
Methods for Mid-Term Forecasting of Crop Export and Production



Abstract
:1. Introduction
- -
- Variable character of agricultural trade flows.
- -
- Too many features influence trade flows and production. Using them all would lead to over-complex prediction models, which are not trainable with the dataset. Mid-term forecasting requires the use of complex models that consider many features and parameters from past observations, but the size of the training dataset is strictly limited [2]. Therefore, complex models can be easily over-fitted and, in some cases, provide incorrect results on unseen data [3].
- -
- Political decisions and economic sanctions strongly affect trade flows and production, but they can hardly ever be predicted using only statistic databases. Additional information such as news and social media messages should be considered.
- Can the textual features improve export and production forecasting?
- Which neural network architectures can integrate heterogeneous structured and textual features to provide accurate forecasting?
- Is there any training regularization to increase the forecasting reliability and reduce the overfitting?
2. Related Work
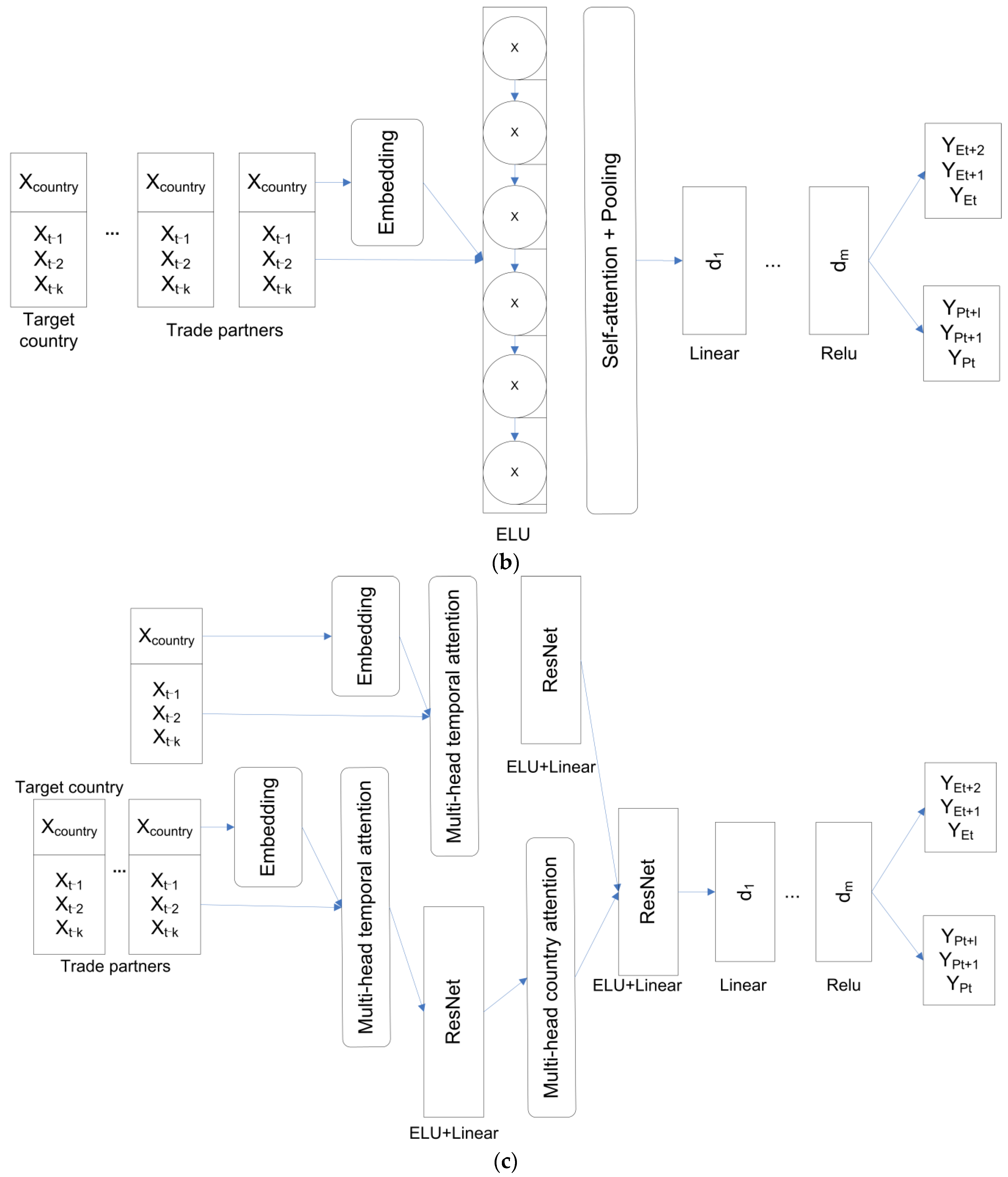
3. Materials and Methods
3.1. Dataset
- -
- -
- Fuel prices. They affect the cost of using agricultural machinery; therefore affect the production level and prices;
- -
- Macroeconomic indicators from International Monetary Fund [26] affect demand and consumption throughout the world;
- -
- Normalized difference vegetation index (NDVI) from UN FAO [27] affect the production level. It usually helps to reveal the areas where vegetation is stressed. The values are obtained from the METOP-AVHRR sensor. The use of the whole raw data array would lead to unacceptable growth of the prediction models; therefore we consider per-seasonal county-level average and extreme (max, min) values.
- -
- Topically-relevant messages from Twitter contain reports about deals in the international wheat market, climate anomalies, etc.
3.2. Modeling of Wheat Export
3.2.1. Regression Models
3.2.2. Stationary Term
3.2.3. Sentiment Analysis and Topic Models
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zurayk, R. Pandemic and food security. J. Agric. Food Syst. Commun. Develop. 2020, 9, 17–21. [Google Scholar]
- Li, X.; Petropoulos, F.; Kang, Y. Improving forecasting with sub-seasonal time series patterns. arXiv 2021, arXiv:2101.00827. [Google Scholar]
- Sánchez-Durán, R.; Luque, J.; Barbancho, J. Long-term demand forecasting in a scenario of energy transition. Energies 2019, 12, 3095. [Google Scholar] [CrossRef] [Green Version]
- Rundo, F.; Trenta, F.; di Stallo, A.L.; Battiato, S. Machine learning for quantitative finance applications: A survey. Appl. Sci. 2019, 9, 5574. [Google Scholar] [CrossRef] [Green Version]
- Bhojani, S.H.; Bhatt, N. Wheat crop yield prediction using new activation functions in the neural network. Neural Comput. Appl. 2020, 32, 17. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L.; Archontoulis, S.V. A cnn-rnn framework for crop yield prediction. Front. Plant Sci. 2020, 10, 1750. [Google Scholar] [CrossRef] [PubMed]
- Jiasheng, C.; Wang, J. Exploration of stock index change prediction model based on the combination of principal component analysis and artificial neural network. Soft Comput. 2020, 24, 7851–7860. [Google Scholar]
- Mor, R.; Bhardwaj, A. Demand forecasting of the short-lifecycle dairy products. In Understanding the Role of Business Analytics; Chahal, H., Jyoti, J., Wirtz, J., Eds.; Springer: Singapore, 2019; pp. 87–117. [Google Scholar]
- Pannakkong, W.; Huynh, V.; Sriboonchitta, S. ARIMA versus artificial neural network for Thailand’s cassava starch export forecasting. In Causal Inference in Econometrics; Springer: Cham, Switzerland, 2016; pp. 255–277. [Google Scholar]
- Ayankoya, K.; Calitz, A.P.; Greyling, J.H. Real-time grain commodities price predictions in South Africa: A big data and neural networks approach. Agrekon 2016, 55, 483–508. [Google Scholar] [CrossRef]
- Menezes, J.M.P., Jr.; Barreto, G.A. Long-term time series prediction with the NARX network: An empirical evaluation. Neurocomputing 2008, 71, 3335–3343. [Google Scholar] [CrossRef]
- Abraham, E.R.; Mendes dos Reis, J.G.; Vendrametto, O.; Oliveira Costa Neto, P.L.D.; Carlo Toloi, R.; Souza, A.E.D.; Oliveira Morais, M.D. Time series prediction with artificial neural networks: An analysis using Brazilian soybean production. Agriculture 2020, 10, 475. [Google Scholar] [CrossRef]
- Lee, W.K.; Tuan Resdi, T.A. Simultaneous hydrological prediction at multiple gauging stations using the NARX network for Kemaman catchment, Terengganu, Malaysia. Hydrol. Sci. J. 2016, 61, 2930–2945. [Google Scholar] [CrossRef] [Green Version]
- Guzman, S.M.; Paz, J.O.; Tagert, M.L.M.; Mercer, A.E. Evaluation of seasonally classified inputs for the prediction of daily groundwater levels: NARX networks vs support vector machines. Environ. Modeling Assess. 2019, 24, 223–234. [Google Scholar] [CrossRef]
- Haider, S.A.; Naqvi, S.R.; Akram, T.; Umar, G.U.; Shahzad, A.; Sial, M.R.; Khaliq, S.; Kamran, M. LSTM neural network based forecasting model for wheat production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Yu, J. Raw grain price forecasting with regression analysis. In Proceedings of the 2019 International Conference on Modeling, Simulation and Big Data Analysis (MSBDA 2019), Wuhan, China, 23 June 2019; Atlantis Press: Paris, France, 2019. [Google Scholar]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-level soybean yield prediction using deep CNN-LSTM model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guzman, S.M.; Paz, J.O.; Tagert, M.L.M. The use of NARX neural networks to forecast daily groundwater levels. Water Resour. Manag. 2017, 31, 1591–1603. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, Y. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. arXiv 2019, arXiv:1907.00235. [Google Scholar]
- Chen, K.; Chen, G.; Xu, D.; Zhang, L.; Huang, Y.; Knoll, A. NAST: Non-Autoregressive Spatial-Temporal Transformer for Time Series Forecasting. arXiv 2021, arXiv:2102.05624. [Google Scholar]
- Picasso, A.; Merello, S.; Ma, Y.; Oneto, L.; Cambria, E. Technical analysis and sentiment embeddings for market trend prediction. Expert Syst. Appl. 2019, 135, 60–70. [Google Scholar] [CrossRef]
- Cambria, E.; Hussain, A.; Havasi, C.; Eckl, C. Affectivespace: Blending common sense and affective knowledge to perform emotive reasoning. In Proceedings of the WOMSA CAEPIA, Seville, Spain, 9–13 November 2009; pp. 32–41. [Google Scholar]
- Food and Agriculture Organization of the United Nations. Available online: http://www.fao.org/faostat/en/ (accessed on 29 September 2021).
- UN Comtrade: International Trade Statistics. Available online: https://comtrade.un.org/data/ (accessed on 29 September 2021).
- International Monetary Foundation. Available online: http://www.imf.org/en/Data (accessed on 29 September 2021).
- Food and Agriculture Organization of the United Nations. Earth Observation. Available online: http://www.fao.org/giews/earthobservation/country/index.jsp?code=AFG&lang=en (accessed on 29 September 2021).
- Dataset for Wheat Export and Production Forecasting. Available online: http://keen.isa.ru/wheat_dataset (accessed on 29 October 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valetta, Malta, 22 May 2010; pp. 46–50. [Google Scholar]
- Al-Rfou, R. Polyglot: A Massive Multilingual Natural Language Processing Pipeline. Ph.D. Thesis, State University of New York at Stony Brook, New York, NY, USA, 2015. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Set | Frequency | For | Features |
|---|---|---|---|
| Trade flows | Annual | Country, Commodity | Export value |
| Import value | |||
| Re-export value | |||
| Re-import value | |||
| Production | Annual | Country, Commodity | Production value |
| Fuel prices | Annual | World | WTI price, USD |
| Brent price, USD | |||
| Macro-economic indicators | Annual | Country | Trade balance |
| GDP | |||
| Inflation (CPI) | |||
| Inflation (PPI) | |||
| Population | |||
| Purchasing power parity (PPP) | |||
| Unemployment rate | |||
| NDVI indicators | Per season: max, min, median | Country | Normalized difference vegetation index |
| Sentiment | Annual | Country | Topic-wise summary tweet sentiment for a country |
| Topic Name | Food Security | Wheat Pests | Yield/ Production Level | International Wheat Trade | Weather Conditions | Organic Agriculture |
|---|---|---|---|---|---|---|
| Keywords | area Asia bread curb prevent Europe farm feed India EU Australian | field crop bitly biggest impact countries problem | flour yields milling farming producers grains crops production harvest | export trade international importing harvesting prices imports bought buys tons market exports | farmers drought rain weather heavy | world GASC great organic breeding fertilizer |
| Features | ALL | ALL—NDVIS | ALL—NDVIS—FUEL | |||
|---|---|---|---|---|---|---|
| Models | RRSE | RRSE | RRSE | |||
| GRU | 0.63 ± 0.46 | 0.48 ± 0.41 | 1.85 ± 1.14 | 0.82 ± 0.65 | 1.33 ± 0.79 | 0.70 ± 0.54 |
| LSTM | 2.04 ± 1.57 | 0.87 ± 0.76 | 2.68 ± 1.47 | 0.99 ± 0.73 | 1.71 ± 1.39 | 0.79 ± 0.71 |
| SimpleRNN | 0.81 ± 0.59 | 0.54 ± 0.46 | 0.80 ± 0.61 | 0.54 ± 0.47 | 1.04 ± 0.81 | 0.62 ± 0.54 |
| NARX | 0.57 ± 0.35 | 0.45 ± 0.36 | 1.73 ± 0.56 | 0.80 ± 0.45 | 0.78 ± 0.56 | 0.53 ± 0.45 |
| Transformer | 0.62 ± 0.35 | 0.47 ± 0.36 | 1.18 ± 0.22 | 0.66 ± 0.28 | 0.79 ± 0.61 | 0.54 ± 0.47 |
| Features | ALL | ALL—NDVIS | ALL—NDVIS—FUEL | |||
|---|---|---|---|---|---|---|
| Models | RRSE | RRSE | 109 | RRSE | ||
| GRU | 1.80 ± 0.47 | 0.15 ± 0.07 | 1.88 ± 0.24 | 0.16 ± 0.05 | 1.68 ± 0.57 | 0.15 ± 0.09 |
| LSTM | 3.76 ± 0.41 | 0.22 ± 0.07 | 3.08 ± 0.36 | 0.20 ± 0.07 | 1.69 ± 0.37 | 0.15 ± 0.07 |
| SimpleRNN | 1.81 ± 0.30 | 0.15 ± 0.06 | 1.83 ± 0.27 | 0.15 ± 0.05 | 1.94 ± 0.53 | 0.16 ± 0.08 |
| NARX | 1.83 ± 0.29 | 0.15 ± 0.06 | 1.92 ± 0.57 | 0.16 ± 0.08 | 1.92 ± 0.36 | 0.16 ± 0.07 |
| Transformer | 1.77 ± 0.34 | 0.15 ± 0.06 | 1.56 ± 0.59 | 0.14 ± 0.08 | 1.82 ± 0.25 | 0.16 ± 0.06 |
| Features | ALL | ALL + SE | ALL + SE + SENTIMENT | |||
|---|---|---|---|---|---|---|
| Models | RRSE | RRSE | RRSE | |||
| GRU | 0.63 ± 0.46 | 0.48 ± 0.41 | 0.89 ± 0.70 | 0.57 ± 0.50 | 0.23 ± 0.11 | 0.29 ± 0.20 |
| LSTM | 2.04 ± 1.57 | 0.87 ± 0.76 | 1.35 ± 0.81 | 0.70 ± 0.54 | 0.67 ± 0.38 | 0.49 ± 0.37 |
| SimpleRNN | 0.81 ± 0.59 | 0.54 ± 0.46 | 0.71 ± 0.15 | 0.51 ± 0.23 | 0.14 ± 0.03 | 0.22 ± 0.10 |
| NARX | 0.57 ± 0.35 | 0.45 ± 0.36 | 0.16 ± 0.05 | 0.24 ± 0.13 | 0.12 ± 0.03 | 0.21 ± 0.10 |
| Transformer | 0.62 ± 0.35 | 0.47 ± 0.36 | 0.14 ± 0.08 | 0.22 ± 0.17 | 0.13 ± 0.03 | 0.22 ± 0.10 |
| Features | ALL | ALL + SE | ALL + SE + SENTIMENT | |||
|---|---|---|---|---|---|---|
| Models | RRSE | RRSE | RRSE | |||
| GRU | 1.80 ± 0.47 | 0.15 ± 0.07 | 1.43 ± 0.49 | 0.13 ± 0.08 | 1.14 ± 0.10 | 0.39 ± 0.11 |
| LSTM | 3.76 ± 0.41 | 0.22 ± 0.07 | 1.69 ± 0.34 | 0.15 ± 0.07 | 1.26 ± 0.13 | 0.41 ± 0.13 |
| SimpleRNN | 1.81 ± 0.30 | 0.15 ± 0.06 | 1.87 ± 0.18 | 0.16 ± 0.04 | 1.02 ± 0.12 | 0.37 ± 0.13 |
| NARX | 1.83 ± 0.29 | 0.15 ± 0.06 | 1.93 ± 0.60 | 0.16 ± 0.09 | 1.23 ± 0.58 | 0.40 ± 0.27 |
| Transformer | 1.77 ± 0.34 | 0.15 ± 0.06 | 1.64 ± 0.42 | 0.14 ± 0.07 | 1.14 ± 0.12 | 0.39 ± 0.13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devyatkin, D.; Otmakhova, Y. Methods for Mid-Term Forecasting of Crop Export and Production. Appl. Sci. 2021, 11, 10973. https://doi.org/10.3390/app112210973
Devyatkin D, Otmakhova Y. Methods for Mid-Term Forecasting of Crop Export and Production. Applied Sciences. 2021; 11(22):10973. https://doi.org/10.3390/app112210973
Chicago/Turabian StyleDevyatkin, Dmitry, and Yulia Otmakhova. 2021. "Methods for Mid-Term Forecasting of Crop Export and Production" Applied Sciences 11, no. 22: 10973. https://doi.org/10.3390/app112210973
APA StyleDevyatkin, D., & Otmakhova, Y. (2021). Methods for Mid-Term Forecasting of Crop Export and Production. Applied Sciences, 11(22), 10973. https://doi.org/10.3390/app112210973