
An Analysis of the Use of Feed-Forward Sub-Modules for Transformer-Based Image Captioning Tasks


Abstract
:1. Introduction
- We propose transformer-based systems that, in the first stage, utilize a feed-forward encoder using deep fully-connected layers and, in the next stage, a decoder that uses feed-forward layers to encode caption embeddings. We study the memory usage at different batch sizes, the captions generated and the implication of the evaluation metric scores.
- We propose, implement and perform a comprehensive analysis of several combinations of fully connected layers on image captioning models in order to add to the body of knowledge available about the use of simpler networks, in this case, linear layers in transformer-based vision-language systems, which is an area that has hardly been explored.
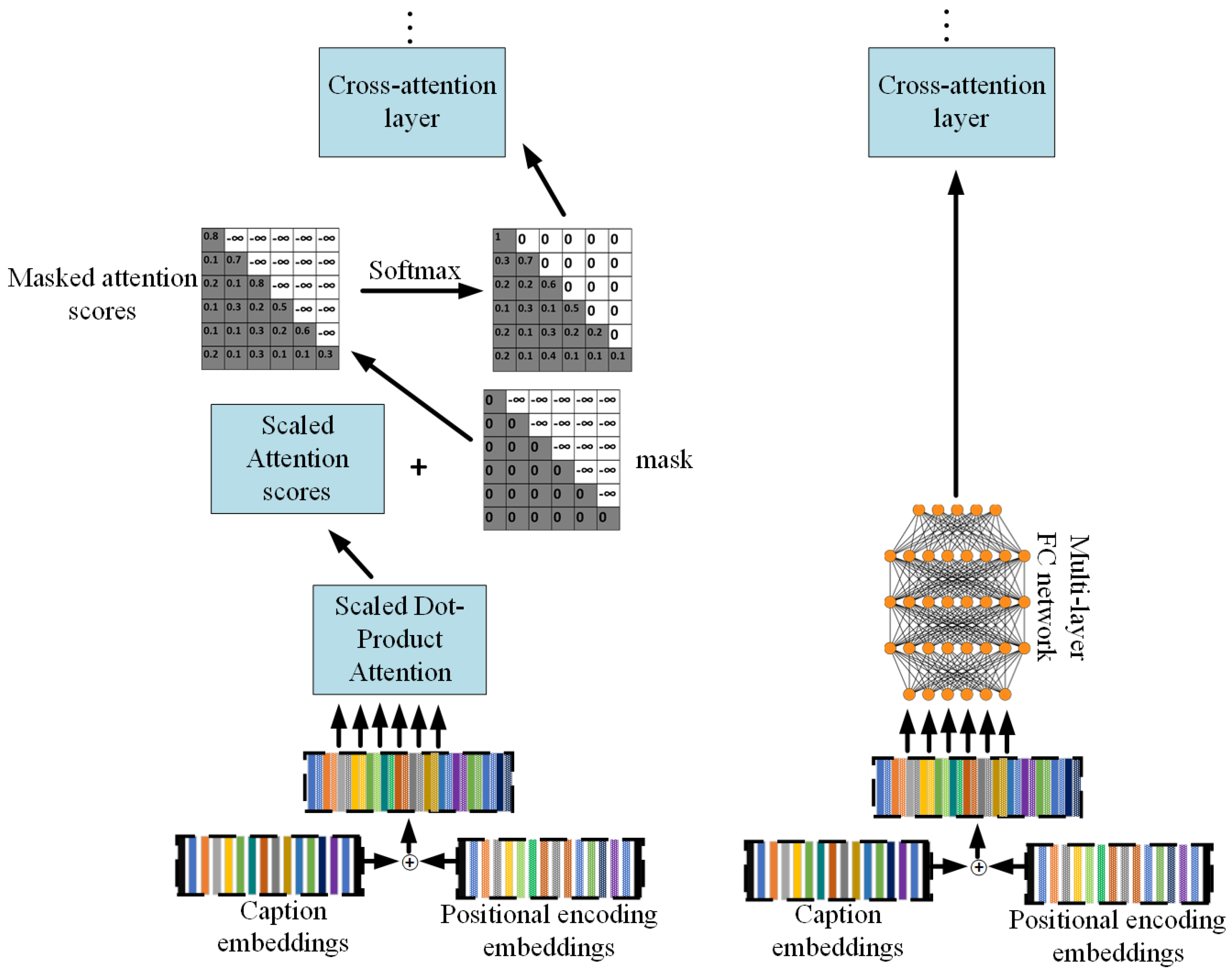
- We make a comparative analysis of the use of fully connected layers in vision language models in comparison to self-attention layers and also show that masking of the decoder input features is unnecessary in feed-forward based caption encoding by implementing an unmasked decoder input transformer module.
- We make recommendations and offer tips based on the observations made during the study in order to foster further research in the area of developing simpler transformer models for vision-language applications.
- The MSCOCO benchmark dataset is used to evaluate the performance of the proposed models, which demonstrate competitive results despite the simplicity of the models. The models also show a shorter training time, and lower memory usage at higher batch sizes in spite of containing more parameters. Lower memory requirements and training time allow for use in lower end systems.
2. Background
2.1. Algorithms in Deep Learning
2.2. Image Captioning
2.3. Masking in Transformer Decoders
3. Method
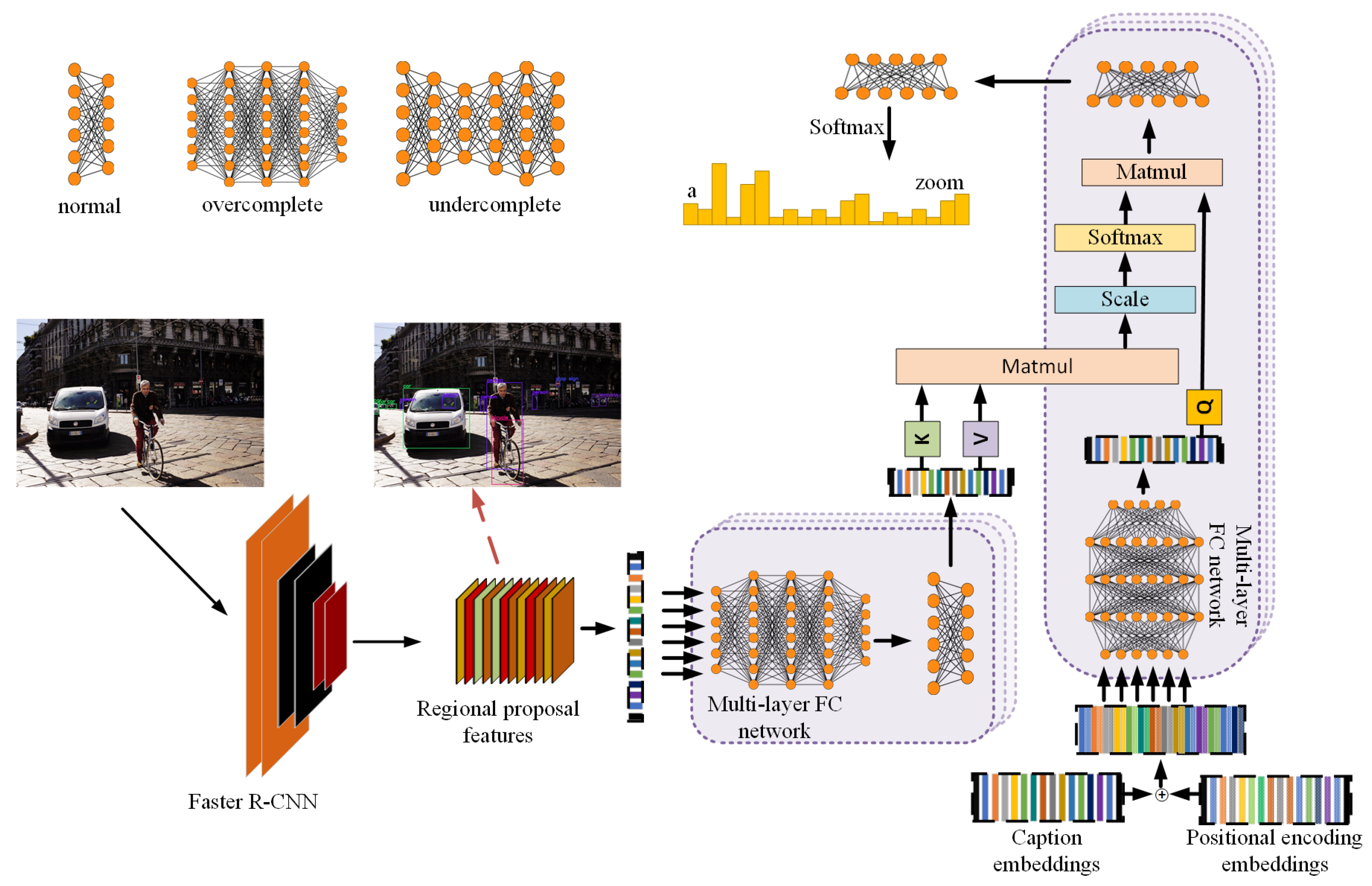
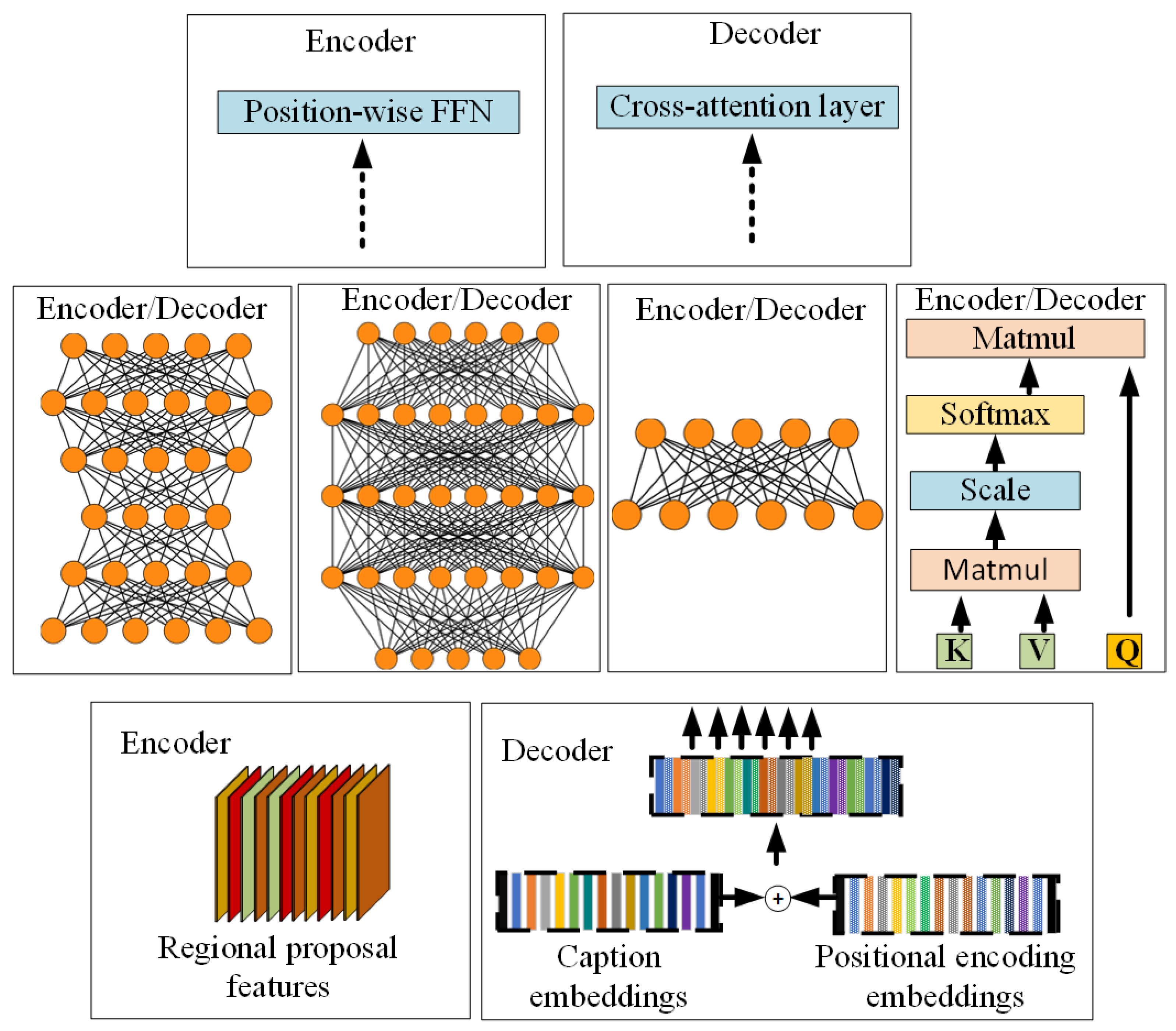
3.1. MLP
3.2. MLPs in Image Captioning
4. Experiments and Results
4.1. Materials: Dataset and Evaluation Metrics
4.2. Settings Implementation
4.3. Evaluation Studies
- (i)
- To evaluate the memory consumption of our model to a similar one using self-attention, we designed a variant that we refer to as FC-SA. In this variant, the encoder feed-forward network is replaced by a self-attention network, and the decoder one, replaced by a masked self-attention layer. The GPU memory consumption with the batch size set to 10, 20, 40, 50, 80, 100 and 150 for both our best model (FC4) and the self-attention based variant FC-SA are shown in Figure 3a.
- (ii)
- To evaluate the memory consumption at different sequence lengths, just as above, we use the FC4 and FC-SA variants. Since it is just a test of memory consumption and not a test of caption generation, we duplicate the captions to create longer captions, i.e., every caption is a multiple of its original length. So we measure memory usage at multiples of the caption length, i.e., (1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8) * caption length. Basically, given a caption sequence , then, where n is the original sequence length. The results are shown in Figure 3b. We also report the inference time required to generate captions for 5000 randomly selected images.
- (iii)
- To investigate the performance of the model before and after using a look-ahead mask, we ran the FC4 and FC-SA variants with and without the mask.
- (iv)
- To evaluate the time complexity of the introduction of the feed-forward layers, we build 2 variants of our model that are comprised of only the encoder. One variant contains the self-attention layers. In the other variant, the self-attention layers are replaced by feed-forward layers. The time taken to produce the image feature representation is noted and shown in Table 1.
- (v)
- FC0, FC1 and FC2 investigate the effect of change in number of layers or stacks on the base variant model FC0. FC0 is designed with the “normal” configuration as shown in Table 2 where input features (2048-dimensional) are directly transformed into the model dimension (512-dimensional) and forwarded to the next stage, i.e., position-wise feed-forward stage, without any other changes. The experiments covered 3-, 6- and 12-layer variants. A layer here refers to one whole encoder or decoder section. Varying the number of layers may improve or degrade the performance of the model. While it could initially improve performance because of the additional discriminatory information mined, the increase in the complexity may result in a reduction in performance, and an explosion in the size of the model and training time. This is discussed further in Section 5.
- (vi)
- FC3 is used to investigate mapping the input image features into a higher dimensional space. , where . This is the initial building block for the next couple of experiments. In this experiment, we try to find out the effect of mapping the input image features (2048-dimensional) into a higher dimensional space (4096-dimensional), an arrangement that mimics an over-complete autoencoder. The aim is to see if it creates a better representation of the input features, which would then lead to better captions. In the same line, in FC5, we implement a model that mimics an under-complete stacked auto encoder configuration, i.e.,, where . Both these are done to try to get the best possible representation of the input features when using feed-forward layers.
- (vii)
- FC4 and FC8 are designed to investigate the effect of having a deep feed-forward network over the caption embeddings. The caption embeddings representation is created using a non-masked deep fully connected neural network. One of the novelties of this paper is the use of a non-masked caption embeddings and so we perform experiments on a variant that has “normal” encoder feed-forward layer and deep fully connected decoder input sub-module that contains a series of 2048 dimensional hidden layers before being converted to the model dimension. We also test and report the results of increasing the number of layers in this configuration.
- (viii)
- Building on the previous configuration, we perform experiments with variants FC6 and FC7 where we use a deep feed-forward networks in both the encoder and decoder sections. This is done to see if we can extract any additional benefits from representing both the images and the text using a series of high dimensional feed-forward layers in both model sections.
4.4. Comparison with Other Models
5. Results Discussion
- (i)
- Generally, more layers are better, up to a certain point. At some point, the trade-off will not be worth it. There will be diminishing returns whereby the time and computational resources required to train the models are so high for a meager improvement in performance. This will especially be apparent during CIDEr-D optimization, whereby you may be forced to significantly reduce batch sizes leading to an explosion in the training time required.
- (ii)
- If implementing a meshed architecture as in [25] you could benefit from meshing just a few of the top layers, meshing all layers may lead to degradation in model performance.
- (iii)
- The GPU has a sweet spot where the batch size saturates the cores and your model can benefit the most from using the GPU. Initial small experiments should be carried out to find the ideal batch size.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Additional Comparison Graphs


Appendix A.2. Sample Captions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 | GT: a couple of young women sitting on the ground next to each other. FC0: two women sitting on the grass looking at her phone. FC1: two women sitting on a blanket looking at their cell phones. FC6: two women sitting on a blanket on her cell phones. FC4: two women sitting on the grass looking at their cell phones. |
 | GT: a large semi truck pulling a blue tractor behind it. FC0: a large truck is driving down a traffic light. FC1: a large dump truck driving down a traffic light. FC6: a construction truck carrying a crane on the road. FC4: a construction truck driving down a traffic light on the road. |
 | GT: group of adults and children at beach playing with various types of surfboards. FC0: a group of people holding surfboards on the beach. FC1: a group of people carrying surfboards on the beach with. FC6: a group of people standing on the beach. FC4: a group of people standing on the beach with surfboards. |
 | GT: lit up night traffic is zooming by a clock tower. FC0: the big ben clock tower towering over the city of london. FC1: the big ben clock tower towering over the street at night. FC6: the big ben clock tower towering over the city of london. FC4: the big ben clock tower towering over the city of london. |
 | GT: three girls walking in front of a parking meter. FC0: two women walking past a sidewalk next to a parking meter. FC1: two women standing next to a parking meter on the. FC6: two women with red hair standing next to each other. FC4: three women standing next to a parking meter on the street. |
 | GT: a group of kids that are standing in the grass. FC0: a group of people playing baseball in a field. FC1: a group of people playing baseball in a baseball field. FC6: a group of people playing baseball in a field. FC4: a group of children playing baseball on a baseball field. |
 | GT: people standing near a train that is blowing smoke. FC0: a man standing next to a train on the tracks. FC1: two people standing next to a black train on the. FC6: a man standing next to a train on the tracks. FC4: two people standing next to a black train on the tracks. |
 | GT: two cute girls with a scooter and tennis raquet. FC0: two little girls standing between two tennis racket. FC1: two young girls holding tennis rackets on a tennis court. FC6: a little girl standing next to a tennis racket. FC4: two little girls holding a tennis racket on a tennis court. |
 | GT: two men riding snowboards in a snow storm down a slope. FC0: two snowboarders are snowboarding down a snow covered slope. FC1: two people are snowboarding down a snow covered slope. FC6: a couple of men riding snowboards in the snow. FC4: two snowboarders are on snowboards in the snow covered slope. |
 | GT: an old car outside near a harbor of some sort. FC0: a yellow car parked in front of a gas station. FC1: a yellow truck parked in front of a fire hydrant. FC6: a yellow car parked in front of a building. FC4: a yellow truck parked in front of a yellow fire hydrant. |
 | GT: a row of girls holding umbrellas pose for a picture. FC0: a group of women walking down a street with umbrellas. FC1: a group of women walking down the street with umbrellas. FC6: a group of women holding umbrellas on the street. FC4: a group of women walking down a street holding umbrellas. |
 | GT: a man in front of a christmas tree with his dog. FC0: a man wearing a christmas tree with a christmas tree. FC1: a dog wearing a santa hat standing in the. FC6: a white dog standing in front of a christmas tree. FC4: a man wearing a santa hat standing in front of a christmas tree. |
References
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical Report; California University San Diego La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontanon, S. FNet: Mixing Tokens with Fourier Transforms. arXiv 2021, arXiv:2105.03824. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 30, pp. 2048–2057. [Google Scholar]
- Biten, A.F.; Gomez, L.; Rusinol, M.; Karatzas, D. Good News, Everyone! Context driven entity-aware captioning for news images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12466–12475. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Karpathy, A.; Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Karpathy, A.; Joulin, A.; Fei-Fei, L.F. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1889–1897. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Wang, Q.; Chan, A.B. Cnn+ cnn: Convolutional decoders for image captioning. arXiv 2018, arXiv:1805.09019. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5561–5570. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4634–4643. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision; Springer: New York, NY, USA, 2020; pp. 121–137. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13041–13049. [Google Scholar]
- Liu, W.; Chen, S.; Guo, L.; Zhu, X.; Liu, J. Cptr: Full transformer network for image captioning. arXiv 2021, arXiv:2101.10804. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-Memory Transformer for Image Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10578–10587. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. arXiv 2015, arXiv:1509.00685. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Osolo, R.I.; Yang, Z.; Long, J. An Attentive Fourier-Augmented Image-Captioning Transformer. Appl. Sci. 2021, 11, 8354. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. arXiv 2019, arXiv:1908.02265. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6281–6290. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. Adv. Neural Inf. Process. Syst. 2016, 29, 289–297. [Google Scholar]
- Zheng, Z.; Wang, W.; Qi, S.; Zhu, S.C. Reasoning visual dialogs with structural and partial observations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6669–6678. [Google Scholar]
- Wang, H.; Wang, W.; Shu, T.; Liang, W.; Shen, J. Active visual information gathering for vision-language navigation. In European Conference on Computer Vision; Springer: New York, NY, USA, 2020; pp. 307–322. [Google Scholar]
- Brownlee, J. Deep Learning for Natural Language Processing: Develop Deep Learning Models for Your Natural Language Problems; Machine Learning Mastery: San Juan, Puerto Rico, 2017. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 740–755. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 382–398. [Google Scholar]
- Jiang, W.; Ma, L.; Jiang, Y.G.; Liu, W.; Zhang, T. Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 499–515. [Google Scholar]
- Bapna, A.; Chen, M.X.; Firat, O.; Cao, Y.; Wu, Y. Training deeper neural machine translation models with transparent attention. arXiv 2018, arXiv:1808.07561. [Google Scholar]


| Batch Size | FC-SA | FC-SA t-enc | FC-SA t/E | FC4 | FC4 t-enc | FC4 t/E |
|---|---|---|---|---|---|---|
| (GB) | (Mins) | (Mins) | (GB) | (Mins) | (Mins) | |
| 10 | 2.1 | 32 | 47 | 2.6 | 26 | 42 |
| 20 | 3.2 | 26 | 37 | 3.7 | 19 | 34 |
| 40 | 5.2 | 23 | 34 | 6.2 | 20 | 32 |
| 50 | 6.5 | 22 | 32 | 7.1 | 17 | 28 |
| 80 | 9.3 | 21 | 32 | 9.6 | 16 | 30 |
| 100 | 10.9 | 21 | 31 | 8.1 | 18 | 31 |
| 150 | 10.7 | 19 | 31 | 9.5 | 16 | 31 |
| Method (Layers) | Encoder | Decoder |
|---|---|---|
| FC0 (3), FC1 (6), FC2 (12) | normal | normal |
| FC5 (3) | sae | normal |
| FC3 (3) | deep ff | normal |
| FC6 (3), FC7 (6) | deep ff | deep ff |
| FC4 (3), FC8 (6) | normal | deep ff |
| Method | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| Xu et al. [9] | 70.7 | 24.3 | 23.90 | - | - | - |
| SCST [41] | - | 34.2 | 26.7 | 57.7 | 114.0 | - |
| Up-Down [11] | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 |
| RFNet [48] | 79.1 | 36.5 | 27.7 | 57.3 | 121.9 | 21.2 |
| FC4 | 80.3 | 38.1 | 28.2 | 58.0 | 124.4 | 21.8 |
| Method | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| FC0 | 79.3 | 37.4 | 28.2 | 57.6 | 122.0 | 21.8 |
| FC5 | 79.3 | 37.0 | 27.5 | 56.7 | 120.8 | 20.8 |
| FC1 | 80.2 | 37.9 | 28.0 | 57.4 | 124.4 | 21.1 |
| FC6 | 78.4 | 36.3 | 27.4 | 56.7 | 117.0 | 21.0 |
| FC3 | 78.6 | 36.6 | 27.6 | 56.9 | 120.0 | 21.1 |
| FC4 | 80.3 | 38.1 | 28.2 | 58.0 | 124.4 | 21.8 |
 | GT: a large semi truck pulling a blue tractor behind it. FC0: a large truck is driving down a traffic light. FC1: a large dump truck driving down a traffic light. FC6: a construction truck carrying a crane on the road. FC4: a construction truck driving down a traffic light on the road |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osolo, R.I.; Yang, Z.; Long, J. An Analysis of the Use of Feed-Forward Sub-Modules for Transformer-Based Image Captioning Tasks. Appl. Sci. 2021, 11, 11635. https://doi.org/10.3390/app112411635
Osolo RI, Yang Z, Long J. An Analysis of the Use of Feed-Forward Sub-Modules for Transformer-Based Image Captioning Tasks. Applied Sciences. 2021; 11(24):11635. https://doi.org/10.3390/app112411635
Chicago/Turabian StyleOsolo, Raymond Ian, Zhan Yang, and Jun Long. 2021. "An Analysis of the Use of Feed-Forward Sub-Modules for Transformer-Based Image Captioning Tasks" Applied Sciences 11, no. 24: 11635. https://doi.org/10.3390/app112411635
APA StyleOsolo, R. I., Yang, Z., & Long, J. (2021). An Analysis of the Use of Feed-Forward Sub-Modules for Transformer-Based Image Captioning Tasks. Applied Sciences, 11(24), 11635. https://doi.org/10.3390/app112411635