchers to use as well as in the achievement of accuracy levels that can be implemented in practice. In this paper, a dataset that was developed from various tweets and divided into seven different classes will be presented. This is by far the largest number of classes for a dataset of Arabic hate speech according to the knowledge of the author. In addition, a novel technique to achieve the highest accuracy compared to that reported in the extant literature will also be proposed.
3. Materials and Methods
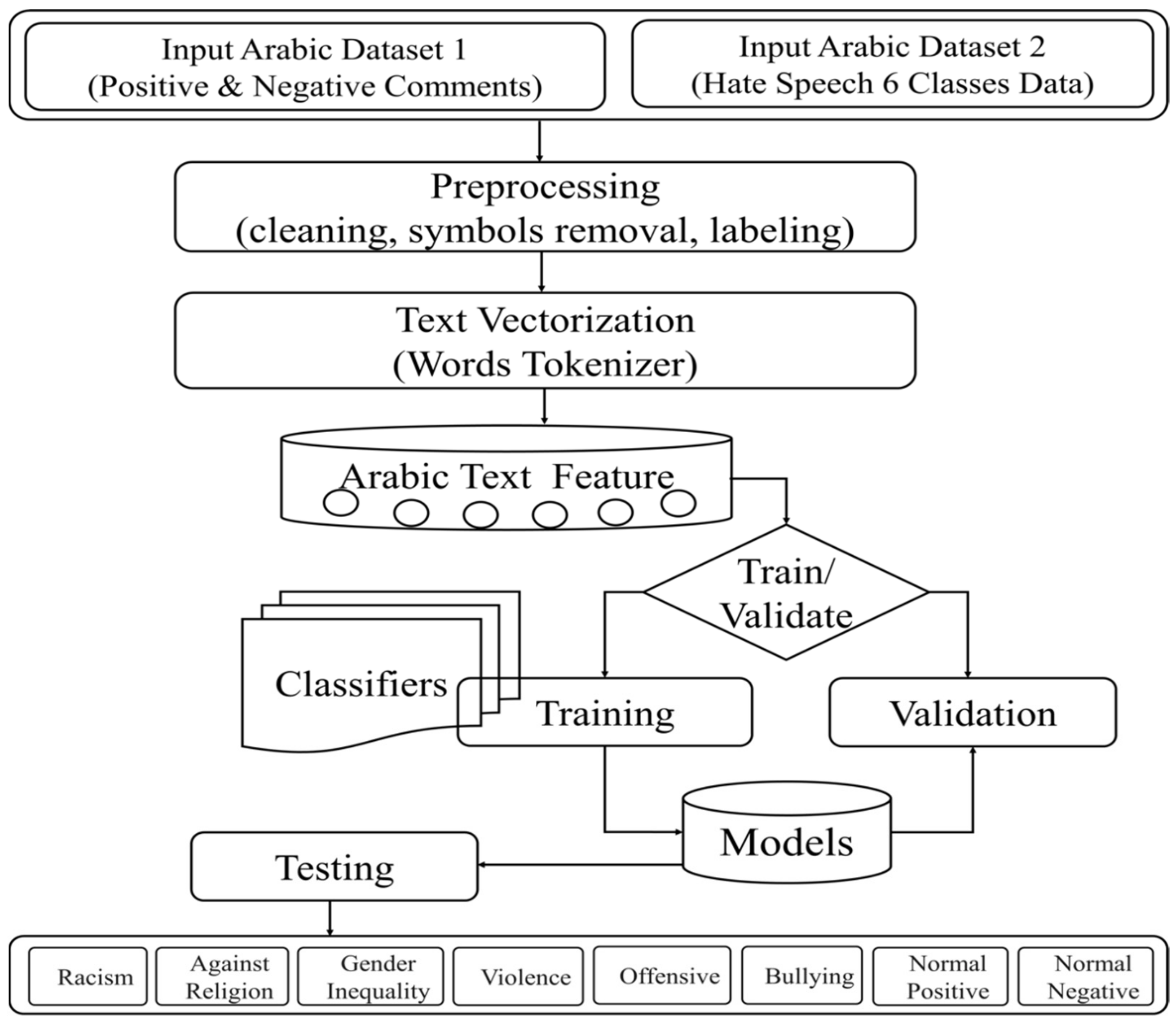
The system was built using machine learning, particularly deep learning-based neural networks, which are artificial intelligence-based learning algorithms that can be designed to identify words, phrases, and sentences from all communication media, including websites, social media, and others. The first step in designing an intelligent system is to train the system using a large dataset of various words, phrases, and sentences that are labeled as hate, racist, bullying, discriminatory, etc. The proposed methodology for this system is as follows: Initially, the dataset is divided into two datasets (one that includes the positive and negative comments and the other that that includes the rest of the classes). The datasets go through a preprocessing phase to clean the data and perform other operations, such as labeling and the removal of symbols. The dataset is then passed to another phase in which the text vectorization is performed. In this phase, the words are tokenized. The phase after that is used to extract the Arabic text features and divide the data for training and validation. The training data is passed to the classifiers that should classify the data into one of the seven classes. It was envisioned that the complete system would be completely autonomous with excellent accuracy that could be implemented in practical systems. The system can then be linked to a cloud-based serviceable to host large amounts of memory and allow access to computing power for real-time processing.
The proposed system is shown in
Figure 1. The first phase consists of dividing the dataset into two categories: one that holds the negative and positive comments, and another that holds the six hate speech classes. The combined dataset undergoes a preprocessing phase, which includes data cleaning, symbol removal, labeling, etc. The dataset is then passed to the second phase for text vectorization or word tokenizing. The very important phase of text feature extraction is then completed. The data are then split into two parts for training and validation, with 80% training and 20% validation. The 20% validation data are also split into 80% validation and 20% verification. Then, the classifiers are trained for the classification of text into one of the seven classes listed in the figure.
3.1. Experimental Dataset and Setup
A large Arabic dataset consisting of thousands of sentences, words, and social media comments was compiled from various sources and labeled accordingly into different classes. The dataset in itself is novel because it identifies words, phrases, and sentences in Arabic and divides them into seven distinct classes, making it unique among the currently published datasets for Arabic hate speech that usually contain two to four classes only. This new dataset will open the door for broad research from a wide audience of researchers in the AI field. The dataset contains a total of 4203 comments collected from various sources on social media. The comments were annotated and labeled by a group of undergraduate students whose mother tongue was Arabic and who were proficient in the dialect, as shown in
Table 2. Each comment was annotated and labeled by at least three students that agreed 100% on the class; otherwise, the comment was discarded. The experiments were performed using a Windows computer with i7-8700K (3.70 GHz) CPU, 32 GB memory, and NVIDIA GeForce GTX1080 GPU; the software code was written in Python.
3.2. Preprocessing and Word Embedding Layer for Arabic Hate Speech Dataset
The cleaning and preprocessing of data is an extremely vital step to increase accuracy. The Arabic hate speech dataset was subjected to a preprocessing stage in which the data were cleaned and irrelevant data were discarded. In addition, diacritics, symbols, special characters, and emojis were removed from the data. It should be noted that Arabic characters depend on the different Unicode representations; thus, a dictionary was created to map the same representation to their fixed characters.
Every sentence inside a single comment separated by space was taken and a default tokenizer was applied to remove symbols from the string. This was then converted to tensor to represent numerical data, which are suitable for neural networks. The data were then extensively labeled; this was a hard, laborious, and time-consuming task. To ensure that the labeling was performed correctly, randomly selected text was shown to a different set of students who were tasked with labeling it; the two labels were compared to indicate if the labeling task had been carried out accurately. The labels’ were converted from an integer to a tensor or float data type so each label contained a vector of the numeral that represented the label. The default batch size was set at 32; however, this, along with other hyperparameters, was changed during each experiment.
Word2Vec [
27] and global vector (GloVe) [
28] were the models chosen for word embedding, which allowed the system to learn word vectors according to their co-occurrence in sentences. This representation of the words in a lower dimension of vector space allowed the deep learning algorithms to map the words based on the similarity of the semantic properties. As shown in
Figure 2, two architectures are present for the Word2Vec: continuous bag of words (CBOW) and skip-gram (SG). The former predicts the target word using its contextual context, i.e., where it lies in the sentence within a window showing the words before and after it. The latter predicts the surrounding words based on the target word. After this extensive preprocessing, a vocabulary set of 25,000 words was created, and its size was changed based on the various experiments. The data were split into two as mentioned earlier, with 80% for training and 20% for validation.
3.3. Proposed Deep Recurrent Neural Network Model for Hate Speech Detection
With the advancement of more sophisticated processing power in computing machines, deep learning has been widely adopted in almost all data processing problems. A convolutional neural network (CNN) is characterized by very deep neural networks that can utilize the advantage of the inherent properties of data, particularly from image data but text as well. Recurrent neural networks (RNNs) are similar to CNNs; however, RNNs also manage the time domain. In a unidirectional (feedforward) RNN, the model learns word by word from start to end.
In the Arabic language, most meanings of words and sentences change based on where the word has occurred as well as the next words in the sentence. In bidirectional recurrent neural networks, two sequences are considered: the forward sequence (left to right) and the backward sequence (right to left). For example, an Arabic sequence can be used in the same order for the forward layer; however, in the backward layer, the order of the text will be reversed. In Arabic text classification, the time domain, which represents the order of the words in the input text, plays a vital role by solving the problem more effectively and enhancing the classification results. Long short-term memory (LSMT) can be used to solve the vanishing gradient problem, which occurs if a long bidirectional RNN is used alone.
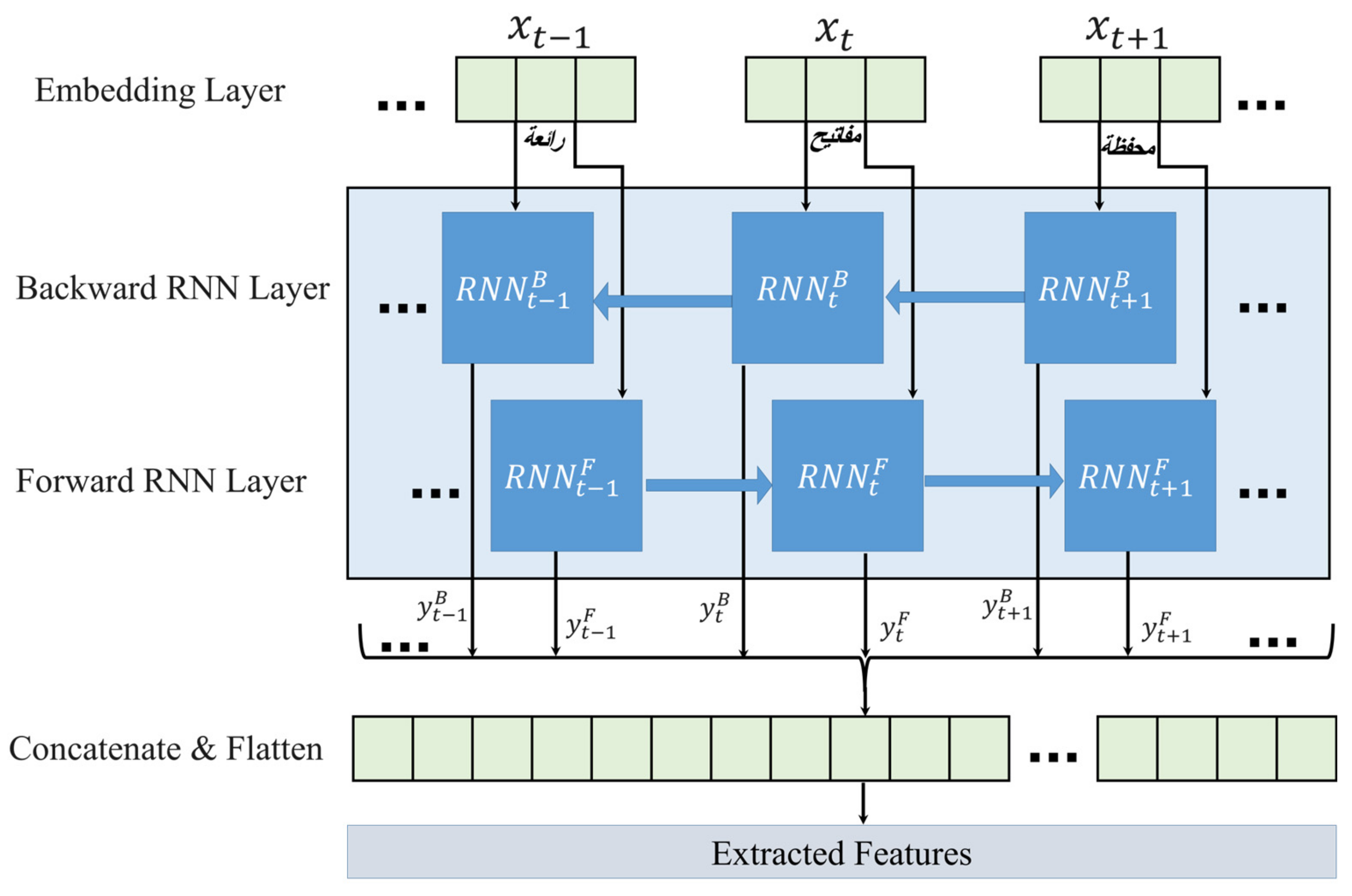
The proposed deep bidirectional RNN model for hate speech detection from the Arabic social media comments consists of 10 layers, including the input layer, bidirectional RNN layers, flatten layer, dense layers, dropout layers, and output layers.
Figure 3 shows the details of the RNN forward and backward layers used to extract the features. The embedding layer produced by Word2Vec and GloVe detailed earlier is then input into the backward RNN layer followed by the forward RNN layer. The output of the RNN is then concatenated, flattened, and input into the dense and dropout layers, as detailed in
Figure 4. The data are then classified into one of the seven classes.
In the proposed deep bidirectional recurrent neural network, the tanh activation function was used for the dense layers while the sigmoid activation function was used for the output layer. The experiments were performed using a learning rate of 0.001 with 32 batch sizes for 50 iterations. The best validation accuracy-based model was saved out of 50 iterations, which were further used for the test dataset to generate and compare results.
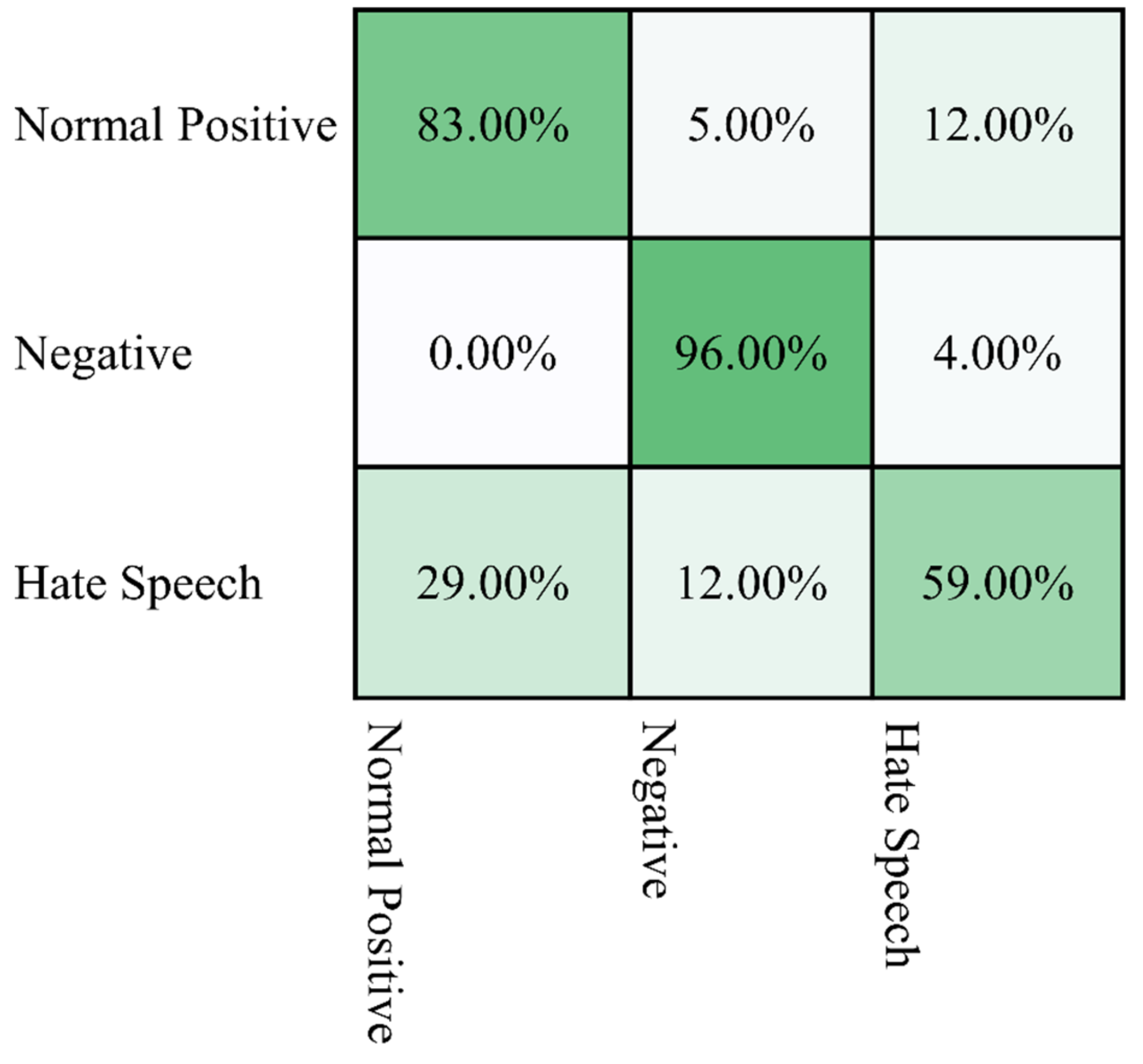
3.4. Evaluation Matrices
Several metrics were used to evaluate the effectiveness of the proposed model. The metrics used were typical metrics that allowed for a comparison with other techniques from the literature, including the confusion matrix, precision, recall, F1 score, and accuracy. The metrics are defined and described in
Table 3.
5. Conclusions
Many social media platforms prevent users from using hate speech, racism, cyberbullying, etc. In many countries, privacy laws prevent governments from monitoring the internet and positing the activities of individuals, even for national security reasons. However, there are many countries in which the government is allowed to monitor social media and other citizen activities for various reasons, including national security and the prevention of cyberbullying, hate speech, and racism. In this paper, a deep machine learning algorithm was proposed for the automatic classification and detection of Arabic hate speech. The availability of publicly published datasets is scarce, and those that are published do not contain the type of written comments that were targeted in this study. Therefore, one of the main contributions of this work was the development of a unique dataset that contained 4203 comments gathered from various social media platforms and labeled into one of the following seven classes: content against religion, racist content, content against gender equality, violent/offensive content, insulting/bullying content, normal positive comments, and normal negative comments.
The dataset was subjected to a thorough preprocessing phase and the comments were labeled in a scientific manner that ensured the accuracy of the labeling and classification. In this work, the use of deep recurrent neural networks (RNNs) for the automatic classification and detection of Arabic hate speech was proposed. The proposed model, which was called RDNN-2, consisted of 10 layers with 32 batch sizes and performed the classification in 50 iterations. Another model consisting of five layers, which was called RDNN-1, was used in the binary classification experiment only. Using the proposed models, a recognition rate of 99.73% was achieved for binary classification, 95.38% for the three classes of Arabic comments, and 84.14% for the seven classes of Arabic comments. This was a high accuracy for the classification of a complex language, such as Arabic, into seven different classes. The achieved accuracy was higher than any similar method reported in the recent literature, whether for binary classification, three-class classification, or seven-class classification.
Future work should include the continuous development of the dataset in order to increase its size and classes and develop a unified dataset for researchers in this field. In addition, future research should focus on the continuous development and modification of machine learning techniques to achieve better accuracies for the classification of hate speech in Arabic. In addition, the author of the current study will work to develop a prototype that can be applied within social media platforms for real-time testing and processing.



 means ‘keys wallet is amazing’).
means ‘keys wallet is amazing’).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}