
Question Difficulty Estimation Based on Attention Model for Question Answering


Abstract
:1. Introduction
- We formally define the question difficult estimation as estimating the difficulty level of a given question in question-answering tasks. The question difficult estimation for any question answering tasks can be formulated using the proposed definition.
- We design an attention-based model for question difficulty estimation. The proposed attention-based model captures the relationship among the information components as well as the inter-relationships between a questionary sentence and each information component.
- We examine the performance of the proposed model with intensive experiments on three real-world QA data sets. The intensive experiments validate the effectiveness of the proposed model.
- We empirically show that the performance of question answering is improved by adding the difficulty level.
2. Related Work
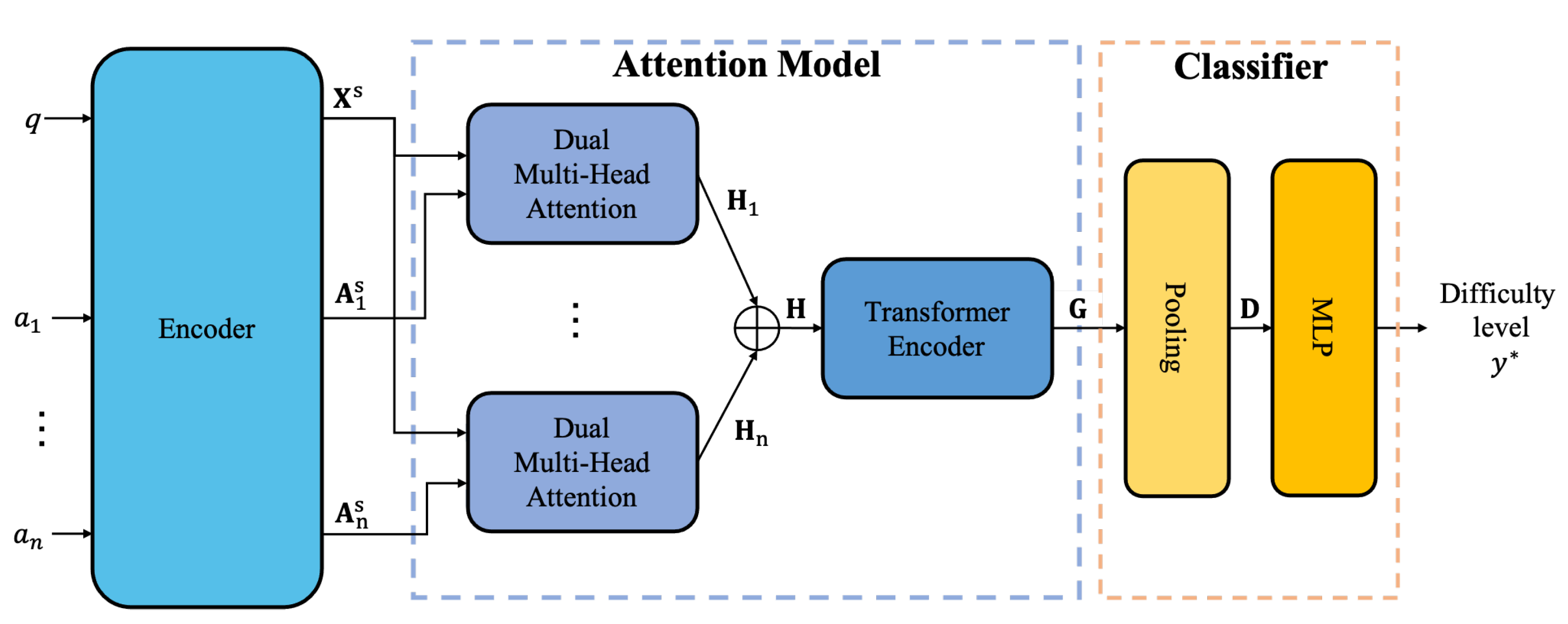
3. Attention-Based Question Difficulty Estimation
3.1. Encoding Question Components
3.2. Representing Relationships Using Attention Model
3.3. Difficulty Prediction and Implementation
4. Experiments
4.1. Experimental Setting
4.2. Experimental Results
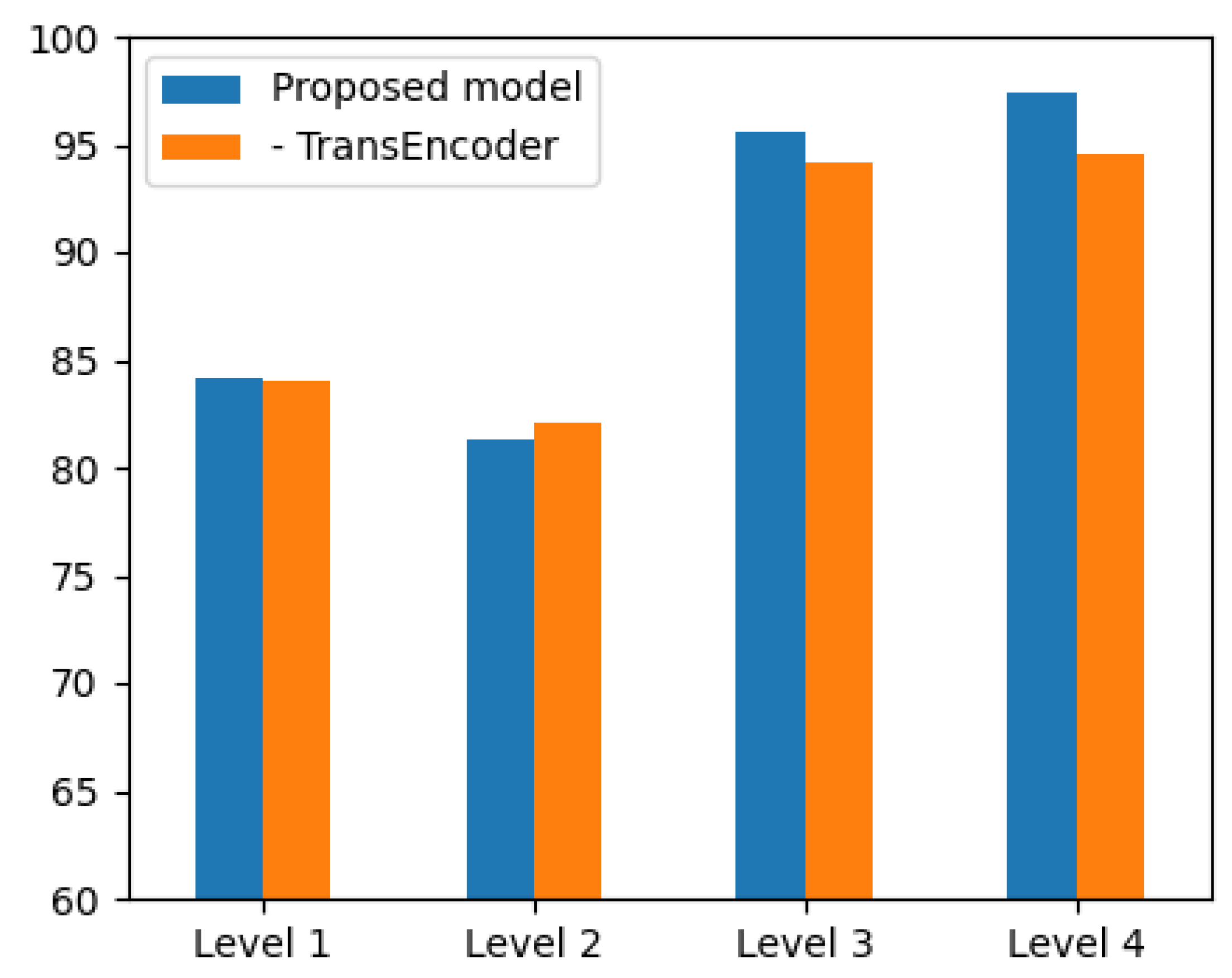
4.3. Ablation Study
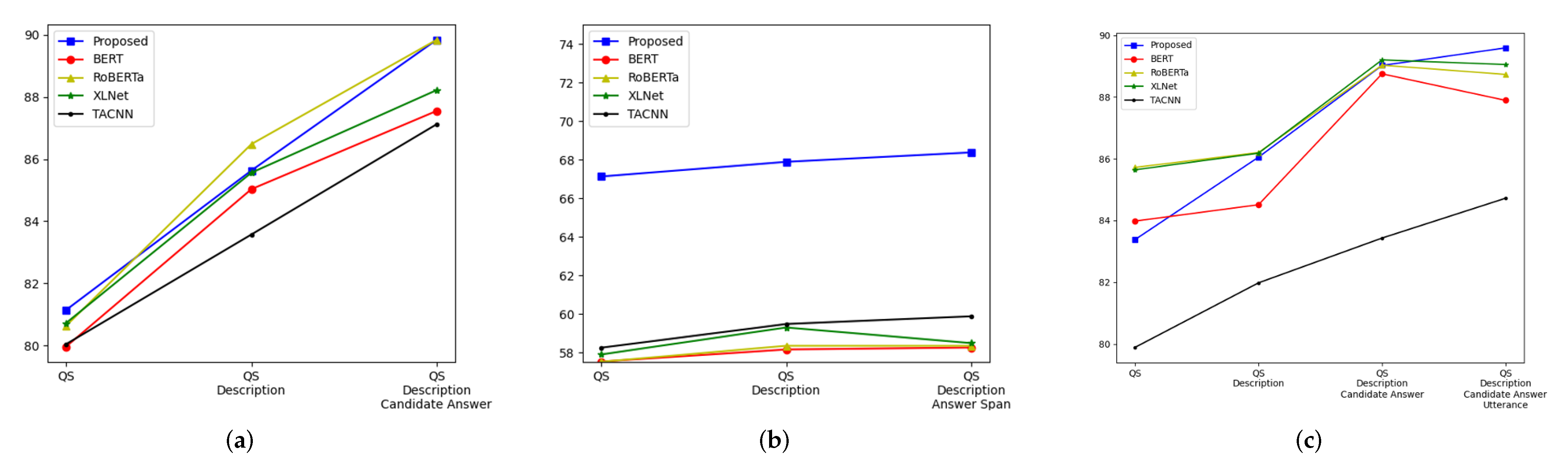
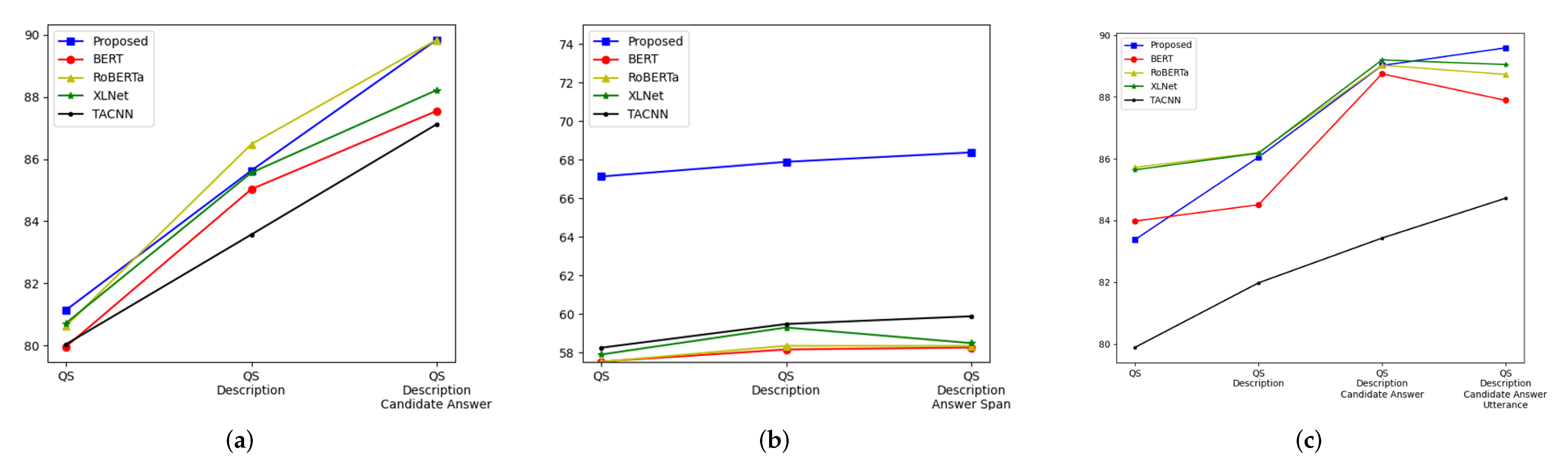
4.4. Performance Change according to No. of Information Components
4.5. Performance of Question Answering with Difficulty Level
4.6. Performance Change according to Data Ratio
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Clark, P.; Cowhey, I.; Etzioni, O.; Khot, T.; Sabharwal, A.; Schoenick, C.; Tafjord, O. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv 2018, arXiv:1803.05457. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 784–789. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. HOTPOTQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2369–2380. [Google Scholar] [CrossRef] [Green Version]
- Cao, Q.; Trivedi, H.; Balasubramanian, A.; Balasubramanian, N. DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4487–4497. [Google Scholar] [CrossRef]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar] [CrossRef]
- Zhu, M.; Ahuja, A.; Juan, D.C.; Wei, W.; Reddy, C.K. Question Answering with Long Multiple-Span Answers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, Online, 16–20 November 2020; pp. 3840–3849. [Google Scholar] [CrossRef]
- He, Y.; Zhu, Z.; Zhang, Y.; Chen, Q.; Caverlee, J. Infusing Disease Knowledge into BERT for Health Question Answering, Medical Inference and Disease Name Recognition. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 4604–4614. [Google Scholar] [CrossRef]
- Heo, Y.J.; On, K.W.; Choi, S.; Lim, J.; Kim, J.; Ryu, J.K.; Bae, B.C.; Zhang, B.T. Constructing Hierarchical Q&A Datasets for Video Story Understanding. arXiv 2019, arXiv:1904.00623. [Google Scholar]
- Choi, S.; On, K.W.; Heo, Y.J.; Seo, A.; Jang, Y.; Lee, M.; Zhang, B.T. DramaQA: Character-Centered Video Story Understanding with Hierarchical QA. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 1166–1174. [Google Scholar]
- Collis, K.F. A Study of Concrete and Formal Operations in School Mathematics: A Piagetian Viewpoint; Australian Council for Educational Research: Camberwell, Australia, 1975. [Google Scholar]
- Bartolo, M.; Roberts, A.; Welbl, J.; Riedel, S.; Stenetorp, P. Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension. Trans. Assoc. Comput. Linguist. 2020, 8, 662–678. [Google Scholar] [CrossRef]
- Desai, T.; Moldovan, D.I. Towards Predicting Difficulty of Reading Comprehension Questions. In Proceedings of the 32th International Flairs Conference, Melbourne, FL, USA, 21–23 May 2018; pp. 8–13. [Google Scholar]
- Ha, L.A.; Yaneva, V.; Baldwin, P.; Mee, J. Predicting the Difficulty of Multiple Choice Questions in a High-stakes Medical Exam. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, 2 August 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Huang, Z.; Liu, Q.; Chen, E.; Zhao, H. Question Difficulty Prediction for READING Problems in Standard Tests. In Proceedings of the 31th AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1352–1359. [Google Scholar]
- Liu, J.; Wang, Q.; Lin, C.Y.; Hon, H.W. Question Difficulty Estimation in Community Question Answering Services. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 85–90. [Google Scholar]
- Qiu, Z.; Wu, X.; Fan, W. Question Difficulty Prediction for Multiple Choice Problems in Medical Exams. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 139–148. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, Y.; Wang, H. Token-level Dynamic Self-Attention Network for Multi-Passage Reading Comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2252–2262. [Google Scholar] [CrossRef] [Green Version]
- Zhu, P.; Zhao, H.; Li, X. DUMA: Reading Comprehension with Transposition Thinking. arXiv 2020, arXiv:2001.09415. [Google Scholar]
- Gao, Y.; Bing, L.; Chen, W.; Lyu, M.R.; King, I. Difficulty Controllable Generation of Reading Comprehension Questions. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4968–4974. [Google Scholar]
- Pasupat, P.; Liang, P. Compositional Semantic Parsing on Semi-Structured Tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1470–1480. [Google Scholar] [CrossRef]
- Herzig, J.; Nowak, P.K.; Müller, T.; Piccinno, F.; Eisenschlos, J. TaPas: Weakly Supervised Table Parsing via Pre-training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4320–4333. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Lawrence Zitnick, C.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Ionescu, B.; Müller, H.; Villegas, M.; de Herrera, A.G.S.; Eickhoff, C.; Andrearczyk, V.; Cid, Y.D.; Liauchuk, V.; Kovalev, V.; Hasan, S.A.; et al. Overview of ImageCLEF 2018: Challenges, datasets and evaluation. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages, Avignon, France, 10–14 September 2018; pp. 309–334. [Google Scholar]
- Ye, Y.; Zhang, S.; Li, Y.; Qian, X.; Tang, S.; Pu, S.; Xiao, J. Video question answering via grounded cross-attention network learning. Inf. Process. Manag. 2020, 57, 102265. [Google Scholar] [CrossRef]
- Xue, K.; Yaneva, V.; Christopher Runyon, P.B. Predicting the Difficulty and Response Time of Multiple Choice Questions Using Transfer Learning. In Proceedings of the 15th Workshop on Innovative Use of NLP for Building Educational Applications, Seattle, WA, USA, 10 July 2020; pp. 193–197. [Google Scholar] [CrossRef]
- Zheng, J.; Cai, F.; Chen, H.; de Rijke, M. Pre-train, Interact, Fine-tune: A novel interaction representation for text classification. Inf. Process. Manag. 2020, 57, 102215. [Google Scholar] [CrossRef] [Green Version]
- Cao, N.D.; Aziz, W.; Titov, I. Question answering by reasoning across documents with graph convolutional networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 2306–2317. [Google Scholar]
- Song, L.; Wang, Z.; Yu, M.; Zhang, Y.; Florian, R.; Gildea, D. Exploring Graph-structured Passage Representation for Multi-hop Reading Comprehension with Graph Neural Networks. arXiv 2018, arXiv:1809.02040. [Google Scholar]
- Wang, Y.; Liu, K.; Liu, J.; He, W.; Lyu, Y.; Wu, H.; Li, S.; Wang, H. Multi-passage machine reading comprehension with cross-passage answer verification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1918–1927. [Google Scholar] [CrossRef] [Green Version]
- Dehghani, M.; Azarbonyad, H.; Kamps, J.; de Rijke, M. Learning to transform, combine, and reason in open-domain question answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 681–689. [Google Scholar] [CrossRef]
- Zhong, V.; Xiong, C.; Keskar, N.S.; Socher, R. Coarse-grain fine-grain coattention network for multi-evidence question answering. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Proceedings of the 20th International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. RACE: Large-scale Reading Comprehension Dataset From Examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Choi, E.; He, H.; Iyyer, M.; Yatskar, M.; Yih, W.T.; Choi, Y.; Liang, P.; Zettlemoyer, L. QuAC: Question Answering in Context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2174–2184. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Carletta, J. Assessing Agreement on Classification Tasks: The Kappa Statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | No. of Questions | No. of Information Components |
|---|---|---|
| RACE | 97,687 | 2 (passage, candidate answers) |
| QuAC | 7354 | 2 (passage, candidate answers) |
| DramaQA | 16,191 | 3 (description, candidate answers, utterance) |
| Parameters | RACE | QuAC | DramaQA | |
|---|---|---|---|---|
| Encoder | Model | BERT-Base | ||
| DUMA | Hidden dim. | 1536 | 1536 | 1536 |
| No. head | 8 | 6 | 6 | |
| dropout | 0.2 | 0.2 | 0.2 | |
| Fuse | concat | |||
| TransEncoder | Hidden dim. | 3072 | 3072 | 4608 |
| No. head | 4 | 4 | 4 | |
| No. layers | 6 | 6 | 6 | |
| dropout | 0.2 | 0.2 | 0.2 | |
| Implementation Option | RACE | QuAC | DramaQA | |
|---|---|---|---|---|
| concat | 89.56 | 70.13 | 89.15 | |
| summation | 88.40 | 70.39 | 88.15 | |
| Relationship direction | single (MHA) | 89.26 | 69.74 | 88.45 |
| dual (DUMA) | 89.56 | 70.13 | 89.15 | |
| Data Set | RACE | QuAC | DramaQA | |||
|---|---|---|---|---|---|---|
| Acc. (%) | F1-Score | Acc. (%) | F1-Score | Acc. (%) | F1-Score | |
| BERT | 87.75 | 87.55 | 58.31 | 58.25 | 87.95 | 87.89 |
| RoBERTa | 89.82 | 89.84 | 58.72 | 58.34 | 88.81 | 88.73 |
| XLNet | 89.02 | 88.22 | 58.51 | 58.48 | 89.07 | 89.05 |
| TACNN | 87.27 | 87.12 | 60.71 | 59.87 | 84.46 | 84.72 |
| Proposed model | 89.81 | 89.84 | 68.23 | 68.37 | 89.53 | 89.59 |
| Model Variations | RACE | QuAC | DramaQA |
|---|---|---|---|
| Proposed model | 89.56 | 70.13 | 89.15 |
| – DUMA | 88.54 | 65.22 | 86.77 |
| – TransEncoder | 88.94 | 68.81 | 88.58 |
| – DUMA and TransEncoder | 87.81 | 63.53 | 85.38 |
| QA Model | Diff. 1 | Diff. 2 | Diff. 3 | Diff. 4 | Overall | Diff. Avg. |
|---|---|---|---|---|---|---|
| Multi-level context matching model [9] | 75.96 | 74.65 | 57.36 | 56.63 | 71.14 | 66.15 |
| + Difficulty level | 76.12 | 74.82 | 59.12 | 57.33 | 73.83 | 66.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.-J.; Yoon, S.-H.; Park, S.-B. Question Difficulty Estimation Based on Attention Model for Question Answering. Appl. Sci. 2021, 11, 12023. https://doi.org/10.3390/app112412023
Song H-J, Yoon S-H, Park S-B. Question Difficulty Estimation Based on Attention Model for Question Answering. Applied Sciences. 2021; 11(24):12023. https://doi.org/10.3390/app112412023
Chicago/Turabian StyleSong, Hyun-Je, Su-Hwan Yoon, and Seong-Bae Park. 2021. "Question Difficulty Estimation Based on Attention Model for Question Answering" Applied Sciences 11, no. 24: 12023. https://doi.org/10.3390/app112412023
APA StyleSong, H.-J., Yoon, S.-H., & Park, S.-B. (2021). Question Difficulty Estimation Based on Attention Model for Question Answering. Applied Sciences, 11(24), 12023. https://doi.org/10.3390/app112412023