
Automated Software Vulnerability Detection Based on Hybrid Neural Network


Abstract
Feature Application
Abstract
1. Introduction
2. Related Work
2.1. Source Code Representation Learning
2.2. Intelligent Vulnerability Detection
3. Methods
3.1. Problem Formulation
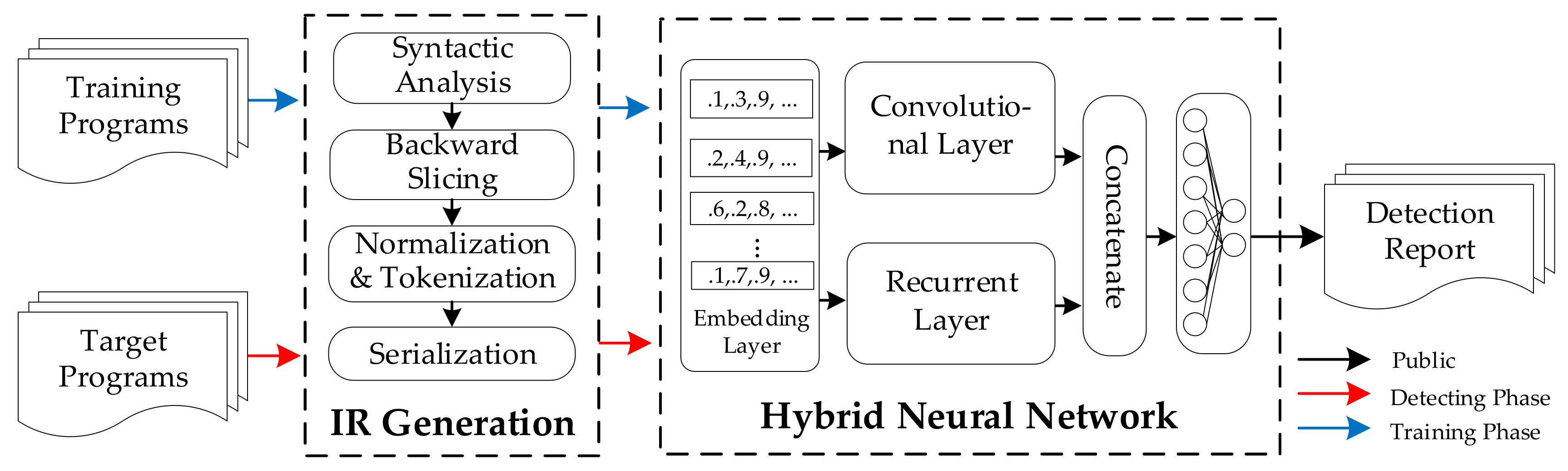
3.2. Overview
3.3. Intermediate Representation Generation
3.3.1. Parsing Source Code
3.3.2. Finding Slice Criterion
| Algorithm 1. Extracting security-sensitive operations from a program. |
| Input: A program , vulnerable syntax rules , Vulnerability manifest Output: A set of slice criterions 1: ; 2: for each vulnerability description do: 3: Get line from 4: Get label from 5: for each rule do: 6: if match : 7: extract slice criterion from ; 8: ; 9: end if; 10: end for; 11: end for; 12: return ; |
3.3.3. Program Slicing and Serialization
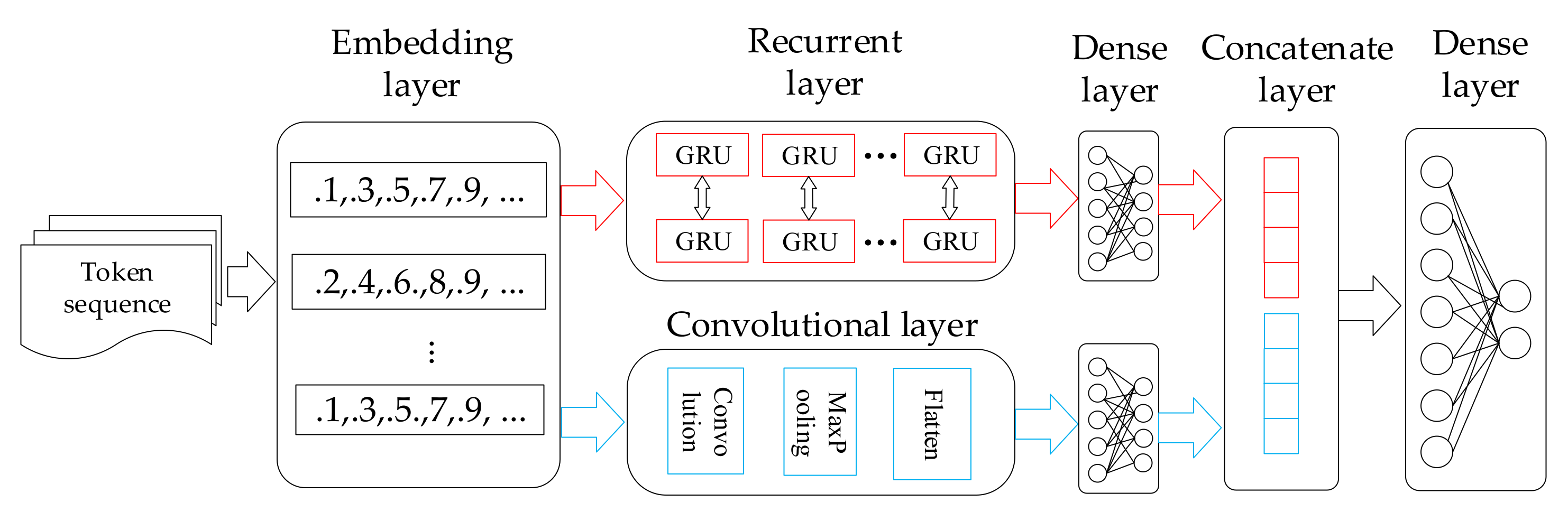
3.4. Hybrid Neural Network
3.5. Vulnerability Detection
4. Experiments
4.1. Research Questions
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Experiments for Answering RQ1
4.5. Experiments for Answering RQ2
4.6. Experiments for Answering RQ3
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- CVSS Severity Distribution Over Time. Available online: https://nvd.nist.gov/general/visualizations/vulnerability-visualizations/cvss-severity-distribution-over-time (accessed on 19 January 2021).
- Over 500,000 Zoom Accounts Sold on Hacker Forums the Dark Web. Available online: https://www.bleepingcomputer.com/news/security/over-500-000-zoom-accounts-sold-on-hacker-forums-the-dark-web/ (accessed on 19 January 2021).
- CheckMarx Software Official Website. Available online: https://www.checkmarx.com (accessed on 19 January 2021).
- Cadar, C.; Dunbar, D.; Engler, D.R. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs. In Proceedings of the OSDI, San Diego, CA, USA, 8–12 December 2008. [Google Scholar]
- Henzinger, T.A.; Jhala, R.; Majumdar, R.; Sutre, G. Software verification with BLAST. In Proceedings of the International SPIN Workshop on Model Checking of Software, Portland, OR, USA, 9–10 May 2003. [Google Scholar]
- Moshtari, S.; Sami, A. Evaluating and comparing complexity, coupling and a new proposed set of coupling metrics in cross-project vulnerability prediction. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016. [Google Scholar]
- Shin, Y.; Williams, L. Can traditional fault prediction models be used for vulnerability prediction? Empir. Softw. Eng. 2013, 18, 25–59. [Google Scholar] [CrossRef]
- Shin, Y.; Meneely, A.; Williams, L.; Osborne, J.A. Evaluating complexity, code churn, and developer activity metrics as indicators of software vulnerabilities. IEEE Trans. Softw. Eng. 2010, 37, 772–787. [Google Scholar] [CrossRef]
- Morrison, P.; Herzig, K.; Murphy, B.; Williams, L. Challenges with applying vulnerability prediction models. In Proceedings of the 2015 Symposium and Bootcamp on the Science of Security, Urbana, IL, USA, 21–22 April 2015. [Google Scholar]
- Wang, S.; Chollak, D.; Movshovitz-Attias, D.; Tan, L. Bugram: Bug detection with n-gram language models. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016. [Google Scholar]
- Ghaffarian, S.M.; Shahriari, H.R. Software vulnerability analysis and discovery using machine-learning and data-mining techniques: A survey. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Riccardo, S.; James, W.; Aram, H.; Wouter, J. Predicting vulnerable software components via text mining. IEEE Trans. Softw. Eng. 2014, 40, 993–1006. [Google Scholar]
- Pang, Y.; Xue, X.; Namin, A.S. Predicting vulnerable software components through n-gram analysis and statistical feature selection. 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. In Proceedings of the 25th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. SySeVR: A framework for using deep learning to detect software vulnerabilities. IEEE Trans. Dependable Secure Comput. 2021, 1. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Xin, Y.; Yang, Y.; Chen, Y. Automated Vulnerability Detection in Source Code Using Minimum Intermediate Representation Learning. Appl. Sci. 2021, 10, 1692. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y.; De Vel, O.; Montague, P. Cross-project transfer representation learning for vulnerable function discovery. IEEE Trans. Ind. Inform. 2018, 14, 3289–3297. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y. POSTER: Vulnerability discovery with function representation learning from unlabeled projects. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Bilgin, Z.; Ersoy, M.A.; Soykan, E.U.; Tomur, E.; Çomak, P.; Karaçay, L. Vulnerability Prediction from Source Code Using Machine Learning. IEEE Access 2020, 8, 150672–150684. [Google Scholar] [CrossRef]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. Code2vec: Learning distributed representations of code. In Proceedings of the ACM on Programming Languages (POPL), Cascais, Portugal, 14–15 January 2019. [Google Scholar]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. Code2seq: Generating Sequences from Structured Representations of Code. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional neural networks over tree structures for programming language processing. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A novel neural source code representation based on abstract syntax tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montréal, QC, Canada, 25–31 May 2019. [Google Scholar]
- Tufano, M.; Watson, C.; Bavota, G.; Di Penta, M.; White, M.; Poshyvanyk, D. Deep learning similarities from different representations of source code. In Proceedings of the 15th International Conference on Mining Software Repositories (MSR), Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to represent programs with graphs. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Eective vulnerability identification by learning comprehensive program semantics via graph neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Duan, X.; Wu, J.; Ji, S.; Rui, Z.; Luo, T.; Yang, M.; Wu, Y. VulSniper: Focus Your Attention to Shoot Fine-Grained Vulnerabilities. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Ben-Nun, T.; Jakobovits, A.S.; Hoefler, T. Neural code comprehension: A learnable representation of code semantics. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Moshtari, S.; Sami, A.; Azimi, M. Using complexity metrics to improve software security. Comput. Fraud. Secur. 2013, 5, 8–17. [Google Scholar] [CrossRef]
- Hovsepyan, A.; Scandariato, R.; Joosen, W. Is Newer Always Better? The Case of Vulnerability Prediction Models. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016. [Google Scholar]
- Shin, Y.; Williams, L. An initial study on the use of execution complexity metrics as indicators of software vulnerabilities. In Proceedings of the 7th International Workshop on Software Engineering for Secure Systems, Waikiki, Honolulu, HI, USA, 22 May 2011. [Google Scholar]
- Du, X.; Chen, B.; Li, Y.; Guo, J.; Zhou, Y.; Liu, Y.; Jiang, Y. Leopard: Identifying vulnerable code for vulnerability assessment through program metrics. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019. [Google Scholar]
- Yamaguchi, F.; Maier, A.; Gascon, H.; Rieck, K. Automatic inference of search patterns for taint-style vulnerabilities. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015. [Google Scholar]
- Yamaguchi, F.; Wressnegger, C.; Gascon, H.; Rieck, K. Chucky: Exposing missing checks in source code for vulnerability discovery. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013. [Google Scholar]
- Bian, P.; Liang, B.; Zhang, Y.; Yang, C.; Shi, W.; Cai, Y. Detecting bugs by discovering expectations and their violations. IEEE Trans. Softw. Eng. 2018, 45, 984–1001. [Google Scholar] [CrossRef]
- Dam, H.K.; Tran, T.; Pham, T.T.M.; Ng, S.W.; Ghose, A. Automatic feature learning for predicting vulnerable software components. IEEE Trans. Softw. Eng. 2021, 47, 67–85. [Google Scholar] [CrossRef]
- Wang, S.; Liu, T.; Tan, L. Automatically learning semantic features for defect prediction. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 18–20 May 2016. [Google Scholar]
- Liu, S.; Lin, G.; Qu, L.; Zhang, J.; De Vel, O.; Montague, P.; Xiang, Y. CD-VulD: Cross-Domain Vulnerability Discovery based on Deep Domain Adaptation. IEEE Trans. Dependable Secure Comput. 2020, PrePrints. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; De Vel, O.; Montague, P.; Xiang, Y. Software vulnerability discovery via learning multi-domain knowledge bases. IEEE Trans. Dependable Secure Comput. 2019, Early access. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Tang, J.; Zhang, Z.; Sun, M.; Jin, H. A comparative study of deep learning-based vulnerability detection system. IEEE Access 2019, 7, 103184–103197. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Chen, Z.; Zhu, Y.; Jin, H. Vuldeelocator: A deep learning-based fine-grained vulnerability detector. arXiv 2020, arXiv:2001.02350. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Ba Hdanau, D.; Bougares, F.; Schwenk, H. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods on Natural Language Processing, Doha, Qatar, 26–28 October 2014. [Google Scholar]
- SARD Manual. Available online: https://samate.nist.gov/index.php/SARD.html (accessed on 28 December 2020).
- Clang: A C Language Family Frontend for LLVM. Available online: https://clang.llvm.org/ (accessed on 28 December 2020).
- Introduction of DG. Available online: https://github.com/mchalupa/dg (accessed on 28 December 2020).
- Flawfinder Software Official Website. Available online: https://www.dwheeler.com/flawfinder/ (accessed on 29 December 2020).




{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| Embedding layer | The size of vocabulary and token vector are 538 and 100, respectively. The embedding matrix is randomly initialized. The max sequence length is 1000. |
| Convolutional layer | The number of convolutional filters is 256 with size 3. The window of the max-pooling filter is 4. |
| Recurrent layer | The units of both forward and backward GRU net are 256. Dropout and recurrent_dropout are set to 0.2 and 0.1, respectively. |
| Dense layer | The first two dense layers with 256 units are connected to the convolutional layer and the recurrent layer. The last dense layer generates prediction with two units. |
| Batch_size | The number of samples that are propagated through the network is 128. |
| Loss function | The function to evaluate the difference between the trained model and datasets is binary_crossentropy. |
| Optimizer | The algorithm to optimize the neural network is Adam. |
| Monitor | The matric to be monitored for early stop is F1-score and patience is 10. |
| Data | Sample Number | Average Length | Vocabulary Size | F1-Score |
|---|---|---|---|---|
| Raw data | 12,301 | 185 | 60,918 | - |
| LLVM IR | 12,301 | 513 | 43,179 | - |
| Source code based | 32,860 | 144 | 691 | 88.9 |
| VulDeeLocator [42] | 140,631 | 34 | 2665 | 97.4 |
| Our method | 32,860 | 51 | 537 | 98.6 |
| Method | FPR (%) | FNR (%) | Acc (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| Vocabulary | 12.9 | 80.3 | 84.1 | 79.7 | 73.8 | 76.6 |
| Random | 1.0 | 1.0 | 99.0 | 98.3 | 99.0 | 98.6 |
| Static | 1.4 | 3.6 | 87.8 | 97.6 | 96.4 | 97.0 |
| None-static | 0.9 | 3.0 | 98.3 | 98.4 | 97.0 | 97.7 |
| Model | Acc (%) | P (%) | R (%) | F1 (%) | TTime (s) | DTime (s) |
|---|---|---|---|---|---|---|
| Text-CNN | 92.6 | 95.6 | 89.8 | 92.6 | 11.0 | 1.5 |
| Bi-GRU | 98.2 | 96.5 | 98.8 | 97.6 | 203.6 | 109.8 |
| GRU + Attention | 93.8 | 90.5 | 93.2 | 91.8 | 831.2 | 180.9 |
| Our model | 99.0 | 98.3 | 99.0 | 98.6 | 1086.7 | 122.1 |
| Method | FPR (%) | FNR (%) | Acc (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| Flawfinder [46] | 12.9 | 80.3 | 62.1 | 47.3 | 19.7 | 27.8 |
| Checkmarx [3] | 46.5 | 51.8 | 51.6 | 37.7 | 48.2 | 42.3 |
| SySeVr [15] | 10.6 | 11.5 | 89.1 | 83.1 | 88.5 | 85.7 |
| VulDeeLocator [41] | 1.3 | 4.1 | 97.7 | 97.8 | 95.9 | 96.8 |
| Devign [26] | 8.3 | 13.3 | 89.8 | 86.0 | 86.7 | 86.4 |
| Our method | 1.0 | 1.0 | 99.0 | 98.3 | 99.0 | 98.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Wang, L.; Xin, Y.; Yang, Y.; Tang, Q.; Chen, Y. Automated Software Vulnerability Detection Based on Hybrid Neural Network. Appl. Sci. 2021, 11, 3201. https://doi.org/10.3390/app11073201
Li X, Wang L, Xin Y, Yang Y, Tang Q, Chen Y. Automated Software Vulnerability Detection Based on Hybrid Neural Network. Applied Sciences. 2021; 11(7):3201. https://doi.org/10.3390/app11073201
Chicago/Turabian StyleLi, Xin, Lu Wang, Yang Xin, Yixian Yang, Qifeng Tang, and Yuling Chen. 2021. "Automated Software Vulnerability Detection Based on Hybrid Neural Network" Applied Sciences 11, no. 7: 3201. https://doi.org/10.3390/app11073201
APA StyleLi, X., Wang, L., Xin, Y., Yang, Y., Tang, Q., & Chen, Y. (2021). Automated Software Vulnerability Detection Based on Hybrid Neural Network. Applied Sciences, 11(7), 3201. https://doi.org/10.3390/app11073201