
Sentiment Analysis of Online Course Evaluation Based on a New Ensemble Deep Learning Mode: Evidence from Chinese


Abstract
:1. Introduction
2. Related Works and Contribution
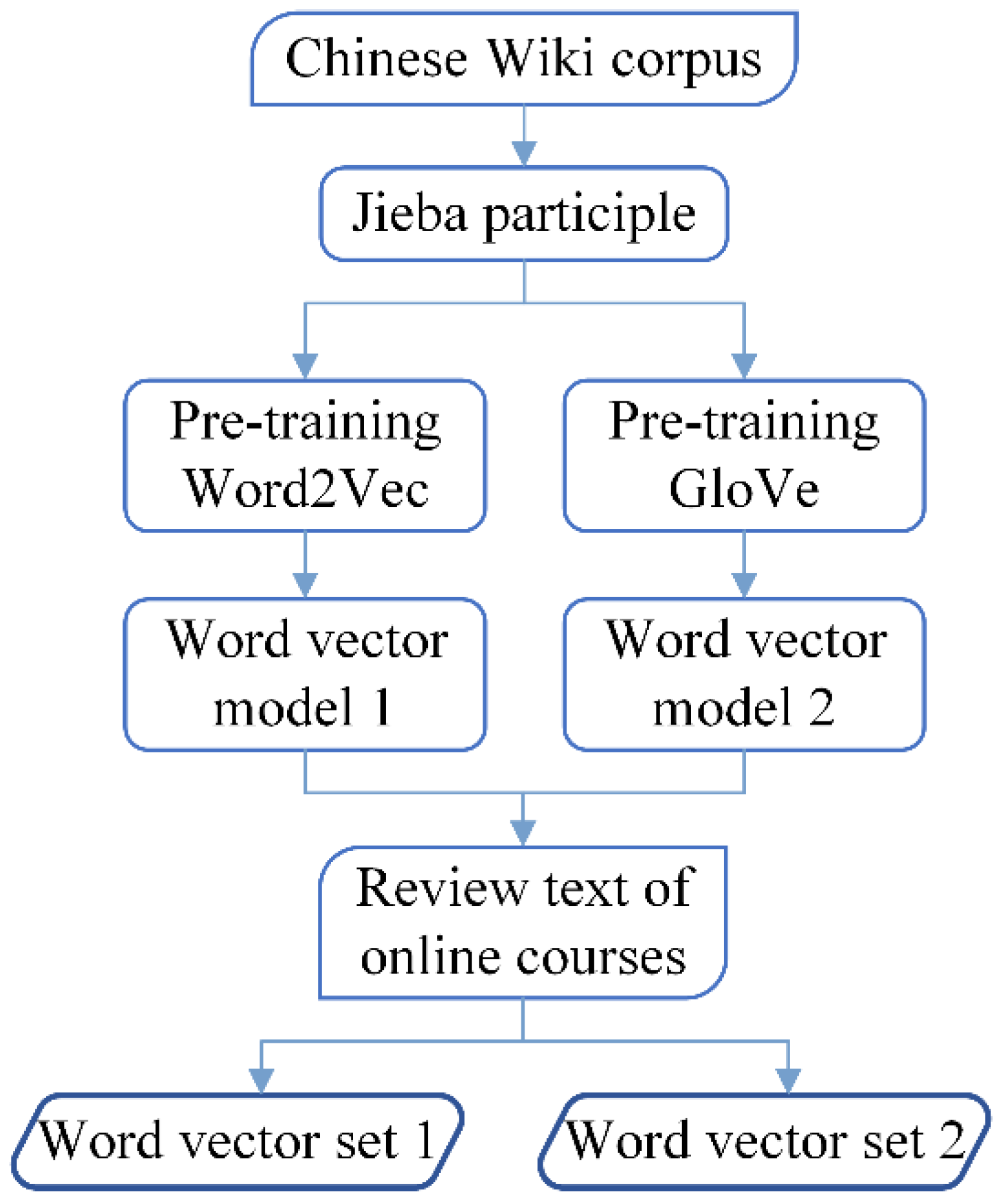
2.1. Word Vector Generation
2.2. Text Sentiment Analysis Methods
2.3. Ensemble Methods
2.4. Contribution of This Work
- (1)
- The two-channel word embedding method is used to represent online course evaluation texts, which can reduce data sparsity and ensure data integrity.
- (2)
- Feature training was carried out by CNN and BiLSTM, respectively, and emotion analysis of each submodel was completed by combining the attention mechanism. The deep network was able to extract different aspects of text depth features, and the stable emotion recognition effect of the deep network laid a foundation for the optimal ensemble method.
- (3)
- The weight of each sub-model was trained based on the multi-objective gray Wolf optimization algorithm to obtain the final sentiment analysis results. The experimental results show that this model has high accuracy and high stability for different data sets.
- (4)
- The model proposed in this paper provides a meaningful reference for the sentiment analysis of online course evaluation. The ensemble deep learning model proposed in this paper is a new framework for text emotion recognition. In addition, compared with the models proposed by 10 other researchers, the proposed ensemble deep learning model adopted in this paper can achieve the optimal recognition accuracy.
3. Methodology
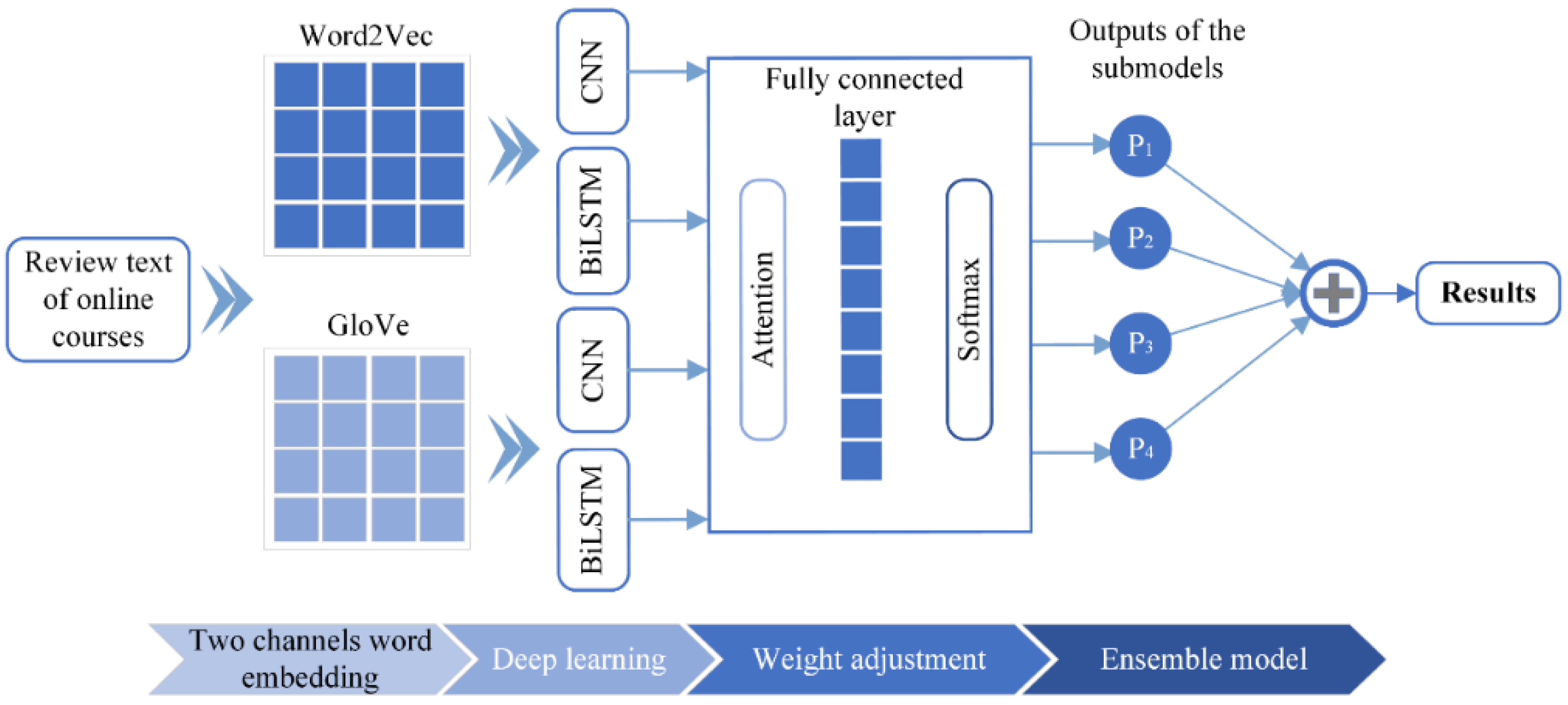
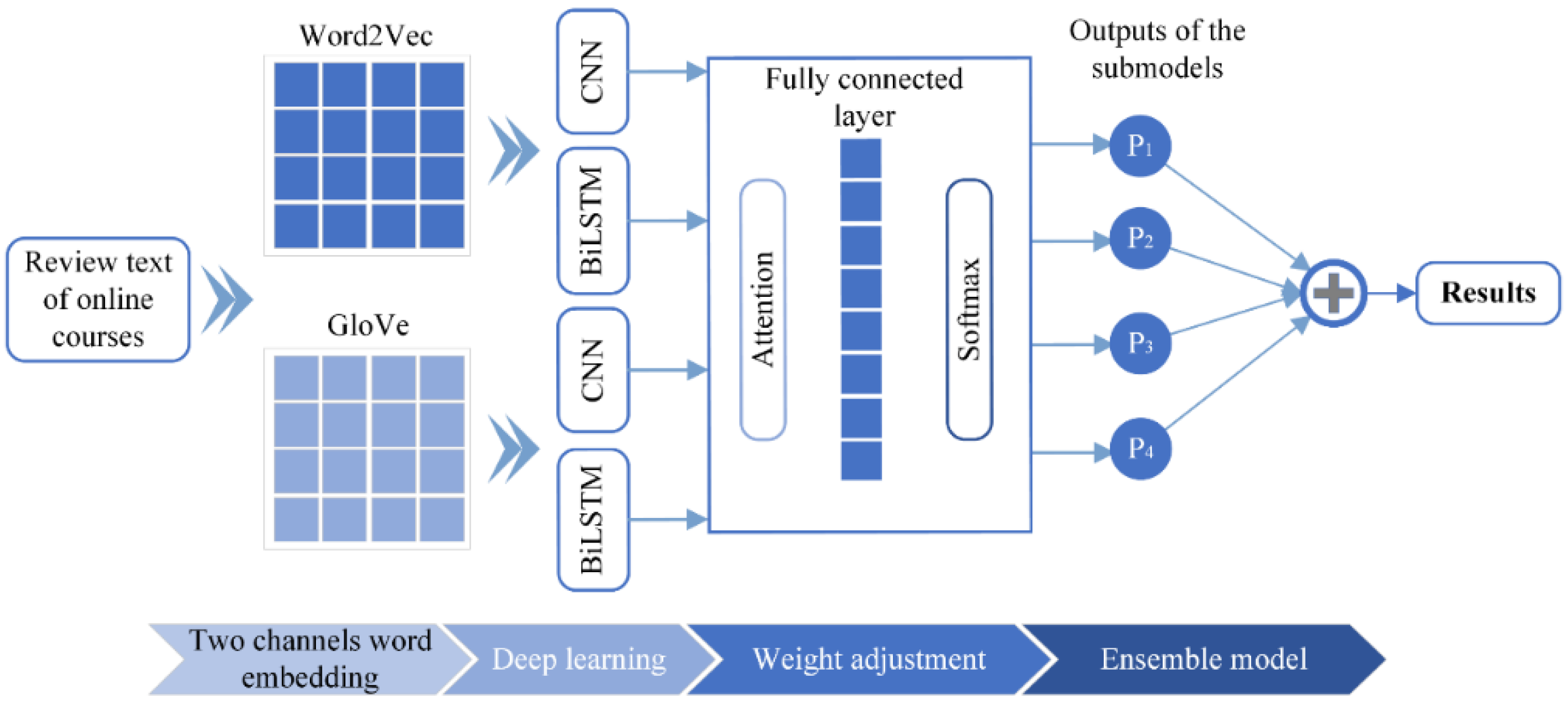
3.1. Model Framework
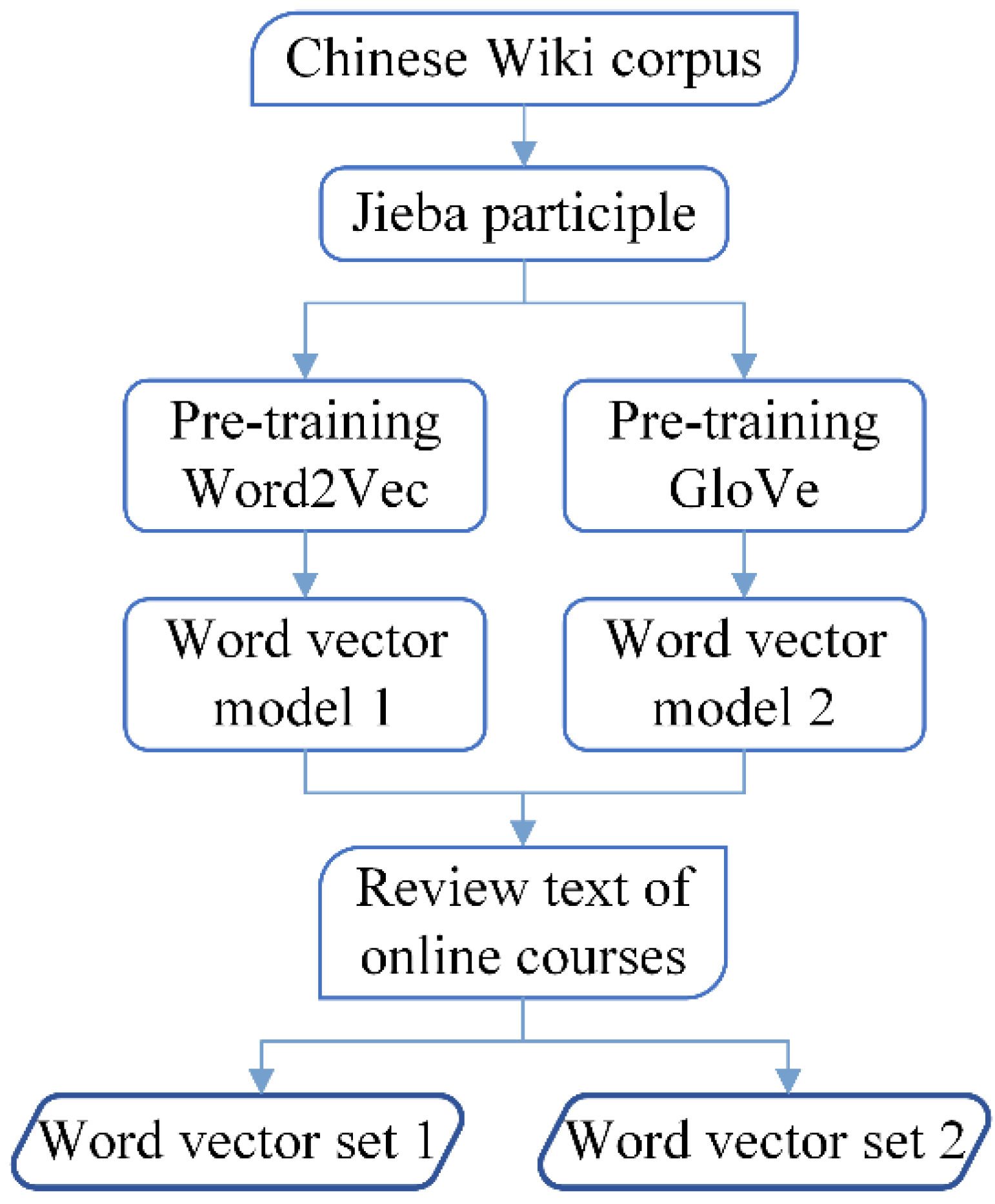
3.2. Two Channels of Word Vector Embedding
3.3. Deep Networks
3.3.1. Convolutional Neural Network
3.3.2. Bidirectional LSTM
3.3.3. Attention Layer
3.3.4. Multi-Objective Gray Wolf Optimization (WOGWO)
- Step 1:
- Initialize parameters, including the number of gray wolves, maximum iteration, search scope, and external archive parameters.
- Step 2:
- Initialize the gray wolves. Firstly, gray wolves were randomly generated, and the constraint conditions were checked. Repeat the above steps until sufficient qualified personnel is produced. Finally, the objective function value is calculated, the non-dominant individual is determined, and the file is updated.
- Step 3:
- α, β, δ wolves are selected from the archives according to the roulette method, and the remaining wolves are updated according to the positions of α, β, δ wolves to check whether the newly generated wolves meet the constraints. This process is repeated until a sufficient number of qualified gray wolves are produced.
- Step 4:
- Calculate the objective function, determine the non-dominant gray Wolf, and update.
- Step 5:
- Repeat Steps 3 and 4 until the end condition is met.
- Step 6:
- Output the location of the gray wolves in the external archive, the Pareto solution set.
4. Results and Discussion
4.1. Data Description and Preprocessing
4.2. Evaluation Metrics
4.3. Comparison Experiments and Results Analysis
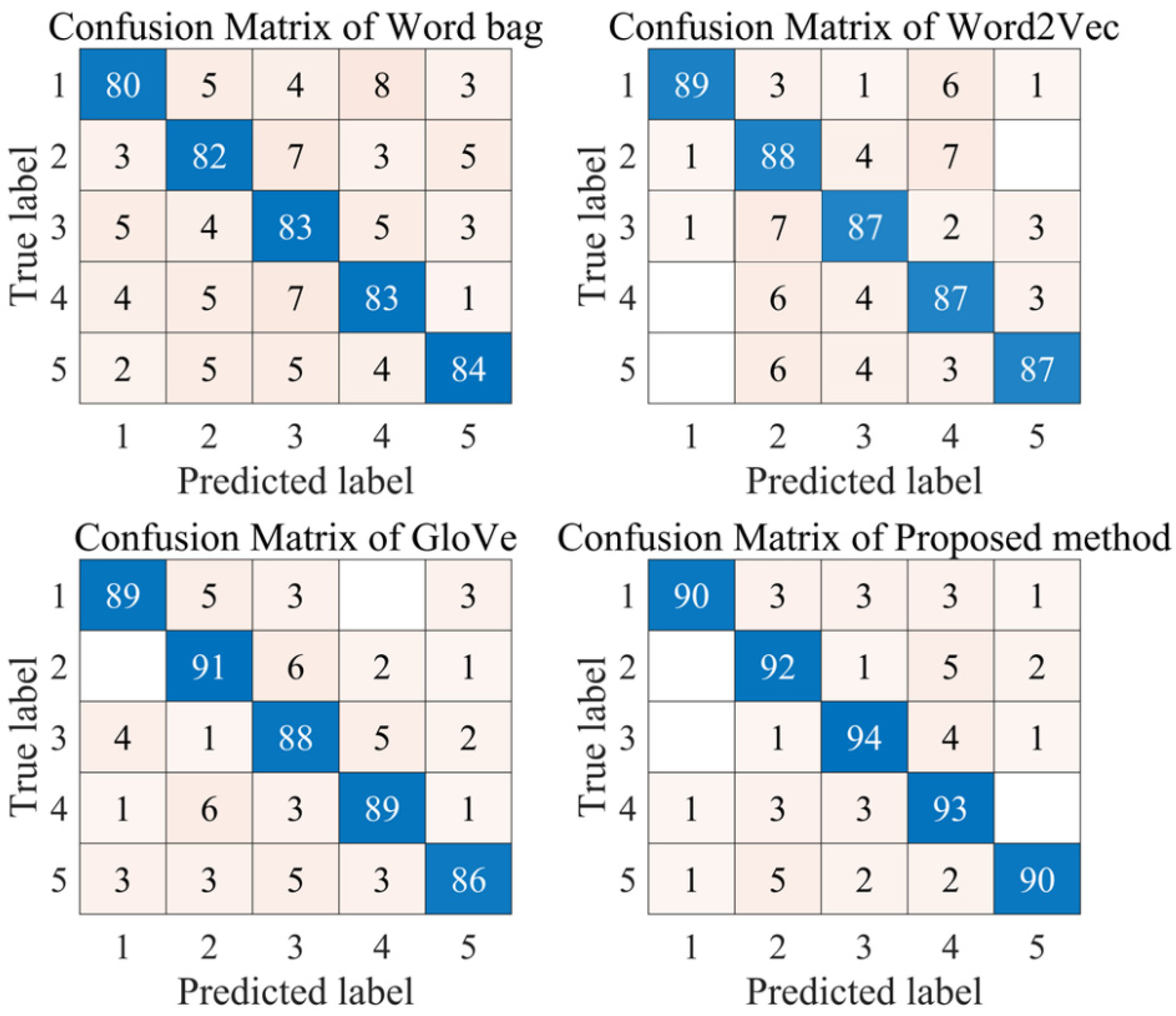
4.3.1. Comparison of Different Word Embedding Models
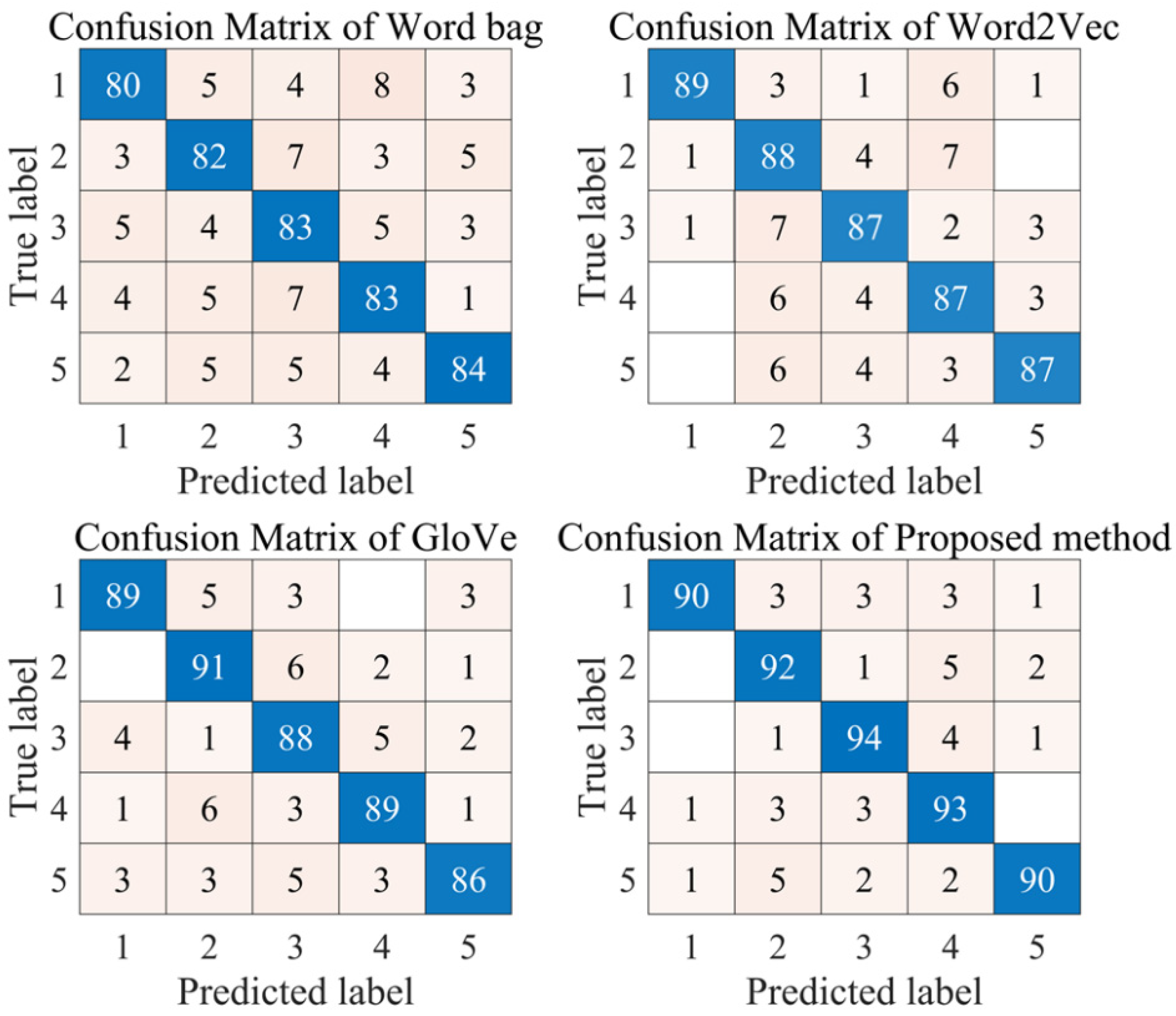
- (1)
- Compared with the word embedding modeling algorithm, the traditional word bag model achieves the worst classification result. This fully shows that the word embedding model can effectively extract the depth feature information from the original text data, which effectively optimizes the input of the subsequent classifier of the model. Therefore, the word embedding model has excellent application value in the field of emotion recognition.
- (2)
- Compared with the classical Word2Vec and GloVe models, the two-channel word embedding model adopted in this paper has a more excellent classification effect. This fully proves that the proposed model has excellent application value in the field of emotion recognition modeling. Two-channel word embedding modeling extracts word vectors from two different angles and transmits the extracted feature information to the classifier. More feature data lay a foundation for further classification.
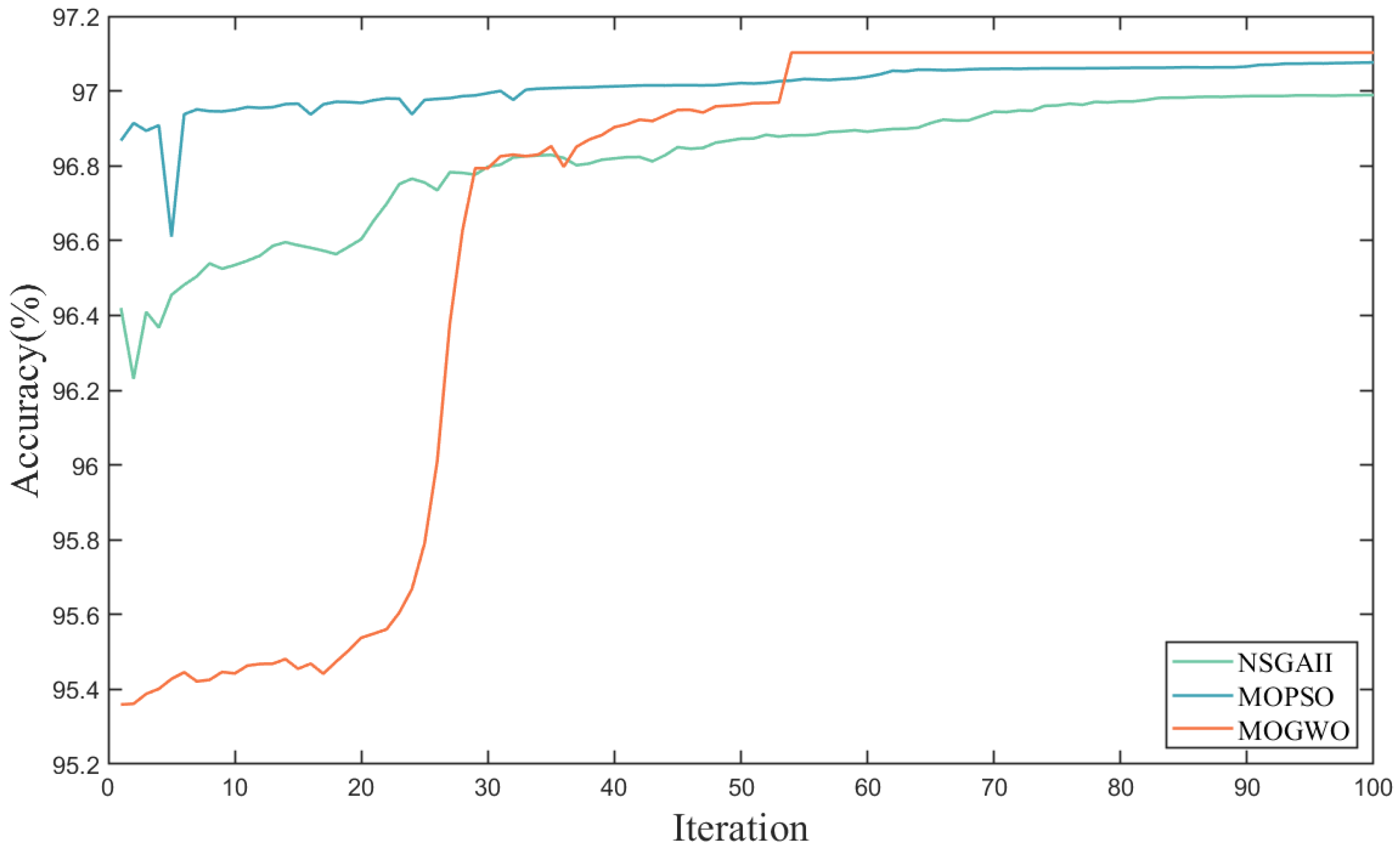
4.3.2. Comparison of Various Ensemble Models
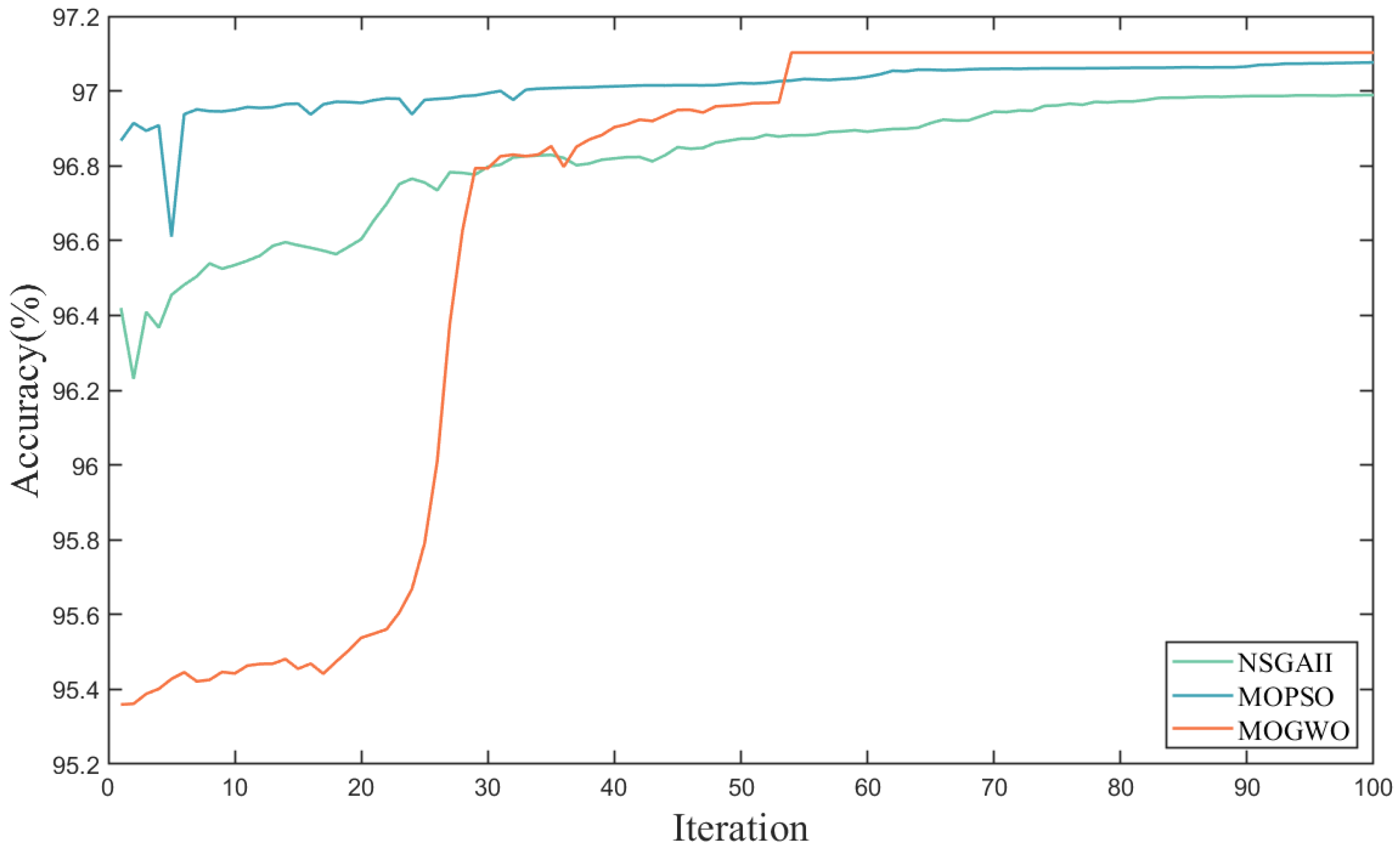
- (1)
- The ensemble learning model can effectively optimize the classification accuracy of a single model. This fully proves that ensemble learning is an effective method to improve the comprehensive recognition ability and generalization ability of models. The possible reason is that for different data, ensemble learning can dynamically optimize the weight according to the characteristics of different classifiers to establish the most suitable model for different data.
- (2)
- Compared with the traditional MOPSO algorithm and NSGAII algorithm, the MOGWO algorithm can achieve better results. This proves that the MOGWO algorithm has excellent weight optimization and decision-making ability in the field of integrated learning. The possible reason is that compared with the MOPSO algorithm and NSGAII algorithm, the MOGWO algorithm can obtain excellent optimization results with fewer parameters, which improves the overall convergence efficiency and global optimization ability of the model.
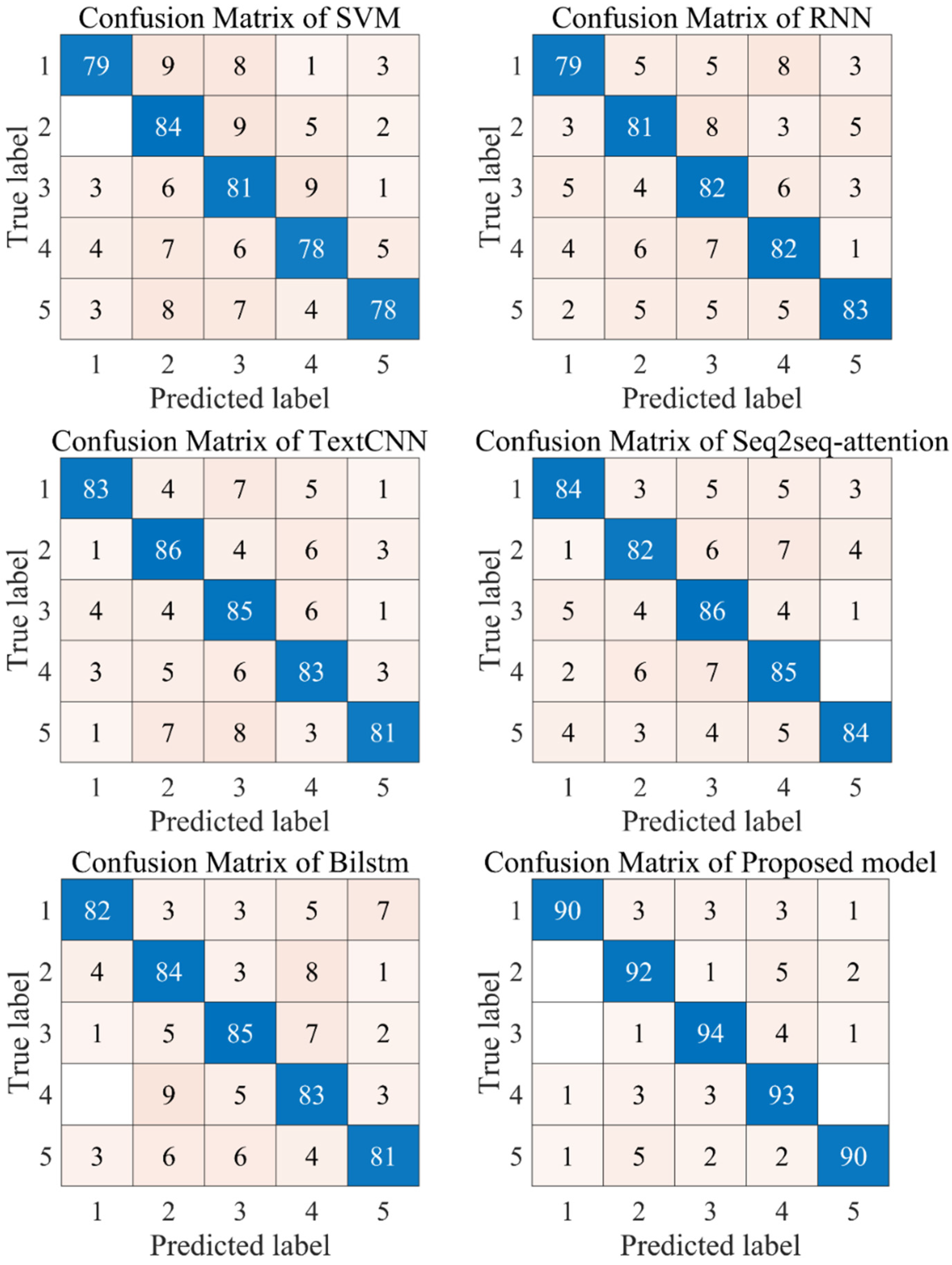
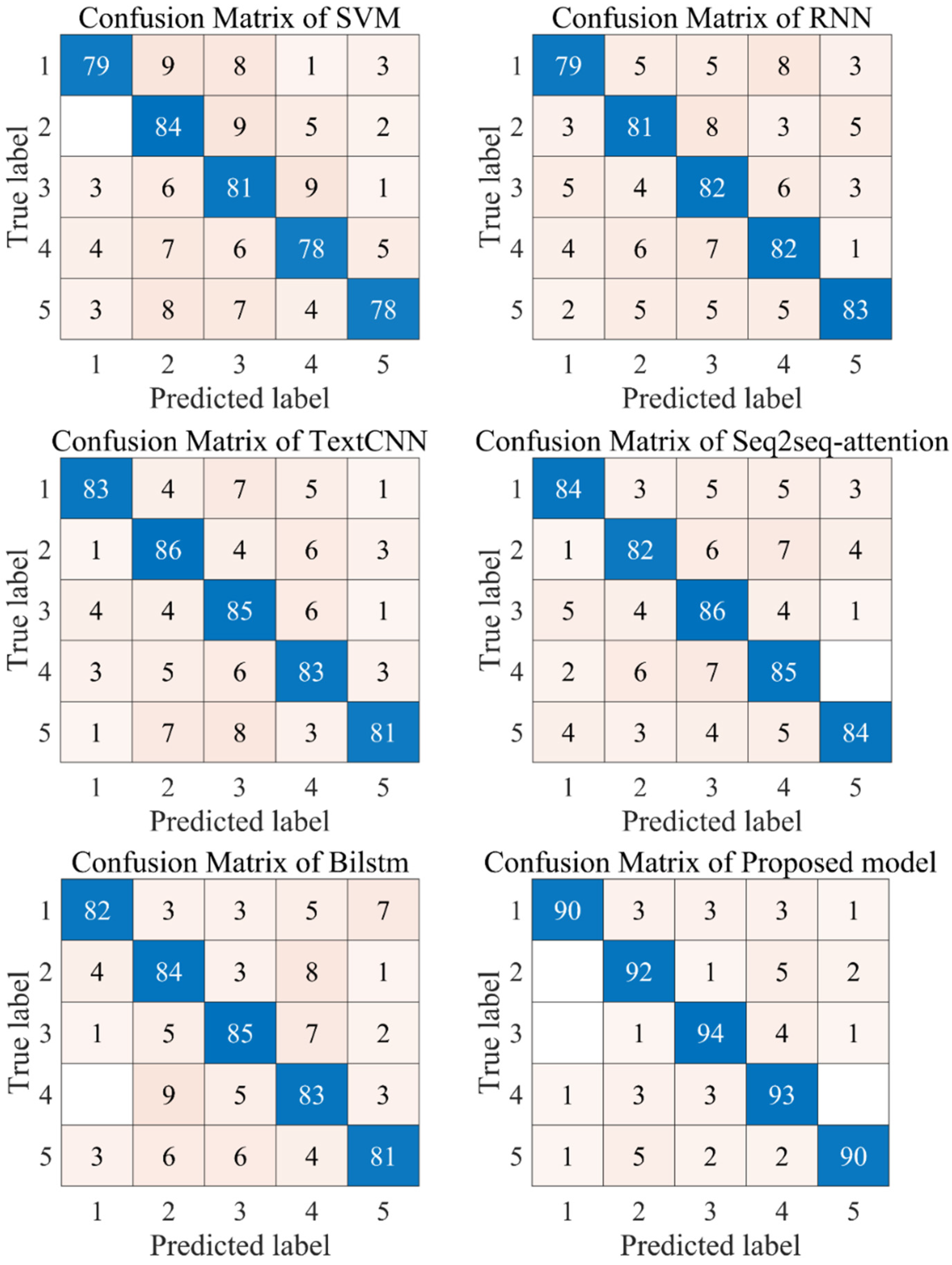
4.3.3. Comparison of Other Existing Models
- (1)
- Compared with traditional machine learning models, other deep learning models can achieve more excellent classification results. This fully proves that the deep learning algorithm has an excellent performance in the field of text emotion recognition. The possible reason is that the deep learning model effectively extracts the features of the original text through the multi-layer neural network structure and achieves more excellent results.
- (2)
- Compared with the traditional Bilstm neural network, the SEq2SEq_attention algorithm can obtain more accurate recognition results. This effectively proves that the attention mechanism effectively optimizes the performance of the neural network. The possible reason is that the attention mechanism can extract the deep correlation between the word vector data more deeply, which effectively improves the overall analysis and modeling ability of the model and achieves better recognition results.
- (3)
- The ensemble method proposed in this paper can achieve the best recognition results, which fully proves that the model proposed in this paper has excellent classification performance. The ensemble model adopted in this paper fully combines the advantages of each component. On the one hand, the feature representation of the original word vector is extracted by using the Word2Vec and GloVe word embedding models trained in this model, which effectively reduces the sparsity of the data. On the other hand, convolutional neural network and long and short-term memory networks were used for feature training, respectively, and four submodels were obtained by combining the attention mechanism. Finally, the integrated learning model based on a multi-objective gray Wolf optimizer can effectively make decisions on the weight of each sub-model and obtain the final emotion analysis results. Therefore, the model adopted in this paper can achieve excellent results in the field of emotion recognition.
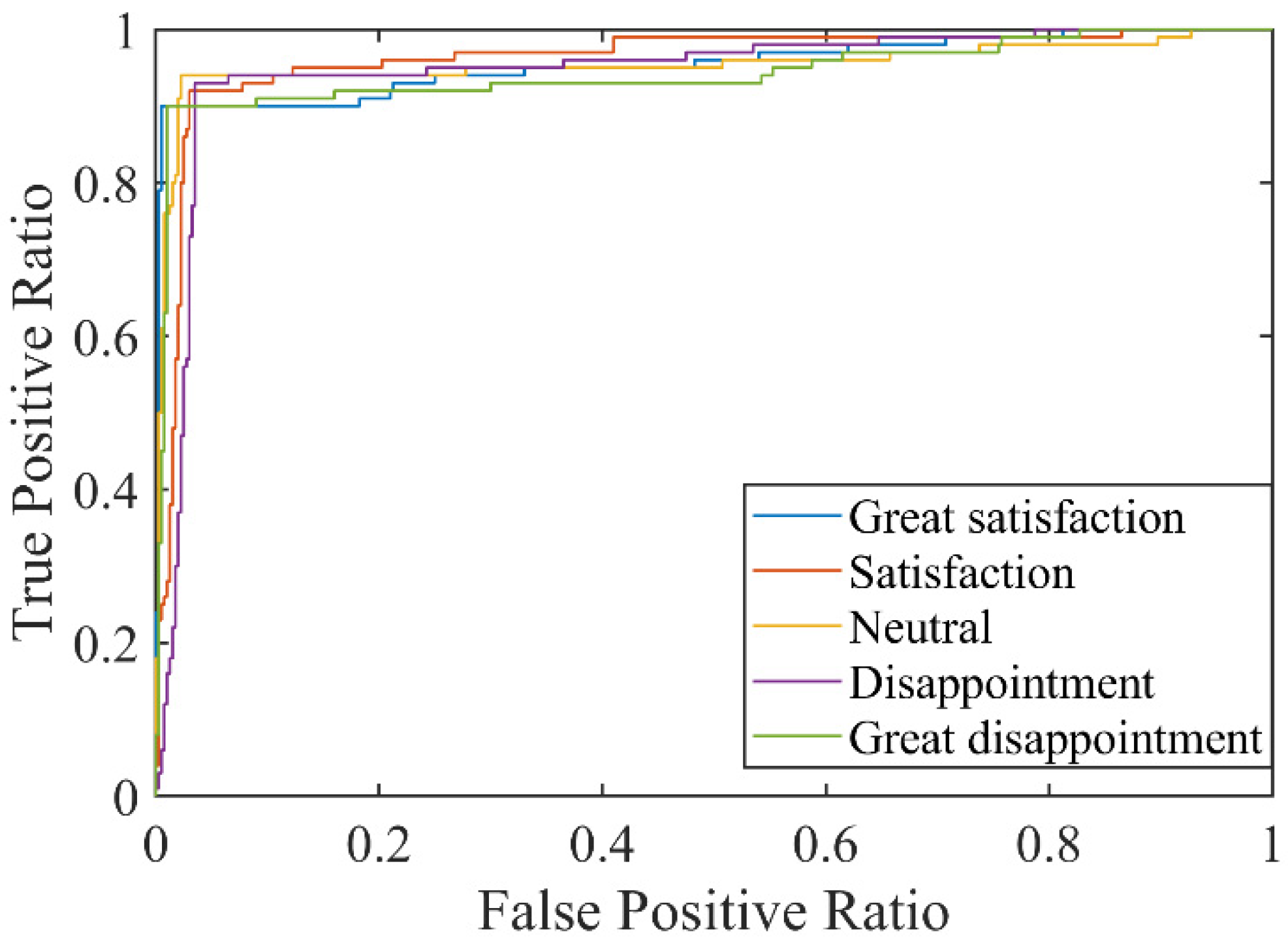
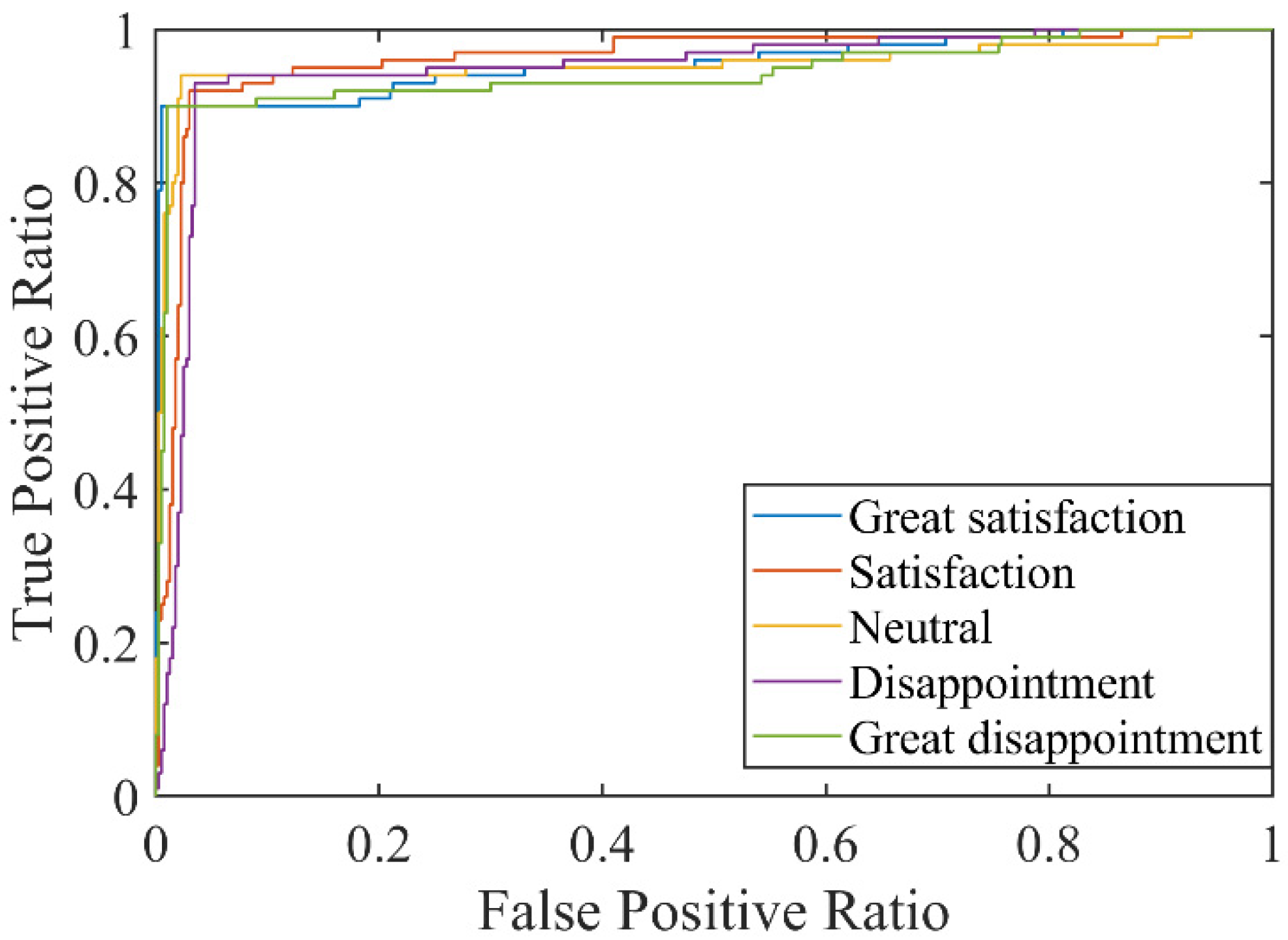
- (4)
- Based on the results of AUC and ROC, it can be seen that the model proposed in this paper can obtain relatively accurate classification results for different emotion categories. In addition, the average AUC values for all classes of the model are satisfactory. Therefore, the model proposed in this paper has excellent emotional recognition ability and can stably identify different emotional categories.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jin, H.; Zhang, M.; He, Q.; Gu, J. Over 200 million students being taught online in China during COVID-19: Will online teaching become the routine model in medical education? Asian J. Surg. 2021, 44, 672. [Google Scholar] [CrossRef]
- Han, Z.-M.; Huang, C.-Q.; Yu, J.-H.; Tsai, C.-C. Identifying patterns of epistemic emotions with respect to interactions in massive online open courses using deep learning and social network analysis. Comput. Hum. Behav. 2021, 122, 106843. [Google Scholar] [CrossRef]
- Dong, C.; Cao, S.; Li, H. Young children’s online learning during COVID-19 pandemic: Chinese parents’ beliefs and attitudes. Child. Youth Serv. Rev. 2020, 118, 105440. [Google Scholar] [CrossRef] [PubMed]
- Cheng, P.; Ding, R. The effect of online review exercises on student course engagement and learning performance: A case study of an introductory financial accounting course at an international joint venture university. J. Account. Educ. 2021, 54, 100699. [Google Scholar] [CrossRef]
- Zhang, Q.; He, Y.-J.; Zhu, Y.-H.; Dai, M.-C.; Pan, M.-M.; Wu, J.-Q.; Zhang, X.; Gu, Y.-E.; Wang, F.-F.; Xu, X.-R.; et al. The evaluation of online course of Traditional Chinese Medicine for Medical Bachelor, Bachelor of Surgery international students during the COVID-19 epidemic period. Integr. Med. Res. 2020, 9, 100449. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Xu, S.; Wu, H.; Bie, R. Sentiment Analysis of Weibo Comment Texts Based on Extended Vocabulary and Convolutional Neural Network. Procedia Comput. Sci. 2019, 147, 361–368. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Wang, Y.; Liao, T. Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Gener. Comput. Syst. 2018, 81, 395–403. [Google Scholar] [CrossRef]
- Aljuaid, H.; Iftikhar, R.; Ahmad, S.; Asif, M.; Tanvir Afzal, M. Important citation identification using sentiment analysis of in-text citations. Telemat. Inform. 2021, 56, 101492. [Google Scholar] [CrossRef]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A.; Setiadi, D.R.I.M. Review of automatic text summarization techniques & methods. J. King Saud Univ.—Comput. Inf. Sci. 2020, in press. [Google Scholar] [CrossRef]
- Ghulam, H.; Zeng, F.; Li, W.; Xiao, Y. Deep Learning-Based Sentiment Analysis for Roman Urdu Text. Procedia Comput. Sci. 2019, 147, 131–135. [Google Scholar] [CrossRef]
- Do, H.H.; Prasad, P.W.C.; Maag, A.; Alsadoon, A. Deep Learning for Aspect-Based Sentiment Analysis: A Comparative Review. Expert Syst. Appl. 2019, 118, 272–299. [Google Scholar] [CrossRef]
- Kumhar, S.H.; Kirmani, M.M.; Sheetlani, J.; Hassan, M. Word Embedding Generation for Urdu Language using Word2vec model. Mater. Today Proc. 2021, in press. [Google Scholar] [CrossRef]
- Liu, R.; Sisman, B.; Lin, Y.; Li, H. FastTalker: A neural text-to-speech architecture with shallow and group autoregression. Neural Netw. 2021, 141, 306–314. [Google Scholar] [CrossRef]
- Sakketou, F.; Ampazis, N. A constrained optimization algorithm for learning GloVe embeddings with semantic lexicons. Knowl. Based Syst. 2020, 195, 105628. [Google Scholar] [CrossRef]
- Sharma, A.K.; Chaurasia, S.; Srivastava, D.K. Sentimental Short Sentences Classification by Using CNN Deep Learning Model with Fine Tuned Word2Vec. Procedia Comput. Sci. 2020, 167, 1139–1147. [Google Scholar] [CrossRef]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Corrado, G.; Kai, C.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Naderalvojoud, B.; Sezer, E.A. Sentiment aware word embeddings using refinement and senti-contextualized learning approach. Neurocomputing 2020, 405, 149–160. [Google Scholar] [CrossRef]
- Onan, A. Two-Stage Topic Extraction Model for Bibliometric Data Analysis Based on Word Embeddings and Clustering. IEEE Access 2019, 7, 145614–145633. [Google Scholar] [CrossRef]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment Analysis Using Word2vec And Long Short-Term Memory (LSTM) For Indonesian Hotel Reviews. Procedia Comput. Sci. 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Cao, X.; Li, J.; Wang, R.; Wang, Y.; Niu, Q.; Shi, J. Calibrating GloVe model on the principle of Zipf’s law. Pattern Recognit. Lett. 2019, 125, 715–720. [Google Scholar] [CrossRef]
- Kamkarhaghighi, M.; Makrehchi, M. Content Tree Word Embedding for document representation. Expert Syst. Appl. 2017, 90, 241–249. [Google Scholar] [CrossRef]
- Li, S.; Pan, R.; Luo, H.; Liu, X.; Zhao, G. Adaptive cross-contextual word embedding for word polysemy with unsupervised topic modeling. Knowl. Based Syst. 2021, 218, 106827. [Google Scholar] [CrossRef]
- Nozza, D.; Manchanda, P.; Fersini, E.; Palmonari, M.; Messina, E. LearningToAdapt with word embeddings: Domain adaptation of Named Entity Recognition systems. Inf. Process. Manag. 2021, 58, 102537. [Google Scholar] [CrossRef]
- Khan, J.; Lee, Y.K. LeSSA: A Unified Framework based on Lexicons and Semi-Supervised Learning Approaches for Textual Sentiment Classification. Appl. Sci. 2019, 9, 5562. [Google Scholar] [CrossRef] [Green Version]
- Wunderlich, F.; Memmert, D. Innovative Approaches in Sports Science-Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication. Appl. Sci. 2020, 10, 431. [Google Scholar] [CrossRef] [Green Version]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef] [Green Version]
- Chintalapudi, N.; Battineni, G.; Canio, M.D.; Sagaro, G.G.; Amenta, F. Text mining with sentiment analysis on seafarers’ medical documents. Int. J. Inf. Manag. Data Insights 2021, 1, 100005. [Google Scholar] [CrossRef]
- Song, C.; Wang, X.-K.; Cheng, P.-F.; Wang, J.-Q.; Li, L. SACPC: A framework based on probabilistic linguistic terms for short text sentiment analysis. Knowl. Based Syst. 2020, 194, 105572. [Google Scholar] [CrossRef]
- Jia, K. Chinese sentiment classification based on Word2vec and vector arithmetic in human–robot conversation. Comput. Electr. Eng. 2021, 95, 107423. [Google Scholar] [CrossRef]
- Tran, T.K.; Phan, T.T. Deep Learning Application to Ensemble Learning-The Simple, but Effective, Approach to Sentiment Classifying. Appl. Sci. 2019, 9, 2760. [Google Scholar] [CrossRef] [Green Version]
- Han, K.X.; Chien, W.; Chiu, C.C.; Cheng, Y.T. Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet. Appl. Sci. 2020, 10, 1125. [Google Scholar] [CrossRef] [Green Version]
- Nassif, A.B.; Elnagar, A.; Shahin, I.; Henno, S. Deep learning for Arabic subjective sentiment analysis: Challenges and research opportunities. Appl. Soft Comput. 2021, 98, 106836. [Google Scholar] [CrossRef]
- Liao, W.; Zeng, B.; Liu, J.; Wei, P.; Cheng, X.; Zhang, W. Multi-level graph neural network for text sentiment analysis. Comput. Electr. Eng. 2021, 92, 107096. [Google Scholar] [CrossRef]
- Ullah, M.A.; Marium, S.M.; Begum, S.A.; Dipa, N.S. An algorithm and method for sentiment analysis using the text and emoticon. ICT Express 2020, 6, 357–360. [Google Scholar] [CrossRef]
- Shi, L.; Jianping, C.; Jie, X. Prospecting Information Extraction by Text Mining Based on Convolutional Neural Networks–A Case Study of the Lala Copper Deposit, China. IEEE Access 2018, 6, 52286–52297. [Google Scholar] [CrossRef]
- Dong, S.; Yu, C.; Yan, G.; Zhu, J.; Hu, H. A Novel ensemble reinforcement learning gated recursive network for traffic speed forecasting. In Proceedings of the 2021 Workshop on Algorithm and Big Data, Fuzhou, China, 12–14 March 2021; pp. 55–60. [Google Scholar]
- Xia, Y.; Chen, K.; Yang, Y. Multi-label classification with weighted classifier selection and stacked ensemble. Inf. Sci. 2021, 557, 421–442. [Google Scholar] [CrossRef]
- Nnabuife, S.G.; Kuang, B.; Whidborne, J.F.; Rana, Z. Non-intrusive classification of gas-liquid flow regimes in an S-shaped pipeline riser using a Doppler ultrasonic sensor and deep neural networks. Chem. Eng. J. 2021, 403, 126401. [Google Scholar] [CrossRef]
- Minakova, S.; Stefanov, T. Buffer sizes reduction for memory-efficient CNN inference on mobile and embedded devices. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD 2020), Kranj, Slovenia, 26–28 August 2020; pp. 133–140. [Google Scholar]
- Yan, G.; Yu, C.; Bai, Y. Wind Turbine Bearing Temperature Forecasting Using a New Data-Driven Ensemble Approach. Machines 2021, 9, 248. [Google Scholar] [CrossRef]
- Zhao, J.F.; Mao, X.; Chen, L.J. Learning deep features to recognise speech emotion using merged deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Cai, H.J.; Chen, T. Multi-dimension CNN for hyperspectral image classificaton. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1275–1278. [Google Scholar]
- Liu, X.; Qin, M.; He, Y.; Mi, X.; Yu, C. A new multi-data-driven spatiotemporal PM2. 5 forecasting model based on an ensemble graph reinforcement learning convolutional network. Atmos. Pollut. Res. 2021, 12, 101197. [Google Scholar] [CrossRef]
- Yang, G.; Xu, H.Z. A Residual BiLSTM Model for Named Entity Recognition. IEEE Access 2020, 8, 227710–227718. [Google Scholar] [CrossRef]
- Liao, F.; Ma, L.L.; Yang, D.J. Research on Construction Method of Knowledge Graph of US Military Equipment Based on BiLSTM model. In Proceedings of the 2019 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Shenzhen, China, 9–11 May 2019; pp. 146–150. [Google Scholar]
- Ma, W.; Yu, H.Z.; Zhao, K.; Zhao, D.S.; Yang, J.; Ma, J. Tibetan location name recognition based on BiLSTM-CRF model. In Proceedings of the 2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CYBERC), Guilin, China, 17–19 October 2019; pp. 412–416. [Google Scholar]
- Zhang, P.F.; Li, F.H.; Du, L.D.; Zhao, R.J.; Chen, X.X.; Yang, T.; Fang, Z. Psychological Stress Detection According to ECG Using a Deep Learning Model with Attention Mechanism. Appl. Sci. 2021, 11, 2848. [Google Scholar] [CrossRef]
- Chen, W.J.; Li, J.L. Forecasting Teleconsultation Demand Using an Ensemble CNN Attention-Based BILSTM Model with Additional Variables. Healthcare 2021, 9, 992. [Google Scholar] [CrossRef] [PubMed]
- Du, J.; Cheng, Y.Y.; Zhou, Q.A.; Zhang, J.M.; Zhang, X.Y.; Li, G.; IOP. Power load forecasting using BiLSTM-attention. In Proceedings of the 2019 5th International Conference on Environmental Science and Material Application, Xi’an, China, 15–16 December 2019. [Google Scholar]
- Zapotecas-Martínez, S.; García-Nájera, A.; López-Jaimes, A. Multi-objective grey wolf optimizer based on decomposition. Expert Syst. Appl. 2019, 120, 357–371. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. Enhanced leadership-inspired grey wolf optimizer for global optimization problems. Eng. Comput. 2020, 36, 1777–1800. [Google Scholar] [CrossRef]
- Ling, O.Y.; Theng, L.B.; Chai, A.; McCarthy, C. A model for automatic recognition of vertical texts in natural scene images. In Proceedings of the 2018 8th IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2018), Penang, Malaysia, 23–25 November 2018; pp. 170–175. [Google Scholar]
- Liu, M.F.; Xie, Z.C.; Huang, Y.X.; Jin, L.W.; Zhou, W.Y. Distilling GRU with data augmentation for unconstrained handwritten text recognition. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 56–61. [Google Scholar]
- Nguyen, H.T.; Nguyen, C.T.; Nakagawa, M. ICFHR 2018-competition on Vietnamese online handwritten text recognition using HANDS-VNOnDB (VOHTR2018). In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 494–499. [Google Scholar]
- Qin, Y.; Zhang, Z. Summary of scene text detection and recognition. In Proceedings of the 15th IEEE Conference on Industrial Electronics and Applications (ICIEA 2020), Kristiansand, Norway, 9–13 November 2020; pp. 85–89. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Number | Mood | Number of Samples |
|---|---|---|
| 1 | Great satisfaction | 4020 |
| 2 | Satisfaction | 4320 |
| 3 | Neutral | 4670 |
| 4 | Disappointment | 3830 |
| 5 | Great disappointment | 3400 |
| True Label | Predicted Label | |
|---|---|---|
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| Model | Evaluation Metrics | Mood States | |||||
|---|---|---|---|---|---|---|---|
| Great Satisfaction | Satisfaction | Neutral | Disappointment | Great Disappointment | Average | ||
| The proposed model | Accuracy | 0.9760 | 0.9600 | 0.9700 | 0.9580 | 0.9720 | 0.9672 |
| Precision | 0.9783 | 0.8846 | 0.9126 | 0.8692 | 0.9574 | 0.9204 | |
| Recall | 0.9000 | 0.9200 | 0.9400 | 0.9300 | 0.9000 | 0.9180 | |
| F1 | 0.9375 | 0.9020 | 0.9261 | 0.8986 | 0.9278 | 0.9184 | |
| Word2Vec | Accuracy | 0.9740 | 0.9320 | 0.9480 | 0.9380 | 0.9600 | 0.9504 |
| Precision | 0.9780 | 0.8000 | 0.8700 | 0.8286 | 0.9255 | 0.8804 | |
| Recall | 0.8900 | 0.8800 | 0.8700 | 0.8700 | 0.8700 | 0.8760 | |
| F1 | 0.9319 | 0.8381 | 0.8700 | 0.8488 | 0.8969 | 0.8771 | |
| GloVe | Accuracy | 0.9620 | 0.9520 | 0.9420 | 0.9580 | 0.9580 | 0.9544 |
| Precision | 0.9175 | 0.8585 | 0.8381 | 0.8990 | 0.9247 | 0.8876 | |
| Recall | 0.8900 | 0.9100 | 0.8800 | 0.8900 | 0.8600 | 0.8860 | |
| F1 | 0.9036 | 0.8835 | 0.8585 | 0.8945 | 0.8912 | 0.8862 | |
| Word bag model | Accuracy | 0.9320 | 0.9260 | 0.9200 | 0.9260 | 0.9440 | 0.9296 |
| Precision | 0.8511 | 0.8119 | 0.7830 | 0.8058 | 0.8750 | 0.8254 | |
| Recall | 0.8000 | 0.8200 | 0.8300 | 0.8300 | 0.8400 | 0.8240 | |
| F1 | 0.8247 | 0.8159 | 0.8058 | 0.8177 | 0.8571 | 0.8243 | |
| Model | Evaluation Metrics | Mood States | |||||
|---|---|---|---|---|---|---|---|
| Great Satisfaction | Satisfaction | Neutral | Disappointment | Great Disappointment | Average | ||
| MOGWO | Accuracy | 0.9760 | 0.9600 | 0.9700 | 0.9580 | 0.9720 | 0.9672 |
| Precision | 0.9783 | 0.8846 | 0.9126 | 0.8692 | 0.9574 | 0.9204 | |
| Recall | 0.9000 | 0.9200 | 0.9400 | 0.9300 | 0.9000 | 0.9180 | |
| F1 | 0.9375 | 0.9020 | 0.9261 | 0.8986 | 0.9278 | 0.9184 | |
| MOPSO | Accuracy | 0.9600 | 0.9520 | 0.9460 | 0.9360 | 0.9660 | 0.9520 |
| Precision | 0.9348 | 0.8800 | 0.8411 | 0.8091 | 0.9560 | 0.8842 | |
| Recall | 0.8600 | 0.8800 | 0.9000 | 0.8900 | 0.8700 | 0.8800 | |
| F1 | 0.8958 | 0.8800 | 0.8696 | 0.8476 | 0.9110 | 0.8808 | |
| NSGAII | Accuracy | 0.9600 | 0.9420 | 0.9500 | 0.9380 | 0.9620 | 0.9504 |
| Precision | 0.9167 | 0.8318 | 0.8713 | 0.8350 | 0.9355 | 0.8780 | |
| Recall | 0.8800 | 0.8900 | 0.8800 | 0.8600 | 0.8700 | 0.8760 | |
| F1 | 0.8980 | 0.8599 | 0.8756 | 0.8473 | 0.9016 | 0.8765 | |
| Emotional Categories | Great Satisfaction | Satisfaction | Neutral | Disappointment | Great Disappointment | Average |
|---|---|---|---|---|---|---|
| AUC values | 0.9546 | 0.9620 | 0.9541 | 0.9477 | 0.9429 | 0.9523 |
| Model | Evaluation Metrics | Mood States | |||||
|---|---|---|---|---|---|---|---|
| Great Satisfaction | Satisfaction | Neutral | Disappointment | Great Disappointment | Average | ||
| The proposed model | Accuracy | 0.9760 | 0.9600 | 0.9700 | 0.9580 | 0.9720 | 0.9672 |
| Precision | 0.9783 | 0.8846 | 0.9126 | 0.8692 | 0.9574 | 0.9204 | |
| Recall | 0.9000 | 0.9200 | 0.9400 | 0.9300 | 0.9000 | 0.9180 | |
| F1 | 0.9375 | 0.9020 | 0.9261 | 0.8986 | 0.9278 | 0.9184 | |
| Seq2seq-attention | Accuracy | 0.9440 | 0.9320 | 0.9280 | 0.9280 | 0.9520 | 0.9368 |
| Precision | 0.8750 | 0.8367 | 0.7963 | 0.8019 | 0.9130 | 0.8446 | |
| Recall | 0.8400 | 0.8200 | 0.8600 | 0.8500 | 0.8400 | 0.8420 | |
| F1 | 0.8571 | 0.8283 | 0.8269 | 0.8252 | 0.8750 | 0.8425 | |
| TextCNN | Accuracy | 0.9480 | 0.9320 | 0.9200 | 0.9260 | 0.9460 | 0.9344 |
| Precision | 0.9022 | 0.8113 | 0.7727 | 0.8058 | 0.9101 | 0.8404 | |
| Recall | 0.8300 | 0.8600 | 0.8500 | 0.8300 | 0.8100 | 0.8360 | |
| F1 | 0.8646 | 0.8350 | 0.8095 | 0.8177 | 0.8571 | 0.8368 | |
| Bilstm | Accuracy | 0.9480 | 0.9220 | 0.9360 | 0.9180 | 0.9360 | 0.9320 |
| Precision | 0.9111 | 0.7850 | 0.8333 | 0.7757 | 0.8617 | 0.8334 | |
| Recall | 0.8200 | 0.8400 | 0.8500 | 0.8300 | 0.8100 | 0.8300 | |
| F1 | 0.8632 | 0.8116 | 0.8416 | 0.8019 | 0.8351 | 0.8307 | |
| SVM | Accuracy | 0.9380 | 0.9080 | 0.9020 | 0.9180 | 0.9340 | 0.9200 |
| Precision | 0.8876 | 0.7368 | 0.7297 | 0.8041 | 0.8764 | 0.8069 | |
| Recall | 0.7900 | 0.8400 | 0.8100 | 0.7800 | 0.7800 | 0.8000 | |
| F1 | 0.8360 | 0.7850 | 0.7678 | 0.7919 | 0.8254 | 0.8012 | |
| RNN | Accuracy | 0.9300 | 0.9220 | 0.9140 | 0.9200 | 0.9420 | 0.9256 |
| Precision | 0.8495 | 0.8020 | 0.7664 | 0.7885 | 0.8737 | 0.8160 | |
| Recall | 0.7900 | 0.8100 | 0.8200 | 0.8200 | 0.8300 | 0.8140 | |
| F1 | 0.8187 | 0.8060 | 0.7923 | 0.8039 | 0.8513 | 0.8144 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, X.; Yan, G.; Yu, C.; Mi, X.; Yu, C. Sentiment Analysis of Online Course Evaluation Based on a New Ensemble Deep Learning Mode: Evidence from Chinese. Appl. Sci. 2021, 11, 11313. https://doi.org/10.3390/app112311313
Pu X, Yan G, Yu C, Mi X, Yu C. Sentiment Analysis of Online Course Evaluation Based on a New Ensemble Deep Learning Mode: Evidence from Chinese. Applied Sciences. 2021; 11(23):11313. https://doi.org/10.3390/app112311313
Chicago/Turabian StylePu, Xiaomin, Guangxi Yan, Chengqing Yu, Xiwei Mi, and Chengming Yu. 2021. "Sentiment Analysis of Online Course Evaluation Based on a New Ensemble Deep Learning Mode: Evidence from Chinese" Applied Sciences 11, no. 23: 11313. https://doi.org/10.3390/app112311313
APA StylePu, X., Yan, G., Yu, C., Mi, X., & Yu, C. (2021). Sentiment Analysis of Online Course Evaluation Based on a New Ensemble Deep Learning Mode: Evidence from Chinese. Applied Sciences, 11(23), 11313. https://doi.org/10.3390/app112311313