
Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning


Abstract
1. Introduction
1.1. Motivation
1.2. Prior Work
1.3. Contributions of the Research
- We provide a joint solution for the power allocation and user association with the objective of maximizing downlink energy efficiency under backhaul link constraint and QoS guarantee. We employ the novel model-free parameterized deep Q-network (P-DQN) framework that is capable of updating policies in a hybrid discrete-continuous action space (i.e., discrete BS-UE association and continuous power allocation).
- To the best of our knowledge, most DRL-based research about power allocation do not consider the wireless backhaul capacity constraint and user QoS. We design the flexible reward function to meet the QoS demands at different traffic scenarios and introduce a penalty mechanism when the backhaul link constraint is violated. We verify by simulations that the proposed P-DQN framework outperforms other proposed approaches in terms of overall energy efficiency while satisfying QoS requirements and backhaul constraints.
1.4. Organization
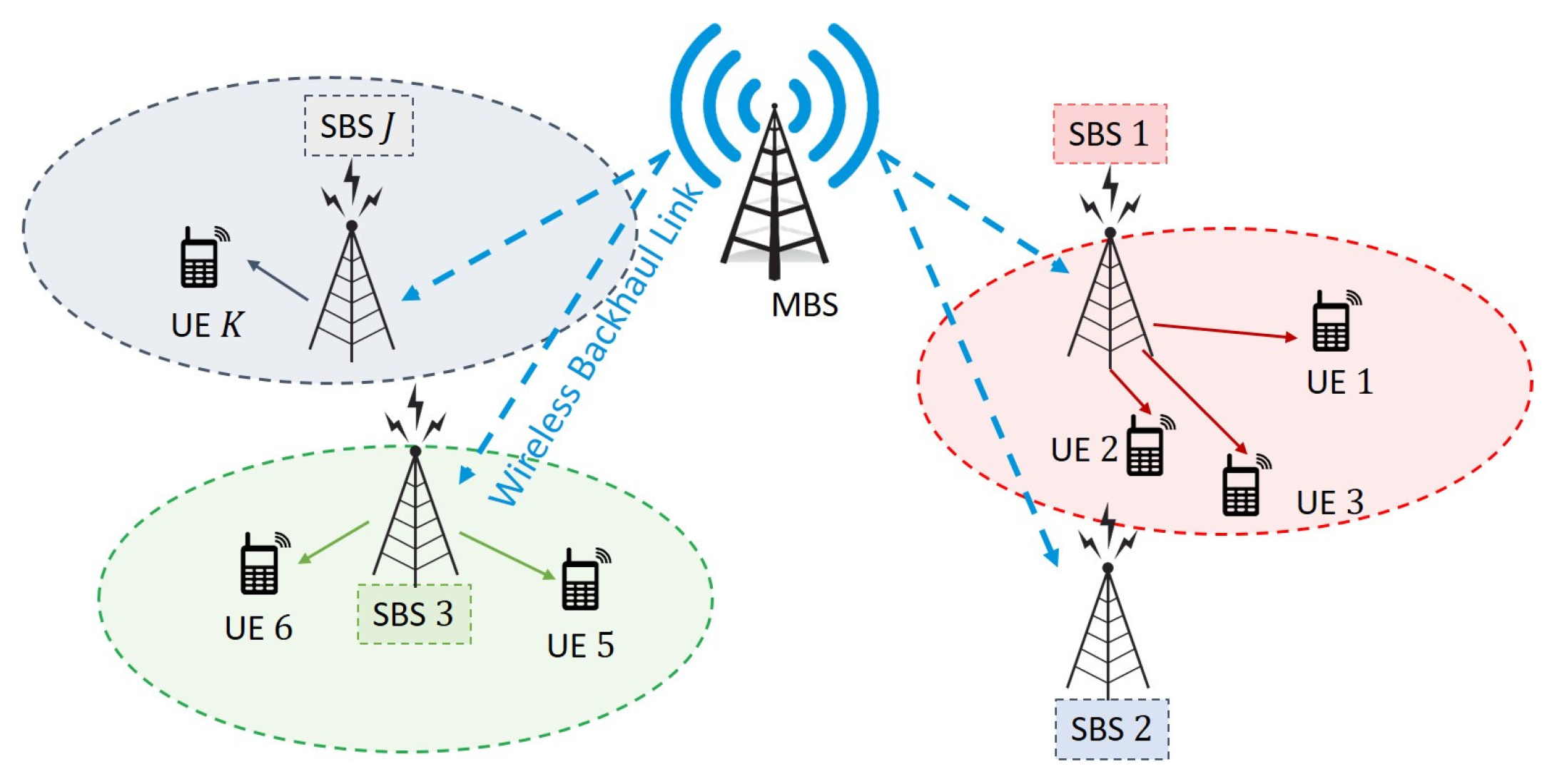
2. System Model
2.1. Heterogeneous Network
2.2. User Association
2.3. Power Consumption
3. Problem Formulation
3.1. Optimization Problem
3.2. Reinforcement Learning
3.3. State, Action, and Reward function
- State: The state at the time slot is defined as the user data rate in that time slot
- Action: The action in the time slot is defined aswhere , with and indicating the sets of user associations and power allocations, respectively. More specifically, the power allocation set is given by , where is the vector of allocated power for data transmission in all subchannels assigned to UE k from its associated SBS .
- Reward: We aim to maximize the overall energy efficiency as in (4a) while maintaining QoS for each US and satisfying the backhaul link capacity constraint for each SBS. Hence, the reward at the time slot is defined aswherewith being the system energy efficiency andbeing the penalty term which discourages the agent from taking the actions such that the capacity of each user deviates too much from the QoS threshold, and and are the Z-scores (i.e., standardized results) of and , respectively. is a threshold used to reduce the likelihood of violating the backhaul capacity constraint.
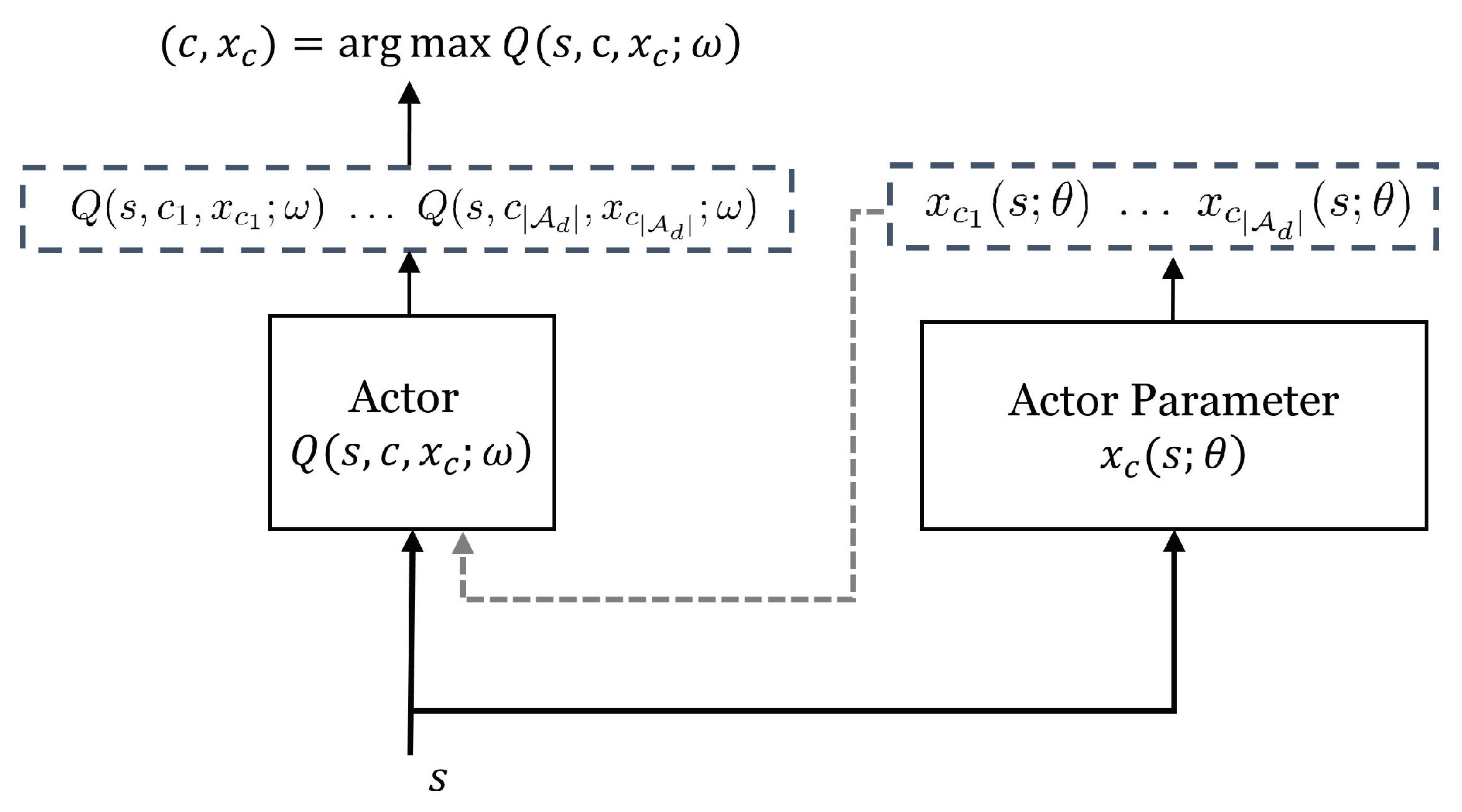
3.4. Parameterized Deep Q Network
| Algorithm 1 Parameterized Deep Q-Network (P-DQN) Algorithm with the quasi-static target networks. |
|
4. Simulation Results
4.1. Simulation Setup
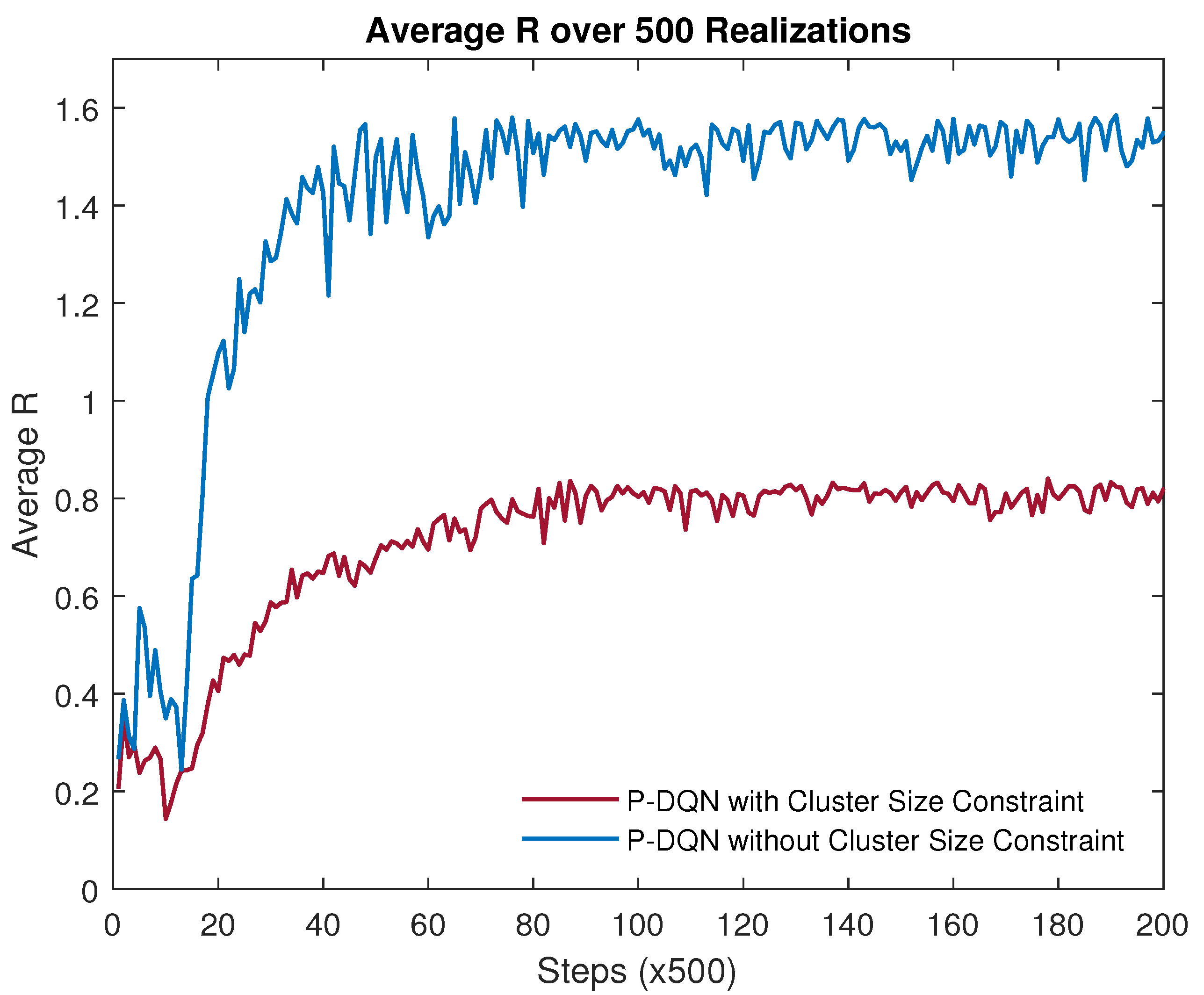
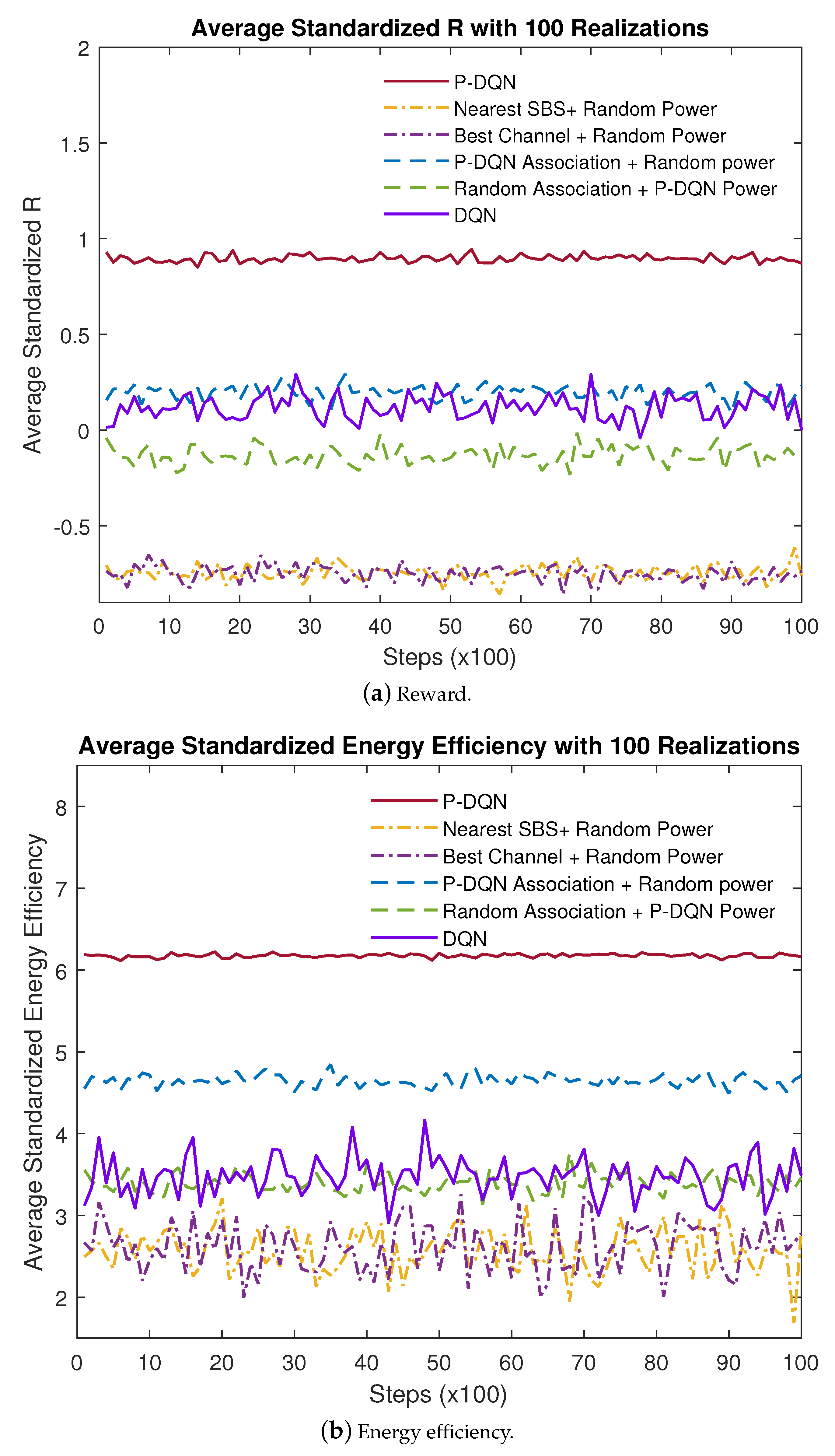
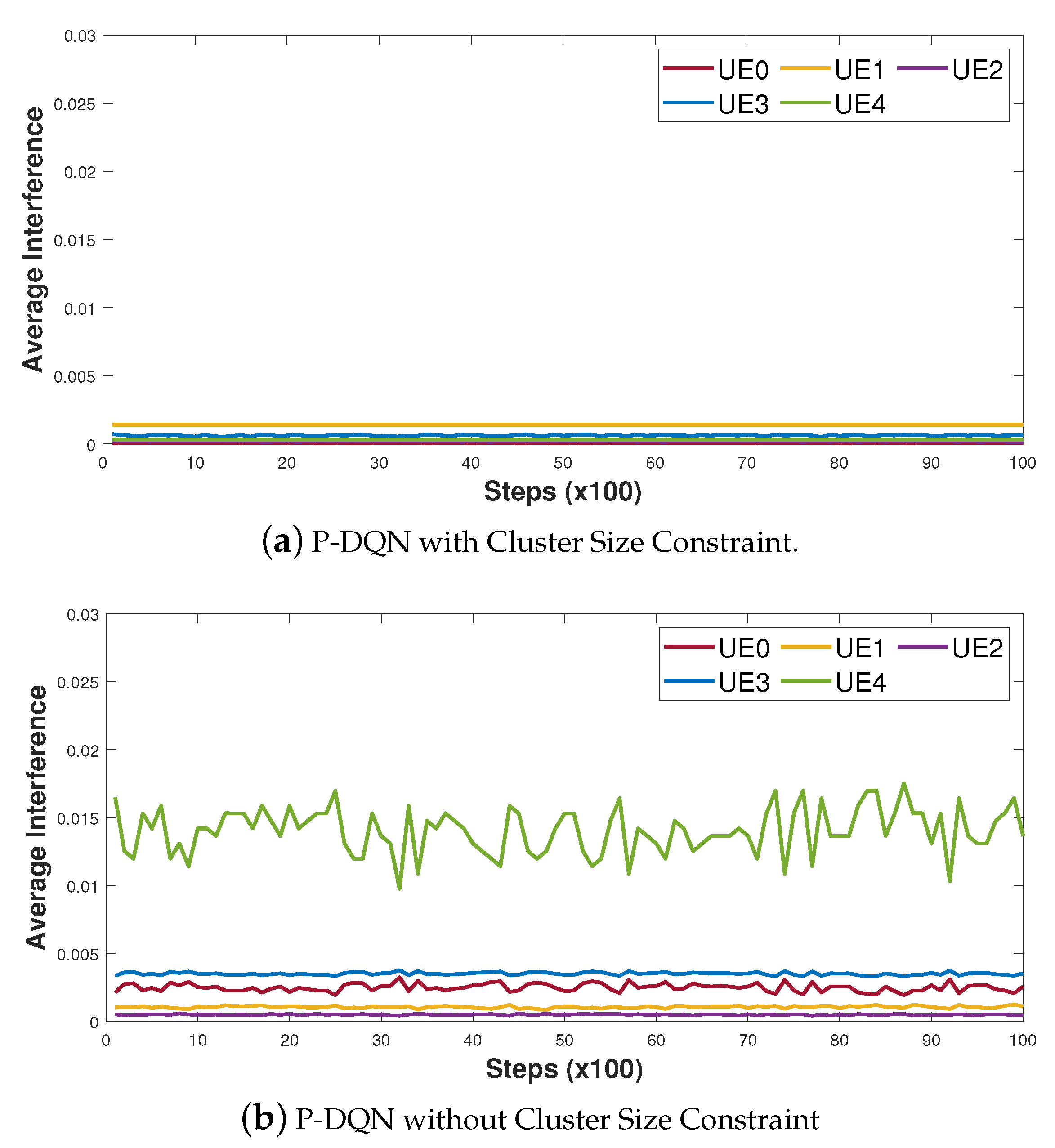
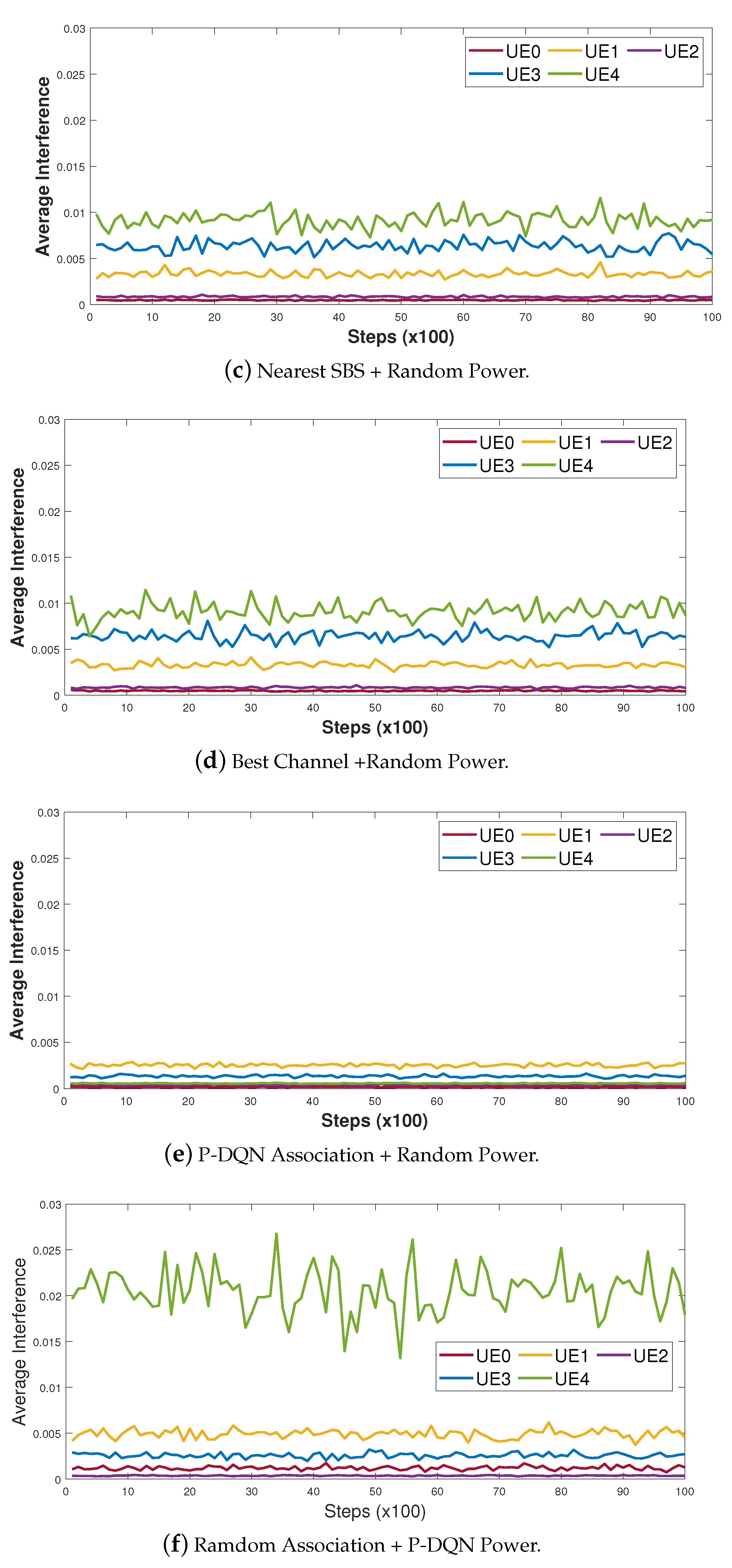
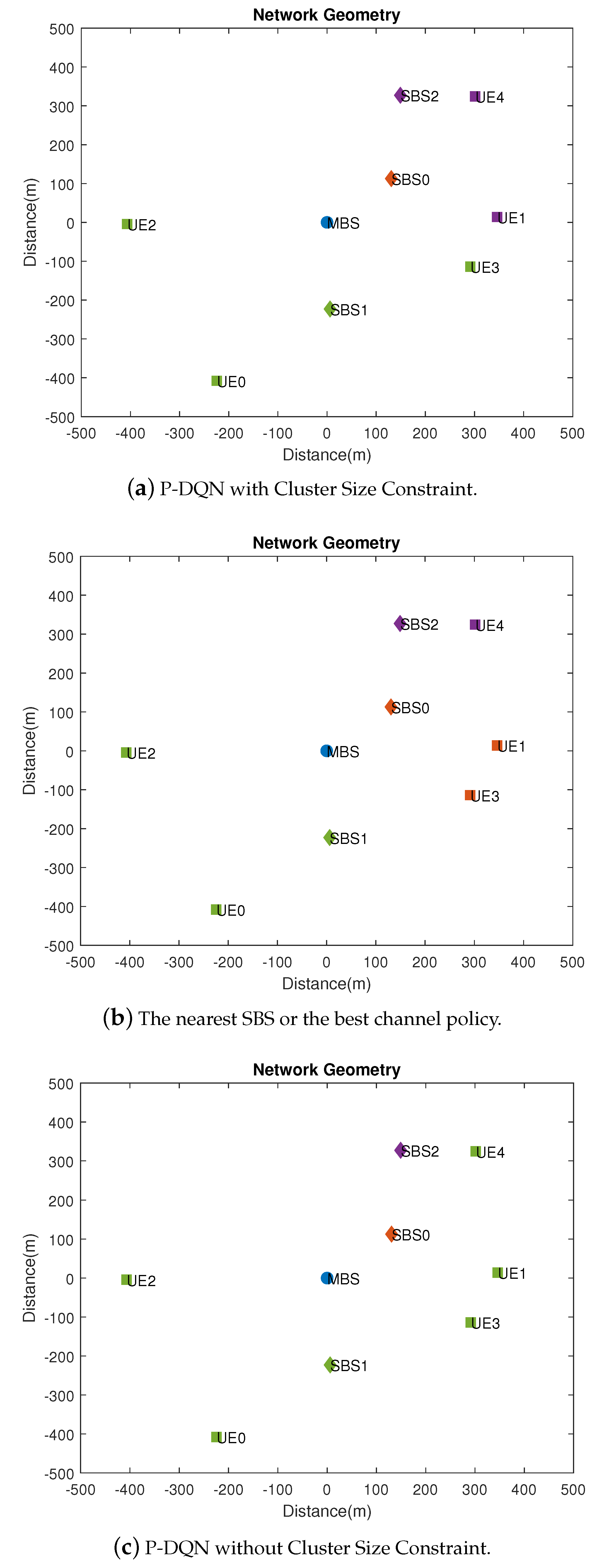
4.2. Performance Analysis
- Nearest SBS + Random Power: Each UE is associated with the nearest SBS. Random power means that each SBS serves the UEs in its cluster with random powers in a way that the resulting sum rate within the cluster cannot exceed the power and backhaul capacity limit.
- Best Channel + Random Power: Each UE is associated with the SBS with the best received signal power, which depends on the UE-SBS distance as well as the small-scale fading effect. Furthermore, each SBS serves the UEs in its cluster with random power allocations under the power and backhaul capacity constraint.
- P-DQN Association + Random Power: The user association policy is accomplished by the proposed P-DQN, whereas each SBS serves the UEs in its cluster with random powers under the total power and backhaul capacity constraint.
- Random Association + P-DQN Power: Each SBS allocates the power to its serving UEs based on the policy determined by the P-DQN. Each UE is randomly associated with one SBS in such a way that the random association policy obeys the backhaul link constraint.
- DQN with Five Discrete Power Levels: The continuous power space is quantized into L non-uniform power intervals, with L discrete power levels with . In this simulation, L is set to 4.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- Cisco. Cisco visual networking index: Global mobile data trafc forecast update, 2017–2022 white paper. Update 2019. [Google Scholar]
- Hu, R.Q.; Qian, Y. An energy efficient and spectrum efficient wireless heterogeneous network framework for 5G systems. IEEE Commun. Mag. 2014, 52, 94–101. [Google Scholar] [CrossRef]
- Mili, M.R.; Hamdi, K.A.; Marvasti, F.; Bennis, M. Joint optimization for optimal power allocation in OFDMA femtocell networks. IEEE Commun. Lett. 2016, 20, 133–136. [Google Scholar] [CrossRef]
- Sambo, Y.A.; Shakir, M.Z.; Qaraqe, K.A.; Serpedin, E.; Imran, M.A. Expanding cellular coverage via cell-edge deployment in heterogeneous networks: Spectral efficiency and backhaul power consumption perspectives. IEEE Commun. Mag. 2014, 52, 140–149. [Google Scholar] [CrossRef]
- Amiri, R.; Almasi, M.A.; Andrews, J.G.; Mehrpouyan, H. Reinforcement learning for self organization and power control of two tier heterogeneous networks. IEEE Trans. Wirel. Commun. 2019, 18, 3933–3947. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine learning paradigms for next-generation wireless networks. IEEE Trans. Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Deng, D.; Li, X.; Zhao, M.; Rabie, K.M.; Rupak, K. Deep learning-based secure MIMO communications with imperfect CSI for heterogeneous networks. Sensors 2020, 20, 1730. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; He, J.; Wu, J. Dynamic cooperative spectrum sensing based on deep multi-user reinforcement learning. Appl. Sci. 2021, 11, 1884. [Google Scholar] [CrossRef]
- Munaye, Y.Y.; Juang, R.T.; Lin, H.P.; Tarekegn, G.B.; Lin, D.B. Deep Reinforcement Learning Based Resource Management in UAV-Assisted IoT Networks. Appl. Sci. 2021, 11, 2163. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power allocation in multi-user cellular networks: Deep reinforcement learning approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Tam, H.H.M.; Tuan, H.D.; Ngo, D.T.; Duong, T.Q.; Poor, H.V. Joint load balancing and interference management for small-cell heterogeneous networks with limited backhaul capacity. IEEE Trans. Wirel. Commun. 2016, 16, 872–884. [Google Scholar] [CrossRef]
- Ma, H.; Zhang, H.; Wang, X.; Cheng, J. Backhaul-aware user association and resource allocation for massive mimo-enabled HetNets. IEEE Commun. Lett. 2017, 21, 2710–2713. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, S.; Jiang, C.; Long, K.; Leung, V.C.M.; Poor, H.V. Energy efficient user association and power allocation in millimeter-wave-based ultra dense networks with energy harvesting base stations. IEEE J. Select. Areas Commun. 2017, 35, 1936–1947. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Nasir, Y.S.; Guo, D. Multi-agent deep reinforcement learning for dynamic power allocation in wireless networks. IEEE J. Select. Areas Commun. 2019, 37, 2239–2250. [Google Scholar] [CrossRef]
- He, C.; Hu, Y.; Chen, Y. Joint power allocation and channel assignment for NOMA with deep reinforcement learning. IEEE J. Select. Areas Commun. 2019, 37, 2200–2210. [Google Scholar] [CrossRef]
- Park, H.; Lim, Y. Reinforcement learning for energy optimization with 5G communications in vehicular social networks. Sensors 2020, 20, 2361. [Google Scholar] [CrossRef]
- Amiri, R.; Mehrpouyan, H.; Fridman, L.; Mallik, R.K.; Nallanathan, A.; Matolak, D. A machine learning approach for power allocation in HetNets considering QoS. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Ahmed, K.I.; Hossain, E. A deep Q-learning method for downlink power allocation in multi-cell networks. arXiv 2019, arXiv:1904.13032. [Google Scholar]
- Xu, Z.; Wang, Y.; Tang, J.; Wang, J.; Gursoy, M.C. A deep reinforcement learning based framework for power-efficient resource allocation in cloud RANs. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Lu, Y.; Lu, H.; Cao, L.; Wu, F.; Zhu, D. Learning deterministic policy with target for power control in wireless networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Wei, Y.; Yu, F.R.; Song, M.; Han, Z. User scheduling and resource allocation in HetNets with hybrid energy supply: An actor-critic reinforcement learning approach. IEEE Trans. Wirel. Commun. 2018, 17, 680–692. [Google Scholar] [CrossRef]
- Li, D.; Zhang, H.; Long, K.; Wei, H.; Dong, J.; Nallanathan, A. User association and power allocation based on Q-learning in ultra dense heterogeneous networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–7. [Google Scholar]
- Liberati, F.; Giuseppi, A.; Pietrabissa, A.; Suraci, V.; Giorgio, A.D.; Trubian, M.; Dietrich, D.; Papadimitriou, P.; Priscoli, F.D. Stochastic and exact methods for service mapping ualized network infrastructures. Int. J. Netw. Manag. 2017, 27, 872–884. [Google Scholar] [CrossRef]
- Gao, J.; Zhong, C.; Chen, X.; Lin, H.; Zhang, Z. Deep Reinforcement Learning for Joint Beamwidth and Power Optimization in mmWave Systems. IEEE Commun. Lett. 2020, 24, 2201–2205. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, J.; Liang, Y.C.; Feng, G.; Niyato, D. Deep Reinforcement Learning-Based Modulation and Coding Scheme Selection in Cognitive Heterogeneous Networks. IEEE Trans. Wirel. Commun. 2019, 18, 3281–3294. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the 31st ICML, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep reinforcement learning in parameterized action space. arXiv 2015, arXiv:1511.04143. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Xiong, J.; Wang, Q.; Yang, Z.; Sun, P.; Han, L.; Zheng, Y.; Fu, H.; Zhang, T.; Liu, J.; Liu, H. Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space. arXiv 2018, arXiv:1810.06394. [Google Scholar]
- Wang, N.; Hossain, E.; Bhargava, V.K. Joint downlink cell association and bandwidth allocation for wireless backhauling in two-tier HetNets with large-scale antenna arrays. IEEE Trans. Wirel. Commun. 2016, 15, 3251–3268. [Google Scholar] [CrossRef]
- 3rd Generation Partnership Project (3GPP). Further Advancements for E-UTRA Physical Layer Aspects (Release 9); 3rd Generation Partnership Project (3GPP): Sofia Technology Park, France, 2016. [Google Scholar]
- Simulator. Available online: https://github.com/chikaihsieh/ Power-Allocation-and-User-Device-Association-with-Deep-Reinforcement-Learning/tree/main (accessed on 27 April 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Objective | QoS Constraint | Backhaul Constraint | User Association | Power Allocation | Method |
|---|---|---|---|---|---|---|
| [11] | Data Rate | × | × | × | Continuous | DDPG |
| [16] | Data Rate | × | × | × | Discrete | Distributed DQN |
| [18] | Power Efficiency | × | × | × | Discrete | DQN |
| [19] | Data Rate | ✓ | × | × | Discrete | DQN |
| [20] | Data Rate | × | × | × | Discrete | DQN |
| [21] | Power Efficiency | ✓ | × | × | × | DQN |
| [22] | Energy Efficiency | ✓ | × | × | Continuous | DRL-DPT |
| [23] | Energy Efficiency | × | × | Not Exactly | Continuous | Actor-Critic |
| [24] | Energy Efficiency | × | × | ✓ | Discrete | DQN |
| This work | Energy Efficiency | ✓ | ✓ | ✓ | Continuous | P-DQN |
| Notation | Definition |
|---|---|
| set of SBSs and set of UEs | |
| set of subchannels allocated to the kth UE | |
| the SBS serving the kth UE | |
| subchannel bandwidth | |
| MBS antenna array size | |
| total power consumption at all the SBSs. | |
| channel gain between SBS j and UE k in the fth subchannel | |
| channel coefficient between SBS j and UE k in the fth subchannel | |
| maximum power available at the jth SBS | |
| * transmit power from SBS j to UE k in the fth subchannel | |
| ** transmit power from the associated SBS to UE k | |
| number of active SBSs | |
| noise power | |
| interference experienced by UE k in subchannel f | |
| the set of UEs in cluster j | |
| link indicator between SBS j and UE k | |
| user association | |
| SINR for UE k in the fth subchannel | |
| capacity for UE k | |
| capacity threshold for UE k | |
| user sum-rate for SBS j | |
| maximum downlink data rate for SBS j |
| Parameter | Value |
|---|---|
| Carrier frequency | GHz |
| Subchannel bandwidth | kHz |
| Number of subchannels | |
| Number of subchannels per user | |
| MBS antenna array size | |
| MBS beamforming group size | |
| The radius of the entire network | 500 m |
| Number of SBS | |
| Number of UE | |
| SINR threshold of UE | for each UE |
| Path loss model | a. |
| (a. and b. indicate the model | in dB, in km |
| for UE and SBS, respectively) | b. |
| in dB, in km | |
| Rayleigh channel coefficient | (0,1) |
| Noise power spectral density | dBm/Hz |
| Maximum transmit power of SBS | dBm |
| Maximum cluster size | |
| Transmit power of MBS | dBm |
| Operational power of SBS | W |
| Operational power of MBS | W |
| Actor | Actor-Parameter | |
|---|---|---|
| Learning rate | ||
| Exploration | -greedy | Ornstein-Uhlenbeck noise |
| Number of Outputs | ||
| Hidden layer | ReLu, 16 ReLu, 128 ReLu, 512 | ReLu, 256 |
| Number of Inputs | K |
| Method Index | Average Reward | Average Energy Efficiency |
|---|---|---|
| (A) | 0.8957 | 6.1770 |
| (B) | −0.7453 | 2.5677 |
| (C) | −0.7499 | 2.6169 |
| (D) | 0.1968 | 4.6477 |
| (E) | −0.1327 | 3.3923 |
| (F) | 0.1186 | 3.4773 |
| Method Index | Percentage of Backhaul Constraint Satisfaction | Percentage of QoS Satisfaction |
|---|---|---|
| (A) | 100.00% | 83.47% |
| (B) | 100.00% | 44.91% |
| (C) | 100.00% | 44.42% |
| (D) | 100.00% | 50.22% |
| (E) | 100.00% | 4.87% |
| (F) | 100.00% | 0.58% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, C.-K.; Chan, K.-L.; Chien, F.-T. Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning. Appl. Sci. 2021, 11, 4135. https://doi.org/10.3390/app11094135
Hsieh C-K, Chan K-L, Chien F-T. Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning. Applied Sciences. 2021; 11(9):4135. https://doi.org/10.3390/app11094135
Chicago/Turabian StyleHsieh, Chi-Kai, Kun-Lin Chan, and Feng-Tsun Chien. 2021. "Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning" Applied Sciences 11, no. 9: 4135. https://doi.org/10.3390/app11094135
APA StyleHsieh, C.-K., Chan, K.-L., & Chien, F.-T. (2021). Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning. Applied Sciences, 11(9), 4135. https://doi.org/10.3390/app11094135