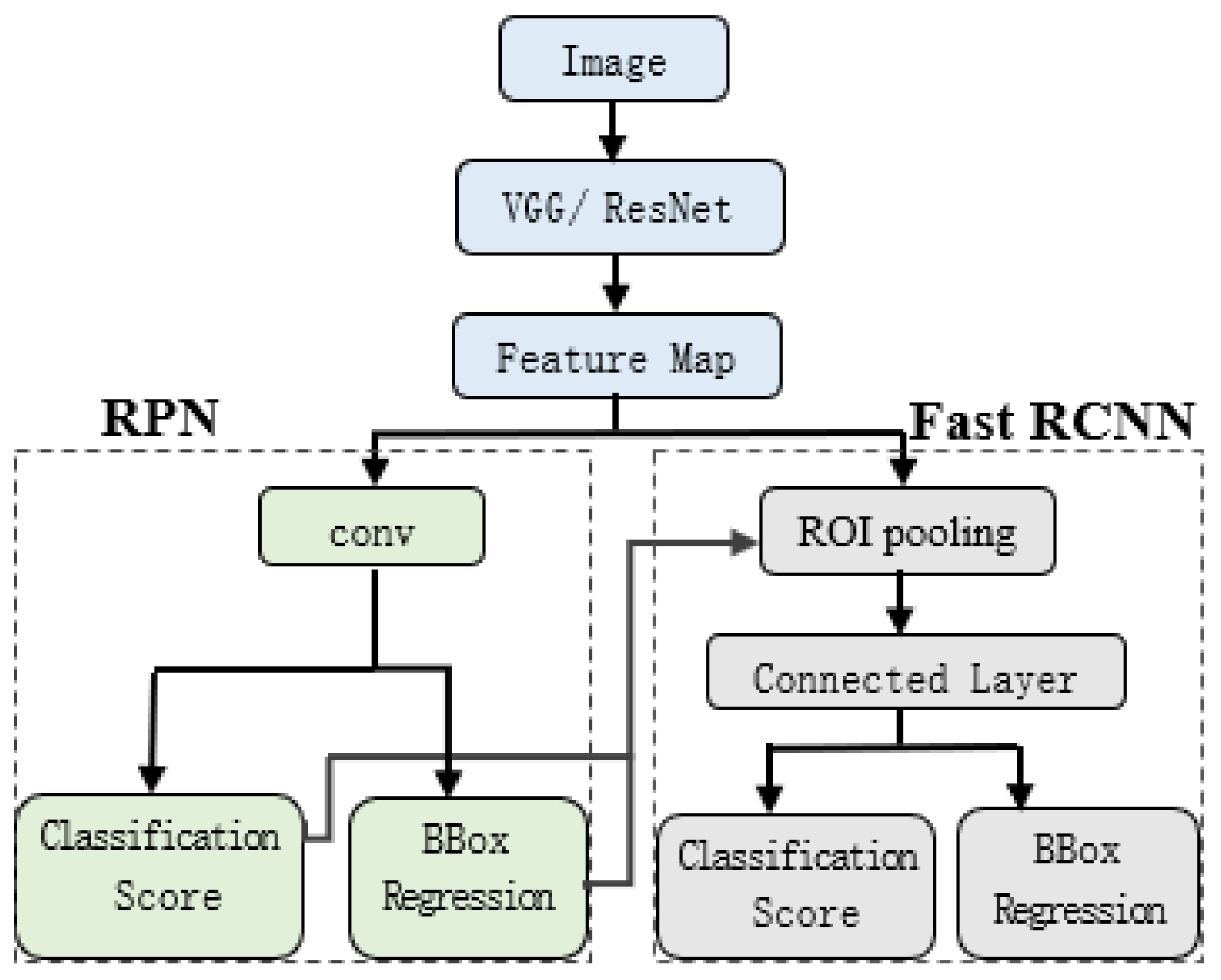
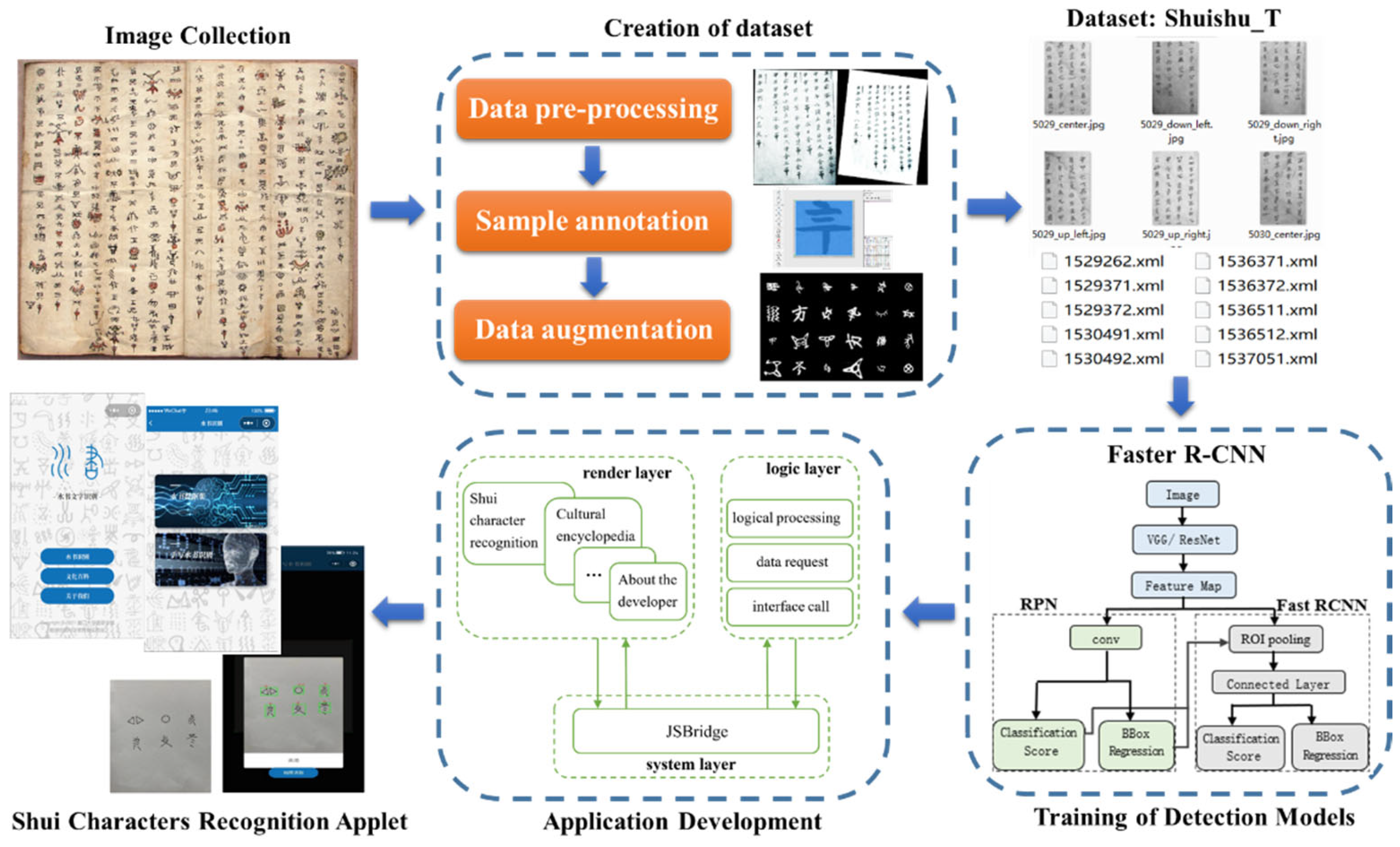
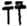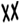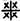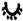3.1. Data Preparation
To create Shuishu_T, we visited libraries, museums, and areas where the Shui people live multiple times and also visited Shui manuscript experts. We collected a total of 1911 scanned images of Shui manuscripts from multiple volumes. The images of ancient Shui manuscripts are all stored in “.jpg” format with an average resolution of 1943 × 2924 pixels. The raw images of Shui manuscripts are not directly usable for experiments and require image correction, binarization, and noise reduction. In addition, the Shui manuscripts are very unusual and more difficult to read than other ethnic scripts, and only a very small number of Mr. Shuishu, who make up less than 5 in 10,000 people, can read them.
At present, there are more than 500 single characters in Shui manuscripts that can be read, and many characters exist in different volumes of Shui manuscripts, including more than 2000 characters in different forms. Various variants of the same type of character can also appear on the same page. As shown in
Figure 1, this is a relatively common occurrence, where two variants of the character “jia” appear on the same page of a Shui manuscript. Consequently, it is necessary to communicate with experts for confirmation when labeling, and it is not possible to hand over to a labeling company for bulk labeling. This makes it extremely difficult to create a dataset.
After manual labeling, 1734 images with labels were obtained, comprising 111 categories and a total of 91,127 characters. Statistics on the labeled Shui manuscript images show that the number of samples in each category is extremely unbalanced. Among them, the category with the smallest number of samples is “
![Applsci 12 05361 i001]()
”, with only one sample; the category with the largest number of samples is “
![Applsci 12 05361 i002]()
”, with 7524 samples. Some categories had very small sample sizes that could not support the training of the model and required data augmentation. For classes with small sample sizes, we used several data augmentation methods, such as manual handwriting, image synthesis, and image cropping.
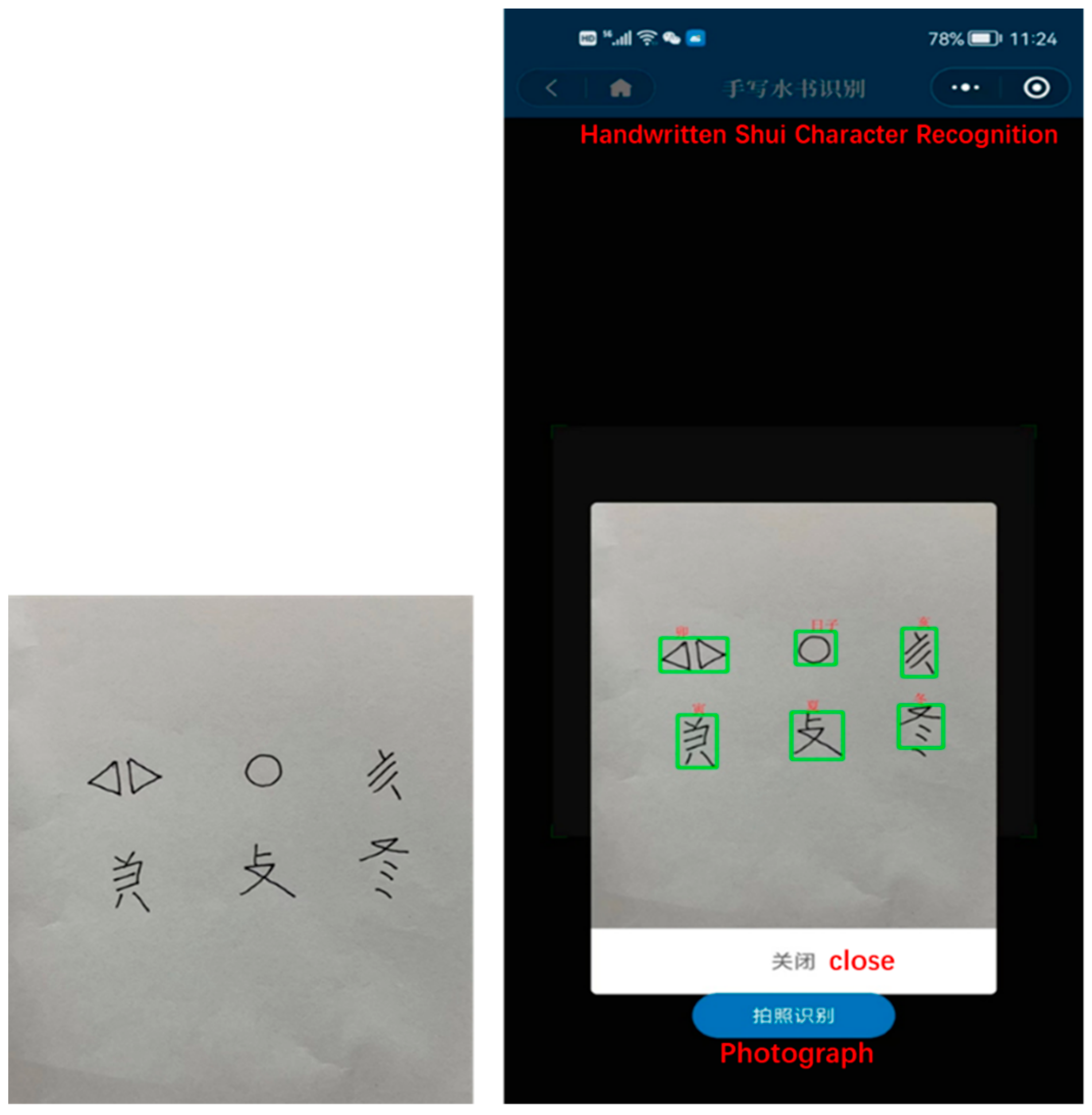
First, manual handwriting data amplification was performed for the category of Shui manuscripts with a sample size of less than 300, and 51 handwritten Shui manuscript images were obtained with a total of 12,651 character samples after 20 handwriting amplifications by different volunteers. Although the manual handwriting amplification method is simple, it has the disadvantages of low efficiency and high cost.
Figure 2 shows the image obtained via the manual handwriting method, and
Table 1 compares the sample size before and after handwriting amplification in some categories.
Second, for target samples that would not be ambiguous after orientation transformation, we used image synthesis to augment the data. A single character slicing operation was performed on the 60 classes with a sample size of less than 500 in Shui manuscript images. Subsequently, binarization, rotation, flipping, and noise addition were performed on the sliced characters. Finally, the sliced characters were randomly combined. Through the image synthesis operation, we obtained 1600 images with an average size of 1200 × 1800 pixels, containing 38,383 character samples. These character samples contained various scenes, such as different text orientations or various noises. The data are thus diverse, which can enhance the generalization ability of the model and prevent overfitting.
Figure 3 shows the image obtained via the image synthesis method.
Third, we cropped 1734 original images and 51 images added by manual handwriting, using the top, bottom, left, right, and center positions as loci of action. With the cropping method, we obtained 10,583 Shui manuscript images with an average size of 1002 × 1509 pixels, containing 126,406 character samples.
Figure 4 shows the image obtained via the image cropping method.
Finally, the well-labeled and sizable Shuishu_T contained 10,583 text images with labels, with the average size of the images being 1002 × 1509 pixels, for a total of 164,789 samples of Shui manuscript characters in 111 categories. Among them, there are seven categories with fewer than 500 samples, accounting for 6%; a further 37 categories with 500 to 1000 samples, accounting for 33%; and 67 categories with more than 1000 samples, accounting for 61%. As shown in
Table 2, Shuishu_T is larger and contains more samples than the known Shui manuscripts character datasets. We discuss the effectiveness of our proposed data enhancement method through ablation experiments in
Section 4.3.
3.2. Target Detection Models
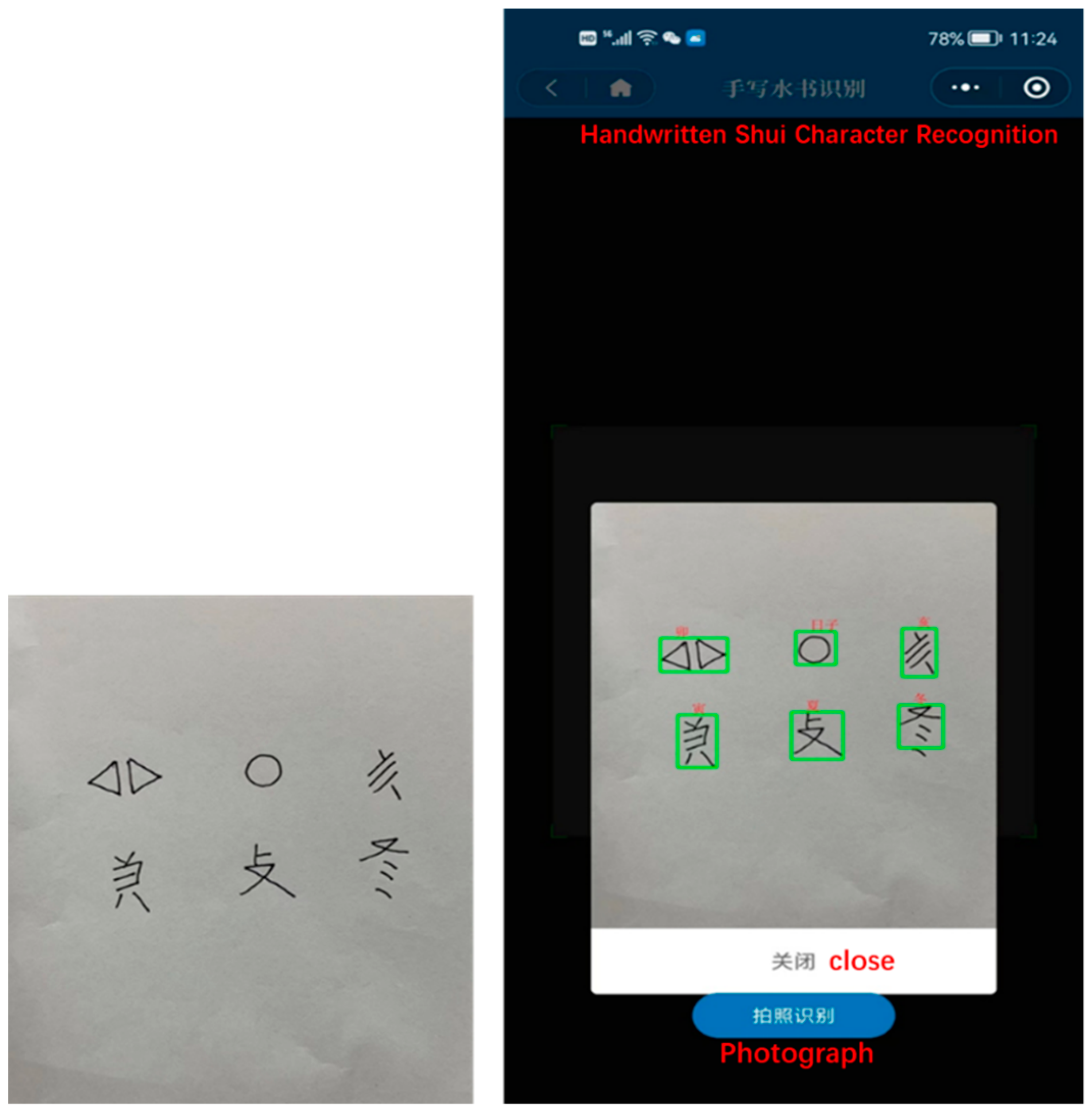
The aim of target detection is to detect whether an image contains certain targets and to identify and locate those targets accurately; it is an application direction in the field of computer vision. The most popular target detection algorithms can be divided into two classes. The first class of algorithms is called “two-step” detection algorithms, in which a dense set of candidate regions is first sampled on the feature map, and then the candidate regions are classified and regressed with high detection accuracy, typically by region-based CNN (R-CNN) [
16], Fast R-CNN [
17], or Faster R-CNN. The other class of algorithms is called “one-step” detection; i.e., direct sampling and regression on a multi-layer feature map, generating the class probability and location coordinate values of the object and outputting them in a single step, which is fast. Typical algorithms include you only look once (YOLO) [
18] and single shot multibox detector (SSD) [
19].
R-CNN, proposed by Girshick et al. in 2014, is one of the first algorithms to apply deep learning techniques to target detection. The data features of the candidate regions are synthesized and classified using a support vector machine. Compared with some traditional algorithms for target detection, R-CNN replaces the feature extraction part with a deep neural network, which is a breakthrough in terms of accuracy and speed. However, the method is computationally overloaded and trades off a large amount of resources and runtime for improved accuracy.
Fast R-CNN is an upgraded version of R-CNN that adds a region of interest (ROI) pooling layer after the last convolutional layer of the CNN. This allows each input image of the network to be of arbitrary size and only one feature extraction for each image, greatly improving efficiency. In addition, Fast R-CNN uses Softmax instead of support vector machines for multi-task classification, which significantly improves the target detection efficiency again. However, it has the problem of time-consuming selection of candidate regions.
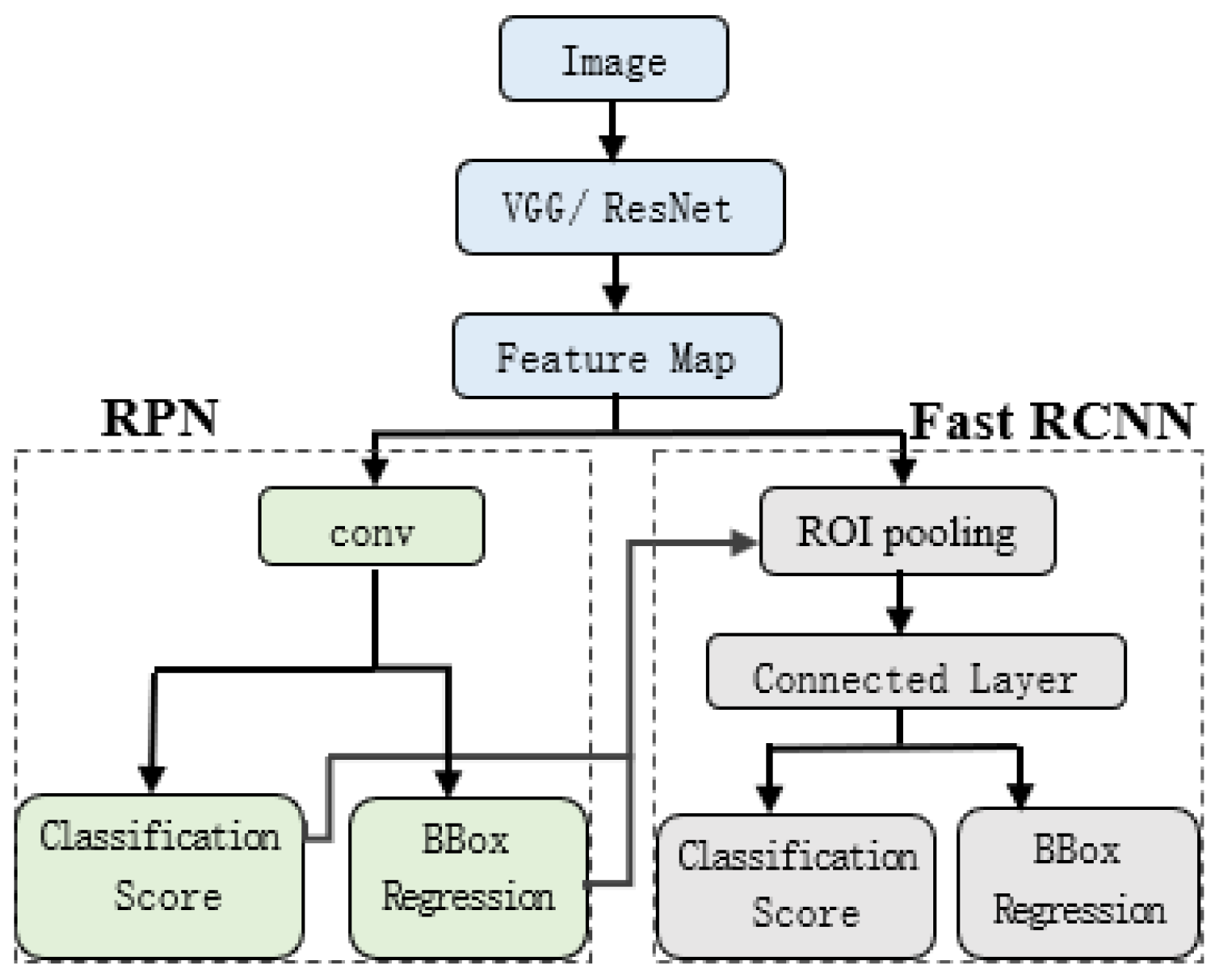
The main feature of Faster R-CNN, published in 2017, is the change of the candidate region extraction method, i.e., the use of the region proposal network (RPN), which allows CNNs to generate candidate regions directly, instead of the selective search method used previously. The RPN can automatically extract candidate regions quickly and efficiently, and the alternating training method of RPN and Fast R-CNN can improve the accuracy of target detection while greatly reducing the time spent on target detection. The overall process can be categorized into four steps: candidate region generation, feature extraction, classification, and position refinement. The overall structure of the Faster R-CNN is shown in
Figure 5.
The core idea of YOLO is to solve the object detection problem as a regression problem, using the whole image as the input to the network, and training and detecting in one network throughout. Published in 2016, YOLO has undergone multiple generations: YOLOv1, YOLOv2 [
20], YOLOv3 [
21], YOLOv4 [
22], and YOLOv5. YOLOv1 directly predicts candidate frame locations, creatively combining recognition and localization into one. YOLOv2 uses offset prediction to speed up the convergence of the network. YOLOv3 provides two major improvements, namely, the use of residual models to deepen the backbone network and the use of the feature pyramid network (FPN) architecture for multi-scale detection. YOLOv4 uses cross stage partial darknet (CSP-Darknet) as the backbone network, which reduces model parameters, enhances rich feature information with Mosaic data, increases the number of positive samples with neighborhood positive sample candidate frame matching calculation, and converges the network more. YOLOv5 enhances the feature fusion capability based on YOLOv4 with the HardWish activation function and provides more flexible parameter configuration to improve the small object detection performance.
SSD, published in 2016, combines the candidate frame mechanism and regression ideas of Faster R-CNN and YOLO to regress different features at multiple scales of regions at different locations in images, extract and analyze these features in layers, and perform computational operations such as scale regression and feature classification of borders in turn. Ultimately, it completes the training and detection tasks for targets in multiple regions of different scales. The SSD algorithm improves the target detection accuracy without affecting the speed. However, because the default box shape and grid size of this algorithm are predetermined, the detection effect for small targets is still unsatisfactory.



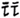 ”, with only one sample; the category with the largest number of samples is “
”, with only one sample; the category with the largest number of samples is “  ”, with 7524 samples. Some categories had very small sample sizes that could not support the training of the model and required data augmentation. For classes with small sample sizes, we used several data augmentation methods, such as manual handwriting, image synthesis, and image cropping.
”, with 7524 samples. Some categories had very small sample sizes that could not support the training of the model and required data augmentation. For classes with small sample sizes, we used several data augmentation methods, such as manual handwriting, image synthesis, and image cropping.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}