1. Introduction
Thanks to the increasing capabilities of open source software (OSS) development tools, the number of open-source users and projects is growing each year. Existing software collaboration platforms include millions of developers with different characters and skill sets, as well as a wide variety of projects that offer solutions to various problems. GitHub, is the largest one among these platforms, that hosting more than 40 million repositories to which over 100 million developers have contributed. On this platform, several features are used to manage the distributed and open-source projects of which the most widely used are issues, commits, and pull requests (PRs). Activities related to these features—such as opening an issue, merging a PR, or commenting on a commit—can provide information about the developers and projects. The knowledge obtained from this information can then be used in the form of developer metrics to solve various software engineering challenges.
The some of the developer metrics used are the number of lines of code in a project, developer degrees of connection to one another, past experience, or common features (e.g., nationality, location, occupation, gender, previously used programming languages). These metrics offer solutions to different problems within OSS development and distributed coding, including automatic assignments (task, issue, bug, or reviewer) [
1,
2,
3], project recommendation systems [
4,
5], and software defect detection [
6].
However, on platforms with such a large amount of data, it is challenging for developers to find similar projects to their own, identify projects of interest, and reach projects to which they can contribute. As developers primarily use search engines or in-platform search menus to find projects, the constraints of text-based search [
7] and challenges related to finding the correct keywords also lead them to miss some projects [
8]. While various project recommendation systems are being developed to overcome this problem, projects must be rated by users if recommendation models are to work properly. In the same way that viewers give ratings to movies that they have watched, developers need to rate the projects in which they are interested. However, this does not currently occur on software collaboration platforms, meaning there is no labeled dataset for work on this problem. For this reason, several developer metrics that can be extracted from the activity or features of both developers and projects can be used to calculate the score that a user gives projects.
In this study, new developer metrics are presented to be used for a variety of open source distributed software development challenges. We developed a project recommendation system due to evaluate these metrics using data from GitHub with the aim of making recommendations to developers based on their GitHub activities. Moreover, to address the sparsity problem on GitHub, we selected a dataset with a high project-user ratio. Despite this handicap, we obtained remarkable results in comparison with a similar study [
5]. We present the following research questions for this study:
- RQ1.
Can we offer new evaluation methods for GitHub project recommendation problem?
- RQ2.
Can we use the activities of GitHub users as a developer metric individually?
- RQ3.
Can new metrics be obtained by combining similar properties or activities?
- RQ4.
Is a user’s amount of activity important in the context of developer metrics?
In light of these research questions, we organized this paper as follows. In the background section, we discuss the literature on previously proposed developer metrics that have been used for a wide range of OSS development challenges. In the following section, we describe our dataset, proposed metrics, and project recommendation model. We evaluate the metrics using different approaches and methods in the last section.
2. Background
The activities of developers in platforms such as GitHub provide collaboration, learning, and reputation management in the community [
9]. These activities are the metadata of the platforms which directly correlated to reputation or performance of the developers [
10]. Besides, the developer metrics are also created from these activities. In general, the metrics are related to the features of distributed code development processes such as issue, commit, and PR. We present some metrics that have been discussed in the literature in terms of these features and explain the challenges on which studies using these metrics have focused.
PR allows users to inform others about changes they have pushed to a branch in a repository on GitHub. PRs are a key feature when contributing code by different developers to a single project [
11]. The proposed metrics related to this feature are used to solve different PR-related problems. PRs need to be reviewed (by a reviewer) in order to merge projects. If the result of a review is positive, the PR is integrated into the master branch. Finding the correct reviewer is thus an important parameter for ensuring rapid and fair PR revisions. Different metrics have been used in this context to address the problem of automatic PR reviewer assignment. The existing literature has proposed various metrics to solve this problem, including PR acceptance rate within a project, active developers on a project [
3], PR file location [
12], pull requesters, social attributes [
13], and textual features of the PR [
14], among others. Closing a PR with an issue, PR age, and mentioning (@) a user in the PR comments have all been used to determine the priority of a PR [
15]. Cosentino proposed three developer metrics (community composition, acceptance rates, and becoming a collaborator) to investigate project openness and stated that project owners could evaluate the attractiveness of their projects using these metrics [
16].
Developer metrics are also used for software defect detection. In one study, defects were estimated using different metrics grouped by file and commit level. The number of files belonging to a commit, the most modified file of all files in a commit, the time between the first and last commit, and the experience of a given developer on a committed file were identified as important metrics [
6].
Reliability metrics are used to quantitatively express the software product reliability [
17]. Metrics used to measure reliability in OSS include number of contributors, number of commits, number of lines in commits, and certain metrics derived from them. Tiwari proposed two important metrics for reliability, namely contributors and number of commits per 1 K code lines [
18].
Code ownership metrics are also important problem for OSS. One study used the modified (touched) number of files to rank developer ownership according to code contributions [
19]. In another study, researchers used the number of changed lines in a file (churn) to address this problem [
20]. Foucault confirmed the relationship between these code ownership metrics and software quality [
21].
Recommender systems are an important research topic in software engineering [
22,
23]. In ordinary recommendation models, previously known user-item matrices are used. In other words, the rating given by a user for an item is known. In such cases, the essential research topic involves using different algorithms and models to estimate the rating that the user has already given [
24]. However, this differs on software collaboration platforms like GitHub. Considering the developer as the user and the project (repository or repo) as the item, the rating that a developer gives to a project is unknown. In this context, the first problem that must be solved is how to create an accurate developer-project matrix. At this point, different developer metrics come into play.
In a study aiming to predict whether a user would join a project in the future, the metrics used included a developer’s GitHub age (i.e., when their account was opened), the number of projects that they had joined, the programming languages of their commits, how many times a project was starred, the number of developers that joined a project, and the number of commits made to a project [
25].
In another study that explored the factors that led a user to join a project, the metrics used included a developer’s social connections, programming with a common language, and contributions to the same projects or files [
26]. Liu et al. designed a neural network-based recommendation system that used metrics such as working at the same company, previous collaboration with the project owner, and different time-related features of a project [
27].
Sun et al. relied on basic user activity to develop a project recommendation model using GitHub data. Specifically, when rating a project for a developer, they used "like-star-create" activities related to projects [
5].
To sum up, some developer metrics that were noted as considerable in their papers are given in
Table 1. In this table, we have also presented the fields of the metrics (the related feature), their definitions, and the target challenge, along with the reference studies. These metrics have been used to address various challenges in OSS development, among them project characterization, reviewer assignment for issues or PRs, and project recommendation are prominent ones. Generally, researchers have aimed to use these metrics to characterize developers by analyzing their activities in order to solve a problem [
28]. Thus, developer metrics become crucial factors for solving these challenges. In this study, we offer a number developer metrics that can be used for a variety of challenges.
3. Research Design
3.1. Dataset
One of the most serious challenges in developing a recommender system is sparsity [
33], a problem that occurs when most users rate only a few items [
34]. This issue is also present on GitHub, as it is not possible for developers to be aware of most of the millions of repositories on the platform. Most of the studies mentioned in the previous section used limited (less sparse) and ad hoc (unpublished) datasets (
Table 2). In
Table 2, we present the number of users, the number of projects, and the ratio of them (user/project or project/user) in the datasets of ours and others. Higher ratios indicates sparsity in the dataset. The greater a dataset’s sparsity, the more difficult it is to make the correct recommendations. Thus, the results of the related studies are controversial in terms of real platform data (because of working on a smaller dataset). Therefore, in this study, we used a public dataset called GitDataSCP (
https://github.com/kadirseker00/GitDataSCP) that is reflective of the sparsity problem inherent in the nature of GitHub [
35].
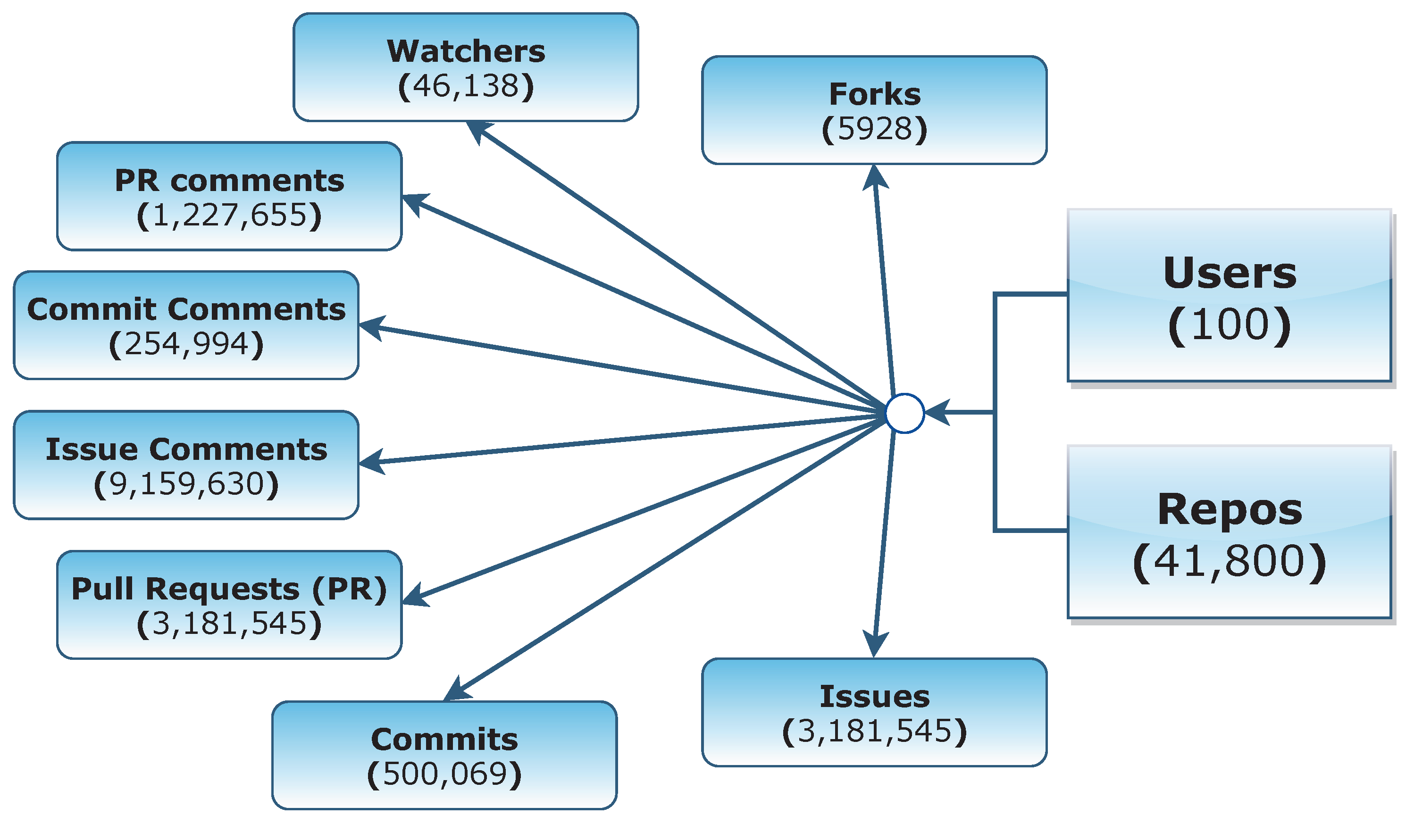
The dataset contained data related to 100 developers and 41,280 projects (repositories). The creators of the dataset indicated that they selected the most active users on the platform and extracted some related data from the activities of these GitHub users (
Figure 1).
The number of records in the dataset is also given in
Figure 1 (below the name of collections). The
Repos and all other collections include records that related to the
Users collection. All details regarding the creation of the dataset are provided in the source study of the dataset [
35].
3.2. Recommendation Model
We created a recommendation model based on item-item collaborative filtering. The collaborative filtering method is usually involves gathering and analyzing information about a user’s behavior, activities, or preferences and predicting what they will like based on their similarity to other users. Collaborative filtering is based on the assumption that different individuals who have had similar preferences in the past will make the same choices in the future. For example; if a user named John prefers A, B, and C products, and a user named Alice prefers B, C, and D products, it is likely that John will also prefer product D and Alice will prefer product A. Item-item logic can thus recommend similar items to a user who consumes any item.
Constructing a recommendation model for GitHub is different from classic (movie) principles. When recommending a movie to a user, the ratings of movies are known. However, this is not the case on GitHub, where developers do not rate projects. In this context, it is thus necessary to determine a metric that can be used as a rating. In addition, the model should recommend projects with which a developer is unfamiliar (just as a movie recommender should suggest movies that the user has not watched). We constructed a model taking into account these conditions.
A project recommender system for software collaboration development platforms includes stages as generating a project-developer rating matrix according to a certain metric, finding similarities between projects, generating recommendations, and evaluating results. First, we generated a project-developer rating matrix (
Table 3) using specific metrics. As seen the
Table 3, columns represent the users, rows represent the projects (repos). We selected a metric, then, input the metric’s values (quantity, ratio, or binary) into the cells. For example, as shown in
Table 3a,
User-1 opened seven issues in
Project-2.
We normalized the values of the project-developer matrix using min-max normalization. The values of the metrics were scaled from 0 to 10. As in the movie-user model, we assumed that each developer gave a rating (0–10) to each project (
Table 3b). First, we calculated similarity scores between projects using two methods (cosine and TF-IDF similarity). We then recommended the top-
n projects to each developers. Finally, we evaluated the correct recommendations using two evaluation methods (community relation and language experience).
3.3. Similarity Methods
First, we found similar projects to recommend to developers. The memory-based collaborative filtering recommendation system selects a set of similar item neighbors for a given item [
36]. Therefore, we used two memory based approaches.
3.3.1. Cosine Similarity (Context Free)
For our first method, we choose a method without textual features. We used the cosine similarity to calculate the similarity score of the two projects (with explicit rating scores).
A project vector consists of related rows from the project-developer matrix (Equation (
1)).
To calculate the similarity score between Project-i (P
i) and Project-j (P
j) according to the metricX rating, we used the Equation (
2).
3.3.2. TF-IDF Similarity (Context Based)
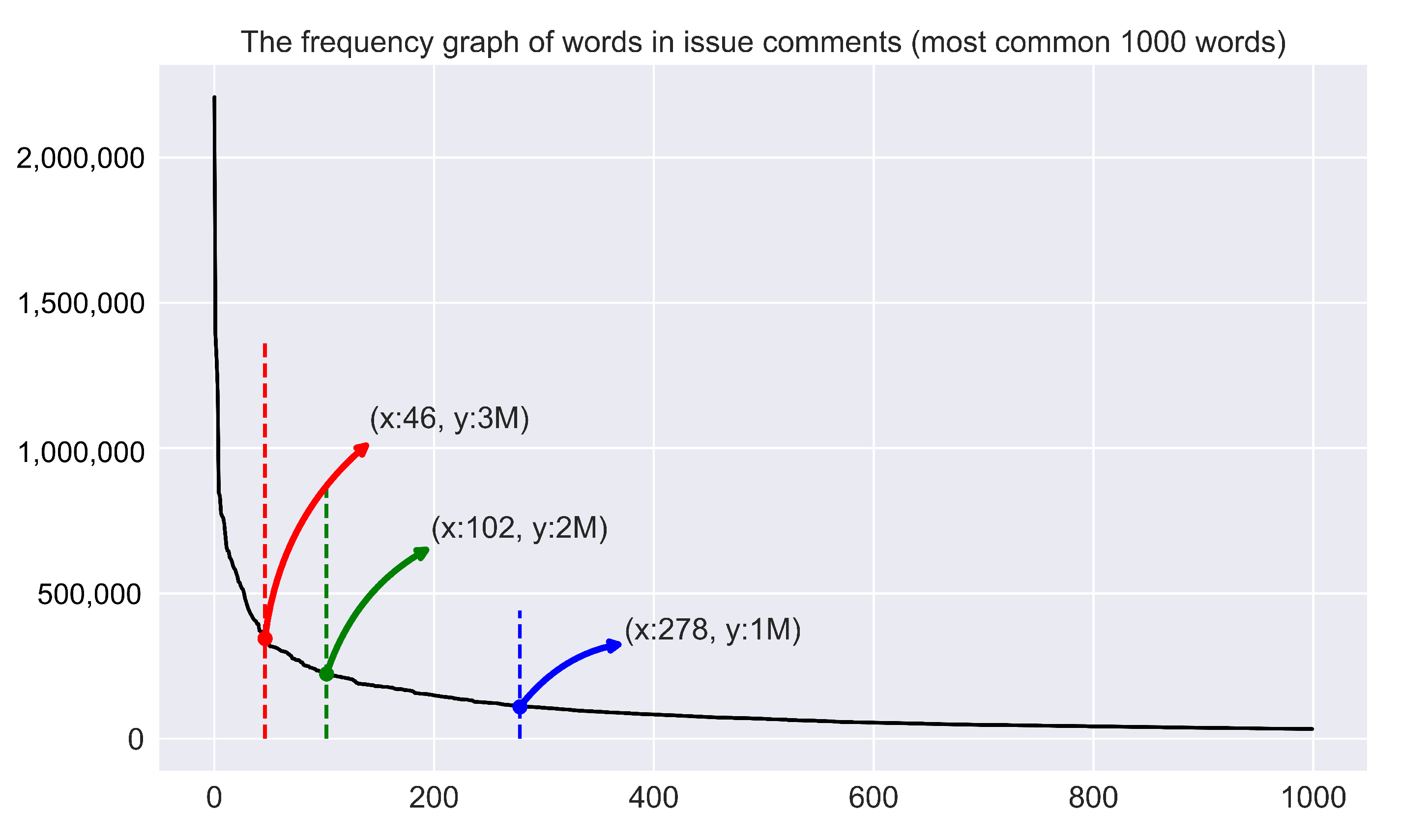
For our second method, we used text-based similarity. We used all of the comments in a project to (implicitly) calculate the similarity score between projects. In
Figure 2, we showed the most frequent words in the comments in the dataset to provide a rough understanding of the corpus.
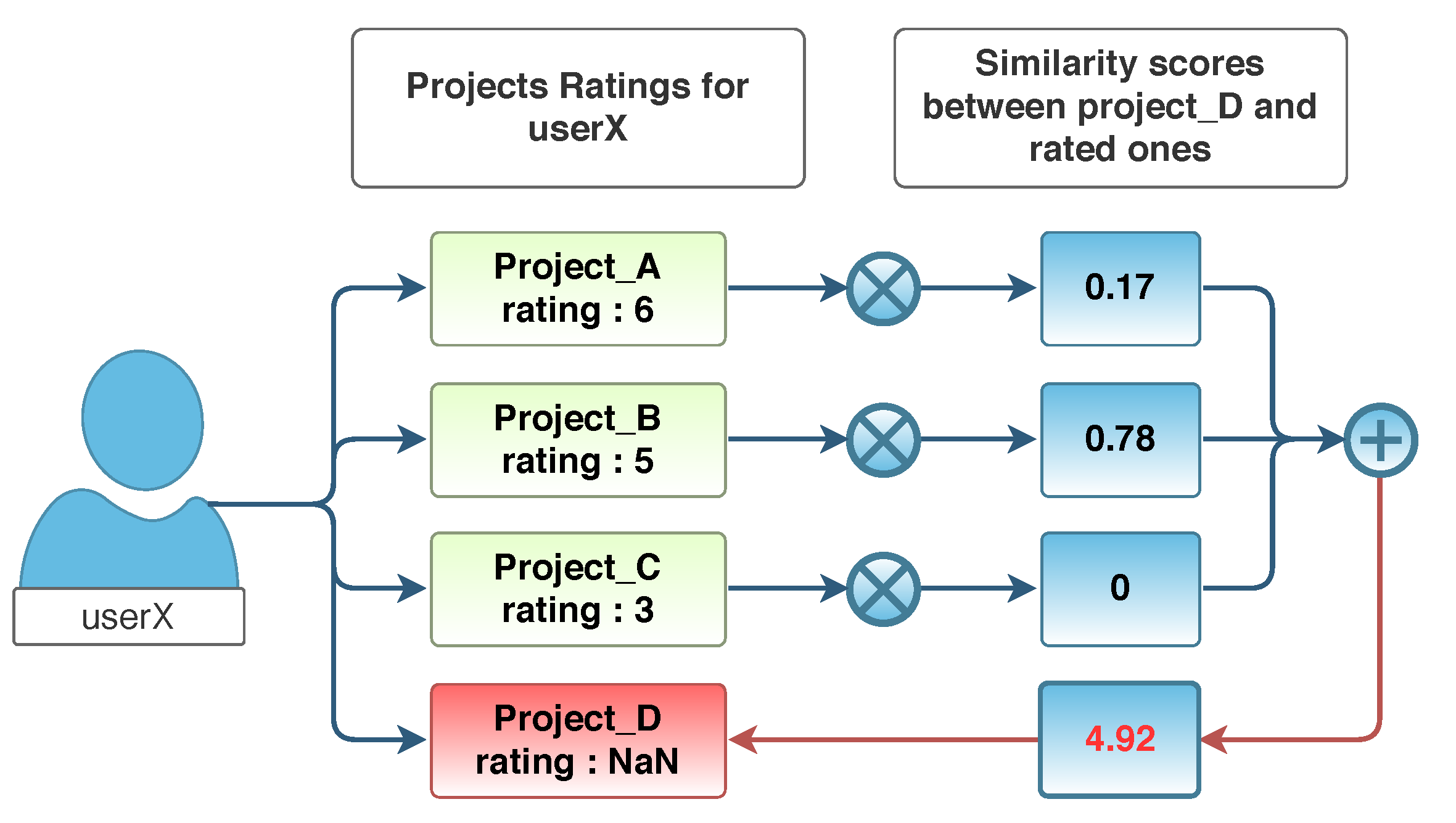
3.3.3. Handling Unknown Projects
After we calculated similarities using above two methods, we generated ratings of unrated (unknown) projects for each developer. The similarity between unknown projects (We assumed that
unknown projects were those to which developers had no relationship and had made no contributions.) and rated projects was used to calculate the rating of known projects [
5]. We calculated the rating of an unknown project using the dot product of the similarity values between the projects that the user rated and the unknown project (Equation (
5)). An example scenario involving this calculation is presented in
Figure 4.
3.4. Evaluation Methods
- RQ1:
Can we offer new evaluation methods for GitHub project recommendation problem?
We recommended the top-n highest-rated projects among the unknown projects to each developer. We then evaluated the recommendations using two methods we proposed. When recommending projects to developers, there should be a ground truth for evaluating the proposed projects. Unlike ordinary recommender systems, this is an unsupervised model. The evaluation criteria used in some studies related to this subject are set forth below.
A project-user rating matrix was split randomly into test and training subsets. Accuracy or recall scores were then calculated from the intersection between the
top-n scores of the test and train subsets [
5]. However, another study argued that this method should not be used on platforms like GitHub where time is an important parameter, pointing out that problems would arise regarding predicting past activity with future data will occur when using k-fold cross-validation by randomly dividing the data [
3].
In another study, the accuracy of project recommendations was evaluated using the developer’s past commits to the related project. A recommendation was assumed to be correct if the number of commits a certain developer made to the project exceeded a certain value. The average number of commits per project was set as the threshold value in the dataset [
27].
In a study predicting whether a developer would join a project in the future, the dataset was split into two different sets by time. In this way, the predicted result was verified with actual future data [
25].
In a survey-based study, the authors asked respondents which features could be used as a recommendation tool. Most of them stated that the languages in which developers already coded or with which they were familiar were important for recommendations [
38].
In this study, we used two evaluation methods to analyze our proposed developer metrics.
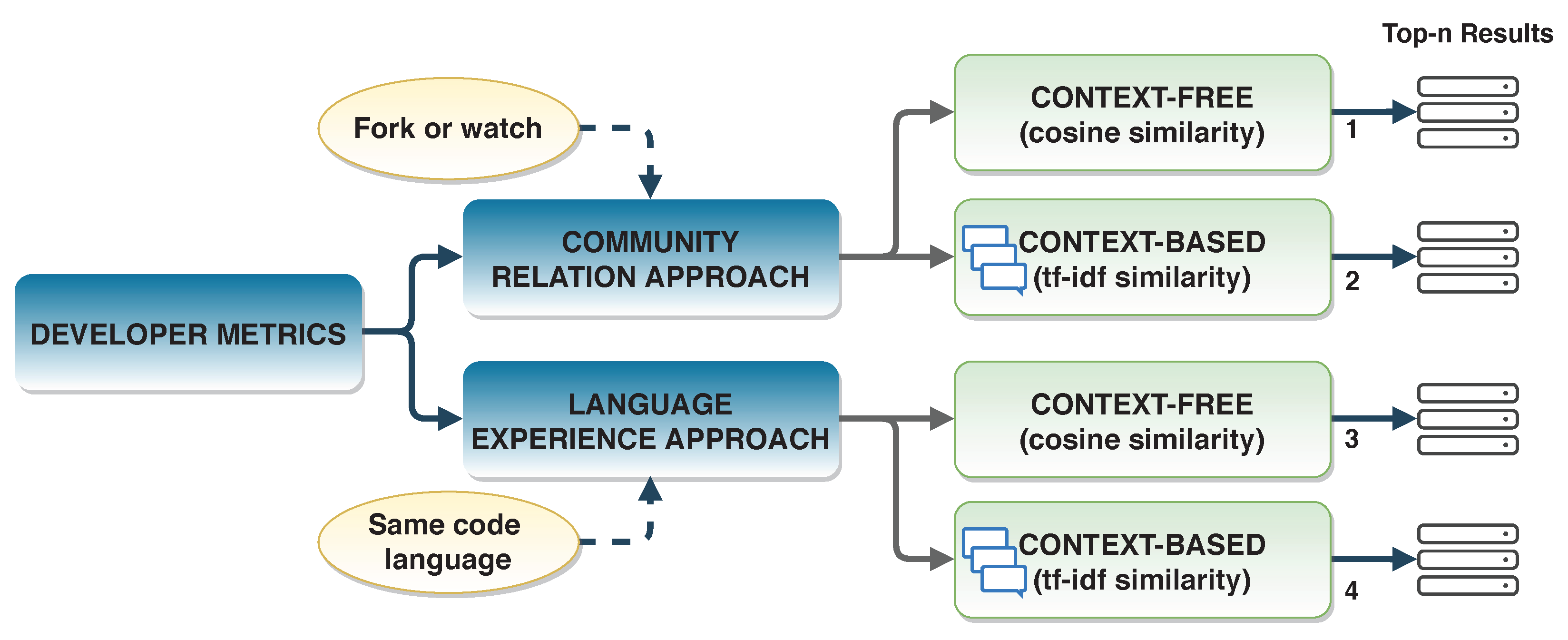
3.4.1. Community Relation Approach
First, with the community relation approach, we used GitHub’s
watching and
forking features as the ground truth. GitHub users can follow, or watch projects whose developments they want to monitor [
39]. If a developer is watching a project, this indicates that he or she is interested in the project. Similarly,
forking is used to contribute independently to the project of interest [
40]. Developers usually make changes in their forked project (local branch) and can then send their contribution via PRs to base project (master branch). External developers mostly use the fork-pull mechanism to contribute to projects of interest. In this context, we believe that both of features are important for recommendations. While we used “
watching or
forking” as an evaluation criteria, we fine-tuned the criteria as detailed below.
The full name of a GitHub repository is created by concatenating the owner’s name (login) with the repository name (e.g., davidteather/handtracking). In analyzing our results, we noticed that the model recommended some project to developers that had only the correct owner login or repository name. In other words, the model suggested an incorrect project of the correct owner or the exact opposite. We evaluated these suggestions as a half point (0.5), as recommending only the correct owner to a developer will still allow the developer to to learn other projects by that owner. Similarly, if the model recommends only a correct repository name with an incorrect owner, this indicates that it has suggested the forked version of a correct repository. Thus, the related developer can discover with the master (base) repository.
An example scenario demonstrating this situation is given in
Table 6. The projects recommended for Alice are listed in the first column
Table 6a. Two of them are among the repos that Alice watches, with the two correct matchs, the initial score is
2. There are two repos by a developer named
fengmk2 among Alice’s watched projects (
fengmk2/parameter and
fengmk2/cnpmjs.org) (
Table 6b). The model suggested the project
fengmk2/emoji that belongs to a developer who Alice is familiar with him. Similarly, Alice watches a forked project of
visionmedia/co. Thus, two
half-score are added to the initial score and
3: (2 + 0.5 + 0.5) is the final score.
We used the Equation (
6) to calculate hit score (In other words, the scores of correct recommendations). Our analysis showed that some developers had only a few watched projects. Thus, the case of a developer interested in (watching or forking) fewer than
n projects was considered in the updated score Equation (
6).
To sum up, in this evaluation approach, if the recommended project is among the developer’s watched or forked projects, the project is considered a hit.
3.4.2. Language Experience Approach
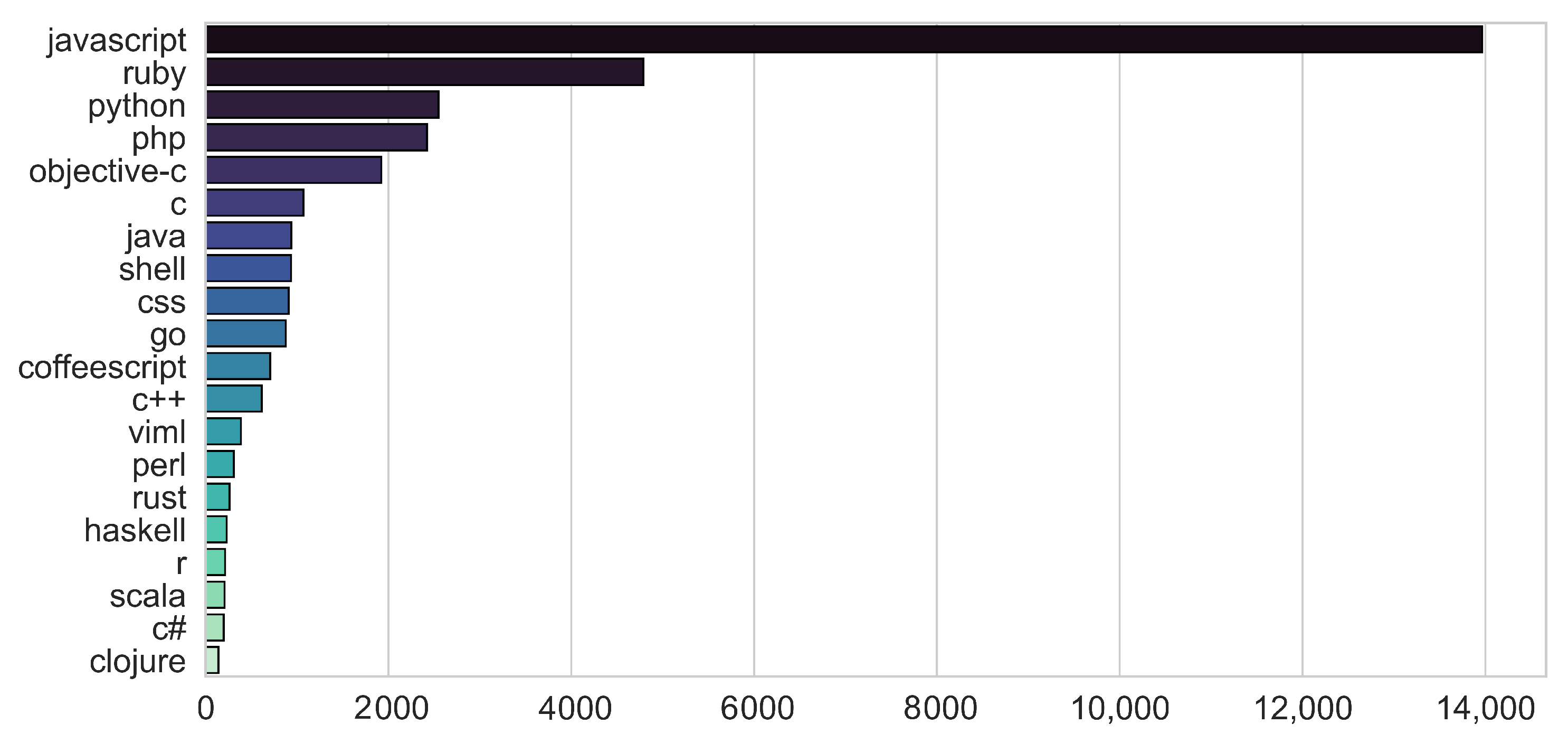
With our second approach, we wanted to benefit from the developer’s coding language experience. Thus, we processed the languages of projects and used the knowledge obtained as an evaluation criterion. The projects in our dataset included 94 unique coding languages. The most used 20 languages are shown in
Figure 5. Due to the diversity of languages in the dataset, we believe that the language feature can be used as another evaluation criterion.
We extracted all programming languages for projects that developers owned or watched or to which they made commits (
Table 7). We aimed to discover the languages in which a developer had any activity. We then sorted them by frequency and identified the three most used languages (“expert languages” column in
Table 7).
Similarly, in this evaluation approach, if the recommended project’s language was among a developer’s top languages, the project was considered a hit. This evaluation’s scores were considerably higher than the first’s. However, our aim was to validate the significant metrics with another evaluation criterion.
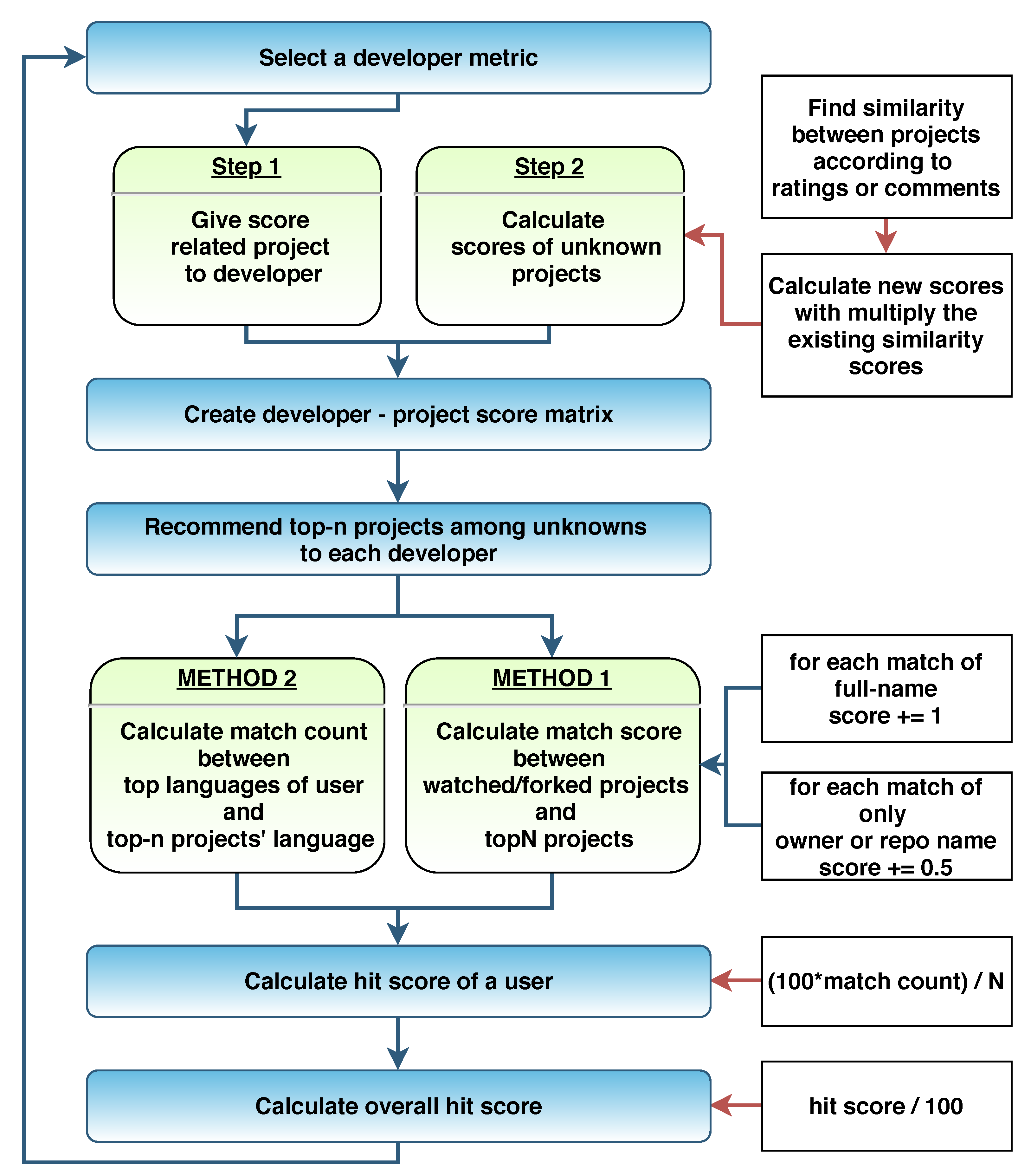
In this way, we created a project recommendation model has been created for software collaboration platforms. The algorithm of the recommendation model is presented in
Figure 6, starting with selecting a feature as a metric and ending with calculating hit scores.
4. Empirical Results
We generated 40 different developer metrics that provide information about a developer’s past activity on a project. All metrics used were scaled from 0 to 10 using the min-max normalization technique. The project-developer relationship was thus rated in the range of 0 to 10 (as with a viewer’s rating of a movie). We then applied all of these metrics to the project recommendation model and evaluated the results with the top 1, 3, 5, 10, and 20 recommendations hit scores.
4.1. Generating Developer Metrics
We created developer metrics using several methods. To extract metrics for a developer in a project, we used the number of activities, the ratio between some number of activities, and the status of whether an activity exists or not. First, using activities individually, we created metrics called single metrics. We then combined the single metrics according to common features to obtain the fusion metrics. Lastly, we created binary fusion metrics indicating whether a particular activity existed in a project.
4.1.1. Single Metrics
- RQ2:
Can we use the activities of GitHub users as a developer metric individually?
Developer activity on projects was handled as a metric. Activity includes all kinds of comments, code contributions, revisions, and so on. In this section, all metrics were treated individually in order to evaluate the significance of each. These metrics refer to the number of activities per project for a given developer (
Table 8).
In addition to these metrics, we calculated the optimized metrics from the values of single developer metrics. We named these metrics with the prefix ’O_’. For example, name of optimized
pr_closed is
O_pr_closed. We aimed to show the contribution ratio of each user for each project. For example, John closed 10 PRs in a projectA, and 10 in projectB. The total number of closed PRs is 100 in projectA and 1000 in projectB. Therefore, John contributed much more to projectA (10% contribution) than to projectB (1% contribution), as his closing PR ratio in projectA is higher. We calculated the rating with Equation (
8).
For comparison purposes, we added another metric proposed by Sun et. al. They scored developers and projects using
like, star, create activities and used textual data extracted from projects’ README and source code files to find project similarities [
5]. Their dataset included approximately 22,000 repositories and 1700 developers. In our dataset, the ratio of number of developers to number of projects was approximately 1:400, in Sun et al.’s study it was 1:14. We also planned to use this less sparsed dataset to make a fair comparison but could not because the dataset was unshared. As we were unable to communicate with the authors, we applied a very similar rating to our dataset.
4.1.2. Fusion Metrics
- RQ3:
Can new metrics be obtained by combining similar properties or activities?
In our results, we observed that some metric groups came to the forefront, especially issue related metrics. New metrics can be proposed by grouping comments, code contributions, or other common feature metrics. Fusion metrics were created from combinations of single metrics.
Sun’s metric: is mentioned previous section. It is metrics from similar study [
5].
code_contributions: is created from the sum of all code contribution-related metrics. -4.6cm0cm
comments: is created from the sum of all comment-related metrics.
issue_related: is created from the sum of all issue-related metrics.
pr_related is created from the sum of all PR-related metrics.
commit_related: is created from the sum of all commit-related metrics.
commit2comment is created from the (
commit_committed divided by
commit_commented)
issue2comment is created from the (
issue_opened divided by
issue_commented)
pr2comment is created from the (
pr_opened divided by
pr_commented)
code2comment is created from the ratio of two fusion metrics (
contribution divided by
comment)
4.1.3. Binary Fusion Metrics
- RQ4:
Is a user’s amount of activity important in the context of developer metrics?
The above metrics offer information about how many activities were made. For instance, if John opened 18 issues in projectX, the John-projectX rating is 18. As an alternative, a set of metrics was created that simply showed whether a given activity existed. For instance, even so, if John opened an issue in projectX, the John-projectX rating is 1; if John did not open an issue in projectY, the John-projectY rating is 0. We created the
binary metrics using the Equation (
18) from the fusion metrics.
Because of the binary metrics consisted only of 0 s and 1 s, we did not used them directly. Instead, we created binary fusion metrics. We named these metrics with the prefix ‘binary_’; for example, the name of the binary fusion metric for comments is binary_comments. from the binary metrics using the same equations while creating fusion metrics from the single metrics.
4.2. Project Recommendation Results
In this section, we showed the only top 1, 5, and 10 hit scores of the most significant metrics. Most of the ratio-based fusion metrics and optimized single metrics were very weak in all cases. Therefore, we removed them from the score tables below. The results of all metrics according to all
n values are provided in the
Appendix A.
We used two similarity metrics to calculate project’s similarity scores. To evaluate the accuracy of developer metrics, we used from two approaches. Thus, we give four results for the recommendation system with the combinations of similarity methods and evaluation approaches (
Figure 7).
After we generated these single, fusion, and binary fusion metrics, we applied all developer metrics to the model. We presented the hit scores percentiles that were obtained according to the two evaluation approaches (detailed in the
Section 3.4 ) in
Table 9 and
Table 10.
In these tables, the columns represent the top-
n hit scores in percentiles, and the green (1st), blue (2nd), and red (3rd) cells show the leading metrics in each top-
n scores. In addition, we styled the most successful five metrics according to overall scores in
bold. We used the mean reciprocal rank (MRR) (It is commonly used in question-answering systems. Here, we used number of models instead of number of queries.) evaluation method (Equation (
19)) to calculate this overall score where
n represents the number of models created
(n:6).
For example, as shown in
Table 9, the MRR value of
comments is calculated as in Equation (
20). The metric ranks for all metrics were used in each of the six models.
In addition to
Table 9 and
Table 10, we presented all top-
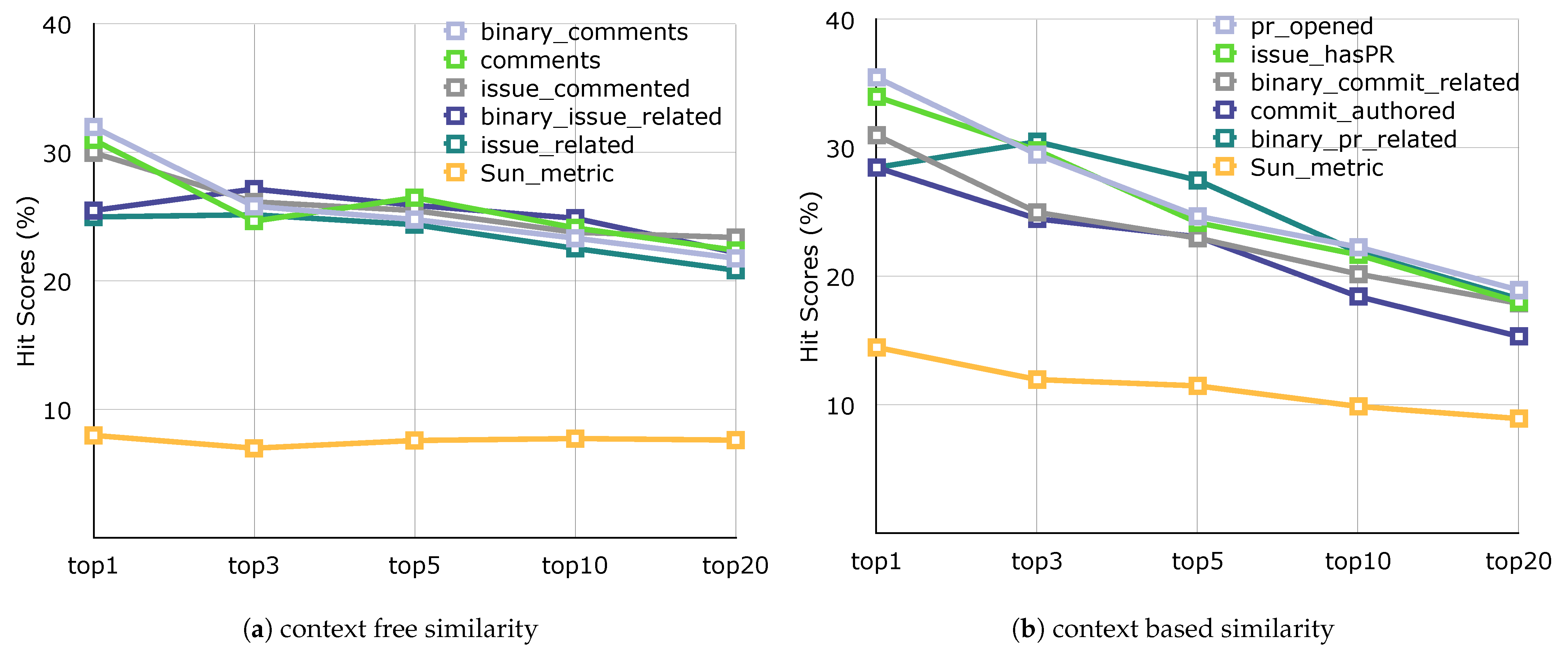
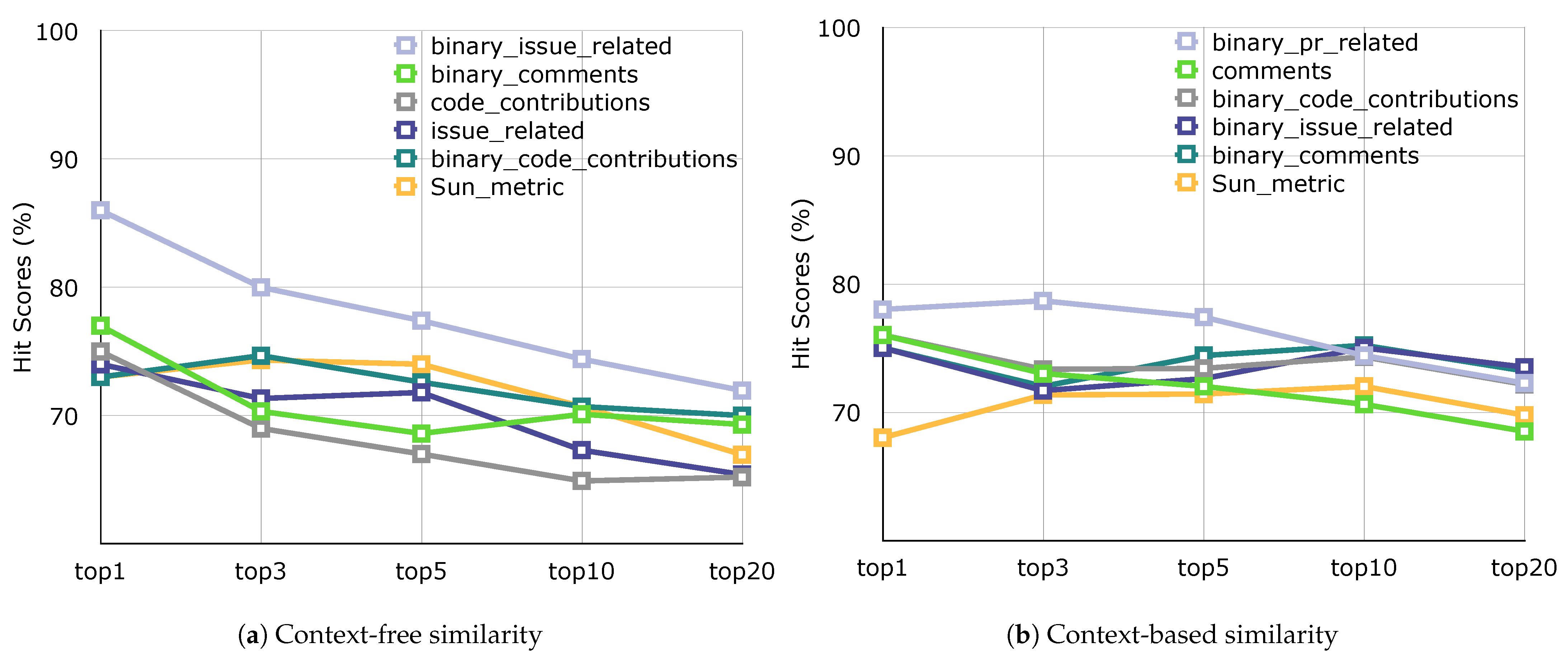
n hit scores charts of the most successful five metrics (+1 Sun_metric) for each methods in
Figure 8 and
Figure 9.
Table 9 shows the results of hit scores using the context-free and context-based similarity methods as evaluated using the community relation approach. When the results were analyzed, the
pr_opened metric was the most successful according to MRR scores. As PRs indicate projects to which a developer contributed directly, we believe that modeling based on PR creation in a given project increases the success of the project recommendation system. In addition, the fusion metrics
comment,
binary_pr_related,
binary_issue_related, and
binary_comment also attracted our attention, as these metrics all related to commenting activity. The results therefore indicate the importance of discussion on the collaboration platforms.
Table 10 shows the results of hit scores according to the context-free and context-based similarity methods as evaluated using the language experience approach. This approach elicited higher hit scores than the first approach as we expected. (In the community relation approach, the model recommends the top-
n projects of the approximately 40,000 projects. On the contrary, the language experience approach makes only recommendation from 94 distinct language projects). However, it is important that evaluate the success rate of the two approaches independently. The binary fusion metrics clearly stand out and most fusion metrics gave better hit scores than single metrics. In this context, because a fusion metric represent many features about a developer, we believe that projects developed in the languages in which the developer specializes are better explored. In addition, in this approach, the
binary_issue_related metric leads among the fusion metrics. The issue that is the primary function of project management operations is the most crucial feature in terms of developer-project correlation. Lastly, the results of
Sun_metric drew attention here, unlike with the previous approach.
Analyzing both
Table 9 and
Table 10 together, we saw that binary metrics were quite successful. It is also a noteworty that comment-based metrics achieved higher scores than code activity-based metrics.
4.3. Threats to Validity
The scope of this study was limited to active developers on GitHub. The first challenge is whether these metrics will work well for inactive developers, a case resembling the cold start problem in classic recommender systems. It is even more difficult to make recommendations for inactive developers due to the comparative lack of information about them. Our proposed metrics must therefore be analyzed in other datasets that include such developers.
The project recommendation problem is important for collaboration platforms. GitHub has recently started to offer project recommendations on the “Explore” page based on certain user activities. Apart from the metrics we proposed, metrics applied to other challenges can successfully be used for the recommendation problem. We encourage researchers to work on this problem using different metrics.
Another problem involves studying private datasets for software engineering challenges. Making comparisons to studies that use different datasets can be challenging. In this sense, our results are limited to our own dataset (which is public). Finally, unlike classic recommender systems, there are no labeled data (ground truth) for our problem. For this reason, we consider it important to create a labeled dataset that can be used to work on the project recommendation systems for platforms such as GitHub.
5. Conclusions
We extracted different types of metrics using the number of activities, the ratio of some metrics, and only the case of whether activity exists. To evaluate our metrics, we developed a top-n project recommender system based on collaborative filtering using item similarity logic which finds items similar to those with which a user has already interacted (e.g., liking, disliking, or rating). In our study, an interaction with an item refers to a contribution to a project. We used two different methods to calculate the similarity between projects. The context-based similarity method had a positive impact on the hit scores. We then evaluated the accuracy of metrics with two particular approaches.
In a movie recommender system, the ground truth is users’ actual ratings. However, there is no common evaluation baseline for GitHub project recommendation systems. Accordingly, in this paper, we proposed two approaches—community relation and language experience—as ground truth. The community relation approach checks whether a developer has watched (or forked) a given project, while the language experience approach uses as a baseline whether the language of the project is one in which the developer has previous experience.
First, we extracted developer metrics for individual activities. Among these single metrics, the most prominents were pr_opened, issue_hasPR, and issue_commented. In this context, we believe that these metrics are adequate even when used individually to obtain knowledge about developers. The crucial single metrics have common traits (such as the issue feature or commenting activity). Next, we created some fusion metrics by combining single metrics. Of these fusion metrics, the comments metric produced significant results. Lastly, as we were curious about whether the amount of activity was important in the context of developer metrics, we created the binary fusion metrics based on the case of activities existence. Taking all results together, the peak scores were gained from these metrics. In particular, the binary_issue_related and binary_comments were the most attention-grabbing metrics.
As PRs indicate projects to which a developer has contributed directly, we believe that modeling based on PR creation in a given project increases the success of the project recommendation system. The issue that is the primary function of project management operations is the most crucial feature in developer–project correlation.
Our results indicate that quantity is not a crucial parameter for some metrics. For example, the issue- and PR-related metrics are quantity-free metrics. Effectively, this means that, when using these metrics, it is sufficient to know whether the feature in question is present. Even if a developer contributes to only one issue on a project, the relation between the developer and the project is tight. In this regard, it is revealing that this issue was a significant feature for collaboration platforms.
In conclusion, we have proposed remarkable and improvable developer metrics based on user activities in GitHub. In particular, we found that commenting on any feature was as important as code contributions. Issue-related activities were also highly important in developer metrics.
We took into consideration the challenge of the sparsity inherent in the nature of GitHub. Despite the sparsity problem, our hit scores were notable compared with a similar study, with most of our metrics more successful than their metric.
Finding similarities between documents is very difficult. In future research, we plan to use word embedding (e.g., word2vec, GloVe, etc.) methods instead of TF-IDF. We plan to apply the proposed metrics to different datasets for validation purposes. We are curious about why some of the new developer metrics we presented became prominent. In light of this study, we are planning another study involving a survey of junior and senior developers whom we can contact to understand the ground truth of our metrics’ success (especially metrics related to commenting activities). In addition, we plan to apply these metrics to solve various problems. For instance, many developers, in addition to owners and collaborators, can make contributions to projects thanks to the open-source nature of GitHub. On some projects, external developers even contribute more than the core team. These metrics can reveal developers’ contribution rankings on a particular project.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















