
Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives

 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
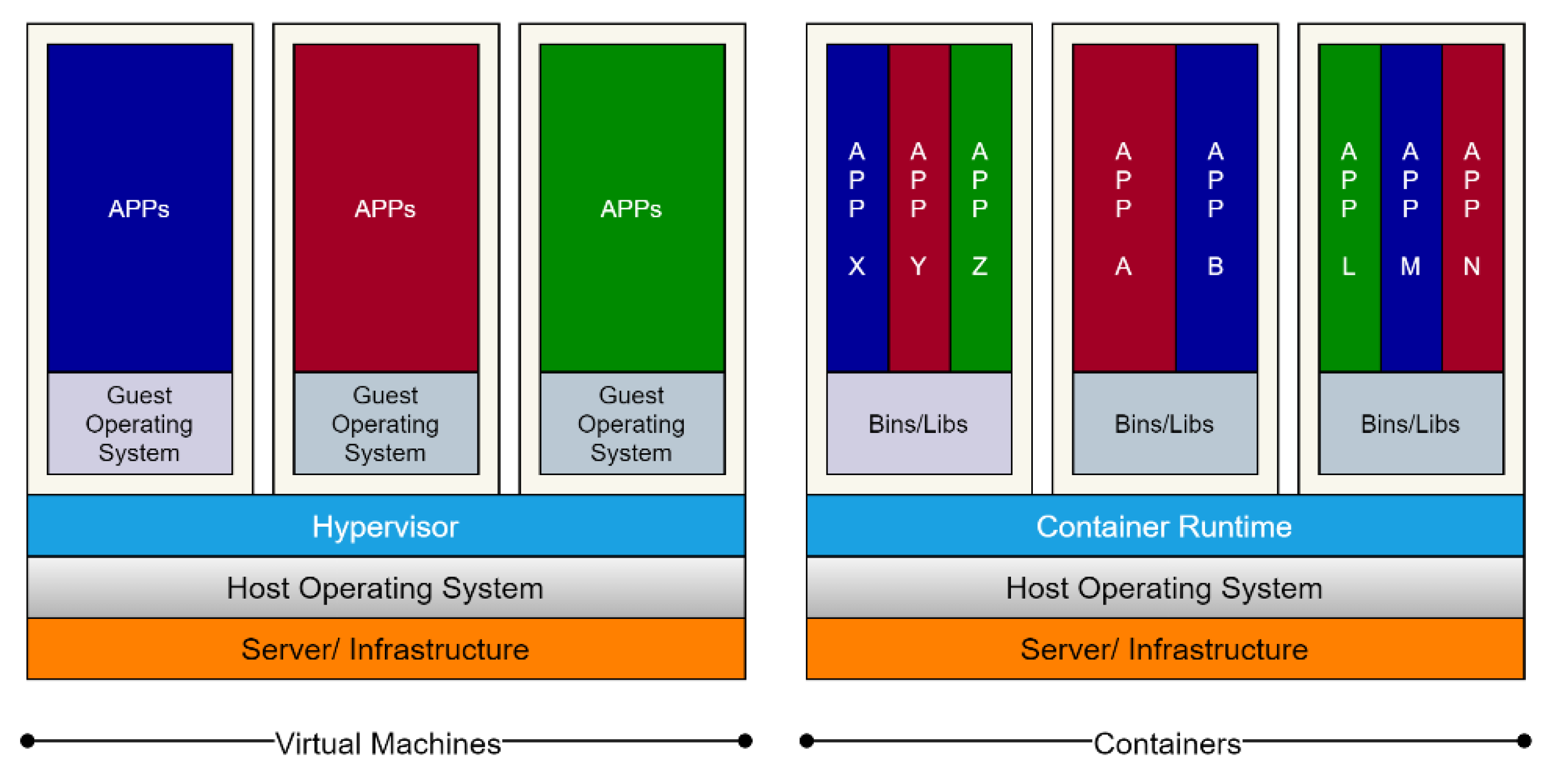
:1. Introduction
- (1)
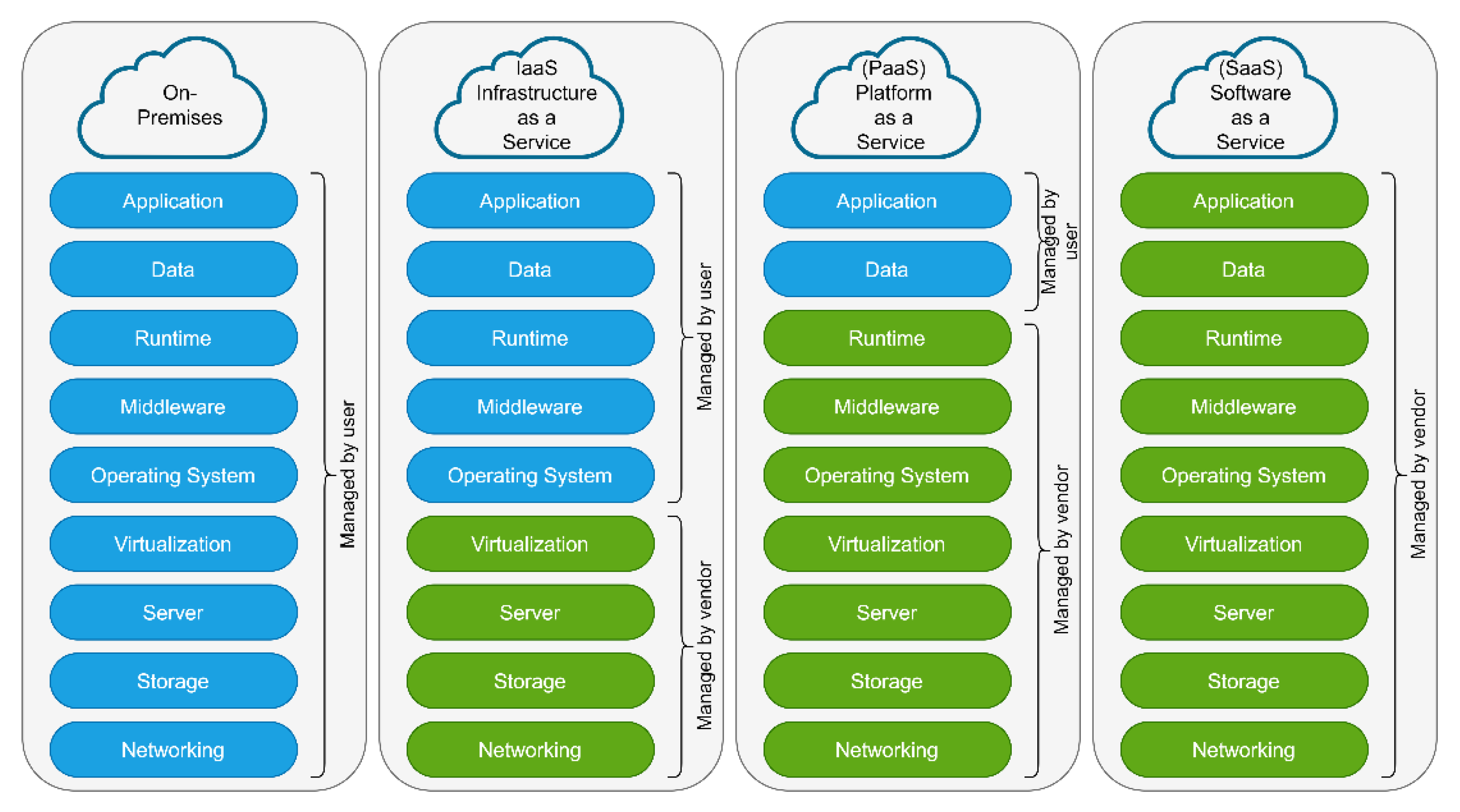
- Software as a Service (SaaS): SaaS provides access to cloud-based software. Through web or API, the users access the software residing on the remote cloud network. In SaaS, the vendor manages most of the technical issues including data handling, storage, servers, etc. Therefore, the users do not have to spend more time installing, maintaining, and upgrading software. Some of the SaaS examples are Dropbox, Salesforce, GoToMeeting, Google Apps, etc.
- (2)
- Infrastructure as a Service (IaaS): In IaaS, the cloud computing vendors provide access to resources such as storage, computing resources, and networking. IaaS lets businesses purchase resources according to their needs/demands. Therefore, IaaS provides a flexible cloud computing model where clients have complete control over the infrastructure. As the whole infrastructure is based on the cloud, there will be no single point of failure. Some of the IaaS examples are Amazon Web Services (AWS), Microsoft Azure, Google Compute Engine (GCE), etc.
- (3)
- Platform as a Service (PaaS): PaaS provides a framework for the users (specifically developers) on which they can develop, manage, and deploy the applications. The users not only have access to computing and storage resources, but they also have access to a set of tools for application development, testing, security, backups, etc. PaaS has several advantages including scalability, high availability, and a cost-effective development and deployment platform. Some of the PaaS examples are Apache Stratos, AWS Elastic Beanstalk, Google App Engine, etc.
2. Literature Review
- Distribution techniques in container orchestration platforms are mostly focused on available and allocated resources and do not take into account the complexity of the microservices’ architecture, microservices’ properties, and workload management accordingly, which need to be addressed.
- The ability to effectively forecast compute demand and application performance under varying resource allocations is one of the research issues related to elastic services.
- Dynamic container orchestration according to microservices interactivity patterns and concerning entities is an active research topic that has room for additional investigation.
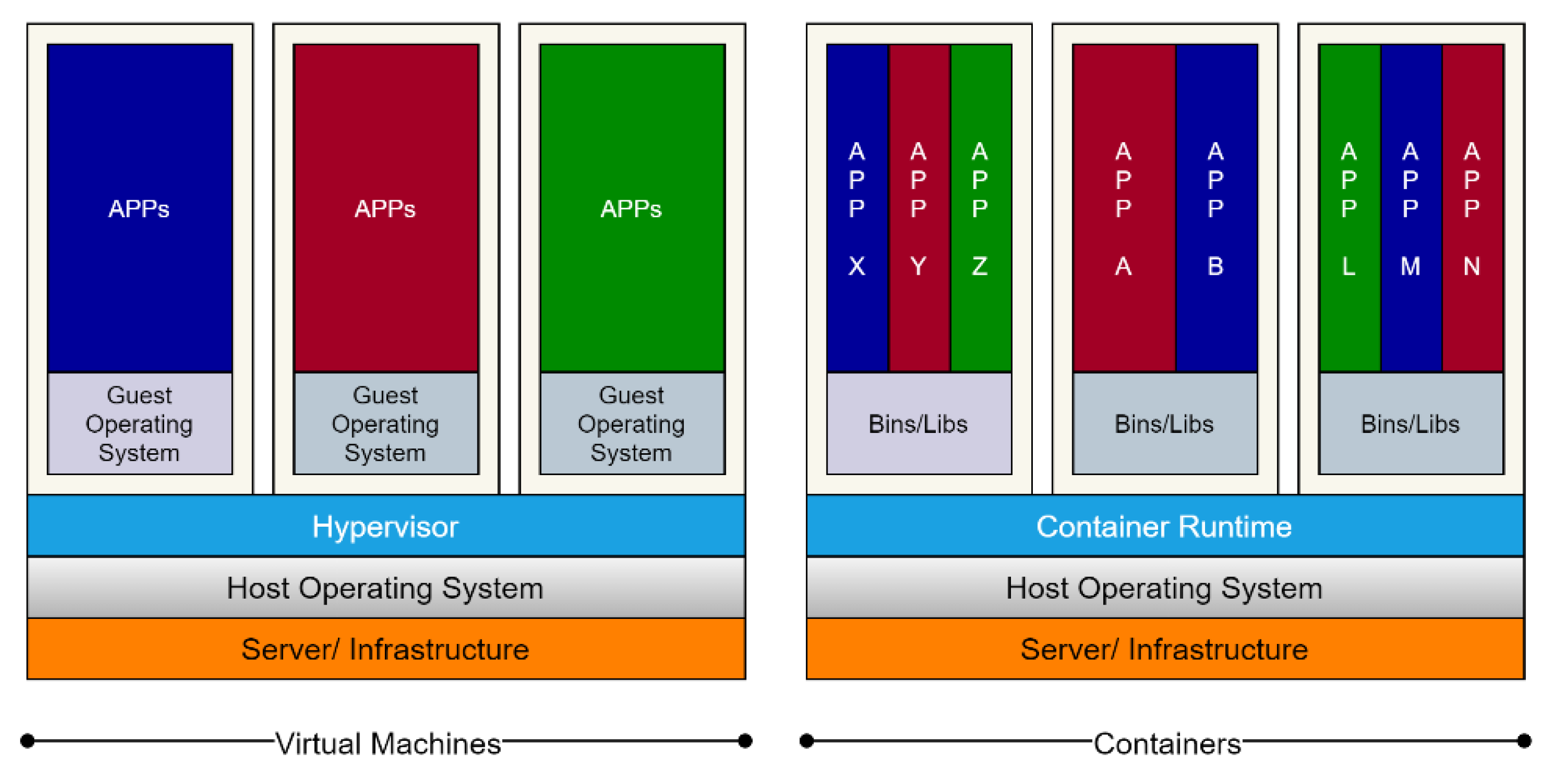
- Containers have less isolation and security than virtual machines (VMs) due to kernel sharing, which is an open issue but not addressed in the article due to the study’s focus and limitation.
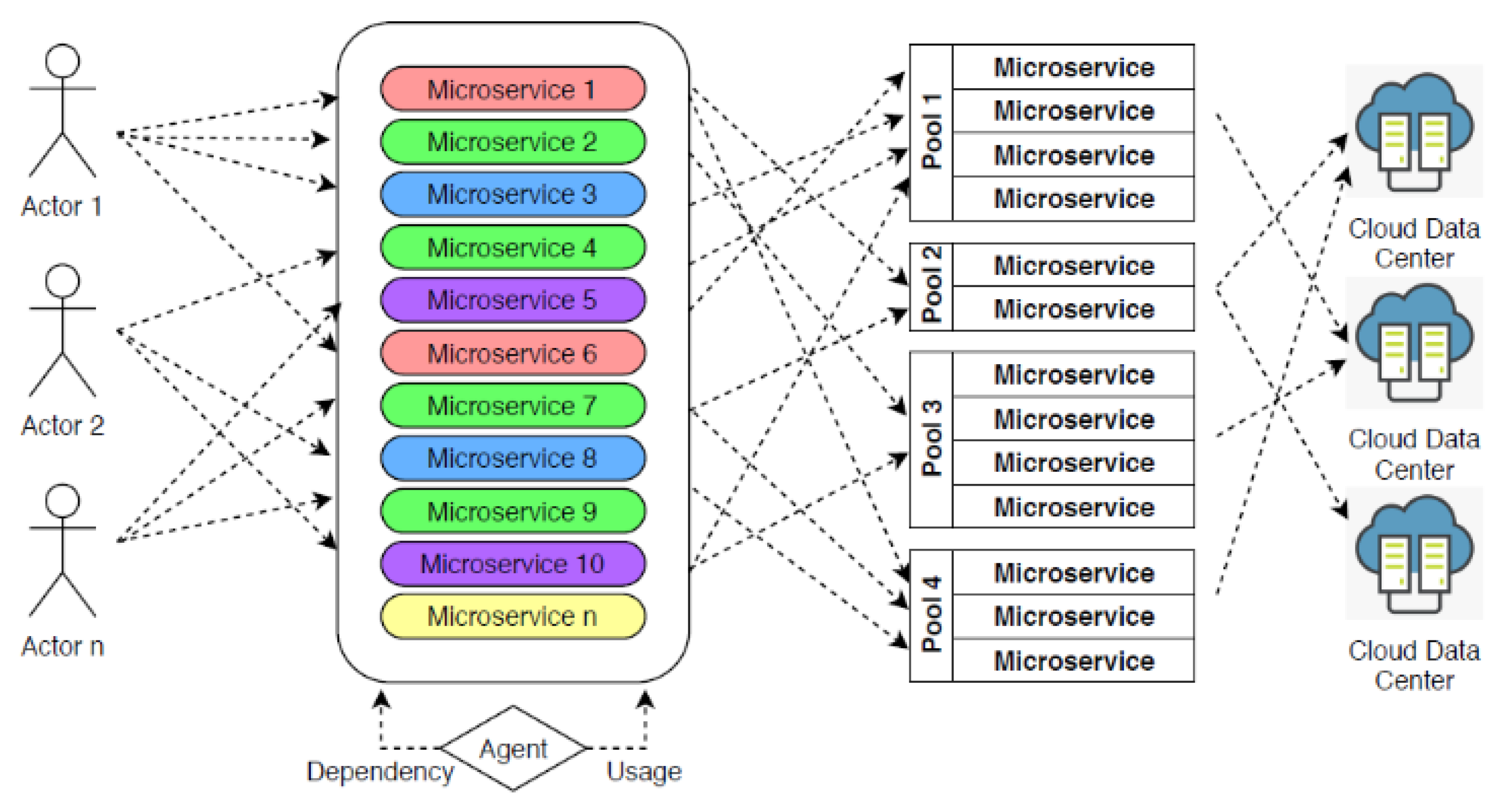
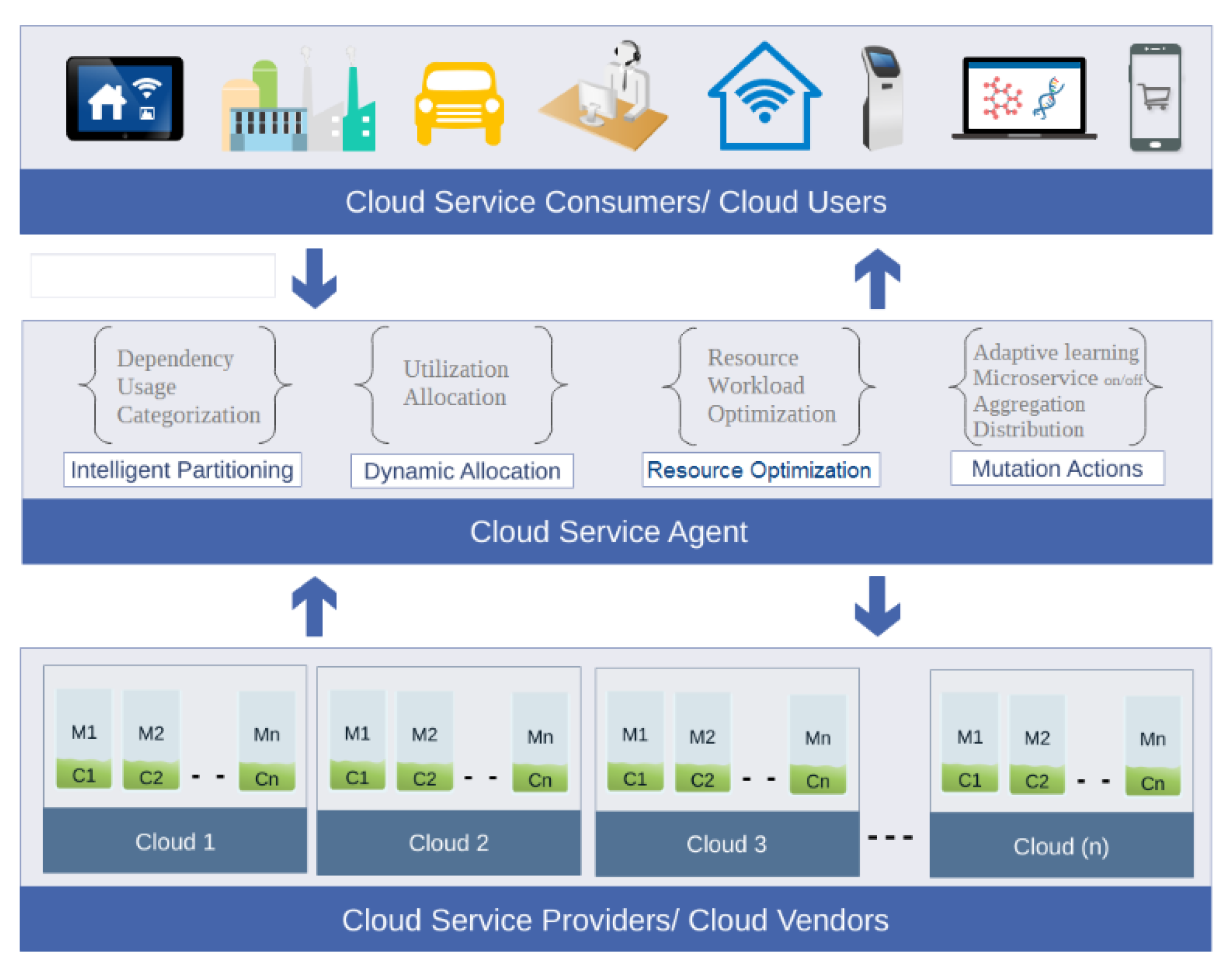
- Intelligent partitioning: responsible for microservice classification and the categorization of microservices based on their usage and dependency on other microservices.
- Dynamic allocation: used for the pre-execution distribution of microservices among containers and making decisions for the dynamic allocation of microservices at runtime.
- Resource optimization: in charge of shifting workloads and ensuring optimal resource use.
- Mutation actions: these are based on procedures that will mutate the microservices based on cloud data center workloads.
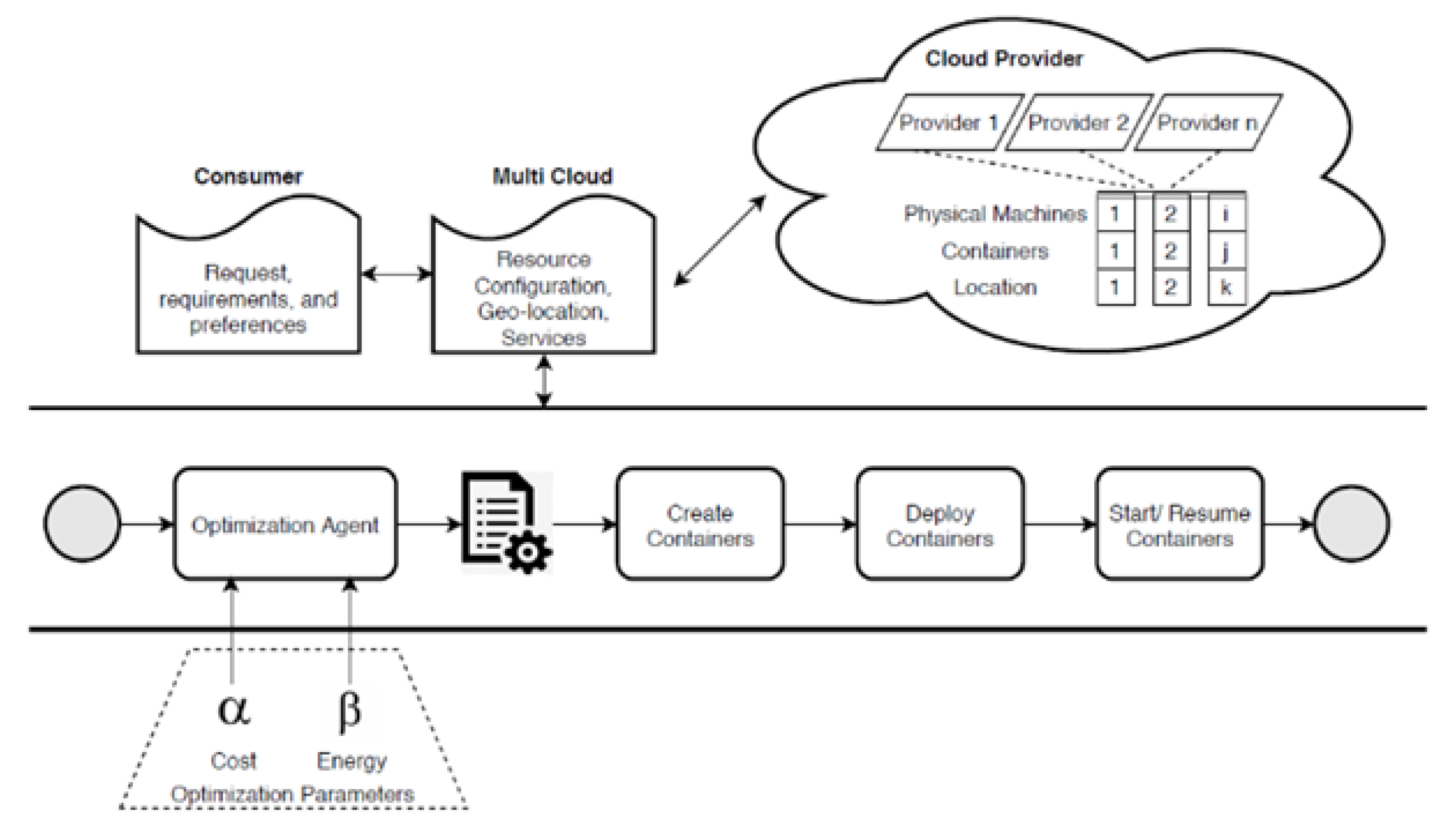
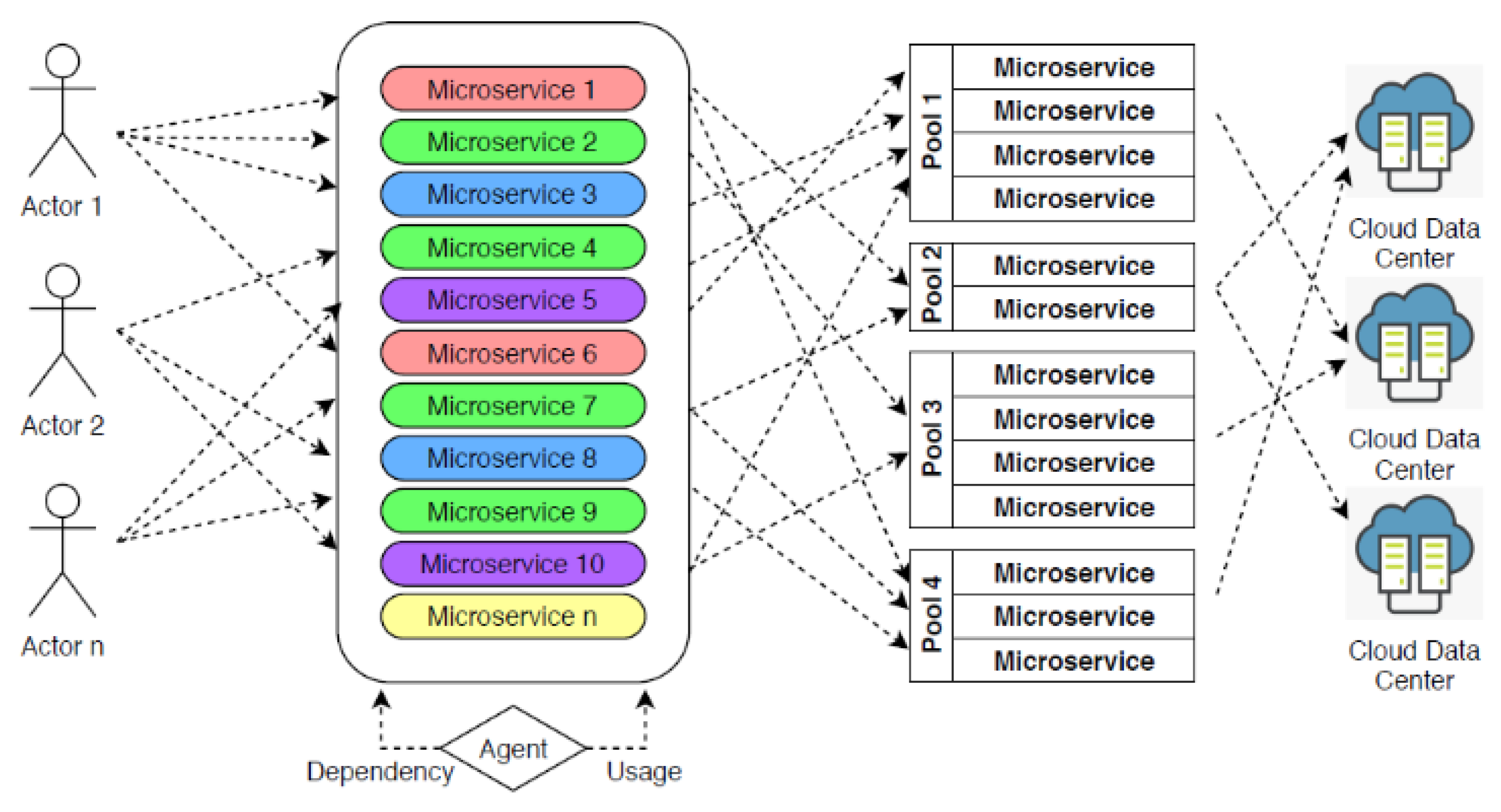
3. Methodology
3.1. Intelligent Partitioning
3.2. Dynamic Allocation
3.3. Resource Optimization
- -
- The overall work needs to be distributed across multiple hosts to comply with the service level agreement.
- -
- Consolidating the number of hosts; thus, a smaller number of hosts will result in lower consumption of energy.
- -
- A specific host performs better than the currently running host.
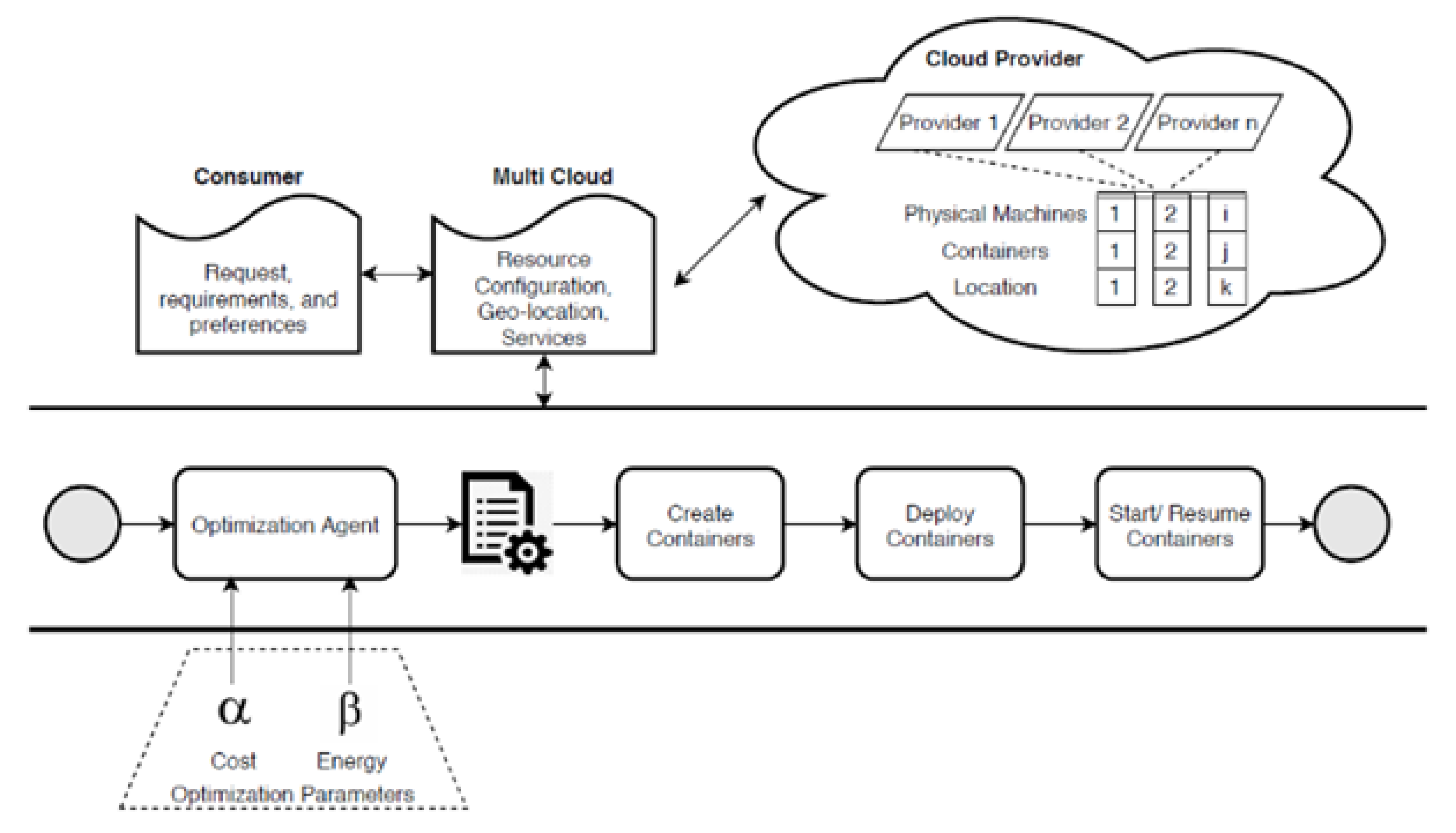
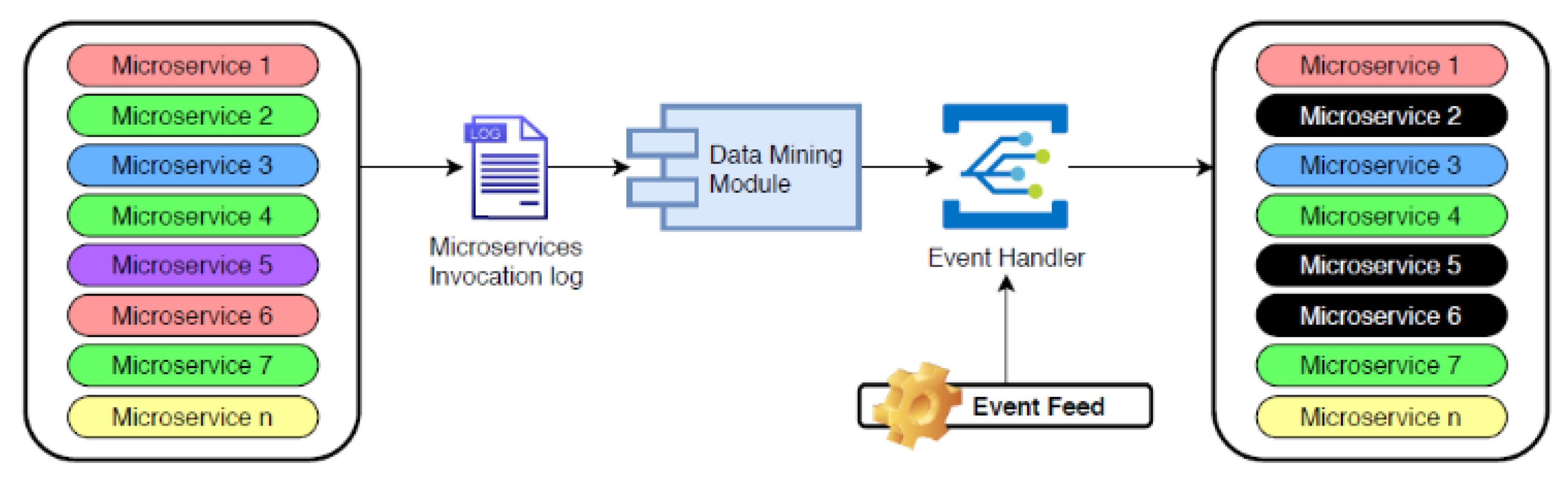
3.4. Mutation Actions
3.5. Metrics for Framework Performance Assessment
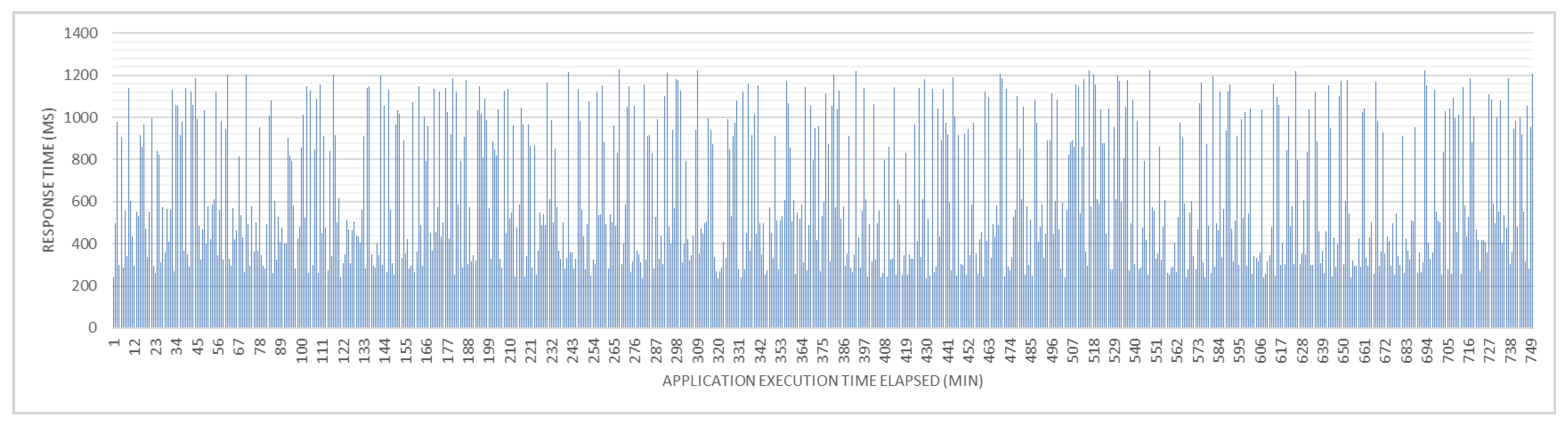
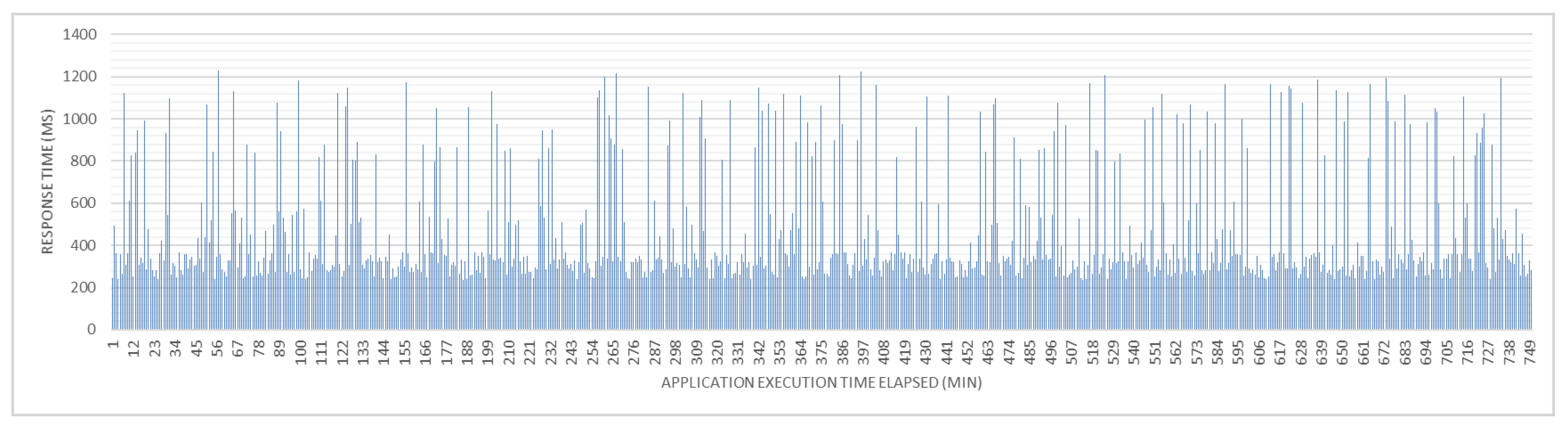
4. Results and Discussion
5. Conclusions
- Intelligent partitioning, which is in charge of microservice classification.
- Dynamic allocation, which is used to distribute microservices to containers at the start of the service and then make dynamic microservice allocation decisions at runtime.
- Resource optimization, which will be in charge of redistributing workloads and maximizing resource use.
- Mutation action, which is built on procedures that will change microservices in response to cloud data center workloads.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mell, P.M.; Grance, T. The NIST Definition of Cloud Computing; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2011. [CrossRef]
- Buyya, R.; Yeo, C.S.; Venugopal, S. Market-Oriented Cloud Computing: Vision, Hype, and Reality for Delivering IT Services as Computing Utilities. In Proceedings of the 2008 10th IEEE International Conference on High Performance Computing and Communications, Dalian, China, 25–27 September 2008; pp. 5–13. [Google Scholar]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I.; et al. A View of Cloud Computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef] [Green Version]
- SaaS vs. PaaS vs. IaaS: What’s The Difference & How To Choose—BMC Software|Blogs. Available online: https://www.bmc.com/blogs/saas-vs-paas-vs-iaas-whats-the-difference-and-how-to-choose/ (accessed on 11 February 2022).
- Gai, K.; Qiu, M.; Zhao, H.; Tao, L.; Zong, Z. Dynamic Energy-Aware Cloudlet-Based Mobile Cloud Computing Model for Green Computing. J. Netw. Comput. Appl. 2016, 59, 46–54. [Google Scholar] [CrossRef]
- Xu, M.; Buyya, R. BrownoutCon: A Software System Based on Brownout and Containers for Energy-Efficient Cloud Computing. J. Syst. Softw. 2019, 155, 91–103. [Google Scholar] [CrossRef]
- Juarez, F.; Ejarque, J.; Badia, R.M. Dynamic Energy-Aware Scheduling for Parallel Task-Based Application in Cloud Computing. Future Gener. Comput. Syst. 2018, 78, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Qiu, C.; Shen, H.; Chen, L. Towards Green Cloud Computing: Demand Allocation and Pricing Policies for Cloud Service Brokerage. IEEE Trans. Big Data 2018, 5, 238–251. [Google Scholar] [CrossRef]
- Horri, A.; Mozafari, M.S.; Dastghaibyfard, G. Novel Resource Allocation Algorithms to Performance and Energy Efficiency in Cloud Computing. J. Supercomput. 2014, 69, 1445–1461. [Google Scholar] [CrossRef]
- Esfandiarpoor, S.; Pahlavan, A.; Goudarzi, M. Structure-Aware Online Virtual Machine Consolidation for Datacenter Energy Improvement in Cloud Computing. Comput. Electr. Eng. 2015, 42, 74–89. [Google Scholar] [CrossRef]
- Watada, J.; Roy, A.; Kadikar, R.; Pham, H.; Xu, B. Emerging Trends, Techniques and Open Issues of Containerization: A Review. IEEE Access 2019, 7, 152443–152472. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Y.; Dong, B.; Tian, F.; Zheng, Q. A Genetic Algorithm-Based Energy-Efficient Container Placement Strategy in CaaS. IEEE Access 2019, 7, 121360–121373. [Google Scholar] [CrossRef]
- Zhang, R.; Zhong, A.; Dong, B.; Tian, F.; Li, R. Container-VM-PM Architecture: A Novel Architecture for Docker Container Placement. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 10967, pp. 128–140. ISBN 9783319942940. [Google Scholar]
- Lv, L.; Zhang, Y.; Li, Y.; Xu, K.; Wang, D.; Wang, W.; Li, M.; Cao, X.; Liang, Q. Communication-Aware Container Placement and Reassignment in Large-Scale Internet Data Centers. IEEE J. Sel. Areas Commun. 2019, 37, 540–555. [Google Scholar] [CrossRef]
- Hussein, M.K.; Mousa, M.H.; Alqarni, M.A. A Placement Architecture for a Container as a Service (CaaS) in a Cloud Environment. J. Cloud Comput. 2019, 8, 7. [Google Scholar] [CrossRef] [Green Version]
- Srikantaiah, S.; Kansal, A.; Zhao, F. Energy Aware Consolidation for Cloud Computing. In Proceedings of the Conference on Power Aware Computing and Systems, Berkeley, CA, USA, 7 December 2008. [Google Scholar]
- Tchana, A.; Son Tran, G.; Broto, L.; DePalma, N.; Hagimont, D. Two Levels Autonomic Resource Management in Virtualized IaaS. Future Gener. Comput. Syst. 2013, 29, 1319–1332. [Google Scholar] [CrossRef] [Green Version]
- Kaewkasi, C.; Chuenmuneewong, K. Improvement of Container Scheduling for Docker Using Ant Colony Optimization. In Proceedings of the 2017 9th International Conference on Knowledge and Smart Technology: Crunching Information of Everything, KST 2017, Chonburi, Thailand, 1–4 February 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 254–259. [Google Scholar]
- Yi, X.; Liu, F.; Niu, D.; Jin, H.; Lui, J.C.S. Cocoa: Dynamic Container-Based Group Buying Strategies for Cloud Computing. ACM Trans. Model. Perform. Eval. Comput. Syst. 2017, 2, 1–31. [Google Scholar] [CrossRef]
- Khan, A.A.; Zakarya, M.; Khan, R.; Rahman, I.U.; Khan, M.; Khan, A.; Ur Rahman, I. An Energy, Performance Efficient Resource Consolidation Scheme for Heterogeneous Cloud Datacenters. J. Netw. Comput. Appl. 2020, 150, 102497. [Google Scholar] [CrossRef]
- Hu, Y.; Zhou, H.; de Laat, C.; Zhao, Z. Concurrent Container Scheduling on Heterogeneous Clusters with Multi-Resource Constraints. Future Gener. Comput. Syst. 2020, 102, 562–573. [Google Scholar] [CrossRef]
- Chung, A.; Park, J.W.; Ganger, G.R. Stratus: Cost-Aware Container Scheduling in the Public Cloud. In Proceedings of the 2018 ACM Symposium on Cloud Computing, Carlsbad, CA, USA, 11–13 October 2018; pp. 121–134. [Google Scholar]
- Tumanov, A.; Jiang, A.; Woo Park, J.; Kozuch, M.A.; Ganger, G.R. JamaisVu: Robust Scheduling with Auto-Estimated Job Runtimes; Technical Report CMU-PDL-16-104; Carnegie Mellon University: Pittsburgh, PA, USA, 2016; pp. 1–24. [Google Scholar]
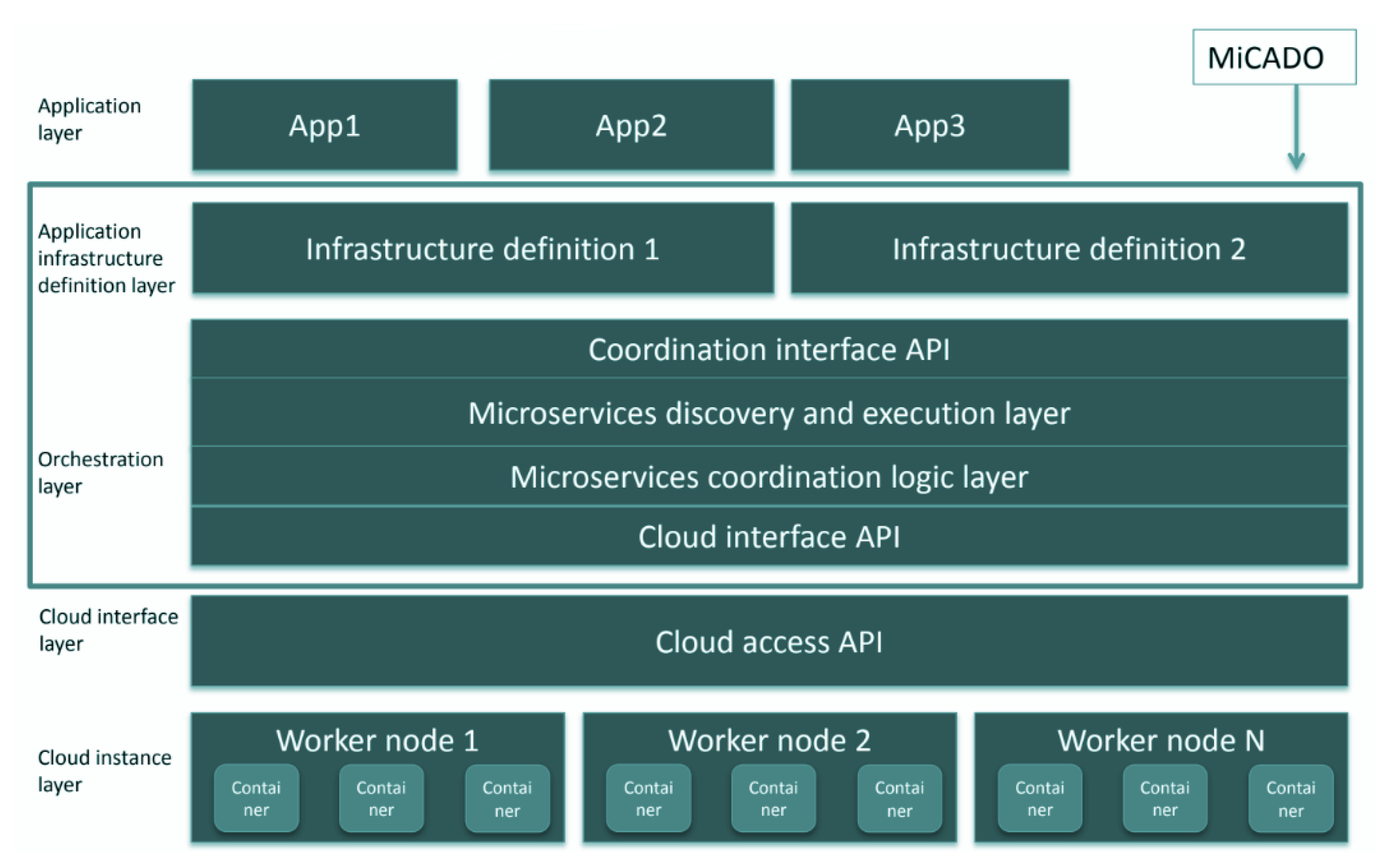
- Visti, H.; Kiss, T.; Terstyanszky, G.; Gesmier, G.; Winter, S. MiCADO-Towards a Microservice-Based Cloud Application-Level Dynamic Orchestrator. In Proceedings of the 8th International Workshop on Science Gateways, IWSG 2016, CEUR Workshop Proceedings, Rome, Italy, 8–19 June 2017; pp. 1–7. [Google Scholar]
- Kiss, T.; Kacsuk, P.; Kovacs, J.; Rakoczi, B.; Hajnal, A.; Farkas, A.; Gesmier, G.; Terstyanszky, G. MiCADO—Microservice-Based Cloud Application-Level Dynamic Orchestrator. Future Gener. Comput. Syst. 2019, 94, 937–946. [Google Scholar] [CrossRef]
- Kiss, T.; DesLauriers, J.; Gesmier, G.; Terstyanszky, G.; Pierantoni, G.; Oun, O.A.; Taylor, S.J.E.; Anagnostou, A.; Kovacs, J. A Cloud-Agnostic Queuing System to Support the Implementation of Deadline-Based Application Execution Policies. Future Gener. Comput. Syst. 2019, 101, 99–111. [Google Scholar] [CrossRef]
- Kovács, J. Supporting Programmable Autoscaling Rules for Containers and Virtual Machines on Clouds. J. Grid Comput. 2019, 17, 813–829. [Google Scholar] [CrossRef] [Green Version]
- Nadgowda, S.; Suneja, S.; Bila, N.; Isci, C. Voyager: Complete Container State Migration. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 2137–2142. [Google Scholar]
- Ding, Z.; Tian, Y.C.; Tang, M.; Li, Y.; Wang, Y.G.; Zhou, C. Profile-Guided Three-Phase Virtual Resource Management for Energy Efficiency of Data Centers. IEEE Trans. Ind. Electron. 2020, 67, 2460–2468. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R.; Li, Z.; Wu, C. An Efficient Online Placement Scheme for Cloud Container Clusters. IEEE J. Sel. Areas Commun. 2019, 37, 1046–1058. [Google Scholar] [CrossRef]
- Tan, B.; Ma, H.; Mei, Y. Novel Genetic Algorithm with Dual Chromosome Representation for Resource Allocation in Container-Based Clouds. In Proceedings of the IEEE International Conference on Cloud Computing, CLOUD, Milan, Italy, 8–13 July 2019; Volume 2019, pp. 452–456. [Google Scholar]
- Boxiong, T.; Hui, M.; Yi, M. A NSGA-II-Based Approach for Service Resource Allocation in Cloud. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), San Sebastian, Spain, 5–8 June 2017; pp. 2574–2581. [Google Scholar]
- Rossi, F.; Nardelli, M.; Cardellini, V. Horizontal and Vertical Scaling of Container-Based Applications Using Reinforcement Learning. In Proceedings of the 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), Milan, Italy, 8–13 June 2019; Volume 2019, pp. 329–338. [Google Scholar]
- With Help from AI, Microservices Divvy up Tasks to Improve Cloud Apps | Cornell Chronicle. Available online: https://news.cornell.edu/stories/2019/03/help-ai-microservices-divvy-tasks-improve-cloud-apps (accessed on 14 March 2022).
- Liu, H.; Zhang, J.; Shan, H.; Li, M.; Chen, Y.; He, X.; Li, X. JCallGraph: Tracing Microservices in Very Large Scale Container Cloud Platforms. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; Volume 11513, pp. 287–302. [Google Scholar]
- Dang-Quang, N.-M.; Yoo, M. An Efficient Multivariate Autoscaling Framework Using Bi-LSTM for Cloud Computing. Appl. Sci. 2022, 12, 3523. [Google Scholar] [CrossRef]
- Malik, S.; Tahir, M.; Sardaraz, M.; Alourani, A. A Resource Utilization Prediction Model for Cloud Data Centers Using Evolutionary Algorithms and Machine Learning Techniques. Appl. Sci. 2022, 12, 2160. [Google Scholar] [CrossRef]
- Malik, N.; Sardaraz, M.; Tahir, M.; Shah, B.; Ali, G.; Moreira, F. Energy-Efficient Load Balancing Algorithm for Workflow Scheduling in Cloud Data Centers Using Queuing and Thresholds. Appl. Sci. 2021, 11, 5849. [Google Scholar] [CrossRef]
- Calderón-Gómez, H.; Mendoza-Pittí, L.; Vargas-Lombardo, M.; Gómez-Pulido, J.M.; Rodríguez-Puyol, D.; Sención, G.; Polo-Luque, M.-L. Evaluating Service-Oriented and Microservice Architecture Patterns to Deploy EHealth Applications in Cloud Computing Environment. Appl. Sci. 2021, 11, 4350. [Google Scholar] [CrossRef]
- Górski, T.; Woźniak, A.P. Optimization of Business Process Execution in Services Architecture: A Systematic Literature Review. IEEE Access 2021, 9, 111833–111852. [Google Scholar] [CrossRef]
- Toosi, A.N.; Calheiros, R.N.; Buyya, R. Interconnected Cloud Computing Environments: Challenges, Taxonomy, and Survey. ACM Comput. Surv. 2014, 47, 1–47. [Google Scholar] [CrossRef]
- Hemmat, R.A.; Hafid, A. SLA Violation Prediction in Cloud Computing: A Machine Learning Perspective. arXiv 2016, arXiv:1611.10338. [Google Scholar] [CrossRef]
- Vasudevan, M.; Tian, Y.-C.; Tang, M.; Kozan, E.; Zhang, X. Energy-Efficient Application Assignment in Profile-Based Data Center Management through a Repairing Genetic Algorithm. Appl. Soft Comput. 2018, 67, 399–408. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Breslow, A.; Mars, J.; Tang, L. Bubble-Flux: Precise Online QoS Management for Increased Utilization in Warehouse Scale Computers. ACM SIGARCH Comput. Archit. News 2013, 41, 607–618. [Google Scholar] [CrossRef]
- Qureshi, B. Profile-Based Power-Aware Workflow Scheduling Framework for Energy-Efficient Data Centers. Future Gener. Comput. Syst. 2019, 94, 453–467. [Google Scholar] [CrossRef]
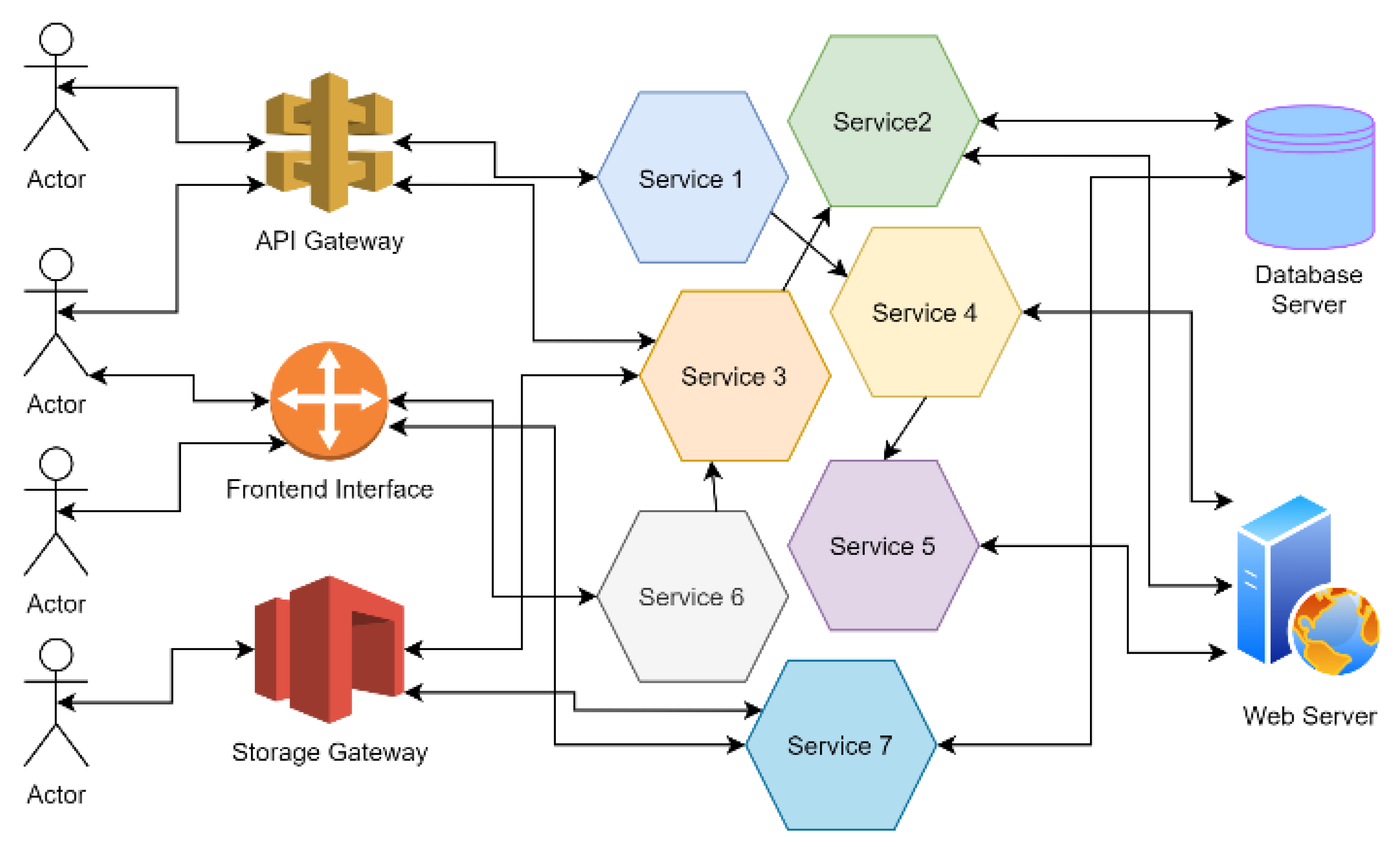
- Yu, Y.; Yang, J.; Guo, C.; Zheng, H.; He, J. Joint Optimization of Service Request Routing and Instance Placement in the Microservice System. J. Netw. Comput. Appl. 2019, 147, 102441. [Google Scholar] [CrossRef]
- Mekala, M.S.; Viswanathan, P. Energy-Efficient Virtual Machine Selection Based on Resource Ranking and Utilization Factor Approach in Cloud Computing for IoT. Comput. Electr. Eng. 2019, 73, 227–244. [Google Scholar] [CrossRef]
- Rossi, F.; Cardellini, V.; Lo Presti, F.; Nardelli, M. Geo-Distributed Efficient Deployment of Containers with Kubernetes. Comput. Commun. 2020, 159, 161–174. [Google Scholar] [CrossRef]
- Chen, F.; Grundy, J.; Yang, Y.; Schneider, J.-G.; He, Q. Experimental Analysis of Task-Based Energy Consumption in Cloud Computing Systems. In Proceedings of the ACM/SPEC International Conference on International Conference on Performance Engineering—ICPE ’13, Prague, Czech Republic, 21–24 April 2013; ACM Press: New York, NY, USA, 2013; pp. 295–306. [Google Scholar]
- Chen, F.; Grundy, J.; Schneider, J.-G.; Yang, Y.; He, Q. Automated Analysis of Performance and Energy Consumption for Cloud Applications. In Proceedings of the 5th ACM/SPEC International Conference on Performance Engineering, Dublin, Ireland, 22–26 March 2014; ACM: New York, NY, USA, 2014; pp. 39–50. [Google Scholar]
- Cambronero, M.E.; Bernal, A.; Valero, V.; Cañizares, P.C.; Núñez, A. Profiling SLAs for Cloud System Infrastructures and User Interactions. PeerJ Comput. Sci. 2021, 7, e513. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yu, H.; Fan, G.; Chen, L. Reliability Modelling and Optimization for Microservice-based Cloud Application Using Multi-agent System. IET Commun. 2022, 1–18. [Google Scholar] [CrossRef]
- Khan, A. Key Characteristics of a Container Orchestration Platform to Enable a Modern Application. IEEE Cloud Comput. 2017, 4, 42–48. [Google Scholar] [CrossRef]
- Wolke, A.; Bichler, M.; Setzer, T. Planning vs. Dynamic Control: Resource Allocation in Corporate Clouds. IEEE Trans. Cloud Comput. 2016, 4, 322–335. [Google Scholar] [CrossRef] [Green Version]
- Morikawa, T.; Kourai, K. Low-Cost and Fast Failure Recovery Using In-VM Containers in Clouds. In Proceedings of the 2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 572–579. [Google Scholar]
- Assuncao, W.K.G.; Colanzi, T.E.; Carvalho, L.; Pereira, J.A.; Garcia, A.; de Lima, M.J.; Lucena, C. A Multi-Criteria Strategy for Redesigning Legacy Features as Microservices: An Industrial Case Study. In Proceedings of the 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 9–12 March 2021; pp. 377–387. [Google Scholar]
- Saboor, A.; Mahmood, A.K.; Hassan, M.F.; Shah, S.N.M.; Hassan, F.; Siddiqui, M.A. Design Pattern Based Distribution of Microservices in Cloud Computing Environment. In Proceedings of the International Conference on Computer & Information Sciences (ICCOINS), Kuching, Malaysia, 13–15 July 2021; pp. 396–400. [Google Scholar]
- Saboor, A.; Mahmood, A.K.; Omar, A.H.; Hassan, M.F.; Shah, S.N.M.; Ahmadian, A. Enabling Rank-Based Distribution of Microservices among Containers for Green Cloud Computing Environment. Peer-to-Peer Netw. Appl. 2022, 15, 77–91. [Google Scholar] [CrossRef]
- Piraghaj, S.F.; Dastjerdi, A.V.; Calheiros, R.N.; Buyya, R. ContainerCloudSim: An Environment for Modeling and Simulation of Containers in Cloud Data Centers. Softw. Pract. Exp. 2017, 47, 505–521. [Google Scholar] [CrossRef]
- Gan, Y.; Zhang, Y.; Cheng, D.; Shetty, A.; Rathi, P.; Katarki, N.; Bruno, A.; Hu, J.; Ritchken, B.; Jackson, B.; et al. An Open-Source Benchmark Suite for Microservices and Their Hardware-Software Implications for Cloud & Edge Systems. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Providence, RI, USA, 13–17 April 2019; ACM: New York, NY, USA, 2019; pp. 3–18. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saboor, A.; Hassan, M.F.; Akbar, R.; Shah, S.N.M.; Hassan, F.; Magsi, S.A.; Siddiqui, M.A. Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives. Appl. Sci. 2022, 12, 5793. https://doi.org/10.3390/app12125793
Saboor A, Hassan MF, Akbar R, Shah SNM, Hassan F, Magsi SA, Siddiqui MA. Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives. Applied Sciences. 2022; 12(12):5793. https://doi.org/10.3390/app12125793
Chicago/Turabian StyleSaboor, Abdul, Mohd Fadzil Hassan, Rehan Akbar, Syed Nasir Mehmood Shah, Farrukh Hassan, Saeed Ahmed Magsi, and Muhammad Aadil Siddiqui. 2022. "Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives" Applied Sciences 12, no. 12: 5793. https://doi.org/10.3390/app12125793
APA StyleSaboor, A., Hassan, M. F., Akbar, R., Shah, S. N. M., Hassan, F., Magsi, S. A., & Siddiqui, M. A. (2022). Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives. Applied Sciences, 12(12), 5793. https://doi.org/10.3390/app12125793