
A Novel Hierarchical Adaptive Feature Fusion Method for Meta-Learning



Abstract
:1. Introduction
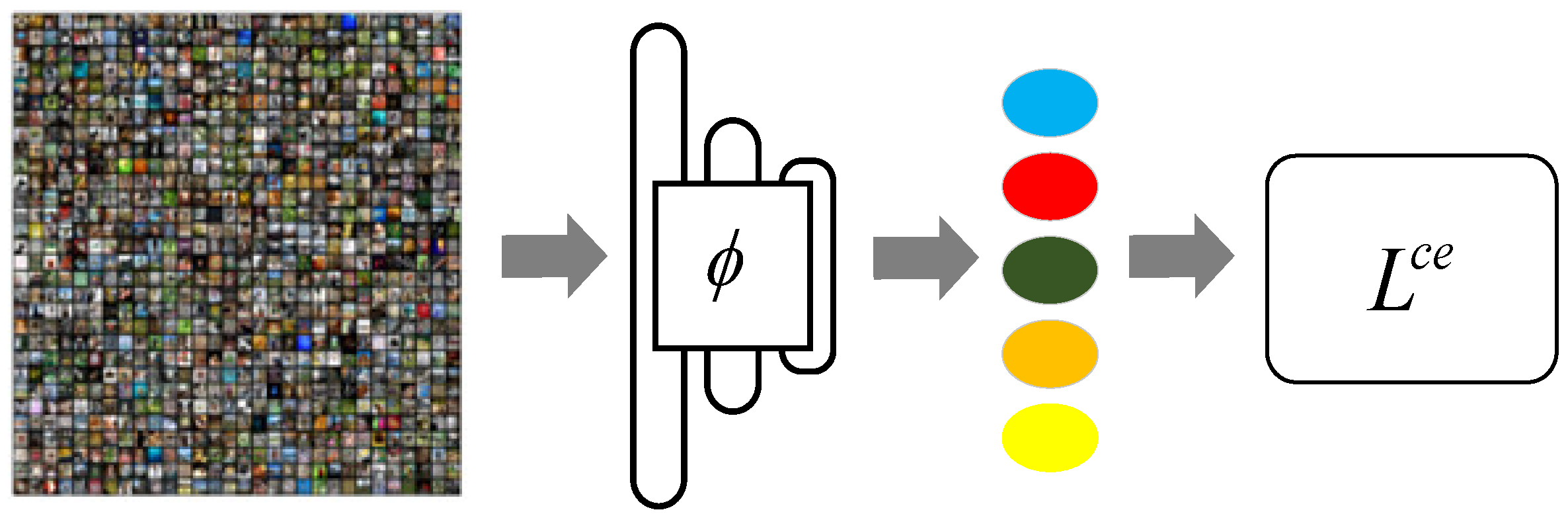
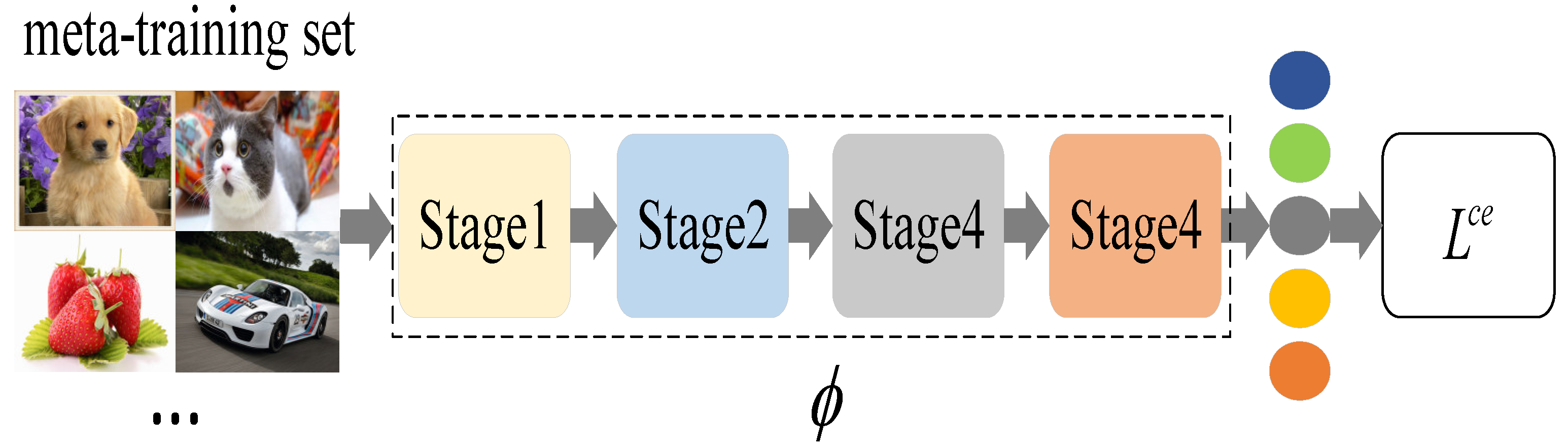
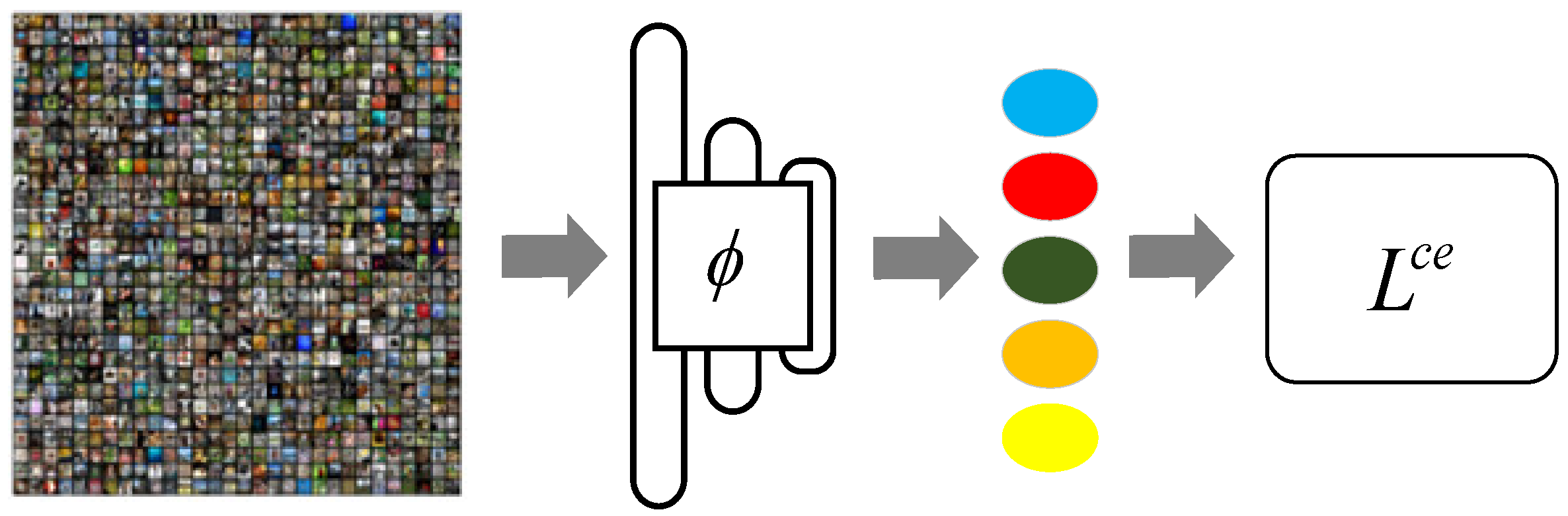
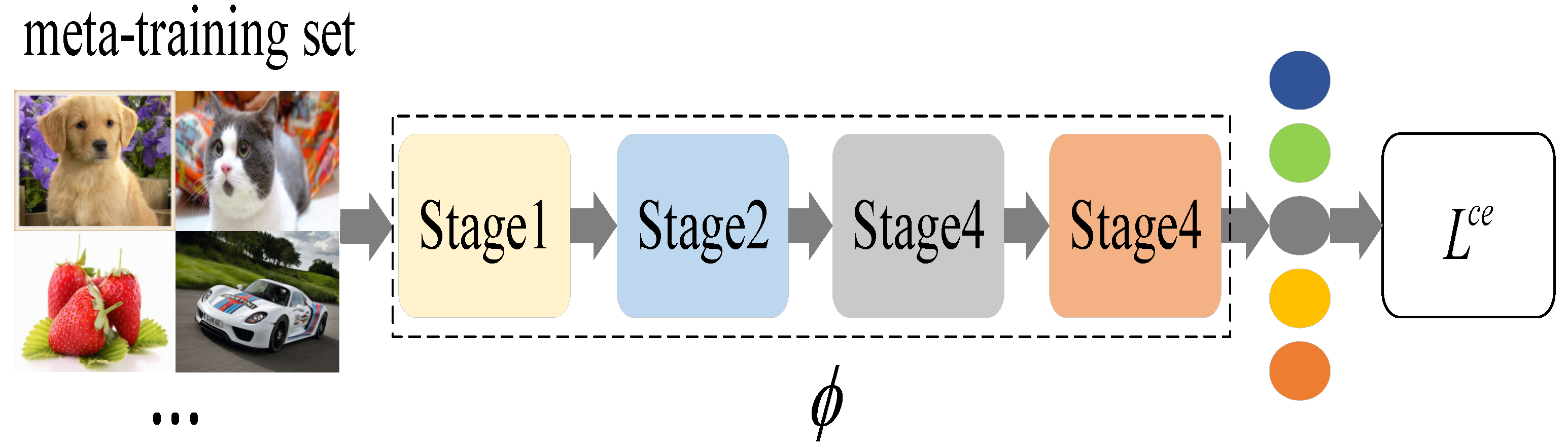
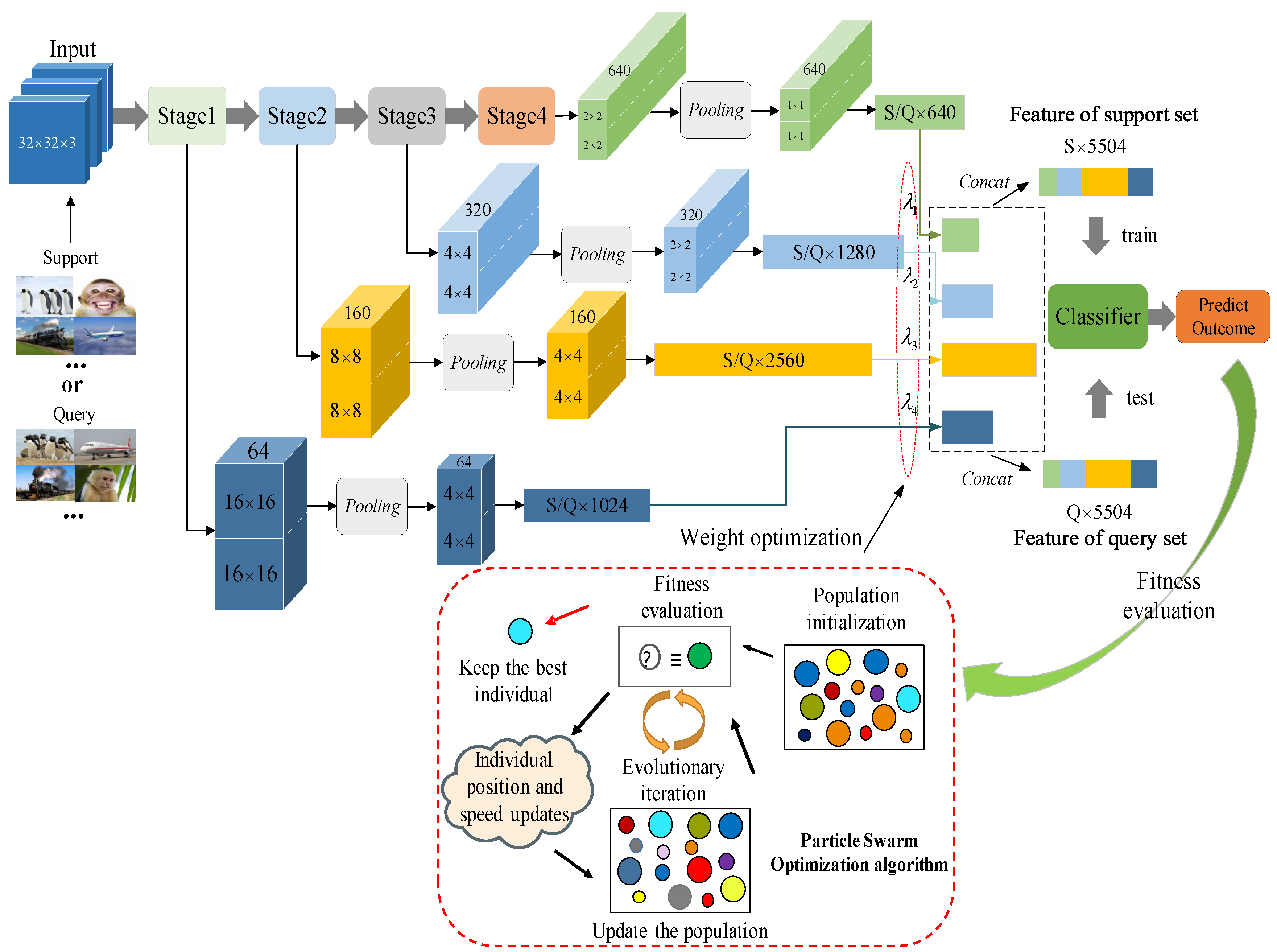
- We propose a meta-learning method based on adaptive feature fusion and weight optimization. The adaptive feature fusion method is used to train and test classifiers by fusing features from each stage of the embedding model, and the feature fusion weight is optimized by combining the classifier’s prediction results.
- In terms of the feature fusion method, we propose a novel feature splicing strategy: the output features of each stage are pooled and flattened, and then unified in a certain dimension. Feature splicing is carried out in this dimension. In the splicing process, the weight of each stage feature is different.
- For the optimization of the feature fusion weights, we combine the optimization algorithm with meta-learning and propose the use of a particle swarm optimization algorithm [27,28] to optimize the weights of the features at each stage of the embedding model. In addition, we use the parallel structure of the computer to optimize the feature fusion weights of multiple groups simultaneously to improve the algorithm’s efficiency.
2. Related Works
2.1. Metric-Based Meta-Learning
2.2. External Memory-Based Meta-Learning
2.3. Initialization Method Based on Strong Generalization
3. Method
3.1. Meta-Learning Knowledge
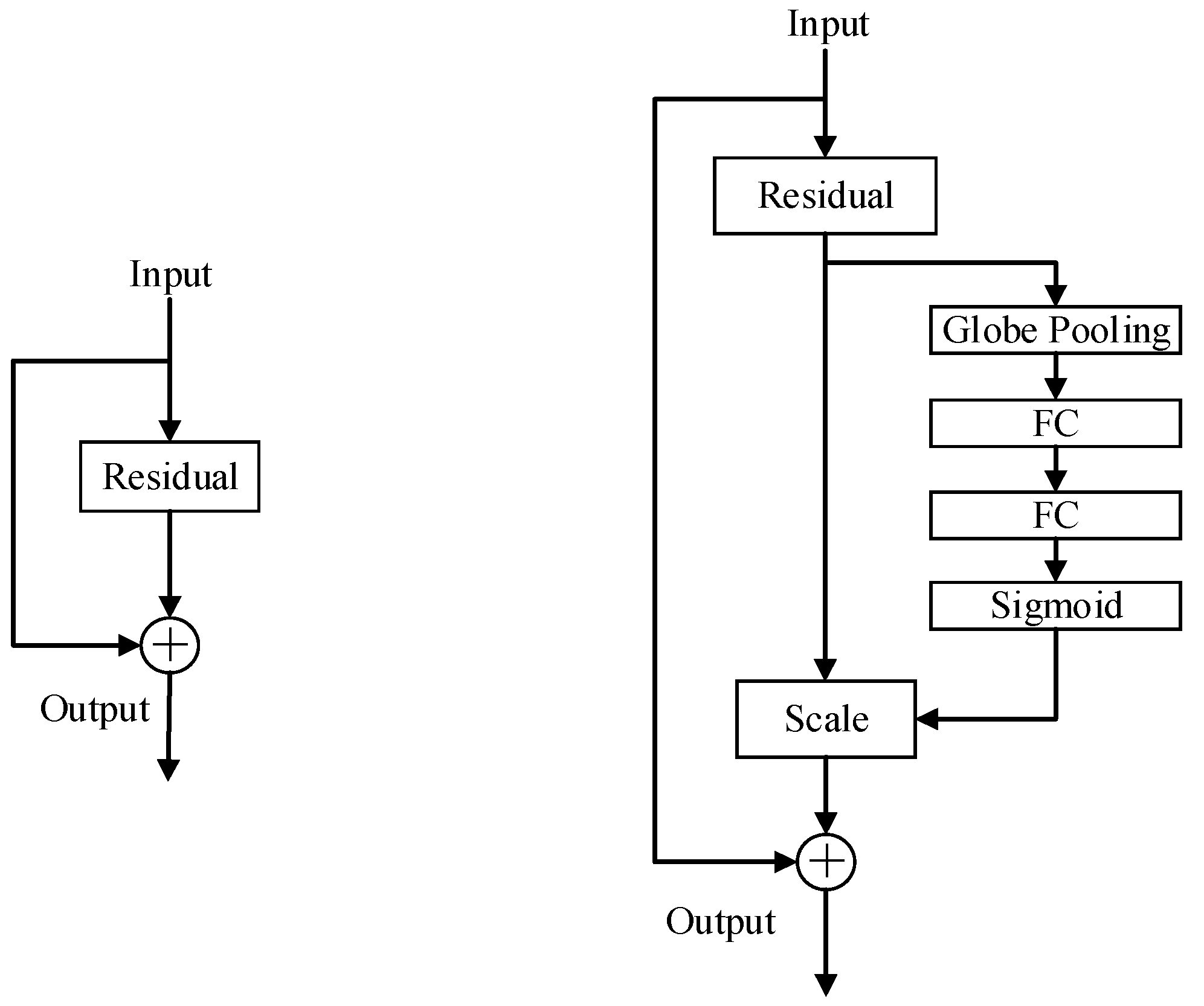
3.2. Feature Fusion
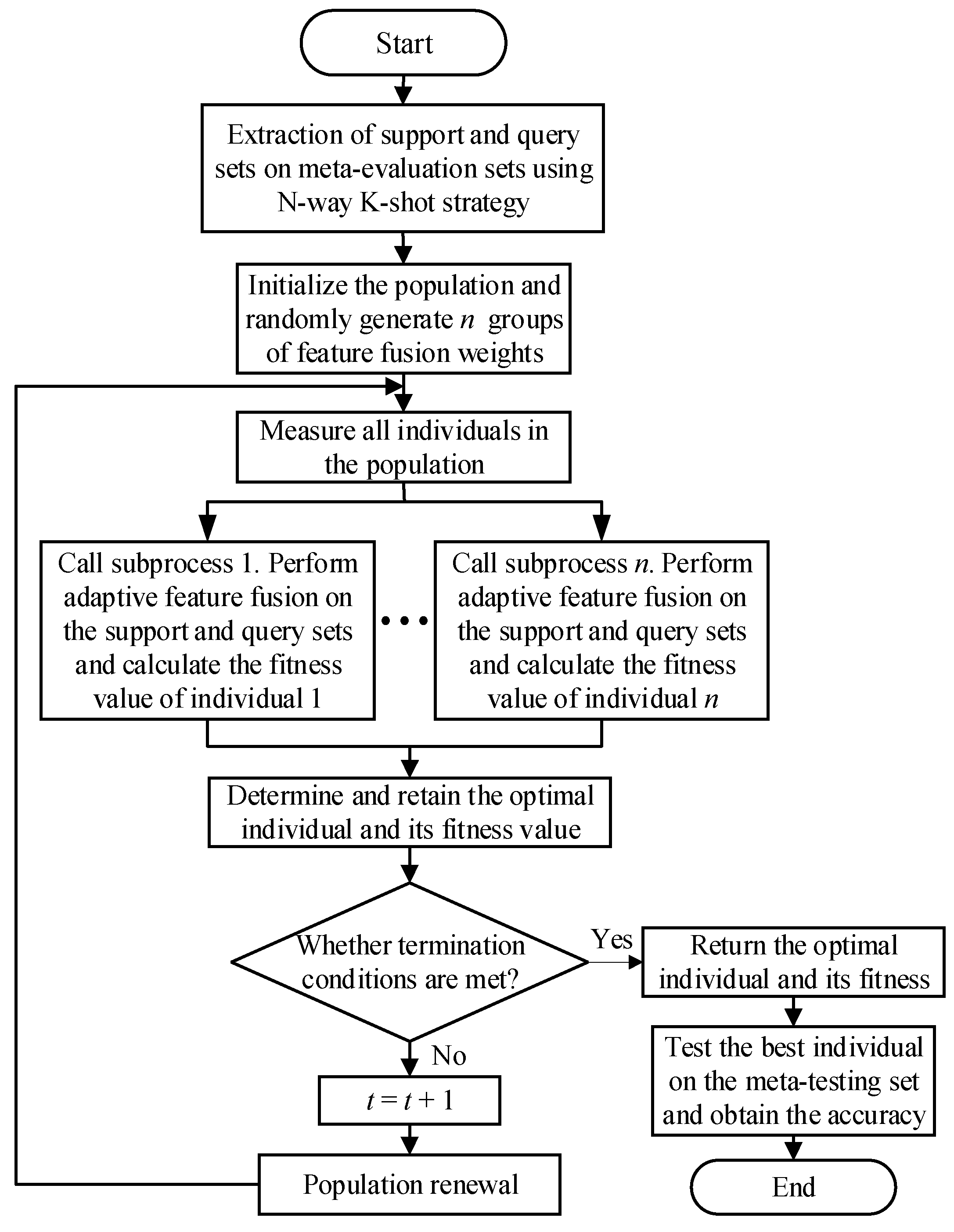
3.3. Weight Optimization
| Algorithm 1 Adaptive feature fusion and weight optimization algorithm pseudo-code |
| Input: the meta-evaluation set ; 1: Initialize t to 1; 2: For i = 1: n do 3: Population initialization ; 4: The individual solution and fitness function was measured by multi-threads. Fitness function evaluation ; 5: Determine and retain the optimal individual and its fitness value; 6: End for 7: while the population position has not reached stability do 8: For i = 1: n do 9: Equation (13) and Equation (14) were used to update population individuals ; 10: End for 11: For i = 1: n do 12: Perform steps 4 and 5; 13: End for 14: t t + 1; 15: End while Output: the optimal individual; |
3.4. Meta-Classifier
4. Experimental Results
4.1. Dataset
4.2. Setup
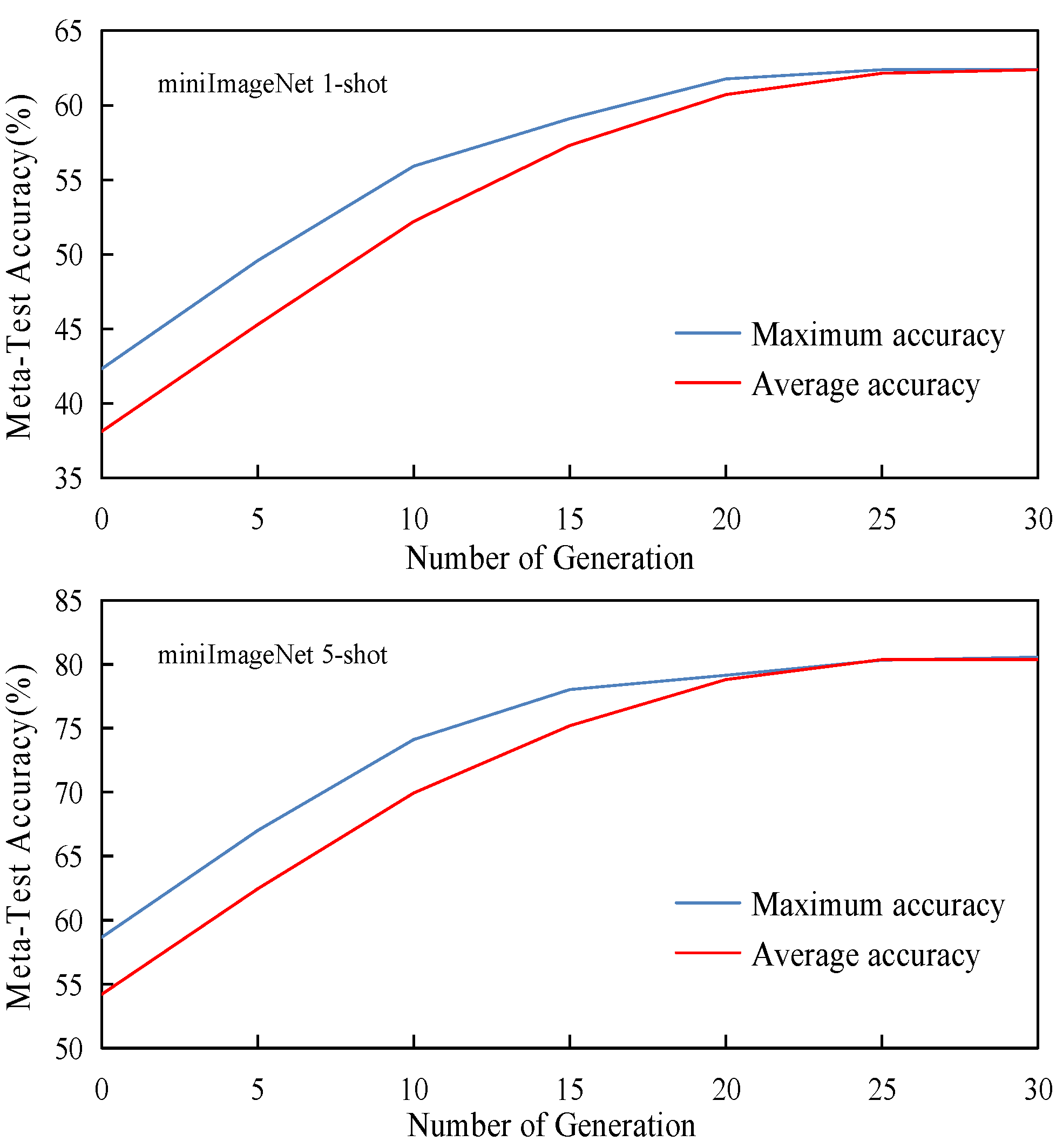
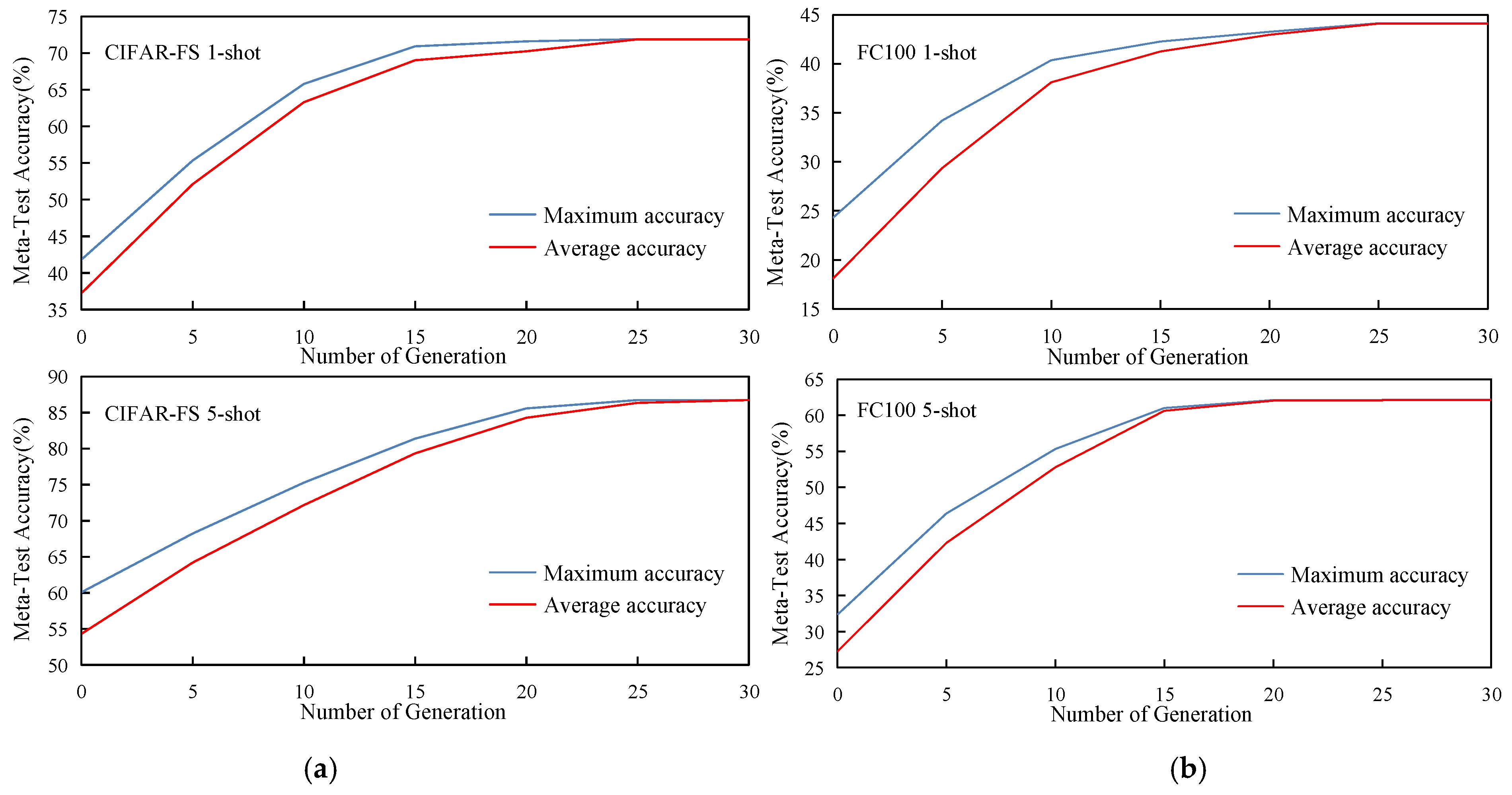
4.3. Results and Discussion
4.4. Ablation Study
4.4.1. Comparison of Different Feature Fusion Methods
4.4.2. Comparison of Different Classifiers
4.4.3. Comparison of Different Backbones
4.4.4. Comparison of Different Optimization Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Vanschoren, J. Meta-learning. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 35–61. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-learning: A survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-baseline: Exploring simple meta-learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Sunnyvale, CA, USA, 25 October 2021; pp. 9062–9071. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Karlinsky, L.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Pankanti, S.; Bronstein, A.M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5197–5206. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7260–7268. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning PMLR, York City, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Munkhdalai, T.; Yu, H. Meta networks. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 2554–2563. [Google Scholar]
- Cai, Q.; Pan, Y.; Yao, T.; Yan, C.; Mei, T. Memory matching networks for one-shot image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4080–4088. [Google Scholar]
- Kaiser, Ł.; Nachum, O.; Roy, A.; Bengio, S. Learning to remember rare events. arXiv 2017, arXiv:1703.03129. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Jamal, M.A.; Qi, G.-J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Sydney, Australia, 6–11 August 2019; pp. 11719–11727. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Ye, H.-J.; Hu, H.; Zhan, D.-C.; Sha, F. Learning embedding adaptation for few-shot learning. arXiv 2019, arXiv:1812.03664. [Google Scholar]
- Hao, F.; Cheng, J.; Wang, L.; Cao, J. Instance-level embedding adaptation for few-shot learning. IEEE Access 2019, 7, 100501–100511. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Krishnan, D.; Tenenbaum, J.B.; Isola, P. Rethinking few-shot image classification: A good embedding is all you need? In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 16 (Pt XIV), pp. 266–282. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, IEEE, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Yu, Y.; Li, Y.; Li, J. Parameter identification of a novel strain stiffening model for magnetorheological elastomer base isolator utilizing enhanced particle swarm optimization. J. Intell. Mater. Syst. Struct. 2015, 26, 2446–2462. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S.; Kim, S.; Cha, M.; Lee, J.K.; Choi, Y.; Choi, Y.; Cho, D.Y.; Kim, J. Auto-meta: Automated gradient based meta learner search. arXiv 2018, arXiv:1806.06927. [Google Scholar]
- Elsken, T.; Staffler, B.; Metzen, J.H.; Hutter, F. Meta-learning of neural architectures for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12365–12375. [Google Scholar]
- Zhou, F.; Wu, B.; Li, Z. Deep meta-learning: Learning to learn in the concept space. arXiv 2018, arXiv:1802.03596. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Henriques, J.F.; Torr, P.H.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. arXiv 2018, arXiv:1805.08136. [Google Scholar]
- Oreshkin, B.N.; Rodriguez, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. arXiv 2018, arXiv:1805.10123. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Torralba, A.; Fergus, R.; Freeman, W.T. 80 million tiny images: A large data set for nonparametric object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1958–1970. [Google Scholar] [CrossRef]
- Ketkar, N. Introduction to pytorch. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 195–208. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665. [Google Scholar]
- Allen, K.; Shelhamer, E.; Shin, H.; Tenenbaum, J. Infinite mixture prototypes for few-shot learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 232–241. [Google Scholar]
- Hao, F.; He, F.; Cheng, J.; Wang, L.; Cao, J.; Tao, D. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8460–8469. [Google Scholar]
- Li, A.; Luo, T.; Xiang, T.; Huang, W.; Wang, L. Few-shot learning with global class representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9715–9724. [Google Scholar]
- Peng, Z.; Li, Z.; Zhang, J.; Li, Y.; Qi, G.-J.; Tang, J. Few-shot image recognition with knowledge transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 441–449. [Google Scholar]
- Wu, Z.; Li, Y.; Guo, L.; Jia, K. PARN: Position-aware relation networks for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6659–6667. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4367–4375. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A simple neural attentive meta-learner. arXiv 2017, arXiv:1707.03141. [Google Scholar]
- Munkhdalai, T.; Yuan, X.; Mehri, S.; Trischler, A. Rapid adaptation with conditionally shifted neurons. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3664–3673. [Google Scholar]
- Ravichandran, A.; Bhotika, R.; Soatto, S. Few-shot learning with embedded class models and shot-free meta training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 331–339. [Google Scholar]
- Qiao, L.; Shi, Y.; Li, J.; Wang, Y.; Huang, T.; Tian, Y. Transductive episodic-wise adaptive metric for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3603–3612. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.-S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Zhang, J.; Zhao, C.; Ni, B.; Xu, M.; Yang, X. Variational few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1685–1694. [Google Scholar]
- Dvornik, N.; Schmid, C.; Mairal, J. Diversity with cooperation: Ensemble methods for few-shot classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3723–3731. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A baseline for few-shot image classification. arXiv 2019, arXiv:1909.02729. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | miniImageNet 5-Way | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| MAML [17] | 32-32-32-32 | 48.70 ± 1.84 | 63.11 ± 0.92 |
| Matching Networks [10] | 64-64-64-64 | 43.56 ± 0.84 | 55.31 ± 0.73 |
| IMP [39] | 64-64-64-64 | 49.2 ± 0.7 | 64.7 ± 0.7 |
| Prototypical Networks [8] | 64-64-64-64 | 49.42 ± 0.78 | 68.20 ± 0.66 |
| TAML [18] | 64-64-64-64 | 51.77 ± 1.86 | 66.05 ± 0.85 |
| SAML [40] | 64-64-64-64 | 52.22 ± n/a | 66.49 ± n/a |
| GCR [41] | 64-64-64-64 | 53.21 ± 0.80 | 72.34 ± 0.64 |
| KTN [42] | 64-64-64-64 | 54.61 ± 0.80 | 71.21 ± 0.66 |
| PARN [43] | 64-64-64-64 | 55.22 ± 0.84 | 71.55 ± 0.66 |
| Dynamic Few-shot [44] | 64-64-128-128 | 56.20 ± 0.86 | 73.00 ± 0.64 |
| Relation Networks [9] | 64-64-128-128 | 50.44 ± 0.82 | 65.32 ± 0.70 |
| R2D2 [33] | 96-192-384-512 | 51.2 ± 0.6 | 68.8 ± 0.1 |
| SNAIL [45] | ResNet-12 | 55.71 ± 0.99 | 68.88 ± 0.92 |
| AdaResNet [46] | ResNet-12 | 56.88 ± 0.62 | 71.94 ± 0.57 |
| TADAM [34] | ResNet-12 | 58.50 ± 0.30 | 76.70 ± 0.30 |
| Shot-Free [47] | ResNet-12 | 59.04 ± n/a | 77.64 ± n/a |
| TEWAM [48] | ResNet-12 | 60.07 ± n/a | 75.90 ± n/a |
| MTL [49] | ResNet-12 | 61.20 ± 1.80 | 75.50 ± 0.80 |
| Variational FSL [50] | ResNet-12 | 61.23 ± 0.26 | 77.69 ± 0.17 |
| MetaOptNet [38] | ResNet-12 | 62.64 ± 0.61 | 78.63 ± 0.46 |
| Diversityw/Cooperation [51] | ResNet-18 | 59.48 ± 0.65 | 75.62 ± 0.48 |
| Fine-tuning [52] | WRN-28-10 | 57.73 ± 0.62 | 78.17 ± 0.49 |
| LEO-trainval [53] | WRN-28-10 | 61.76 ± 0.08 | 77.59 ± 0.12 |
| GEFS [23] | ResNet-12 | 62.02 ± 0.63 | 79.64 ± 0.44 |
| Ours | ResNet-12 | 62.55 ± 0.81 | 80.57 ± 0.57 |
| Model | Backbone | CIFAR-FS 5-Way | FC100 5-Way | ||
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | ||
| MAML [17] | 32-32-32-32 | 58.9 ± 1.9 | 71.5 ± 1.0 | - | - |
| Prototypical Networks [8] | 64-64-64-64 | 55.5 ± 0.7 | 72.0 ± 0.6 | 35.3 ± 0.6 | 48.6 ± 0.6 |
| Relation Networks [9] | 64-64-128-128 | 55.0 ± 1.0 | 69.3 ± 0.8 | - | - |
| R2D2 [33] | 96-192-384-512 | 65.3 ± 0.2 | 79.4 ± 0.1 | - | - |
| TADAM [34] | ResNet-12 | - | - | 40.1 ± 0.4 | 56.1 ± 0.4 |
| Shot-Free [47] | ResNet-12 | 69.2 ± n/a | 84.7 ± n/a | - | - |
| TEWAM [48] | ResNet-12 | 70.4 ± n/a | 81.3 ± n/a | - | - |
| Prototypical Networks [8] | ResNet-12 | 72.2 ± 0.7 | 83.5 ± 0.5 | 37.5 ± 0.6 | 52.5 ± 0.6 |
| MetaOptNet [38] | ResNet-12 | 72.6 ± 0.7 | 84.3 ± 0.5 | 41.1 ± 0.6 | 55.5 ± 0.6 |
| GEFS [23] | ResNet-12 | 71.5 ± 0.8 | 86.0 ± 0.5 | 42.6 ± 0.7 | 59.1 ± 0.6 |
| Ours | ResNet-12 | 71.91 ± 0.85 | 86.77 ± 0.63 | 44.16 ± 0.77 | 62.17 ± 0.72 |
| Model | Backbone | MUB 5-Way | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| Ours-simple | MobileNet-V2 | 39.57 ± 2.42 | 52.92 ± 2.19 |
| Ours-fuse | MobileNet-V2 | 49.48 ± 2.05 | 68.25 ± 2.03 |
| Model | Backbone | miniImageNet 5-Way | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| Ours-channels | ResNet-12 | 62.25 ± 0.61 | 80.14 ± 0.42 |
| Ours-addition | ResNet-12 | 62.16 ± 0.58 | 79.83 ± 0.51 |
| Ours-fuse | ResNet-12 | 62.55 ± 0.81 | 80.57 ± 0.57 |
| Model | Backbone | CIFAR-FS 5-way | FC100 5-Way | ||
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | ||
| Ours-channels | ResNet-12 | 71.72 ± 0.8 | 86.32 ± 0.64 | 42.92 ± 0.71 | 59.8 ± 0.54 |
| Ours-addition | ResNet-12 | 71.67 ± 0.72 | 86.21 ± 0.59 | 42.81 ± 0.75 | 59.42 ± 0.67 |
| Ours-fuse | ResNet-12 | 71.91 ± 0.85 | 86.77 ± 0.63 | 44.16 ± 0.77 | 62.17 ± 0.72 |
| Classifier | CIFAR-FS 5-Way | FC100 5-Way | miniImageNet 5-Way | |||
|---|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| NN | 68.9 ± 0.86 | 81.82 ± 0.67 | 42.41 ± 0.75 | 57.92 ± 0.74 | 61.03 ± 0.83 | 73.85 ± 0.65 |
| SVM | 71.32 ± 0.88 | 83.96 ± 0.75 | 40.89 ± 0.75 | 58.43 ± 0.76 | 58.16 ± 0.78 | 74.58 ± 0.64 |
| Cosine | 68.9 ± 0.86 | 81.82 ± 0.67 | 42.41 ± 0.75 | 57.92 ± 0.74 | 61.03 ± 0.83 | 73.85 ± 0.65 |
| LR | 71.91 ± 0.85 | 86.77 ± 0.63 | 44.16 ± 0.77 | 62.17 ± 0.72 | 62.55 ± 0.81 | 80.57 ± 0.57 |
| Model | CIFAR-FS 5-Way | FC100 5-Way | ||
|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| ResNet-12 | 71.91 ± 0.85 | 86.77 ± 0.63 | 44.16 ± 0.77 | 62.17 ± 0.72 |
| SEResNet-12 | 72.31 ± 0.93 | 86.84 ± 0.59 | 44.58 ± 0.84 | 62.52 ± 0.68 |
| Model | miniImageNet 5-Way | |
|---|---|---|
| 1-Shot | 5-Shot | |
| ResNet-12 | 62.55 ± 0.81 | 80.57 ± 0.57 |
| SEResNet-12 | 62.81 ± 0.92 | 80.95 ± 0.62 |
| Optimization Method | Backbone | miniImageNet 5-Way | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| QGA | ResNet-12 | 62.29 ± 0.71 | 80.05 ± 0.52 |
| PSO | ResNet-12 | 62.55 ± 0.81 | 80.57 ± 0.57 |
| Optimization Method | Backbone | CIFAR-FS 5-Way | FC100 5-Way | ||
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | ||
| QGA | ResNet-12 | 71.72 ± 0.76 | 86.68 ± 0.94 | 44.02 ± 0.59 | 61.98 ± 0.64 |
| PSO | ResNet-12 | 71.91 ± 0.85 | 86.77 ± 0.63 | 44.16 ± 0.77 | 62.17 ± 0.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, E.; Chu, X.; Liu, Z.; Zhang, K.; Yu, Q. A Novel Hierarchical Adaptive Feature Fusion Method for Meta-Learning. Appl. Sci. 2022, 12, 5458. https://doi.org/10.3390/app12115458
Ding E, Chu X, Liu Z, Zhang K, Yu Q. A Novel Hierarchical Adaptive Feature Fusion Method for Meta-Learning. Applied Sciences. 2022; 12(11):5458. https://doi.org/10.3390/app12115458
Chicago/Turabian StyleDing, Enjie, Xu Chu, Zhongyu Liu, Kai Zhang, and Qiankun Yu. 2022. "A Novel Hierarchical Adaptive Feature Fusion Method for Meta-Learning" Applied Sciences 12, no. 11: 5458. https://doi.org/10.3390/app12115458
APA StyleDing, E., Chu, X., Liu, Z., Zhang, K., & Yu, Q. (2022). A Novel Hierarchical Adaptive Feature Fusion Method for Meta-Learning. Applied Sciences, 12(11), 5458. https://doi.org/10.3390/app12115458