
Multi-Head TrajectoryCNN: A New Multi-Task Framework for Action Prediction


Abstract
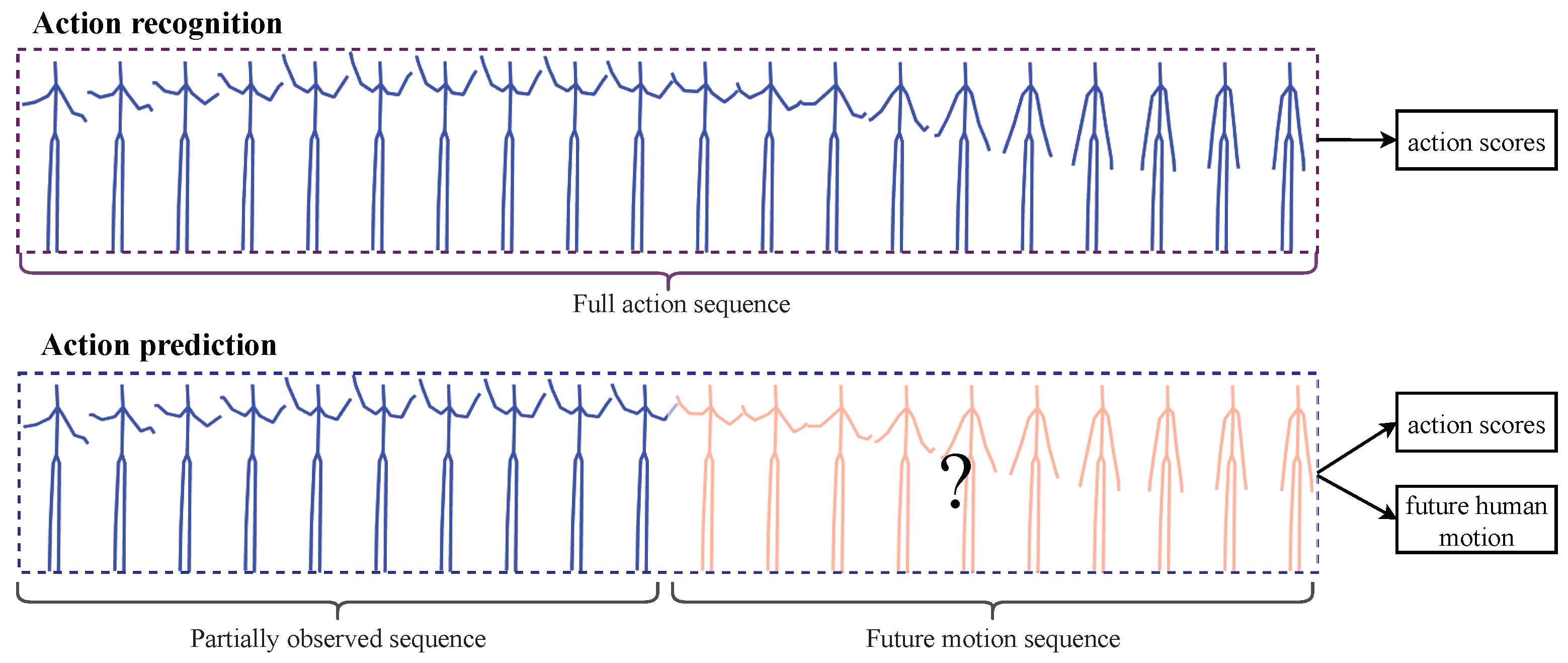
:1. Introduction
- (1)
- We improve the model performance of human motion prediction utilizing action semantics, which helps reduce the uncertainty of future movements.
- (2)
- We propose a new multi-task framework (i.e., Multi-head TrajectoryCNN) to jointly predict the action semantics and human motion of future motion dynamics. Different tasks of action prediction are incorporated in a unified model, which associates these tasks to improve their performance with each other.
- (3)
- Experiments on the NTU RGB+D dataset show the state-of-art performance, proving the effectiveness of our proposed method. The experimental results also show that the action semantics can greatly help predict accurate future poses, and the average errors of our method reduce by 10.12 mm and 11.07 mm per joint for CV and CS protocols.
2. Related Work
2.1. Human Motion Prediction
2.2. Action Semantic Prediction
2.3. Multi-Task Framework for Human Activity Analysis
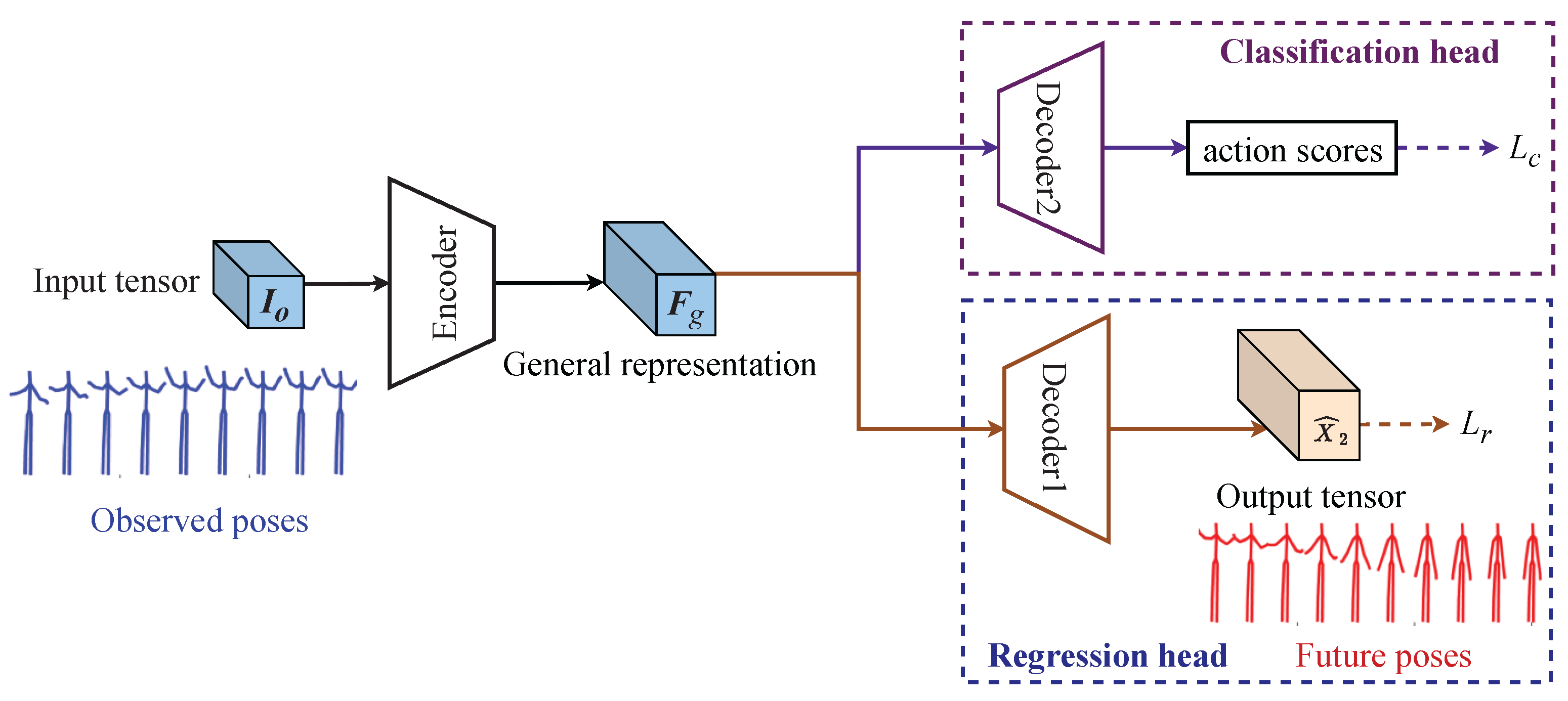
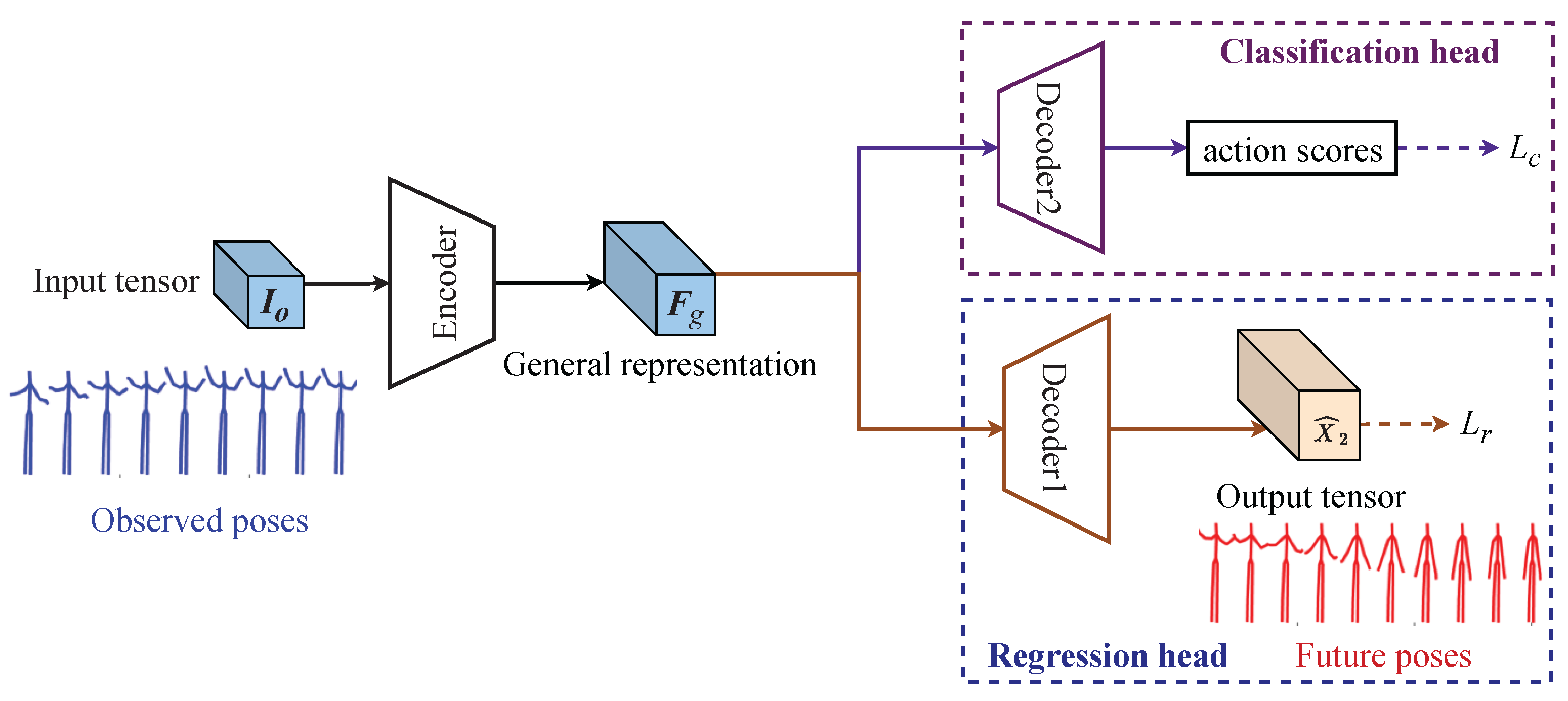
3. Methodology
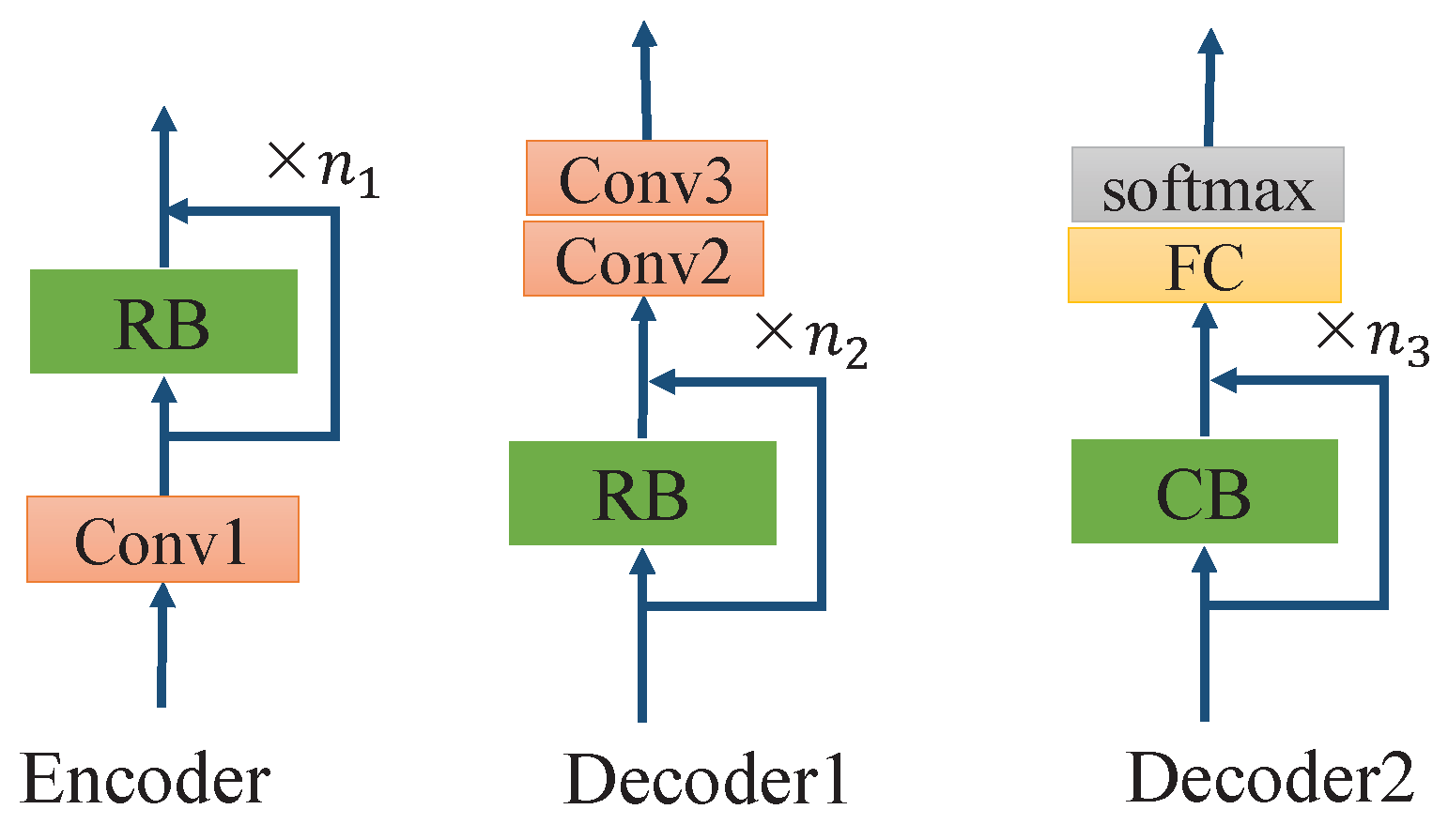
3.1. Backbone Layers
3.2. Network Structure
3.3. Loss
4. Experiments
4.1. Dataset and Implementation Settings
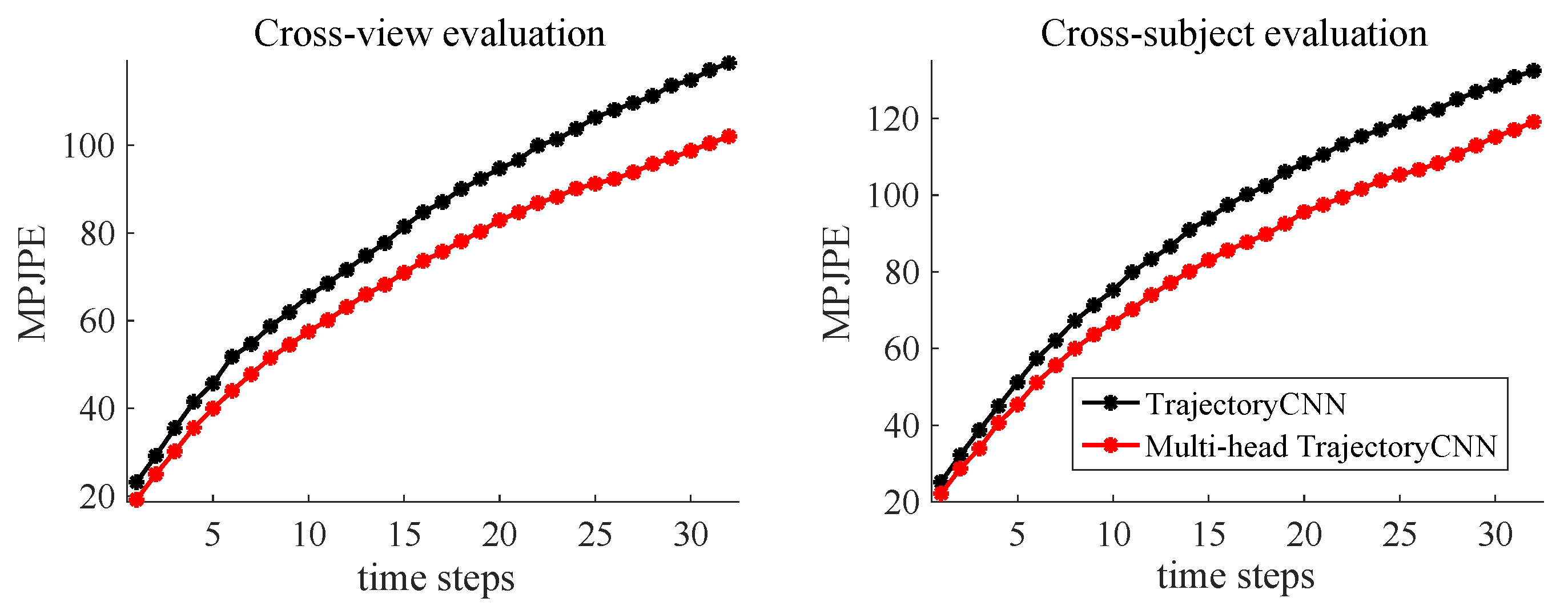
4.2. Comparison with State-of-the-Art
4.3. Ablative Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, H.; Wildes, R.P. Review of Video Predictive Understanding: Early Action Recognition and Future Action Prediction. arXiv 2021, arXiv:2107.05140. [Google Scholar]
- Barsoum, E.; Kender, J.; Liu, Z. Hp-gan: Probabilistic 3d human motion prediction via gan. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kundu, J.N.; Gor, M.; Babu, R.V. Bihmp-gan: Bidirectional 3d human motion prediction gan. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Butepage, J.; Black, M.J.; Kragic, D.; Kjellstrom, H. Deep representation learning for human motion prediction and classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, M.; Chen, S.; Zhao, Y.; Zhang, Y.; Wang, Y.; Tian, Q. Dynamic multiscale graph neural networks for 3d skeleton based human motion prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sun, C.; Shrivastava, A.; Vondrick, C.; Sukthankar, R.; Murphy, K.; Schmid, C. Relational action forecasting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Hu, J.F.; Lai, J.; Zhang, J.; Zheng, W.S. Progressive teacher-student learning for early action prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, X.; Yin, J.; Liu, J.; Ding, P.; Liu, J.; Liu, H. Trajectorycnn: A new spatio-temporal feature learning network for human motion prediction. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2133–2146. [Google Scholar] [CrossRef]
- Fragkiadaki, K.; Levine, S.; Felsen, P.; Malik, J. Recurrent network models for human dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Martinez, J.; Black, M.J.; Romero, J. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gui, L.Y.; Wang, Y.X.; Ramanan, D.; Moura, J.M.F. Few-shot human motion prediction via meta-learning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chiu, H.; Adeli, E.; Wang, B.; Huang, D.A.; Niebles, J.C. Action-agnostic human pose forecasting. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Honolulu, HI, USA, 7–11 January 2019. [Google Scholar]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Structural-rnn: Deep learning on spatio-temporal graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, H.; Dong, J.; Cheng, B.; Feng, J. PVRED: A Position-Velocity Recurrent Encoder-Decoder for Human Motion Prediction. IEEE Trans. Image Process. 2021, 30, 6096–6106. [Google Scholar] [CrossRef] [PubMed]
- Pavllo, D.; Feichtenhofer, C.; Auli, M.; Grangier, D. Modeling human motion with quaternion-based neural networks. Int. J. Comput. Vis. 2020, 128, 855–872. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, Z.; Yang, X.; Wang, M.; Poiana, S.; Chaudhry, E.; Zhang, J. Efficient convolutional hierarchical autoencoder for human motion prediction. Vis. Comput. 2019, 35, 1143–1156. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Zhang, Z.; Lee, W.S.; Lee, G.H. Convolutional sequence to sequence model for human dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mao, W.; Liu, M.; Salzmann, M. History repeats itself: Human motion prediction via motion attention. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Mao, W.; Liu, M.; Salzmann, M.; Li, H. Learning trajectory dependencies for human motion prediction. In Proceedings of the IEEE International Conference on Computer Vision 2019, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Cui, Q.; Sun, H.; Yang, F. Learning dynamic relationships for 3d human motion prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kong, Y.; Gao, S.; Sun, B.; Fu, Y. Action prediction from videos via memorizing hard-to-predict samples. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Ma, L.; Wang, G.; Lai, J.; Zhang, J. Early action prediction by soft regression. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2568–2583. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadegh Aliakbarian, M.; Sadat Saleh, F.; Salzmann, M.; Fernando, B. Encouraging lstms to anticipate actions very early. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, L.; Lu, J.; Song, Z.; Zhou, J. Part-activated deep reinforcement learning for action prediction. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wu, X.; Wang, R.; Hou, J.; Lin, H.; Luo, J. Spatial–temporal relation reasoning for action prediction in videos. Int. J. Comput. Vis. 2021, 129, 1484–1505. [Google Scholar] [CrossRef]
- Chen, J.; Bao, W.; Kong, Y. Group activity prediction with sequential relational anticipation model. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Wang, B.; Huang, L.; Hoai, M. Active vision for early recognition of human actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 16 June 2020. [Google Scholar]
- Gammulle, H.; Denman, S.; Sridharan, S.; Fookes, C. Predicting the future: A jointly learnt model for action anticipation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Pang, G.; Wang, X.; Hu, J.; Hu, J.F.; Zhang, Q.; Zheng, W.S. DBDNet: Learning Bi-directional Dynamics for Early Action Prediction. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Fernando, B.; Herath, S. Anticipating human actions by correlating past with the future with Jaccard similarity measures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Ma, L.; Wang, G.; Lai, J. Real-time RGB-D activity prediction by soft regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Kong, Y.; Tao, Z.; Fu, Y. Deep sequential context networks for action prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cai, Y.; Li, H.; Hu, J.F.; Zheng, W.S. Action knowledge transfer for action prediction with partial videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Cai, H.; Bai, C.; Tai, Y.W.; Tang, C.K. Deep video generation, prediction and completion of human action sequences. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mahmud, T.; Hasan, M.; Roy-Chowdhury, A.K. Joint prediction of activity labels and starting times in untrimmed videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhao, H.; Wildes, R.P. On diverse asynchronous activity anticipation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liao, D.; Liu, W.; Zhong, Y.; Li, J.; Wang, G. Predicting Activity and Location with Multi-task Context Aware Recurrent Neural Network. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Guan, J.; Yuan, Y.; Kitani, K.M.; Rhinehart, N. Generative hybrid representations for activity forecasting with no-regret learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 16 June 2020. [Google Scholar]
- Liu, M.; Tang, S.; Li, Y.; Rehg, J.M. Forecasting human-object interaction: Joint prediction of motor attention and actions in first person video. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, B.; Tian, J.; Zhang, Z.; Feng, H.; Li, X. Multitask non-autoregressive model for human motion prediction. IEEE Trans. Image Process. 2020, 30, 2562–2574. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Symbiotic graph neural networks for 3d skeleton-based human action recognition and motion prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CV | CS | ||
|---|---|---|---|---|
| Accuracy | Average Error | Accuracy | Average Error | |
| TrajectoryCNN | - | 80.97 | - | 91.78 |
| TrajectoryCNN-classification | 67.74% | - | 60.22% | - |
| Multi-head TrajectoryCNN (Ours) | 74.55% (+6.81%) | 70.85 (+10.12) | 63.82% (+3.6%) | 80.71 (+11.07) |
| Model | Accuracy | Average Error |
|---|---|---|
| w/o CB | 69.44% | 70.64 |
| w/o RH | 66.11% | - |
| w/o CH | - | 71.15 |
| Multi-head TrajectoryCNN | 74.55% | 70.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yin, J. Multi-Head TrajectoryCNN: A New Multi-Task Framework for Action Prediction. Appl. Sci. 2022, 12, 5381. https://doi.org/10.3390/app12115381
Liu X, Yin J. Multi-Head TrajectoryCNN: A New Multi-Task Framework for Action Prediction. Applied Sciences. 2022; 12(11):5381. https://doi.org/10.3390/app12115381
Chicago/Turabian StyleLiu, Xiaoli, and Jianqin Yin. 2022. "Multi-Head TrajectoryCNN: A New Multi-Task Framework for Action Prediction" Applied Sciences 12, no. 11: 5381. https://doi.org/10.3390/app12115381
APA StyleLiu, X., & Yin, J. (2022). Multi-Head TrajectoryCNN: A New Multi-Task Framework for Action Prediction. Applied Sciences, 12(11), 5381. https://doi.org/10.3390/app12115381