1. Introduction
In popular online social networks such as Twitter, Facebook, and Instagram, it is easy for users to share information and post their opinions and comments. Given the huge amount of user-generated content (UGC), it is difficult to search for the most relevant information effectively. Since people tend to share information that interests them and comment on the topics they like, user posts and comments are likely to reflect their preferences. In addition to individual posts, it would be useful if we can also recommend groups of people with similar interests. This might help users discover more relevant content in social media. Conventionally, characteristics of users are often defined by their demographic information, such as gender, age group, occupation, and income status. These are usually obtained by filling in surveys and basic personal information which is often lacking since users are reluctant to provide this in most social media. Thus, it is a challenge to learn detailed user preferences without explicit user feedback.
Conventional recommender systems focus on suggestion of items as a function of similar items or users in previous records. However, user behaviors in online social networks are different from e-commerce websites since there is no explicit feedback from users regarding the relevance assessment of items. Instead, users participate in social media by posting, replying (or retweeting), and forwarding multimedia content. Since users might post various types of multimedia content related to the corresponding texts in the surrounding paragraphs, it would be useful if these contextual relations could be utilized to discover implicit user preferences. In this paper, we propose a multimodal feature fusion approach to implicit user preference prediction by learning deep features from texts and images in user posts for recommending similar users in social media. First, text and image features in user posts are extracted using deep learning techniques, such as convolutional neural networks (CNNs) and TextCNN. Then, these features are combined using multimodal feature fusion methods as a potential representation of user preferences. Lastly, similarity among user preferences can be defined and calculated for finding and recommending similar users. Since there are multiple types of features, in this paper, we compare the effects of early and late fusions of features for user preference prediction. To evaluate the performance of user recommendation, a dimensionality reduction method using autoencoders is compared with user clustering.
From the experimental results of Instagram data, we can see the clear advantage of deep learning and feature fusion over individual features. Recommending the top-k similar users when applying late fusion of individual classification results of texts and images gives the best average top-k accuracy of 0.491. This shows the potential of discovering implicit user preferences from multimodal content posted by users. Further investigation is needed to verify the effects in different types of social media.
The major contributions of this paper can be summarized as follows:
First, we propose a convolutional deep learning method for extracting image and text features from user posts as a potential representation of implicit user preferences.
Second, we compare feature fusion methods to combine text and image features from user posts for predicting user preferences.
In our experimental results on real-world Instagram data, the best average top-k accuracy of 0.491 for recommending top-50 similar users can be obtained when applying late fusion on text and image features. This shows an improvement of 36.3% over the baseline in terms of accuracy.
2. Related Works
There are two categories of studies related to our work. One involves techniques that model user preferences by items and user’s information for user recommendation. The other involves deep learning techniques adopted for feature extraction and fusion.
For user or people recommendation in social networks, most existing approaches rely on social relations and network structures in addition to content similarity. For example, Chen et al. [
1] found out that the social network structure tends to give known contacts, while content similarity helps to find new friends. Hannon et al. [
2] considered content-based techniques and collaborative filtering approaches based on followees and followers of users.
Armentano et al. [
3] proposed to recommend relevant users by exploring the topology of the network. Since content-based approaches tend to have low precision while collaborative filtering based approaches based on follower-followee relations have data sparsity issues, Zhao et al. [
4] proposed a community-based approach that utilizes an Latent Dirichlet Allocation (LDA)-based method on follower–followee relations to discover communities before applying matrix factorization for user recommendation. Gurini et al. [
5] proposed to extract semantic attitudes from user-generated content, including sentiment, volume, and objectivity, and they conducted people recommendation using matrix factorization. In this paper, since there are no social network structures available, we used content-based approach as our baseline model. Moreover, we included word embedding using a pretrained Word2Vec model to get semantic information of texts.
Predicting user preferences is very important when constructing a recommender system. In social networks, user preferences can be derived from three sources. The first is user post contents including texts and images. They provide the direct evidence of what users like. The second is user interested topics, which could be reflected from tags in posts. The third is the user relations in social networks. Recent preference prediction models integrate information including user posts [
6], images [
7,
8], social network attributes [
9], and user demographic information [
10]. Examples include gender, age, and political tendency [
11]. In past research, researchers considered integrating information such as reviews and social relations to predict user preferences. For example, some methods learned user sentiments from user reviews [
12,
13] and item topics regarding user preferences [
14,
15]. Some methods used hybrid methods to learn user’s opinion in different domains [
8,
16]. Unlike the above studies, we did not use the extra information such as social relations or user demographics. Instead, we focused on extracting information from post contents, including texts and images.
On the other hand, deep learning practices have been applied to texts to provide more insights into the reasons behind users’ preferences and more awareness of item features they consider relevant [
17]. Deep learning has been shown to be effective in user preference learning [
18,
19]. Palangi et al. [
20] proposed a deep model which used a variant of recurrent neural network (RNN) architecture called Long Short-Term Memory (LSTM) for retrieval task. The study by Tai [
21] used Tree-LSTM to predict semantic connection of sentences and sentiment classification. Yousif et al. [
22] combined CNN and Bidirectional LSTM (Bi-LSTM) to analyze citation sentiment and purpose classification. Seo et al. [
23] used CNN with attention to model user preferences and item properties as expressed in review texts. However, these methods take more computation due to their complex structure. In contrast, our proposed method focuses on fusing different features instead of relying on complex models to achieve good performance in classification.
Some existing preference prediction methods utilized users’ review texts to learn user preference. In Chambua et al. [
24], they used the hybrid approach to learn and represent user preferences and predict them by using RNN–LSTM and probabilistic matrix factorization in the Amazon Products Datasets. Because they only used review texts as the user feature, they are faced with the problem of missing data. In Lv et al. [
25], the visual and social features were fused by linear regression, matrix factorization, and support vector regression. Unlike our proposed method, they used tags and titles as the textual feature. This might not accurately capture the user’s true emotional preferences. Zhang et al. [
26] used the attention mechanisms to extract textual and visual features by a variant of CNN called VGGnet and LSTM in the Flickr dataset. Through a linear attention mechanism, they fused the textual, visual, and user features for prediction. With the same problems as Lv et al. [
25], the textual description of posts only included titles and tags which might not reflect emotional preferences. Aloufi et al. [
27] used the visual and social features and information-associated content to predict popular images by ranking the Support Vector Machine (SVM) model in the Flickr dataset. They added several extra features to predict which photos would be popular. Mazloom et al. [
28] used the Instagram dataset for their experiment. They used features from users, items, and contexts of posts as representation to predict the popularity of a post related to a specific user and item in social media by matrix factorization. The difference to our proposed method is that they added the visual and textual sentiment based on Visual Sentiment Ontology [
29] and SentiStrength [
30]. Unlike the above papers, we represent user preferences by fusing text contents and image features extracted with convolutional neural networks. Furthermore, we address the issue of user recommendation by autoencoders and user clustering.
Feature fusion is an important method in pattern recognition which allows for more robust predictions by incorporating multiple features that might complement each other. When some of the features are missing, we can still make predictions. Contextual similarity [
31] has been extensively exploited recently in retrieval tasks, such as biological information retrieval, natural image search, shape retrieval, and analysis of time series. A more recent example is the unsupervised ranking model in which all words of a query or document are embedded into vectors, which are matched by deep neural networks [
32]. The multimodal approach was constructed by different input sources [
33,
34]. For example, the multimodal approach based on image and text features was employed in multiple tasks such as retrieval, classification, and natural language processing. To find relationships between text and image features, two general multimodal fusion approaches were deployed: early and late fusions [
35]. Features with poor performance will greatly affect the effects of early fusion [
36]. In contrast to early fusion, late fusion uses mechanisms such as averaging [
37], voting [
38], and learned model [
39,
40] to fuse predictions from each model. In our paper, we aimed to compare the effects of early and late fusions in user preference prediction.
3. The Proposed Method
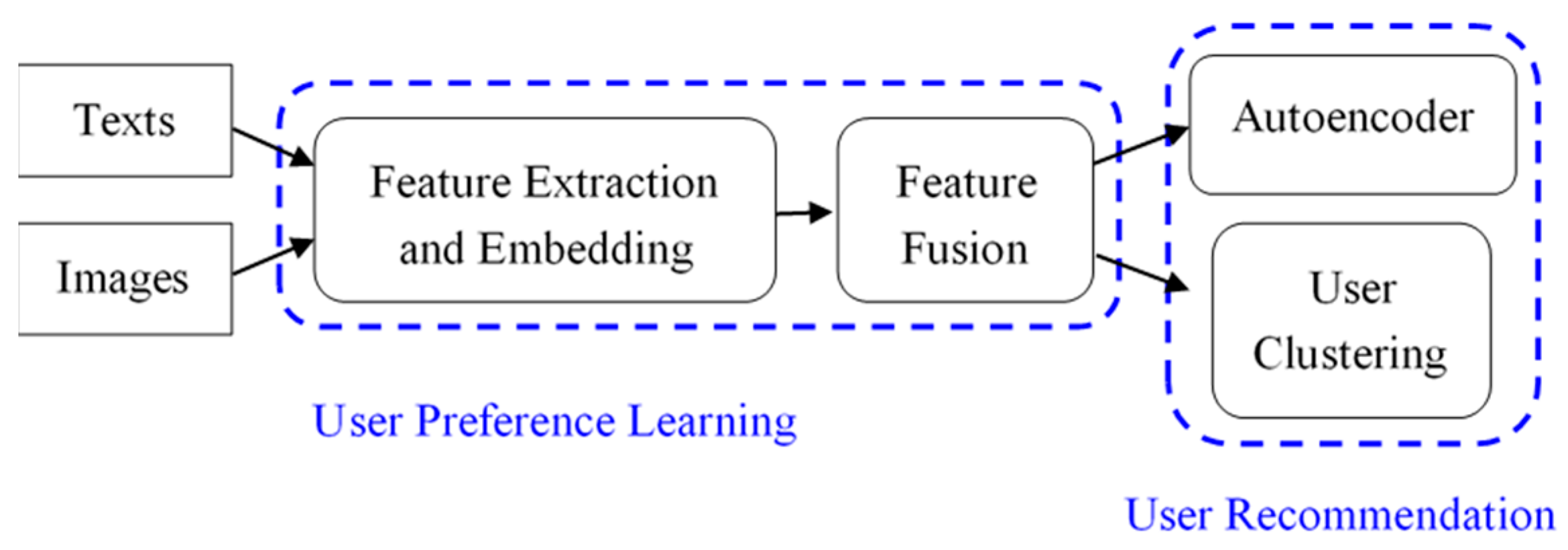
In this paper, we propose a feature fusion approach to implicit user preference learning from user posts and related images for similar user recommendation. The overall system architecture is illustrated in
Figure 1.
As shown in
Figure 1, there are three modules in the proposed method: feature extraction and embedding, feature fusion, and user recommendation. First, user posts in social networks are collected as the dataset, where texts and images are extracted by using text and image convolutional networks, respectively. Second, text and image features are combined using feature fusion techniques as the representation of user preferences. Lastly, on the basis of the similarity among user preferences, top similar users are recommended by autoencoders and user clustering.
3.1. Feature Extraction
People often express their opinions on selected topics by posting related texts and images they are interested in. These behaviors might show their implicit user preferences. Thus, to better understand what people like, in this paper, we assume that user preferences can be represented by the characteristics of texts and images in their posts and comments.
Previous studies used the title or tags as text features for classification. However, user preferences cannot be effectively learned since tags might be ambiguous and diverse in their meanings. Since text contents usually contain more semantic information such as emotions or stances than tags, text contents are used instead of tags. In this paper, we focus on deep learning methods such as the TextCNN model [
41] for text feature extraction. First, text documents are represented by a word embedding model such as Word2Vec [
42,
43]. This is a distributional representation of words among different contexts in fix-sized vectors. Next, we use TextCNN [
41] to extract text features. This is a slight variant of the CNN architecture by Collobert et al. [
44]. The TextCNN architecture is shown in
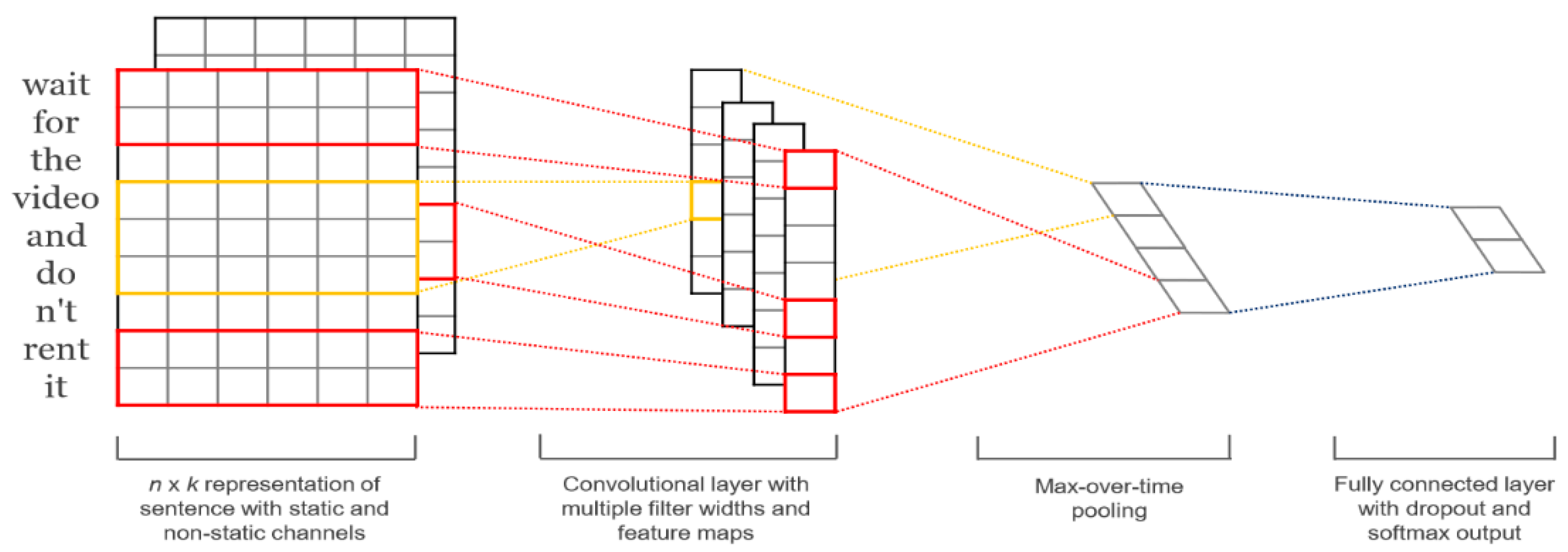
Figure 2.
As shown in
Figure 2, there are four layers in the TextCNN model: word embedding layer, convolutional layer, max pooling layer, and fully connected layer. First, given a sentence of length
n, we denote it by its word embeddings as follows:
where
xi is the embedding of word
i with dimension
k, and ∅ is the concatenation operator. Second, in the convolutional layer, the convolution operation involves a filter
w∈Rhk, which is applied to a window of
h words to produce a feature
ci for the
i-th window as follows:
where
b ∈ R is a bias term and
f is a nonlinear function, such as the hyperbolic tangent. For the given sentence
x1:n, this filter produces a feature map
c as follows:
where
c∈Rn−h+1. Then, in the max pooling layer, we take the maximum value
c’ = max(c1, c2, …, cn−h+1) as the feature map corresponding to this particular filter. Lastly, the fully connected layer outputs the final classification result or category. In this paper, we also extract outputs from the layer before the last layer to compare the effects of feature fusion.
To extract image features, we utilize a CNN model called VGG16 [
45] to convolve the image pixels represented in the Red-Green-Blue (RGB) color model. This architecture contains several differences from the previous convolutional networks. It is a multilayer convolutional network that is a thorough evaluation of networks of increasing depth using an architecture with very small (3 × 3) convolution filters, which shows a significant improvement by increasing the depth to 16 layers (13 convolutional layers and three fully connected layers). Layers of configurations are designed using the same principles, inspired by Ciresan et al. [
46] and Krizhevsky et al. [
47]. Compared with other models such as [
48], VGG16 is a CNN architecture with fewer parameters but comparable accuracy. For this reason, it is used as the Image CNN model to extract the feature map from images.
3.2. Feature Fusion
With texts and images in a user post, we try to combine them in two different ways, i.e., early fusion and late fusion.
3.2.1. Early Fusion
In early fusion, embeddings of texts and images are input to the same CNN model simultaneously for feature extraction. Early fusion is also known as feature-level fusion, which can be expressed as follows:
xm= f (
x1, …xn), where an aggregated representation
xm of features is computed by function
f that integrates individual features
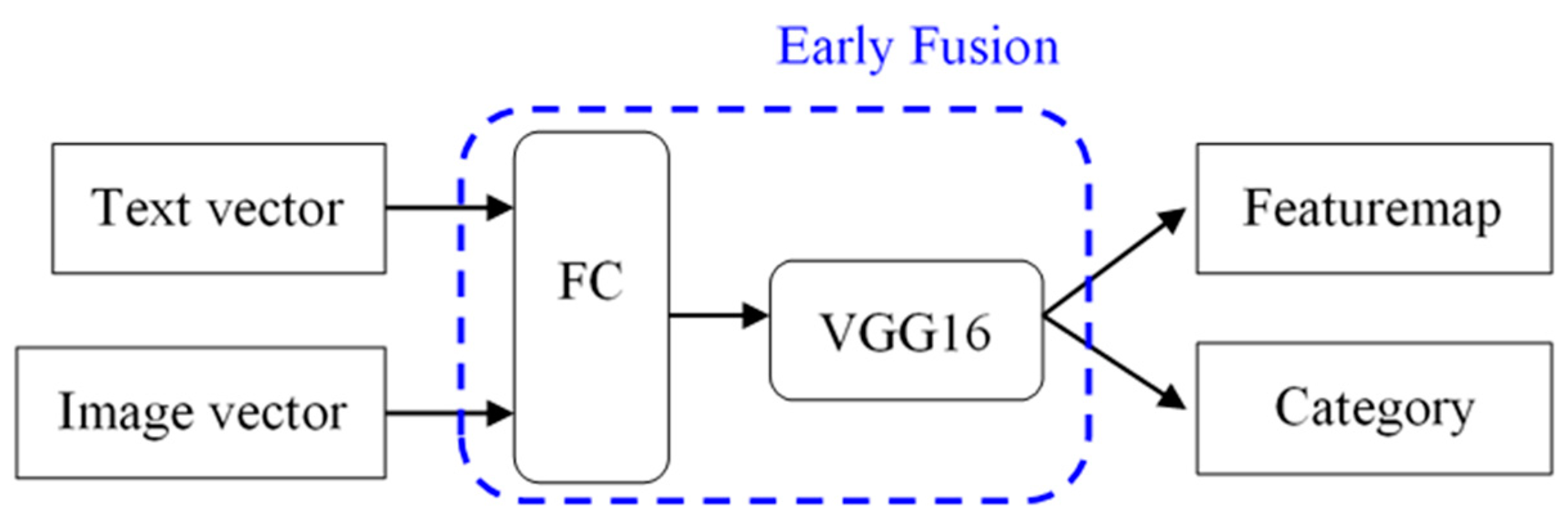
x1, …, xn. Early fusion combines different input sources into a single feature vector, which is used as inputs to the classification framework. The advantage of early fusion is that it learns all the features in one phase. This makes the training pipeline easier, but a lot of important information might be lost. The architecture is shown in
Figure 3.
As shown in
Figure 3, first, since the sizes of text and image embeddings are different, we use a fully connected (FC) neural network to fuse these vectors. There are two different ways of concatenation: text vector concatenated with images or image vector concatenated with texts. Next, we extract the output of different layers in the VGG16 model including the feature map and the final classification result or category as the combined representation for the texts and images.
3.2.2. Late Fusion
In late fusion, text and image features are extracted and then combined for classification. This is also known as decision-level fusion [
49]. It integrates different model predictors by a fusion mechanism to come up with the final decision. Late fusion can be expressed as follows:
output = g(
f1 (
x1),
…, fn(
xn)), where functions
f1,…,fn are applied to individual features and function
g is used to aggregate the individual decisions by
f1,…,fn. The main disadvantage of late fusion is that it cannot learn the correlation among features. Compared to early fusion, late fusion tends to be more robust to features that have negative influence [
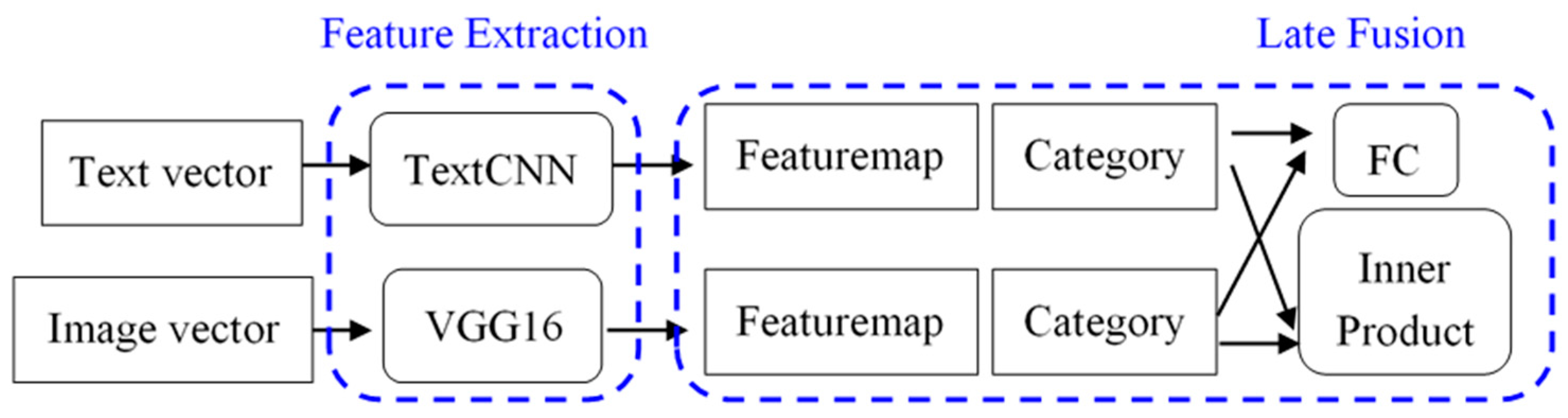
36]. The architecture is shown in
Figure 4.
As shown in
Figure 4, after embedding texts and images into vectors by Word2Vec and RGB models, respectively, they are input to two separate CNN models for feature extraction as described in
Section 3.1. The corresponding feature map and text/image category can be obtained. Then, to fuse text and image features, in addition to using a fully connected layer, we also try to combine the two feature maps by inner product since they are of the same size. The idea is to increase the correlation and reduce the dimension through the inner product.
3.3. User Preference Learning
After combining text and image features using either early or late fusion techniques, we obtain the corresponding feature map and category for each user post. To further represent user preferences, there are two different methods. First, since feature map is the internal representation of a post, the centroid of the feature maps of all posts can be regarded as the user preferences. We can simply add all features with the addition operator to get the centroid. Second, the category of each user post is assumed to reflect part of the user preferences since people tend to post topics they are interested in. People with the same preferences are more likely to post in the same category. Therefore, for each user, we count the number of posts in each category and find out the majority category as the user preference. These are shown in Equations (4) and (5).
where
Fa is the addition operator and
Fc is the count operator, whereas
ci and
Ri are the feature maps and categories of the post, respectively. Since the output categories
Ri in neural networks are usually represented by one-hot encoding, we can simply accumulate them using the count operator to find out the majority category. By aggregating the feature map and category of all images and texts posted by the user, we can obtain the potential feature for user preferences.
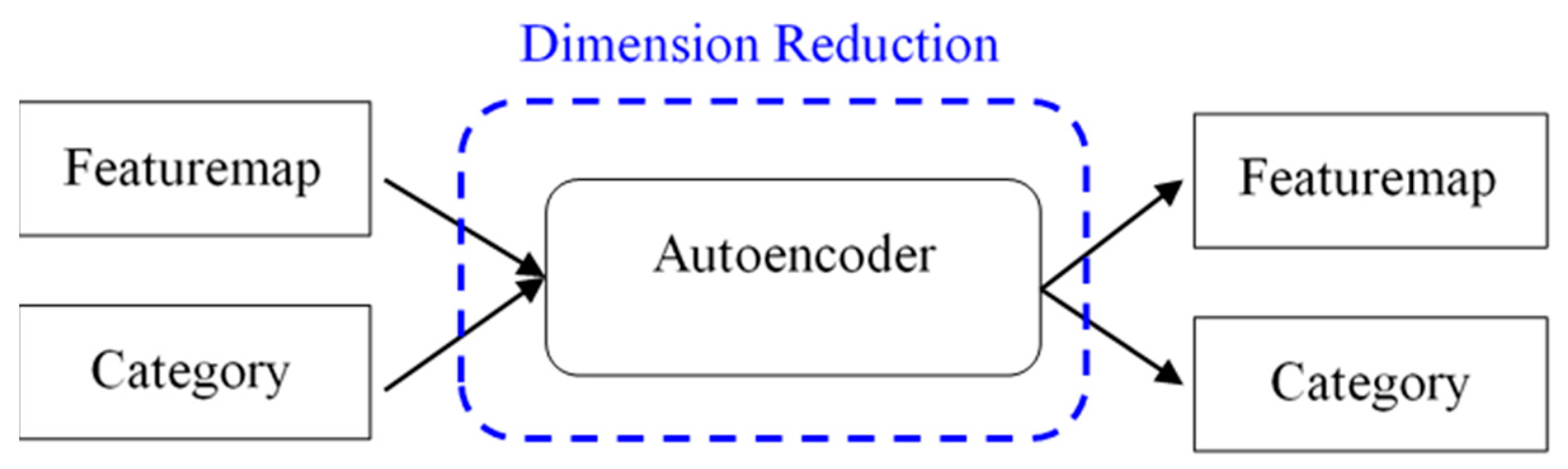
3.4. Dimension Reduction
From preliminary observations, we found that feature maps in images and texts usually have very high dimensions, which could be as high as 8192 after feature fusion. In addition to computational time complexity, it may also include a lot of noise inside. To find out the most important features, we further apply autoencoders for dimension reduction.
Given a fixed dimensional representation of the user preferences as inputs, we design the autoencoder as a single-hidden-layer
d-dimensional neural network. Autoencoders consist of an encoder that transforms input to a code, and a decoder which reconstructs the input from the code. When the number of neurons in the hidden layer of autoencoders is less than that in the input layer, it is forced to learn the compressed representation of the input data. After dimensionality reduction, our model performs similarity calculations among users to generate a list of recommendations. The architecture is shown in
Figure 5.
Since the goal of using autoencoders is to reduce dimensionality by simple neural networks, it would be beneficial if the dimensionality can be reduced while maintaining comparable performance in recommendation. In order to find out the most compact representation which is still effective in recommendation, we conducted experiments to verify the effects of different dimensionality d on the performance of user recommendation.
3.5. Recommendation Based on User Clustering
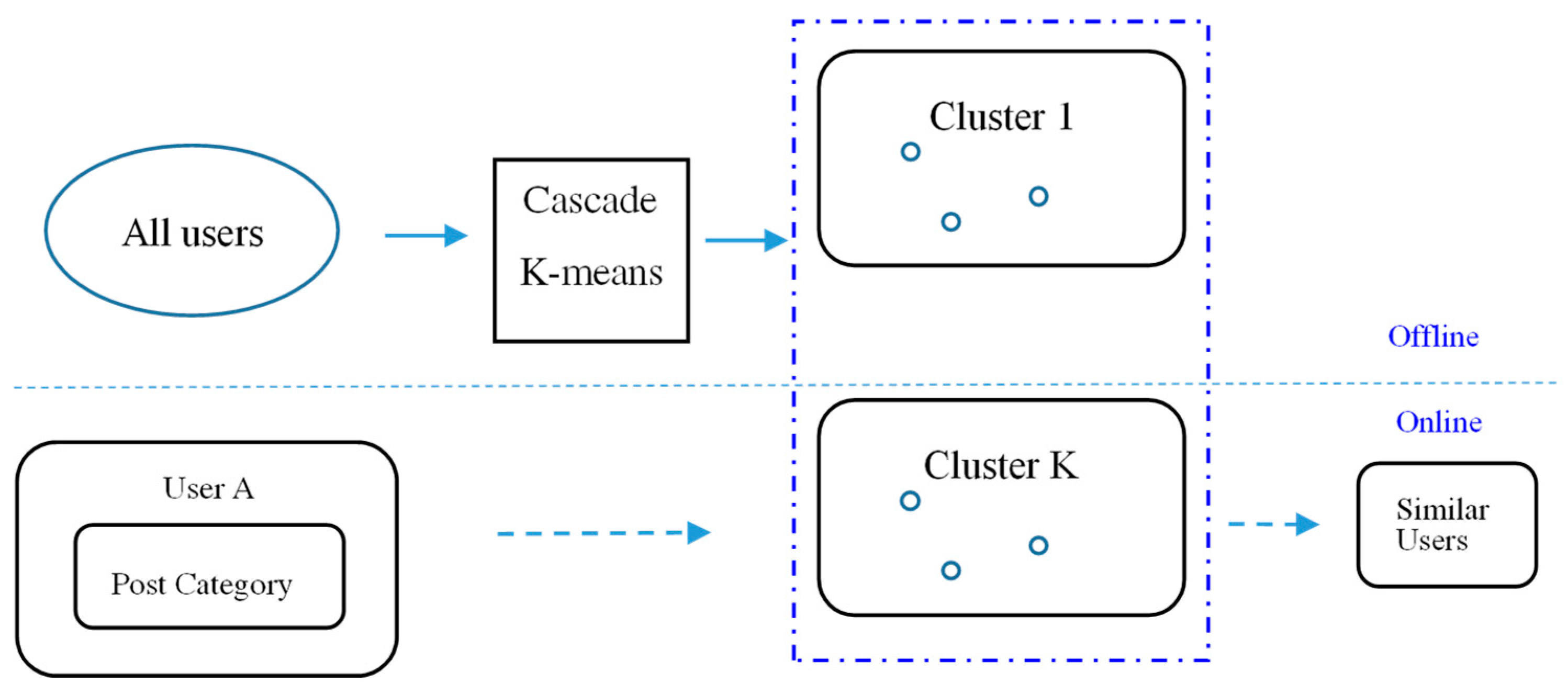
When there are many users, it takes a lot of time to calculate similarity between each one according to the aforementioned method. It is hard to give real-time recommendation. Thus, we further investigate the effect of clustering all users by the K-means algorithm to reduce the number of candidates for similar user recommendation.
Although K-means clustering is incremental, to save time when updating clusters, we propose to divide it into two stages: offline clustering and online recommendation. First, users are represented by the output category after learning user preferences in
Section 3.3 and then clustered using the K-means algorithm. Since the dimension of the category vector is lower than that of feature maps, it reduces the computational time. Then, we calculate cosine similarity by using the feature map of each member in the same cluster to find out the most similar members to recommend. Because the number of users in each group is much smaller than all users, it also reduces the computational time for online recommendation if user clustering can be done offline.
If the original user posts a new post, we only need to calculate the similarity for the members of the same group. If we have a new member, we just need to calculate which cluster it belongs to for recommendation and then calculate the similarity between cluster members, instead of all users. In addition, since clustering can be done offline, the method greatly improves the efficiency of online recommendation. The architecture is shown in
Figure 6.
The problem for conventional K-means algorithm is to determine the best number of clusters. Since Cascade K-means [
50,
51] can automatically determine the optimal number of clusters, it was selected to solve this problem. We use the classification result of the user as inputs for user clustering with Cascade K-means. Lastly, after calculating cosine similarity among the members in the same cluster, we can obtain the most similar K members to recommend.
Although we did not deploy it as a potential real-world recommendation system, we could implement different types of thresholds before initiating the update process by clustering. For example, we could count the number of new users, and set the threshold for a new user ratio. Furthermore, when the percentage of new posts by a user reaches a threshold, we could initiate an update process to update the cluster members for more accurate recommendation.
4. Experiments
In this section, we describe our datasets, how training and testing are performed, and our baseline algorithms, and we analyze the experimental results.
To evaluate the performance of the proposed method, we used the current mainstream social media—Instagram—in our experiments. To the best of our knowledge, there is no publicly available social media dataset that includes both images and texts posted by the same user. To collect the Instagram dataset, we randomly selected six hashtags from the list of top 100 hashtags on Instagram in 2018 as queries to get user posts. This can be done using the Hashtag Search API, which is only available for Instagram Professional accounts. Thus, we had to directly crawl the latest updates for each user on Instagram webpages for tag-based queries. There is a limit of a maximum number of 45 posts per user that can be crawled. To avoid large variations in user participation where there were too few posts to learn the features, we chose to keep only users who had posted at least nine posts, which is a 5:1 ratio (20% of the maximum). Each post contained the user identifier (ID) and contents of the user posts and hashtags. This dataset was used to train the classification models of user preferences (denoted as Dataset_1). There were 239 users and 6941 posts in Dataset_1, from which we split into 5553 posts for training and 1388 posts for testing. The major language was English.
Considering the diversity in linguistic form, we used two pretrained Word2Vec embeddings as dictionaries for English and Chinese. The detailed attributes of the word embeddings are outlined in
Table 1.
4.1. The Performance of User Preference Learning
First, we compared the performance of three classification models: TextCNN, ImageCNN, and early fusion of the two. The training data in Dataset_1 were used to build the models, and the test data in Dateset_1 were used to evaluate the models. In the dataset, there were only user-defined hashtags in addition to texts and images in user posts. It is difficult to know user preferences without explicit user feedback. To obtain the ground truth for user preferences, the hashtag that was used to retrieve each post was set as the class label of that post. We assumed that users implicitly express their preferences through the use of hashtags in the posts and comments that they are interested in.
In our ImageCNN model, the training procedure generally followed Simonyan et al. [
45]. In this model, we included three convolutional layers with the kernel size set to 5 and strides = 1. The training was regularized by weight decay (the L2 penalty multiplier was set to 5 × 10
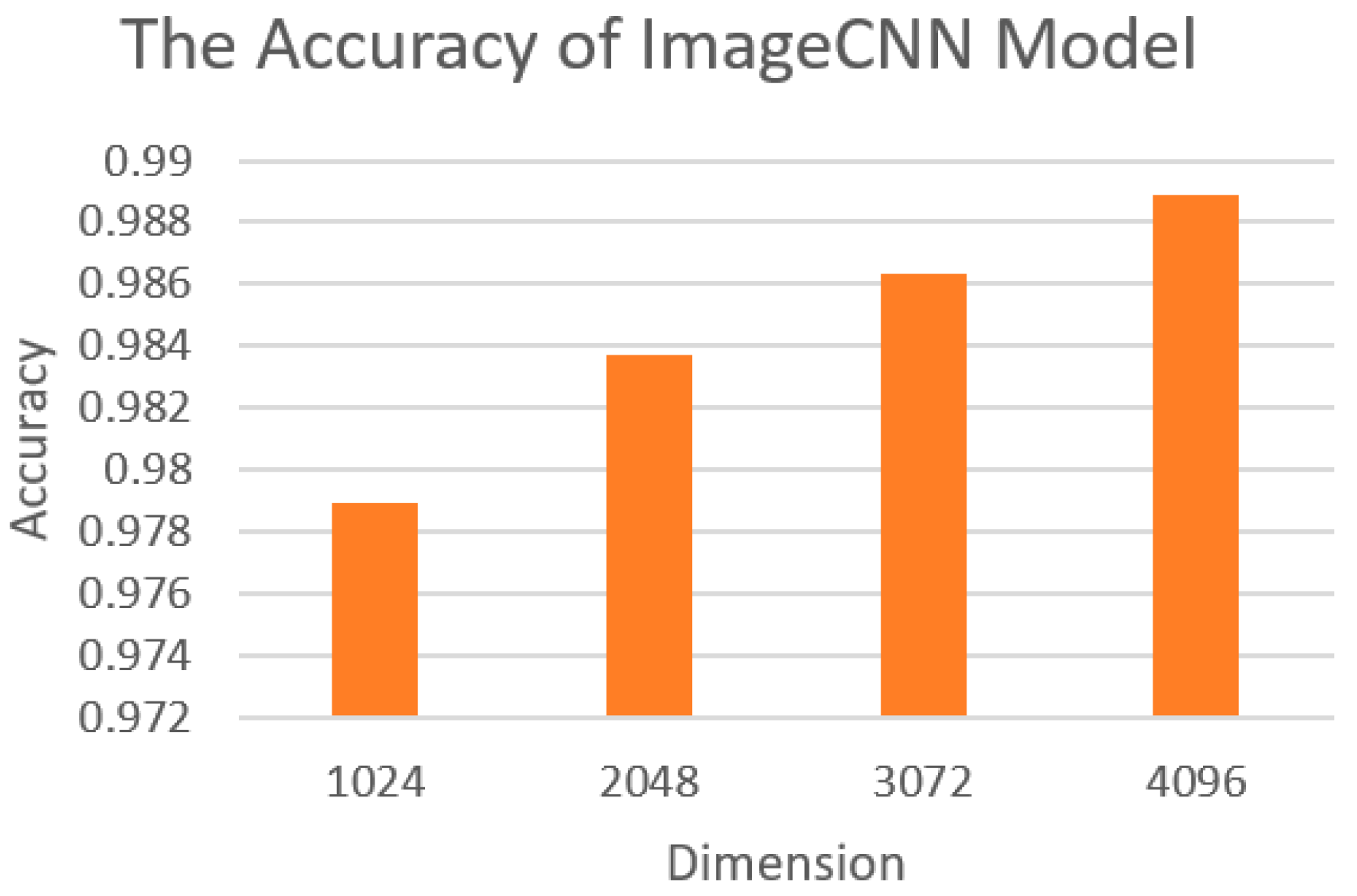
−4) and dropout regularization for the first two fully connected layers with a dropout rate of 0.2. The learning rate was initially set to 0.1. Rectified Linear Unit (ReLU) and Root Mean Square Error (RMSE) were used as the activation function and loss function. The final layer is the softmax layer. The performance of the ImageCNN model is shown in
Figure 7.
As shown in
Figure 7, when the dimension was 4096, we could obtain the best performance with an accuracy of 98.89%. Since the pretrained model of VGG16 had dimensionality in multiples of 1024, models larger than 4096 could not be run due to the limitation of our computer hardware. In the subsequent experiments, we used the dimension of 4096 for the ImageCNN model.
In our TextCNN model, the training procedure generally followed Kim [
41]. We used Word2vec for embedding text contents as input. Three filters of window sizes 3, 4, and 5 were tested, the stride was 1, the dropout rate was set to 0.5, the L2 constraint was 3, and the mini-batch size was set to 50. The learning rate was set to 0.1. We applied a max pooling operation. Training was done through stochastic gradient descent over shuffled mini-batches with the Adadelta update rule [
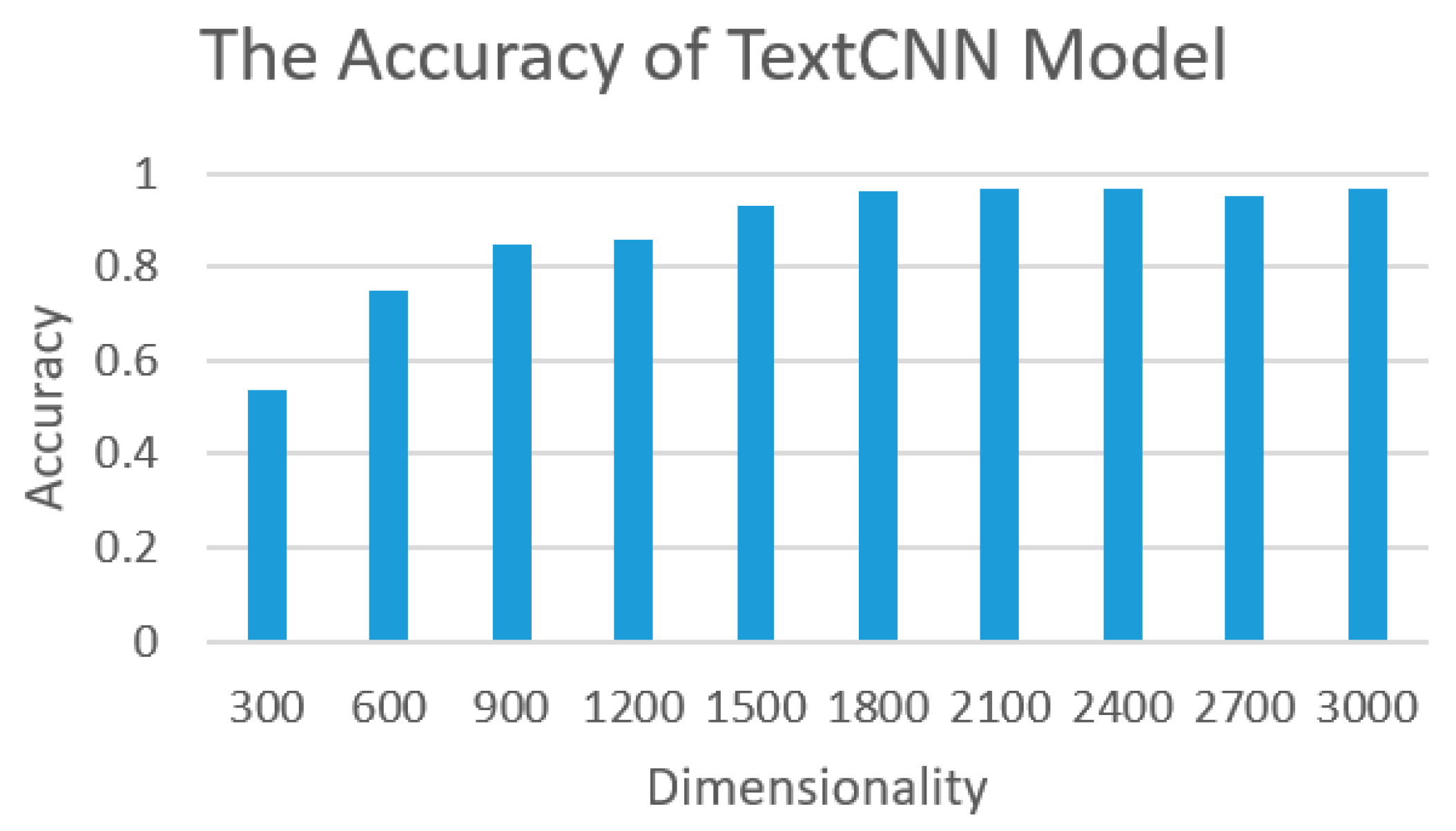
41]. RMSE and LeakyReLu were used as the loss and activation function, respectively. We chose an adaptive learning rate method for neural networks proposed by Geoff Hinton called RMSPROP as the optimizer. The performance of the TextCNN model is shown in
Figure 8.
As shown in
Figure 8, when the dimension was 2100, we could obtain the best performing TextCNN model with an accuracy of 96.8%. In the subsequent experiments, we used the dimension of 2100 for the TextCNN model. Then, when texts and images were input at the same time, we applied early fusion as shown in
Figure 3. The best performance with an accuracy of 80% could be observed when the dimension was 4096. According to our observations, the lower accuracy might have been due to the number of classes in multiclass classification.
4.2. The Performance of Similar User Recommendation
To evaluate the performance of user recommendation and to deal with posts in different languages, we further collected a larger dataset (denoted as Dataset_2) where 12 tags were randomly selected from the list of top 100 hashtags on Instagram in 2018 as queries. There were 1143 users and 49,353 posts in Dataset_2, where the major language was Chinese.
In order to compare the performance of different models in similar user recommendation, we established the ground truth for similar users as follows: in the absence of real user preferences, we assumed that the hashtags in each user’s posts represents the user’s implicit preference and attributes. Thus, the set of hashtags
Tags(
ui) for each user
ui was collected from all the posts as the real preference. The similarity between users was calculated by Jaccard similarity as follows:
Then, the ground truth of top
k similar users for a given user
ui was defined as follows:
where
j ≠ i. That is, top
k users with the highest similarity to the given user were regarded as the ground truth.
With the recommendation ground truth, we then defined the evaluation metric of the top-
k accuracy of a user
ui by calculating the Jaccard similarity between the recommendation list
RLk(
ui) generated by the proposed method and the ground truth
SLk(
ui), as follows:
Then, the overall performance of the model was calculated by the average of the top-k accuracies for all users. To compare the performance of different models, we evaluated the average top-k accuracies for each model when recommending top k similar users, for different values of k.
4.2.1. The Baseline Models
In this paper, we took a different approach to recommender systems than conventional ones. Conventional recommender systems have the premise that the ratings of different users on various items are available. Then, standard recommendation methods such as user-based and item-based collaborative filtering approaches can be used to learn similar users or similar items on the basis of their past rating behaviors, so that ratings for items that were never given before can be deduced. However, in a real-world scenario in social networks where only post content and hashtags are available, it is not possible to obtain the “items” since posts are only posted by one user and replied or shared by a few. It is not possible for them to be “rated” by many different users. In this case, we propose a more realistic approach using hashtags as user preferences for recommending similar users in social networks. When we only have post content and hashtags, the baseline for such a recommendation system is simply content-based recommendation from posts since hashtags have been used as the ground truth.
In our experiments, we considered two baseline models: baseline_text and baseline_pic. The baseline_text model is based on the representation of user preferences only by the text contents of users’ posts. Specifically, for each user, we simply use the distributed representation of the texts posted by that user as their characteristics. First, we converted the words into vectors using the same Word2Vec embedding model with the same dictionaries in
Table 1. Next, vectors for all words in a document were averaged as the representation of the document. We further averaged the vectors of all documents posted by the user as the user feature. Lastly, we calculated the cosine similarity of the current user to all other users to generate a list of recommendations. On the other hand, the baseline_pic model is based on the representation of user preferences only by the image contents of user posts using the ImageCNN model. The only difference is that we took the featuremaps and categories from all images posted by the user as the user feature.
4.2.2. Effects of the CNN Models
In order to verify the performance of CNN models for extracting text and image features, we compared the average top-k accuracy for the TextCNN model and ImageCNN model with the baseline_text model. First, when using word embedding from Word2Vec for texts, the performance of the baseline_text model on Dataset_1 achieved the average top-k accuracy of 0.128. For the TextCNN model, the average top-k accuracy was 0.326 and 0.322 when the number of dimensions was 2100 and 4096, respectively. For the ImageCNN model, the average top-k accuracy was 0.330 and 0.327 when the number of dimensions was 2100 and 4096, respectively. When we combined the Word2Vec embedded text features and ImageCNN extracted image features by a simple concatenation, the best performance of the baseline_pic model could be obtained with the average top-k accuracy of 0.331. This showed a slightly better performance when using multimodal features than that of individual features. Both TextCNN and ImageCNN models achieved better performance than the baseline_text model. This validates the effectiveness of using CNN models to extract text and image features for finding similar users.
4.2.3. Effects of Multimodal Feature Fusion
To validate the effectiveness of multimodal feature fusion, we further compared the performance of combining text and image features with CNN models using early fusion and late fusion. In early fusion, we concatenate text and image features as inputs to a single CNN model, while, in late fusion, we separately input text features and image features into TextCNN and ImageCNN models, with the resulting feature map and categories are combined as the user feature for recommendation. The performance comparison is shown in
Figure 9.
As shown in
Figure 9, the best performance of early fusion could be obtained when the number of dimensions was 2100, with the average top-k accuracy of 0.473. For late fusion, the best performance could be obtained with the average top-k accuracy of 0.491, when we used the categories as features, with the number of dimensions of 4096. We could observe the better performance of both early fusion and late fusion than the baseline_pic model with a simple concatenation. This shows the effectiveness of feature fusion, especially for late fusion. In the case of late fusion, we further address the effect of k on the average top-k accuracy and number of hits in
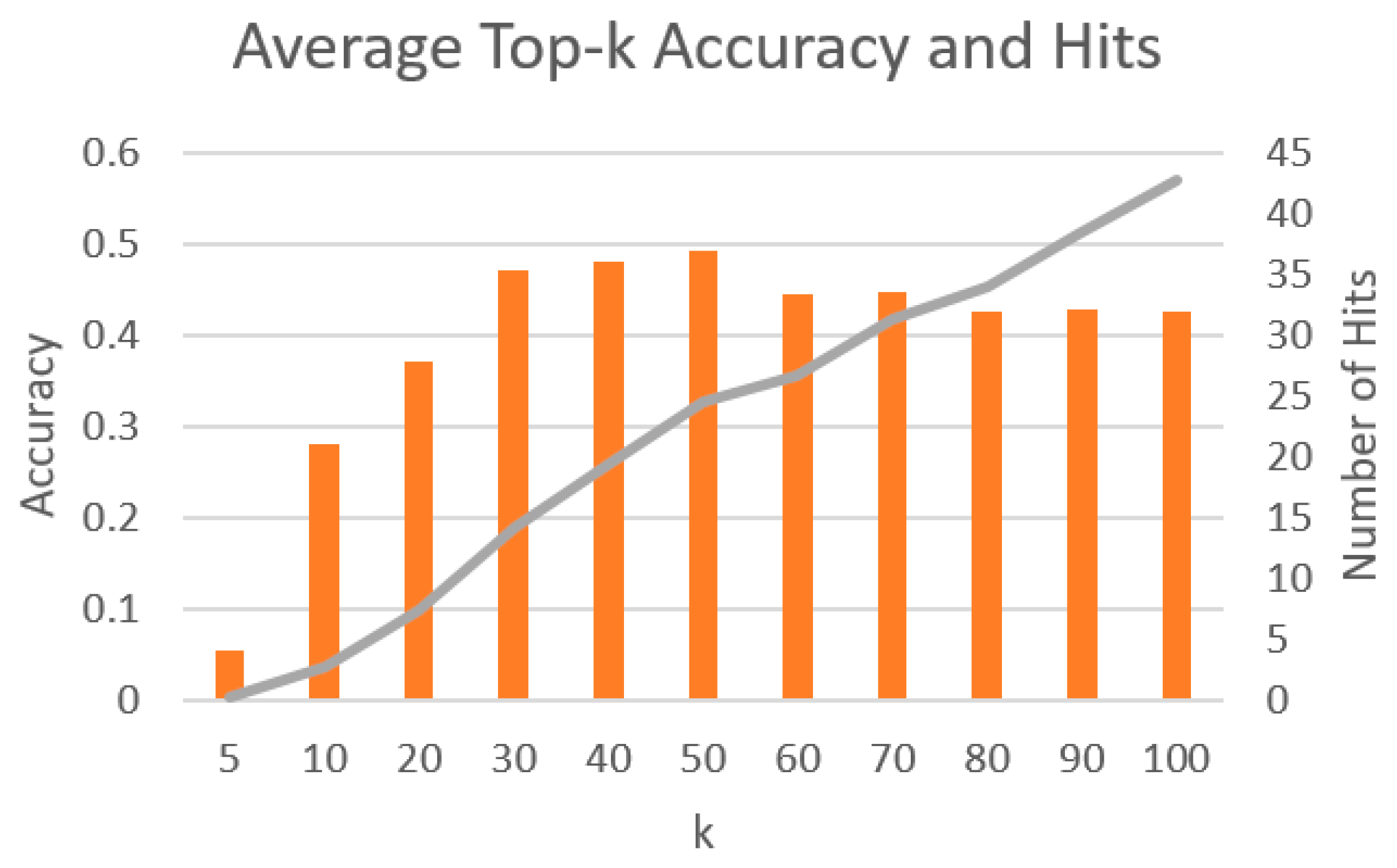
Figure 10.
As shown in
Figure 10, the average number of hits in our recommendation increased when k increased. Moreover, we could obtain the best average top-k accuracy of 0.491 when k = 50. This was also the best performance in all of our experiments. In the remaining experiments, we used the value of k as 50.
4.2.4. Effects of Autoencoder for Dimension Reduction
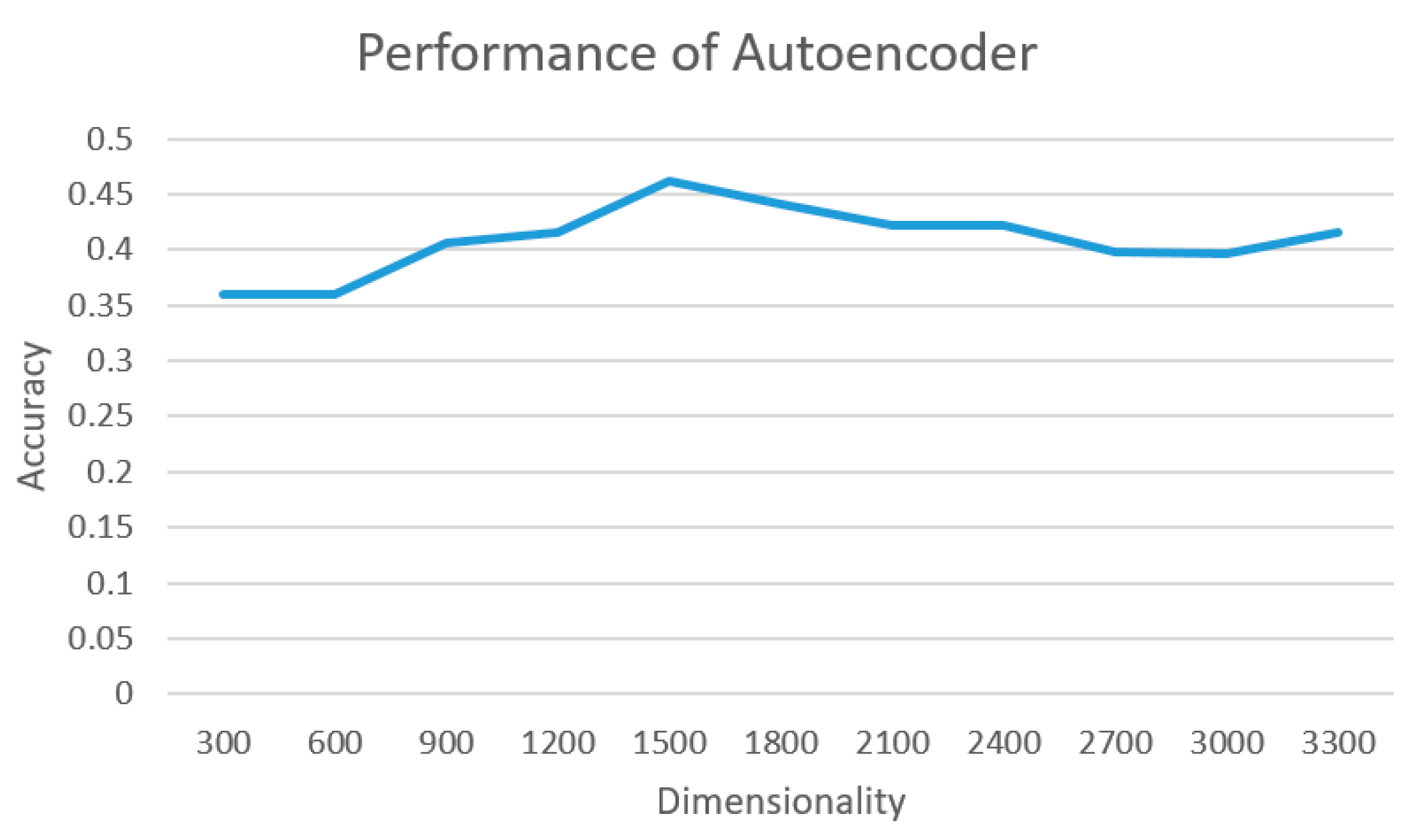
To verify the effectiveness of using an autoencoder in finding similar users, we took the features produced by either early fusion or late fusion as inputs to a single-layer neural network for dimension reduction. The performance comparison of autoencoders in different dimensions is shown in
Figure 11.
From the experimental results in
Figure 11, the best performance could be obtained with the average top-k accuracy of 0.462, when the feature dimension was reduced to 1500 if we used the feature map as the features. This was not as good as the best performance after either early or late fusion. However, the number of dimensions could be greatly reduced from 4096 to 1500. This can help reduce the storage needed for the redundant features. It would be useful to keep the more important features for more efficient computations in practice.
4.2.5. Effects of User Clustering
To verify if user clustering is effective in finding similar users, we further took the feature map and categories from either early fusion or late fusion. Since user clustering can be done offline, only the similarity calculations are needed for those users in the same cluster as the given user. From our experimental results, the best number of clusters was 3 with the average top-k accuracy of 0.367. Since the effectiveness was not as good as a direct recommendation, we further verify the efficiency of recommendation using user clustering in
Table 2.
As shown in
Table 2, although the total amount of time needed in the user clustering model was longer than late fusion due to the time for clustering, the actual amount of time for recommendation was less than that for late fusion. In practical application scenarios, user clustering only needs to be calculated offline once when there are certain amounts of new content or new users. This makes it much faster in the recommendation stage.
To investigate the effects of our proposed approach on a larger scale, we further conducted experiments on Dataset_2. The performance comparison of different models on both datasets is summarized below.
As shown in
Table 3, multimodal feature fusion is useful since we can combine clues from both text and image contents. The best performance could be obtained for the late fusion model, with the average top-k accuracy of 0.491 and 0.281 for Dataset_1 and Dataset_2, respectively. Although the accuracy could not be further improved by autoencoders, we could obtain comparable performance with the benefits of dimensionality reduction since a lower dimension means less storage needed, as well as less time required for recommendation systems.
5. Discussions
From these experimental results, there are several observations. First, the performance of the CNN-based models (either text or image) is better than the baseline model (text). The improvement of TextCNN or ImageCNN over the baseline is 19% in terms of accuracy. This shows that neural network-based models can improve the performance of content-based baseline models.
However, in this paper, we focused on the task of user recommendation. Existing recommender systems focus on item recommendation on the basis of user ratings on different items. User recommendation is more challenging since we have many users, where each one has different attributes and preferences that cannot be exactly the same as others. When we categorize user preferences, multiclass classification is more difficult than binary classification. To the best of our knowledge, there is no publicly available dataset for user recommendation. Since there is no ground truth in real-world data, we assume that hashtags posted by users represent their implicit user preferences. For each user, the users with more similar hashtags are assumed to be the ground truth of their similar users. Then, we evaluate the performance by the average top-k accuracy of each system-generated user list, as shown in Equation (8). As shown in
Section 4, all four proposed model variations outperformed the baseline model. Among the four different variations, late fusion achieved the best performance of 0.491 in terms of average top-k accuracy for similar user recommendation. This shows the effectiveness of the proposed model. Although autoencoders cannot further improve the accuracy, comparable performance can be obtained with the benefits of dimensionality reduction. This gives better efficiency for real-world recommendation systems.
To further assess the performance on a larger scale, all models were executed on Dataset_2. We applied the same parameters as obtained in the best performing models in previous experiments for Dataset_2. From the experimental results, the best performance could be obtained with the average top-k accuracy of 0.281 for late fusion when we used the categories as the user feature with a dimension of 4096. It is worth noting that the proposed approach is far better than the baseline. The improvement across all models is about 8–18%. This further validates the usefulness of our proposed method in practice. The attributes in Dataset_2 are completely different from those in Dataset_1 since they were written in different languages. This shows the effectiveness of our proposed approach in different languages.
The reasons why the performance of Dataset 2 was inferior to that of Dataset 1 are as follows: first, since more tags were used as our queries to Instagram to collect our Dataset 2, we could obtain more posts by more people which could give us more diverse content. Specifically, we included hashtags in Chinese, which involves cross-lingual issues when we cannot effectively identify different hashtags in different languages with similar meanings. One of the reasons why the top-k accuracy for user recommendation was not as high as accuracy in classification tasks is that user-provided hashtags are very diverse. Since our approach is evaluated on the basis of hashtags, this shows its limitation. However, as shown in the experimental results, our proposed approach can outperform the cases of single-modal feature. We demonstrated the effectiveness of multimodal feature fusion from texts and images for user recommendation. In the future, we plan to resolve the issue of diverse hashtags by consolidating the semantic meanings of hashtags using word embedding models or state-of-the-art deep learning models for linguistic tasks such as transformers or Bidirectional Encoder Representations from Transformers (BERT).
As a potential application of our proposed approach, we can utilize the similar user recommendation algorithm to build an intellectual data crawler in social networks. For example, according to the targeted topics of interest, we can utilize our proposed approach to discover related posts, with multimedia content and related user information. Then, by clustering similar users on the basis of user preferences, it would be useful to further expand our proposed approach across multiple social networks that might be different in their structure. This could help reduce the problem of social network analysis across different social networks.
In real application scenarios, there could be issues such as posted and reposted images, as well as drawings and photos of the same thing, to name a few. In this paper, we did not distinguish between posted and reposted images if they were captured in the same resolution. Since the features of all images were extracted by the same CNN architecture of VGG16, the posted and reposted images would have the same features if they are represented by the same pixels. This classifies them into the same category, from which our recommendation is made. Following the same line of thought, various content such as drawings and photos of the same thing would not have exactly the same features since it would be difficult to mimic the photos when drawing the same thing. However, CNN models were demonstrated [
52] to improve the performance of sketch-based image retrieval (SBIR) by extracting deep features in recent years. Since we utilize VGG16 with multiple convolutional and pooling layers, our algorithm is able to extract the important semantic features from drawings and photos of the same thing that give similar classification results.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}