
Evaluation of Artificial Intelligence-Based Models for Classifying Defective Photovoltaic Cells

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
- The indoor measurements have been performed in the commercial system Pasan SunSim 3 CM, which consisted of a light pulse solar simulator class AAA according to IEC 60904-9 standard, which can perform I-V curve measurements at Standard Test conditions;
- The EL and indoor IRT tests were simultaneously performed with the EL in this chamber. The module was fed with a Delta power supply SM 70-22. A Fluke 189 multimeter connected to module terminals allowing it to register the exact module voltage. EL and IR images were captured with a PCO 1300 and a FLIR SC 640 camera, respectively.
- Group 1: Power ≥ 95%;
- Group 2: 80% ≤ Power < 95%;
- Group 3: Power < 80%.
- Group 1: 0, 2, 3, 5, 7, 8, 9, 10, 11, 12, 13, 15, 16, 18, 19, 20, 21, 22, 23, 24, 25, 28, 30, 31, 33, and 53;
- Group 2: 14, 17, 26, 27, 29, 32, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 51, 52, 54, 55, 56, 57, and 58;
- Group 3: 1, 4, 6, 45, 49, 50, and 59.
2.2. Methods
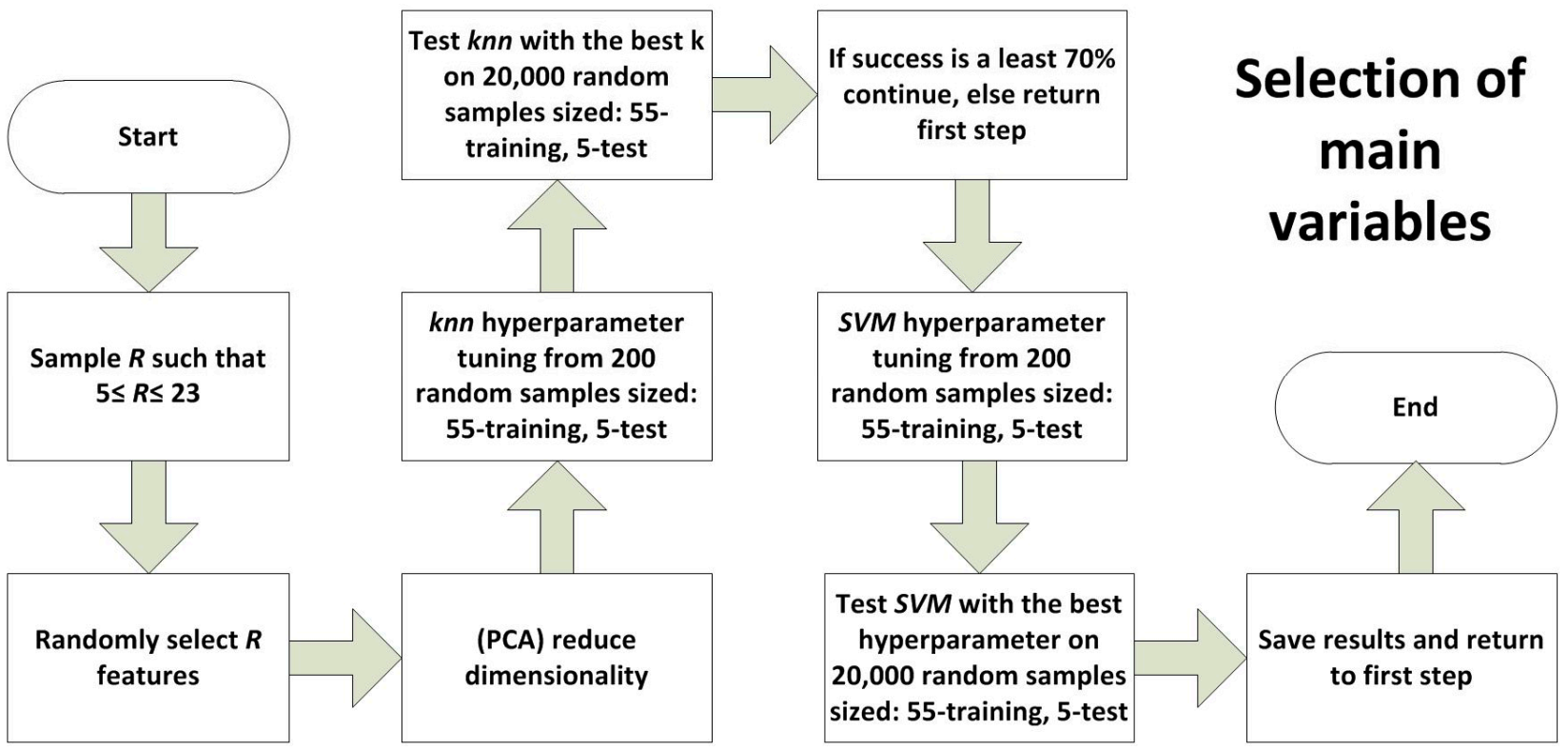
- Sample R such that 5 ≤ R ≤ 23 and randomly select R features: A random number R is obtained between 5 and 23. Next, R variables are chosen at random from among the 28 possible ones;
- Principal Component Analysis (PCA) to Reduce dimensionality: Subsequently, principal component analysis is applied, saving the first variables that explain more than 99.5% of the variance of the data. Therefore, from now on, we work with 60 individuals explained in at most R new variables;
- KNN hyperparameter tuning from 200 random samples sized 55-training and 5-test, test KNN with the best K on 20,000 random samples sized 55-training and 5-test: As we were interested in obtaining a good classification, the optimal number of neighbors k was sought, choosing between 1 and 10, starting from the one that offers the best results when applied in 200 random samples of size 55-training, 5-test. Once k has been obtained, the percentage of success with KNN is now estimated from 20,000 random samples of size 55-training, 5-test. Finally, the proportion of bad classifications related to group 3 is noted. If the percentage of success with KNN is less strict than 70%, step 1 becomes:
- SVM hyperparameter tuning from 200 random samples sized 55-training, 5-test: Now, exceeding 70% of success with KNN, SVM is applied taking into account the following parameters:
- ○
- Core: function in charge of transporting the data to a higher dimension where a better separation of the same can be achieved. Sigmoidal, polynomial, and Gaussian functions and the linear core were taken into account for the experiment;
- ○
- Penalty parameter C: it is an indicator of the error that one is willing to tolerate. The values for C of 10, 50, 75, and 100 were taken into account for the experiment;
- ○
- Gamma: indicates how far the points are taken into account when drawing up the separating boundary. The gamma values of 1, 0.8, 0.6, 0.4, 0.1, 0.01, and 0.001 were taken into account for the experiment;
- ○
- Degree: degree of the function in the polynomial nucleus. Grades 1, 2, 3, and 4 were taken into account for the experiment;
- ○
- Based on these parameters, a search was done among all the possible combinations in order to calculate which one of them offered the best results applied to 200 random samples of size 55-training, 5-test. GridSearchCV was used to perform the above task.
- Test SVM with the best hyperparameters on 20,000 random samples sized 55-training 5-test: Once the ideal combination has been obtained, the efficacy of SVM is estimated running the supervised method based on these parameters and applied to 20,000 random samples of size 55-training, 5-test. Hit and misclassification ratios related to group 3 are saved;
- Save results and return to first step: Back to step 1.
- Maximum depth: represents the maximum number of levels allowed in each decision tree. The values 20, 40, 60, 80, and 100 were taken into account;
- Minimum points per node: this is the minimum number of data allowed in each partition. The values 1, 2, 3, 4, and 5 were taken into account.
- Maximum variables: indicates the maximum number of variables (chosen at random) that are taken into consideration when partitioning a node. Usually, √n is used as a standard parameter, where n is the number of total variables, but √n − 1, √n, and √n + 1 were taken into account.
- Epochs: indicates the number of times that the neural network reads the data from the training sample in order to adjust to them (translated into a successive update of its parameters). The values 25, 50, 75, 100, 150, and 200 were taken into account;
- Batches: indicates the speed with which the network parameters are updated as the epochs progress. The values 15, 25, 50, 75, 100, 150, and 200 were taken into account.
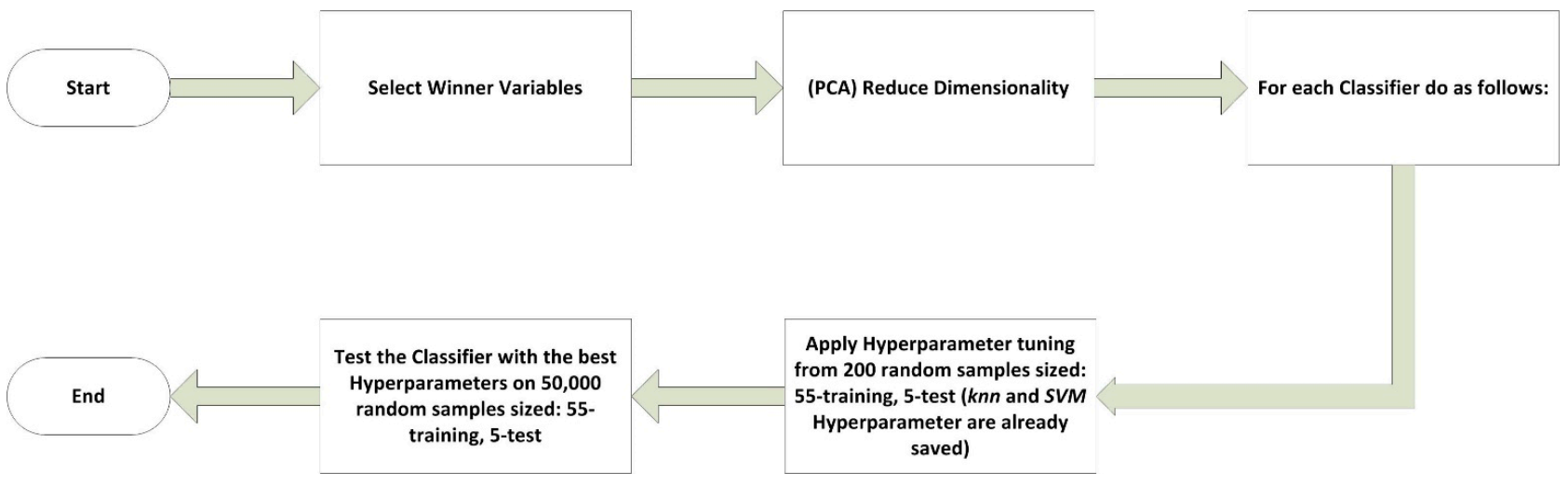
- For KNN and SVM:
- a.
- Test the classifier with the best hyperparameters (previously calculated) on 50,000 random samples sized: 55-training, 5-test.
- For RF and MLP:
- a.
- Apply hyperparameter tuning from 200 random samples sized: 55-training and 5-test.
- b.
- Test the classifier with the best hyperparameters on 50,000 random samples sized: 55-training and 5-test.
- For CNN:
- a.
- Test the classifier with the best hyperparameters (manually settled) on 100 random samples sized: 55-training and 5-test.
3. Results and Discussion
3.1. Justification of the Correct Initial Power Rating
3.2. Classification of Variables
- Success with KNN greater than 68.5% (seventy-fifth percentile);
- The proportion of bad classifications not related to group 3 higher than 79.4% (eighty-fifth percentile).
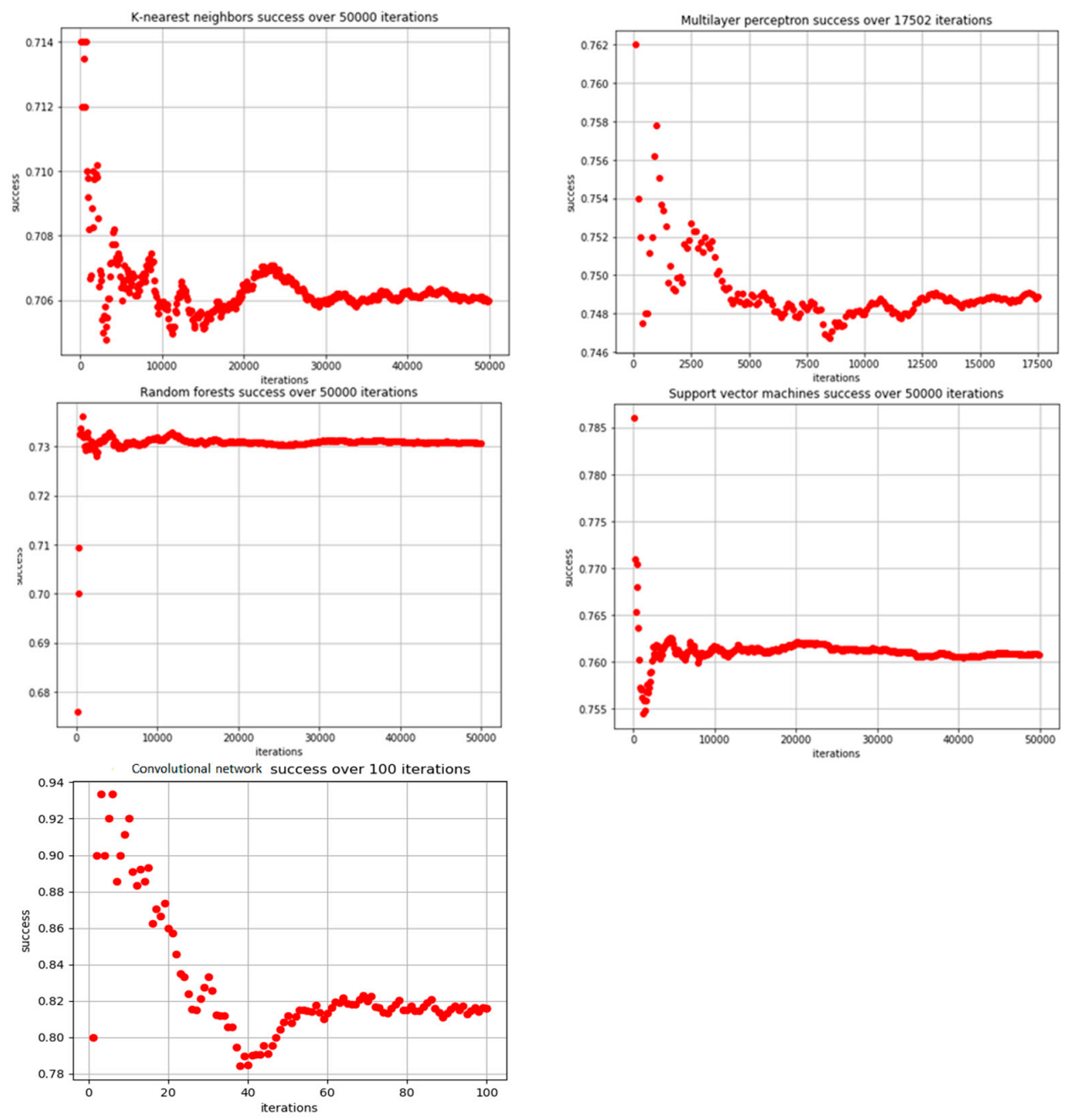
3.3. Convergence and Results of the Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scholten, D.; Bazilian, M.; Overland, I.; Westphal, K. The geopolitics of renewables: New board, new game. Energy Policy 2020, 138, 111059. [Google Scholar] [CrossRef]
- Gugler, K.; Haxhimusa, A.; Liebensteiner, M.; Schindler, N. Investment opportunities, uncertainty, and renewables in European electricity markets. Energy Econ. 2020, 85, 104575. [Google Scholar] [CrossRef]
- REN21. Renewables 2020 Global Status Report; REN21 Secretariat: Paris, France, 2020; ISBN 978-3-948393-00-7. Available online: http://www.ren21.net/gsr-2020/ (accessed on 15 January 2021).
- Behzadi, A.; Arabkoohsar, A. Feasibility study of a smart building energy system comprising solar PV/T panels and a heat storage unit. Energy 2020, 210, 118528. [Google Scholar] [CrossRef]
- Fachrizal, R.; Ramadhani, U.H.; Munkhammar, J.; Widén, J. Combined PV–EV hosting capacity assessment for a residential LV distribution grid with smart EV charging and PV curtailment. Sustain. Energy Grids Netw. 2021, 26, 100445. [Google Scholar] [CrossRef]
- Thornbush, M.; Golubchikov, O. Smart energy cities: The evolution of the city-energy-sustainability nexus. Environ. Dev. 2021, 100626, 100626. [Google Scholar] [CrossRef]
- Hernández-Callejo, L.; Gallardo-Saavedra, S.; Alonso-Gómez, V. A review of photovoltaic systems: Design, operation and maintenance. Sol. Energy 2019, 188, 426–440. [Google Scholar] [CrossRef]
- Gallardo-Saavedra, S.; Hernández-Callejo, L.; Duque-Pérez, O. Quantitative failure rates and modes analysis in photovoltaic plants. Energy 2019, 183, 825–836. [Google Scholar] [CrossRef]
- Gallardo-Saavedra, S.; Hernández-Callejo, L.; Alonso-García, M.D.C.; Santos, J.D.; Morales-Aragonés, J.I.; Alonso-Gómez, V.; Moretón-Fernández, Á.; González-Rebollo, M.A.; Martínez-Sacristán, O. Nondestructive characterization of solar PV cells defects by means of electroluminescence, infrared thermography, I–V curves and visual tests: Experimental study and comparison. Energy 2020, 205, 117930. [Google Scholar] [CrossRef]
- Blakesley, J.C.; Castro, F.A.; Koutsourakis, G.; Laudani, A.; Lozito, G.M.; Fulginei, F.R. Towards non-destructive individual cell I-V characteristic curve extraction from photovoltaic module measurements. Sol. Energy 2020, 202, 342–357. [Google Scholar] [CrossRef]
- Morales-Aragonés, J.; Gallardo-Saavedra, S.; Alonso-Gómez, V.; Sánchez-Pacheco, F.; González, M.; Martínez, O.; Muñoz-García, M.; Alonso-García, M.; Hernández-Callejo, L. Low-cost electronics for online i-v tracing at photovoltaic module level: Development of two strategies and comparison between them. Electronics 2021, 10, 671. [Google Scholar] [CrossRef]
- Morales-Aragonés, J.; Alonso-García, M.; Gallardo-Saavedra, S.; Alonso-Gómez, V.; Balenzategui, J.; Redondo-Plaza, A.; Hernández-Callejo, L. Online distributed measurement of dark i-v curves in photovoltaic plants. Appl. Sci. 2021, 11, 1924. [Google Scholar] [CrossRef]
- Jordan, D.C.; Silverman, T.J.; Wohlgemuth, J.H.; Kurtz, S.R.; VanSant, K.T. Photovoltaic failure and degradation modes. Prog. Photovolt. Res. Appl. 2017, 25, 318–326. [Google Scholar] [CrossRef]
- Gallardo-Saavedra, S.; Hernández-Callejo, L.; Duque-Perez, O. Technological review of the instrumentation used in aerial thermographic inspection of photovoltaic plants. Renew. Sustain. Energy Rev. 2018, 93, 566–579. [Google Scholar] [CrossRef]
- Gallardo-Saavedra, S.; Hernandez-Callejo, L.; Duque-Perez, O.; Hermandez, L. Image resolution influence in aerial thermographic inspections of photovoltaic plants. IEEE Trans. Ind. Inform. 2018, 14, 5678–5686. [Google Scholar] [CrossRef]
- Ballestín-Fuertes, J.; Muñoz-Cruzado-Alba, J.; Sanz-Osorio, J.F.; Hernández-Callejo, L.; Alonso-Gómez, V.; Morales-Aragones, J.I.; Gallardo-Saavedra, S.; Martínez-Sacristan, O.; Moretón-Fernández, Á. Novel utility-scale photovoltaic plant electroluminescence maintenance technique by means of bidirectional power inverter controller. Appl. Sci. 2020, 10, 3084. [Google Scholar] [CrossRef]
- Gligor, A.; Dumitru, C.-D.; Grif, H.-S. Artificial intelligence solution for managing a photovoltaic energy production unit. Procedia Manuf. 2018, 22, 626–633. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Zhou, B.; Li, C.; Cao, G.; Voropai, N.; Barakhtenko, E. Taxonomy research of artificial intelligence for deterministic solar power forecasting. Energy Convers. Manag. 2020, 214, 112909. [Google Scholar] [CrossRef]
- Kayri, I.; Gencoglu, M.T. Predicting power production from a photovoltaic panel through artificial neural networks using atmospheric indicators. Neural Comput. Appl. 2017, 31, 3573–3586. [Google Scholar] [CrossRef]
- Li, L.-L.; Wen, S.-Y.; Tseng, M.-L.; Chiu, A.S.F. Photovoltaic array prediction on short-term output power method in centralized power generation system. Ann. Oper. Res. 2018, 290, 243–263. [Google Scholar] [CrossRef]
- Hussain, M.; Dhimish, M.; Titarenko, S.; Mather, P. Artificial neural network based photovoltaic fault detection algorithm integrating two bi-directional input parameters. Renew. Energy 2020, 155, 1272–1292. [Google Scholar] [CrossRef]
- Cho, K.-H.; Jo, H.-C.; Kim, E.-S.; Park, H.-A.; Park, J.H. Failure diagnosis method of photovoltaic generator using support vector machine. J. Electr. Eng. Technol. 2020, 15, 1669–1680. [Google Scholar] [CrossRef]
- Pérez-Romero, Á.; Hernández-Callejo, L.; Gallardo-Saavedra, S.; Alonso-Gómez, V.; Alonso-García, M.d.C.; Mateo-Romero, H.F. Photovoltaic cell defect classifier: A model comparison. In Proceedings of the III Ibero-American Conference on Smart Cities, San José, Costa Rica, 9–11 November 2020; pp. 257–273. [Google Scholar]
- Bishop, C.M. Pattern recognition and machine learning. In Information Science and Statistics; Springer: New York, NY, USA, 2006; pp. 21–24. ISBN 9780387310732. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organization and Associative Memory, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1988; ISBN 978-3540183143. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Silverman, B.W.; Jones, M.C.; Fix, E. An important contribution to nonparametric discriminant analysis and density estimation: Commentary on fix and hodges (1951). Int. Stat. Rev. 1989, 57, 233. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer Series in Information Sciences: Berlin/Heidelberg, Germany, 2001; Volume 30, ISBN 978-3-540-67921-9. [Google Scholar]
- Kothari, S.; Oh, H. Neural networks for pattern recognition. Adv. Comput. 1993, 37, 119–166. [Google Scholar] [CrossRef]
- Clancey, W.J. Heuristic classification. Artif. Intell. 1985, 27, 289–350. [Google Scholar] [CrossRef]
- Rodrigues, M.A. Invariants for Pattern Recognition and Classification. In Ensemble Learning; World Scientific: Singapore, 2000; Volume 42. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam; ICLR Work: Paris, France, 2016; pp. 1–4. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KNN Success | SVM Success | KNN + SVM Success Group 3 | KNN Success Group 3 | SVM Success Group 3 | Variables | |
|---|---|---|---|---|---|---|
| Top 1 KNN success | 0.745 | 0.756 | 1.425 | 0.734 | 0.691 | 2, 4, 5, 7, 10, 13, 16, 17, and 22 |
| Top 1 SVM success | 0.7077 | 0.7628 | 1.5973 | 0.6975 | 0.8998 | 4, 5, 8, 10, 13, 17, 19, 20, and 24 |
| Top 1 KNN + SVM success group 3 | 0.7005 | 0.7187 | 1.7646 | 0.9093 | 0.8552 | 2, 4, 6, 8, 10, 20, 23, and 24 |
| Top 1 KNN success group 3 | 0.7095 | 0.7187 | 1.7646 | 0.9093 | 0.8552 | 2, 4, 6, 8, 10, 20, 23, and 24 |
| Top 1 SVM success group 3 | 0.7099 | 0.7401 | 1.6371 | 0.704 | 0.9331 | 2, 4, 5, 7, 8, 9, 10, 12, 15, 16, 17, 18, 19, 20, and 21 |
| Classification Success | Time Spent on Hyperparameter Tuning (hr) | Time Spent Testing 50,000 (17,502 with MLP/100 CNN) Samples (hr) | |
|---|---|---|---|
| KNN | 0.7061 | 0.0017 | 0.0267 |
| SVM | 0.7607 | 0.0223 | 0.0196 |
| RF | 0.7308 | 2.1552 | 8.8071 |
| MLP | 0.7488 | 0.9633 | 15.5442 |
| CNN | 0.8160 | 100 |
| Success on Group 3 | 1 Missclassified as 2 | 1 Missclassified as 3 | 2 Missclassified as 1 | 2 Missclassified as 3 | 3 Missclassified as 1 | 3 Missclassified as 2 | |
|---|---|---|---|---|---|---|---|
| KNN | 0.7002 | 0.1017 | 0 | 0.5985 | 0.0117 | 0.0579 | 0.2302 |
| SVM | 0.9055 | 0.1377 | 0.0077 | 0.7678 | 0.0142 | 0.0044 | 0.0752 |
| RF | 0.7746 | 0.2525 | 0 | 0.5221 | 0.0142 | 0.0173 | 0.1939 |
| MLP | 0.8224 | 0.2166 | 0.0018 | 0.6058 | 0.0687 | 0.0073 | 0.0998 |
| CNN | 0.6956 | 0.2282 | 0.0217 | 0.3586 | 0.0865 | 0.0543 | 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Romero, Á.; Mateo-Romero, H.F.; Gallardo-Saavedra, S.; Alonso-Gómez, V.; Alonso-García, M.d.C.; Hernández-Callejo, L. Evaluation of Artificial Intelligence-Based Models for Classifying Defective Photovoltaic Cells. Appl. Sci. 2021, 11, 4226. https://doi.org/10.3390/app11094226
Pérez-Romero Á, Mateo-Romero HF, Gallardo-Saavedra S, Alonso-Gómez V, Alonso-García MdC, Hernández-Callejo L. Evaluation of Artificial Intelligence-Based Models for Classifying Defective Photovoltaic Cells. Applied Sciences. 2021; 11(9):4226. https://doi.org/10.3390/app11094226
Chicago/Turabian StylePérez-Romero, Álvaro, Héctor Felipe Mateo-Romero, Sara Gallardo-Saavedra, Víctor Alonso-Gómez, María del Carmen Alonso-García, and Luis Hernández-Callejo. 2021. "Evaluation of Artificial Intelligence-Based Models for Classifying Defective Photovoltaic Cells" Applied Sciences 11, no. 9: 4226. https://doi.org/10.3390/app11094226
APA StylePérez-Romero, Á., Mateo-Romero, H. F., Gallardo-Saavedra, S., Alonso-Gómez, V., Alonso-García, M. d. C., & Hernández-Callejo, L. (2021). Evaluation of Artificial Intelligence-Based Models for Classifying Defective Photovoltaic Cells. Applied Sciences, 11(9), 4226. https://doi.org/10.3390/app11094226