
Empirical Analysis of Parallel Corpora and In-Depth Analysis Using LIWC

 , , and
, , and
Abstract
:1. Introduction
- For the first time, we conduct a deep data analysis on AI Hub data. To the best of our knowledge, this is the first time LIWC has been used to analyze corpora. This study acts as a milestone for further studies on NMT with respect to the Korean language.
- We conduct baseline translation experiments on all the data in the AI Hub parallel corpus. Our experiments provide a foundation for further research on Korean-based NMT.
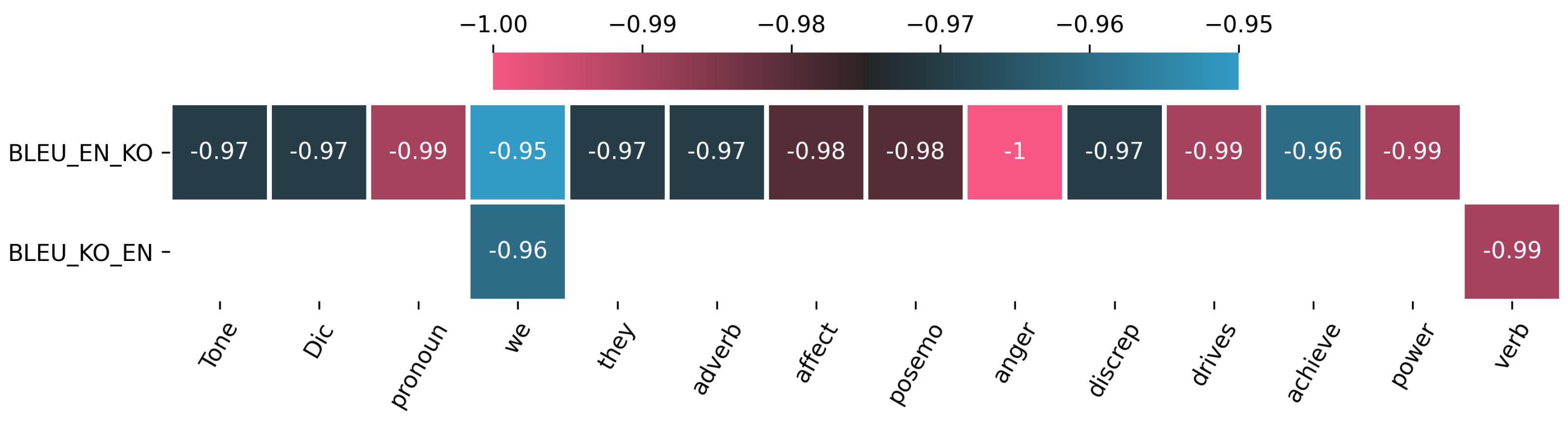
- We discovered that many factors might cause decreasing model performance, and we provide the direction that those factors could be filtered through our correlation analysis between LIWC and model performance.
2. Related Works and Background
2.1. Machine Translation
2.2. AI Hub
2.3. Parallel Corpus Quality Assessment
2.4. Korean Neural Machine Translation Research
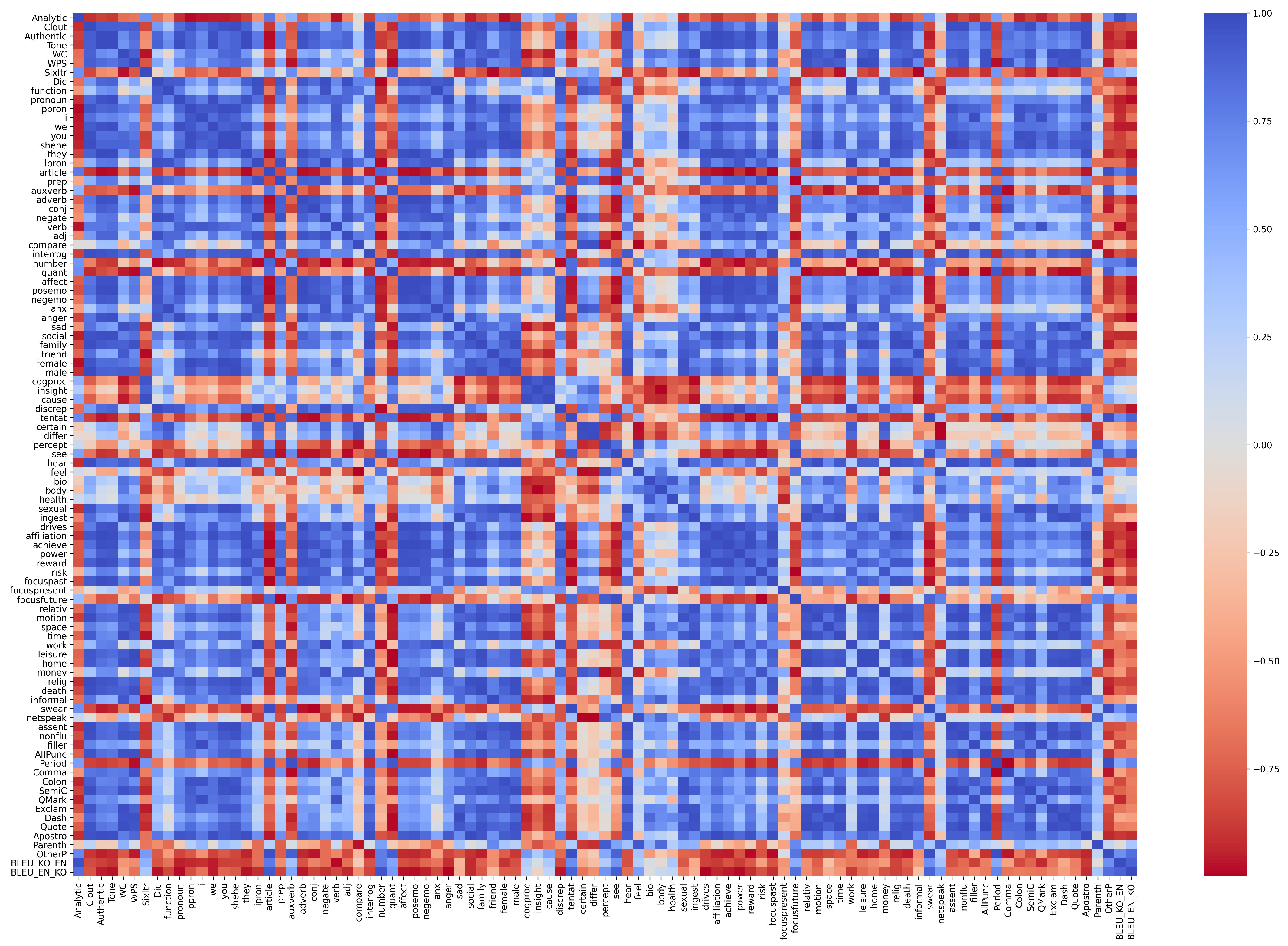
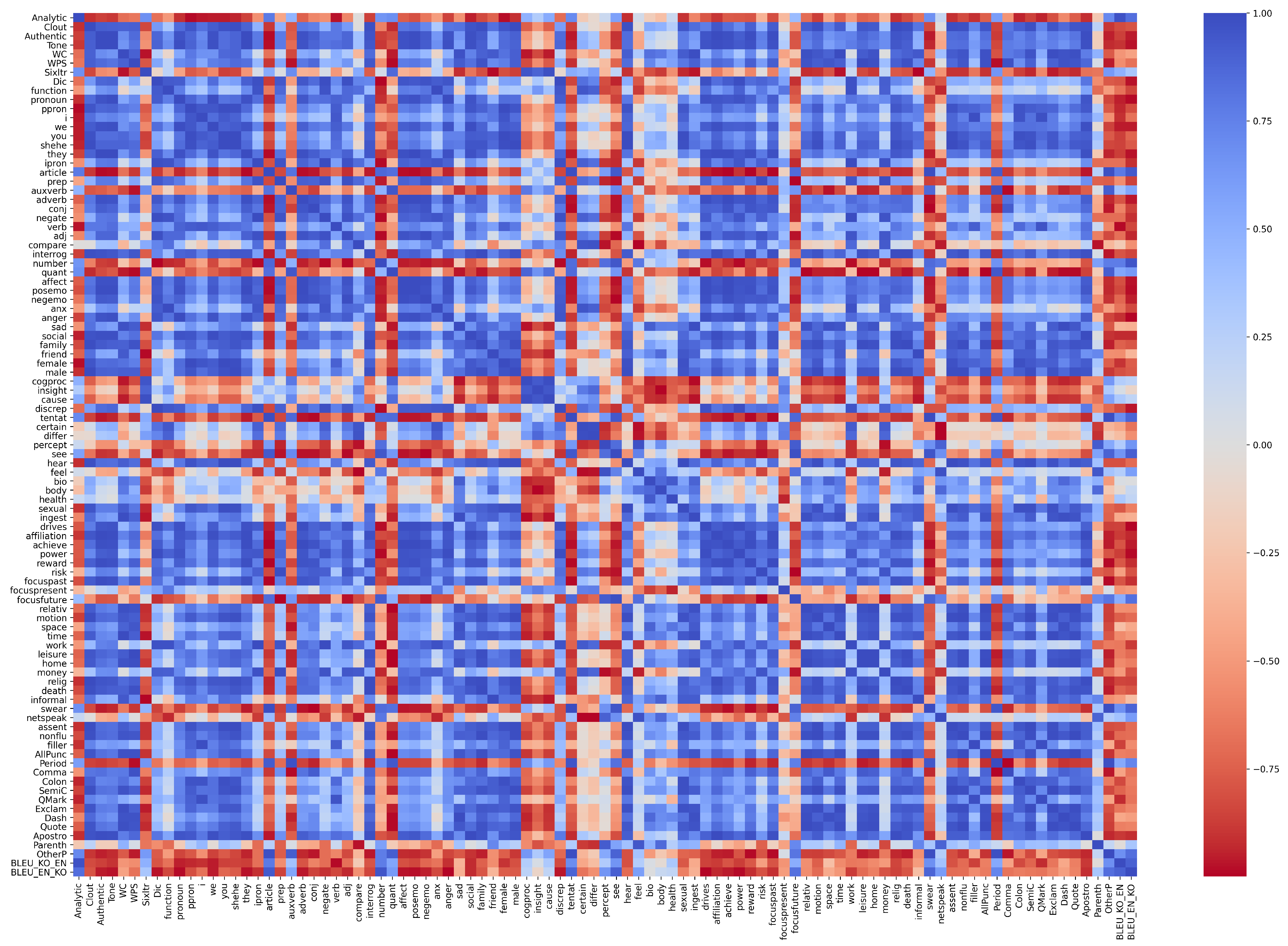
3. Analyzing the AI Hub Corpus Using LIWC
3.1. Linguistic Inquiry and Word Count (LIWC)
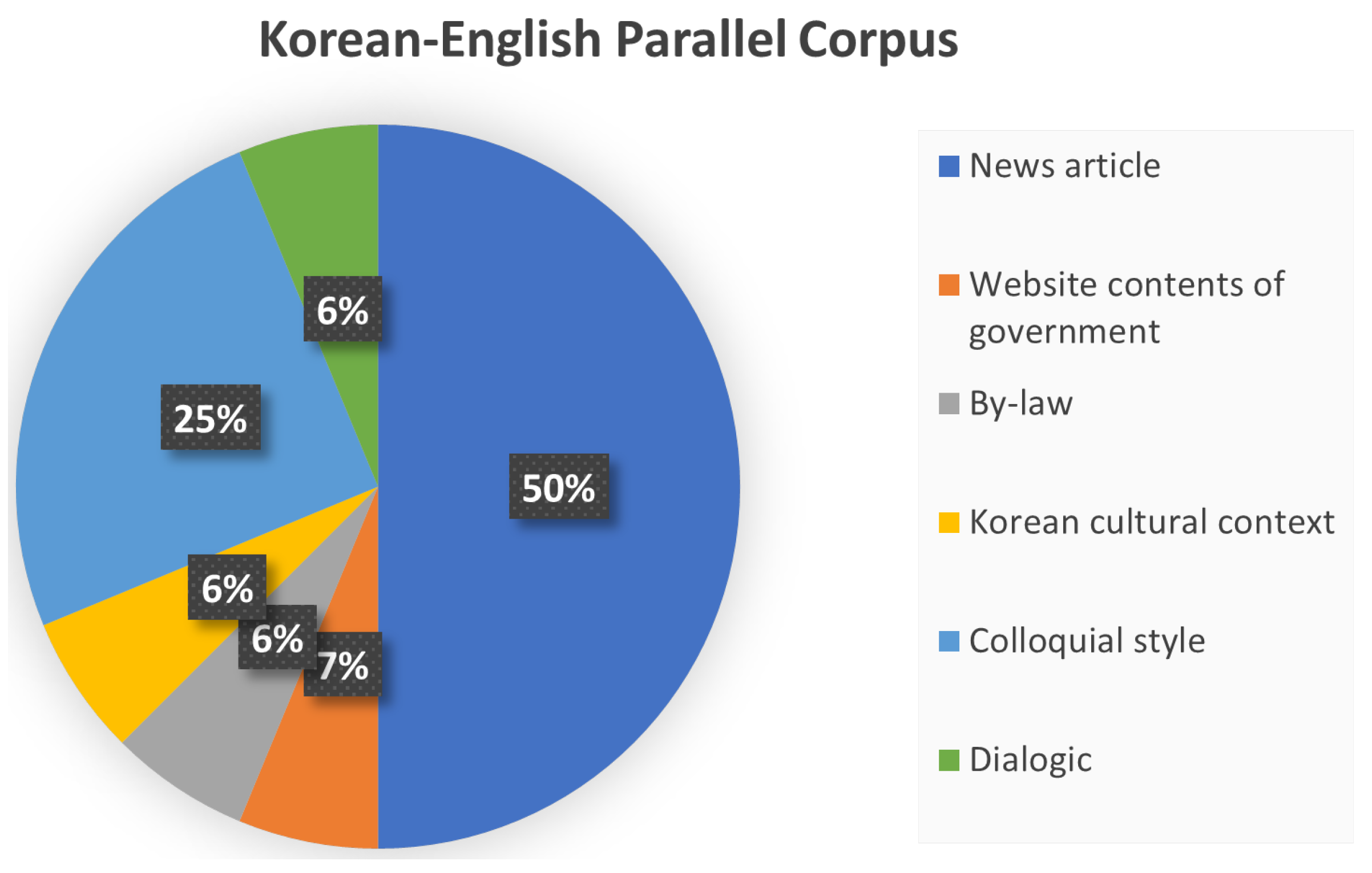
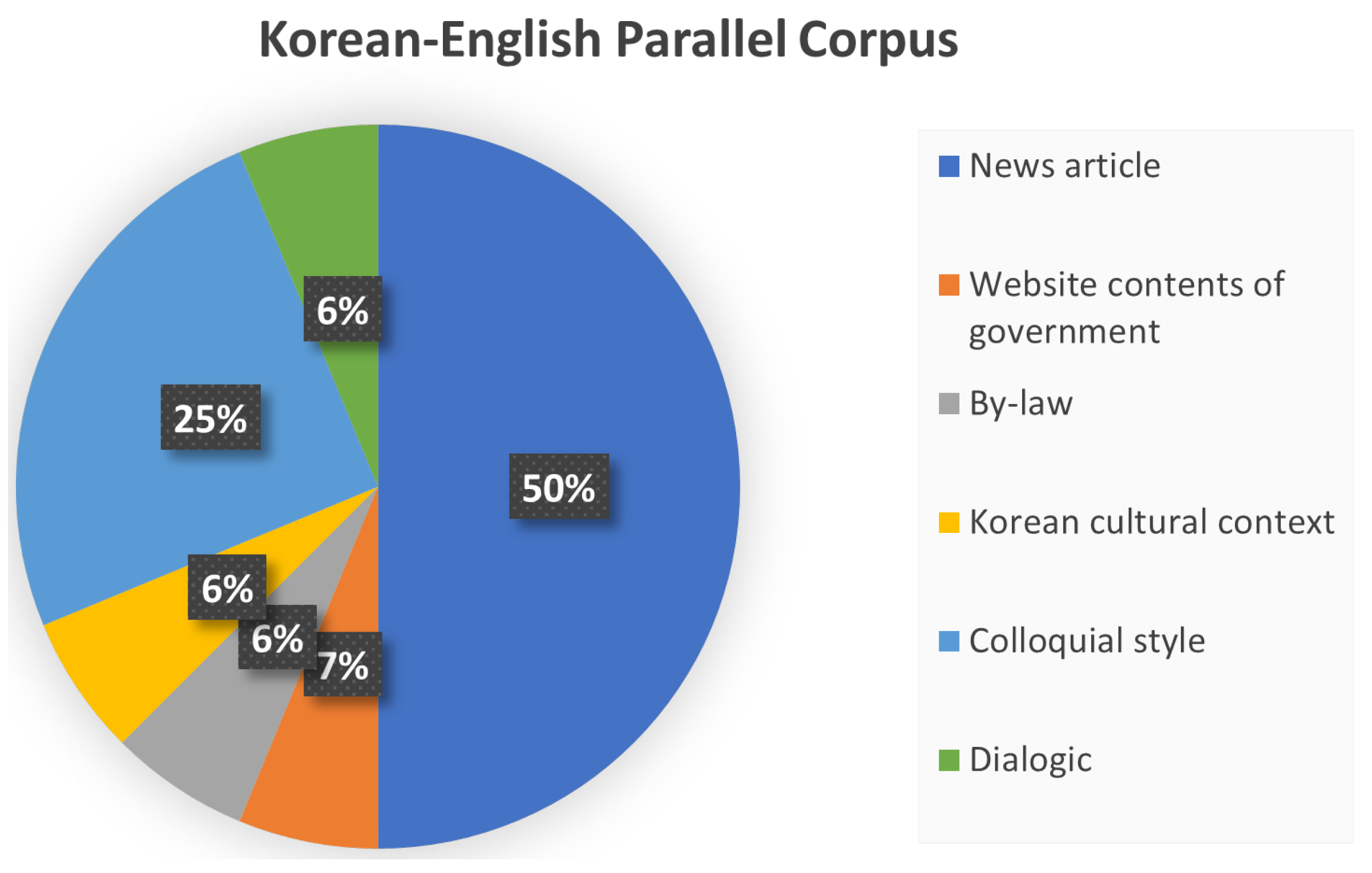
3.2. Korean–English Parallel Corpus
3.3. Korean–English Domain-Specialized Parallel Corpus
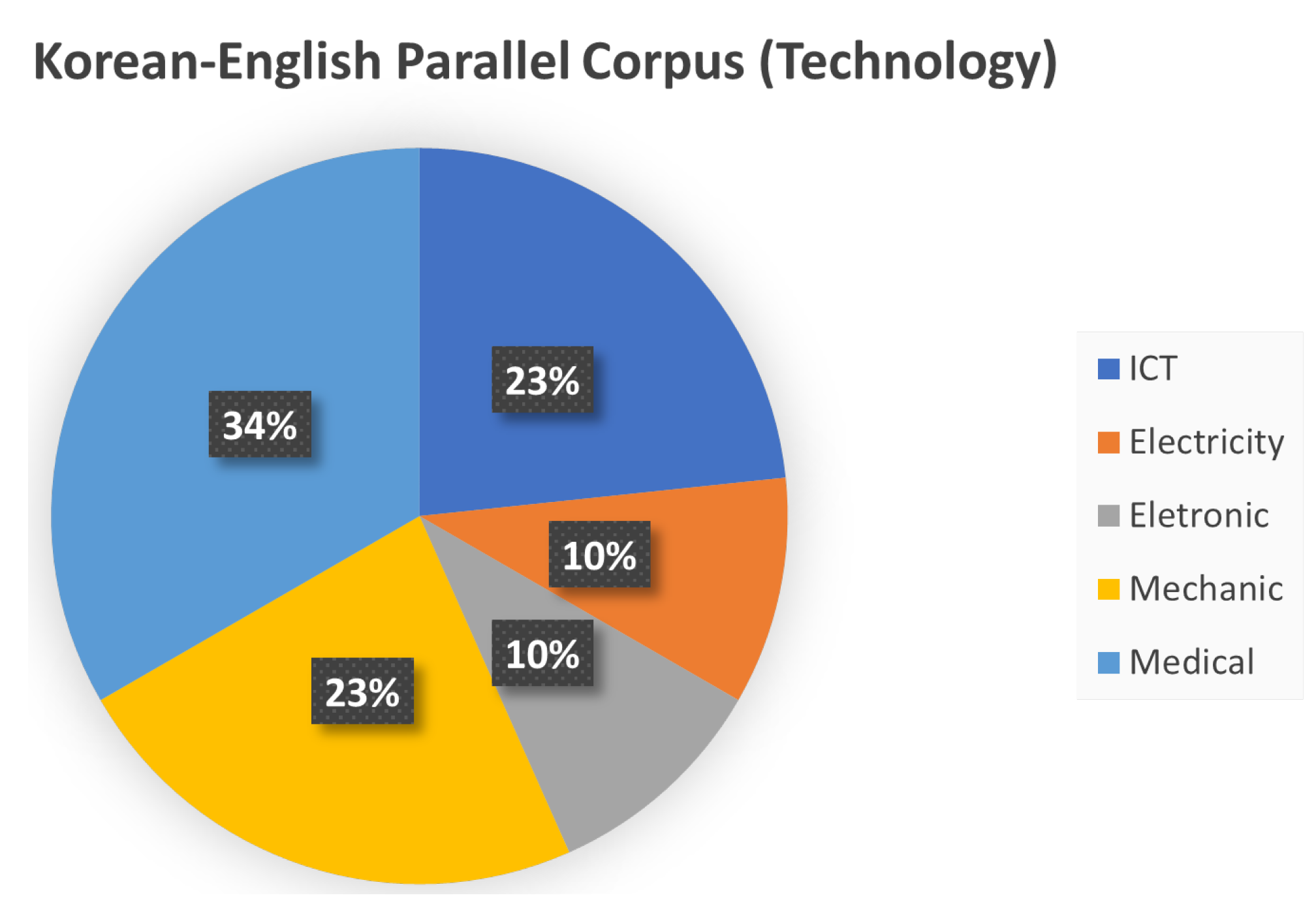
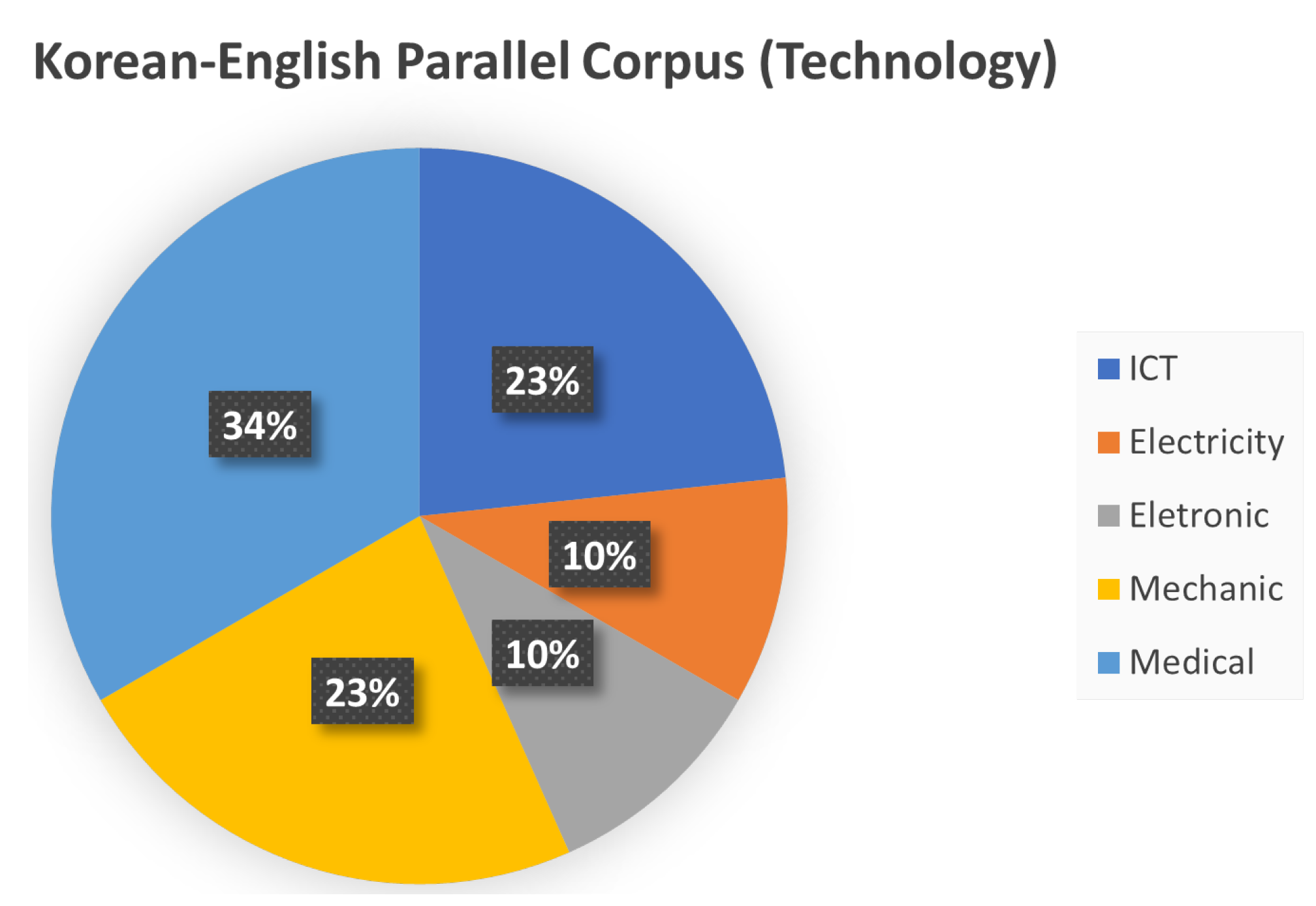
3.4. Korean–English Parallel Corpus (Technology)
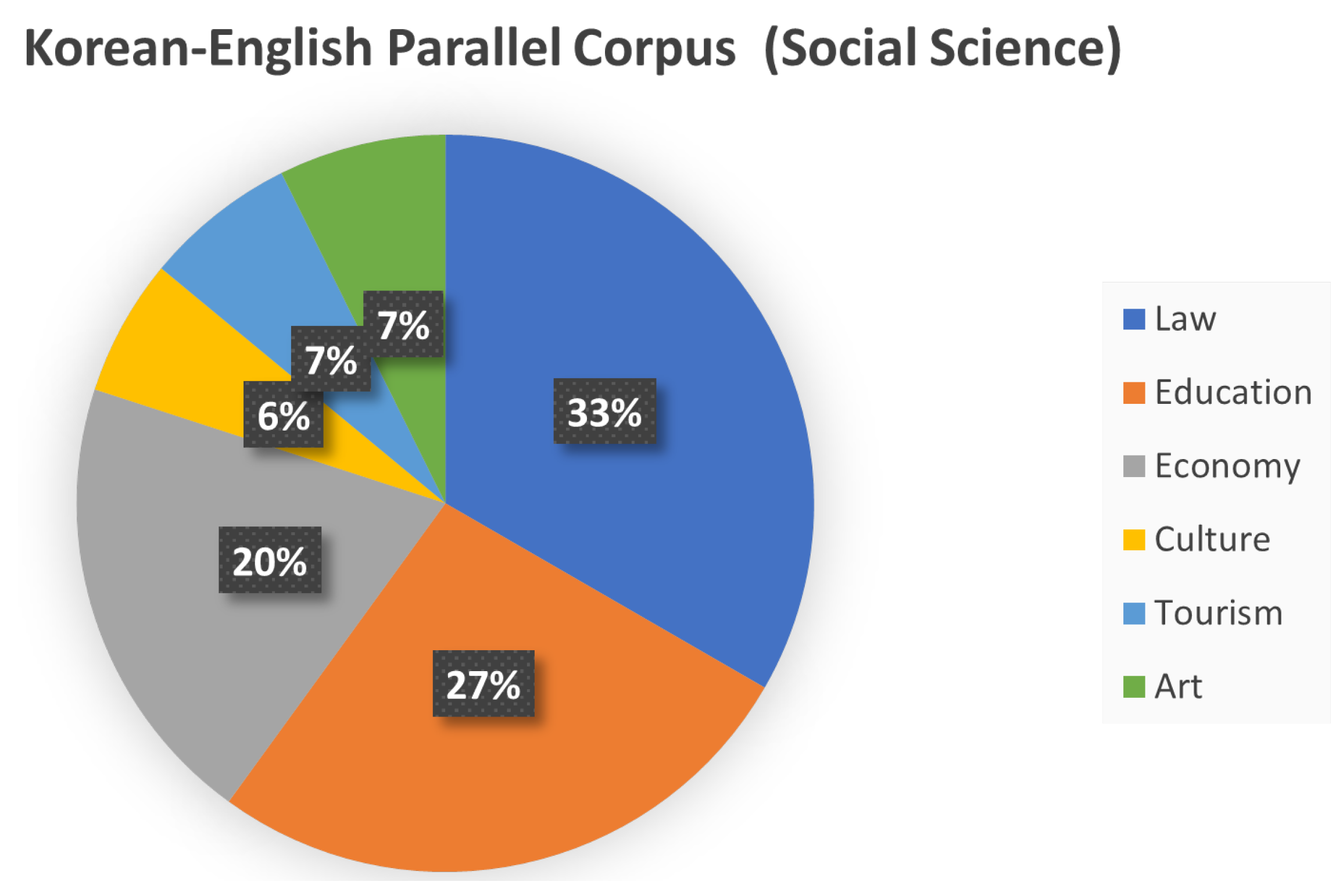
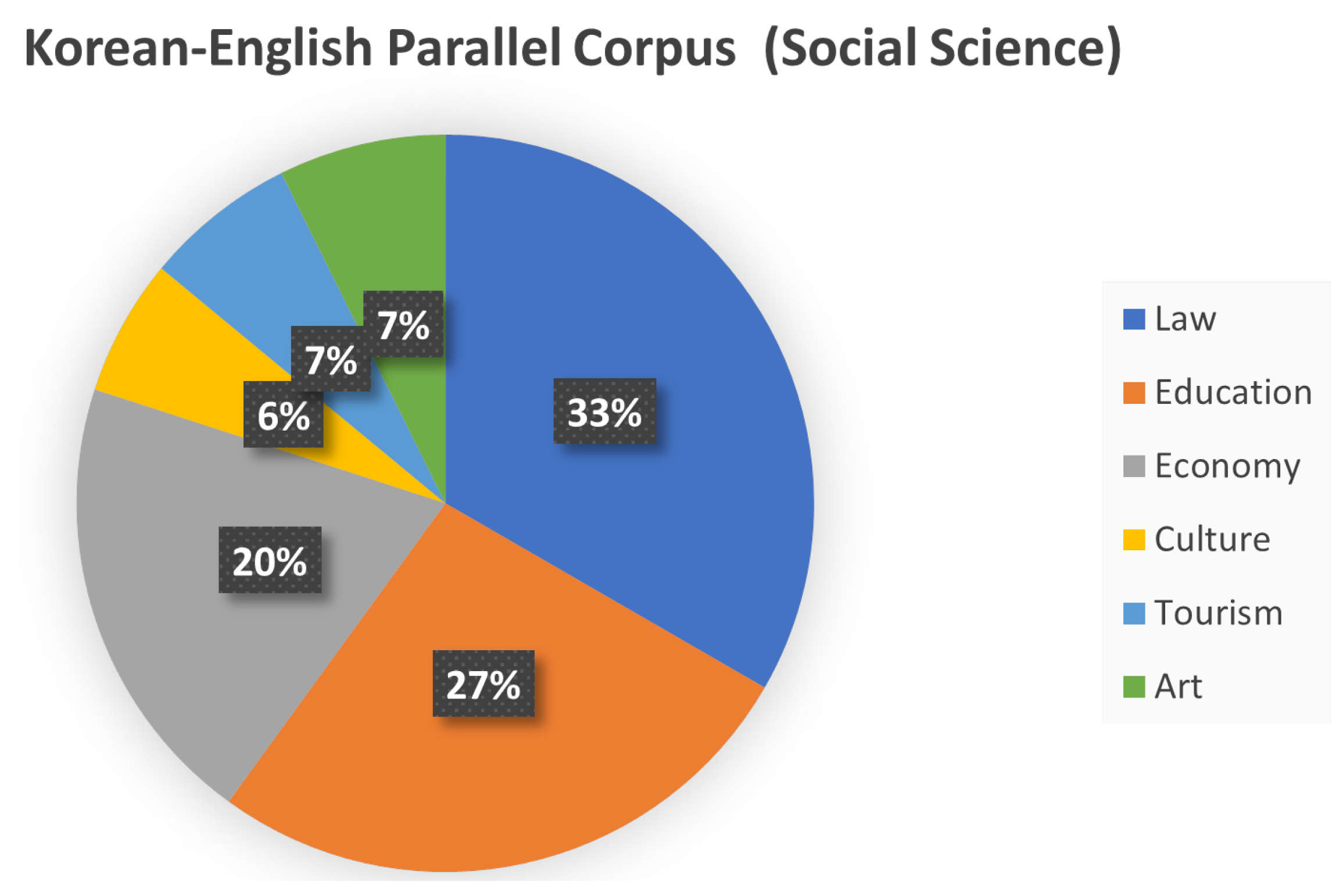
3.5. Korean–English Parallel Corpus (Social Science)
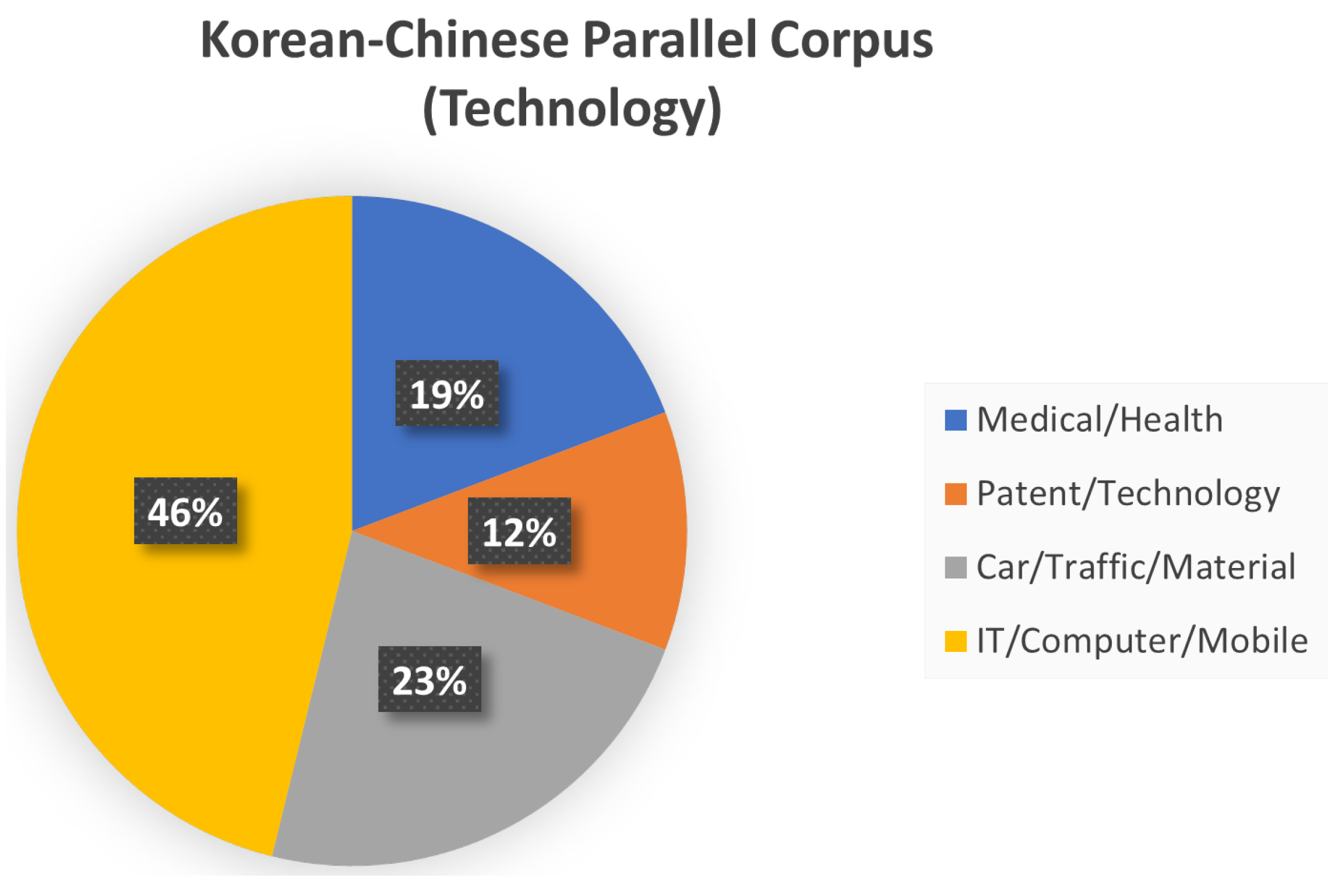
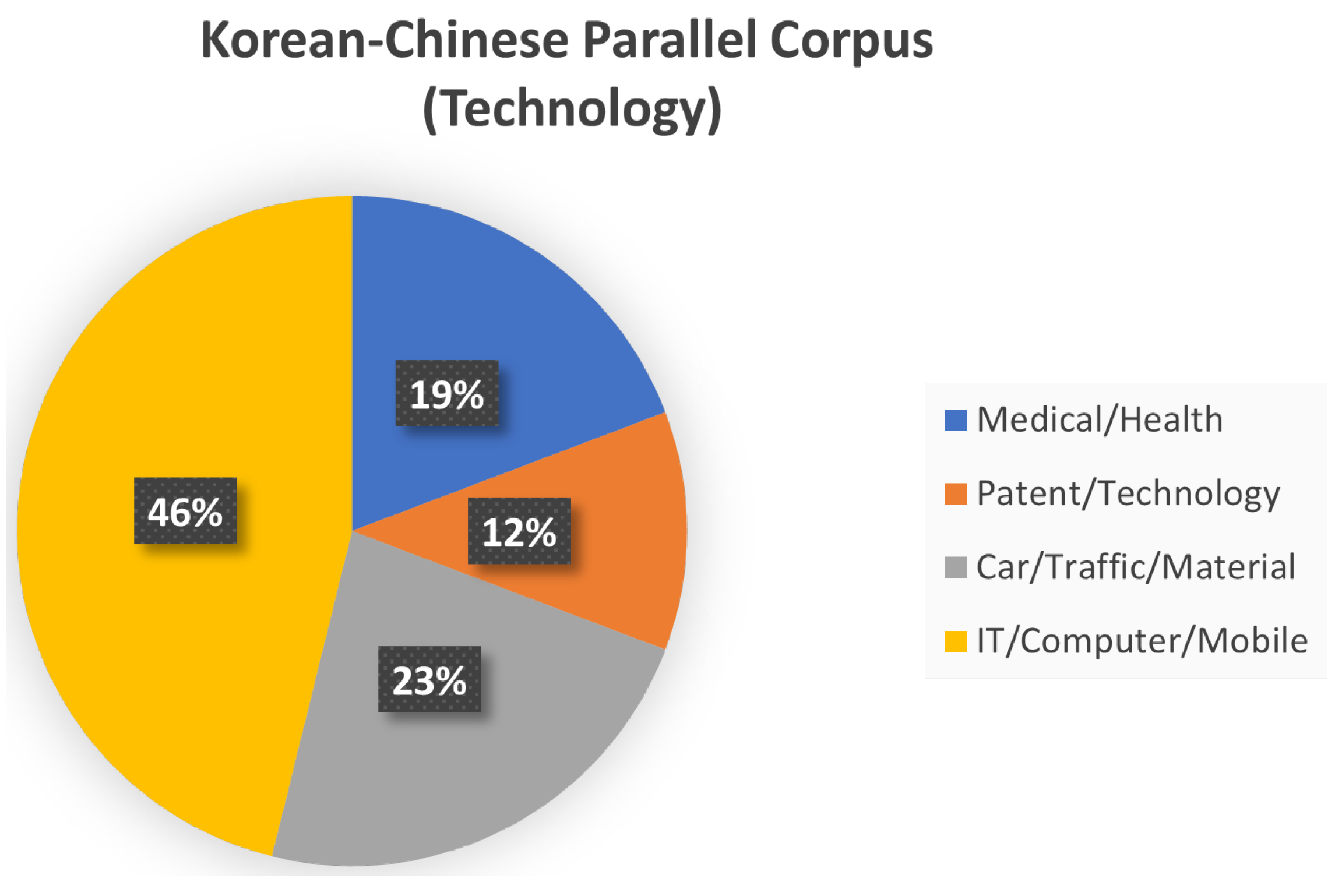
3.6. Korean–Chinese Parallel Corpus (Technology)
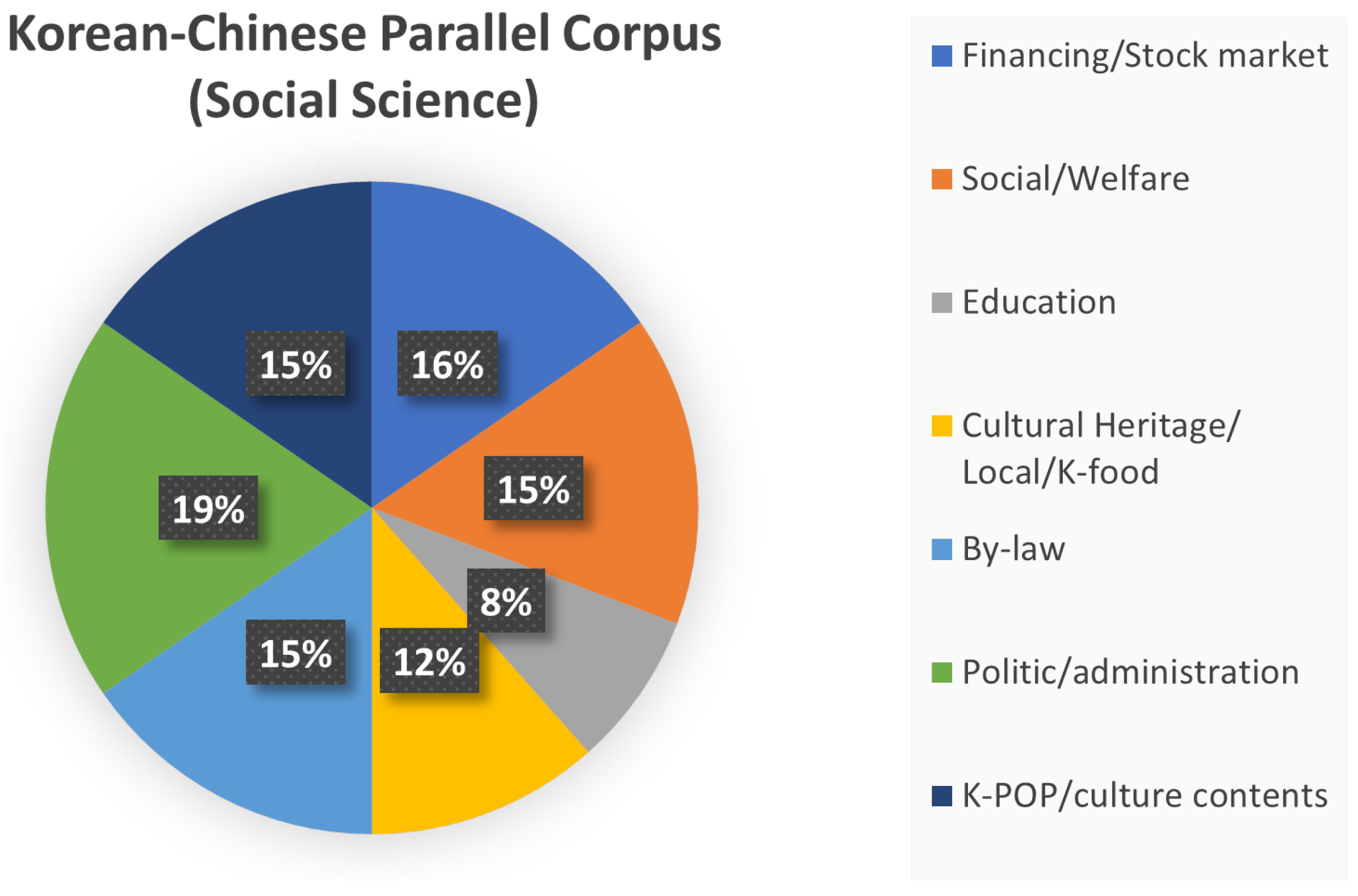
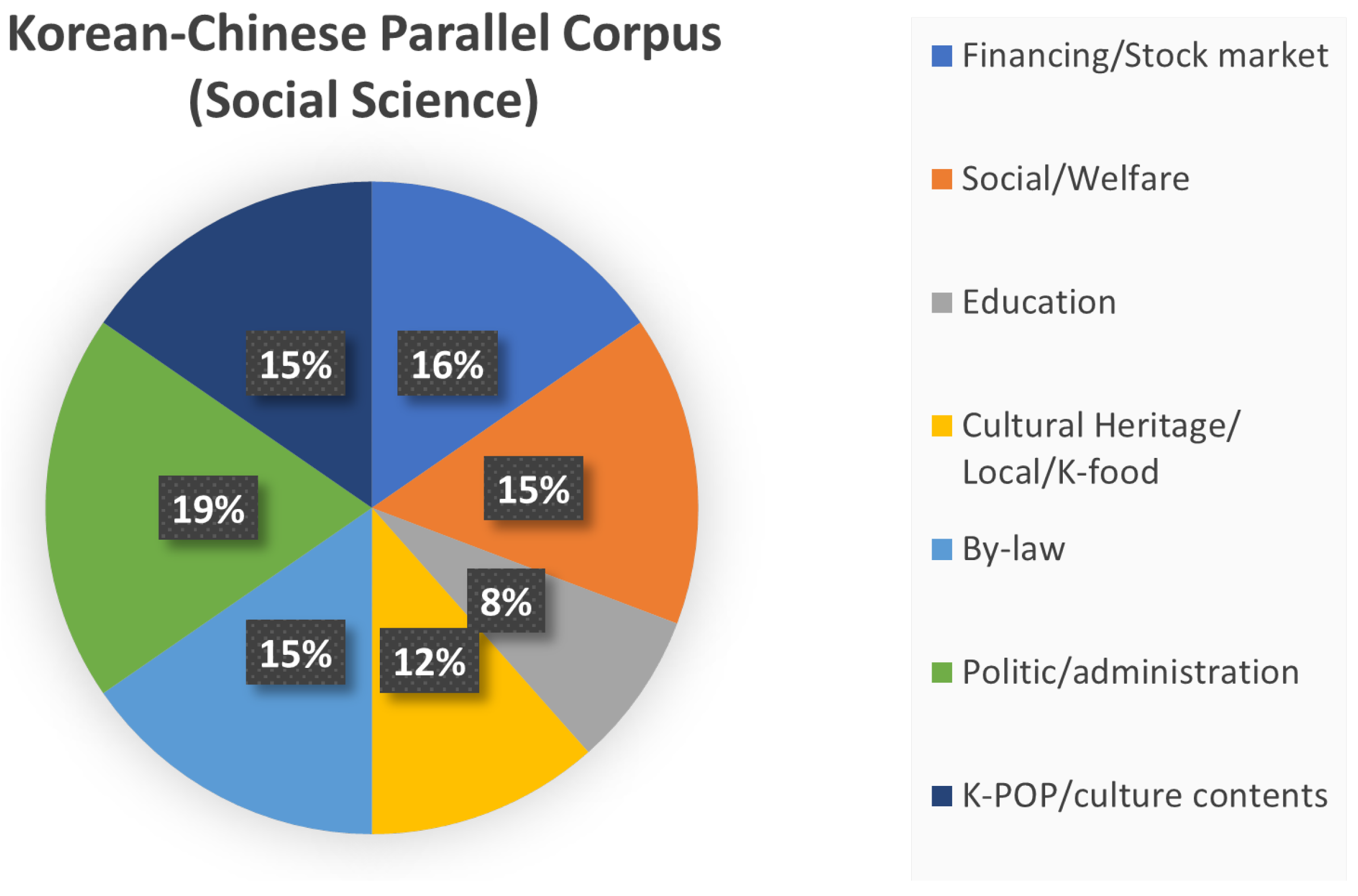
3.7. Korean–Chinese Parallel Corpus (Social Science)
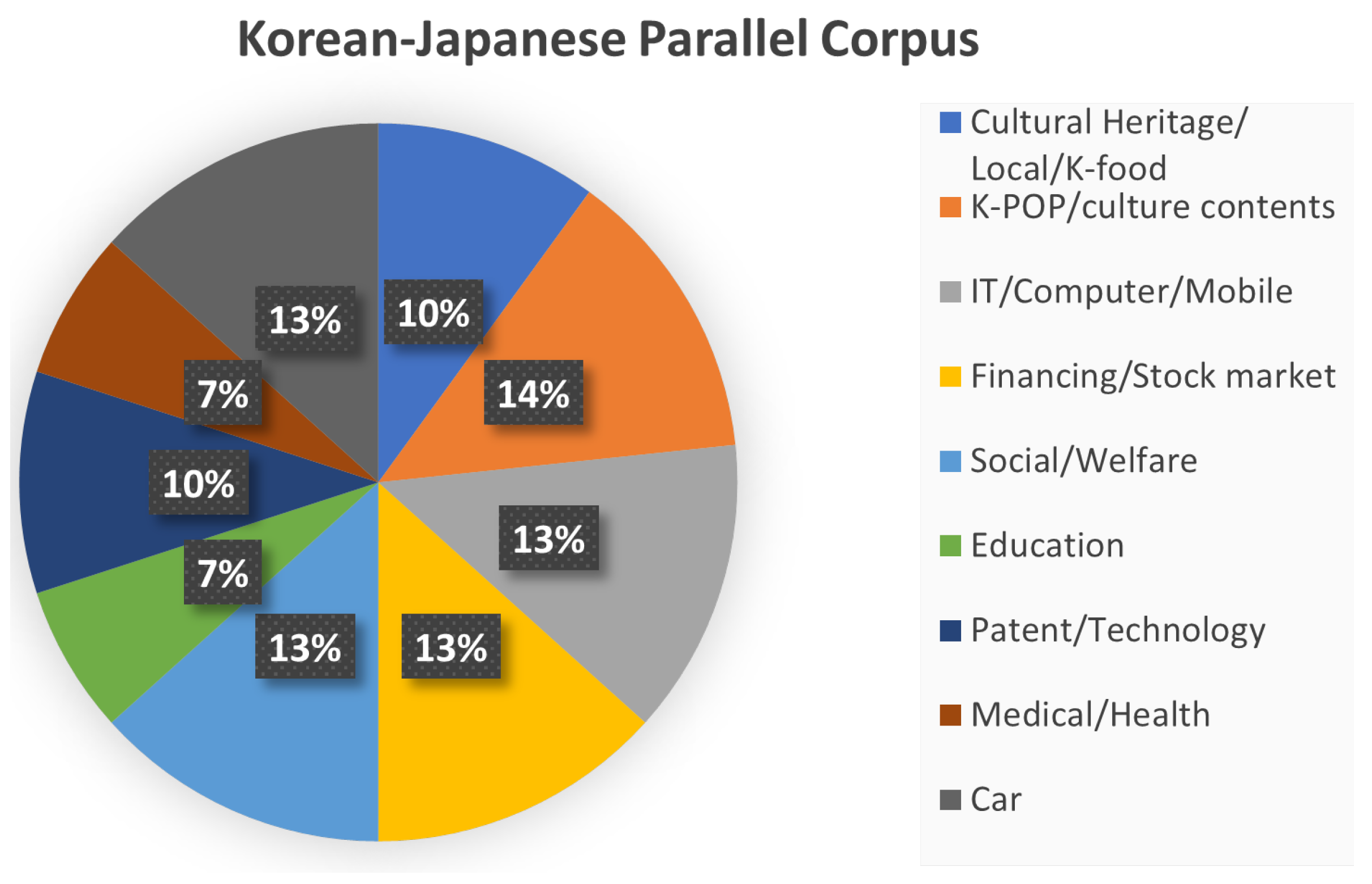
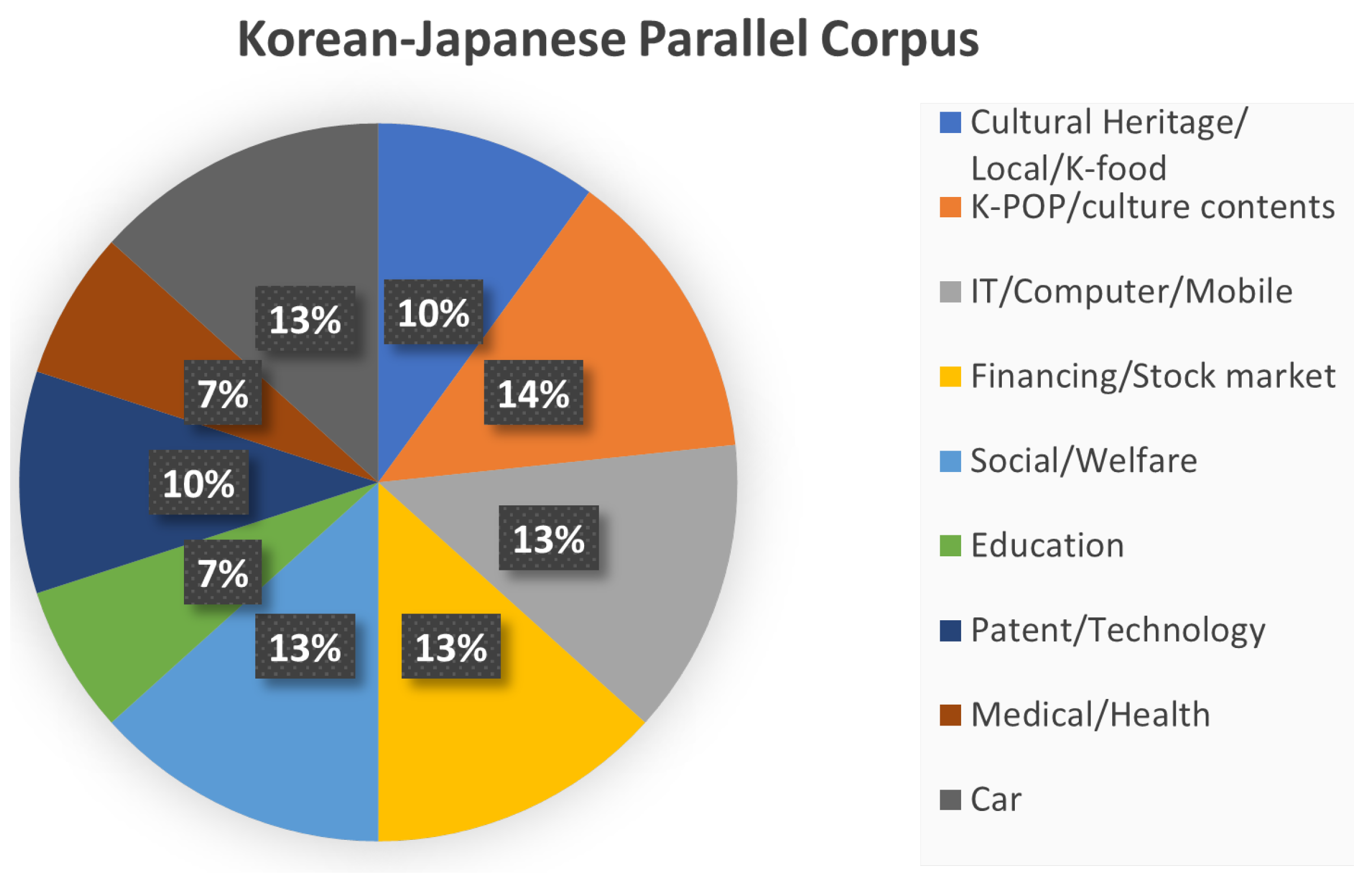
3.8. Korean–Japanese Parallel Corpus
4. Experiments and Results
4.1. Dataset Details
4.2. Models Detail
4.3. Main Results
5. Discussion and Positive Impact of This Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vieira, L.N.; O’Hagan, M.; O’Sullivan, C. Understanding the societal impacts of machine translation: A critical review of the literature on medical and legal use cases. Inf. Commun. Soc. 2021, 24, 1515–1532. [Google Scholar] [CrossRef]
- Zheng, W.; Wang, W.; Liu, D.; Zhang, C.; Zeng, Q.; Deng, Y.; Yang, W.; He, P.; Xie, T. Testing untestable neural machine translation: An industrial case. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montreal, QC, Canada, 25–31 May 2019; pp. 314–315. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. Mass: Masked sequence to sequence pre-training for language generation. arXiv 2019, arXiv:1905.02450. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Park, C.; Oh, Y.; Choi, J.; Kim, D.; Lim, H. Toward High Quality Parallel Corpus Using Monolingual Corpus. In Proceedings of the 10th International Conference on Convergence Technology (ICCT 2020), Jeju Island, Korea, 21–23 October 2020; Volume 10, pp. 146–147. [Google Scholar]
- Park, C.; Park, K.; Moon, H.; Eo, S.; Lim, H. A study on performance improvement considering the balance between corpus in Neural Machine Translation. J. Korea Converg. Soc. 2021, 12, 23–29. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding back-translation at scale. arXiv 2018, arXiv:1808.09381. [Google Scholar]
- Currey, A.; Miceli-Barone, A.V.; Heafield, K. Copied monolingual data improves low-resource neural machine translation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 148–156. [Google Scholar]
- Burlot, F.; Yvon, F. Using monolingual data in neural machine translation: A systematic study. arXiv 2019, arXiv:1903.11437. [Google Scholar]
- Epaliyana, K.; Ranathunga, S.; Jayasena, S. Improving Back-Translation with Iterative Filtering and Data Selection for Sinhala-English NMT. In Proceedings of the 2021 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 27–29 July 2021; pp. 438–443. [Google Scholar]
- Imankulova, A.; Sato, T.; Komachi, M. Improving low-resource neural machine translation with filtered pseudo-parallel corpus. In Proceedings of the 4th Workshop on Asian Translation (WAT2017), Taipei, Taiwan, 27 November–1 December 2017; pp. 70–78. [Google Scholar]
- Koehn, P.; Guzmán, F.; Chaudhary, V.; Pino, J. Findings of the WMT 2019 shared task on parallel corpus filtering for low-resource conditions. In Proceedings of the Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2), Florence, Italy, 1–2 August 2019; pp. 54–72. [Google Scholar]
- Park, C.; Lee, Y.; Lee, C.; Lim, H. Quality, not quantity?: Effect of parallel corpus quantity and quality on neural machine translation. In Proceedings of the 32st Annual Conference on Human Cognitive Language Technology (HCLT2020), Online, 15–16 October 2020; pp. 363–368. [Google Scholar]
- Khayrallah, H.; Koehn, P. On the impact of various types of noise on neural machine translation. arXiv 2018, arXiv:1805.12282. [Google Scholar]
- Koehn, P.; Chaudhary, V.; El-Kishky, A.; Goyal, N.; Chen, P.J.; Guzmán, F. Findings of the WMT 2020 Shared Task on Parallel Corpus Filtering and Alignment. In Proceedings of the Fifth Conference on Machine Translation, Association for Computational Linguistics, Online, 19–20 November 2020; pp. 726–742. [Google Scholar]
- Park, C.; Lim, H. A Study on the Performance Improvement of Machine Translation Using Public Korean–English Parallel Corpus. J. Digit. Converg. 2020, 18, 271–277. [Google Scholar]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Holtzman, N.S.; Tackman, A.M.; Carey, A.L.; Brucks, M.S.; Küfner, A.C.; Deters, F.G.; Back, M.D.; Donnellan, M.B.; Pennebaker, J.W.; Sherman, R.A.; et al. Linguistic markers of grandiose narcissism: A LIWC analysis of 15 samples. J. Lang. Soc. Psychol. 2019, 38, 773–786. [Google Scholar] [CrossRef] [Green Version]
- Bae, Y.J.; Shim, M.; Lee, W.H. Schizophrenia Detection Using Machine Learning Approach from Social Media Content. Sensors 2021, 21, 5924. [Google Scholar] [CrossRef]
- Sekulić, I.; Gjurković, M.; Šnajder, J. Not Just Depressed: Bipolar Disorder Prediction on Reddit. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 72–78. [Google Scholar]
- Kasher, A. Language in Focus: Foundations, Methods and Systems: Essays in Memory of Yehoshua Bar-Hillel; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 43. [Google Scholar]
- Dugast, L.; Senellart, J.; Koehn, P. Statistical Post-Editing on SYSTRAN’s Rule-Based Translation System. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; pp. 220–223. [Google Scholar]
- Forcada, M.L.; Ginestí-Rosell, M.; Nordfalk, J.; O’Regan, J.; Ortiz-Rojas, S.; Pérez-Ortiz, J.A.; Sánchez-Martínez, F.; Ramírez-Sánchez, G.; Tyers, F.M. Apertium: A free/open-source platform for rule-based machine translation. Mach. Transl. 2011, 25, 127–144. [Google Scholar] [CrossRef]
- Zens, R.; Och, F.J.; Ney, H. Phrase-based statistical machine translation. In Proceedings of the Annual Conference on Artificial Intelligence, Aachen, Germany, 16–20 September 2002; pp. 18–32. [Google Scholar]
- Koehn, P. Statistical Machine Translation; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, USA, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay less attention with lightweight and dynamic convolutions. arXiv 2019, arXiv:1901.10430. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual denoising pre-training for neural machine translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Schwab, K. The Fourth Industrial Revolution. Currency. 2017. Available online: https://www.weforum.org/about/the-fourth-industrial-revolution-by-klaus-schwab (accessed on 25 May 2022).
- Goyal, N.; Gao, C.; Chaudhary, V.; Chen, P.J.; Wenzek, G.; Ju, D.; Krishnan, S.; Ranzato, M.; Guzman, F.; Fan, A. The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation. arXiv 2021, arXiv:2106.03193. [Google Scholar] [CrossRef]
- Esplà-Gomis, M.; Forcada, M.L.; Ramírez-Sánchez, G.; Hoang, H. ParaCrawl: Web-scale parallel corpora for the languages of the EU. In Proceedings of the Machine Translation Summit XVII Volume 2: Translator, Project and User Tracks, Dublin, Ireland, 19–23 August 2019; pp. 118–119. [Google Scholar]
- Gale, W.A.; Church, K. A program for aligning sentences in bilingual corpora. Comput. Linguist. 1993, 19, 75–102. [Google Scholar]
- Simard, M.; Plamondon, P. Bilingual sentence alignment: Balancing robustness and accuracy. Mach. Transl. 1998, 13, 59–80. [Google Scholar] [CrossRef]
- Abdul-Rauf, S.; Fishel, M.; Lambert, P.; Noubours, S.; Sennrich, R. Extrinsic evaluation of sentence alignment systems. In Proceedings of the Workshop on Creating Cross-language Resources for Disconnected Languages and Styles, Istanbul, Turkey, 27 May 2012. [Google Scholar]
- Lee, H.G.; Kim, J.S.; Shin, J.H.; Lee, J.; Quan, Y.X.; Jeong, Y.S. papago: A machine translation service with word sense disambiguation and currency conversion. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; pp. 185–188. [Google Scholar]
- Park, C.; Eo, S.; Moon, H.; Lim, H.S. Should we find another model? Improving Neural Machine Translation Performance with ONE-Piece Tokenization Method without Model Modification. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 97–104. [Google Scholar]
- Park, C.; Kim, G.; Lim, H. Parallel Corpus Filtering and Korean-Optimized Subword Tokenization for Machine Translation. In Proceedings of the 31st Annual Conference on Human & Cognitive Language Technology, Daejeon, Korea, 11–12 October 2019. [Google Scholar]
- Park, C.; Kim, K.; Lim, H. Optimization of Data Augmentation Techniques in Neural Machine Translation. In Proceedings of the 31st Annual Conference on Human & Cognitive Language Technology, Daejeon, Korea, 11–12 October 2019. [Google Scholar]
- Park, C.; Kim, K.; Yang, Y.; Kang, M.; Lim, H. Neural spelling correction: Translating incorrect sentences to correct sentences for multimedia. Multimed. Tools Appl. 2020, 80, 34591–34608. [Google Scholar] [CrossRef]
- Park, C.; Lee, C.; Yang, Y.; Lim, H. Ancient Korean Neural Machine Translation. IEEE Access 2020, 8, 116617–116625. [Google Scholar] [CrossRef]
- Lee, C.; Yang, K.; Whang, T.; Park, C.; Matteson, A.; Lim, H. Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models. Appl. Sci. 2021, 11, 1974. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.; Blackburn, K. The Development and Psychometric Properties of LIWC2015; Technical Report; University of Texas Libraries: Austin, TX, USA, 2015. [Google Scholar]
- Prates, M.O.; Avelar, P.H.; Lamb, L. Assessing gender bias in machine translation–a case study with Google translate. arXiv 2018, arXiv:1809.02208. [Google Scholar] [CrossRef] [Green Version]
- Saunders, D.; Byrne, B. Reducing gender bias in neural machine translation as a domain adaptation problem. arXiv 2020, arXiv:2004.04498. [Google Scholar]
- Coppersmith, G.; Dredze, M.; Harman, C. Quantifying mental health signals in Twitter. In Proceedings of the Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Baltimore, MD, USA, 22–27 June 2014; pp. 51–60. [Google Scholar]
- Su, Q.; Wan, M.; Liu, X.; Huang, C.R. Motivations, methods and metrics of misinformation detection: An NLP perspective. Nat. Lang. Process. Res. 2020, 1, 1–13. [Google Scholar] [CrossRef]
- Garcıa-Dıaz, J.A. Using Linguistic Features for Improving Automatic Text Classification Tasks in Spanish. In Proceedings of the Doctoral Symposium on Natural Language Processing from the PLN.net Network (PLNnet-DS-2020), Jaén, Spain, 16 December 2020. [Google Scholar]
- Biggiogera, J.; Boateng, G.; Hilpert, P.; Vowels, M.; Bodenmann, G.; Neysari, M.; Nussbeck, F.; Kowatsch, T. BERT meets LIWC: Exploring State-of-the-Art Language Models for Predicting Communication Behavior in Couples’ Conflict Interactions. arXiv 2021, arXiv:2106.01536. [Google Scholar]
- Moon, H.; Park, C.; Eo, S.; Park, J.; Lim, H. Filter-mBART Based Neural Machine Translation Using Parallel Corpus Filtering. J. Korea Converg. Soc. 2021, 12, 1–7. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Cai, L.; Zhu, Y. The challenges of data quality and data quality assessment in the big data era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Koehn, P.; Khayrallah, H.; Heafield, K.; Forcada, M.L. Findings of the wmt 2018 shared task on parallel corpus filtering. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Belgium, Brussels, 31 October–1 November 2018; Association for Computational Linguistics: Belgium, Brussels, 2018; pp. 726–739. [Google Scholar]
- Park, C.; Seo, J.; Lee, S.; Lee, C.; Moon, H.; Eo, S.; Lim, H. BTS: Back TranScription for Speech-to-Text Post-Processor using Text-to-Speech-to-Text. In Proceedings of the 8th Workshop on Asian Translation (WAT2021), Association for Computational Linguistics, Online, 5–6 August 2021; pp. 106–116. [Google Scholar] [CrossRef]
- Zhang, B.; Nagesh, A.; Knight, K. Parallel corpus filtering via pre-trained language models. arXiv 2020, arXiv:2005.06166. [Google Scholar]
- Pope, D.; Griffith, J. An Analysis of Online Twitter Sentiment Surrounding the European Refugee Crisis. In Proceedings of the KDIR, Porto, Portugal, 9–11 November 2016; pp. 299–306. [Google Scholar]
- Fast, E.; Chen, B.; Bernstein, M.S. Empath: Understanding topic signals in large-scale text. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4647–4657. [Google Scholar]
- Garzón-Velandia, D.C.; Barreto, I.; Medina-Arboleda, I.F. Validación de un diccionario de LIWC para identificar emociones intergrupales. Rev. Latinoam. Psicol. 2020, 52, 149–159. [Google Scholar] [CrossRef]
- Paixao, M.; Lima, R.; Espinasse, B. Fake News Classification and Topic Modeling in Brazilian Portuguese. In Proceedings of the 2020 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Melbourne, Australia, 14–17 December 2020; pp. 427–432. [Google Scholar]
- Lee Chang-hwan, S.J.m.; Ae-sun, Y. The Review about the Development of Korean Linguistic Inquiry and Word Count. Korean Psychol. Assoc. 2004, 2004, 295–296. [Google Scholar]
- Lee, J.W.; Oh, J.H.; Jung, J.S.; Lee, C.H. Counselor-Client Language Analysis Using the K-LIWC Program. J. Korean Data Anal. Soc. 2007, 9, 2545–2567. [Google Scholar]
- Kim Youngil, K.Y.; Kyungil, K. Detecting a deceptive attitude in non-pressure situations using K-LIWC. Korean Soc. Cogn. Sci. 2016, 27, 247–273. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Features (Label) |
|---|---|
| Summary | Analytical thinking (Analytic), Clout (Clout), |
| language variables | Authenticity (Authentic), Emotional tone (Tone) |
| Words per sentence (WPS), Percent of target words captured by the dictionary (Dic), | |
| Linguistic | Percent of words in the text that are longer than six letters (Sixltr), Word count (WC), |
| Dimension | Articles (article), Prepositions (prep), Total pronouns (pronoun), Personal pronouns (ppron), 1st pers singular (i), 1st pers plural (we), 2nd person (you), 3rd pers singular (shehe), 3rd pers plural (they), Impersonal pronouns (ipron) |
| Grammars | Auxiliary verbs (auxverb), Common verbs (verb), Common Adverbs (adverb), Conjunctions (conj), Negations (negate), Common adjectives (adj), Comparisons (compare), Interrogatives (interrog), Number (number), Quantifiers (quant) |
| Affect process | Total affect process (affect), Positive emotion (posemo), Negative emotion (negemo), Anxiety (anx), Anger (anger), Sadness (sad) |
| Cognitive process | Total cognitiive process (cogproc), Insight (insight), Cause (cause), Discrepanices (discrep), Tentativeness (tentat), Certainty (certain), Differentiation (differ) |
| Social process | Total social process (social), Familty (family), Friends (friend), Female referents (female), Male referents (male) |
| Perceptual process | Total perceptual process (percept), Seeing (see), Hearing (hear), Feeling (feel) |
| Biological process | Total biological process (bio), Body (body), Health/Illness (health), Sexuality (sexual), Ingesting (ingest) |
| Drives | Total drives (drives), Affiliation (affiliation), Achievement (achieve), Power (power), Reward focus (reward), Risk focus (risk) |
| Time orientations | Past focus (focuspast), Present focus (focuspresent), Future focus (focusfuture) |
| Relativity | Total relativity (relativ), Motion (motion), Space (space), Time (time) |
| Personal concerns | Work (work), Home (home), Money (money), Leisure activities (leisure), Religion (relig), Death (death) |
| Informal | Total informal language markers (Informal), Assents (assent), |
| language markers | Fillers (filler), Swear words (swear), Netspeak (netspeak), Nonfluencies (nonfl) |
| Punctuations | Total punctuation (Allpunc), Semicolons (SemiC), Commas (Comma), Colons (Colon), Parantheses (Parenth), Question marks (QMark), Exclamation marks (Exclam), Periods (Period), Apostrophes (Apostro), Quoatation marks (Quote) Dashes (Dash), Other puntuation (OtherP) |
| KR-En Domain-Specialized Parallel Corp | KR-En Parallel Corpus | ||||
|---|---|---|---|---|---|
| Categories | Features | Train | Valid | Total | Total |
| summary language variables | Analytic | 97.14 | 97.26 | 97.16 | 94.16 |
| Clout | 61.1 | 61.17 | 61.11 | 65.39 | |
| Authentic | 25.7 | 25.37 | 25.66 | 27.76 | |
| Tone | 49.14 | 49.08 | 49.13 | 54.48 | |
| Linguistic dimensions | WC | 33,750,816 | 4,222,191 | 37,973,007 | 38,481,936 |
| WPS | 27.33 | 27.29 | 27.33 | 25.39 | |
| Sixltr | 26.5 | 26.49 | 26.5 | 25.69 | |
| Dic | 76.33 | 76.3 | 76.32 | 79.25 | |
| function | 43.78 | 43.78 | 43.78 | 45.24 | |
| pronoun | 4.9 | 4.87 | 4.89 | 6.73 | |
| ppron | 1.54 | 1.54 | 1.54 | 3.08 | |
| i | 0.21 | 0.21 | 0.21 | 1.02 | |
| we | 0.23 | 0.23 | 0.23 | 0.38 | |
| you | 0.3 | 0.3 | 0.3 | 0.56 | |
| shehe | 0.42 | 0.42 | 0.42 | 0.67 | |
| they | 0.38 | 0.38 | 0.38 | 0.45 | |
| ipron | 3.36 | 3.33 | 3.35 | 3.64 | |
| article | 10.4 | 10.42 | 10.4 | 10.2 | |
| prep | 15.51 | 15.52 | 15.51 | 15.1 | |
| grammar | auxverb | 6.07 | 6.05 | 6.06 | 6.75 |
| adverb | 2.46 | 2.47 | 2.46 | 2.55 | |
| conj | 5.92 | 5.92 | 5.92 | 5.43 | |
| negate | 0.63 | 0.62 | 0.63 | 0.7 | |
| verb | 9.94 | 9.91 | 9.94 | 11.36 | |
| adj | 4.49 | 4.46 | 4.49 | 4.47 | |
| compare | 2.35 | 2.34 | 2.35 | 2.25 | |
| interrog | 1.21 | 1.2 | 1.21 | 1.3 | |
| number | 3.27 | 3.28 | 3.27 | 2.53 | |
| quant | 1.36 | 1.36 | 1.36 | 1.4 | |
| affective process | affect | 3.78 | 3.75 | 3.77 | 4.03 |
| posemo | 2.49 | 2.48 | 2.49 | 2.75 | |
| negemo | 1.24 | 1.23 | 1.24 | 1.23 | |
| anx | 0.17 | 0.17 | 0.17 | 0.19 | |
| anger | 0.21 | 0.2 | 0.21 | 0.29 | |
| sad | 0.3 | 0.3 | 0.3 | 0.28 | |
| social process | social | 5.07 | 5.04 | 5.06 | 6.7 |
| family | 0.23 | 0.23 | 0.23 | 0.25 | |
| friend | 0.12 | 0.12 | 0.12 | 0.15 | |
| female | 0.18 | 0.17 | 0.18 | 0.34 | |
| male | 0.46 | 0.47 | 0.46 | 0.63 | |
| cognitive process | cogproc | 6.75 | 6.73 | 6.74 | 7.48 |
| insight | 1.56 | 1.56 | 1.56 | 1.75 | |
| cause | 1.69 | 1.68 | 1.69 | 1.73 | |
| discrep | 0.77 | 0.77 | 0.77 | 0.99 | |
| tentat | 1.14 | 1.14 | 1.14 | 1.41 | |
| certain | 0.65 | 0.65 | 0.65 | 0.7 | |
| differ | 1.92 | 1.91 | 1.92 | 1.96 | |
| perceptual process | percept | 1.53 | 1.53 | 1.53 | 1.82 |
| see | 0.58 | 0.58 | 0.58 | 0.68 | |
| hear | 0.48 | 0.48 | 0.48 | 0.65 | |
| feel | 0.32 | 0.32 | 0.32 | 0.35 | |
| Biological process | bio | 2.31 | 2.31 | 2.31 | 1.63 |
| body | 0.46 | 0.46 | 0.46 | 0.46 | |
| health | 1.35 | 1.36 | 1.35 | 0.67 | |
| sexual | 0.04 | 0.04 | 0.04 | 0.05 | |
| ingest | 0.51 | 0.51 | 0.51 | 0.46 | |
| drives | drives | 7.39 | 7.4 | 7.4 | 8.26 |
| affiliation | 1.52 | 1.52 | 1.52 | 1.77 | |
| achieve | 1.92 | 1.92 | 1.92 | 1.96 | |
| power | 3.33 | 3.33 | 3.33 | 3.94 | |
| reward | 1.02 | 1.02 | 1.02 | 1.05 | |
| risk | 0.79 | 0.78 | 0.79 | 0.63 | |
| time-orientations | focuspast | 3.27 | 3.25 | 3.26 | 3.4 |
| focuspresent | 5.79 | 5.78 | 5.79 | 6.63 | |
| focusfuture | 0.97 | 0.96 | 0.96 | 1.49 | |
| relativivity | relativ | 14.53 | 14.55 | 14.53 | 14.29 |
| motion | 1.72 | 1.72 | 1.72 | 1.81 | |
| space | 8.31 | 8.32 | 8.31 | 7.83 | |
| time | 4.59 | 4.6 | 4.59 | 4.73 | |
| personal concerns | work | 5.64 | 5.64 | 5.64 | 6.37 |
| leisure | 1.52 | 1.52 | 1.52 | 1.43 | |
| home | 0.52 | 0.53 | 0.52 | 0.5 | |
| money | 2.19 | 2.18 | 2.19 | 1.87 | |
| relig | 0.23 | 0.23 | 0.23 | 0.29 | |
| death | 0.14 | 0.14 | 0.14 | 0.14 | |
| informal language | informal | 0.23 | 0.23 | 0.23 | 0.26 |
| swear | 0 | 0 | 0 | 0.01 | |
| netspeak | 0.1 | 0.11 | 0.1 | 0.1 | |
| assent | 0.06 | 0.06 | 0.06 | 0.09 | |
| nonflu | 0.08 | 0.08 | 0.08 | 0.09 | |
| filler | 0 | 0 | 0 | 0 | |
| punctuations | AllPunc | 14.72 | 14.72 | 14.72 | 14.68 |
| Period | 3.81 | 3.81 | 3.81 | 4.33 | |
| Comma | 6.23 | 6.23 | 6.23 | 5.24 | |
| Colon | 0.03 | 0.03 | 0.03 | 0.08 | |
| SemiC | 0.01 | 0.01 | 0.01 | 0.01 | |
| QMark | 0.01 | 0.01 | 0.01 | 0.22 | |
| Exclam | 0 | 0 | 0 | 0 | |
| Dash | 1.88 | 1.89 | 1.89 | 1.6 | |
| Quote | 1.11 | 1.1 | 1.11 | 1.16 | |
| Apostro | 0.85 | 0.85 | 0.85 | 1.11 | |
| Parenth | 0.56 | 0.57 | 0.56 | 0.7 | |
| OtherP | 0.22 | 0.23 | 0.22 | 0.23 | |
| KR-En Parallel Corpus (Social Science) | KR-En Parallel Corpus (Technology) | ||||||
|---|---|---|---|---|---|---|---|
| Categories | Features | Train | Valid | Total | Train | Valid | Total |
| summary language variables | Analytic | 97.38 | 97.38 | 97.38 | 99 | 99 | 99 |
| Clout | 53.86 | 53.87 | 53.86 | 49.13 | 49.17 | 49.13 | |
| Authentic | 23.99 | 24.26 | 24.02 | 16.69 | 16.49 | 16.67 | |
| Tone | 47.66 | 47.91 | 47.69 | 34.02 | 33.99 | 34.02 | |
| Linguistic dimensions | WC | 9,991,408 | 1,250,115 | 11,241,523 | 13,621,209 | 1,702,722 | 15,323,931 |
| WPS | 20.77 | 20.79 | 20.77 | 17.87 | 17.87 | 17.87 | |
| Sixltr | 30.65 | 30.61 | 30.65 | 29.02 | 29.03 | 29.02 | |
| Dic | 80.71 | 80.71 | 80.71 | 67.19 | 67.17 | 67.19 | |
| function | 46.81 | 46.81 | 46.81 | 42.15 | 42.19 | 42.15 | |
| pronoun | 5.32 | 5.31 | 5.32 | 2.04 | 2.06 | 2.04 | |
| ppron | 0.96 | 0.96 | 0.96 | 0.14 | 0.15 | 0.14 | |
| i | 0.14 | 0.14 | 0.14 | 0.03 | 0.03 | 0.03 | |
| we | 0.22 | 0.22 | 0.22 | 0.02 | 0.02 | 0.02 | |
| you | 0.1 | 0.1 | 0.1 | 0.02 | 0.01 | 0.02 | |
| shehe | 0.16 | 0.17 | 0.16 | 0.01 | 0.02 | 0.01 | |
| they | 0.34 | 0.34 | 0.34 | 0.06 | 0.07 | 0.06 | |
| ipron | 4.35 | 4.34 | 4.35 | 1.9 | 1.91 | 1.9 | |
| article | 11.42 | 11.42 | 11.42 | 14.95 | 14.95 | 14.95 | |
| prep | 16.14 | 16.13 | 16.14 | 13.2 | 13.23 | 13.2 | |
| grammar | auxverb | 7.23 | 7.21 | 7.23 | 7.68 | 7.7 | 7.68 |
| adverb | 2.44 | 2.42 | 2.44 | 1.35 | 1.34 | 1.35 | |
| conj | 5.41 | 5.44 | 5.41 | 3.77 | 3.76 | 3.77 | |
| negate | 0.85 | 0.86 | 0.85 | 0.3 | 0.3 | 0.3 | |
| verb | 10.3 | 10.25 | 10.29 | 9.51 | 9.53 | 9.51 | |
| adj | 4.73 | 4.73 | 4.73 | 3.32 | 3.32 | 3.32 | |
| compare | 2.6 | 2.57 | 2.6 | 2.15 | 2.15 | 2.15 | |
| interrog | 0.88 | 0.88 | 0.88 | 0.54 | 0.54 | 0.54 | |
| number | 1.89 | 1.87 | 1.89 | 6.28 | 6.27 | 6.28 | |
| quant | 1.58 | 1.58 | 1.58 | 1.63 | 1.62 | 1.63 | |
| affective process | affect | 3.78 | 3.79 | 3.78 | 1.73 | 1.73 | 1.73 |
| posemo | 2.45 | 2.46 | 2.45 | 1.09 | 1.09 | 1.09 | |
| negemo | 1.27 | 1.26 | 1.27 | 0.62 | 0.62 | 0.62 | |
| anx | 0.21 | 0.2 | 0.21 | 0.15 | 0.15 | 0.15 | |
| anger | 0.24 | 0.25 | 0.24 | 0.05 | 0.05 | 0.05 | |
| sad | 0.22 | 0.22 | 0.22 | 0.23 | 0.23 | 0.23 | |
| social process | social | 4.27 | 4.28 | 4.27 | 1.83 | 1.84 | 1.83 |
| family | 0.12 | 0.13 | 0.12 | 0.05 | 0.05 | 0.05 | |
| friend | 0.06 | 0.07 | 0.06 | 0.09 | 0.09 | 0.09 | |
| female | 0.1 | 0.09 | 0.1 | 0.04 | 0.04 | 0.04 | |
| male | 0.18 | 0.19 | 0.18 | 0.03 | 0.03 | 0.03 | |
| cognitive process | cogproc | 11.14 | 11.13 | 11.14 | 9.6 | 9.59 | 9.6 |
| insight | 3.34 | 3.34 | 3.34 | 2.09 | 2.07 | 2.09 | |
| cause | 2.78 | 2.76 | 2.78 | 2.29 | 2.3 | 2.29 | |
| discrep | 1.06 | 1.06 | 1.06 | 0.35 | 0.34 | 0.35 | |
| tentat | 1.89 | 1.89 | 1.89 | 3.71 | 3.72 | 3.71 | |
| certain | 1.09 | 1.09 | 1.09 | 0.45 | 0.44 | 0.45 | |
| differ | 2.63 | 2.64 | 2.63 | 1.72 | 1.72 | 1.72 | |
| perceptual process | percept | 1.16 | 1.17 | 1.16 | 2.17 | 2.17 | 2.17 |
| see | 0.56 | 0.56 | 0.56 | 1.37 | 1.37 | 1.37 | |
| hear | 0.26 | 0.25 | 0.26 | 0.2 | 0.2 | 0.2 | |
| feel | 0.18 | 0.19 | 0.18 | 0.42 | 0.42 | 0.42 | |
| Biological process | bio | 0.8 | 0.81 | 0.8 | 1.42 | 1.42 | 1.42 |
| body | 0.18 | 0.19 | 0.18 | 0.41 | 0.41 | 0.41 | |
| health | 0.45 | 0.44 | 0.45 | 0.8 | 0.79 | 0.8 | |
| sexual | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | |
| ingest | 0.15 | 0.15 | 0.15 | 0.22 | 0.22 | 0.22 | |
| drives | drives | 7.95 | 8.02 | 7.96 | 4.59 | 4.58 | 4.59 |
| affiliation | 1.3 | 1.32 | 1.3 | 0.66 | 0.66 | 0.66 | |
| achieve | 1.87 | 1.9 | 1.87 | 1.46 | 1.46 | 1.46 | |
| power | 3.87 | 3.91 | 3.87 | 2.08 | 2.08 | 2.08 | |
| reward | 0.83 | 0.84 | 0.83 | 0.37 | 0.37 | 0.37 | |
| risk | 0.83 | 0.82 | 0.83 | 0.34 | 0.34 | 0.34 | |
| time-orientations | focuspast | 2.66 | 2.66 | 2.66 | 1.34 | 1.36 | 1.34 |
| focuspresent | 6.98 | 6.92 | 6.97 | 6.15 | 6.14 | 6.15 | |
| focusfuture | 0.76 | 0.76 | 0.76 | 2.85 | 2.85 | 2.85 | |
| relativity | relativ | 11.88 | 11.93 | 11.89 | 11.72 | 11.69 | 11.72 |
| motion | 1.49 | 1.52 | 1.49 | 1.43 | 1.42 | 1.43 | |
| space | 7.34 | 7.36 | 7.34 | 7.29 | 7.29 | 7.29 | |
| time | 3 | 3.01 | 3 | 3.16 | 3.15 | 3.16 | |
| personal concerns | work | 8.42 | 8.41 | 8.42 | 2.25 | 2.26 | 2.25 |
| leisure | 0.76 | 0.76 | 0.76 | 0.44 | 0.42 | 0.44 | |
| home | 0.32 | 0.32 | 0.32 | 0.28 | 0.28 | 0.28 | |
| money | 3.2 | 3.17 | 3.2 | 0.38 | 0.38 | 0.38 | |
| relig | 0.13 | 0.12 | 0.13 | 0.02 | 0.02 | 0.02 | |
| death | 0.08 | 0.08 | 0.08 | 0.04 | 0.05 | 0.04 | |
| informal language | informal | 0.13 | 0.13 | 0.13 | 0.18 | 0.18 | 0.18 |
| swear | 0.01 | 0.01 | 0.01 | 0.03 | 0.03 | 0.03 | |
| netspeak | 0.06 | 0.06 | 0.06 | 0.12 | 0.12 | 0.12 | |
| assent | 0.02 | 0.02 | 0.02 | 0.01 | 0.01 | 0.01 | |
| nonflu | 0.05 | 0.04 | 0.05 | 0.04 | 0.04 | 0.04 | |
| filler | 0 | 0 | 0 | 0 | 0 | 0 | |
| punctuations | AllPunc | 11.75 | 11.76 | 11.75 | 11.17 | 11.16 | 11.17 |
| Period | 4.81 | 4.81 | 4.81 | 5.65 | 5.65 | 5.65 | |
| Comma | 4.66 | 4.66 | 4.66 | 3.54 | 3.54 | 3.54 | |
| Colon | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| SemiC | 0 | 0.01 | 0 | 0 | 0 | 0 | |
| QMark | 0.04 | 0.04 | 0.04 | 0 | 0 | 0 | |
| Exclam | 0 | 0 | 0 | 0 | 0 | 0 | |
| Dash | 0.83 | 0.84 | 0.83 | 0.82 | 0.8 | 0.82 | |
| Quote | 0.12 | 0.12 | 0.12 | 0.02 | 0.02 | 0.02 | |
| Apostro | 0.63 | 0.65 | 0.63 | 0.12 | 0.12 | 0.12 | |
| Parenth | 0.37 | 0.37 | 0.37 | 0.69 | 0.7 | 0.69 | |
| OtherP | 0.26 | 0.26 | 0.26 | 0.31 | 0.31 | 0.31 | |
| Ko-Zh Parallel Corpus (Social Science) | Ko-Zh Parallel Corpus (Technology) | ||||||
|---|---|---|---|---|---|---|---|
| Categories | Features | Train | Valid | Total | Train | Valid | Total |
| summary language variables | Analytic | 93.25 | 93.24 | 93.25 | 93.15 | 93.09 | 93.14 |
| Clout | 50.44 | 50.49 | 50.45 | 51.73 | 52.14 | 51.78 | |
| Authentic | 1 | 1 | 1 | 1 | 1 | 1 | |
| Tone | 26.97 | 27.05 | 26.98 | 29.18 | 29.75 | 29.25 | |
| Linguistic dimensions | WC | 3,907,897 | 482,441 | 4,390,338 | 3,954,651 | 512,873 | 4,467,524 |
| WPS | 598.73 | 724.39 | 612.54 | 2569.62 | 2947.55 | 2613.01 | |
| Sixltr | 66.89 | 66.68 | 66.87 | 66.35 | 64.84 | 66.18 | |
| Dic | 1.02 | 1.07 | 1.03 | 3.27 | 3.81 | 3.33 | |
| function | 0.21 | 0.21 | 0.21 | 0.55 | 0.67 | 0.56 | |
| pronoun | 0.07 | 0.08 | 0.07 | 0.27 | 0.35 | 0.28 | |
| ppron | 0.06 | 0.06 | 0.06 | 0.2 | 0.25 | 0.21 | |
| i | 0.03 | 0.03 | 0.03 | 0.05 | 0.06 | 0.05 | |
| we | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| you | 0.02 | 0.02 | 0.02 | 0.15 | 0.19 | 0.15 | |
| shehe | 0 | 0 | 0 | 0 | 0 | 0 | |
| they | 0 | 0 | 0 | 0 | 0 | 0 | |
| ipron | 0.02 | 0.02 | 0.02 | 0.07 | 0.09 | 0.07 | |
| article | 0.06 | 0.05 | 0.06 | 0.08 | 0.09 | 0.08 | |
| prep | 0.05 | 0.05 | 0.05 | 0.15 | 0.17 | 0.15 | |
| grammar | auxverb | 0.01 | 0.02 | 0.01 | 0.02 | 0.03 | 0.02 |
| adverb | 0.01 | 0.01 | 0.01 | 0.02 | 0.03 | 0.02 | |
| conj | 0.01 | 0.01 | 0.01 | 0.04 | 0.04 | 0.04 | |
| negate | 0.01 | 0.01 | 0.01 | 0 | 0 | 0 | |
| verb | 0.08 | 0.08 | 0.08 | 0.16 | 0.17 | 0.16 | |
| adj | 0.07 | 0.08 | 0.07 | 0.27 | 0.3 | 0.27 | |
| compare | 0.01 | 0.01 | 0.01 | 0.02 | 0.02 | 0.02 | |
| interrog | 0.01 | 0.01 | 0.01 | 0.02 | 0.02 | 0.02 | |
| number | 1.45 | 1.41 | 1.45 | 1.33 | 1.16 | 1.31 | |
| quant | 0.01 | 0.01 | 0.01 | 0.04 | 0.04 | 0.04 | |
| affective process | affect | 0.12 | 0.13 | 0.12 | 0.29 | 0.35 | 0.3 |
| posemo | 0.1 | 0.1 | 0.1 | 0.25 | 0.29 | 0.25 | |
| negemo | 0.02 | 0.03 | 0.02 | 0.04 | 0.06 | 0.04 | |
| anx | 0 | 0 | 0 | 0 | 0.01 | 0 | |
| anger | 0 | 0.01 | 0 | 0.02 | 0.02 | 0.02 | |
| sad | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| social process | social | 0.13 | 0.14 | 0.13 | 0.34 | 0.41 | 0.35 |
| family | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| friend | 0.01 | 0.02 | 0.01 | 0.04 | 0.04 | 0.04 | |
| female | 0.02 | 0.01 | 0.02 | 0.02 | 0.03 | 0.02 | |
| male | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | |
| cognitive process | cogproc | 0.05 | 0.06 | 0.05 | 0.2 | 0.24 | 0.2 |
| insight | 0.02 | 0.02 | 0.02 | 0.09 | 0.11 | 0.09 | |
| cause | 0.02 | 0.02 | 0.02 | 0.08 | 0.11 | 0.08 | |
| discrep | 0 | 0.01 | 0 | 0 | 0.01 | 0 | |
| tentat | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| certain | 0.01 | 0.01 | 0.01 | 0.03 | 0.03 | 0.03 | |
| differ | 0 | 0 | 0 | 0.01 | 0.01 | 0.01 | |
| perceptual process | percept | 0.09 | 0.09 | 0.09 | 0.22 | 0.25 | 0.22 |
| see | 0.04 | 0.04 | 0.04 | 0.11 | 0.13 | 0.11 | |
| hear | 0.03 | 0.03 | 0.03 | 0.05 | 0.06 | 0.05 | |
| feel | 0.01 | 0.01 | 0.01 | 0.03 | 0.03 | 0.03 | |
| Biological process | bio | 0.06 | 0.07 | 0.06 | 0.18 | 0.21 | 0.18 |
| body | 0.01 | 0.01 | 0.01 | 0.04 | 0.05 | 0.04 | |
| health | 0.02 | 0.02 | 0.02 | 0.08 | 0.1 | 0.08 | |
| sexual | 0 | 0 | 0 | 0.01 | 0.01 | 0.01 | |
| ingest | 0.02 | 0.02 | 0.02 | 0.06 | 0.06 | 0.06 | |
| drives | drives | 0.16 | 0.18 | 0.16 | 0.57 | 0.71 | 0.59 |
| affiliation | 0.06 | 0.06 | 0.06 | 0.22 | 0.27 | 0.23 | |
| achieve | 0.03 | 0.03 | 0.03 | 0.11 | 0.14 | 0.11 | |
| power | 0.07 | 0.08 | 0.07 | 0.2 | 0.26 | 0.21 | |
| reward | 0.02 | 0.02 | 0.02 | 0.06 | 0.07 | 0.06 | |
| risk | 0 | 0 | 0 | 0.03 | 0.04 | 0.03 | |
| time-orientations | focuspast | 0.01 | 0.01 | 0.01 | 0.02 | 0.03 | 0.02 |
| focuspresent | 0.06 | 0.07 | 0.06 | 0.14 | 0.16 | 0.14 | |
| focusfuture | 0.01 | 0.01 | 0.01 | 0.02 | 0.02 | 0.02 | |
| relativivity | relativ | 0.17 | 0.18 | 0.17 | 0.65 | 0.72 | 0.66 |
| motion | 0.03 | 0.04 | 0.03 | 0.13 | 0.15 | 0.13 | |
| space | 0.09 | 0.08 | 0.09 | 0.35 | 0.38 | 0.35 | |
| time | 0.05 | 0.06 | 0.05 | 0.17 | 0.19 | 0.17 | |
| personal concerns | work | 0.11 | 0.12 | 0.11 | 0.52 | 0.56 | 0.52 |
| leisure | 0.11 | 0.11 | 0.11 | 0.35 | 0.49 | 0.37 | |
| home | 0.01 | 0.01 | 0.01 | 0.06 | 0.06 | 0.06 | |
| money | 0.06 | 0.06 | 0.06 | 0.26 | 0.24 | 0.26 | |
| relig | 0.01 | 0.01 | 0.01 | 0.02 | 0.02 | 0.02 | |
| death | 0 | 0 | 0 | 0.01 | 0.02 | 0.01 | |
| informal language | informal | 0.09 | 0.09 | 0.09 | 0.32 | 0.41 | 0.33 |
| swear | 0 | 0 | 0 | 0 | 0.01 | 0 | |
| netspeak | 0.07 | 0.08 | 0.07 | 0.31 | 0.4 | 0.32 | |
| assent | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | |
| nonflu | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| filler | 0 | 0 | 0 | 0 | 0 | 0 | |
| punctuations | AllPunc | 66.01 | 63.97 | 65.79 | 63.19 | 63.24 | 63.2 |
| Period | 0.15 | 0.15 | 0.15 | 0.1 | 0.12 | 0.1 | |
| Comma | 42.3 | 41.26 | 42.19 | 38.9 | 37.37 | 38.72 | |
| Colon | 1.09 | 0.94 | 1.07 | 1.03 | 0.82 | 1.01 | |
| SemiC | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| QMark | 0.18 | 0.13 | 0.17 | 0.05 | 0.05 | 0.05 | |
| Exclam | 0.05 | 0.06 | 0.05 | 0.02 | 0.02 | 0.02 | |
| Dash | 0.52 | 0.52 | 0.52 | 1.14 | 1.15 | 1.14 | |
| Quote | 15.52 | 14.31 | 15.39 | 12.68 | 12.89 | 12.7 | |
| Apostro | 0.52 | 0.46 | 0.51 | 0.57 | 0.5 | 0.56 | |
| Parenth | 3.79 | 4.28 | 3.84 | 6.65 | 8.53 | 6.87 | |
| OtherP | 1.89 | 1.86 | 1.89 | 2.05 | 1.79 | 2.02 | |
| # of Sents | # of Min Toks | # of Max Toks | Avg Toks per S | # of Min Chars | # of Max Chars | Avg Chars per S | |||
|---|---|---|---|---|---|---|---|---|---|
| Korean–English Parallel Corpus | Train | KR | 1,399,116 | 1 | 78 | 12.97 | 4 | 359 | 55.07 |
| EN | 1,399,116 | 2 | 180 | 22.57 | 10 | 999 | 135.24 | ||
| Valid | KR | 200,302 | 2 | 32 | 17.46 | 9 | 220 | 75.36 | |
| EN | 200,302 | 3 | 110 | 30.73 | 14 | 706 | 187.89 | ||
| Test | KR | 3000 | 7 | 25 | 9.02 | 25 | 113 | 35.71 | |
| EN | 3000 | 5 | 12 | 10.46 | 31 | 101 | 66.50 | ||
| Korean–English Parallel Corpus (Social Science) | Train | KR | 474,967 | 2 | 138 | 12.57 | 11 | 629 | 52.94 |
| EN | 474,967 | 2 | 271 | 20.71 | 9 | 1617 | 128.78 | ||
| Valid | KR | 59,746 | 6 | 144 | 12.58 | 21 | 636 | 52.96 | |
| EN | 59,746 | 6 | 280 | 20.73 | 29 | 1550 | 128.88 | ||
| Test | KR | 3000 | 6 | 45 | 12.60 | 22 | 236 | 53.00 | |
| EN | 3000 | 7 | 69 | 20.86 | 35 | 451 | 129.33 | ||
| Korean–English Parallel Corpus (Technology) | Train | KR | 697,665 | 4 | 37 | 12.25 | 21 | 180 | 51.97 |
| EN | 697,665 | 1 | 52 | 19.23 | 9 | 311 | 115.88 | ||
| Valid | KR | 87,583 | 4 | 35 | 12.25 | 23 | 155 | 51.95 | |
| EN | 87,583 | 5 | 48 | 19.24 | 37 | 310 | 115.86 | ||
| Test | KR | 3000 | 6 | 34 | 12.23 | 26 | 161 | 51.98 | |
| EN | 3000 | 6 | 42 | 19.17 | 45 | 294 | 115.75 | ||
| Korean–English Domain-Specialized Parallel Corpus | Train | KR | 1,197,000 | 3 | 35 | 15.30 | 11 | 304 | 66.18 |
| EN | 1,197,000 | 1 | 145 | 27.53 | 1 | 1001 | 167.23 | ||
| Valid | KR | 150,000 | 5 | 32 | 15.30 | 14 | 192 | 66.21 | |
| EN | 150,000 | 4 | 97 | 27.55 | 26 | 691 | 167.34 | ||
| Test | KR | 3000 | 7 | 30 | 15.50 | 27 | 147 | 67.79 | |
| EN | 3000 | 7 | 69 | 28.56 | 46 | 433 | 175.57 | ||
| Korean–Japanese Parallel Corpus | Train | KR | 1,197,000 | 3 | 35 | 15.65 | 11 | 216 | 67.56 |
| JP | 1,197,000 | NA | NA | NA | 9 | 250 | 61.63 | ||
| Valid | KR | 150,000 | 4 | 31 | 15.70 | 18 | 243 | 67.87 | |
| EN | 150,000 | NA | NA | NA | 13 | 241 | 61.69 | ||
| Test | KR | 3000 | 4 | 30 | 14.15 | 20 | 168 | 61.99 | |
| JP | 3000 | NA | NA | NA | 16 | 186 | 58.87 | ||
| Korean–Chinese Parallel Corpus (Social Science) | Train | KR | 1,037,000 | 3 | 78 | 15.95 | 12 | 359 | 69.03 |
| ZH | 1,037,000 | NA | NA | NA | 5 | 259 | 46.73 | ||
| Valid | KR | 130,000 | 4 | 52 | 15.66 | 12 | 283 | 68.04 | |
| ZH | 130,000 | NA | NA | NA | 7 | 200 | 46.29 | ||
| Test | KR | 3000 | 6 | 30 | 14.35 | 25 | 151 | 62.12 | |
| ZH | 3000 | NA | NA | NA | 11 | 117 | 37.77 | ||
| Korean–Chinese Parallel Corpus (Technology) | Train | KR | 1,037,000 | 2 | 35 | 15.82 | 10 | 236 | 69.01 |
| ZH | 1,037,000 | NA | NA | NA | 7 | 296 | 48.22 | ||
| Valid | KR | 130,000 | 3 | 31 | 15.93 | 17 | 213 | 69.71 | |
| ZH | 130,000 | NA | NA | NA | 9 | 199 | 49.07 | ||
| Test | KR | 3000 | 4 | 30 | 15.07 | 22 | 163 | 65.75 | |
| ZH | 3000 | NA | NA | NA | 14 | 181 | 45.91 | ||
| Corpus | Language | BLEU |
|---|---|---|
| Korean–English Parallel corpus | KR-EN | 28.36 |
| EN-KR | 13.53 | |
| Korean–English Parallel corpus (Social Science) | KR-EN | 45.64 |
| EN-KR | 17.71 | |
| Korean–English Parallel corpus (Technology) | KR-EN | 63.88 |
| EN-KR | 39.17 | |
| Korean–English Domain-specialized Parallel corpus | KR-EN | 51.88 |
| EN-KR | 21.99 | |
| Korean–Japanese Parallel corpus | KR-JA | 68.88 |
| JP-KR | 49.05 | |
| Korean–Chinese Parallel corpus (Social Science) | KR-ZH | 48.74 |
| ZH-KR | 25.16 | |
| Korean–Chinese Parallel corpus (Technology) | KR-ZH | 46.70 |
| ZH-KR | 25.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Shim, M.; Eo, S.; Lee, S.; Seo, J.; Moon, H.; Lim, H. Empirical Analysis of Parallel Corpora and In-Depth Analysis Using LIWC. Appl. Sci. 2022, 12, 5545. https://doi.org/10.3390/app12115545
Park C, Shim M, Eo S, Lee S, Seo J, Moon H, Lim H. Empirical Analysis of Parallel Corpora and In-Depth Analysis Using LIWC. Applied Sciences. 2022; 12(11):5545. https://doi.org/10.3390/app12115545
Chicago/Turabian StylePark, Chanjun, Midan Shim, Sugyeong Eo, Seolhwa Lee, Jaehyung Seo, Hyeonseok Moon, and Heuiseok Lim. 2022. "Empirical Analysis of Parallel Corpora and In-Depth Analysis Using LIWC" Applied Sciences 12, no. 11: 5545. https://doi.org/10.3390/app12115545
APA StylePark, C., Shim, M., Eo, S., Lee, S., Seo, J., Moon, H., & Lim, H. (2022). Empirical Analysis of Parallel Corpora and In-Depth Analysis Using LIWC. Applied Sciences, 12(11), 5545. https://doi.org/10.3390/app12115545