
A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset

 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
- We implemented a speech emotion recognizer using a pre-trained xlsr-Wav2Vec 2.0 model on an English speech-to-text task. We analyzed the performance reached using two transfer-learning techniques: feature extraction and fine-tuning.
- This work also incorporated visual information, which is a rarely used modality on RAVDESS (‘The Ryerson Audio-Visual Database of Emotional Speech and Song’) due to the difficulties associated with working with videos. However, our results showed it is a valuable source of information that should be explored to improve current emotion recognizers. We designed a facial emotion recognizer using Action Units as features and evaluated them on two models: static and sequential.
- To our knowledge, our study is the first that assembles the posteriors of a fine-tuned audio transformer with the posteriors extracted from the visual information of the models trained with the Action Units on the RAVDESS dataset.
- We also leveraged our code to allow the replication of our results and the set-up of our experiments. In this way, we expect to create a common framework to compare contributions and models’ performance on the RAVDESS dataset. We decided to continue with the formulation of our previous paper of Luna-Jiménez et al. [13] that consisted of a subject-wise 5-CV technique based on the eight emotions captured in the RAVDESS dataset.
2. Related Work
2.1. Speech Emotion Recognition
2.2. Facial Emotion Recognition
2.3. Multimodal Emotion Recognition
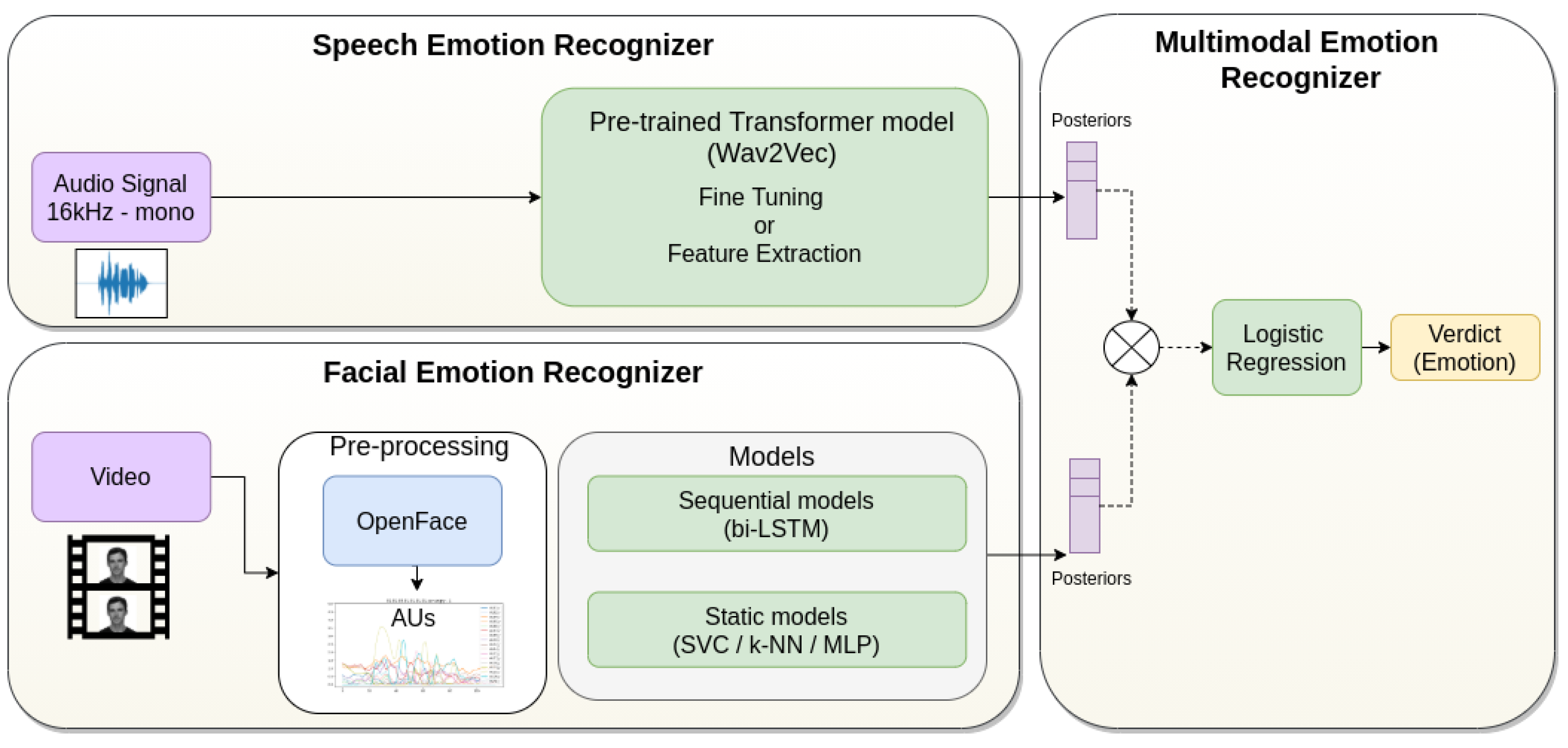
3. Methodology
3.1. The Dataset and Evaluation
- Fold 0: (2, 5, 14, 15, 16);
- Fold 1: (3, 6, 7, 13, 18);
- Fold 2: (10, 11, 12, 19, 20);
- Fold 3: (8, 17, 21, 23, 24);
- Fold 4: (1, 4, 9, 22).
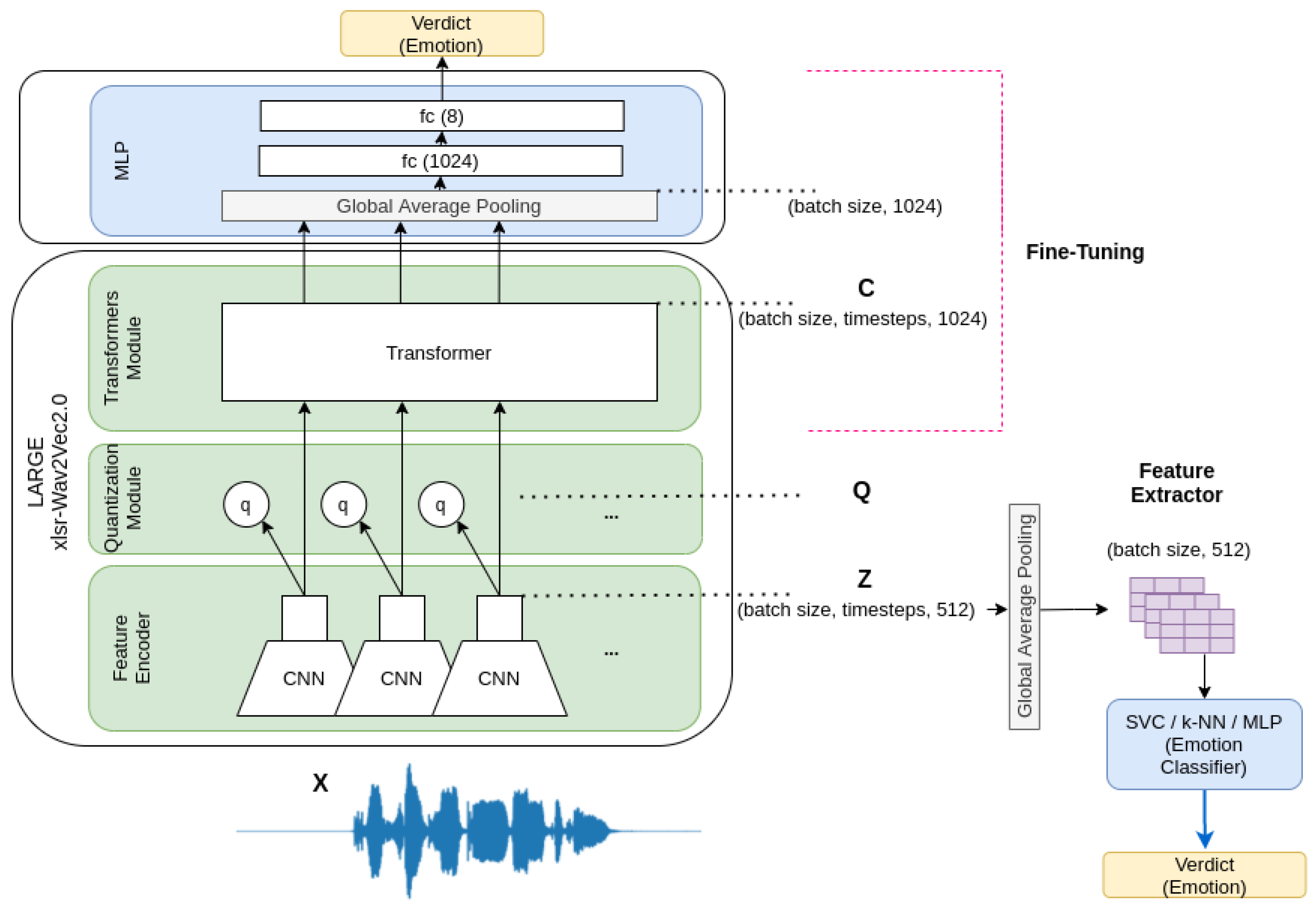
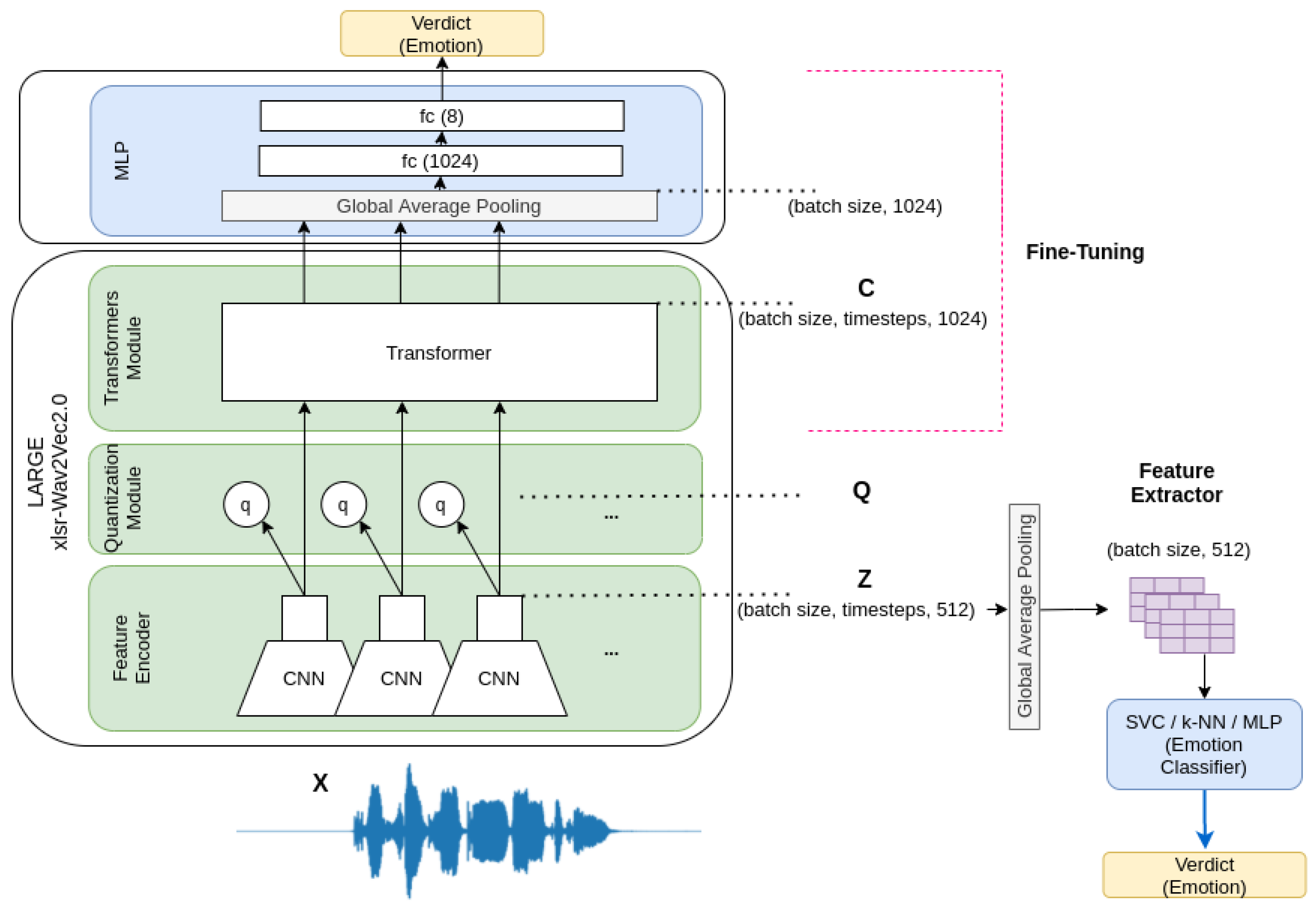
3.2. Speech Emotion Recognizer
3.2.1. Feature Extraction
3.2.2. Fine-Tuning
3.3. Facial Emotion Recognizer
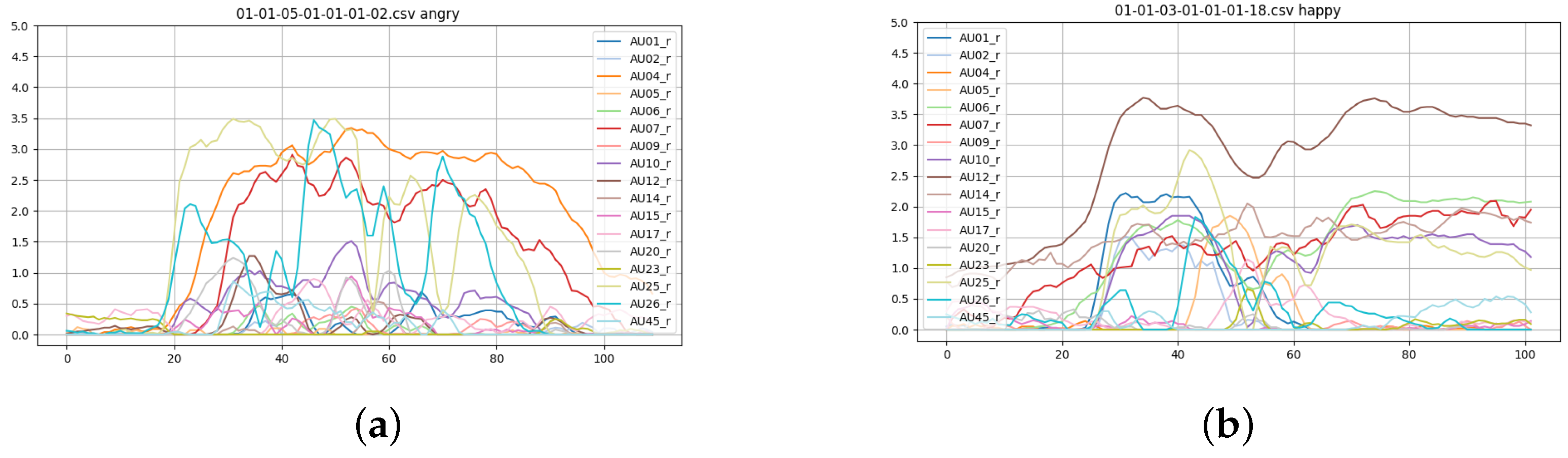
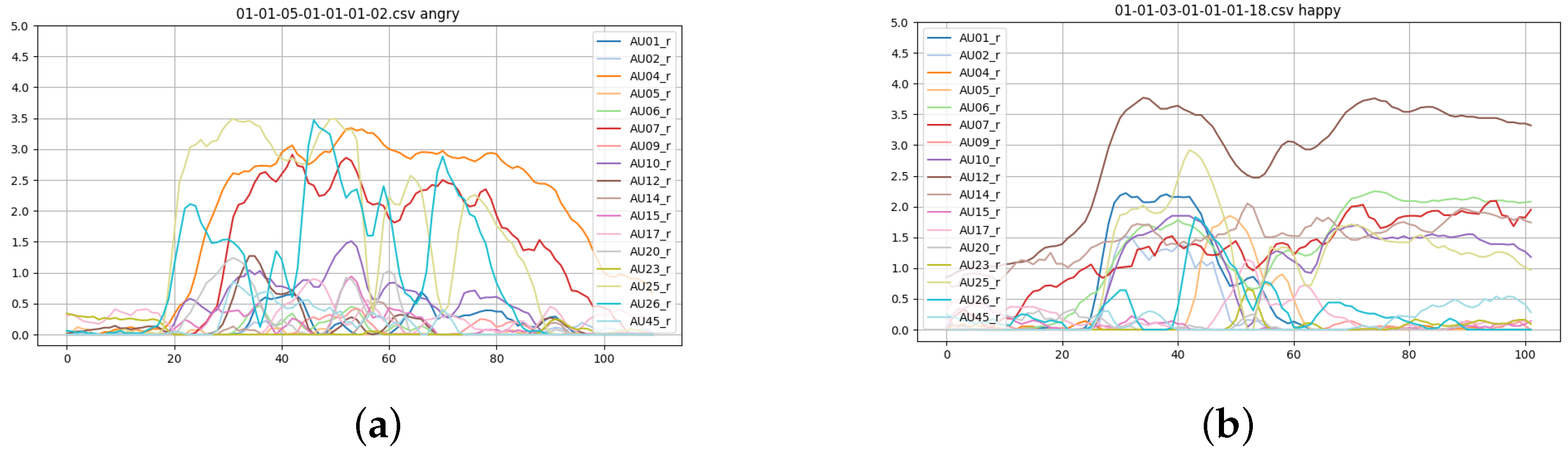
3.3.1. AUs Extraction
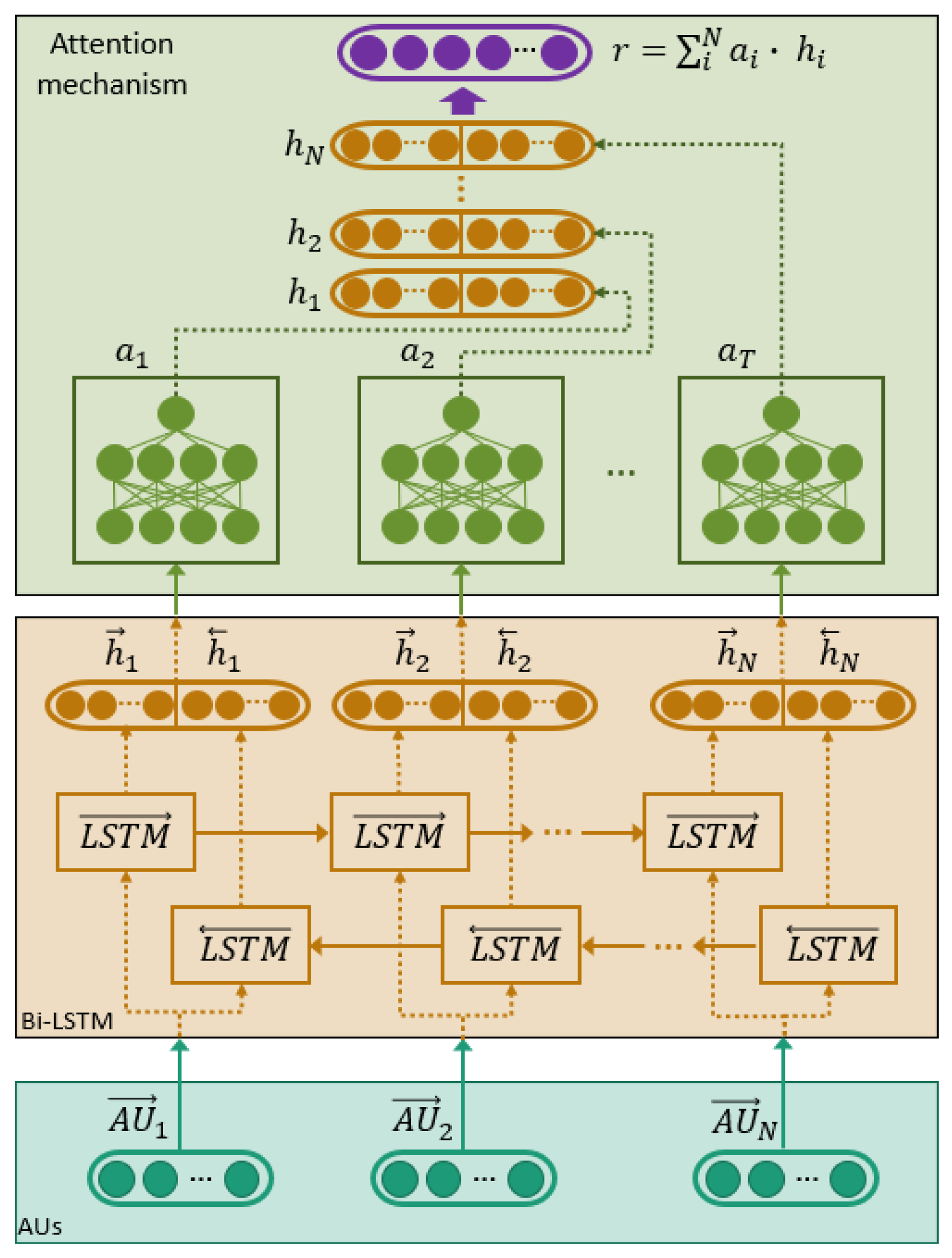
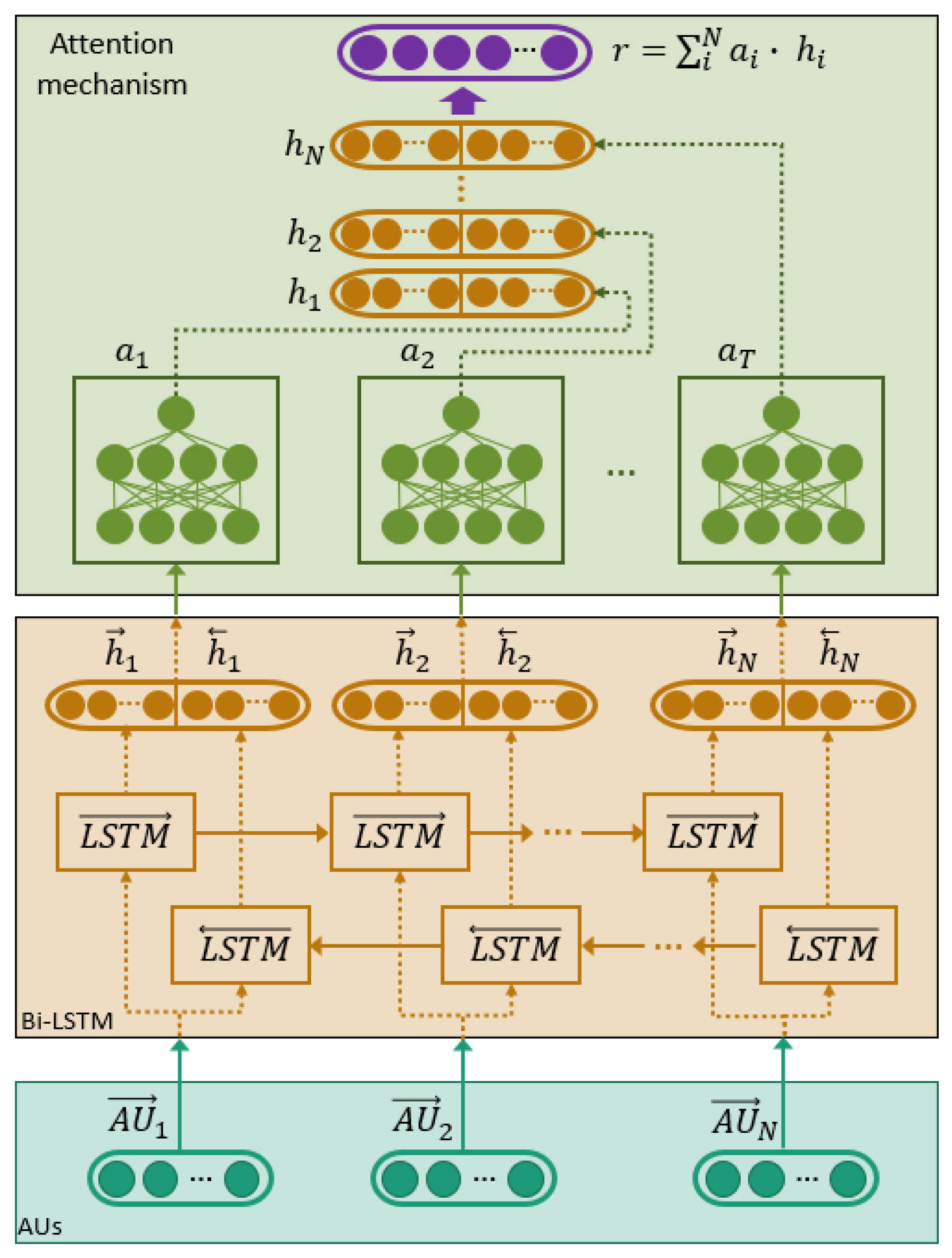
3.3.2. Static vs. Sequential Models
3.4. Multimodal Recognizer
4. Experiments
4.1. Speech Emotion Recognizer Setup
4.1.1. Facial Emotion Recognizer Setup
4.1.2. Multimodal Emotion Recognizer Setup
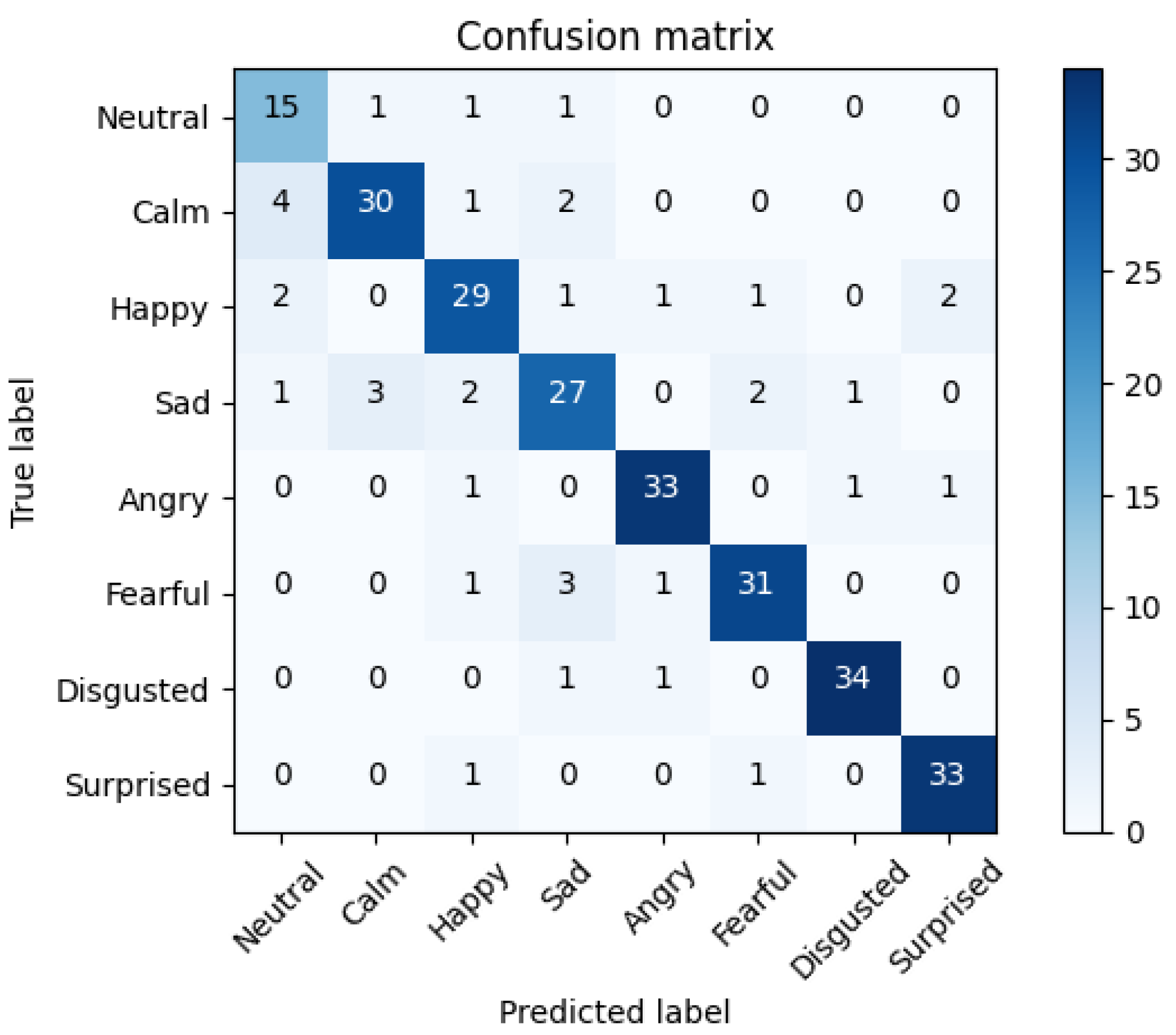
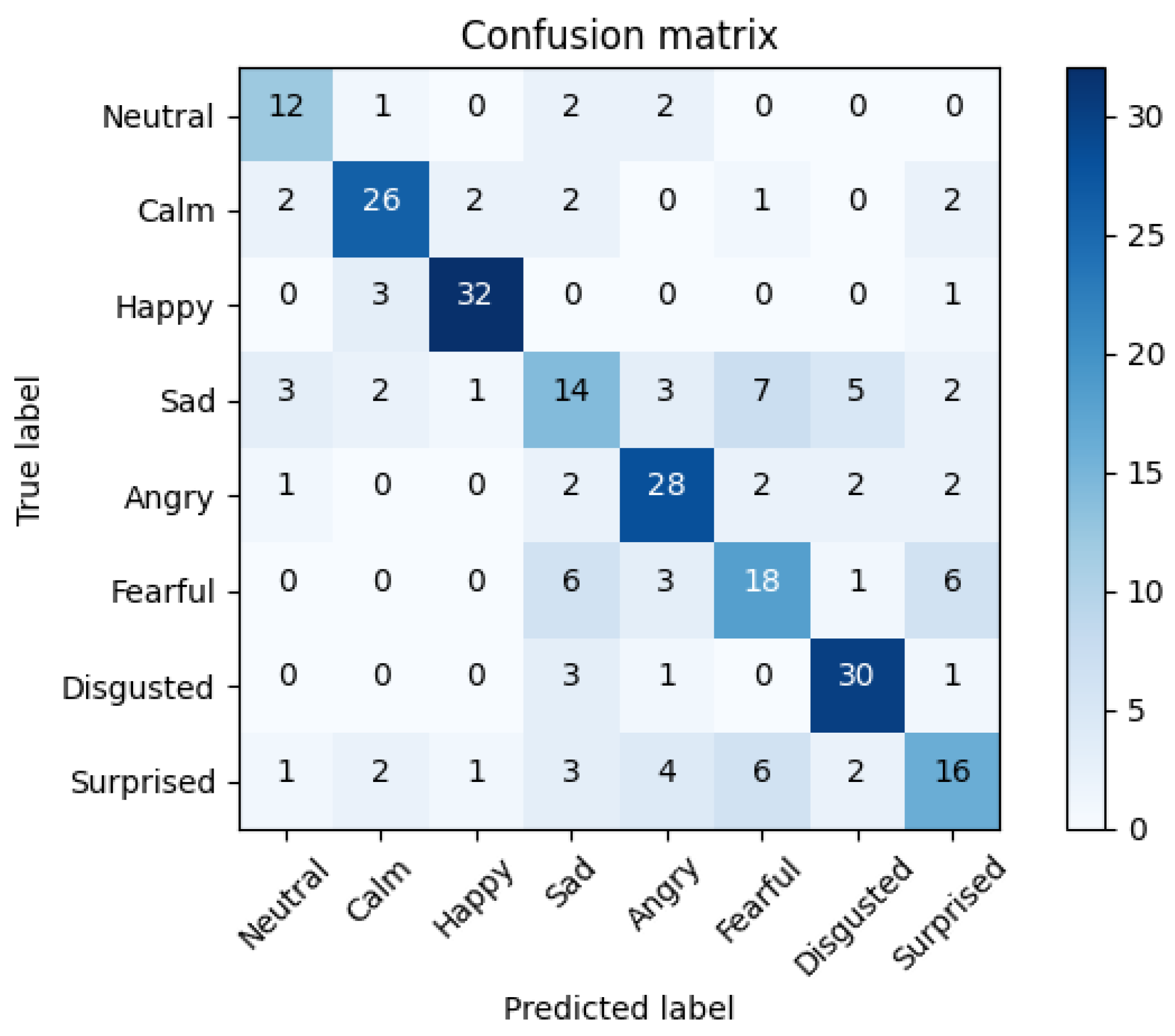
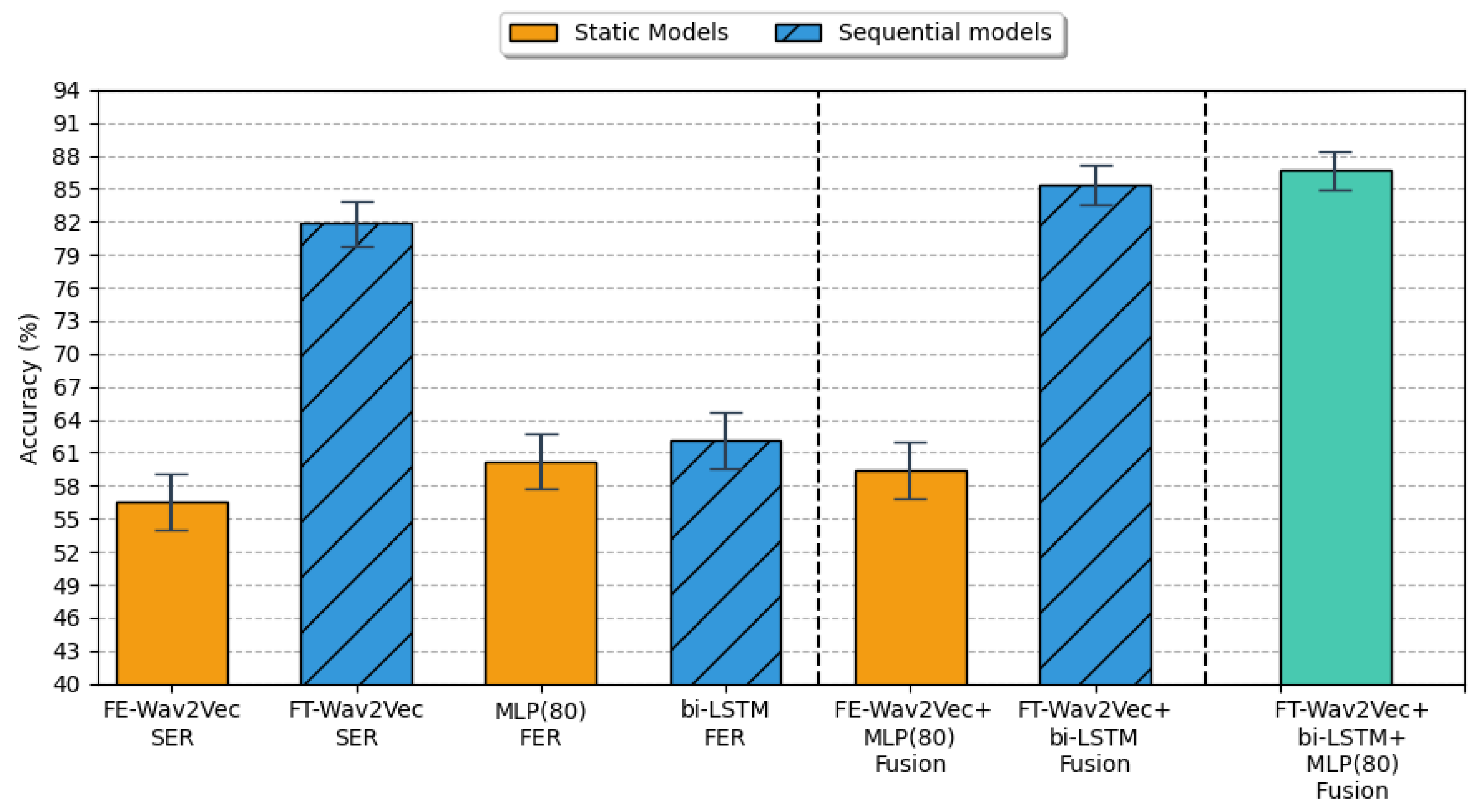
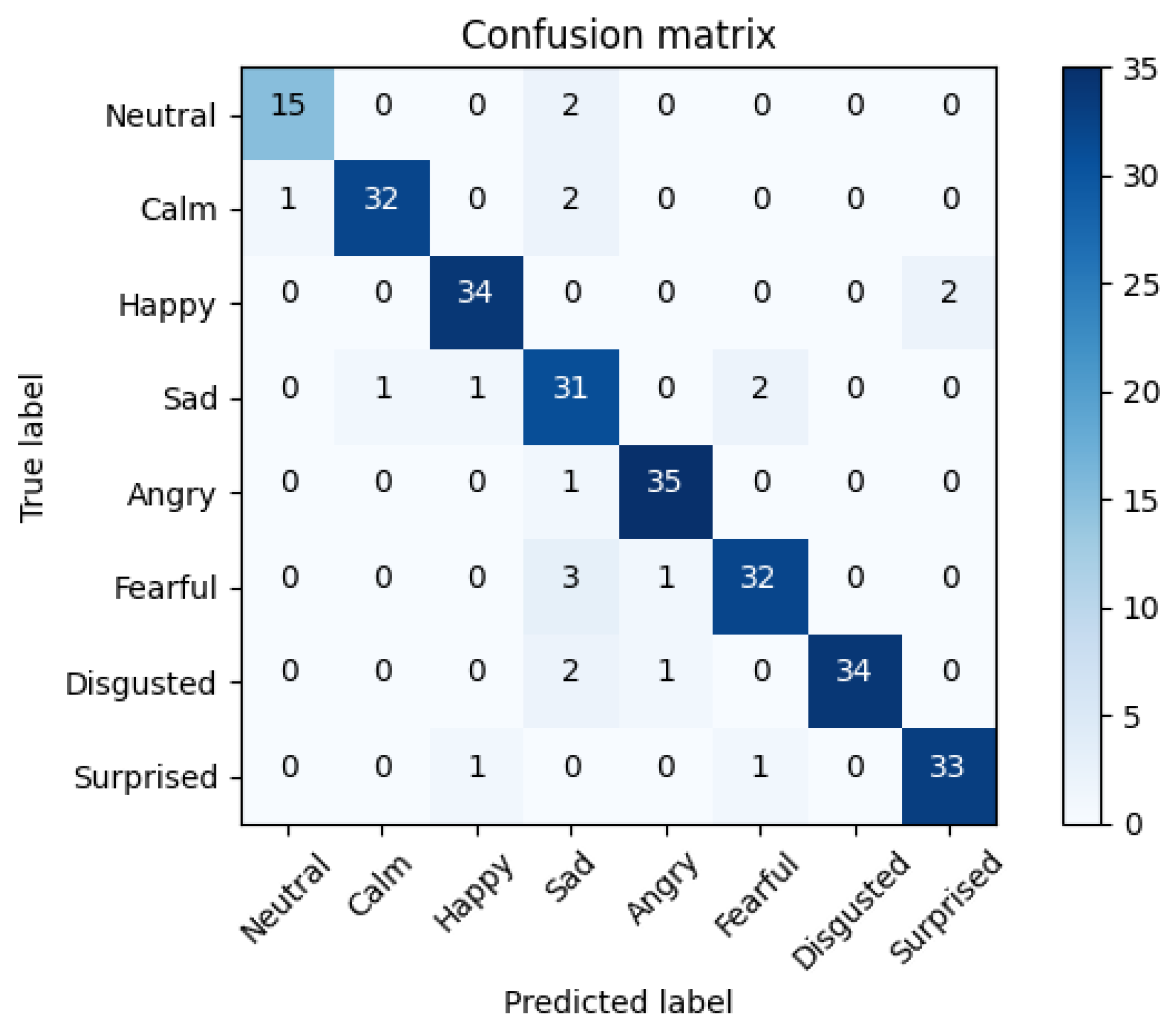
5. Results
5.1. Speech Emotion Recognition Results
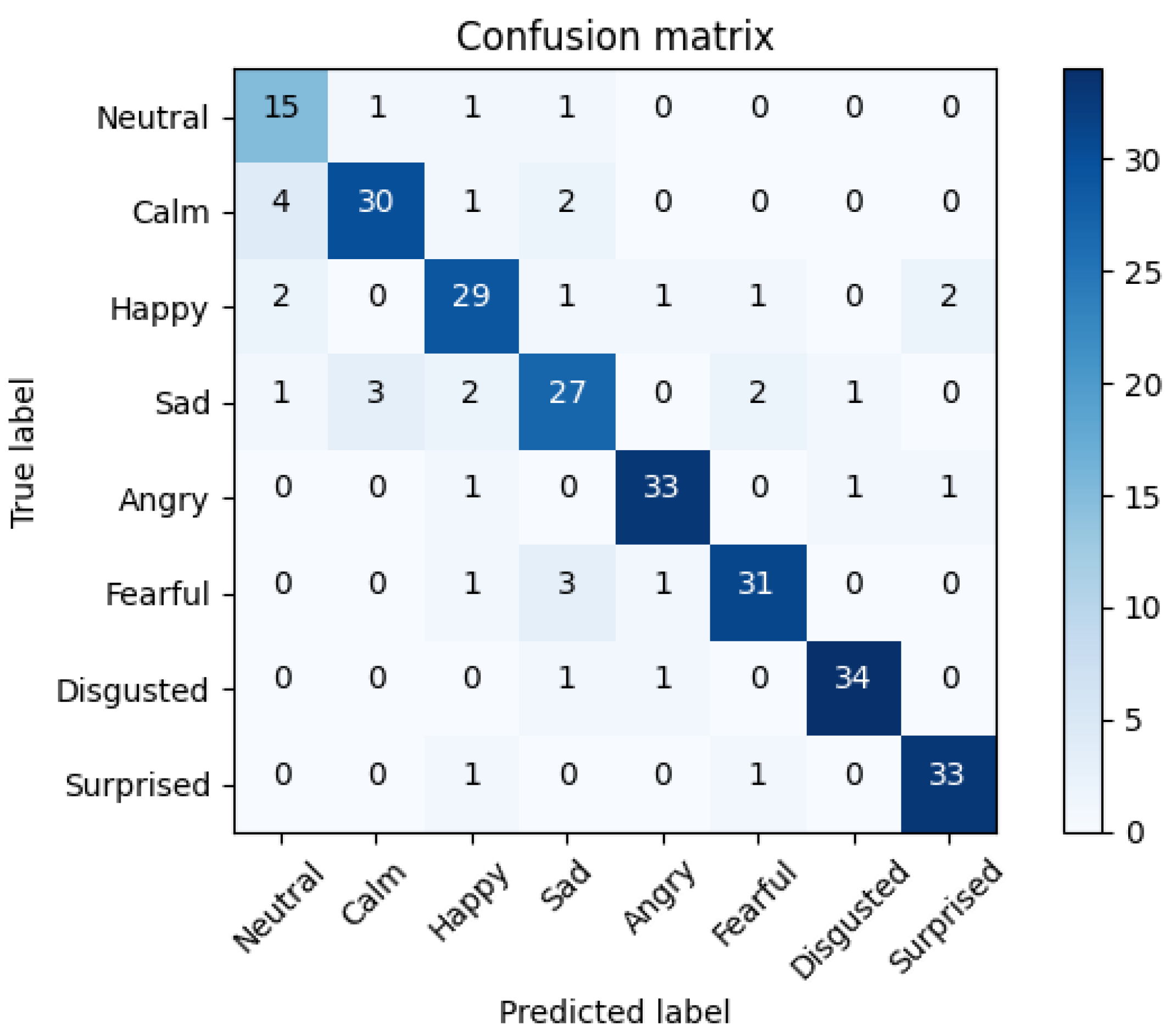
5.2. Facial Emotion Recognition Results
5.3. Multimodal Fusion Results
5.4. Comparative Results with Previous Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FER | facial emotion recognition |
| SER | speech emotion recognition |
| RAVDESS | The Ryerson Audio-Visual Database of Emotional Speech and Song |
| Bi-LSTM | Bi-directional long short-term memory networks |
| GAN | aenerative adversarial networks |
| embs | embeddings |
| fc | fully-connected |
| SVC | support vector machines/classification |
| k-NN | k-Nearest Neighbours |
| MLP | multilayer perceptron |
| AU | Action Unit |
| FACS | facial action coding system |
| TL | transfer-learning |
| FT | fine-tuning |
| FE | feature extraction |
| CI | confidence interval |
Appendix A. Generated AUs by the OpenFace Library

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AU Number | FACs Name |
|---|---|
| 1 | Inner brow raiser |
| 2 | Outer brow raiser |
| 4 | Brow lowerer |
| 5 | Upper lid raiser |
| 6 | Check raiser |
| 7 | Lid tightener |
| 9 | Nose wrinkler |
| 10 | Upper lip raiser |
| 12 | Lip corner puller |
| 14 | Dimpler |
| 15 | Lip corner depressor |
| 17 | Chin raiser |
| 20 | Lip stretcher |
| 23 | Lip tightener |
| 25 | Lip part |
| 26 | Jaw drop |
| 28 | Lip suck |
| 45 | Blink |
Appendix B. Training with as Many Samples as Frames + Max. Voting
| Inuts | Models | Hyper- Parameters | Norm | Accuracy |
|---|---|---|---|---|
| Average Action Units | SVC | C = 0.1 | Yes | 52.23 ± 2.58 |
| No | 54.18 ± 2.57 | |||
| C = 1 | Yes | 54.15 ± 2.57 | ||
| No | 53.02 ± 2.58 | |||
| C = 10 | Yes | 53.20 ± 2.58 | ||
| No | 52.48 ± 2.58 | |||
| k-NN | k = 10 | Yes | 49.78 ± 2.58 | |
| No | 49.20 ± 2.58 | |||
| k = 20 | Yes | 51.12 ± 2.58 | ||
| No | 50.90 ± 2.58 | |||
| k = 30 | Yes | 52.57 ± 2.58 | ||
| No | 51.67 ± 2.58 | |||
| k = 40 | Yes | 52.35 ± 2.58 | ||
| No | 51.60 ± 2.58 | |||
| MLP | 1 layer (80) | Yes | 51.08 ± 2.58 | |
| No | 50.07 ± 2.58 | |||
| 2 layers (80,80) | Yes | 48.75 ± 2.58 | ||
| No | 49.78 ± 2.58 |
References
- Kraus, M.; Wagner, N.; Callejas, Z.; Minker, W. The Role of Trust in Proactive Conversational Assistants. IEEE Access 2021, 9, 112821–112836. [Google Scholar] [CrossRef]
- Cassell, J.; Sullivan, J.; Prevost, S.; Churchill, E.F. Embodied Conversational Agents; The MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- de Visser, E.J.; Pak, R.; Shaw, T.H. From ‘automation’ to ‘autonomy’: The importance of trust repair in human–machine interaction. Ergonomics 2018, 61, 1409–1427. [Google Scholar] [CrossRef]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R.W. Driver Emotion Recognition for Intelligent Vehicles: A Survey. ACM Comput. Surv. 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Nyquist, A.C.; Luebbe, A.M. An Emotion Recognition–Awareness Vulnerability Hypothesis for Depression in Adolescence: A Systematic Review. Clin. Child Fam. Psychol. Rev. 2019, 23, 27–53. [Google Scholar] [CrossRef] [PubMed]
- Greco, C.; Matarazzo, O.; Cordasco, G.; Vinciarelli, A.; Callejas, Z.; Esposito, A. Discriminative Power of EEG-Based Biomarkers in Major Depressive Disorder: A Systematic Review. IEEE Access 2021, 9, 112850–112870. [Google Scholar] [CrossRef]
- Argaud, S.; Vérin, M.; Sauleau, P.; Grandjean, D. Facial emotion recognition in Parkinson’s disease: A review and new hypotheses. Mov. Disord. 2018, 33, 554–567. [Google Scholar] [CrossRef] [PubMed]
- Franzoni, V.; Milani, A.; Nardi, D.; Vallverdú, J. Emotional machines: The next revolution. Web Intell. 2019, 17, 1–7. [Google Scholar] [CrossRef] [Green Version]
- McTear, M.; Callejas, Z.; Griol, D. The Conversational Interface: Talking to Smart Devices; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Schuller, B.; Batliner, A. Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing, 1st ed.; Wiley Publishing: Hoboken, NJ, USA, 2013. [Google Scholar]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-Net: A Lightweight CNN-Based Speech Emotion Recognition System Using Deep Frequency Features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef]
- Luna-Jiménez, C.; Griol, D.; Callejas, Z.; Kleinlein, R.; Montero, J.M.; Fernández-Martínez, F. Multimodal Emotion Recognition on RAVDESS Dataset Using Transfer Learning. Sensors 2021, 21, 7665. [Google Scholar] [CrossRef]
- Shah Fahad, M.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digital Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]
- Naga, P.; Marri, S.D.; Borreo, R. Facial emotion recognition methods, datasets and technologies: A literature survey. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Clavel, C.; Callejas, Z. Sentiment Analysis: From Opinion Mining to Human-Agent Interaction. IEEE Trans. Affect. Comput. 2016, 7, 74–93. [Google Scholar] [CrossRef]
- Ashraf, A.; Gunawan, T.; Rahman, F.; Kartiwi, M. A Summarization of Image and Video Databases for Emotion Recognition. In Recent Trends in Mechatronics Towards Industry 4.0. Lecture Notes in Electrical Engineering; Springer: Singapore, 2022; Volume 730, pp. 669–680. [Google Scholar] [CrossRef]
- Thanapattheerakul, T.; Mao, K.; Amoranto, J.; Chan, J. Emotion in a Century: A Review of Emotion Recognition. In Proceedings of the 10th International Conference on Advances in Information Technology (IAIT 2018), Bangkok, Thailand, 10–13 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; Volume 17, pp. 1–8. [Google Scholar] [CrossRef]
- Ekman, P. Basic Emotions. In Handbook of Cognition and Emotion; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 1999; Chapter 3; pp. 45–60. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech 2005, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar] [CrossRef]
- Posner, J.; Russell, J.A.; Peterson, B.S. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev. Psychopathol. 2005, 17, 715–734. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower Provost, E.; Kim, S.; Chang, J.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Prasanth, S.; Roshni Thanka, M.; Bijolin Edwin, E.; Nagaraj, V. Speech emotion recognition based on machine learning tactics and algorithms. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oguz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Ancilin, J.; Milton, A. Improved speech emotion recognition with Mel frequency magnitude coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The Munich Versatile and Fast Open-Source Audio Feature Extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar] [CrossRef]
- Boersma, P.; Weenink, D. PRAAT, a system for doing phonetics by computer. Glot Int. 2001, 5, 341–345. [Google Scholar]
- Bhavan, A.; Chauhan, P.; Hitkul; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Singh, P.; Srivastava, R.; Rana, K.; Kumar, V. A multimodal hierarchical approach to speech emotion recognition from audio and text. Knowl.-Based Syst. 2021, 229, 107316. [Google Scholar] [CrossRef]
- Pepino, L.; Riera, P.; Ferrer, L. Emotion Recognition from Speech Using wav2vec 2.0 Embeddings. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 3400–3404. [Google Scholar] [CrossRef]
- Issa, D.; Fatih Demirci, M.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control. 2020, 59, 101894. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Atila, O.; Şengür, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Wijayasingha, L.; Stankovic, J.A. Robustness to noise for speech emotion classification using CNNs and attention mechanisms. Smart Health 2021, 19, 100165. [Google Scholar] [CrossRef]
- Sun, L.; Zou, B.; Fu, S.; Chen, J.; Wang, F. Speech emotion recognition based on DNN-decision tree SVM model. Speech Commun. 2019, 115, 29–37. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jindal, R.; Ekbal, A.; Bhattachharyya, P. Borrow from rich cousin: Transfer learning for emotion detection using cross lingual embedding. Expert Syst. Appl. 2020, 139, 112851. [Google Scholar] [CrossRef]
- Amiriparian, S.; Gerczuk, M.; Ottl, S.; Cummins, N.; Freitag, M.; Pugachevskiy, S.; Baird, A.; Schuller, B. Snore Sound Classification Using Image-Based Deep Spectrum Features. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 3512–3516. [Google Scholar]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics (EMNLP 2020), Virtual Conference, 16–20 November 2020; pp. 38–45. [Google Scholar]
- King, D.E. Dlib-Ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Nguyen, B.T.; Trinh, M.H.; Phan, T.V.; Nguyen, H.D. An efficient real-time emotion detection using camera and facial landmarks. In Proceedings of the 2017 Seventh International Conference on Information Science and Technology (ICIST), Da Nang, Vietnam, 16–19 April 2017; pp. 251–255. [Google Scholar] [CrossRef]
- Poulose, A.; Kim, J.H.; Han, D.S. Feature Vector Extraction Technique for Facial Emotion Recognition Using Facial Landmarks. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 20–22 October 2021; pp. 1072–1076. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar] [CrossRef]
- Sanchez-Mendoza, D.; Masip, D.; Lapedriza, A. Emotions Classification using Facial Action Units Recognition. In Artificial Intelligence Research and Development: Recent Advances and Applications; Frontiers in Artificial Intelligence and Applications; Museros, L., Pujol, O., Agell, N., Eds.; Catalan Assoc Artificial Intelligence: Barcelona, Spain, 2014; Volume 269, pp. 55–64. [Google Scholar] [CrossRef]
- Yao, L.; Wan, Y.; Ni, H.; Xu, B. Action unit classification for facial expression recognition using active learning and SVM. Multimed. Tools Appl. 2021, 80, 24287–24301. [Google Scholar] [CrossRef]
- Senechal, T.; Bailly, K.; Prevost, L. Impact of Action Unit Detection in Automatic Emotion Recognition. Pattern Anal. Appl. 2014, 17, 51–67. [Google Scholar] [CrossRef]
- Bagheri, E.; Esteban, P.G.; Cao, H.L.; De Beir, A.; Lefeber, D.; Vanderborght, B. An Autonomous Cognitive Empathy Model Responsive to Users’ Facial Emotion Expressions. ACM Trans. Interact. Intell. Syst. 2020, 10, 20. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar] [CrossRef]
- Tautkute, I.; Trzcinski, T. Classifying and Visualizing Emotions with Emotional DAN. Fundam. Inform. 2019, 168, 269–285. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Kim, J.H.; Poulose, A.; Han, D.S. The Extensive Usage of the Facial Image Threshing Machine for Facial Emotion Recognition Performance. Sensors 2021, 21, 2026. [Google Scholar] [CrossRef]
- Huang, S.C.; Pareek, A.; Seyyedi, S.; Banerjee, I.; Lungren, M.P. Fusion of medical imaging and electronic health records using deep learning: A systematic review and implementation guidelines. NPJ Digit. Med. 2020, 3, 136. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [Green Version]
- Sun, L.; Xu, M.; Lian, Z.; Liu, B.; Tao, J.; Wang, M.; Cheng, Y. Multimodal Emotion Recognition and Sentiment Analysis via Attention Enhanced Recurrent Model. In Proceedings of the 2nd on Multimodal Sentiment Analysis Challenge, Virtual Event China, 24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 15–20. [Google Scholar] [CrossRef]
- Sun, L.; Lian, Z.; Tao, J.; Liu, B.; Niu, M. Multi-Modal Continuous Dimensional Emotion Recognition Using Recurrent Neural Network and Self-Attention Mechanism. In Proceedings of the 1st International on Multimodal Sentiment Analysis in Real-Life Media Challenge and Workshop, Seattle, WA, USA, 16 October 2020; pp. 27–34. [Google Scholar] [CrossRef]
- Deng, J.J.; Leung, C.H.C. Towards Learning a Joint Representation from Transformer in Multimodal Emotion Recognition. In Brain Informatics; Mahmud, M., Kaiser, M.S., Vassanelli, S., Dai, Q., Zhong, N., Eds.; Springer: Cham, Switzerland, 2021; pp. 179–188. [Google Scholar]
- Pandeya, Y.R.; Lee, J. Deep learning-based late fusion of multimodal information for emotion classification of music video. Multimed. Tools Appl. 2021, 80, 2887–2905. [Google Scholar] [CrossRef]
- Abdulmohsin, H.A.; Abdul wahab, H.B.; Abdul hossen, A.M.J. A new proposed statistical feature extraction method in speech emotion recognition. Comput. Electr. Eng. 2021, 93, 107172. [Google Scholar] [CrossRef]
- García-Ordás, M.T.; Alaiz-Moretón, H.; Benítez-Andrades, J.A.; García-Rodríguez, I.; García-Olalla, O.; Benavides, C. Sentiment analysis in non-fixed length audios using a Fully Convolutional Neural Network. Biomed. Signal Process. Control. 2021, 69, 102946. [Google Scholar] [CrossRef]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised Cross-Lingual Representation Learning for Speech Recognition. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 2426–2430. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 12449–12460. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. In Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), Marseílle, France, 20–25 June 2020; pp. 4211–4215. [Google Scholar]
- Tomar, S. Converting video formats with FFmpeg. Linux J. 2006, 2006, 10. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Baltrusaitis, T.; Mahmoud, M.; Robinson, P. Cross-Dataset Learning and Person-Specific Normalisation for Automatic Action Unit Detection. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Baziotis, C.; Nikolaos, A.; Chronopoulou, A.; Kolovou, A.; Paraskevopoulos, G.; Ellinas, N.; Narayanan, S.; Potamianos, A. NTUA-SLP at SemEval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive RNNs and Transfer Learning. In Proceedings of the 12th International Workshop on Semantic Evaluation, Orleans, LA, USA, 5–6 June 2018. [Google Scholar] [CrossRef]
- Romero, S.E.; Kleinlein, R.; Jiménez, C.L.; Montero, J.M.; Martínez, F.F. GTH-UPM at DETOXIS-IberLEF 2021: Automatic Detection of Toxic Comments in Social Networks. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2021), Co-Located with the Conference of the Spanish Society for Natural Language Processing (SEPLN 2021), Málaga, Spain, 21 September 2021; Volume 2943, pp. 533–546. [Google Scholar]
- Pavlopoulos, J.; Malakasiotis, P.; Androutsopoulos, I. Deep Learning for User Comment Moderation. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Dissanayake, V.; Zhang, H.; Billinghurst, M.; Nanayakkara, S. Speech Emotion Recognition ‘in the Wild’ Using an Autoencoder. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 526–530. [Google Scholar] [CrossRef]

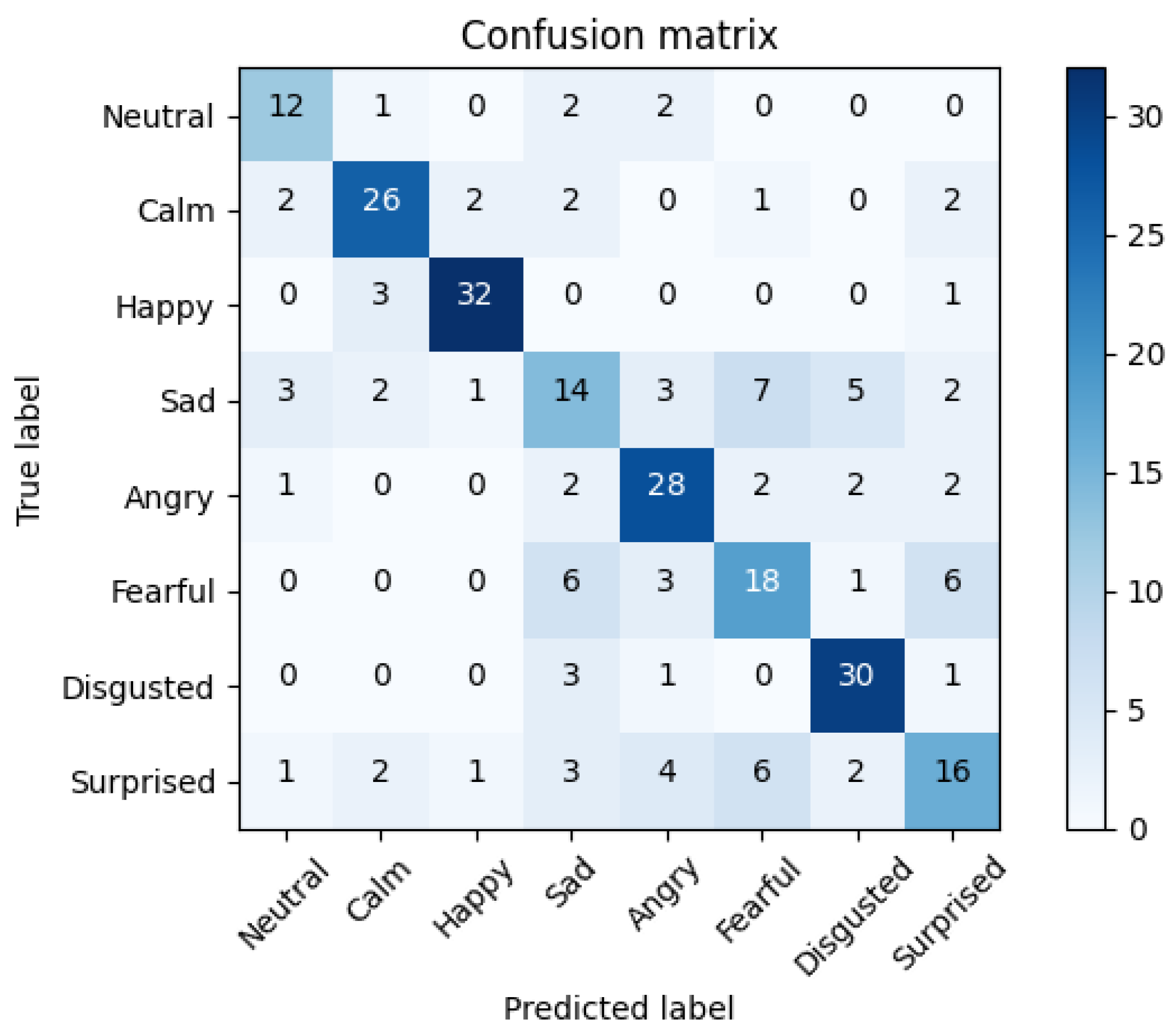
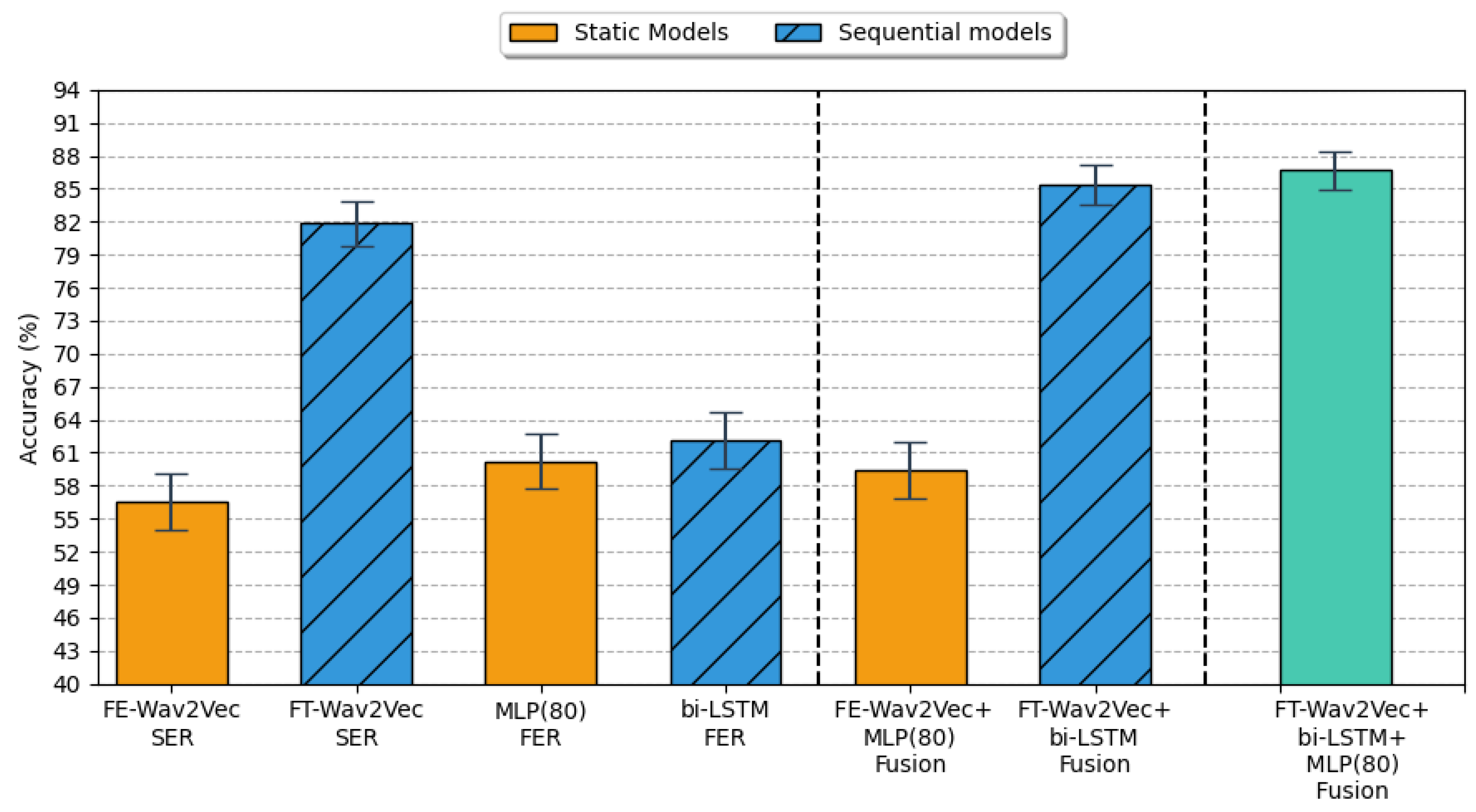
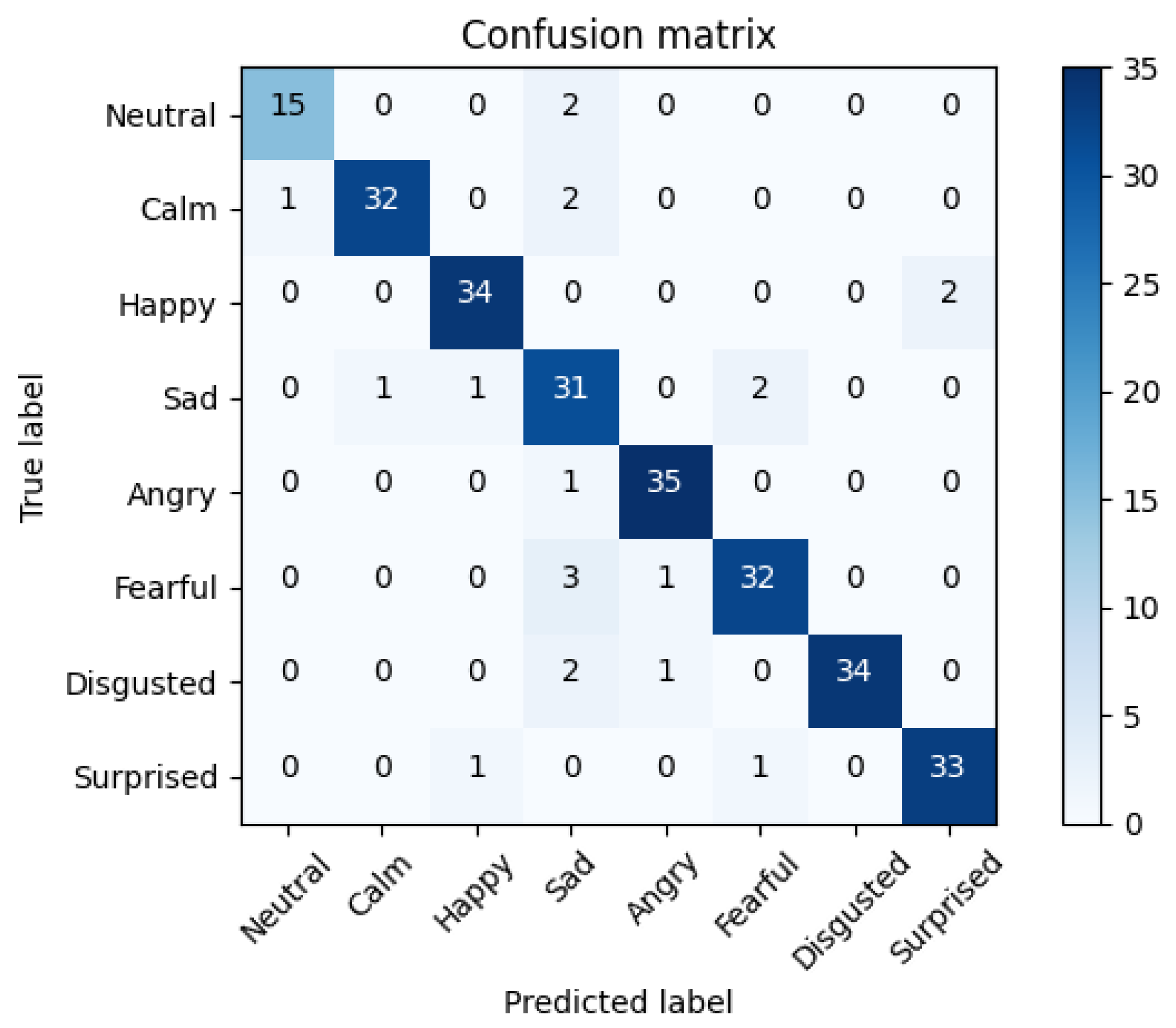
| TL Strategy | Inputs | Models | Hyper- Parameters | Accuracy ± 95% CI |
|---|---|---|---|---|
| - | - | Human perception | - | 67.00 |
| - | - | ZeroR | - | 13.33 ± 1.76 |
| Feature Extraction (Static) | Average xlsr-Wav2Vec2.0 embs. from feature encoder | SVC | C = 1.0 | 50.13 ± 2.58 |
| C = 10.0 | 53.12 ± 2.58 | |||
| C = 100.0 | 53.10 ± 2.58 | |||
| kNN | k = 10 | 36.07 ± 2.48 | ||
| k = 20 | 37.90 ± 2.51 | |||
| k = 30 | 38.65 ± 2.51 | |||
| k = 40 | 38.47 ± 2.51 | |||
| MLP | 1 layer (80) | 56.53 ± 2.56 | ||
| 2 layers (80,80) | 55.82 ± 2.56 | |||
| Fine Tuning (Sequential) | Raw audio | xlsr-Wav2Vec2.0 + MLP | MLP 2 layers (1024,8) | 81.82 ± 1.99 |
| Inputs | Models | Hyper- Parameters | Norm. | Accuracy ± 95% CI |
|---|---|---|---|---|
| - | Human perception | - | - | 75.00 |
| - | ZeroR | - | - | 13.33 ± 1.76 |
| Average Action Units | SVC | C = 0.1 | Yes | 53.25 ± 2.58 |
| No | 48.07 ± 2.58 | |||
| C = 1.0 | Yes | 59.93 ± 2.53 | ||
| No | 54.88 ± 2.57 | |||
| C = 10.0 | Yes | 55.93 ± 2.56 | ||
| No | 51.65 ± 2.58 | |||
| kNN | k = 10 | Yes | 53.10 ± 2.58 | |
| No | 46.80 ± 2.58 | |||
| k = 20 | Yes | 54.30 ± 2.57 | ||
| No | 49.07 ± 2.58 | |||
| k = 30 | Yes | 55.18 ± 2.57 | ||
| No | 48.82 ± 2.58 | |||
| k = 40 | Yes | 55.40 ± 2.57 | ||
| No | 50.20 ± 2.58 | |||
| MLP | 1 layer (80) | Yes | 60.22 ± 2.53 | |
| No | 58.93 ± 2.54 | |||
| 2 layers (80,80) | Yes | 57.77 ± 2.55 | ||
| No | 55.82 ± 2.56 | |||
| Sequence of Action Units | bi-LSTM | 2 bi-LSTM layers (50,50) + 2 attention layers | No | 62.13 ± 2.51 |
| Neutral | Calm | Happy | Sad | Angry | Fearful | Disgusted | Surprised | |
|---|---|---|---|---|---|---|---|---|
| Precision | 88.31 | 91.45 | 89.79 | 71.22 | 91.78 | 88.26 | 93.99 | 89.50 |
| Recall | 82.25 | 85.63 | 89.25 | 81.88 | 92.37 | 83.62 | 88.50 | 87.87 |
| Accuracy | 98.05 | 96.88 | 97.05 | 92.73 | 97.83 | 96.20 | 97.70 | 96.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.M.; Fernández-Martínez, F. A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset. Appl. Sci. 2022, 12, 327. https://doi.org/10.3390/app12010327
Luna-Jiménez C, Kleinlein R, Griol D, Callejas Z, Montero JM, Fernández-Martínez F. A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset. Applied Sciences. 2022; 12(1):327. https://doi.org/10.3390/app12010327
Chicago/Turabian StyleLuna-Jiménez, Cristina, Ricardo Kleinlein, David Griol, Zoraida Callejas, Juan M. Montero, and Fernando Fernández-Martínez. 2022. "A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset" Applied Sciences 12, no. 1: 327. https://doi.org/10.3390/app12010327
APA StyleLuna-Jiménez, C., Kleinlein, R., Griol, D., Callejas, Z., Montero, J. M., & Fernández-Martínez, F. (2022). A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset. Applied Sciences, 12(1), 327. https://doi.org/10.3390/app12010327