
PornNet: A Unified Deep Architecture for Pornographic Video Recognition


Abstract
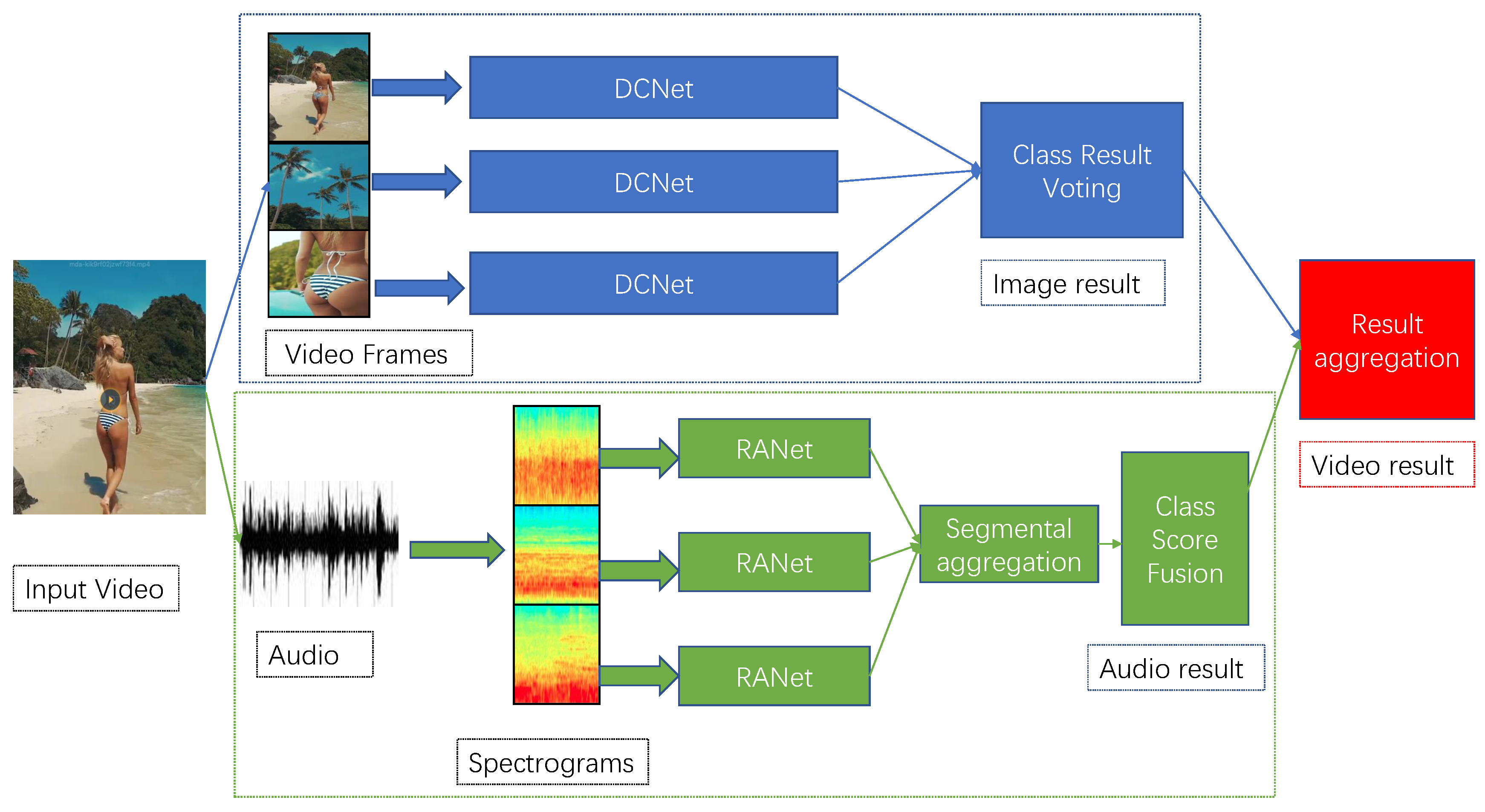
1. Introduction
- In order to capture the global and local information of porn images, we propose the DCNet including two carefully designed branches, namely detection and classification. In the detection branch, particularly, our proposed detector is anchor box free as well as proposal free, and thus completely avoids the complicated computation process related to anchor boxes such as setting the rate of the anchors. Besides, a weighted bi-directional feature pyramid network (BiFPN) is used to achieve multi-scale feature fusion;
- We propose a RANet based on audio feature embedding for pornographic audio detection. Specifically, the feature embedding termed log Mel-Spectrogram is an image-like representation, and the number of features is equal to the audio seconds. Furthermore, a frequency attention block is used to extract the inter-spatial relationship of a spectrogram, while the framework of Temporal Segment Networks (TSN) [28] is used for capturing the relationship of spectrograms along the temporal dimension in RANet. To the best of our knowledge, this is the first attempt to introduce DCNN to recognize pornographic audio;
- For pornographic video recognition, we specially assemble a dataset including 1 k real-world pornographic videos merged with 1 k videos and 1 k normal videos. Due to the privacy and copyright issue, we only show some examples analogous to our simulated data as illustrated in Figure 1. Experiments show that our proposed method can achieve an accuracy of 93.4% on the real-world dataset, demonstrating superior performance over the other state-of-the-art networks.
2. Related Work
2.1. Porn Image Recognition
2.1.1. Hand-Crafted Feature-Based Approaches
2.1.2. DCNN-Based Approaches
2.2. Porn Audio Recognition
2.2.1. Raw Waveform and 1D-CNN
2.2.2. Time-Frequency Representation and 2D-CNN
3. Our Proposed Methods
3.1. Detection-Classification Network
3.2. ResNet-Attention Network
3.3. Fusion of Pornographic Image and Audio Recognition Results
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.2.1. Training Setup
4.2.2. On-the-fly Inference
4.3. Ablation Studies
4.3.1. Ablation Studies on DCNet
4.3.2. Ablation Studies on ResNet-Attention Network
4.3.3. Combining DCNet and RANet
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Levy, S. Good Intentions, Bad Outcomes: Social Policy, Informality, and Economic Growth in Mexico; Brookings Institution Press: Washington, DC, USA, 2010. [Google Scholar]
- Zhao, Z.; Cai, A. Combining multiple SVM classifiers for adult image recognition. In Proceedings of the IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 24–26 September 2010; pp. 149–153. [Google Scholar]
- Moustafa, M. Applying deep learning to classify pornographic images and videos. arXiv 2015, arXiv:1511.08899. [Google Scholar]
- Tamburlini, G.; Ehrenstein, O.; Bertollini, R. Children’s Health and Environment: A Review of Evidence: A Joint Report from the European Environment Agency and the WHO Regional Office for Europe; World Health Organization, Regional Office for Europe, EE Agency: Copenhagen, Denmark, 2002. [Google Scholar]
- Bosson, A. Non-retrieval: Blocking pornographic images. In Proceedings of the International Conference on Image and Video Retrieval, London, UK, 18–19 July 2002; pp. 50–60. [Google Scholar]
- Zheng, Q.-F.; Zeng, W.; Wang, W.-Q.; Gao, W. Shape-based adult image detection. Inter. J. Image Graph. 2006, 6, 115–124. [Google Scholar] [CrossRef]
- Jang, S.-W.; Park, Y.-J.; Kim, G.-Y.; Choi, H.-I.; Hong, M.-C. An adult image identification system based on robust skin segmentation. J. Imaging Sci. Technol. 2011, 55, 20508–20601. [Google Scholar] [CrossRef]
- Deselaers, T.; Pimenidis, L.; Ney, H. Bag-of-visual-words models for adult image classification and filtering. In Proceedings of the Pattern Recogn, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Jiao, F.; Gao, W.; Duan, L.; Cui, G. Detecting adult image using multiple features. In Proceedings of the International Conferences on Info-Tech and Info-Net., Beijing, China, 29 October–1 November 2001; pp. 378–383. [Google Scholar]
- Shih, J.-L.; Lee, C.-H.; Yang, C.-S. An adult image identification system employing image retrieval technique. Pattern Recogn. Lett. 2007, 28, 2367–2374. [Google Scholar] [CrossRef]
- Yin, H.; Xu, X.; Ye, L. Big Skin Regions Detection for Adult Image Identification. In Proceedings of the 2011 Workshop on Digital Media and Digital Content Management, Hangzhou, China, 15–16 May 2011; pp. 242–247. [Google Scholar]
- Zhu, Q.; Wu, C.-T.; Cheng, K.-T.; Wu, Y.-L. An adaptive skin model and its application to objectionable image filtering. In Proceedings of the 12th annual ACM international conference on Multimedia, New York, NY, USA, 10–15 October 2004; pp. 56–63. [Google Scholar]
- Smith, D.; Harvey, R.; Chan, Y.; Bangham, J. Classifying Web Pages by Content. In Proceedings of the IEE European Workshop Distributed Imaging, London, UK, 18 November 1999; pp. 1–7. [Google Scholar]
- Chan, Y.; Harvey, R.; Bangham, J. Using Colour Features to Block Dubious Images. In Proceedings of the European Signal Processing Conference, Tampere, Finland, 4–8 September 2000; pp. 1–4. [Google Scholar]
- Garcia, C.; Tziritas, G. Face detection using quantized skin color regions merging and wavelet packet analysis. IEEE Trans. Multimed. 1999, 1, 264–277. [Google Scholar] [CrossRef]
- Fleck, M.M.; Forsyth, D.A.; Bregler, C. Finding naked people. In Proceedings of the European Conference on Computer Vision(ECCV), Cambridge, UK, 14–18 April 1996; pp. 593–602. [Google Scholar]
- Lopes, A.P.; de Avila, S.E.; Peixoto, A.N.; Oliveira, R.S.; Araujo, A.A. A bag-of-features approach based on hue-sift descriptor for nude detection. In Proceedings of the European Signal Processing Conference, Scotland, UK, 24–28 August 2009; pp. 1552–1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ou, X.; Ling, H.; Yu, H.; Li, P.; Zou, F.; Liu, S. Adult Image and Video Recognition by a Deep Multicontext Network and Fine-to-Coarse Strategy. ACM T. Intel. Syst. Technol. 2017, 8, 1–25. [Google Scholar] [CrossRef]
- Wang, X.; Cheng, F.; Wang, S. Adult image classification by a local-context aware network. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2989–2993. [Google Scholar]
- Kong, Q.; Xu, Y.; Wang, W.; Plumbley, M.D. Audio Set classification with attention model: A probabilistic perspective. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 316–320. [Google Scholar]
- Yu, C.; Barsim, K.S.; Kong, Q.; Yang, B. Multi-level attention model for weakly supervised audio classification. arXiv 2018, arXiv:1803.02353. [Google Scholar]
- Chou, S.-Y.; Jang, J.-S.R.; Yang, Y.-H. Learning to recognize transient sound events using attentional supervision. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 3336–3342. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Wang, Y.; Li, J.; Metze, F. A comparison of five multiple instance learning pooling functions for sound event detection with weak labeling. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 31–35. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bozkurt, B.; Germanakis, I.; Stylianou, Y. A study of time-frequency features for CNN-based automatic heart sound classification for pathology detection. Comput. Biol. Med. 2018, 100, 132–143. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. 2018, 41, 2740–2755. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.Z.; Li, J.; Wiederhold, G.; Firschein, O. System for Screening Objectionable Images. Comput. Commun. 1998, 21, 1355–1360. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Mallmann, J.; Santin, A.O.; Viegas, E.K. PPCensor: Architecture for real-time pornography detection in video streaming. Future Gener. Comp. Syst. 2020, 112, 945–955. [Google Scholar] [CrossRef]
- Tokozume, Y.; Harada, T. Learning environmental sounds with end- to-end convolutional neural network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2721–2725. [Google Scholar]
- Zhu, B.; Xu, K.; Wang, D.; Zhang, L.; Li, B.; Peng, Y. Environmental sound classification based on multi-temporal resolution convolutional neural network combining with multi-level features. In Proceedings of the Pacific Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; pp. 528–537. [Google Scholar]
- Abdoli, S.; Cardinal, P.; Koerich, A.L. End-to-end environmental sound classification using a 1D convolutional neural network. Expert Syst. Appl. 2019, 136, 252–263. [Google Scholar] [CrossRef]
- Volkmann, J.; Stevens, S.S.; Newman, E.B. A scale for the measurement of the psychological magnitude pitch. J. Acoust. Soc. Am. 1937, 8, 208. [Google Scholar] [CrossRef]
- Logan, B. Mel frequency cepstral coefficients for music modeling. In Proceedings of the International Symposium on Music Information Retrieval (ISMIR), Plymouth, MA, USA, 23–25 October 2000; Volume 270. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W. CNN architectures for large-scale audio classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Mydlarz, C.; Salamon, J.; Bello, J.P. The implementation of low-cost urban acoustic monitoring devices. Appl. Acoust. 2017, 117, 207–218. [Google Scholar] [CrossRef]
- Guzhov, A.; Raue, F.; Hees, J.; Dengel, A. ESResNet: Environmental Sound Classification Based on Visual Domain Models. arXiv 2020, arXiv:2004.07301. [Google Scholar]
- Piczak, K.J. Esc: Dataset for environmental sound classification. In Proceedings of the ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 18–19 June 2014; pp. 1041–1044. [Google Scholar]
- Riaz, H.; Park, J.; Choi, H.; Kim, H.; Kim, J. Deep and Densely Connected Networks for Classification of Diabetic Retinopathy. Diagnostics 2020, 100, 24. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Precision (%) | Recall (%) | Acc (%) | ||||
|---|---|---|---|---|---|---|---|
| P | S | N | P | S | N | ||
| ResNet50 | 85.0 | 90.3 | 93.5 | 90.1 | 85.0 | 92.4 | 89.2 |
| RCNet | 87.5 | 92.3 | 94.2 | 91.6 | 86.3 | 94.0 | 90.6 |
| FCNet | 88.3 | 93.3 | 94.8 | 92.3 | 87.2 | 94.6 | 91.4 |
| A-RCNet | 88.5 | 93.5 | 94.7 | 92.4 | 87.3 | 94.8 | 91.5 |
| DCNet | 90.0 | 95.5 | 95.1 | 93.5 | 88.5 | 95.5 | 92.5 |
| Features | Precision (%) | Recall (%) | Acc (%) | ||
|---|---|---|---|---|---|
| P | N | P | N | ||
| MFCC | 82.9 | 76.0 | 73.1 | 85.0 | 79.1 |
| GFCC | 86.2 | 78.1 | 75.6 | 87.9 | 81.8 |
| log-power SIFT Spectrograms | 82.3 | 82.1 | 82.1 | 82.4 | 82.3 |
| Log Mel-Spectrograms | 85.5 | 87.0 | 87.3 | 85.2 | 86.3 |
| Networks | Precision (%) | Recall (%) | Acc (%) | ||
|---|---|---|---|---|---|
| P | N | P | N | ||
| VGG | 80.6 | 82.6 | 83.1 | 80.0 | 81.6 |
| ResNet-18 | 82.5 | 85.0 | 85.6 | 81.9 | 83.8 |
| A-ResNet-18 | 83.8 | 86.1 | 86.6 | 83.3 | 85.0 |
| ResNet-50 | 83.0 | 85.6 | 86.1 | 82.4 | 84.3 |
| RANet | 85.5 | 87.0 | 87.3 | 85.2 | 86.3 |
| Frameworks | Precision (%) | Recall (%) | Acc (%) | ||||
|---|---|---|---|---|---|---|---|
| P | S | N | P | S | N | ||
| A-ResNet-18 + ResNet50 | 88.7 | 90.3 | 93.7 | 92.2 | 85.0 | 92.6 | 89.9 |
| A-ResNet-18 + RCNet | 90.1 | 92.3 | 94.3 | 93.6 | 86.3 | 94.1 | 91.3 |
| A-ResNet-18 + FCNet | 92.4 | 93.3 | 94.9 | 94.2 | 87.2 | 94.8 | 92.1 |
| A-ResNet-18 + A-RCNet | 92.3 | 93.5 | 94.8 | 94.8 | 87.3 | 95.0 | 92.4 |
| A-ResNet-18 + DCNet | 93.2 | 95.5 | 95.3 | 95.0 | 88.5 | 95.8 | 93.1 |
| Frameworks | Precision (%) | Recall (%) | Acc (%) | ||||
|---|---|---|---|---|---|---|---|
| P | S | N | P | S | N | ||
| RANet + ResNet50 | 90.3 | 90.3 | 93.9 | 92.6 | 85.0 | 92.7 | 90.1 |
| RANet + RCNet | 93.3 | 92.3 | 94.4 | 94.0 | 86.3 | 94.3 | 91.5 |
| RANet + FCNet | 94.1 | 93.3 | 94.9 | 94.6 | 87.2 | 94.9 | 92.2 |
| RANet + A-RCNet | 94.3 | 93.5 | 95.1 | 95.1 | 87.3 | 95.3 | 92.6 |
| RANet + DCNet | 95.6 | 95.5 | 95.6 | 95.8 | 88.5 | 96.0 | 93.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Z.; Li, J.; Chen, G.; Yu, T.; Deng, T. PornNet: A Unified Deep Architecture for Pornographic Video Recognition. Appl. Sci. 2021, 11, 3066. https://doi.org/10.3390/app11073066
Fu Z, Li J, Chen G, Yu T, Deng T. PornNet: A Unified Deep Architecture for Pornographic Video Recognition. Applied Sciences. 2021; 11(7):3066. https://doi.org/10.3390/app11073066
Chicago/Turabian StyleFu, Zhikang, Jun Li, Guoqing Chen, Tianbao Yu, and Tiansheng Deng. 2021. "PornNet: A Unified Deep Architecture for Pornographic Video Recognition" Applied Sciences 11, no. 7: 3066. https://doi.org/10.3390/app11073066
APA StyleFu, Z., Li, J., Chen, G., Yu, T., & Deng, T. (2021). PornNet: A Unified Deep Architecture for Pornographic Video Recognition. Applied Sciences, 11(7), 3066. https://doi.org/10.3390/app11073066