1. Introduction
The Arabic language is one of the oldest languages and is characterized due to its uniqueness and flexibility. Among many Semitic languages, Arabic is the most widely spoken language with over 290 million native speakers and 132 million non-native speakers [
1]. Arabic is one of the six official languages of the United Nations (UN) [
2]. Classical Arabic (CA) and modern standard Arabic (MSA) are the two main dialects of Arabic. CA is the language of the Quran while MSA is its modified version, which is currently used in everyday communication.
Rules of pronunciation are very well-defined for CA to preserve the accurate meaning of the words and constitute basic building blocks to help natives as well as non-natives to learn the Arabic language. The requirements to consider for correct pronunciation are the articulation points of the alphabets, characteristics of the alphabets, and extensive practicing of vocals [
3]. This research work focuses on developing an automated system that can recognize the correct pronunciation of the Arabic alphabet. This research is an important milestone for developing and classify a more sophisticated system that can automatically classify words and sentences to help in teaching classical Arabic pronunciation.
In this research, we take users’ audio data, process, and train neural networks (NN) over this data. The network learns from the data and classifies audio data and hence provides feedback to a learner on the alphabet pronunciation.
Automatic speech recognition (ASR) [
4] has received considerable attention and recently made significant progress with its applications in mobile computing [
5], human–computer interaction [
6,
7], information retrieval [
8], and assisted communication [
9]. ASR is a process of recognizing information from spoken words. Generally, ASR algorithms use acoustic, pronunciation, and language modeling [
4,
10]. ASR has active research attention in different human languages [
11]. In addition to ASR, many studies performed speech recognition with mispronunciation detection for children and other non-native language learners in many languages, i.e., English [
12,
13,
14], and Mandarin Chinese [
15,
16]. However, limited work has been done in Arabic ASR using pattern recognition and feature extraction techniques. Pattern recognition techniques used in ASR incorporate hidden Markov model (HMM) [
4,
17,
18], Gaussian mixture model (GMM) [
4,
19], artificial neural network (ANN) [
20], and multi-layer perceptron (MLP) [
20] using different feature extraction techniques such as mel-frequency cepstral coefficient (MFCC), linear predictive cepstrum coefficients (LPCC) [
21], and spectrogram.
The HMM [
17,
18] determines the set of states and associates them with the probabilities of transitions between these states called the Markov chain. GMM [
19] is a probabilistic model, which represents a normally distributed subclass within a class. Mixture models do not know a data point belonging to a subclass, and it allows the model to learn automatically. During the past decade, a few HMM and NN speech recognition systems have demonstrated to provide higher accuracy in the classical Arabic alphabet and verse recognition tasks. CMU Sphinx is one of the well-known open-source tools for CA based on HMM [
22,
23,
24,
25]. Researchers worked on different tasks using HMM such as an ‘E-Hafiz system’ which was proposed for CA learning using HMM and MFCC as a feature learning technique [
26]. This system achieved an accuracy of 92% for men and 90% for children. In [
27], the proposed system helps to improve the pronunciation of alphabets using mean square error (MSE) for pattern matching and MFCC as a feature extraction technique. This system successfully recognized correct pronunciation for various alphabets. In [
28], the ‘Tajweed checking system’ demonstrates detection and correction of students’ mistakes during recitations using MFCC, and vector quantization (VQ) with an accuracy of
–95%. In [
29], a ‘Qalqalah letter pronunciation’ is proposed using spectrogram, this technique illustrates the mechanism of Qalqalah sound pronunciation. In [
30], a ‘mispronunciation detection system for Qalqalah letters’ is proposed using the MFCC, and support vector machine (SVM) classifier, which provides an accuracy of
%.
Deep learning (DL) algorithms learn a hierarchical representation from data with numerous layers [
31]. The hidden layers are responsible to extract important features from the raw data to achieve a better representation of the audio data. In [
32], the author proposes an Arabic alphabet recognition model using RNN with back-propagation through time, with an accuracy of 82.3% tested for 20 alphabets. In recent research [
33], the authors demonstrated a mispronunciation detection system using different handcrafted techniques for feature extraction and SVM, KNN, and NN as classifiers. This experiment achieved an accuracy of 74.37% for KNN,
% for SVM, and 90.1% for NN.
In this paper, we propose a DL algorithm, i.e., DCNN, AlexNet, and BLSTM neural networks, for the Arabic alphabet classification. Our research is different from the previous works in terms of the dataset, features extraction, network architecture, and performance. We employ mel-spectrogram for extracting features of the audio dataset of alphabets. The mel-spectrogram is the conversion of audio frames into frequency-domain representation, which are scaled on an equally spaced mel-scale. The magnitude or power spectrum passes through the mel-filter to obtain the mel-spectrogram. The previous approaches mostly use MFCC, which is related to mel-spectrogram. MFCC coefficients are obtained by passing a mel-spectrum through a logarithmic scale and then discrete cosine transform (DCT). Due to excessive use of DL in speech systems, DCT is no longer a necessary step [
34].
We are working on two classification problems using an audio dataset of the Arabic alphabet. The first problem is a multi-class classification task to detect and classify the alphabet to their respective classes. The second problem is a binary class classification task that detects and classifies the correct and incorrect pronunciation to their respective class. The models we use in this research are CNN model learns features from mel-spectrogram and BLSTM learns to use the spectral features technique. In this paper, our major contributions are:
Collection of an audio dataset for the Arabic alphabet with correct and mispronunciation.
Arabic alphabet classification (recognize each alphabet).
Arabic alphabet pronunciation classification (detect correct pronunciation of the alphabet).
Exploration of DCNN, AlexNet, and BLSTM to perform classification of the audio set of the Arabic alphabet.
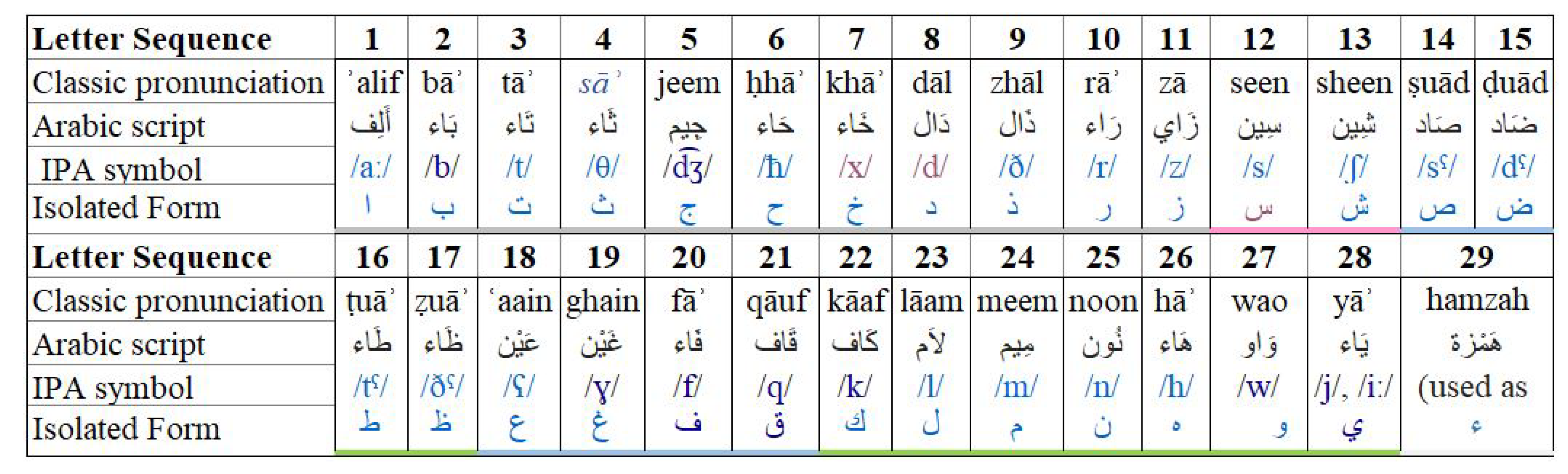
The Arabic language has 29 alphabets, and we consider each alphabet as a class. The Arabic alphabet classification is a multi-class classification problem, which involves the Arabic alphabet audio dataset, and the classification task recognizes each alphabet’s class. The audio file with the alphabet sequence shown in
Figure 1, is fed into NN. The network learns and extracts the feature set of each alphabet based on its characteristics. The classifier then evaluates and differentiates the alphabet in their respected class. On the other hand, Arabic alphabet pronunciation classification is a binary classification problem. In this task, our focus is to detect the correct pronunciation of the alphabet. The network learns characteristics of the dataset and classifies them into correct pronunciation and mispronunciation classes.
The organization of the rest of the paper is as follows.
Section 2 explains the collection and preprocessing of the data.
Section 3 presents the proposed methodology and DL classification models. In
Section 4, we present experimental results and their comparative analysis.
Section 5 concludes our work.
3. Methodology
This section presents the methodology and different stages of this research work. This research work consists of five stages: data collection, preprocessing, feature extraction, network training, and classification of unseen data. These stages are described through the system architecture as shown in
Figure 5.
The first and second stage of this proposed methodology involves the collection of the dataset and preprocessing, we have already discussed these two stages in the previous section. The third stage involves feature extraction; the features are extracted from the raw data and input to the fourth stage for training the network using deep learning models. In the end, we compare the training data with unseen testing data. Then we estimate the accuracy and display the confusion charts for each class.
DCNN, AlexNet, and BLSTM algorithms applicable to both the Arabic alphabet classification problem and the alphabet pronunciation classification problem. The only difference is in the dataset and the number of classes. The evaluation experiment conducted in this work is speaker-open/speaker-independent.
3.1. Feature Extraction
In ASR systems, we extract a feature set from the speech signals. The classification algorithm is performed on the features set instead of speech signals directly. Feature extraction provides a compact representation of speech waveforms. Classification-based feature extraction reduces redundancy and removes the irrelevant information in large datasets [
40]. A large dataset requires huge memory and computation power and leads to over-fitting.
CNN extracts feature autonomously and converts the raw audio data into mel-spectrogram [
41]. We have done this conversion only for CNN (DCNN and AlexNet) as it takes an input image, processes it, and then classifies it in different categories. CNN extracts and filters an enormous number of features to get useful features for the classification of the audio alphabet. In this work, we are using filtered features, from the FC layer.
On the other hand, BLSTM needs assistance for extracting features. In the BLSTM network, we extract the information of the given dataset using spectral features from the raw audio data. The extracted data are stored and later given as input to the BLSTM network for training, testing, and evaluation of audio alphabet [
42]. First, we use mel-spectrum with BLSTM, but the results were not promising, so we opted toward handcrafted features. We extract 12 spectral features from the raw data including spectral centroid, spectral spread, spectral skewness, spectral kurtosis, spectral entropy, spectral flatness, spectral crest, spectral flux, spectral slope, spectral decrease, spectral roll-off point, and pitch. These features are widely used in machine learning, deep learning applications, and perceptual analysis. We are using these features to differentiate notes, pitch, rhythm, and melody of speech.
3.2. Neural Network Model Training
The development of the learning model requires a history of the training data and provide observation of the data with input. The network captures the meaning of these observations in the output. The neural network learns a mapping function to find an optimal set of model parameters. We tested different network parameters and after their empirical analysis, the following parameter values are used as shown in
Table 1.
Table 1.
Training option of the neural network.
Table 1.
Training option of the neural network.
| Parameters | DCNN | AlexNet | BLSTM |
|---|
| Learning Rate | 0.0001 | 0.00001 | 0.001 |
| Epochs | 35 | 35 | 100 |
| Batch Size | 75 | 373 | 126 |
| Optimizing Algorithm | Adam [43] |
3.3. Deep Learning Models for Classification
DL consists of vast models and several associated algorithms. The dataset and the type of tasks performed play a significant role in selecting a model. The audio alphabet dataset is trained and tested using deep learning models to achieve better accuracy and minimum loss function. The pre-trained models on the Quranic dataset are not available, so we trained the algorithms from scratch and by fine-tuning the existing models. Two types of models are selected for the classification of audio alphabets:
3.3.1. Convolution Neural Network
Convolution neural network [
44] consists of an independent filter used for image data, classification prediction problems, and regression prediction problems due to its deep structure, it is also called DCNN. The number of features depends on the number of filters and extracts the mel-spectrogram of raw data (wav file). Each convolution layer learns features from the mel-spectrogram and the remaining layers process the useful information from the learned feature. This network consists of the 24-layer architecture of DCNN given in
Figure 6. We have used the following Algorithm 1 for DCNN.
| Algorithm 1: Classification task performed using DCNN. |
| Input |
| ads = Audio dataset |
| nLabels = Number of classes |
| Labels = Define class labels |
| numBands = Numbers of bands |
| Seg_Dr = Segment duration |
| Hop_Dr = Hop duration |
| Frame_Dr = Frame duration |
| Output |
| Accuracy = Model accuracy |
| YPredicted = Predicted labels |
| Algorithm |
| Begin |
| nBands, Seg_Dr, Hop_Dr, Frame_Dr←Define Parameters |
| adsTrain[ ], adsTest[ ] ← Split(ads) |
| melspectrogram(adsTrain[ ], Seg_Dr, Hop_Dr, Frame_D, nBands)→XTrain[ ] |
| melspectrogram (adsTest[ ], Seg_Dr, Hop_Dr, Frame_Dr, nBands)→ XTest[ ] |
| YTrain[ ] ← adsTest.Labels[ ] |
| YTest[ ] ← adsTest.Labels[ ] |
| Define Image Size → imageSize[ ] |
| trainNetwork ← XTrain[ ], YTrain[ ], layers, options |
| YPredicted[ ], Probability[ ] ← classify(trainedNetwork, XTest) |
| Accuracy ← mean (YPredicted[ ] == YTest[ ]) |
| Confusion_Matrix ← YPredicted[ ], YTest[ ] |
| End |
The transfer learning (TL) [
45,
46] technique is used in ML and its sub-field DL. This method is designed for one task and can be reused as a starting point for a new related task. Pre-trained networks are used as a starting point in new research, as these networks help us save vast computation and time resources required to design a network. There are two ways to use transfer learning. Firstly, by extracting features using a pre-trained network, and then train the network model. Secondly, by fine-tuning the pre-trained network by keeping the weights learned as an initial parameter. Fine-tuning is used when we are using an NN that has been designed and trained by someone else. It allows taking advantage without having to develop it from scratch. Therefore, we are relying on the second method.
AlexNet is trained on millions of images from the ImageNet database [
44]. It is trained in 1000 categories and is enriched with a wide range of feature representations. The standard size of this network is
(In image size 227 represents the number of frames, 227 represents the number of bands, and 3 represents the spectrum.) and consists of 25-layers shown in
Figure 7. We convert the raw data to the mel-spectrogram because AlexNet is trained on the ImageNet dataset. The mel-spectrograms are resized according to AlexNet’s standard input size, and inputs to the model. The standard AlexNet is trained on 1000 categories, whereas this work consists of 29 classes of the alphabet classification problem and 2 classes of the alphabet pronunciation classification problem. Therefore, to use pre-trained AlexNet, we have replaced 3 final layers of AlexNet named fully connected layer (Fc8), SoftMax layer, and classification layer (output layer). We have fine-tuned them according to our classification problems. After this, the network extracts features from the mel-spectrogram autonomously and learns from the dataset.
We need to specify the output size of the fully connected layers according to the number of classes of our data. Other parameters are learned after their empirical analysis, and network training. The test dataset is compared to the training dataset to observe the performance of the network. We have used Algorithm 2 for the AlexNet pre-trained network model.
3.3.2. Recurrent Neural Network
The recurrent neural network is designed to work with sequence prediction problems. Long short-term memory (LSTM) network is a special kind of RNN, which is skilled in learning long-term dependencies to help RNN in remembering long-term information lost during training.
| Algorithm 2: Classification task using AlexNet with the transfer learning approach. |
| Input |
| ads = Audio dataset |
| nLabels = Number of classes |
| Labels = Define class labels |
| Output |
| AlexNet_Accuracy = Model accuracy |
| YPredicted = Predicted labels |
| Algorithm |
| Begin |
| XTrain[ ], YTrain[ ] ← Training set |
| XTest[ ], YTest[ ] ← Testing set |
| Define Image Size → inputSize[ ] |
| network → AlexNet |
| layersTranfer ← net.Layers(1:end-3) |
| netTransfer ← trainNetwork(XTrain, YTrain, layers_1, options) |
| [YPredicted, Probability] ← classify(netTransfer, XTest) |
| AlexNet_Accuracy ← mean(YPredicted[ ] == YTest[ ]) |
| Confusion_Matrix ← confusionchart(YTest, YPred) |
| End |
RNNs and LSTMs have received a high success rate when working with sequences of words and paragraphs. This includes both sequences of text and spoken words represented as time series. RNNs are mostly used for text data, speech data, classification prediction problems, regression prediction problems, and generative models. LSTM is a unidirectional network that learns only forward sequence as it can only see past. Whereas BLSTM is used to predict backward and forward sequence: one from past to future and the other from future to past [
47]. We have used BLSTM for the training of our dataset and the architecture is shown in
Figure 8. The most commonly used in audio sequences for spectral feature extraction for input in RNN networks. We have used the following Algorithm 3.
3.4. Classification of Unseen Data
Partitioning of the data is useful for the training and evaluation of machine learning models. The dataset is usually divided into two non-overlapping groups: training data and testing data. The training data are used for the modeling and feature set development. The test data are used to measure the model’s performance. We have divided our dataset into
training data and 20% testing data.
| Algorithm 3: Classification task using a recurrent neural network (BLSTM). |
| Input |
| ads = Audio dataset |
| nLabels = Number of classes |
| Labels = Define class labels |
| Output |
| YPredicted = Predicted labels |
| AlexNet_Accuracy = Model accuracy |
| Algorithm |
| Begin |
| FeatureTrain[ ] ← ExtractFeature( adsTrain), FeatureTest[ ] ←ExtractFeature( adsTest) |
| FeatureYTrain [ ] ← FeatureTrain.labels, FeatureYTest[ ] ←FeatureTest.Labels |
| Define Image Size → inputSize[ ] |
| for i ← 1:numObservationsTrain |
| sequence ← FeaturesTrain{i} |
| sequenceLengthsTrain(i) ← size(sequence, 2) |
| endfor |
| [sequenceLengthsTrain, idx] ← sort(sequenceLengthsTrain) |
| for i ← 1:numObservationsTest |
| sequence ← Featurestest{i} |
| sequenceLengthsTest(i) ← size(sequence, 2) |
| endfor |
| [sequenceLengthsTest, idx] ← sort(sequenceLengthsTest) |
| XTrain ← FeaturesTrain(idx), YTrain ← FeatureYTrain(idx) |
| XTest ← FeaturesTest(idx), YTest ← FeatureYTest(idx) |
| network → BLSTM |
| net ← trainNetwork(XTrain, YTrain, layers, options) |
| [YPredicted, Probability] ← classify(net, YTest) |
| BLSTM_Accuracy ← mean(YPredicted[ ] == YTest[ ]) |
| Confusion_Matrix ← confusionchart(YTest, YPred) |
| End |
5. Conclusions
In this paper, we have proposed a framework for CA speech recognition using deep learning techniques including DCNN, AlexNet, and BLSTM. We implemented these learning models and demonstrated their results on the Arabic alphabet audio dataset. Several experiments are performed using three different validation techniques including random splitting, 5-fold cross-validation, and hold-out validation. AlexNet outperformed the DCNN and BLSTM in the classification tasks. We have performed two tasks, i.e., Arabic alphabet classification and Arabic alphabet pronunciation classification using augmented and non-augmented dataset while we have achieved promising results with data augmentation.
The first part of this research is Arabic alphabet classification, which is successfully performed by using AlexNet and yielded an accuracy of % with data augmentation. The second part of this research is the Arabic alphabet pronunciation classification using the AlexNet model and, we achieved an accuracy of % with data augmentation. As future work, we would like to extend the proposed method to incorporate more feature sets and increase the size of the dataset for words and sentence recognition. We would further like to investigate some new network architectures, i.e., Xception, Inception, ResNet, and NASNet.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








