
Simulated Annealing-Based Hyperspectral Data Optimization for Fish Species Classification: Can the Number of Measured Wavelengths Be Reduced?


 ,
, 
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Hyperspectral Imaging Systems
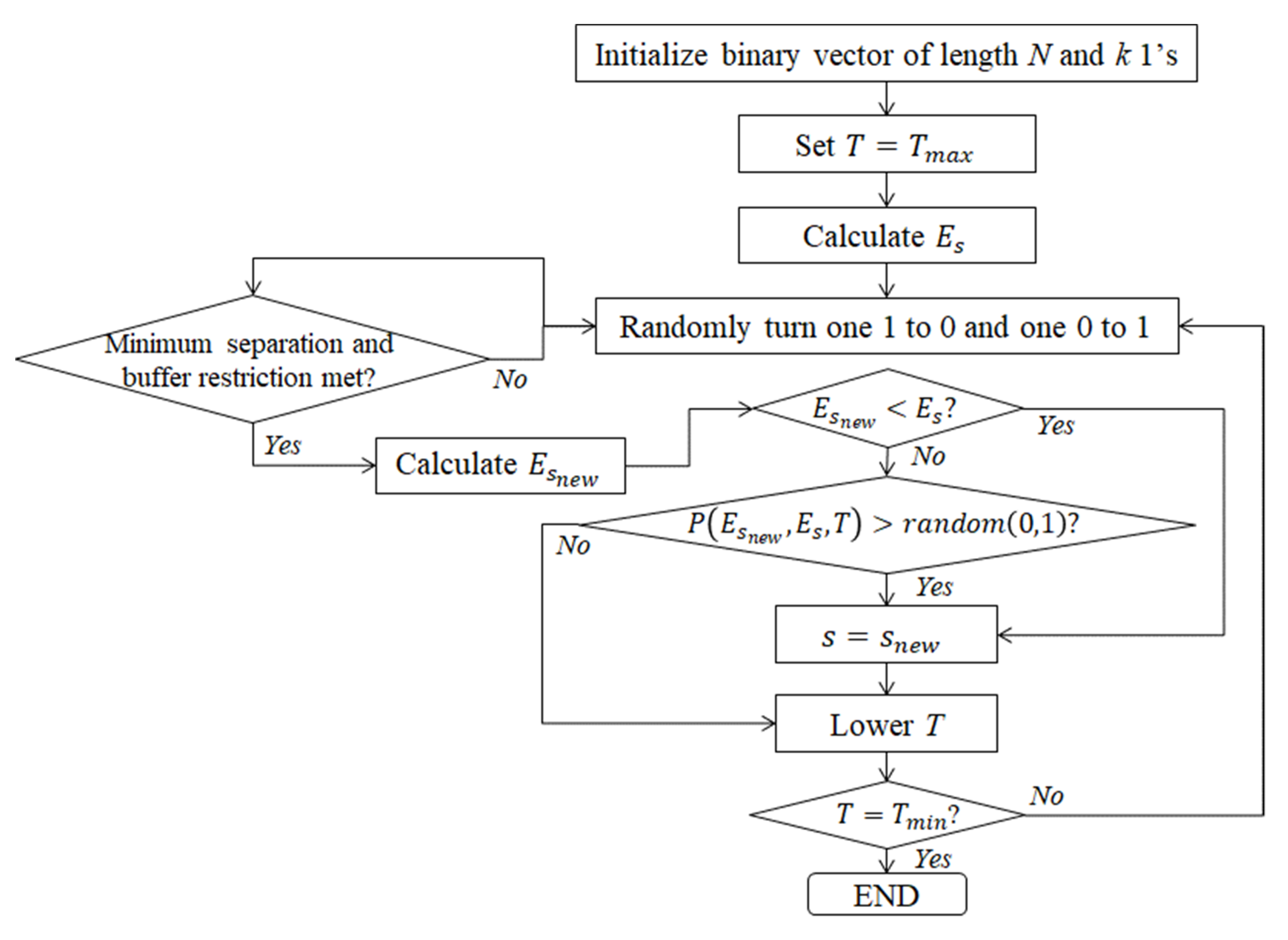
2.2. Simulated Annealing
2.3. Classification of Fish Species
2.3.1. Multi-Layer Perceptron (MLP) Classifier
2.3.2. Single-Mode Classification Study
2.3.3. Spectral Fusion Classification Study
2.4. Fish Fillet Data Collection
2.5. Cross-Validation Train and Test Datasets
2.6. Data Imbalance Correction
3. Results and Discussion
3.1. Wavelength Selection
3.2. Classification
3.2.1. Results of the Single-Mode Study
3.2.2. Results of the Fusion Classification Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, M.; Huang, D.; Hu, X.-J.; Tong, W.-H.; Han, B.-L.; Tian, J.-P.; Luo, H.-B. Application of hyperspectral technology in detection of agricultural products and food: A Review. Food Sci. Nutr. 2020, 8, 5206–5214. [Google Scholar] [CrossRef]
- Lu, Y.; Saeys, W.; Kim, M.; Peng, Y.; Lu, R. Hyperspectral imaging technology for quality and safety evaluation of horticultural products: A review and celebration of the past 20-year progress. Postharvest Biol. Technol. 2020, 170, 111318. [Google Scholar] [CrossRef]
- Yuan, D.; Jiang, J.; Qiao, X.; Qi, X.; Wang, W. An application to analyzing and correcting for the effects of irregular topographies on NIR hyperspectral images to improve identification of moldy peanuts. J. Food Eng. 2020, 280, 109915. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, J.; Qiao, X.; Qi, X.; Pan, Y.; Pan, X. Using convolution neural network and hyperspectral image to identify moldy peanut kernels. LWT 2020, 132, 109815. [Google Scholar] [CrossRef]
- Sun, J.; Cao, Y.; Zhou, X.; Wu, M.; Sun, Y.; Hu, Y. Detection for lead pollution level of lettuce leaves based on deep belief network combined with hyperspectral image technology. J. Food Saf. 2021, 41, e12866. [Google Scholar] [CrossRef]
- Liang, K.; Huang, J.; He, R.; Wang, Q.; Chai, Y.; Shen, M. Comparison of Vis-NIR and SWIR hyperspectral imaging for the non-destructive detection of DON levels in Fusarium head blight wheat kernels and wheat flour. Infrared Phys. Technol. 2020, 106, 103281. [Google Scholar] [CrossRef]
- Vasefi, F.; Isaacs, R.; Sokolov, S.; Kang, L.; Hellberg, R.; Farkas, D.L.; Qin, J.; Chan, D.E.; Kim, M.S. Multimode optical imaging for identification of fish fillet substitution and mislabeling (Conference Presentation). In Sensing for Agriculture and Food Quality and Safety XI; International Society for Optics and Photonics: Baltimore, MA, USA, 2019; Volume 11016, p. 1101606. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11016/1101606/Multimode-optical-imaging-for-identification-of-fish-fillet-substitution-and/10.1117/12.2523224.short (accessed on 1 January 2021).
- Qin, J.; Vasefi, F.; Hellberg, R.S.; Akhbardeh, A.; Isaacs, R.B.; Yilmaz, A.G.; Hwang, C.; Baek, I.; Schmidt, W.F.; Kim, M.S. Detection of fish fillet substitution and mislabeling using multimode hyperspectral imaging techniques. Food Control 2020, 114, 107234. [Google Scholar] [CrossRef]
- Goetz, A.F.H. Three decades of hyperspectral remote sensing of the Earth: A personal view. Remote Sens. Environ. 2009, 113, S5–S16. [Google Scholar] [CrossRef]
- Kumar, A.; Bharti, V.; Kumar, V.; Kumar, U.; Meena, P.D. Hyperspectral imaging: A potential tool for monitoring crop infestation, crop yield and macronutrient analysis, with special emphasis to Oilseed Brassica. J. Oilseed Brassica 2016, 7, 113–125. [Google Scholar]
- Teke, M.; Deveci, H.S.; Haliloğlu, O.; Gürbüz, S.Z.; Sakarya, U. A short survey of hyperspectral remote sensing applications in agriculture. In Proceedings of the 2013 6th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 12–14 June 2013; pp. 171–176. [Google Scholar]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef] [Green Version]
- Benelli, A.; Cevoli, C.; Fabbri, A. In-field hyperspectral imaging: An overview on the ground-based applications in agriculture. J. Agric. Eng. 2020, 51, 129–139. [Google Scholar] [CrossRef]
- Wu, D.; Sun, D.-W. Advanced applications of hyperspectral imaging technology for food quality and safety analysis and assessment: A review—Part I: Fundamentals. Innov. Food Sci. Emerg. Technol. 2013, 19, 1–14. [Google Scholar] [CrossRef]
- Gat, N. Imaging spectroscopy using tunable filters: A review. In Wavelet Applications VII; International Society for Optics and Photonics: Orlando, FL, USA, 2000; Volume 4056, pp. 50–64. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/4056/0000/Imaging-spectroscopy-using-tunable-filters-a-review/10.1117/12.381686.short (accessed on 1 January 2021).
- Hagen, N.A.; Kudenov, M.W. Review of snapshot spectral imaging technologies. Opt. Eng. 2013, 52, 090901. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.J.; Shields, E.A. Compressive hyperspectral imaging using total variation minimization. In Imaging Spectrometry XXII: Applications, Sensors, and Processing; International Society for Optics and Photonics: San Diego, CA, USA, 2018; Volume 10768, p. 1076804. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/10768/1076804/Compressive-hyperspectral-imaging-using-total-variation-minimization/10.1117/12.2322145.short (accessed on 3 January 2021).
- Thompson, J.V.; Bixler, J.N.; Hokr, B.H.; Noojin, G.D.; Scully, M.O.; Yakovlev, V.V. Single-shot chemical detection and identification with compressed hyperspectral Raman imaging. Opt. Lett. 2017, 42, 2169–2172. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Lin, L.; Zhao, Q.; Yue, T.; Meng, D.; Leung, Y. Compressive Sensing of Hyperspectral Images via Joint Tensor Tucker Decomposition and Weighted Total Variation Regularization. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2457–2461. [Google Scholar] [CrossRef]
- Lee, D.J. Deep neural networks for compressive hyperspectral imaging. In Imaging Spectrometry XXIII: Applications, Sensors, and Processing; International Society for Optics and Photonics: San Diego, CA, USA, 2019; Volume 11130, p. 1113006. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11130/1113006/Deep-neural-networks-for-compressive-hyperspectral-imaging/10.1117/12.2528048.short (accessed on 3 January 2021).
- Ferrari, C.; Foca, G.; Ulrici, A. Handling large datasets of hyperspectral images: Reducing data size without loss of useful information. Anal. Chim. Acta 2013, 802, 29–39. [Google Scholar] [CrossRef]
- Chauvin, J.; Vasefi, F.; Tavakolian, K.; Akhbardeh, A.; MacKinnon, N.; Qin, J.; Chan, D.E.; Kim, M.S. Reconstruction of hyperspectral spectra of fish fillets using multi-wavelength imaging and point spectroscopy. In Sensing for Agriculture and Food Quality and Safety XII; International Society for Optics and Photonics: San Diego, CA, USA, 2020; Volume 11421, p. 114210I, Online only; Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11421/114210I/Reconstruction-of-hyperspectral-spectra-of-fish-fillets-using-multi-wavelength/10.1117/12.2559230.short (accessed on 14 June 2021).
- Kim, M.; Chao, K.; Chan, D.; Jun, W.; Lefcourt, A.; Delwiche, S.; Kang, S.; Lee, K.; Lefcourt, A.; Kang, S.; et al. Line-Scan Hyperspectral Imaging Platform for Agro-Food Safety and Quality Evaluation: System Enhancement and Characterization. Trans. ASABE 2011, 54, 703–711. [Google Scholar] [CrossRef]
- Bertsimas, D.; Tsitsiklis, J. Simulated Annealing. Stat. Sci. 1993, 8, 10–15. [Google Scholar] [CrossRef]
- Perry, M. Simanneal: Simulated Annealing in Python. Available online: https://github.com/perrygeo/simanneal (accessed on 29 May 2021).
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. Available online: https://www.springer.com/gp/book/9780 (accessed on 8 November 2021).
- Kim, M.S.; Chen, Y.R.; Mehl, P.M. Hyperspectral Reflectance and Fluorescence Imaging System for Food Quality and Safety. 2001. Available online: https://pubag.nal.usda.gov/catalog/26654 (accessed on 14 June 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Number of Fillets | Number of Valid Voxels | ||
|---|---|---|---|---|
| VNIR | Fluorescence | SWIR | ||
| Almaco Jack (Seriola rivoliana) | 4 | 1157 | 1169 | 1992 |
| Atlantic Cod (Gadus morhua) | 4 | 1322 | 1391 | 1508 |
| Bigeye Tuna (Thunnus obesus) | 4 | 831 | 572 | 2416 |
| California Flounder (Paralichthys californicus) | 4 | 1016 | 1113 | 2416 |
| Char (Salvelinus sp.) | 4 | 1165 | 1156 | 1508 |
| Chinook Salmon (Oncorhynchus tshawytscha) | 4 | 1630 | 1570 | 2416 |
| Cobia (Rachycentron canadum) | 4 | 1235 | 1170 | 1508 |
| Coho Salmon (Oncorhynchus kisutch) | 4 | 894 | 887 | 2416 |
| Gilthead Bream (Sparus aurata) | 4 | 1314 | 1275 | 1362 |
| Goosefish (Lophiidae sp.) | 4 | 1304 | 1356 | 1508 |
| Haddock (Melanogrammus aeglefinus) | 4 | 1193 | 1375 | 1508 |
| Malabar Blood Snapper (Lutjanus malabaricus) | 12 | 5530 | 4750 | 7248 |
| Opah (Lampris sp.) | 4 | 913 | 875 | 2416 |
| Pacific Halibut (Hippoglossus stenolepis) | 4 | 1943 | 2120 | 2416 |
| Pacific Cod (Gadus macrocephalus) | 4 | 1619 | 1723 | 2416 |
| Petrale Sole (Eopsetta jordani) | 6 | 2253 | 2427 | 3624 |
| Rainbow Trout (Oncorhynchus mykiss) | 11 | 4263 | 3606 | 4806 |
| Red Snapper (Lutjanus campechanus) | 18 | 9482 | 7351 | 10,872 |
| Rockfish (Sebastes sp.) | 4 | 1230 | 1310 | 2416 |
| Sablefish (Anoplopoma fimbria) | 4 | 954 | 963 | 2416 |
| Sockeye Salmon (Oncorhynchus nerka) | 4 | 1033 | 909 | 2416 |
| Swordfish (Xiphias gladius) | 4 | 789 | 786 | 2416 |
| Tuna (Thunnus sp.) | 6 | 1473 | 1314 | 3170 |
| Winter Skate (Leucoraja ocellata) | 4 | 1839 | 1815 | 1860 |
| Yelloweye Rockfish (Sebastes ruberrimus) | 4 | 1197 | 1216 | 2416 |
| Mode | k | Simulated Annealing | ANOVA | RFE | Extra Trees |
|---|---|---|---|---|---|
| VNIR | 3 | 48.23% | 31.42% | 27.09% | 14.09% |
| 4 | 57.90% | 35.20% | 28.00% | 23.95% | |
| 5 | 63.49% | 36.28% | 31.87% | 25.93% | |
| 6 | 67.08% | 39.74% | 37.04% | 26.62% | |
| 7 | 68.10% | 41.21% | 43.42% | 29.58% | |
| Fluorescence | 3 | 71.75% | 59.71% | 44.18% | 54.96% |
| 4 | 75.90% | 62.95% | 48.21% | 64.09% | |
| 5 | 77.94% | 65.83% | 49.64% | 63.51% | |
| 6 | 78.08% | 66.80% | 51.95% | 65.20% | |
| 7 | 78.27% | 68.05% | 58.47% | 66.30% | |
| SWIR | 3 | 40.15% | 20.30% | 15.13% | 11.56% |
| 4 | 46.55% | 21.20% | 19.81% | 17.13% | |
| 5 | 51.21% | 37.39% | 20.15% | 17.32% | |
| 6 | 51.77% | 38.24% | 30.75% | 17.39% | |
| 7 | 52.01% | 39.26% | 32.28% | 16.82% |
| Benchmark | Selected Wavelengths | |||||
|---|---|---|---|---|---|---|
| All Wavelengths | k = 3 | k = 4 | k = 5 | k = 6 | k = 7 | |
| MLP | 87.7% | 50.4% | 60.1% | 72.7% | 79.7% | 82.7% |
| SVM | 89.8% | 50.6% | 59.9% | 68.7% | 74.5% | 77.6% |
| WKNN | 69.8% | 45.6% | 56.0% | 61.7% | 65.1% | 67.4% |
| LD | 91.7% | 45.0% | 51.2% | 54.6% | 58.4% | 61.3% |
| GNB | 33.1% | 26.8% | 31.2% | 27.3% | 28.6% | 31.7% |
| Benchmark | Selected Wavelengths | |||||
|---|---|---|---|---|---|---|
| All Wavelengths | k = 3 | k = 4 | k = 5 | k = 6 | k = 7 | |
| MLP | 92.9% | 78.9% | 84.3% | 86.2% | 89.4% | 89.9% |
| SVM | 82.5% | 66.7% | 71.7% | 70.8% | 79.5% | 79.5% |
| WKNN | 79.2% | 71.1% | 75.2% | 77.3% | 77.1% | 77.3% |
| LD | 84.1% | 59.0% | 62.2% | 65.4% | 65.5% | 68.5% |
| GNB | 51.0% | 40.2% | 45.2% | 44.0% | 49.0% | 49.0% |
| Benchmark | Selected Wavelengths | |||||
|---|---|---|---|---|---|---|
| All Wavelengths | k = 3 | k = 4 | k = 5 | k = 6 | k = 7 | |
| MLP | 75.8% | 46.1% | 56.1% | 66.4% | 67.7% | 67.6% |
| SVM | 63.2% | 44.5% | 53.0% | 62.1% | 64.2% | 64.1% |
| WKNN | 41.0% | 38.7% | 46.3% | 50.9% | 52.1% | 52.6% |
| LD | 80.7% | 38.2% | 45.2% | 51.1% | 53.3% | 54.5% |
| GNB | 20.3% | 14.4% | 14.5% | 14.8% | 14.7% | 14.6% |
| Fusion | Benchmark | k = 3 | k = 4 | k = 5 | k = 6 | k = 7 |
|---|---|---|---|---|---|---|
| VNIR-Fluor-SWIR | 94.9% | 90.4% | 92.3% | 93.8% | 94.8% | 94.5% |
| VNIR-Fluor | 95.5% | 88.9% | 90.2% | 92.4% | 94.7% | 94.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chauvin, J.; Duran, R.; Tavakolian, K.; Akhbardeh, A.; MacKinnon, N.; Qin, J.; Chan, D.E.; Hwang, C.; Baek, I.; Kim, M.S.; et al. Simulated Annealing-Based Hyperspectral Data Optimization for Fish Species Classification: Can the Number of Measured Wavelengths Be Reduced? Appl. Sci. 2021, 11, 10628. https://doi.org/10.3390/app112210628
Chauvin J, Duran R, Tavakolian K, Akhbardeh A, MacKinnon N, Qin J, Chan DE, Hwang C, Baek I, Kim MS, et al. Simulated Annealing-Based Hyperspectral Data Optimization for Fish Species Classification: Can the Number of Measured Wavelengths Be Reduced? Applied Sciences. 2021; 11(22):10628. https://doi.org/10.3390/app112210628
Chicago/Turabian StyleChauvin, John, Ray Duran, Kouhyar Tavakolian, Alireza Akhbardeh, Nicholas MacKinnon, Jianwei Qin, Diane E. Chan, Chansong Hwang, Insuck Baek, Moon S. Kim, and et al. 2021. "Simulated Annealing-Based Hyperspectral Data Optimization for Fish Species Classification: Can the Number of Measured Wavelengths Be Reduced?" Applied Sciences 11, no. 22: 10628. https://doi.org/10.3390/app112210628
APA StyleChauvin, J., Duran, R., Tavakolian, K., Akhbardeh, A., MacKinnon, N., Qin, J., Chan, D. E., Hwang, C., Baek, I., Kim, M. S., Isaacs, R. B., Yilmaz, A. G., Roungchun, J., Hellberg, R. S., & Vasefi, F. (2021). Simulated Annealing-Based Hyperspectral Data Optimization for Fish Species Classification: Can the Number of Measured Wavelengths Be Reduced? Applied Sciences, 11(22), 10628. https://doi.org/10.3390/app112210628