
An Automatic Partition Time-Varying Markov Model for Reliability Evaluation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Tsallis Entropy
2.2. The Automatic Partition Time-Varying Markov Model for Reliability Evaluation
2.2.1. The Automatic Partition Method for State Number Determination of the Markov Model
- (1)
- Initialization
- (2)
- Loop calculation.
- (i)
- Calculate the cluster prototype .
- (ii)
- Cluster merging
2.2.2. The Time-Varying Markov Model
3. Results
3.1. Experiment Description
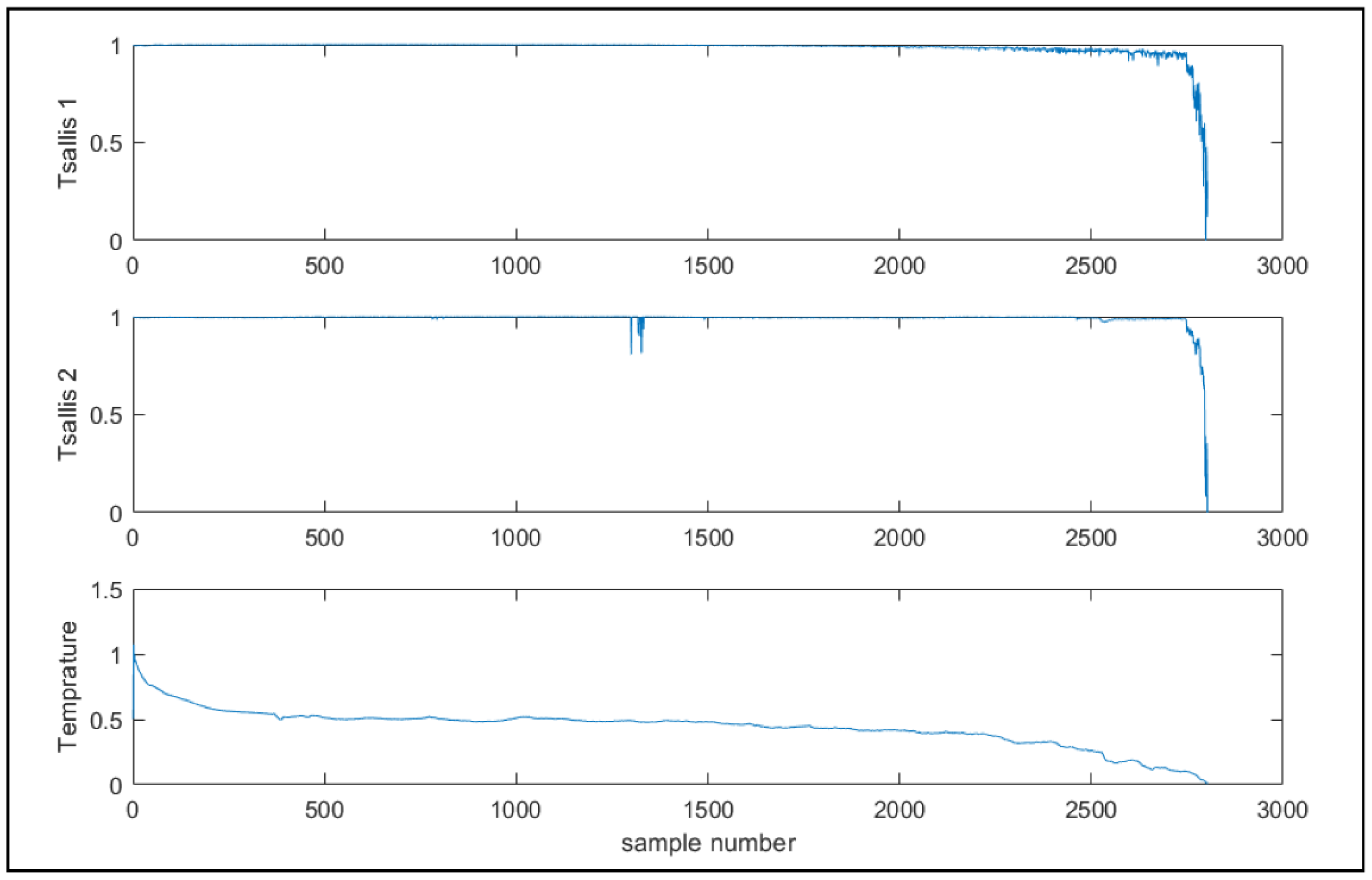
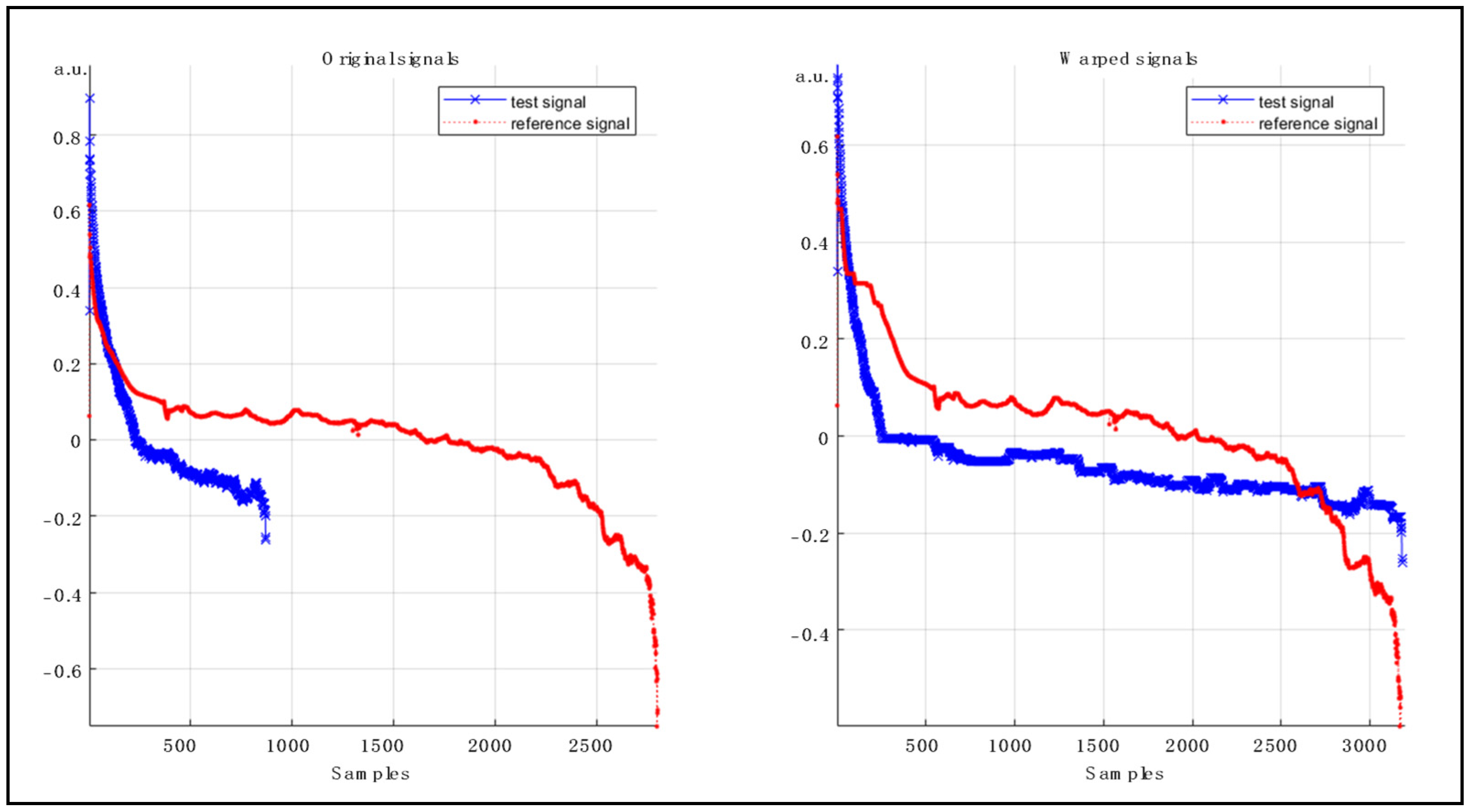
3.2. Feature Extraction
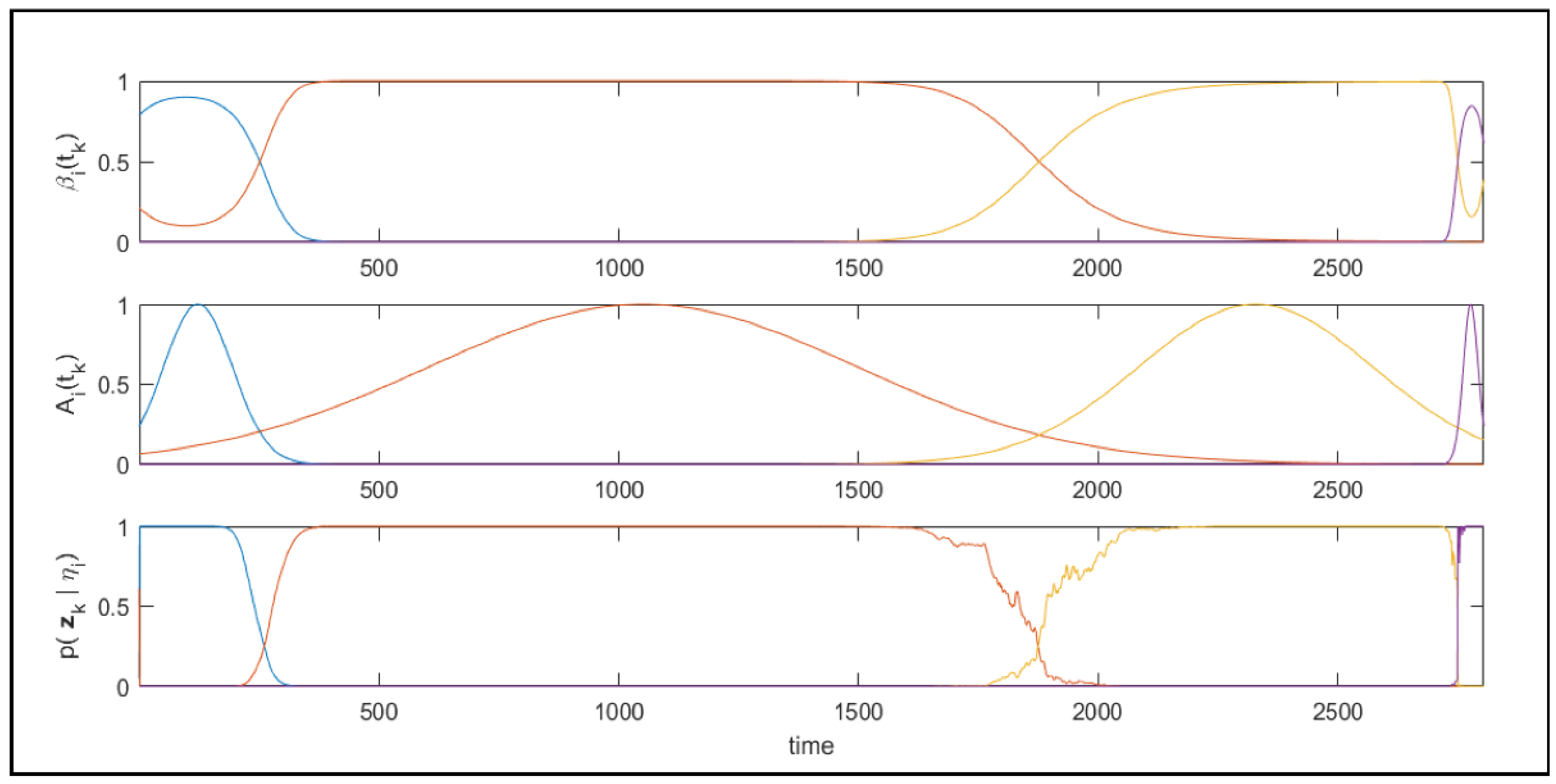
3.3. The Automatic State Number Determination of the Markov Model
3.4. Reliability Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arena, S.; Roda, I.; Chiacchio, F. Integrating Modelling of Maintenance Policies within a Stochastic Hybrid Automaton Framework of Dynamic Reliability. Appl. Sci. 2021, 11, 2300. [Google Scholar] [CrossRef]
- Bucci, P.; Kirschenbaum, J.; Mangan, L.A.; Aldemir, T.; Smith, C.; Wood, T. Construction of event-tree/fault-tree models from a Markov approach to dynamic system reliability. Reliab. Eng. Syst. Saf. 2008, 93, 1616–1627. [Google Scholar] [CrossRef]
- Wang, L.; Dai, W.; Luo, G.; Zhao, Y. A Novel Approach to Support Failure Mode, Effects, and Criticality Analysis Based on Complex Networks. Entropy 2019, 21, 1230. [Google Scholar] [CrossRef] [Green Version]
- Zaman, S.U.; Tao, X.; Cochrane, C.; Koncar, V. E-Textile Systems Reliability Assessment—A Miniaturized Accelerometer Used to Investigate Damage during Their Washing. Sensors 2021, 21, 605. [Google Scholar] [CrossRef] [PubMed]
- Gertsbakh, I.B. Models of Failure; Springer: Berlin/Heidelberg, Germany, 1969. [Google Scholar]
- Lvarez, M.; Ibáez, J.; Mingo, C. Reliability Assessment of Repairable Systems Using Simple Regression Models. Int. J. Math. Eng. Manag. Sci. 2020, 6, 180–192. [Google Scholar] [CrossRef]
- Nejad, R.M.; Liu, Z.; Ma, W.; Berto, F. Reliability analysis of fatigue crack growth for rail steel under variable amplitude service loading conditions and wear. Int. J. Fatigue 2021, 152, 106450. [Google Scholar] [CrossRef]
- Lehmann, A. Joint modeling of degradation and failure time data. J. Stat. Plan. Inference 2009, 139, 1693–1706. [Google Scholar] [CrossRef]
- Gao, H.; Cui, L.; Dong, Q. Reliability modeling for a two-phase degradation system with a change point based on a Wiener process. Reliab. Eng. Syst. Saf. 2020, 193, 106601. [Google Scholar] [CrossRef]
- Tamura, Y.; Yamada, S. Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data. Entropy 2015, 17, 4533–4546. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.P.; Ling, M.H.; Cabrera, J.; Yang, F.; Yu, D.; Tsui, K.L. Prognostics for lithium-ion batteries using a two-phase gamma degradation process model. Reliab. Eng. Syst. Saf. 2021, 214, 107797. [Google Scholar] [CrossRef]
- Cai, C.H.; Lu, Z.H.; Leng, Y.; Zhao, Y.G.; Li, C.Q. Time-Dependent Structural Reliability Assessment for Nonstationary Non-Gaussian Performance Functions. J. Eng. Mech. 2021, 147, 04020145. [Google Scholar] [CrossRef]
- Meango, J.M.; Ouali, M.S. Failure interaction model based on extreme shock and Markov processes. Reliab. Eng. Syst. Saf. 2020, 197, 106827. [Google Scholar] [CrossRef]
- Yeh, W.C. A quick BAT for evaluating the reliability of binary-state networks. Reliab. Eng. Syst. Saf. 2021, 216, 107917. [Google Scholar] [CrossRef]
- Rushdi, A.; Ghaleb, F. Reliability Characterization of Binary-Imaged Multi-State Coherent Threshold Systems. Int. J. Math. Eng. Manag. Sci. 2021, 6, 309–321. [Google Scholar] [CrossRef]
- Yeh, W.C. Computation of the Activity-on-Node Binary-State Reliability with Uncertainty Components. arXiv 2021, arXiv:2108.00405. [Google Scholar]
- Ding, Y.; Hu, Y.; Lin, Y.; Zeng, Z. Reliability Analysis of Multiperformance Multistate System Considering Performance Conversion Process. IEEE Trans. Reliab. 2022, 71, 2–15. [Google Scholar] [CrossRef]
- Jiang, S.; Li, Y.F. Dynamic Reliability Assessment of Multi-cracked Structure under Fatigue Loading via Multi-State Physics Model. Reliab. Eng. Syst. Saf. 2021, 213, 107664. [Google Scholar] [CrossRef]
- Kuppusamy, S.; Joo, Y.H.; Han, S.K. Asynchronous Control for Discrete-Time Hidden Markov Jump Power Systems. IEEE Trans. Cybern. 2021, 1–6. [Google Scholar] [CrossRef]
- Chávez-Fuentes, J.; Costa, E.F.; Terra, M.H.; Rocha, K. The linear quadratic optimal control problem for discrete-time Markov jump linear singular systems. Automatica 2021, 127, 109506. [Google Scholar] [CrossRef]
- Compare, M.; Baraldi, P.; Bani, I.; Zio, E.; Mcdonnell, D. Industrial equipment reliability estimation: A Bayesian Weibull regression model with covariate selection. Reliab. Eng. Syst. Saf. 2020, 200, 106891. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, S.; Fang, Z.; Dong, W. Modeling ageing effects for multi-state systems with multiple components subject to competing and dependent failure processes. Reliab. Eng. Syst. Saf. 2020, 199, 106890. [Google Scholar] [CrossRef]
- He, Y.A.; Lc, B.; Nb, C. New reliability indices for first- and second-order discrete-time aggregated semi-Markov systems with an application to TT&C system. Reliab. Eng. Syst. Saf. 2021, 215, 107882. [Google Scholar]
- Zabala, Y.A.; Costa, O. Static Output Constrained Control for Discrete-Time Hidden Markov Jump Linear Systems. IEEE Access 2020, 8, 62969–62979. [Google Scholar] [CrossRef]
- Wang, T.; Cai, J.; Meng, Y.; Zhu, S.; Li, Z. Reliability evaluation method for warm standby embryonic cellular array. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 617–634. [Google Scholar] [CrossRef]
- Li, M.; Kang, J.; Sun, L.; Wang, M. Development of Optimal Maintenance Policies for Offshore Wind Turbine Gearboxes Based on the Non-homogeneous Continuous-Time Markov Process. J. Mar. Sci. Appl. 2019, 18, 93–98. [Google Scholar] [CrossRef]
- Barbu, V.S.; D’Amico, G.; Gkelsinis, T. Sequential Interval Reliability for Discrete-Time Homogeneous Semi-Markov Repairable Systems. Mathematics 2021, 9, 1997. [Google Scholar] [CrossRef]
- Barbu, V.; Limnios, N. Semi-Markov Chains and Hidden Semi-Markov Models toward Applications; Springer: New York, NY, USA, 2008. [Google Scholar]
- Chryssaphinou, O.; Limnios, N.; Malefaki, S. Multi-State Reliability Systems Under Discrete Time Semi-Markovian Hypothesis. IEEE Trans. Reliab. 2011, 60, 80–87. [Google Scholar] [CrossRef]
- Moghaddass, R.; Zuo, M.J. A parameter estimation method for a condition-monitored device under multi-state deterioration. Reliab. Eng. Syst. Saf. 2012, 106, 94–103. [Google Scholar] [CrossRef]
- Dong, M.; Peng, Y. Equipment PHM using non-stationary segmental hidden semi-Markov model. Robot. Comput. Manuf. 2011, 27, 581–590. [Google Scholar] [CrossRef]
- Li, S. Multi-Source Knowledge Reasoning for Data-Driven IoT Security. Sensors 2021, 21, 7579. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Plastino, A.R.; Plastino, A. Tsallis’ entropy, Ehrenfest theorem and information theory. Phys. Lett. A 1993, 177, 177–179. [Google Scholar] [CrossRef]
- Himberg, J.; Korpiaho, K.; Mannila, H.; Tikanmaki, J.; Toivonen, H.T.T. Time Series Segmentation for Context Recognition in Mobile Devices. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001. [Google Scholar]
- Vasko, K.T.; Toivonen, H.T.T. Estimating the number of segments in time series data using permutation tests. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002. [Google Scholar]
- Bezdek, J.C.; Dunn, J.C. Optimal Fuzzy Partitions: A Heuristic for Estimating the Parameters in a Mixture of Normal Distributions. IEEE Trans. Comput. 1975, C-24, 835–838. [Google Scholar] [CrossRef]
- Abonyi, J.; Babuska, R.; Szeifert, F. Modified Gath-Geva fuzzy clustering for identification of Takagi-Sugeno fuzzy models. IEEE Trans. Syst. Man Cybern. Part B Cybern. A Publ. IEEE Syst. Man Cybern. Soc. 2002, 32, 612–621. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Mixtures of Probabilistic Principal Component Analyzers. Neural Comput. 1999, 11, 443–482. [Google Scholar] [CrossRef]
- Kaymak, U.; Babuska, R. Compatible cluster merging for fuzzy modelling. In Proceedings of the 1995 IEEE International Conference on Fuzzy Systems, Yokohama, Japan, 20–24 March 1995. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Operating Conditions | ||
|---|---|---|---|
| Condition 1 | Condition 2 | Condition 3 | |
| Learning set | Bearing1_1 | Bearing2_1 | Bearing3_1 |
| Bearing1_2 | Bearing2_4 | ||
| Bearing1_4 | |||
| Bearing1_5 | |||
| Test set | Bearing1_6 | Bearing2_5 | Bearing3_3 |
| Bearing1_7 | |||
| Bearing Number | State 1 Running-in Stage | State 2 Normal Operation Stage | State 3 Degradation Stage | State 4 Complete Failure Stage |
|---|---|---|---|---|
| Bearing1_1 | [1, 360] | [361, 1800] | [1801, 2740] | [2741, 2803] |
| Bearing1_2 | [1, 289] | [290, 392] | [393, 844] | [845, 871] |
| Bearing1_4 | [1, 329] | [330, 1084] | [1085, 1376] | [1377, 1428] |
| Bearing1_5 | [1, 612] | [613, 1020] | [1021, 2421] | [2422, 2463] |
| Bearing1_7 | [1, 540] | [541, 1980] | [1981, 2210] | [2211, 2259] |
| Bearing2_1 | [1, 660] | [661, 817] | [818, 874] | [875, 977] |
| Bearing2_4 | [1, 402] | - | [403, 740] | [741, 751] |
| Bearing2_5 | [1, 566] | [567, 2254] | - | [2255, 2311] |
| Bearing3_1 | [1, 246] | [247, 490] | - | [491, 517] |
| Bearing3_3 | [1, 134] | [135, 294] | [295, 423] | [424, 436] |
| States | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|
| State 1 | 0.8712 | 0.1112 | 0.0173 | 0.0003 |
| State 2 | 0.0000 | 0.7496 | 0.2511 | 0.0993 |
| State 3 | 0.0000 | 0.0000 | 0.7028 | 0.2972 |
| State 4 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| States | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|
| Average sojourn time | 413.8 | 739.5 | 383.9 | 44.3 |
| States | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|
| State 1 | 0.8695 | 0.1128 | 0.0174 | 0.0003 |
| State 2 | 0.0000 | 0.7496 | 0.2511 | 0.0993 |
| State 3 | 0.0000 | 0.0000 | 0.7028 | 0.2972 |
| State 4 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| States | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|
| Expectation of sojourn time | 390.8451 | 739.5547 | 383.93594 | 44.3543 |
| Variance of sojourn time | 2.9458 | 1.5942 | 1.5026 | 1.4358 |
| State Number | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 1 | - | - | - | - |
| 2 | 0.0000 | 0.6512 | 0.3291 | 0.1179 |
| 3 | 0.0000 | 0.0000 | 0.7028 | 0.2972 |
| 4 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| States | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|
| Expectation of sojourn time | - | 665.9154 | 383.9326 | 44.3427 |
| Variance of sojourn time | - | 1.9425 | 1.5026 | 1.4358 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kou, L.; Chu, B.; Chen, Y.; Qin, Y. An Automatic Partition Time-Varying Markov Model for Reliability Evaluation. Appl. Sci. 2022, 12, 5933. https://doi.org/10.3390/app12125933
Kou L, Chu B, Chen Y, Qin Y. An Automatic Partition Time-Varying Markov Model for Reliability Evaluation. Applied Sciences. 2022; 12(12):5933. https://doi.org/10.3390/app12125933
Chicago/Turabian StyleKou, Linlin, Baiqing Chu, Yan Chen, and Yong Qin. 2022. "An Automatic Partition Time-Varying Markov Model for Reliability Evaluation" Applied Sciences 12, no. 12: 5933. https://doi.org/10.3390/app12125933
APA StyleKou, L., Chu, B., Chen, Y., & Qin, Y. (2022). An Automatic Partition Time-Varying Markov Model for Reliability Evaluation. Applied Sciences, 12(12), 5933. https://doi.org/10.3390/app12125933