
Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools

 ,
,  ,
,  ,
,  , and
, and
Abstract
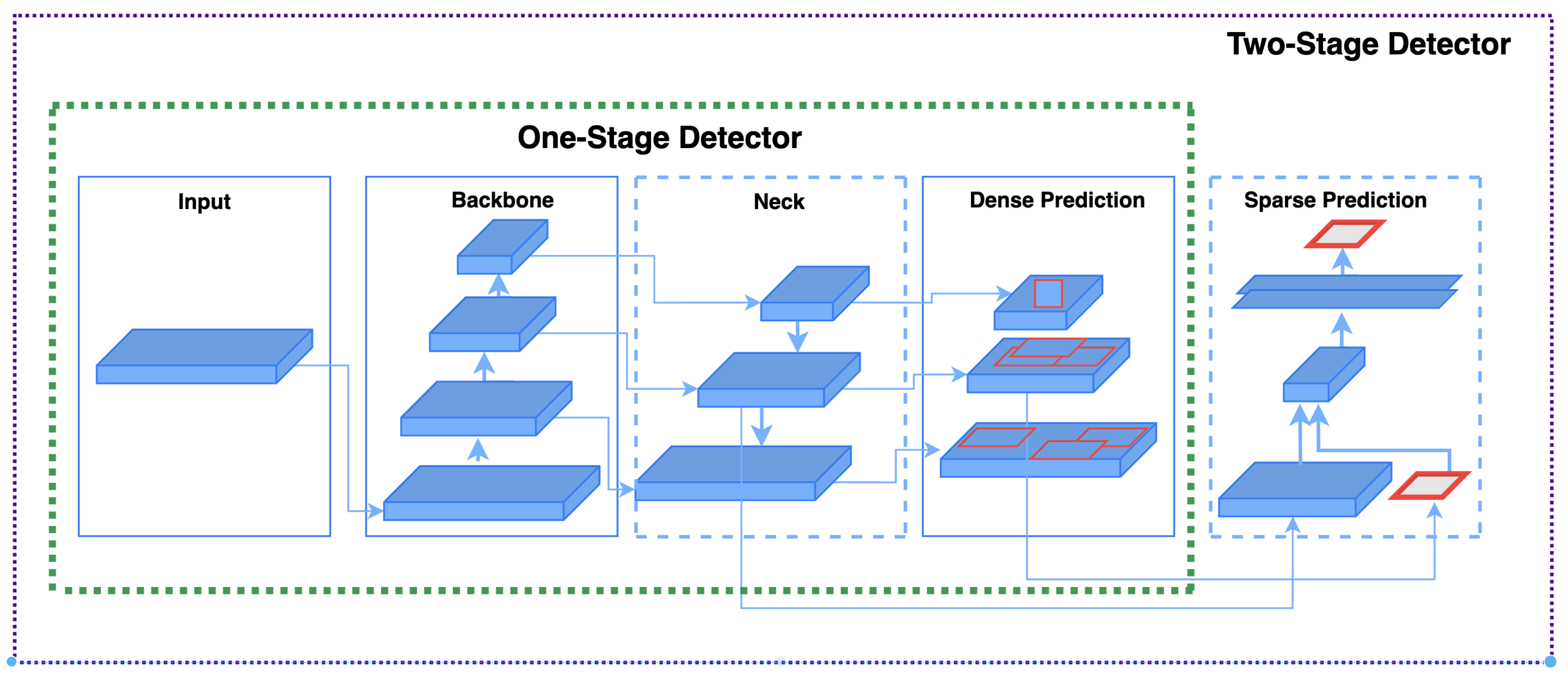
:1. Introduction
2. Materials and Methods
2.1. Data
2.2. Experimental Environment
2.3. Data Classification
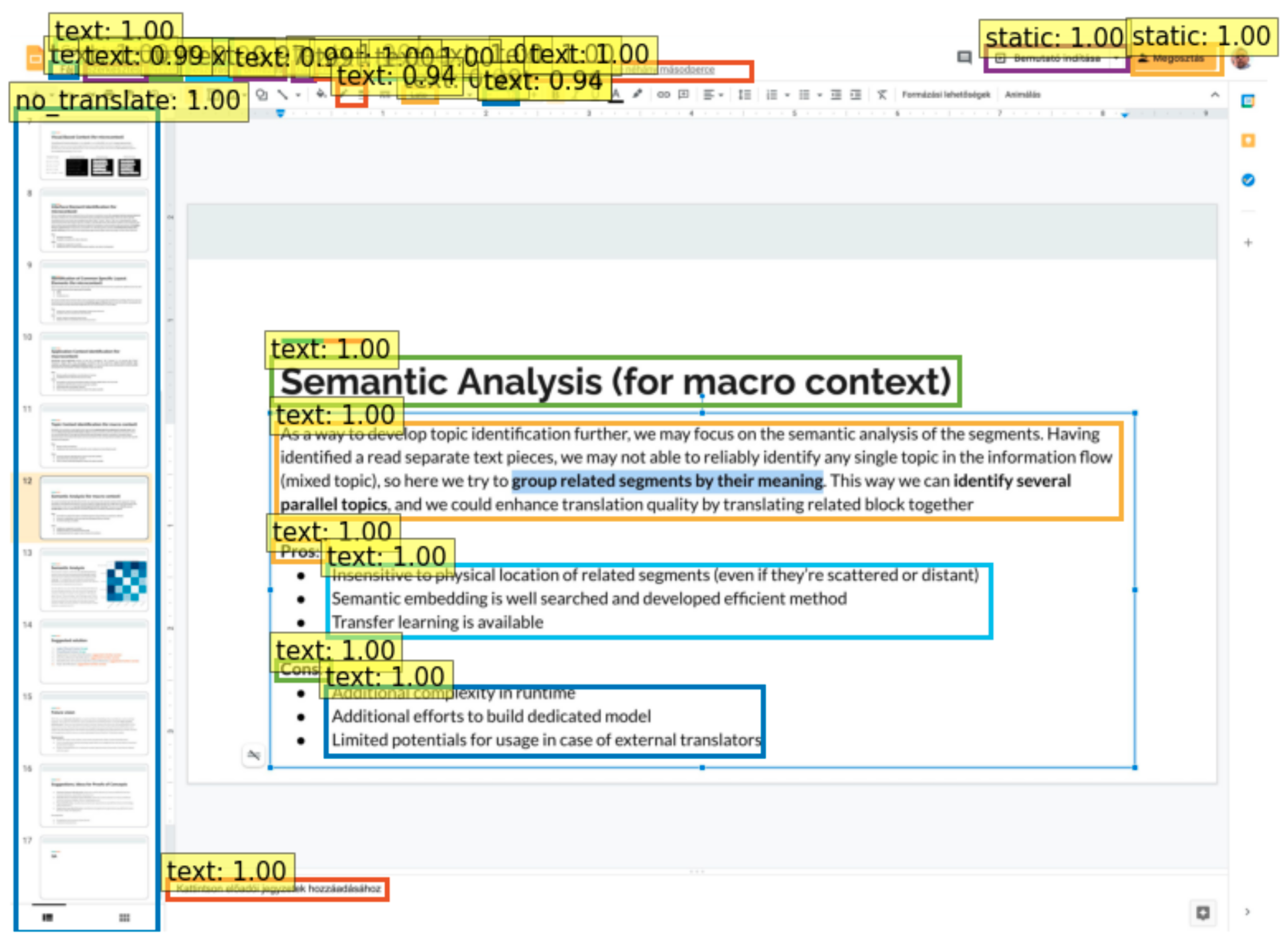
- Class 1 (TEXT) are the text blocks, and contains text only;
- Class 2 (STATIC) contains buttons or texts and need additional dictionaries for further processing;
- Class 3 (NO TRANSLATE) contains mixed elements unnecessary to process. They prevent sections from being recognized as any other category, providing data processing according to GDPR;
- Class 4 (CONTAINER) is defined as inter-dependency element. They are container objects to connect larger blocks of interdependent textual elements.
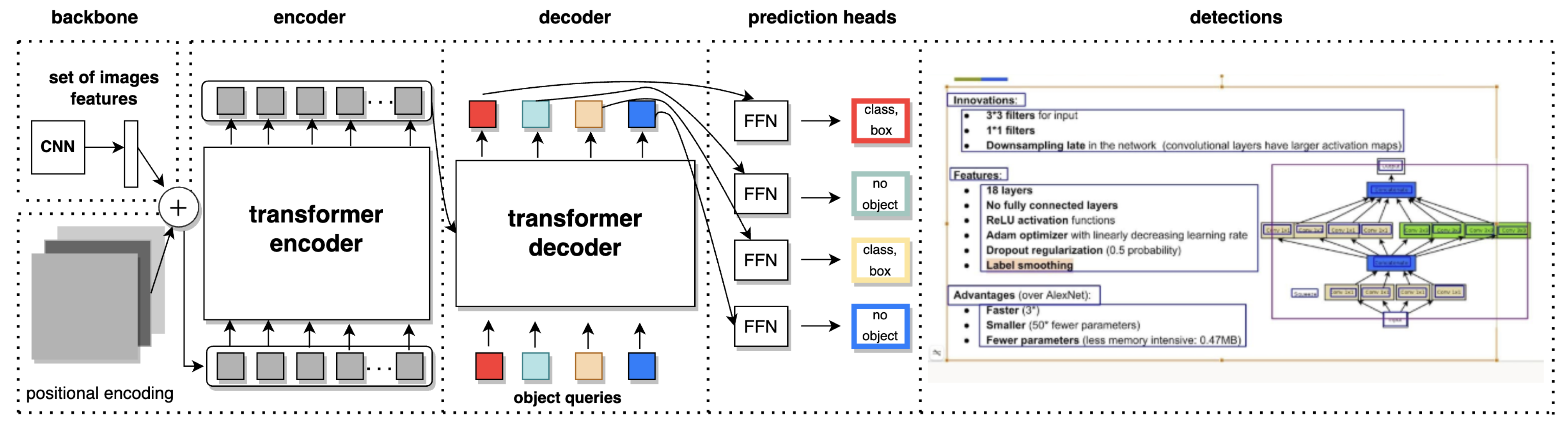
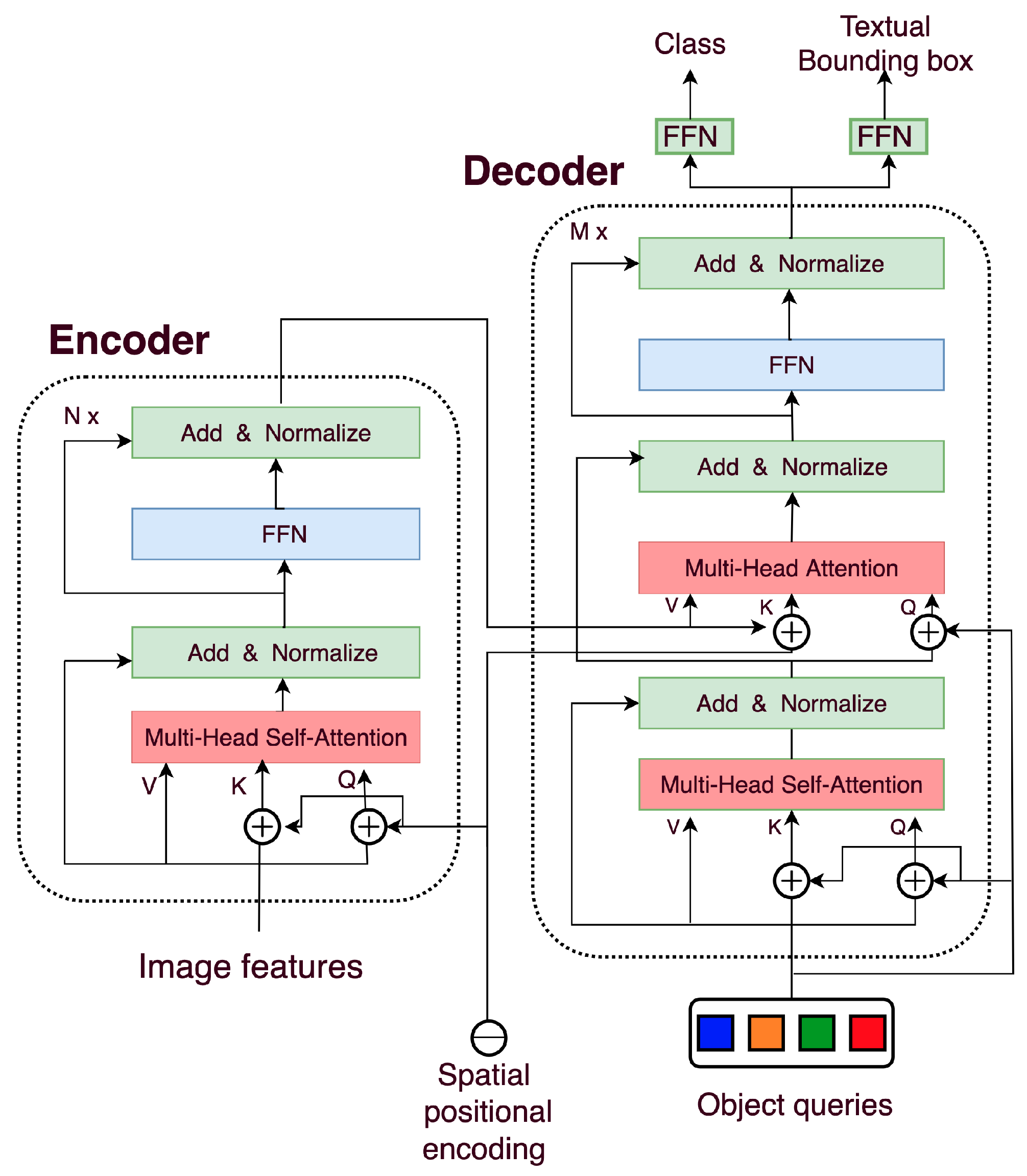
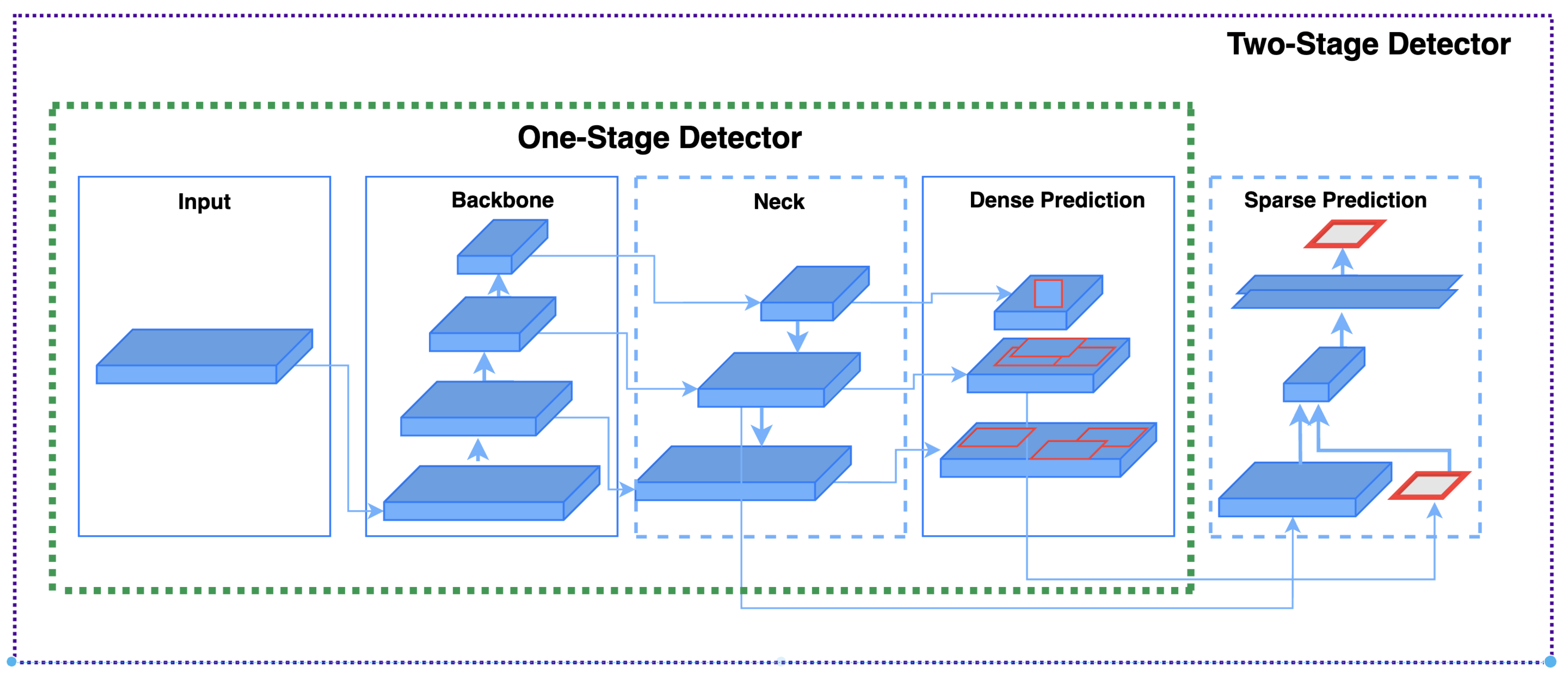
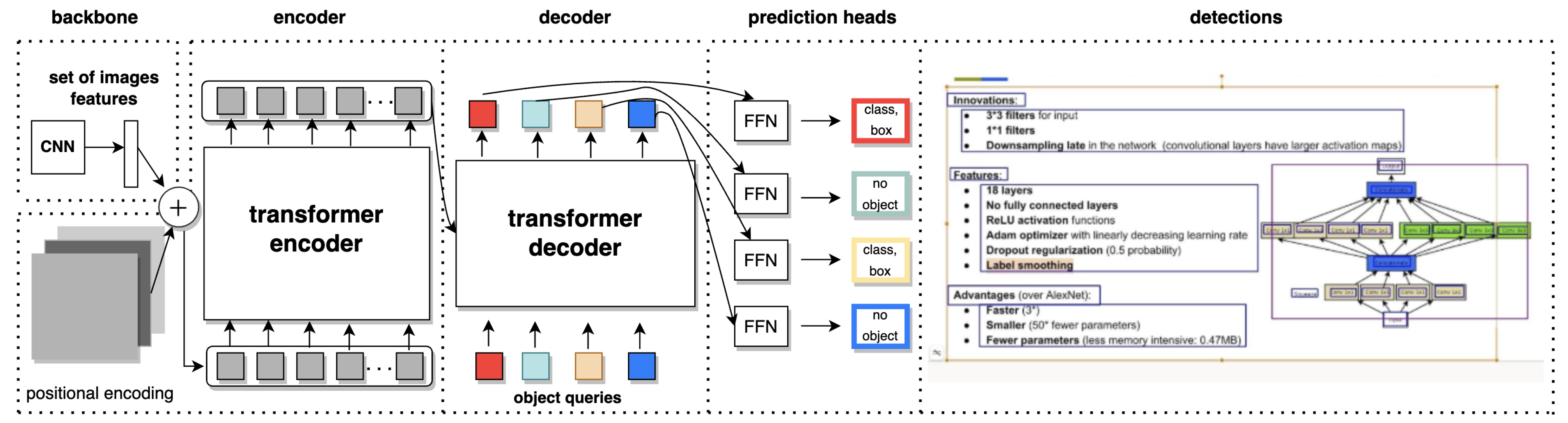
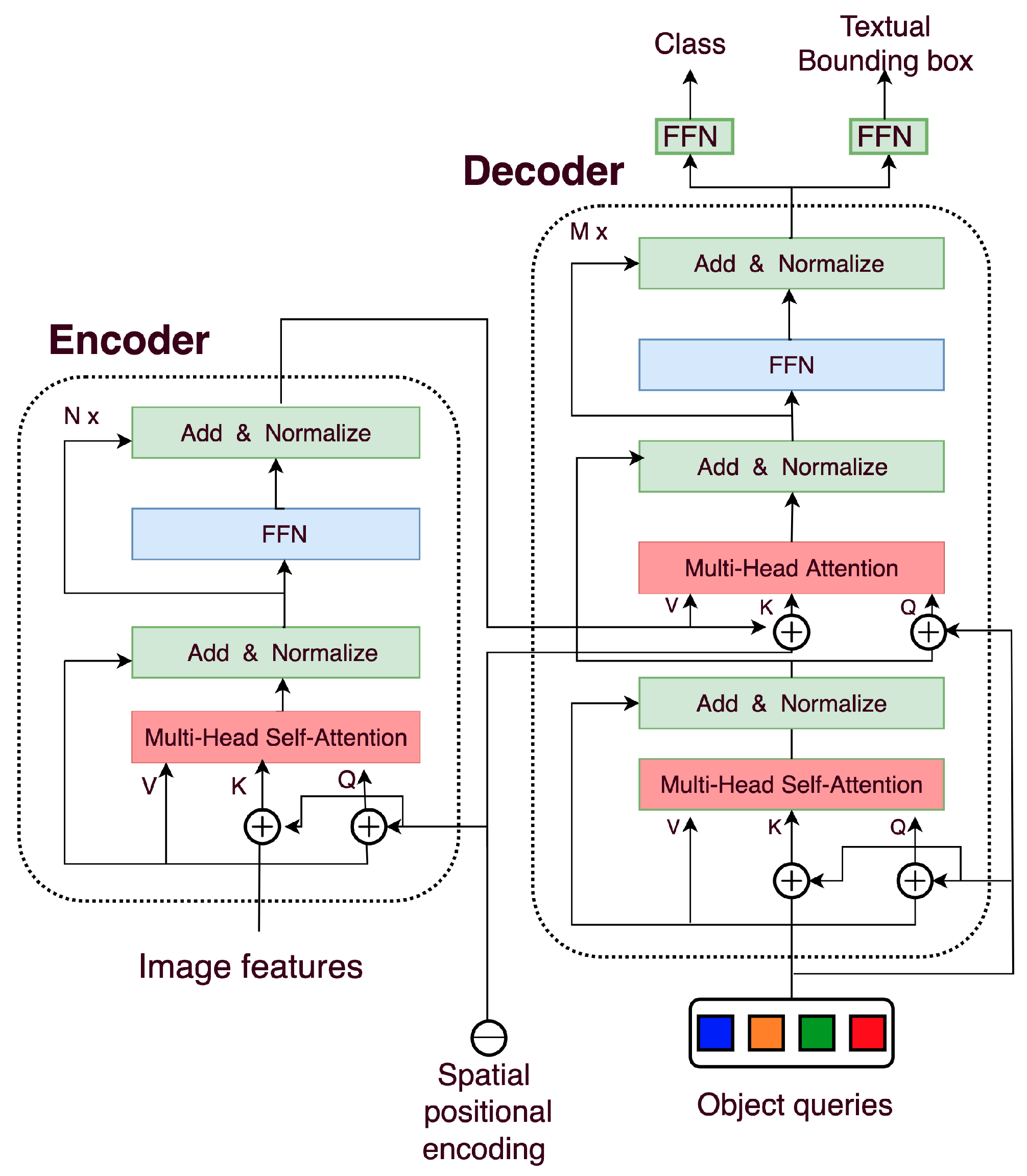
2.4. Architecture
2.5. Algorithm Logic
2.5.1. Advantages
2.5.2. Disadvantages of DETR from the Textual Object Detection Perspective
2.6. Pre-Processing
- Different number of epochs: 50, 150, and 1000.
- Different categorizations: all 4 predefined categories, or 2 categories: text + others (static, no translate, container categories merged to one category).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Iterations | mAP | Total Loss | |||
|---|---|---|---|---|---|---|
| faster_rcnn_R_50_C4_3x | 500 | 0.07034 | 0.07367 | 0.09235 | 0.06877 | 1.320 |
| faster_rcnn_R_50_DC5_3x | 1000 | 0.17659 | 0.23342 | 0.20921 | 0.17706 | 1.253 |
| faster_rcnn_R_50_FPN_3x | 700 | 0.30985 | 0.44342 | 0.36016 | 0.34255 | 1.154 |
| faster_rcnn_R_50_FPN_3x | 1000 | 0.30560 | 0.42302 | 0.34745 | 0.34160 | 1.183 |
| faster_rcnn_R_101_FPN_3x | 1000 | 0.29764 | 0.47187 | 0.43785 | 0.39341 | 1.129 |
| faster_rcnn_X_101_32x8_FPN_3x | 3000 | 0.42799 | 0.56096 | 0.56331 | 0.49369 | 0.458 |
| faster_rcnn_X_101_32x8_FPN_3x | 10,000 | 0.45223 | 0.57821 | 0.55734 | 0.48758 | 0.343 |
| retinanet_R_50_FPN_1x | 1000 | 0.31027 | 0.45998 | 0.47357 | 0.40872 | 0.495 |
| retinanet_R_50_FPN_3x | 1000 | 0.32150 | 0.46114 | 0.46953 | 0.41103 | 0.477 |
| retinanet_R_101_FPN_3x | 3000 | 0.36923 | 0.55230 | 0.55267 | 0.49589 | 0.250 |
| retinanet_R_101_FPN_3x | 10,000 | 0.37968 | 0.55938 | 0.57270 | 0.50513 | 0.189 |
| rpn_R_50_C4_1x | 1000 | 0.320 | ||||
| rpn_R_50_FPN_1x | 3000 | 0.180 | ||||
| Model | Total Loss | mAP | Workers | BATCH/IMG | IMS/BATCH | Iterations |
|---|---|---|---|---|---|---|
| faster_rcnn_R_50_C4_1x | 0.963 | 0.29753 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_DC5_1x | 0.967 | 0.31446 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_FPN_1x | 0.912 | 0.33348 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_C4_3x | 0.912 | 0.34338 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_DC5_3x | 0.886 | 0.34033 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_FPN_3x | 0.912 | 0.36219 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_50_FPN_3x | 0.707 | 0.39064 | 4 | 128 | 6 | 3000 |
| faster_rcnn_R_101_C4_3x | 0.857 | 0.32096 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_101_DC5_3x | 0.882 | 0.30924 | 4 | 128 | 6 | 1000 |
| faster_rcnn_R_101_FPN_3x | 0.869 | 0.32056 | 4 | 128 | 6 | 1000 |
| faster_rcnn_X_101_32x8_FPN_3x | 0.998 | 0.30455 | 2 | 64 | 3 | 1000 |
| retinanet_R_50_FPN_1x | 0.661 | 0.24791 | 4 | 128 | 6 | 1000 |
| retinanet_R_50_FPN_3x | 0.568 | 0.25690 | 4 | 128 | 6 | 1000 |
| retinanet_R_101_FPN_3x | 0.564 | 0.28165 | 4 | 128 | 6 | 1000 |
| rpn_R_50_C4_1x | 0.350 | 0.24046 | 4 | 128 | 6 | 1000 |
| rpn_R_50_FPN_1x | 0.376 | 0.35200 | 4 | 128 | 6 | 1000 |
| YOLO4 TINY 640 (16) | YOLO4 TINY 416 (32) | YOLO4 TINY 800 (16) | ||||||||||
| Epochs | mAP | mAP | mAP | |||||||||
| 10 | 0.029 | 0.040 | 0.130 | 0.066 | 0.145 | 0.199 | 0.398 | 0.247 | ||||
| 20 | 0.164 | 0.153 | 0.352 | 0.223 | 0.051 | 0.039 | 0.117 | 0.069 | 0.172 | 0.141 | 0.312 | 0.208 |
| 30 | 0.158 | 0.136 | 0.352 | 0.215 | 0.069 | 0.047 | 0.131 | 0.082 | 0.280 | 0.344 | 0.291 | 0.305 |
| 40 | 0.272 | 0.150 | 0.343 | 0.255 | 0.064 | 0.051 | 0.127 | 0.081 | 0.281 | 0.265 | 0.392 | 0.312 |
| 50 | 0.255 | 0.156 | 0.372 | 0.261 | 0.070 | 0.063 | 0.118 | 0.084 | 0.257 | 0.332 | 0.445 | 0.345 |
| 60 | 0.270 | 0.179 | 0.337 | 0.262 | 0.068 | 0.065 | 0.113 | 0.084 | 0.269 | 0.222 | 0.472 | 0.321 |
| 70 | 0.308 | 0.129 | 0.339 | 0.259 | 0.078 | 0.058 | 0.131 | 0.089 | 0.290 | 0.400 | 0.484 | 0.392 |
| 80 | 0.296 | 0.105 | 0.356 | 0.252 | 0.087 | 0.062 | 0.130 | 0.093 | 0.326 | 0.359 | 0.485 | 0.390 |
| 90 | 0.343 | 0.231 | 0.364 | 0.313 | 0.080 | 0.059 | 0.138 | 0.092 | 0.347 | 0.405 | 0.485 | 0.412 |
| 100 | 0.350 | 0.152 | 0.418 | 0.307 | 0.087 | 0.069 | 0.133 | 0.096 | 0.339 | 0.379 | 0.481 | 0.400 |
| 110 | 0.326 | 0.180 | 0.408 | 0.305 | 0.090 | 0.069 | 0.137 | 0.099 | 0.335 | 0.395 | 0.486 | 0.405 |
| 120 | 0.326 | 0.236 | 0.393 | 0.348 | 0.092 | 0.072 | 0.137 | 0.100 | 0.355 | 0.399 | 0.479 | 0.411 |
| 130 | 0.300 | 0.175 | 0.410 | 0.295 | 0.343 | 0.411 | 0.486 | 0.413 | ||||
| 140 | nan | nan | nan | nan | 0.340 | 0.411 | 0.483 | 0.411 | ||||
| 150 | 0.345 | 0.409 | 0.483 | 0.412 | ||||||||
| YOLO4 LARGE 480 (16) | YOLO4 TINY 416 (16) | YOLO4 TINY 800 (16, 0.005) | ||||||||||
| Epochs | mAP | mAP | mAP | |||||||||
| 10 | 0.140 | 0.023 | 0.190 | 0.118 | 0.035 | 0.008 | 0.104 | 0.049 | 0.315 | 0.337 | 0.451 | 0.368 |
| 20 | 0.206 | 0.061 | 0.263 | 0.177 | 0.049 | 0.026 | 0.093 | 0.056 | 0.373 | 0.271 | 0.432 | 0.359 |
| 30 | 0.214 | 0.024 | 0.266 | 0.168 | 0.043 | 0.030 | 0.109 | 0.061 | 0.440 | 0.247 | 0.372 | 0.353 |
| 40 | 0.247 | 0.041 | 0.288 | 0.192 | 0.064 | 0.015 | 0.102 | 0.060 | nan | nan | nan | nan |
| 50 | 0.228 | 0.024 | 0.300 | 0.184 | 0.062 | 0.031 | 0.111 | 0.068 | ||||
| 60 | 0.268 | 0.057 | 0.371 | 0.232 | 0.049 | 0.028 | 0.118 | 0.065 | ||||
| 70 | 0.252 | 0.042 | 0.344 | 0.213 | 0.061 | 0.031 | 0.105 | 0.065 | ||||
| 80 | 0.272 | 0.057 | 0.323 | 0.217 | 0.076 | 0.027 | 0.120 | 0.074 | ||||
| 90 | 0.258 | 0.012 | 0.283 | 0.184 | 0.079 | 0.018 | 0.142 | 0.080 | ||||
| 100 | 0.281 | 0.040 | 0.316 | 0.212 | 0.084 | 0.029 | 0.110 | 0.074 | ||||
| 110 | 0.235 | 0.011 | 0.298 | 0.181 | 0.078 | 0.034 | 0.132 | 0.081 | ||||
| 120 | 0.262 | 0.034 | 0.299 | 0.198 | 0.080 | 0.027 | 0.140 | 0.082 | ||||
| 130 | 0.087 | 0.023 | 0.130 | 0.080 | ||||||||
| 140 | 0.086 | 0.022 | 0.135 | 0.081 | ||||||||
| 150 | 0.087 | 0.024 | 0.133 | 0.081 | ||||||||
2.7. Decision Making
- New Class 1, which corresponds to the previous Class 1 and requires translation,
- New Class 2, which corresponds to the union of previous Classes 2, 3, and 4, and requires no translation.
3. Data Analysis
3.1. Alternative No. 1: YOLO4 Model and Analysis
3.2. Alternative No. 2: Detectron2 Model and Analysis
4. Results
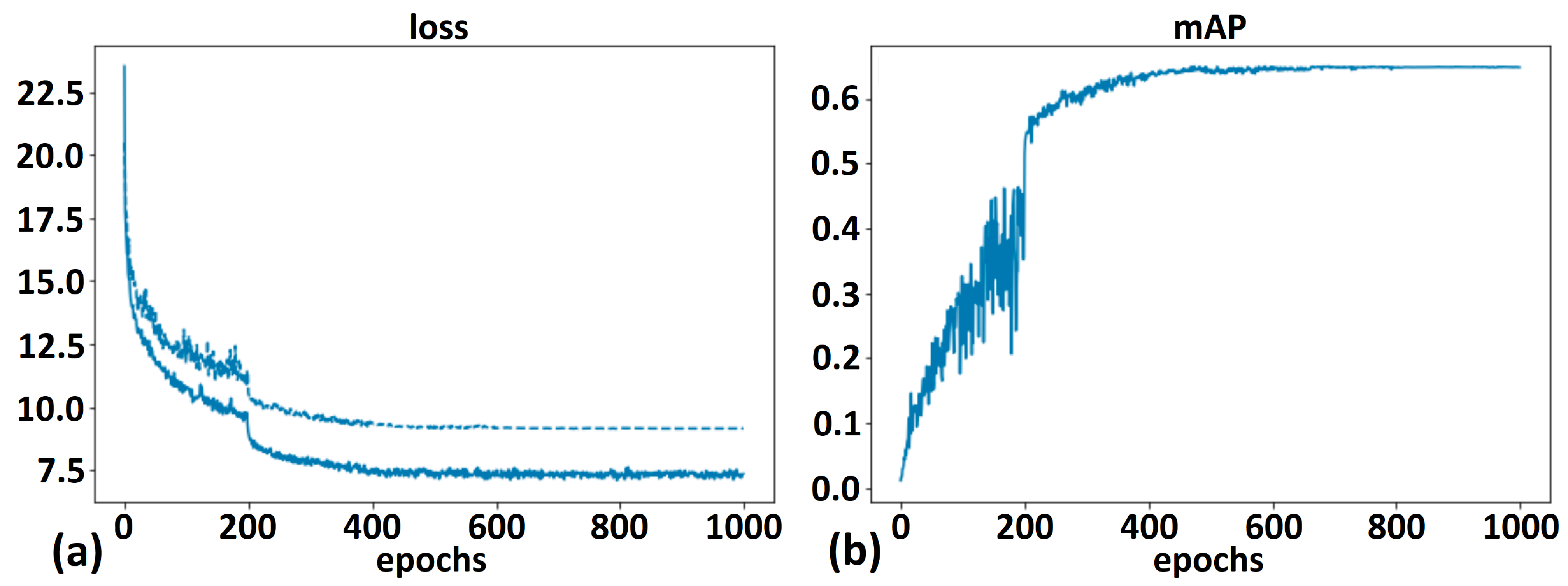
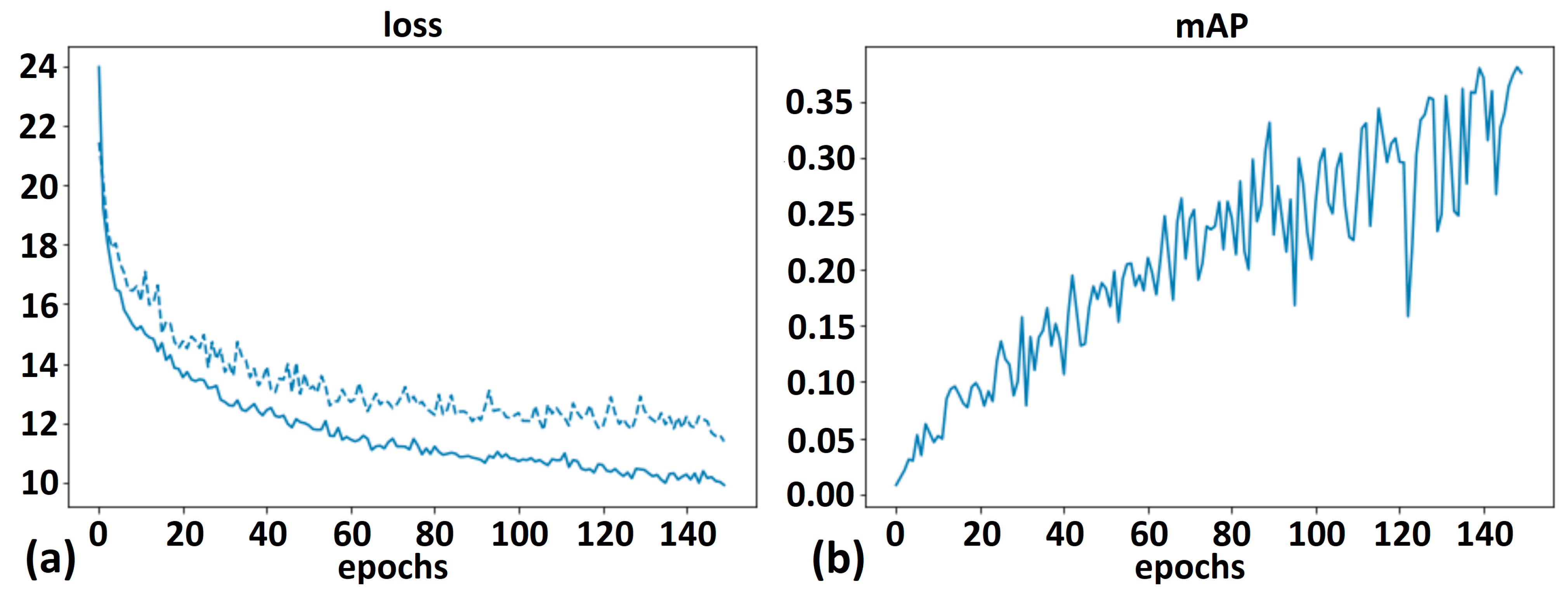
4.1. DETR Models
4.2. Alternative No. 1: YOLO4 Models
- The performance does not strictly correlate with training time (epochs).
- The performance almost always plateaued before terminating the learning process.
- Accuracy does not always correlate with the overall mAP and class-specific AP values.
- In comparison with other experiment groups such as Detectron2 or DETR, YOLO requires more training time (around 3–6 min per epoch), which makes the hyperparameter tuning process very slow.
- A very long training–over 150 epochs–becomes uncertain due to the vanishing gradient phenomenon. At this moment, the training is interrupted irrespective of the original expected length of the experiment. ‘YOLO large’ and ‘YOLO tiny’ have the same performance, ‘YOLO tiny’ actually tends to give better results. We realized that there is no reason to choose YOLO large for further experiments. Larger input image size provided better results than expected (up to the examined , at least).
- With batch size up to 8 the relevant models were unable to learn, so we had to set the batch size to 16 as the minimum value, while 32 was the maximum value we employed due to GPU memory constraints (see Section 2.2).
4.3. Alternative No. 2: Detectron2 Models
4.4. Detectron Phase 2 Research
5. Discussion
- YOLO4 Tiny: input size, 120 epochs, SGD optimizer, learning rate 0.01, batch size 16;
- Detectron2 RetinaNet R 101 FPN 3x: 10,000 epochs, learning rate 0.01, 6 images per batch, 128 batch per images, 150 warm-ups;
- DETR RESNET50: variable input size, 500 epochs, learning rate 0.0001, batch size 2, LR decay every 200 epochs.
5.1. DETR Insights on Textual Object Detection
- About 6 GB of VRAM is required (at least) for efficient training;
- The model could not be over-fitted during the experiments, and this is promising;
- At approximately 500 epochs, all experiments reached their peak performance;
- The global loss values are a combination of bounding box detection accuracy and categorization accuracy;
- Moderate training time (9.5 h/1000 epochs with the available training data);
- The number of categories affects the model’s final performance—object detection with clustering [42] was a line of research connected to our scope.
5.2. AI for OCR and Multilingual Translations for Video Conference Consultancies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Adam | an alternative optimization algorithm |
| AI | artificial intelligence |
| AP | average precision |
| Bi-FPN | weighted bi-directional feature pyramid network |
| CenterNet | machine learning model for Anchorless Object Detection |
| CNN | convolutional neural network |
| COCO | common objects in context |
| CornerNet | new approach to object detection |
| COVID-19 | coronavirus disease |
| CPU | central processing unit |
| Darknet53 | is a convolutional neural network architecture |
| DDR | Document Domain Randomization |
| DETR | Detection Transformer |
| DenseNet | a type of convolutional neural network architecture |
| EfficientNet | a convolutional neural network architecture |
| FCOS | fully convolutional one-stage object detection |
| FPN | feature pyramid network |
| GB | gigabyte |
| GDPR | General Data Protection Regulation |
| IT | information technology |
| JSON | JavaScript object notation |
| mAP | mean average precision |
| MatrixNet | a proprietary machine learning algorithm |
| MobileNet | a convolutional neural network architecture |
| Nadam | Nesterov-accelerated Adaptive Moment Estimation |
| NN | neural network |
| OCR | optical character recognition |
| PANet | Path Aggregation Network |
| Resnet50 | a convolutional neural network architecture |
| ResNeXt-101 | a model introduced in the Aggregated Residual Transformations |
| RetinaNet | is a one-stage object detection model |
| ROI | Region of Interest |
| RPN | Region Proposal Network |
| R-CNN | region-based convolutional neural network |
| R-FCN | region-based fully convolutional network |
| SGD | stochastic gradient descent |
| SSD | Single Shot Multi-Box Detector |
| ShuffleNet | an extremely efficient CNN |
| SpineNet | learning scale-permuted backbone |
| SqueezeNet | a convolutional neural network |
| TVOD | textual visual object detection |
| VC | video consultation |
| VGA | Video Graphics Array |
| VGG | Visual Geometry Group |
| VGG16 | a convolutional neural network |
| VOD | visual object detection |
| VOTT | Visual Object Tagging Tool |
| VRAM | video RAM, video random access memory |
| YOLO | You Only Look Once |
References
- Ozili, P.K.; Arun, T. Spillover of COVID-19: Impact on the Global Economy. SSRN 2020. [Google Scholar] [CrossRef]
- Pogue, M.; Raker, E.; Hampton, K.; Saint Laurent, M.; Mishori, R. Conducting remote medical asylum evaluations in the United States during COVID-19: Clinicians’ perspectives on acceptability, challenges and opportunities. J. Forensic Leg. Med. 2021, 84, 102255. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, D.; Yin, F.; Zhang, Y. Salient object detection based on global to local visual search guidance. Signal Process. Image Commun. 2022, 102, 116618. [Google Scholar] [CrossRef]
- Krause, M.; Brado, M.; Schosser, R.; Bartsch, F.-R.; Gerneth, M.; Kauffmann, G. Diagnostic accuracy in remote expert consultation using standard video-conference technology. Eur. Radiol. 1996, 6, 932–938. [Google Scholar] [CrossRef]
- Mori, S.; Suen, C.Y.; Yamamoto, K. Historical review of OCR research and development. Proc. IEEE 1992, 80, 1029–1058. [Google Scholar] [CrossRef]
- Smith, R.; Antonova, D.; Lee, D.-S. Adapting the Tesseract open source OCR engine for multilingual OCR. In Proceedings of the International Workshop on Multilingual OCR, Barcelona, Spain, 25 July 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Gu, J.T.; Neubig, G.; Cho, K.H.; Li, V.O.K. Learning to translate in real-time with neural machine translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 1053–1062. [Google Scholar]
- Das, H.S.; Roy, P. A CNN-BiLSTM based hybrid model for Indian language identification. Appl. Acoustics 2021, 182, 108274. [Google Scholar] [CrossRef]
- Ding, L.A.; Wu, D.; Tao, D.C. Improving neural machine translation by bidirectional training. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3278–3284. [Google Scholar] [CrossRef]
- Qi, J.W.; Peng, Y.X. Cross-modal bidirectional translation via reinforcement learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 2630–2636. [Google Scholar] [CrossRef]
- Shin, J.H.; Georgiou, P.G.; Narayanan, S. Towards modeling user behavior in interactions mediated through an automated bidirectional speech translation system. Comput. Speech Lang. 2010, 24, 232–256. [Google Scholar] [CrossRef]
- Ataman, D.; Firat, O.; Di Gangi, M.A.; Federico, F.; Birch, A. On the importance of word boundaries in character-level neural machine translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, 4 November 2019; pp. 187–193. [Google Scholar] [CrossRef]
- Bulut, S.Ö. Integrating machine translation into translator training: Towards ‘Human Translator Competence’? Translogos Transl. Stud. J. 2019, 2, 1–26. [Google Scholar] [CrossRef]
- Bizzoni, Y.; Juzek, T.S.; España-Bonet, C.; Chowdhury, K.D.; van Genabith, J.; Teich, E. How human is machine translationese? Comparing human and machine translations of text and speech. In Proceedings of the 17th International Conference on Spoken Language Translation, Online, 9–10 July 2020; pp. 280–290. [Google Scholar] [CrossRef]
- Briones, J. Object Detection with Transformers. Available online: https://medium.com/swlh/object-detection-with-transformers-437217a3d62e (accessed on 28 April 2022).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Wang, J.F.; Song, L.; Li, Z.M.; Sun, H.B.; Sun, J.; Zheng, N.N. End-to-end object detection with fully convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15844–15853. [Google Scholar] [CrossRef]
- Wieniawska, H.W. What Exactly is Happening Inside the Transformer. Available online: https://medium.com/swlh/what-exactly-is-happening-inside-the-transformer-b7f713d7aded (accessed on 28 April 2022).
- Du, J. Understanding of object detection based on CNN family and YOLO. J. Phys. Conf. Ser. 2018, 1004, 012029. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- TensorFlow 2 YOLOv4. Available online: https://bit.ly/3kgtaff (accessed on 28 April 2022).
- DETR: End-to-End Object Detection with Transformers. 2020. Available online: https://github.com/facebookresearch/detr (accessed on 28 April 2022).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- He, Y.H.; Zhu, C.C.; Wang, J.R.; Savvides, M.; Zhang, X.Y. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 2888–2897. [Google Scholar] [CrossRef]
- Li, Z.M.; Peng, C.; Yu, G.; Zhang, X.Y.; Deng, Y.D.; Sun, J. DetNet: Design backbone for object detection. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11213, pp. 339–354. [Google Scholar] [CrossRef]
- Shao, S.; Li, Z.M.; Zhang, T.Y.; Peng, C.; Yu, G.; Zhang, X.Y.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8430–8439. [Google Scholar] [CrossRef]
- Zhang, H.K.; Chang, H.; Ma, B.P.; Wang, N.Y.; Chen, X.L. Dynamic R-CNN: Towards high quality object detection via dynamic training. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12360, pp. 260–275. [Google Scholar] [CrossRef]
- Tarimoradi, H.; Karami, H.; Gharehpetian, G.B.; Tenbohlen, S. Sensitivity analysis of different components of transfer function for detection and classification of type, location and extent of transformer faults. Measurement 2022, 187, 110292. [Google Scholar] [CrossRef]
- GitHub—George Kalitsios: Face Detection Using DETR End-to-End Object Detection with Transformers. 2021. Available online: https://github.com/george-kalitsios/Face-Detection-using-DETR-End-to-End-Object-Detection-with-Transformers (accessed on 28 April 2022).
- Ma, T.L.; Mao, M.Y.; Zheng, H.H.; Gao, P.; Wang, X.D.; Han, S.M.; Ding, E.R.; Zhang, B.C.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146v1. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- VoTT—Visual Object Tagging Tool 2020. Available online: https://github.com/microsoft/VoTT (accessed on 28 April 2022).
- LabelImg. 2018. Available online: https://github.com/tzutalin/labelImg (accessed on 28 April 2022).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Nath, U.; Kushagra, S. Better Together: Resnet-50 accuracy with 13× fewer parameters and at 3× speed. arXiv 2020, arXiv:2006.05624v3. [Google Scholar]
- Gao, P.; Zheng, M.; Wang, X.; Dai, J.; Li, H. Fast convergence of DETR with spatially modulated co-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3621–3630. [Google Scholar] [CrossRef]
- Tan, R.J. Breaking Down Mean Average Precision (mAP)—Another Metric for Your Data Science Toolkit. 2019. Available online: https://towardsdatascience.com/breaking-down-mean-average-precision-map-ae462f623a52#1a59 (accessed on 28 April 2022).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Honda, H. Digging into Detectron 2—Part 1. Available online: https://medium.com/@hirotoschwert/digging-into-detectron-2-47b2e794fabd (accessed on 28 April 2022).
- FAIR’s Research Platform for Object Detection Research, Implementing Popular Algorithms Like MASK R-CNN and RetinaNet. Available online: https://github.com/facebookresearch/Detectron (accessed on 28 April 2022).
- Zheng, M.H.; Gao, P.; Zhang, R.R.; Li, K.C.; Wang, X.G.; Li, H.S.; Dong, H. End-to-end object detection with adaptive clustering transformer. In Proceedings of the 32nd British Machine Vision Conference, Online, 22–25 November 2021; pp. 1–13. [Google Scholar]
- Dai, Z.G.; Cai, B.L.; Lin, Y.G.; Chen, J.Y. UP-DETR: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biró, A.; Jánosi-Rancz, K.T.; Szilágyi, L.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, S.M. Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools. Appl. Sci. 2022, 12, 5977. https://doi.org/10.3390/app12125977
Biró A, Jánosi-Rancz KT, Szilágyi L, Cuesta-Vargas AI, Martín-Martín J, Szilágyi SM. Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools. Applied Sciences. 2022; 12(12):5977. https://doi.org/10.3390/app12125977
Chicago/Turabian StyleBiró, Attila, Katalin Tünde Jánosi-Rancz, László Szilágyi, Antonio Ignacio Cuesta-Vargas, Jaime Martín-Martín, and Sándor Miklós Szilágyi. 2022. "Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools" Applied Sciences 12, no. 12: 5977. https://doi.org/10.3390/app12125977
APA StyleBiró, A., Jánosi-Rancz, K. T., Szilágyi, L., Cuesta-Vargas, A. I., Martín-Martín, J., & Szilágyi, S. M. (2022). Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools. Applied Sciences, 12(12), 5977. https://doi.org/10.3390/app12125977