
Deep Transfer Learning for Machine Diagnosis: From Sound and Music Recognition to Bearing Fault Detection




Abstract
:1. Introduction
2. Theoretical Background
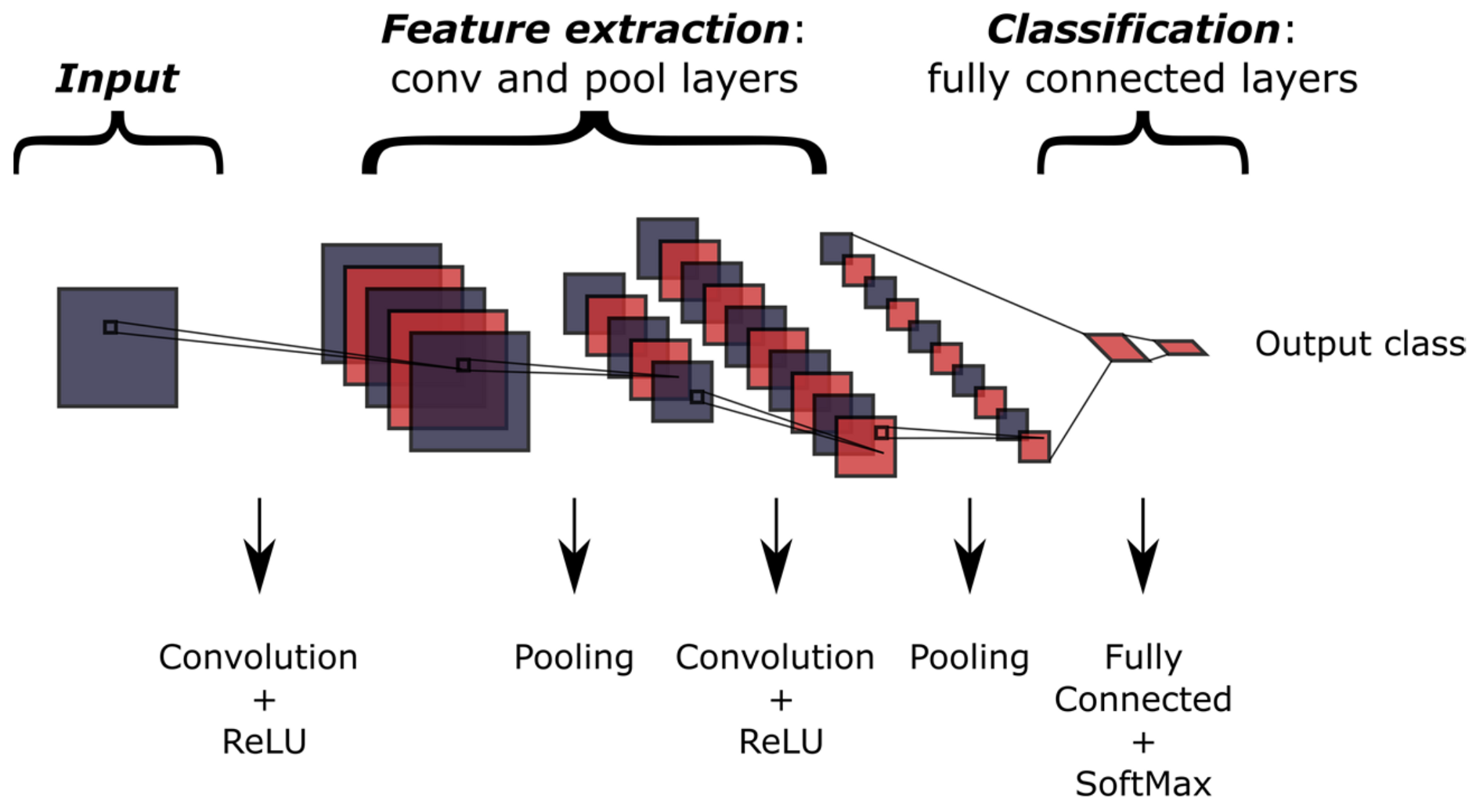
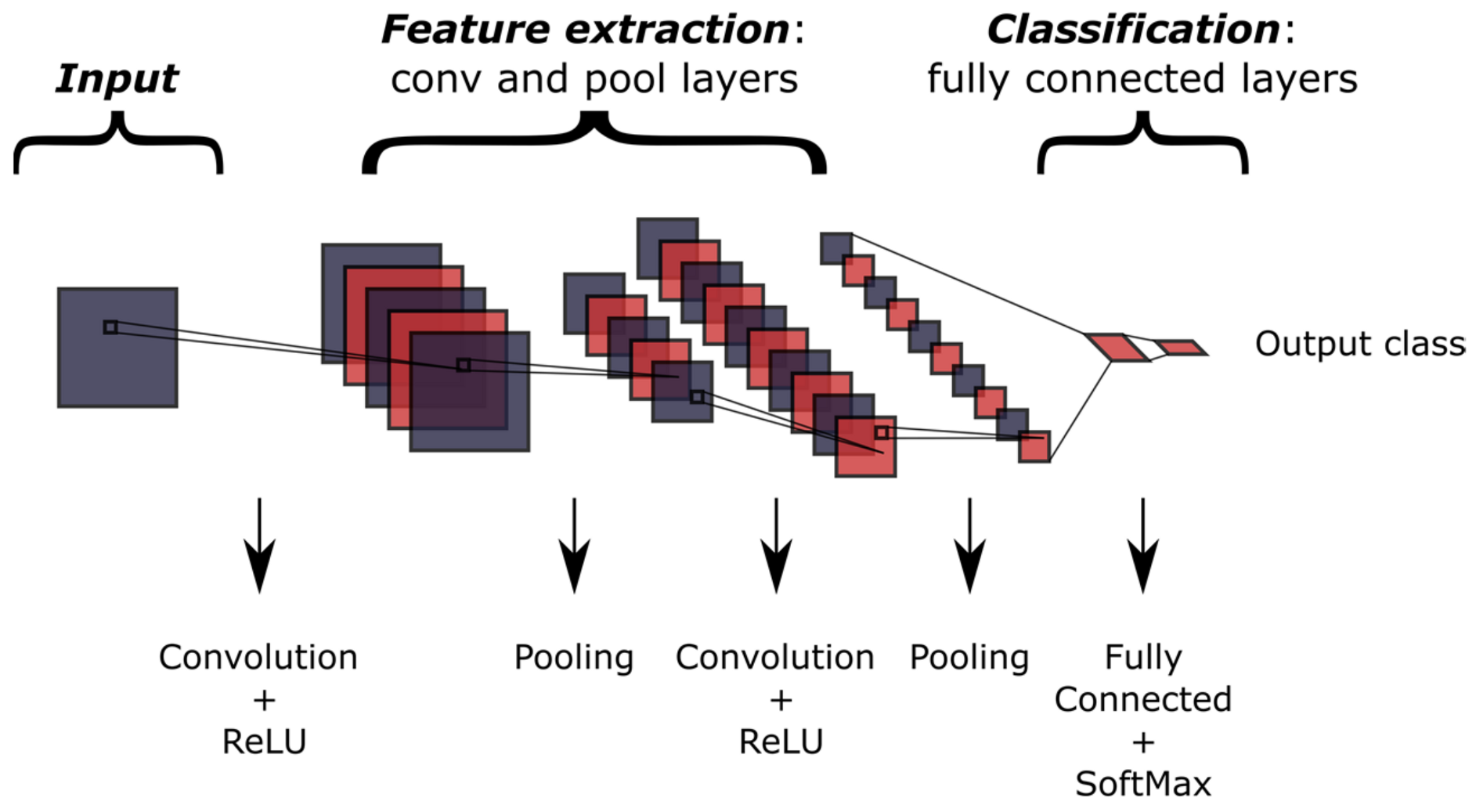
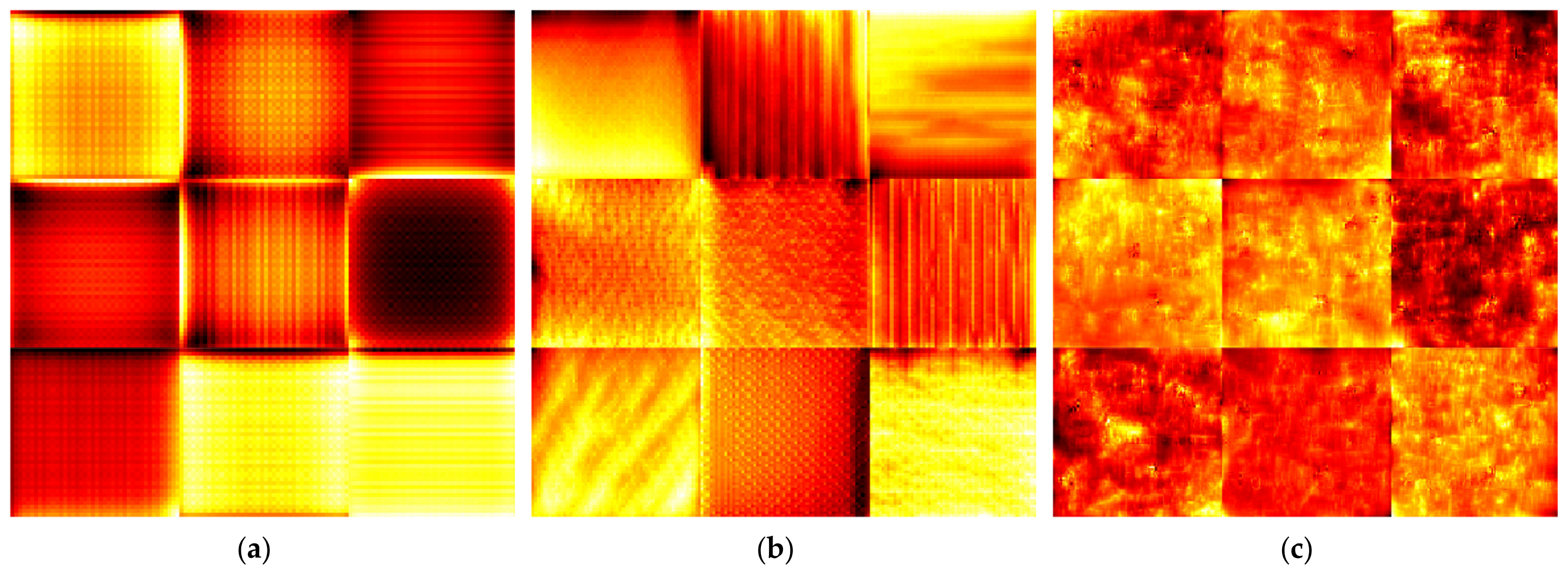
2.1. Convolutional Neural Networks (CNNs)
2.2. Transfer Learning
3. YAMNet: An Efficient CNN for Sound Event Detection
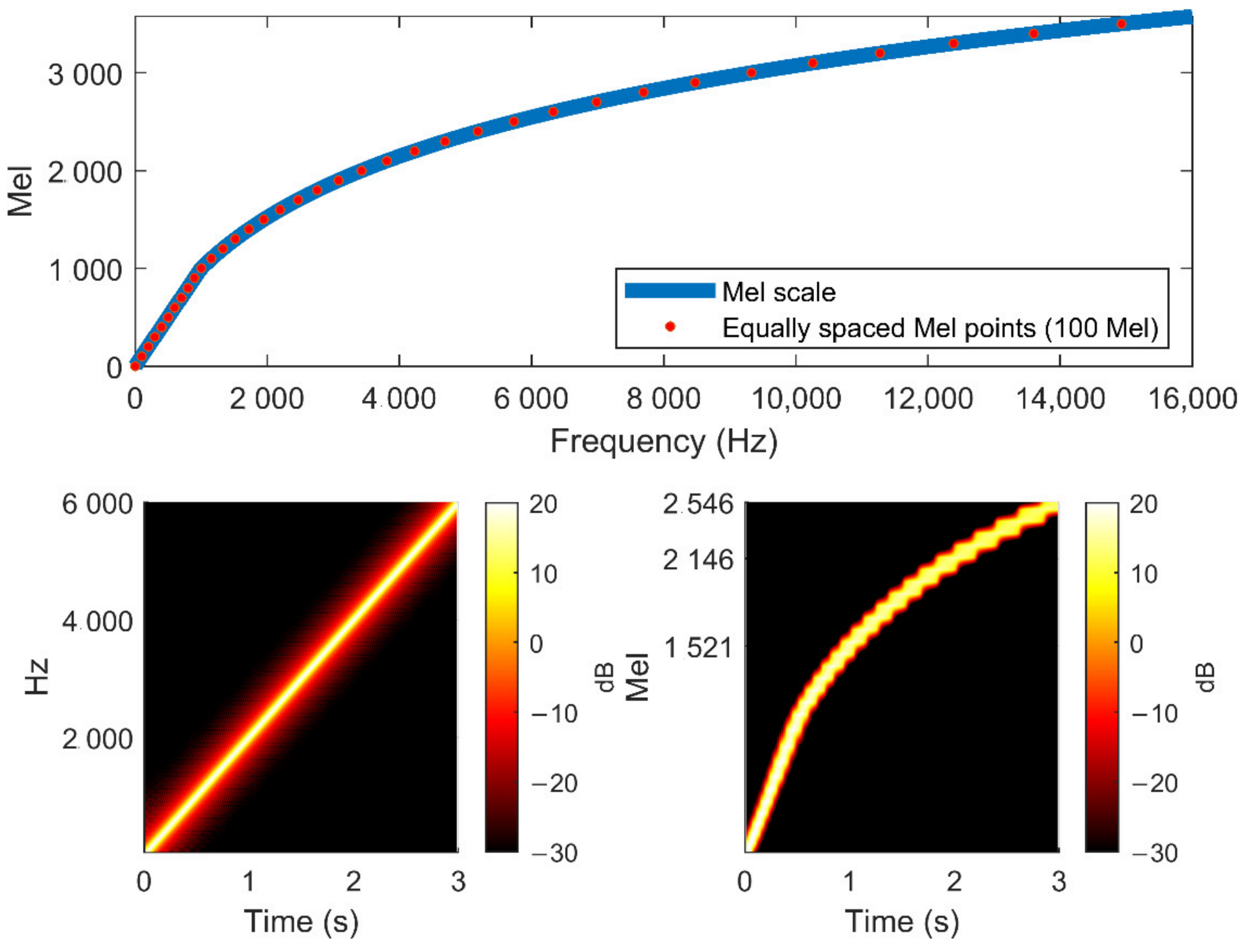
Mel Spectrogram Features
4. Bearing Fault Detection Using YAMNet and Transfer Learning
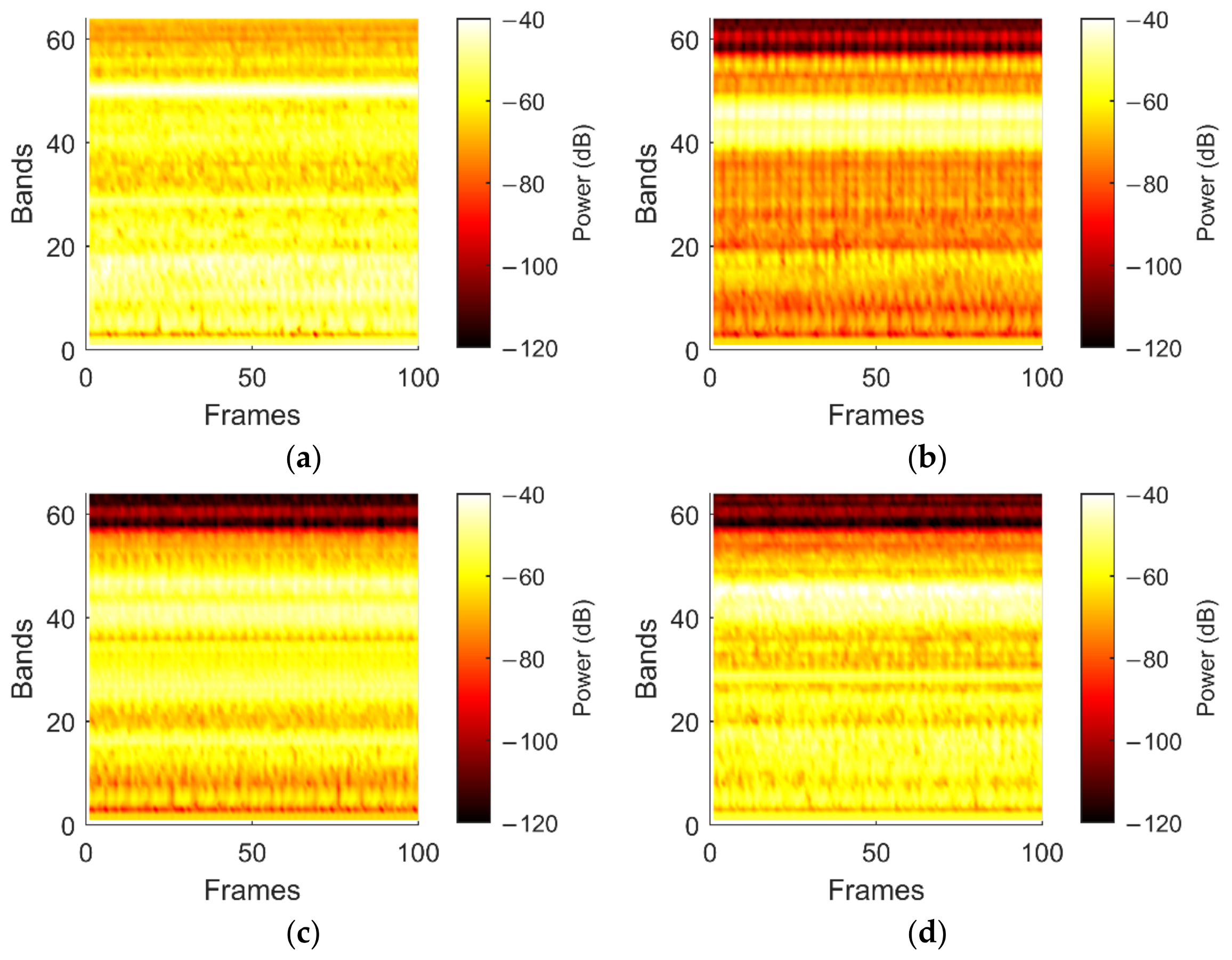
4.1. CWRU Dataset
4.2. Dataset Pre-Processing
- Dataset A includes 4 classes (B, IR, OR, and Normal);
- Dataset B includes 12 classes (B007, B014, B021, B028, IR007, IR014, IR021, IR028, OR007, OR014, OR021, and Normal);
- Dataset C includes 13 different classes (B_0, B_1, B_2, B_3, IR_0, IR_1, IR_2, IR_3, OR_0, OR_1, OR_2, OR_3, and Normal).
- Signals are resampled at 16 kHz and normalized in the range ;
- The Mel spectrogram is computed using Hann windows with 400 samples length and 60% overlap. The Mel scale filter bank includes 64 filtering bands;
- The resulting spectrogram is partitioned by using 96 sliding frames with 48 frames of overlap.
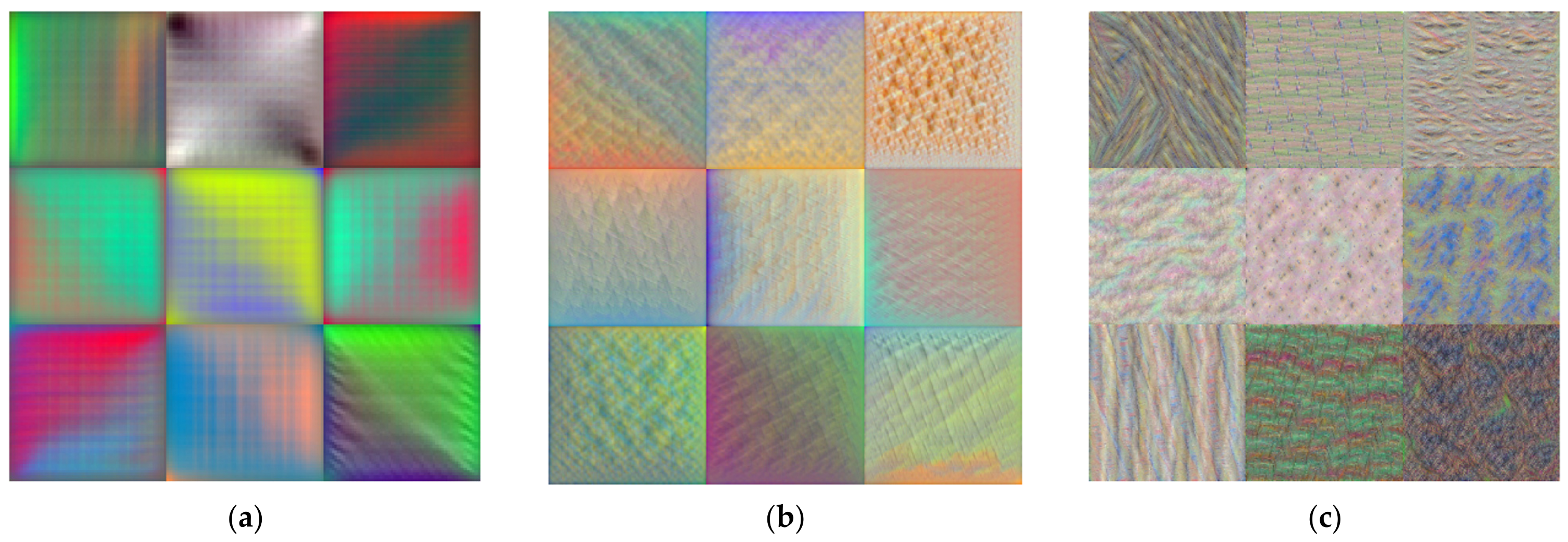
4.3. YAMNet Fine-Tuning
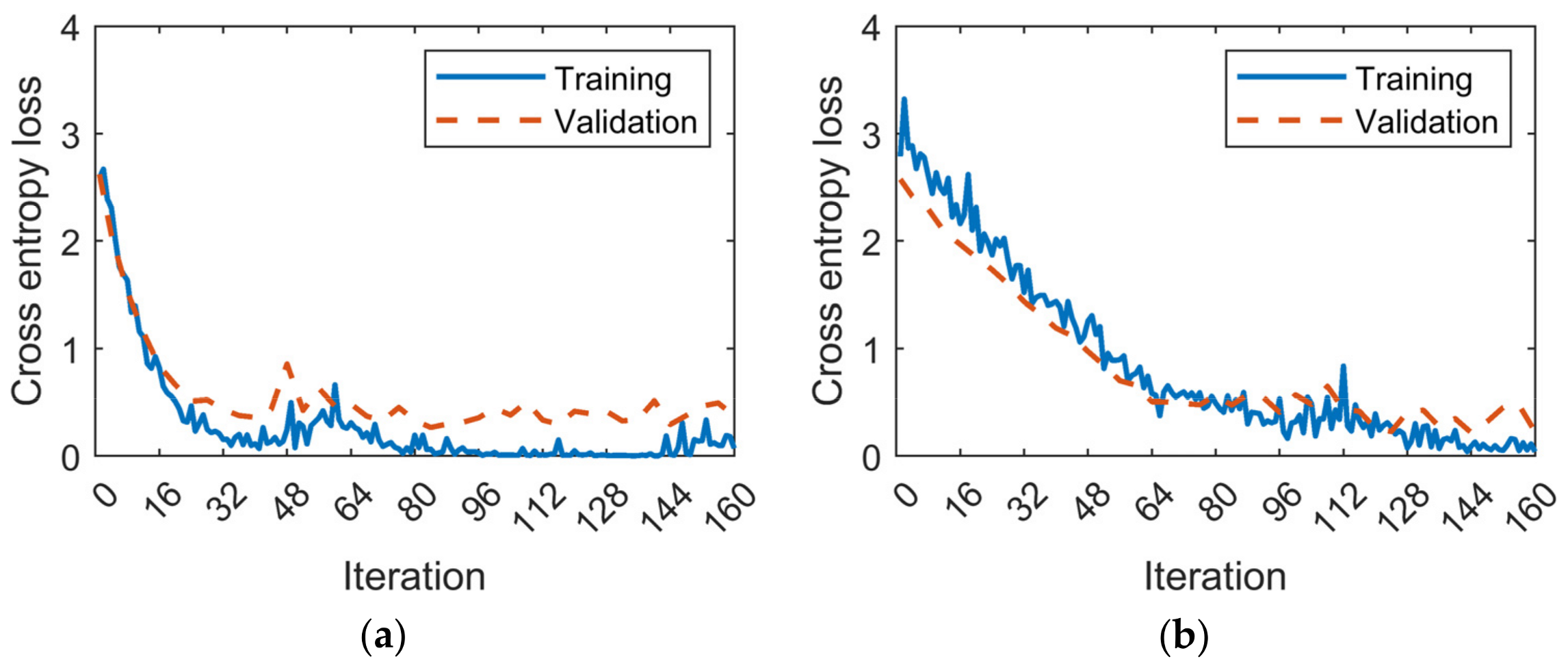
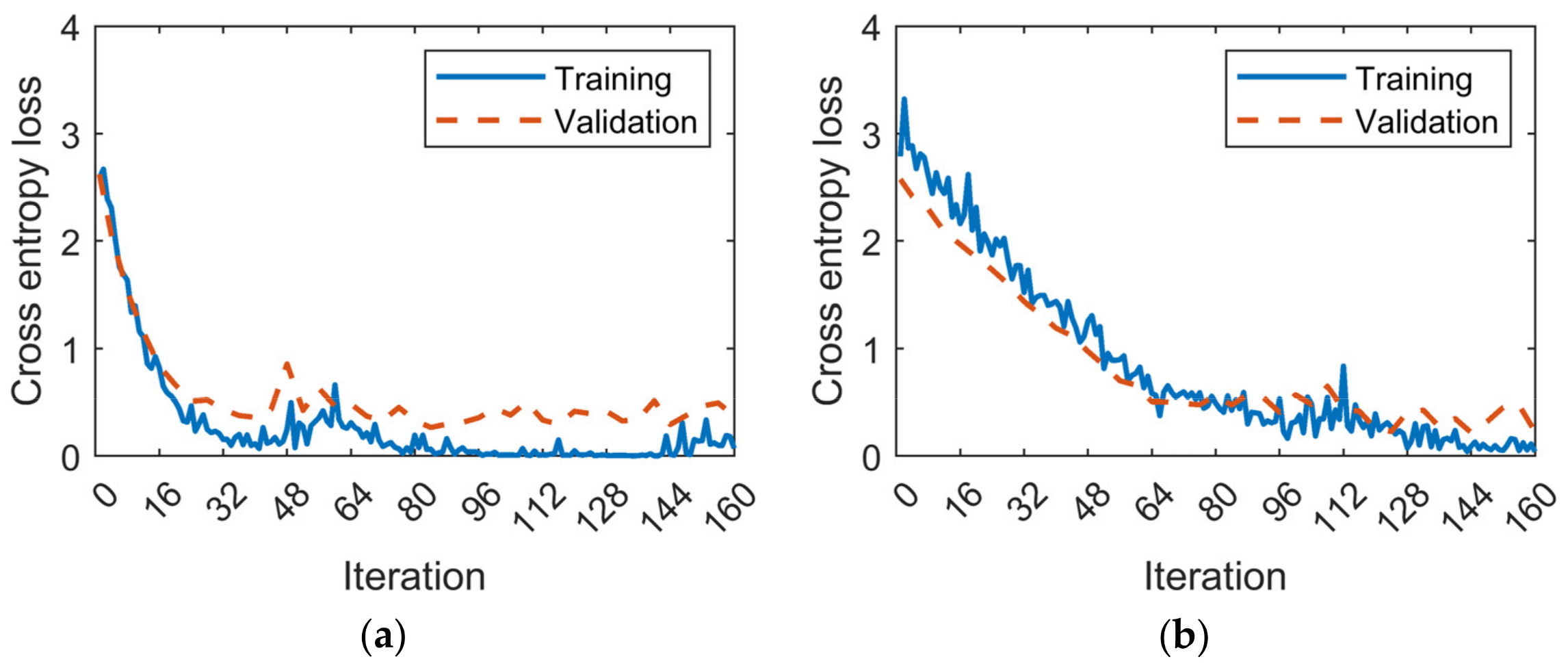
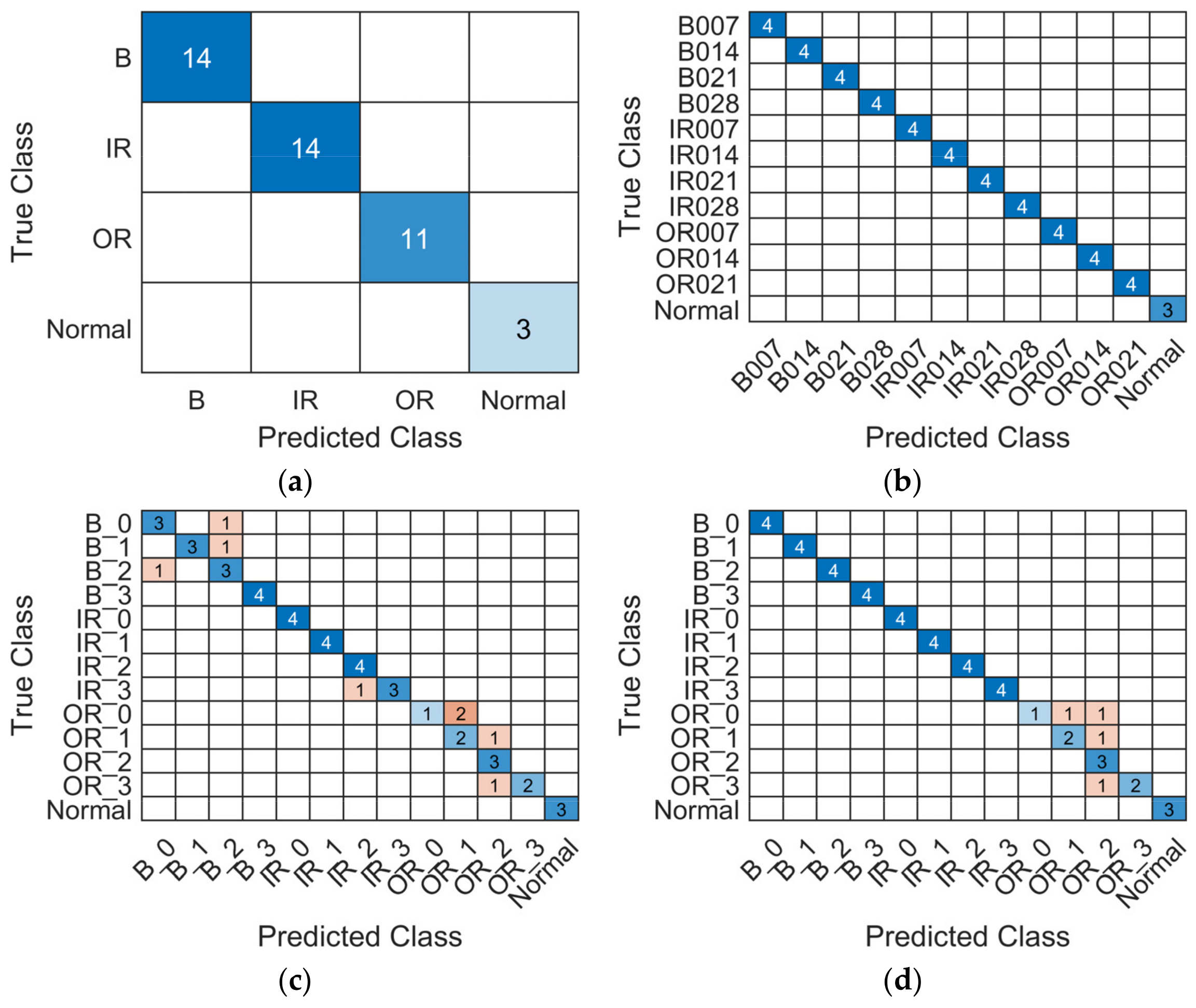
4.4. Model Validation
5. Discussion
6. Conclusions
- Networks pre-trained on sound events can fulfill a fault diagnosis task with ideal accuracy by adopting transfer learning approaches;
- The features learned over stacked convolutional layers of YAMNet architecture are also relevant for spectrograms of machine vibrations;
- Limited data scenarios can be successfully addressed by replacing a single fully connected layer for fine-tuning YAMNet;
- When limited data are split in many fault classes with imbalances, overfitting may occur despite high accuracies. In such cases, dropout layers consistently mitigate this phenomenon and further improvements in model accuracies are achieved.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Randall, R.B. Vibration-Based Condition Monitoring: Industrial, Aerospace and Automotive Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 9780470747858. [Google Scholar]
- Woodley, B.J. Failure prediction by condition monitoring (part 1). Int. J. Mater. Eng. Appl. 1978, 1, 19–26. [Google Scholar] [CrossRef]
- Mohanty, A.R. Machinery Condition Monitoring: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2014; ISBN 9781466593053. [Google Scholar]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Randall, R.B.; Antoni, J. Rolling element bearing diagnostics-A tutorial. Mech. Syst. Signal Process. 2011, 25, 485–520. [Google Scholar] [CrossRef]
- McFadden, P.D.; Smith, J.D. Model for the vibration produced by a single point defect in a rolling element bearing. J. Sound Vib. 1984, 96, 69–82. [Google Scholar] [CrossRef]
- McFadden, P.D.; Smith, J.D. Vibration monitoring of rolling element bearings by the high-frequency resonance technique—A review. Tribol. Int. 1984, 17, 3–10. [Google Scholar] [CrossRef]
- Antoni, J. The spectral kurtosis: A useful tool for characterising non-stationary signals. Mech. Syst. Signal Process. 2006, 20, 282–307. [Google Scholar] [CrossRef]
- Antoni, J. The Spectral Kurtosis of nonstationary signals: Formalisation, some properties, and application. In Proceedings of the 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004. [Google Scholar]
- Brusa, E.; Bruzzone, F.; Delprete, C.; Di Maggio, L.G.; Rosso, C. Health indicators construction for damage level assessment in bearing diagnostics: A proposal of an energetic approach based on envelope analysis. Appl. Sci. 2020, 10, 8131. [Google Scholar] [CrossRef]
- Wang, D.; Tse, P.W.; Tsui, K.-L. An enhanced Kurtogram method for fault diagnosis of rolling element bearings. Mech. Syst. Signal Process. 2013, 35, 176–199. [Google Scholar] [CrossRef]
- Hebda-Sobkowicz, J.; Zimroz, R.; Wyłomanska, A. Selection of the informative frequency band in a bearing fault diagnosis in the presence of non-gaussian noise-Comparison of recently developed methods. Appl. Sci. 2020, 10, 2657. [Google Scholar] [CrossRef] [Green Version]
- Al-Ghamd, A.M.; Mba, D. A comparative experimental study on the use of acoustic emission and vibration analysis for bearing defect identification and estimation of defect size. Mech. Syst. Signal Process. 2006, 20, 1537–1571. [Google Scholar] [CrossRef] [Green Version]
- Mba, D. The use of acoustic emission for estimation of bearing defect size. J. Fail. Anal. Prev. 2008, 8, 188–192. [Google Scholar] [CrossRef]
- Al-Dossary, S.; Hamzah, R.I.R.; Mba, D. Observations of changes in acoustic emission waveform for varying seeded defect sizes in a rolling element bearing. Appl. Acoust. 2009, 70, 58–81. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.-S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Yang, Y.; Yu, D.; Cheng, J. A fault diagnosis approach for roller bearing based on IMF envelope spectrum and SVM. Meas. J. Int. Meas. Confed. 2007, 40, 943–950. [Google Scholar] [CrossRef]
- Abbasion, S.; Rafsanjani, A.; Farshidianfar, A.; Irani, N. Rolling element bearings multi-fault classification based on the wavelet denoising and support vector machine. Mech. Syst. Signal Process. 2007, 21, 2933–2945. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Guo, X.; Shen, C.; Chen, L. Deep fault recognizer: An integrated model to denoise and extract features for fault diagnosis in rotating machinery. Appl. Sci. 2017, 7, 41. [Google Scholar] [CrossRef]
- Lu, C.; Wang, Z.Y.; Qin, W.L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process. 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A novel fault diagnosis method for rotating machinery based on a convolutional neural network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, M.M.M.; Kim, J.M. Automated bearing fault diagnosis scheme using 2D representation of wavelet packet transform and deep convolutional neural network. Comput. Ind. 2019, 106, 142–153. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Zhuang, Z.; Lv, H.; Xu, J.; Huang, Z.; Qin, W. A deep learning method for bearing fault diagnosis through stacked residual dilated convolutions. Appl. Sci. 2019, 9, 1823. [Google Scholar] [CrossRef] [Green Version]
- Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A.V. An Explainable Artificial Intelligence Approach for Unsupervised Fault Detection and Diagnosis in Rotating Machinery. arXiv 2021, arXiv:2102.11848. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012. [Google Scholar]
- Daga, A.P.; Fasana, A.; Marchesiello, S.; Garibaldi, L. The Politecnico di Torino rolling bearing test rig: Description and analysis of open access data. Mech. Syst. Signal Process. 2019, 120, 252–273. [Google Scholar] [CrossRef]
- Lee, J.; Qiu, H.; Yu, G.; Lin, J. Bearing data set. IMS, Univ. Cincinnati, NASA Ames Progn. Data Repos. Rexnord Tech. Serv. 2007, 38, 8430–8437. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2018, 15, 2446–2455. [Google Scholar] [CrossRef]
- Cao, P.; Zhang, S.; Tang, J. Preprocessing-Free Gear Fault Diagnosis Using Small Datasets with Deep Convolutional Neural Network-Based Transfer Learning. IEEE Access 2018, 6, 26241–26253. [Google Scholar] [CrossRef]
- Zhang, R.; Tao, H.; Wu, L.; Guan, Y. Transfer Learning with Neural Networks for Bearing Fault Diagnosis in Changing Working Conditions. IEEE Access 2017, 5, 14347–14357. [Google Scholar] [CrossRef]
- Hasan, M.J.; Kim, J.M. Bearing fault diagnosis under variable rotational speeds using Stockwell transform-based vibration imaging and transfer learning. Appl. Sci. 2018, 8, 2357. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Liu, M.; Drossos, K.; Virtanen, T. Sound event detection via dilated convolutional recurrent neural networks. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 286–290. [Google Scholar]
- Drossos, K.; Mimilakis, S.I.; Gharib, S.; Li, Y.; Virtanen, T. Sound event detection with depthwise separable and dilated convolutions. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef] [Green Version]
- Mesaros, A.; Heittola, T.; Virtanen, T.; Plumbley, M.D. Sound Event Detection: A tutorial. IEEE Signal Process. Mag. 2021, 38, 67–83. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Zhang, Y.; Liu, M.; Wang, W. Anomalous Sound Detection Using Deep Audio Representation and a BLSTM Network for Audio Surveillance of Roads. IEEE Access 2018, 6, 58043–58055. [Google Scholar] [CrossRef]
- Butko, T.; Pla, F.G.; Segura, C.; Nadeu, C.; Hernando, J. Two-source acoustic event detection and localization: Online implementation in a Smart-room. Eur. Signal Process. Conf. 2011, 29, 1317–1321. [Google Scholar]
- Lee, D.; Lee, S.; Han, Y.; Lee, K. Ensemble of Convolutional Neural Networks for Weakly-Supervised Sound Event Detection Using Multiple Scale Input. DCASE 2017, 1, 14–18. [Google Scholar]
- Peng, Y.T.; Lin, C.Y.; Sun, M.T.; Tsai, K.C. Healthcare audio event classification using hidden Markov models and hierarchical hidden Markov models. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 1218–1221. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Gururani, S.; Summers, C.; Lerch, A. Instrument activity detection in polyphonic music using deep neural networks. In Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, 23–27 September 2018; pp. 569–576. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1990, 39, 396–404. [Google Scholar] [CrossRef]
- Zhou, P.; Zhou, G.; Zhu, Z.; Tang, C.; He, Z.; Li, W.; Jiang, F. Health monitoring for balancing tail ropes of a hoisting system using a convolutional neural network. Appl. Sci. 2018, 8, 1346. [Google Scholar] [CrossRef] [Green Version]
- Yoo, Y.; Baek, J.G. A novel image feature for the remaining useful lifetime prediction of bearings based on continuous wavelet transform and convolutional neural network. Appl. Sci. 2018, 8, 1102. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines with Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- YAMNet Mathworks. Available online: https://it.mathworks.com/help/audio/ref/yamnet.html (accessed on 7 May 2021).
- YAMNet Tensorflow. Available online: https://www.tensorflow.org/hub/tutorials/yamnet (accessed on 7 May 2021).
- YAMNet GitHub. Available online: https://github.com/tensorflow/models/tree/master/research/audioset/yamnet (accessed on 7 May 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ioffe, S.; Christian, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR. pp. 448–456. [Google Scholar]
- Stevens, S.S.; Volkmann, J.; Newman, E.B. A Scale for the Measurement of the Psychological Magnitude Pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Rabiner, L.; Schafer, R. Theory and Applications of Digital Speech Processing; Prentice Hall Press: Hoboken, NJ, USA, 2010. [Google Scholar]
- CWRU Bearing Data Center. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 3 August 2020).








{kind=link}
{kind=link}
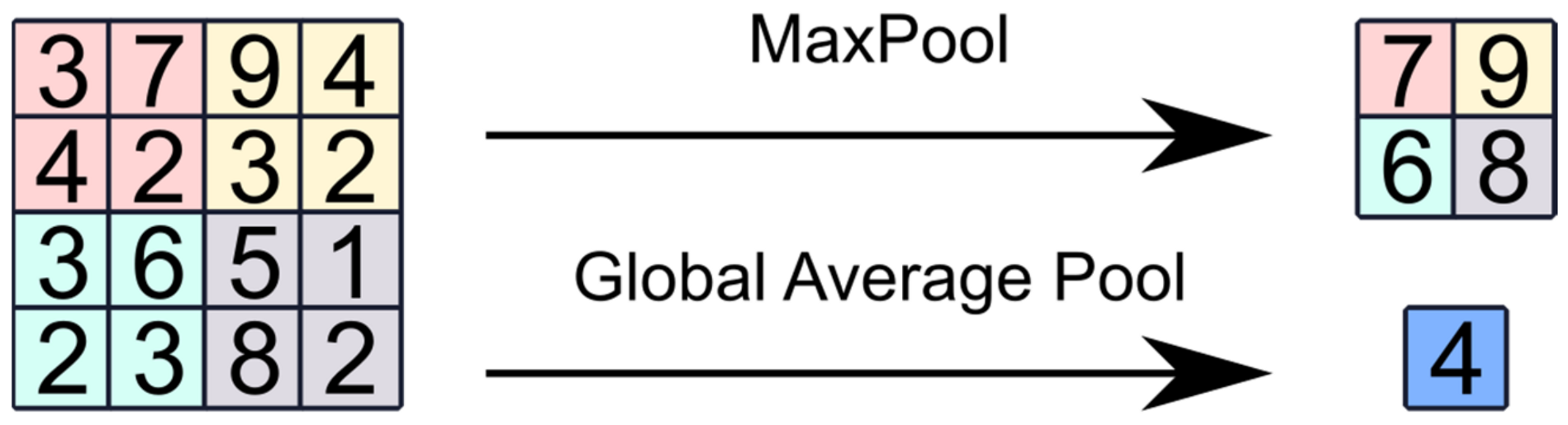{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Classes | Labels | Training Samples (70%) | Validation Samples (20%) | Test Samples (10%) |
|---|---|---|---|---|---|
| A | 4 | B | 101 | 29 | 14 |
| IR | 102 | 29 | 14 | ||
| OR | 76 | 21 | 11 | ||
| Normal | 22 | 6 | 3 | ||
| Total | 301 | 85 | 42 | ||
| B | 12 | B007 | 25 | 7 | 4 |
| B014 | 25 | 7 | 4 | ||
| B021 | 25 | 7 | 4 | ||
| B028 | 25 | 7 | 4 | ||
| IR007 | 26 | 7 | 4 | ||
| IR014 | 25 | 7 | 4 | ||
| IR021 | 25 | 7 | 4 | ||
| IR028 | 25 | 7 | 4 | ||
| OR007 | 25 | 7 | 4 | ||
| OR014 | 25 | 7 | 4 | ||
| OR021 | 25 | 7 | 4 | ||
| Normal | 22 | 6 | 3 | ||
| Total | 298 | 83 | 47 | ||
| C | 13 | B_0 | 25 | 7 | 4 |
| B_1 | 25 | 7 | 4 | ||
| B_2 | 25 | 7 | 4 | ||
| B_3 | 25 | 7 | 4 | ||
| IR_0 | 25 | 7 | 4 | ||
| IR_1 | 25 | 7 | 4 | ||
| IR_2 | 25 | 7 | 4 | ||
| IR_3 | 26 | 7 | 4 | ||
| OR_0 | 19 | 5 | 3 | ||
| OR_1 | 19 | 5 | 3 | ||
| OR_2 | 19 | 5 | 3 | ||
| OR_3 | 19 | 5 | 3 | ||
| Normal | 22 | 6 | 3 | ||
| Total | 299 | 82 | 47 |
| Window | Window Length (Samples) | Overlap (%) | Mel Spectrum Bands | Mel Spectrum Frames |
|---|---|---|---|---|
| Hann | 400 | 60% | 64 | 96 |
| Hyperparameter | Value |
|---|---|
| Optimizer | Adam |
| Initial learning rate | 0.0003 |
| Mini batch size | 64 |
| Max epochs | 40 |
| Validation frequency 1 | 4 |
| Dataset | Training Epochs | Training Stop Criterion | Training Time (s) |
|---|---|---|---|
| A | 5 | Max accuracy | 38 |
| B | 4 | Max accuracy | 29 |
| C | 40 | Max epochs | 330 |
| C with dropout | 40 | Max epochs | 330 |
| Dataset | Training Accuracy | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| A | 100% | 100% | 100% |
| B | 98.4% | 100% | 100% |
| C | 96.9% | 90.2% | 83.0% |
| C with dropout | 100% | 93.9% | 91.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brusa, E.; Delprete, C.; Di Maggio, L.G. Deep Transfer Learning for Machine Diagnosis: From Sound and Music Recognition to Bearing Fault Detection. Appl. Sci. 2021, 11, 11663. https://doi.org/10.3390/app112411663
Brusa E, Delprete C, Di Maggio LG. Deep Transfer Learning for Machine Diagnosis: From Sound and Music Recognition to Bearing Fault Detection. Applied Sciences. 2021; 11(24):11663. https://doi.org/10.3390/app112411663
Chicago/Turabian StyleBrusa, Eugenio, Cristiana Delprete, and Luigi Gianpio Di Maggio. 2021. "Deep Transfer Learning for Machine Diagnosis: From Sound and Music Recognition to Bearing Fault Detection" Applied Sciences 11, no. 24: 11663. https://doi.org/10.3390/app112411663
APA StyleBrusa, E., Delprete, C., & Di Maggio, L. G. (2021). Deep Transfer Learning for Machine Diagnosis: From Sound and Music Recognition to Bearing Fault Detection. Applied Sciences, 11(24), 11663. https://doi.org/10.3390/app112411663