A neural network is a class of machine learning algorithm whose basic structure is made up of inter-linked neurons and often nonlinear activation functions. These neurons are organized into layers and are made up of a set of mathematical operations wherein the input to the layer is multiplied by a set of learnt weights, bias is optionally added, and the activation function is applied to the output which is sent to the next layer. The value of the weights are learnt by the network via an optimization task in which a given distance between the target and the network output is minimized. This enables the network to learn complex nonlinear mappings between the inputs and outputs which would make this method suited to the task of distortion modelling.
We can see similarities between this process and certain methods described previously in the black- and gray-box categories of methods. For example, an architecture comprising a 1D convolutional layer followed by a nonlinear activation can be considered as a Wiener model (linear filter followed by a nonlinearity) [
23]. Certain nonlinear activation functions present in neural networks, such as the sigmoid or hyperbolic tangent, appear frequently in the literature of VA modelling [
6]. Additionally, certain architectures that exist, designed for times series and sequence modelling, are well suited to the amplifier emulation task and also bear similarities with classic DSP elements. For example, Kuznetsov et al. [
4] show an equivalence between infinite impulse response (IIR) filters and RNN. Taking into account such similarities between traditional VA modelling and neural networks, it seems natural to extend the use of ANN to this simulation task.
A number of DL architectures have appeared in the state-of-the-art of distortion circuit modelling techniques in recent years including various configurations of both convolutional and recurrent layers. Here, we study the recent works that have appeared in this state-of-the-art. Each aspect of the neural modelling problem will be discussed with recapitulative tables that aim to summarize and clarify the situation. The different aspects that will be detailed here are the architectures used, the different modelling approaches, the various data sets, the loss functions, the evaluation techniques, and finally the real-time capabilities of each body of work.
3.1. Architectures
We detail here the three main categories of architectures that have populated the state-of-the-art: convolutional networks, recurrent networks, and hybrid configurations.
The first instance of CNN being used for the task of amplifier and distortion effects modelling was presented in [
25] for the emulation of tube amplifiers and their follow-up article [
26] for the emulation of distortion pedals, where the authors use a feed-forward variant of the WaveNet architecture from [
27]. This autoregressive architecture from Deep Mind was originally designed for the generation of raw audio waveforms for speech synthesis. The feedforward variant presented by Damskägg et al. [
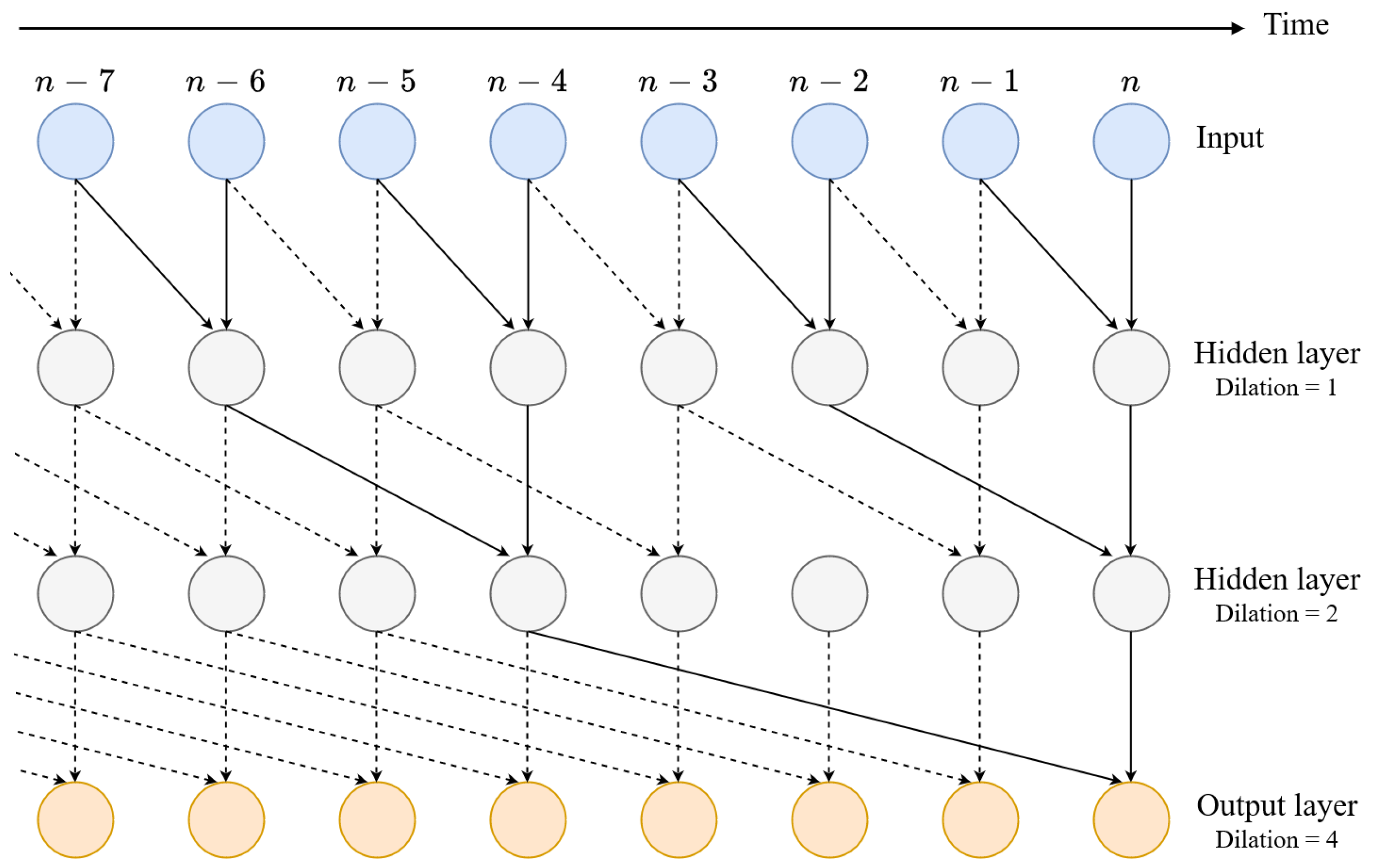
25] contains a stack of dilated causal convolution layers, which enable for a large field of view without increasing the computational cost of the processing. The dilation is done by only using certain outputs from the previous layers for the convolution operation as illustrated in
Figure 1. The larger field of view means that the network can be exposed to more past information and is thus able to better model long-term dependencies of the signal.
In the first article from Damskägg et al. [
25], two models of different sizes are presented and compared, both with 10 convolutional layers with a filter size of 3 and a dilation pattern of
. Both networks have a post-processing block comprising a three-layer fully connected network and the smallest network has two channels in the convolutional and post-processing layers for a total of around 600 parameters, while the largest one has 16 channels in both the convolutional and post-processing layers for around 30,000 parameters. The network was used to model a Fender Bassman 56F-A preamplifier. The WaveNet models were compared to a block-oriented model from [
21] and a Multi-Layer Perceptron (MLP). The larger WaveNet model outperformed the others in both the objective and subjective evaluation.
In their follow-up article [
26], Damskägg et al. focus more on the real-time possibilities of their WaveNet architecture applied to distortion pedal emulation. The feedforward WaveNet is slightly modified in this work, for instance the three-layer post-processing block from their previous work is replaced with a single 1x1 convolutional layer. They aim to find a trade-off between accuracy of their method and computational load as well as the minimum amount of data required for training. For this, three different configurations were studied, see
Table 1.
This new WaveNet variant was tested on three effects pedals: Ibanez Tube Screamer, Boss DS-1, and an Electro-Harmonix Big Muff Pi.
A modified version of the feedforward WaveNet architecture, also known as Temporal Convolutional Network (TCN), was used in [
28] in order to achieve more efficient computation for real-time use of models with more complex nonlinear behaviour. The authors show that by using shallower networks with very large dilation factors (in order to retain a large enough receptive field with this shallower configuration), they were able to achieve comparable performance with greater efficiency. In order to have a large enough receptive field for the input of the shallow network, large dilation factors are necessary. In [
26], a dilation factor of
where
l is the
lth layer of the network was used, whereas, here,
was used for the dilation growth. Batch normalization was also used in this work and the original gated activation from [
27] is instead replaced with the Feature-wise Linear Modulation (FiLM) activation from [
29]. This activation consists of a feature-wise affine transformation conditioned on scaling and bias parameters obtained via an embedding of the device’s control parameters. Both causal and non-causal versions of this modified architecture were tested and compared for the emulation of a LA-2A dynamic range compressor. They achieved comparable performance but the noncausal variants performed slightly better in the time-domain. The results of listening tests indicated that a small difference was perceived among the models in comparison to the reference.
The first article presenting the use of recurrent neural networks for vacuum tube amplifier modelling dates back to 2013 where a Nonlinear AutoRegressive eXogenous (NARX) network was applied to the task in [
30]. A NARX network is similar to a traditional RNN (i.e., a fully-connected network incorporating recurrence) but with limited connectivity to remedy the training problems usually present in RNN which are linked to vanishing and exploding gradients due to their recursive nature. The architecture used was a two-layer, feedforward network with sigmoid activation functions in the hidden layer and a single linear neuron in the output layer. The audio quality of this method was reported to be low when modelling a 4W Vox AC4TV tube amplifier either due to insufficient training or limited model capacity.
Zhang et al. [
31] follow up the work on the NARX network with a study using Long Short Term Memory (LSTM), first proposed in [
32], for the task of amplifier modelling. Again, a 4W Vox AC4TV was chosen for this work. LSTM is a RNN variant that incorporates the use of various gates to control information flow through each recurrent layer in order to avoid the vanishing and exploding gradients of regular RNN. These gates are the following:
where
is the sigmoid activation function, the
Ws represent the weights of the layer, the
bs represent the biases, and ⊙ is the Hadamard product. The
and the
refer to the input of the cell and the hidden state, respectively.
The models used were configured as three or four-layer networks with a structure comprising a variable length input, followed by LSTM with a variable number of units (including either linear or tanh activation) and a linear output unit. The number of units used in the LSTM layers varied from 5 to 20, with a number of hidden units varying in the same range and a sequence length in the range of [1, 5]. During subjective listening tests, the audio quality of the network output, when compared to the target device, was not deemed satisfactory by semiprofessional guitarists.
Wright et al. tested a new LSTM architecture along with another variant on the traditional RNN, the Gated Recurrent Unit (GRU) [
33] and both were compared to the WaveNet architecture from [
26]. The GRU, like LSTM, aims to remedy exploding and vanishing gradient problems by controlling information flow through using an update gate instead of the four gates of LSTM, leading to improved computational efficiency. The computations carried out in a GRU are the following [
34]:
The architecture used is comprised of a single recurrent layer followed by a fully connected one. Preliminary experiments showed that adding extra recurrent layers had little effect on the audio quality of the output. This method was used to model a pedal (Big Muff) and a combo amplifier (Blackstar HT-1) in [
33]. In terms of objective quality, the most accurate RNN outperformed the WaveNet for the pedal and the most accurate WaveNet outperformed the RNN for the amplifier, with LSTM outperforming the GRU in terms of accuracy with roughly the same processing time.
In a follow-up article [
23], further comparisons between the recurrent networks from [
33] and various WaveNet configurations were carried out for the modelling of two vacuum tube amplifiers: a Blackstar HT-5 Metal and a Mesa Boogie 5:50 Plus. This study includes the results from previous articles on the feedforward WaveNet and the LSTM network for distortion pedal emulation, and extends this with the inclusion of the vacuum tube amplifier models.
Various configurations of each architecture were trained and compared in order to gauge both the real-time capabilities (using C++ implementations) and the audio quality. The largest configurations were WaveNet3 with gated activation from [
27], 18 layers, and 16 channels, and LSTM96 with 96 recurrent units. The smallest configurations were WaveNet1 with gated activation, 10 layers, and 16 channels, and LSTM32 with 32 recurrent units. The LSTM provides better processing speeds than the WaveNet models; however, the largest WaveNet can better model the highly nonlinear HT5M amplifier.
Analog distortion effects can be emulated by various configurations of neural network architectures [
35]. In this work, eight architectures are tested and compared, one of which is the subject of a 2018 article [
36]. These architectures include four LSTM networks, one hybrid convolutional LSTM, one plain Deep Neural Network (DNN) in the form of a MLP, one CNN, and one hybrid convolutional RNN. The most notable architectures of this work are:
The parametric LSTM in which the input dimensions are extended in order to taken into account the amplifier parameters.
The convolutional LSTM in which two stacked 2D convolution layers are used to redimension the input signals in order to parallelize the computations on GPU for accelerated processing.
The sequence-to-sequence LSTM which outputs a buffer instead of a single sample, again to accelerate processing.
All architectures presented vary in terms of accuracy and real-time performance but the hybrid convolutional LSTM presented the best Computation Time (CT) and accuracy trade-off.
Another category of hybrid method includes autoencoder architectures such as those presented in the works of Martinez-Ramirez et al. [
37,
38,
39]. The general structure of an autoencoder comprises three stages, namely, an encoding front-end, a latent space containing the new representation of the input data, and a decoding back-end. This structure enables the model to learn an approximate copy of the input, forcing it to prioritize useful properties of the data [
22].
In their preliminary article focused on modelling nonlinear audio effects [
39], a convolutional autoencoder with fully connected latent space (dubbed CAFx) was proposed with the following structure: an adaptive front-end consisting of two 1D convolutional layers (the first with 128 filters of size 64 and the second with 128 filters of size 128), a max pooling layer, batch normalization before this pooling and a residual connection; as well as a latent-space of two dense layers with 64 units and a decoder consisting of four fully connected layers (of sizes 128, 64, 64, 128) whose last layer includes a Smooth Adaptive Activation Function (SAAF). This architecture was used to model three of the audio effects in the IDMT-SMT-Audio-Effects data set [
40]: distortion, overdrive, and equalization (EQ).
Their follow-up article [
37] modifies the latent space of this structure by replacing the fully connected layers with Bidirectional LSTM (Bi-LSTM) which are LSTM containing forward and backward information at every time step to create a convolutional and recurrent autoencoder (CRAFx) to model more complex, time-varying audio effects, again from the IDMT-SMT-Audio-Effects data set.
Another variant of this architecture that uses the feedforward WaveNet in the latent space (CWAFx) is introduced in [
37] and the three autoencoders are compared with the original feedforward WaveNet architecure introduced in [
26] on various modelling tasks, including that of a vacuum tube amplifier, sampled from a 6176 Vintage Channel Strip unit. The results of this comparison showed that both the feedforward WaveNet and CAFx, the original DNN autoencoder, performed similarly and that they are both outperformed by CRAFx and CWAFx with CRAFx performing slightly better than CWAFx. It was reported that the vacuum tube preamplifier was able to be successfully modeled on the two-second samples.
The last two architectures presented in
Table 2 fall under the scope of gray-box neural methods which, along with newly emerging white-box methods, aim to improve interpretability of neural-network based approaches.
3.2. Approaches
Neural networks are black-box by nature but in recent years they have started to be integrated into both gray- and even white-box modelling methods. Indeed, the recent works of Parker et al. [
41], Nercessian et al. [
43], Kuznetsov et al. [
4], and Aleksi Peussa [
42] fall into the category of gray-box approaches.
Parker et al. present the State Trajectory Network (STN) in their gray-box approach [
41], which is a method of integrating neural networks, namely, a MLP here, into a State-Space model. This method aims to augment the black-box neural network approach by integrating the internal values into the training data for a more accurate simulation. A number of distortion circuits are tested, namely a simplified version of the main distortion stage in the Boss DS-1 pedal was used in the form of a second-order diode clipper. Results show that this method is viable as all the circuits modeled were said to be indistinguishable from the targets in informal listening tests however the network training can be unstable [
41,
42].
Aleksi Peussa augments the STN in his Masters thesis [
42] to include recurrence using a GRU and compares this to both the original STN and a black-box network using only the GRU trained on input-output recordings. This work confirms the instability in training for the STN as it was unable to model a Boss SD-1 pedal. Although the State-Space GRU was able to emulate this pedal, it was outperformed by its black-box equivalent. However the state-space model managed to outperform the black-box one when applied to a Moog ladder filter due to its self-oscillatory nature.
Some of the gray- and white-box approaches making an appearance in the neural network landscape result from the introduction of the Differentiable Digital Signal Processing (DDSP) library from Magenta [
44]. DDSP enables the integration of classic signal processing elements, such as filters or oscillators which are typically non-differentiable and thus cannot be dealt with via gradient-based optimization techniques, into the deep learning pipeline in Tensorflow.
Kuznetsov et al. [
4] explore the idea of differentiable IIR filters using the DDSP library. The authors present the link between IIR filters and RNN and present a Wiener–Hammerstein model using differentiable IIR filters. This model is used to emulate a Boss DS-1 distortion pedal and compared with a simple convolutional layer as a baseline. None of the models were able to fit the target data perfectly using this method.
Differentiable IIR filters are explored further in [
43] by proposing a cascade of differentiable biquads to model a distortion effect. A digital biquad filter is a second order recursive linear filter containing two poles and two zeros, and higher order IIR filters can be created by cascading biquads in series [
45]. The proposed model is said to have significantly fewer parameters and reduced complexity when compared to more traditional black-box architectures. This method was used to model a Boss MT-2 distortion pedal and comparison with WaveNet showed that the parametric EQ representation of the cascaded biquad outperformed the other three representations as well as the WaveNet.
Finally, white-box approaches have started to appear also in the landscape of neural methods. Esqueda et al. [
46] implement a white-box model in differentiable form which allows approximate component values to be learned, thus remedying the accuracy problems that can arise in white-box modelling due to lack of access of the exact component values of the DUT’s circuit. This method was tested on a Fender, Marshall, Vox (FMV) tone stack as well as on an Ibanez TS-808 Overdrive stage in order to validate the proposed model. The advantages and downsides of each approach is presented in
Table 3.
3.3. Data Sets
The performance of any of the networks, no matter what category of approach they may fall under, is directly determined by a number of choices made regarding the training process. Notably, the choice of data set is critical.
The performance of neural networks for any given task depends heavily on the data set they are given during the training phase. Indeed, the network needs to be exposed to a wide range input–output pairings in order to learn an accurate mapping for the majority of cases it will encounter during its use.
There exists a number of data sets used for the task of amplifier modelling, all bearing certain similarities. Almost all of the data used throughout the state-of-the-art comprises clean guitar Direct Input (DI) sent through either the analog device or a SPICE simulation of the device. However, the data used depends on the approach.
In black-box approaches, only input–output guitar recordings are necessary for the neural network training, whereas for gray- or white-box different or additional data is required. In the gray-box approaches presented in [
4,
41,
42,
43], component values of the internal circuit are also used in the training data. In the white-box approach of Esqueda et al. [
46], only the circuit component values are used.
In the black- and gray-box approaches, certain aspects of the training data have a significant impact on the resulting model. These aspects are, namely, the sampling rate, the length, and type of the data. The sampling rate dictates the audio quality of the simulation and impacts its real-time processing capabilities.
The data used to train the WaveNet from [
25] was obtained from a SPICE simulation of a Fender Bassman 56F-A preamplifier applied to DI from a Freesound data set for audio tagging [
47]. A total of 4 h of data was used for the train set and 20 min for validation split into 100 ms segments and a random gain value in the range of [−15 dB, 15 dB] was applied to the inputs for more dynamic range. All data were recorded with a sampling rate of 44.1 kHz.
In their follow-up article [
26], Damskägg et al. show that as little as three minutes of data is sufficient for the training of the convolutional networks, although final results presented were obtained with five minutes of data (50% guitar and 50% bass) from the IDMT-SMT-Guitar/Bass data sets from [
48,
49]. The sampling rate for all recordings was 44.1 kHz. These data sets contain a variety of single note recordings of various different playing styles with varying pickups. The raw inputs from this data set were sent through three effects pedals: Ibanez Tube Screamer, Boss DS-1, and an Electro-Harmonix Big Muff Pi. This data set was also used to train the recurrent networks from [
33].
The amplifier models of [
23] used a different training set than the pedal emulation, taken from a pre-existing data set. This data set was tailor-made for this modelling task and was published in [
50]. It includes five different styles of guitar sounds sent through various guitar amplifiers with their gain parameters set to ten different levels. The audio used in [
23] consists of around three minutes of guitar audio recorded at 44.1 kHz with the training set consisting of 2 min 43 s of audio. This data was used to train both the WaveNet style model and the LSTM.
The SignalTrain data set from [
51] was used for training, testing, and validation of the shallower TCN architectures. This data set contains input–output recordings (at 44.1 kHz) of various instruments from a LA-2A dynamic range compressor.
The training data used for the NARX network of [
30] was comprised of both signals from a function generator (with frequencies in the range [100 Hz, 500 Hz]) and an electric guitar fed to a vacuum tube amplifier, a 4W Vox AC4TV. All training data was recorded at a sampling frequency of 96 kHz and saved to 24-bit stereo wav files with one channel containing the raw input signal and the other containing the tube amplifier signal. The guitar recordings from this data set were used for the LSTM training in [
31].
A summary of these data sets is presented in
Table 4.
As the choice of training data has a decisive impact on the performance of a neural network, so does the choice of cost function used in the optimization process.
3.4. Loss Functions
Training neural networks is an optimization problem in which we often aim to minimize a given loss function. This loss represents the distance between the prediction and the target and must therefore accurately depict the perceptual difference between signals. This is often not the case with objective losses such as the Mean-Squared Error (MSE) defined as:
The models used for amplifier modelling process raw audio in the time domain and the losses used are computed directly with the signal’s waveform whose shape does not perfectly correspond to human perception. For example, different frequencies are not perceived in the same way to the human ear, with certain frequencies appearing louder than others [
52]. This difference in loudness is represented by equal-loudness contours.
To improve the accuracy of a given network, spectral information can also be included into the loss computations but this approach presents its own problems and most of the loss functions used remain time domain-based.
The most widely known loss for training neural networks is the MSE described previously. This loss is one of the most used for training networks in distortion circuit simulation. It was used in one of the first articles presenting recurrent networks for amplifier simulation [
31] as well as in all of the gray-box methods presented previously, including a normalized variant used in [
41] in order to stabilize the initial training of the network.
Similar losses include the Root Mean Squared Error (RMSE) used in [
30]:
and the Normalized Root Mean Squared Error (NRMSE) used in [
35]:
Despite having relatively widespread use, the MSE-based losses lack perceptual accuracy. Another loss function frequently encountered in the state-of-the-art of amplifier simulation methods using neural networks is the Error-to-Signal Ratio (ESR) defined as:
Variants of this loss have been used in the works of Damskägg et al. [
25,
26] and Wright et al. [
23,
33] with pre-emphasis filtering for better perceptual accuracy. In both Damskägg et al. papers, the high-pass pre-emphasis filter with the transfer function
was used to train their WaveNet architecture as without this filtering it was found that the model struggled at higher frequencies.
In order to train the recurrent networks presented in the works of Wright et al., a different pre-emphasis filter was applied to the ESR with the transfer function
along with a term to compensate for a DC offset present in the prediction:
In a further work [
53], various pre-emphasis filters are studied and compared, along with weighting functions in order to gauge which combination better reflects perceptual accuracy. The filters with the following transfer functions were tested:
The low-pass filter is preceded by A-weighting in order to decrease emphasis in regions where little energy is present as this weighting aims to mimic the equal loudness curves of the human ear. Listening tests carried out in this study showed that pre-emphasis filtering enabled better accuracy during the modelling task, with the A-weighted low-pass filtering achieving the best performance.
The Mean Absolute Error (MAE) is also present in the state-of-the-art in both a purely time-domain formulation and a variant in which spectral content is also taken into account. The MAE is defined as
and was used to train all of the autoencoders presented in a previous section [
37,
38,
39]. Steinmetz and Reiss [
28] use a combination loss comprising both time-domain and spectral features. For the time-domain, the MAE was used, and for the spectral magnitude, the Short-Term Fourier Transform (STFT) loss from [
54] is used, leading to the following cost function:
where:
is the Frobenius norm.
An overview of the loss functions used in this field is presented in
Table 5.
The loss functions used for training can also be applied to the evaluation process for an objective measure of performance during testing. However, other methods also exist to provide a more comprehensive assessment of the overall quality.
3.5. Evaluation Methods
The metrics presented in the previous section must be differentiable in order to be used within the optimization problem of the training phase. These metrics can also be used for the evaluation of the network after training and validation, as well as non-differentiable functions and subjective listening tests.
While objective metrics struggle to properly reflect the perceptual aspects of the output audio, listening tests take time to implement and hinder continuous integration of ML systems. Therefore, there is a real need for objective evaluation metrics that do not rely on human participation.
Most of the evaluation methods used for this modelling task rely on reuse of the loss functions used during training or a variation thereof. For example, Damskägg et al. [
26] used pre-emphasized ESR for training and plain ESR for evaluation. While simple to implement, a single objective metric cannot replace subjective listening tests.
The listening tests that are mainly used for this task rely on MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) testing. In a MUSHRA test, the participants are presented with a labeled reference, various test samples, an unlabeled reference, and an anchor. This method is detailled in the Recommendation ITU-R BS.1534-3 [
55].
A similar framework used to carried out listening tests with human participants is the Web Audio Evaluation Tool [
56] which is based on the HTML5 Web Audio API for perceptual audio evaluation.
For the objective evaluation of the models compared in [
28], three metrics were used: the MAE and the STFT loss described above and a perceptually informed loudness metric that uses the loudness algorithm from the ITU-R BS. 1770 Recommendation [
57]. Both the causal and noncausal versions of the network achieved comparable performance but the noncausal variants performed slightly better in the time-domain. A listening test similar to MUSHRA was also carried out using the WebMUSHRA interface [
58] to further validate the accuracy of the models. The results of this test indicated that a small difference was perceived among the models in comparison to the reference.
Subjective evaluation was provided in [
23] in the form of a MUSHRA test, carried out using the WebMUSHRA interface [
58]. These tests showed the WaveNet3 to be the most perceptually accurate model of the HT5M amplifier, although this prediction could still be distinguished from the original amplifier, whereas the LSTM96 proved to be closest to the Mesa 5:50 in terms of subjective quality and most people could not tell the difference between the model and the target.
For the work established in Thomas Schmitz’s PhD thesis [
35], a number of objective metrics as well as listening tests were presented. One listening test studies the number of parameters that can be reduced without loss of accuracy and the other is used to determine the threshold of a given metric above which the accuracy is no longer improved. An overview of the evaluation methods is presented in
Table 6.
3.6. Real-Time Capabilities
The audio quality of the prediction is not the only aspect that requires evaluation. The real-time capabilities are a crucial aspect to take into account when studying any VA model and can also be presented as an objective metric of the quality of the emulation. This is illustrated in the last two methods cited in
Table 6 that take into account the computation times of the methods.
A major factor to take into account when modelling analog audio devices is the real-time constraint. If the solution implemented cannot be used in real-time then it is of little use to the end-users. The real-time constraint for this type of application is approximately 10 ms [
3]. Any latency above this value is likely to be perceived by the musician and hinder their playing.
The latency produced in digital audio processing is known as round-trip latency that is not limited to only the computation time (CT) of the DSP algorithm used [
3]. Analog-to-Digital and then Digital-to-Analog conversion can add up to a 1 ms to the round-trip latency. Additionally, there is a latency inherent to the processing in buffers used in audio interfaces and Digital Audio Workstations (DAW). In order to process a buffer of audio, a delay of that buffer size is added to the round-trip latency which can quickly exceed the real-time constraint. For example, when processing buffers of 256 samples at 44.1 kHz, the time necessary to fill this buffer is around 5.8 ms, which significantly decreases the time left for the DSP computations. This means that using DL architectures with a lot of computations and layers is complicated as it either entails too high a latency or excessive CPU usage which prohibits its use. A number of the architectures present in the state-of-the-art are capable of being used in real-time to varying degrees but caveats also exist.
The architectures presented here although often capable of real-time processing, some of which are light-weight enough to work in real-time on CPU, are still computationally heavy and have not been demonstrated to be able to achieve real-time speeds for sampling rates over 44.1 kHz. Indeed, the hybrid convolutional and recurrent architecture from [
35] utilizes parallelization on GPU in order to process the data in real-time which poses a problem for use in a practical setting in which CPU processing is required. The autoencoder architectures from [
38] have been demonstrated using a sampling rate of 16 kHz, which is insufficient for high-quality audio applications. The shallow TCN from [
28] are capable of real-time use only for input buffer sizes over 1024 samples, which, at 44.1 kHz, incurs a latency of approximately 23.2 ms, which is double the latency required for real-time use of around 10 ms. Finally, the architectures presented in [
23], although capable of real-time processing, remain computationally heavy, even for a sampling rate of 44.1 kHz, which is the lower bound for high quality audio in music applications.
Moreover, digital implementations of analog audio effects usually introduce aliasing into the signal, and to remedy this, anti-aliasing techniques are used which often require upsampling the signals by a factor of eight [
6]. This means that eight times the amount of samples need to be processed in the same amount of time required for a real-time (RT) implementation, further restraining the allowed CT of the chosen DSP algorithm. This also applies to neural networks, although formal study of the aliasing introduced by neural networks in this field is lacking.
A number of architectures are capable of real-time use, even on CPU. However, the RT measures presented in
Table 7 vary in a number of ways including:
The sample rate used for processing;
The processing unit;
The implementation language;
The method of measuring the RTF (number of operations, timing the inference, etc.).
This makes formal comparison challenging. We provide the RTF of a number of illustrative models of the state-of-the-art, from each of the architecture classes of
Section 3.1 in the following section.


 ,
, 

{kind=link}