
Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics



Abstract
:1. Introduction
2. Related Work
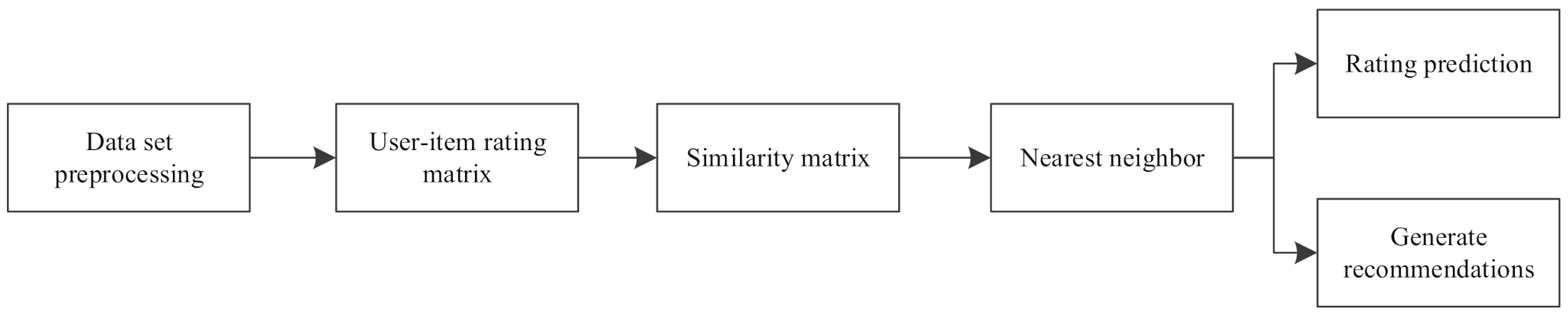
2.1. Data Preprocessing
2.2. Similarity Calculation
2.3. Generate Recommendation Set
3. Proposed Method
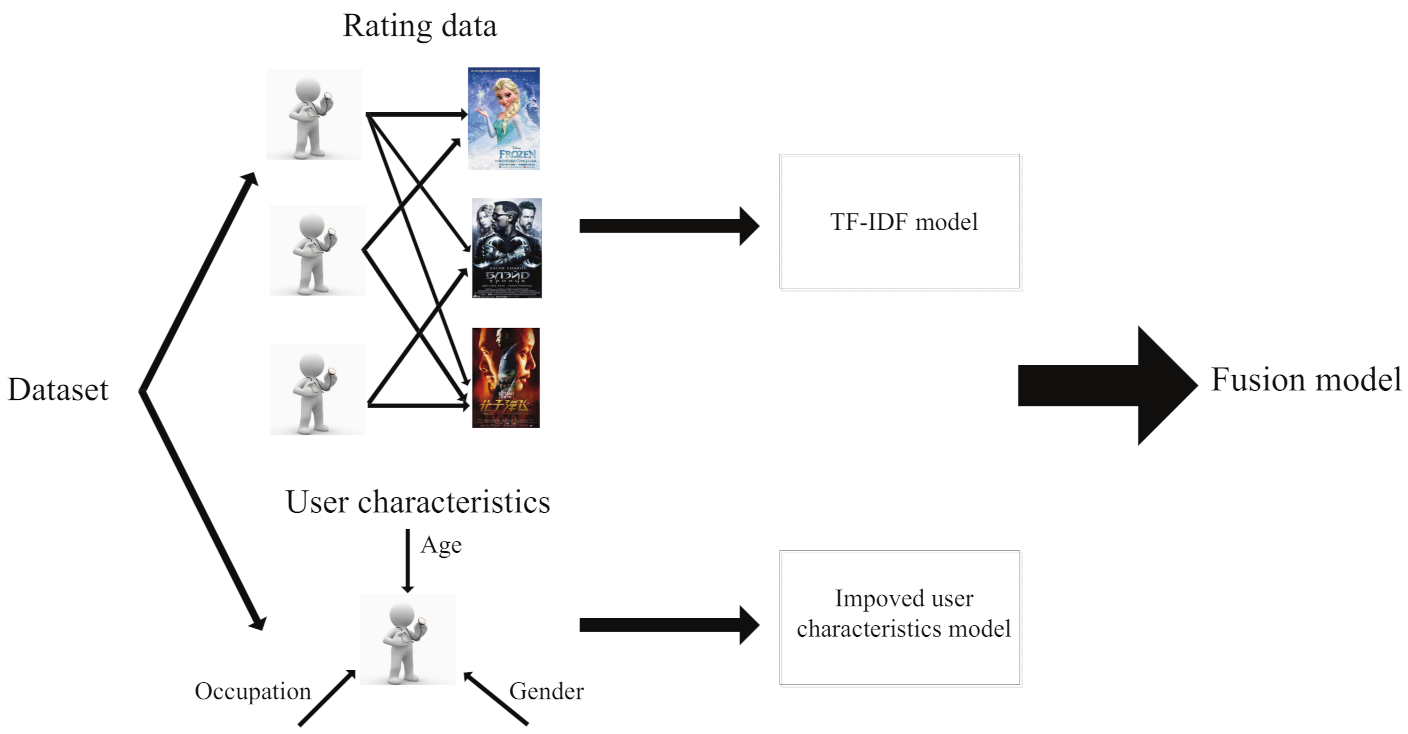
3.1. Improved TF-IDF Based Method
3.2. Improved User Characteristics Model
- (1)
- Age similarity
- (2)
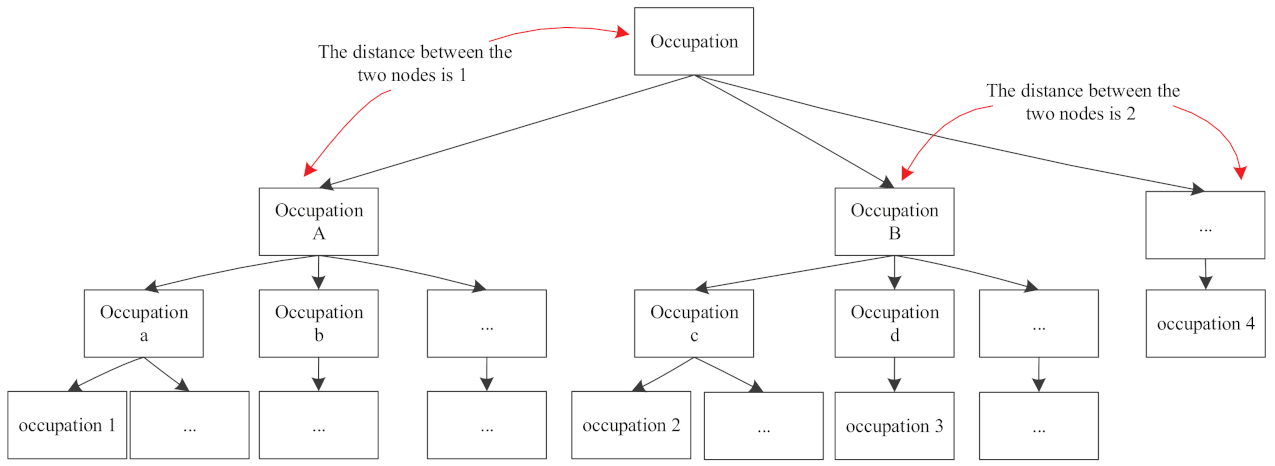
- Occupation similarity
- (3)
- Gender similarity
- (4)
- User characteristics similarity
3.3. Proposed Fusion Strategy to Generate Recommendation
| Algorithm 1 Optimal solution search algorithm |
|
- Step 1: Preprocess the rating data and construct the user-item rating matrix ;
- Step 2: Use TF-IDF method and rating data to calculate the user similarity matrix ;
- Step 3: Use user characteristics information to calculate the user characteristics similarity matrix ;
- Step 4: Fuse the similarity matrices from Step2 and Step3 to generate the final user comprehensive similarity matrix ;
- Step 5: After the comprehensive similarity matrix of a user is obtained, the nearest neighbor set of the target user is selected to make rating prediction and generate recommendations.
4. Experiments
4.1. Dataset and Metrics
4.2. Comparison Experiment
5. Discussions
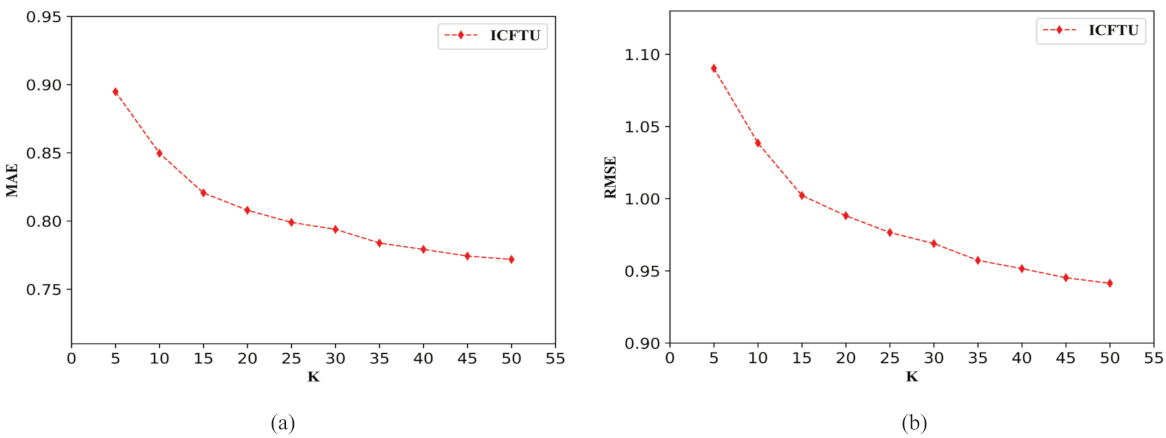
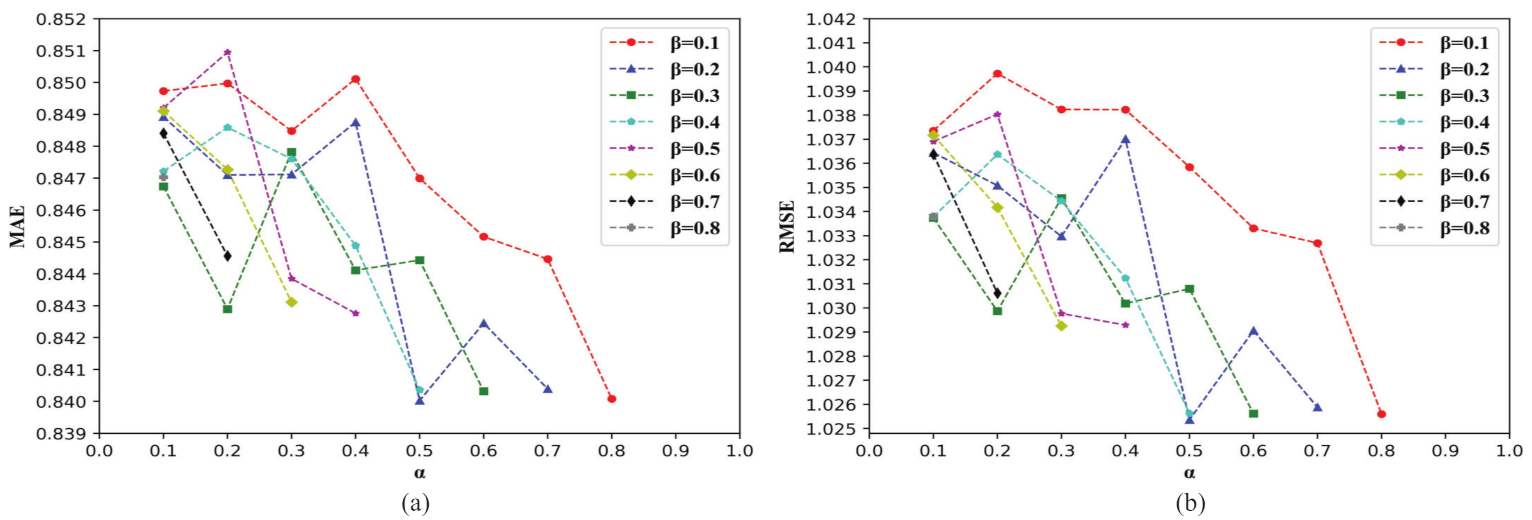
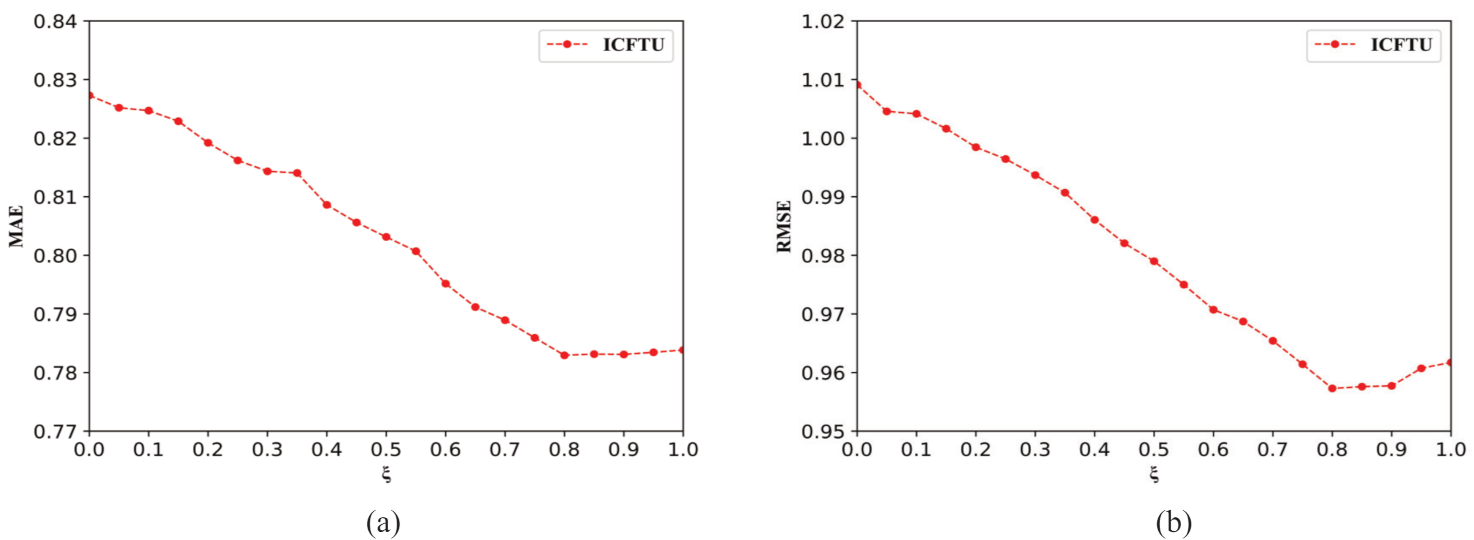
5.1. Parameter Discussion
- (1)
- About the nearest neighbor
- (2)
- About the user characteristic parameters
- (3)
- About the model fusion parameters
5.2. Ablation Experiment
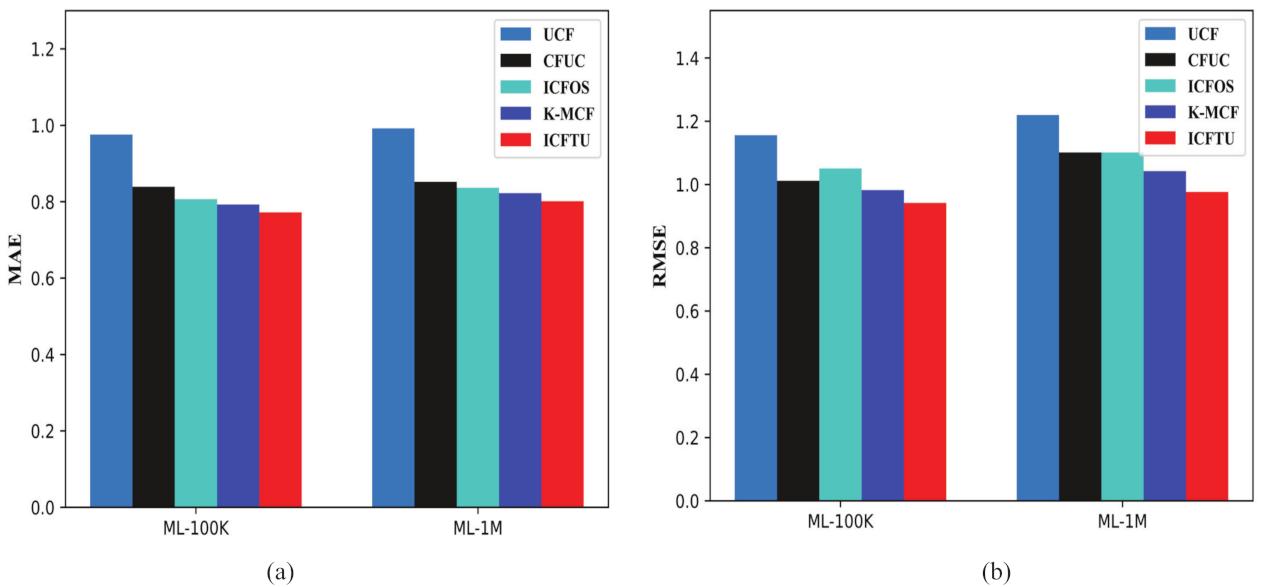
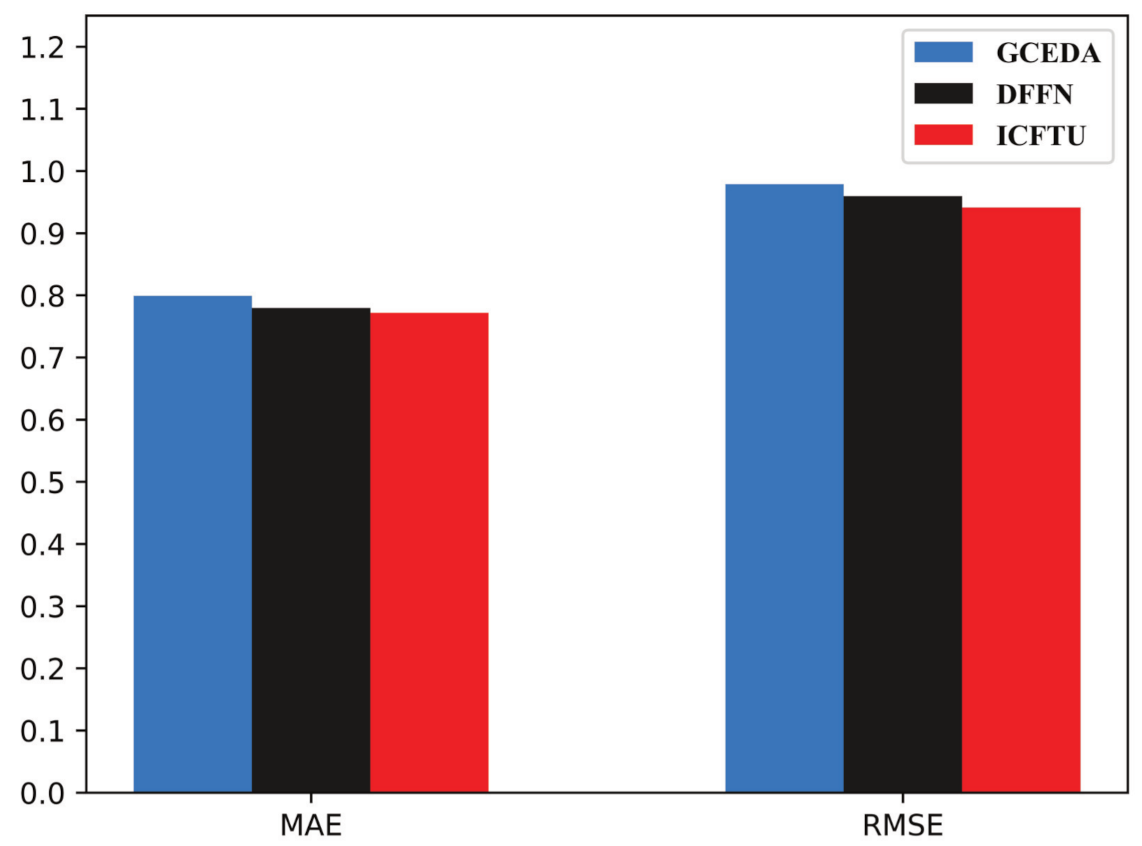
5.3. Compared with Other Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Z.; Guo, Q.; Yang, J.; Fang, H.; Guo, G.; Zhang, J.; Burke, R. Research commentary on recommendations with side information: A survey and research directions. Electron. Commer. Res. Appl. 2019, 37, 100879. [Google Scholar] [CrossRef] [Green Version]
- Quijano-Sanchez, L.; Cantador, I.; Cortes-Cediel, M.E.; Gil, O. Recommender systems for smart cities. Inf. Syst. 2020, 92, 101545. [Google Scholar] [CrossRef]
- Conceicao, F.L.A.; Padua, F.L.C.; Lacerda, A.; Machado, A.C.; Dalip, D.H. Multimodal data fusion framework based on autoencoders for top-N recommender systems. Appl. Intell. 2019, 49, 3267–3282. [Google Scholar] [CrossRef]
- Chen, Y.C.; Hui, L.; Thaipisutikul, T.; Chen, H.L. A Collaborative Filtering Recommendation System with Dynamic Time Decay. J. Supercomput. 2021, 77, 244–262. [Google Scholar] [CrossRef]
- Jiang, M.; Zhang, Z.; Jiang, J.; Wang, Q.; Pei, Z. A collaborative filtering recommendation algorithm based on information theory and bi-clustering. Neural Comput. Appl. 2019, 31, 8279–8287. [Google Scholar] [CrossRef]
- Nakagawa, A.; Ito, T. An implementation of a knowledge recommendation system based on similarity among users’ profiles. In Proceedings of the 41st SICE Annual Conference, SICE 2002, Osaka, Japan, 5–7 August 2002; Volume 1, pp. 326–327. [Google Scholar]
- Yu, L.; Liu, L.; Li, X. A hybrid collaborative filtering method for multiple-interests and multiple-content recommendation in E-Commerce. Expert Syst. Appl. 2005, 28, 67–77. [Google Scholar]
- Park, Y.; Park, S.; Lee, S.G.; Jung, W. Fast Collaborative Filtering with a k-nearest neighbor graph. In Proceedings of the 2014 International Conference on Big Data and Smart Computing, BIGCOMP 2014, Bangkok, Thailand, 15–17 January 2014; pp. 92–95. [Google Scholar]
- Wu, Y.K.; Yao, J.R.; Tang, Z.H.; Meng, J.Q. Collaborative filtering based on multi-level item category system. J. Converg. Inf. Technol. 2012, 7, 64–71. [Google Scholar]
- Bartolini, I.; Zhang, Z.; Papadias, D. Collaborative filtering with personalized skylines. IEEE Trans. Knowl. Data Eng. 2011, 23, 190–203. [Google Scholar] [CrossRef] [Green Version]
- Sajedi-Badashian, A.; Stroulia, E. Vocabulary and time based bug-assignment: A recommender system for open-source projects. Softw.-Pract. Exp. 2020, 50, 1539–1564. [Google Scholar] [CrossRef]
- Pirasteh, P.; Jung, J.J.; Hwang, D. Item-based collaborative filtering with attribute correlation: A case study on movie recommendation. In Proceedings of the 6th Asian Conference on Intelligent Information and Database Systems, Bangkok, Thailand, 7–9 April 2014; Volume 8398, pp. 245–252. [Google Scholar]
- Kumar, R.; Verma, B.K.; Rastogi, S.S. Social Popularity based SVD++ Recommender System. Int. J. Comput. Appl. 2014, 87, 33–37. [Google Scholar] [CrossRef]
- Sun, B.; Dong, L. Dynamic Model Adaptive to User Interest Drift Based on Cluster and Nearest Neighbors. IEEE Access 2017, 5, 1682–1691. [Google Scholar] [CrossRef]
- Wang, J.; Lan, Y.-X.; Wu, C.-Y. Survey of Recommendation Based on Collaborative Filtering. In Proceedings of the 2019 3rd International Conference on Electrical, Mechanical and Computer Engineering, ICEMCE 2019, Guiyang, China, 9–11 August 2019; Volume 1314. [Google Scholar]
- Zarzour, H.; Jararweh, Y.; Al-Sharif, Z.A. An Effective Model-Based Trust Collaborative Filtering for Explainable Recommendations. In Proceedings of the 2020 11th International Conference on Information and Communication Systems, ICICS 2020, Copenhagen, Denmark, 24–26 August 2020; pp. 238–242. [Google Scholar]
- Chen, J.; Wang, B.; Ouyang, Z.; Wang, Z. Dynamic clustering collaborative filtering recommendation algorithm based on double-layer network. Int. J. Mach. Learn. Cybern. 2021, 12, 1097–1113. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Y.; Zhao, J.; Zhu, Q. Mobile edge cache strategy based on neural collaborative filtering. IEEE Access 2020, 8, 18475–18482. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Wang, Y. A Novel K-medoids clustering recommendation algorithm based on probability distribution for collaborative filtering. Knowl.-Based Syst. 2019, 175, 96–106. [Google Scholar] [CrossRef]
- Zhang, X. Collaborative filtering recommendation algorithm based on sparse bilinear convolution. Eng. Intell. Syst. 2020, 28, 205–214. [Google Scholar]
- Wu, L. Collaborative Filtering Recommendation Algorithm for MOOC Resources Based on Deep Learning. Complexity 2021, 2021, 5555226. [Google Scholar]
- Xiao, Y.; Ai, P.; Hsu, C.H.; Wang, H.; Jiao, X. Time-ordered collaborative filtering for news recommendation. China Commun. 2015, 12, 53–62. [Google Scholar] [CrossRef]
- Ba, Q.; Li, X.; Bai, Z. A Similarity Calculating Approach Simulated from TF-IDF in Collaborative Filtering Recommendation. In Proceedings of the 2013 Fifth International Conference on Multimedia Information Networking and Security, Washington, DC, USA, 1–3 November 2013. [Google Scholar]
- Alhijawi, B.; Kilani, Y. A collaborative filtering recommender system using genetic algorithm. Inf. Process. Manag. 2020, 57, 102310. [Google Scholar] [CrossRef]
- Li, X.; Li, D. An Improved Collaborative Filtering Recommendation Algorithm and Recommendation Strategy. Mob. Inf. Syst. 2019, 2019, 3560968. [Google Scholar] [CrossRef]
- Xu, L.; Li, X.; Guo, Y. Gauss-core extension dependent prediction algorithm for collaborative filtering recommendation. Clust. Comput. 2019, 22, 11501–11511. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Wang, J.; Chen, J.; Liu, J.; Gong, Z. Trust-Enhanced Collaborative Filtering for Personalized Point of Interests Recommendation. IEEE Trans. Ind. Inform. 2020, 16, 6124–6132. [Google Scholar] [CrossRef]
- Wu, S.; Kou, H.; Lv, C.; Huang, W.; Qi, L.; Wang, H. Service recommendation with high accuracy and diversity. Wirel. Commun. Mob. Comput. 2020, 2020, 8822992. [Google Scholar] [CrossRef]
- Li, S.; Li, X. Collaborative filtering recommendation algorithm based on user characteristics and user interests. J. Phys. Conf. Ser. 2020, 1616, 012032. [Google Scholar] [CrossRef]
- Kowal, P.; Chatterji, S.; Naidoo, N.; Biritwum, R.; Wu, F.; Ridaura, R.; Maximova, T.; Arokiasamy, P.; Phaswana-Mafuya, N.; Williams, S.; et al. Data Resource Profile: The World Health Organization Study on global AGEing and adult health (SAGE). Int. J. Epidemiol. 2012, 41, 1639–1649. [Google Scholar] [CrossRef] [PubMed]
- Forouzandeh, S.; Berahmand, K.; Rostami, M. Presentation of a recommender system with ensemble learning and graph embedding: A case on MovieLens. Multimed. Tools Appl. 2021, 80, 7805–7832. [Google Scholar] [CrossRef]
- Tahmasbi, H.; Jalali, M.; Shakeri, H. TSCMF: Temporal and social collective matrix factorization model for recommender systems. J. Intell. Inf. Syst. 2021, 56, 169–187. [Google Scholar] [CrossRef]
- Velammal, B. Typicality-based collaborative filtering for book recommendation. Expert Syst. 2019, 36, e12382. [Google Scholar]
- Chen, H.; Li, Z.; Hu, W. An improved collaborative recommendation algorithm based on optimized user similarity. J. Supercomput. 2016, 72, 2565–2578. [Google Scholar] [CrossRef]
- Rizzo, G.L.C.; De Marco, M.; De Rosa, P.; Laura, L. Collaborative Recommendations with Deep Feed-Forward Networks: An Approach to Service Personalization. In Proceedings of the 10th International Conference on Exploring Service Science, Porto, Portugal, 5–7 February 2020; Volume 377, pp. 65–78. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | User | Item | Number of Ratings | Rating Range |
|---|---|---|---|---|
| ML-100K | 943 | 1682 | 100,000 | 1–5 |
| ML-1M | 6040 | 3900 | 1,000,209 | 1–5 |
| Dataset | MAE | RMSE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UCF | CFUC | ICFOS | K-MCF | ICFTU | UCF | CFUC | ICFOS | K-MCF | ICFTU | |
| ML-100k | 0.976 | 0.839 | 0.806 | 0.792 | 0.771 | 1.156 | 1.011 | 1.05 | 0.982 | 0.941 |
| ML-1M | 0.992 | 0.852 | 0.836 | 0.822 | 0.801 | 1.219 | 1.101 | 1.102 | 1.042 | 0.976 |
| Method | MAE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | |
| ICFTU-UC | 0.975 | 0.916 | 0.897 | 0.873 | 0.859 | 0.847 | 0.838 | 0.827 | 0.822 | 0.819 |
| ICFTU-TI | 0.894 | 0.855 | 0.832 | 0.817 | 0.804 | 0.798 | 0.792 | 0.785 | 0.784 | 0.779 |
| ICFTU | 0.894 | 0.849 | 0.82 | 0.807 | 0.798 | 0.793 | 0.783 | 0.779 | 0.774 | 0.771 |
| Method | RMSE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | |
| ICFTU-UC | 1.174 | 1.118 | 1.097 | 1.069 | 1.052 | 1.023 | 1.01 | 1.004 | 1.001 | 0.999 |
| ICFTU-TI | 1.087 | 1.045 | 1.015 | 0.998 | 0.985 | 0.976 | 0.969 | 0.959 | 0.957 | 0.952 |
| ICFTU | 1.090 | 1.038 | 1.002 | 0.988 | 0.976 | 0.968 | 0.957 | 0.951 | 0.945 | 0.941 |
| Metric | GCEDA | DFFN | ICFTU |
|---|---|---|---|
| MAE | 0.799 | 0.779 | 0.771 |
| Improvements | 3.50% | 1.03% | - |
| RMSE | 0.979 | 0.959 | 0.941 |
| Improvements | 3.88% | 1.88% | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Cai, Y.; Tang, G.; Xie, Y. Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics. Appl. Sci. 2021, 11, 9554. https://doi.org/10.3390/app11209554
Ni J, Cai Y, Tang G, Xie Y. Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics. Applied Sciences. 2021; 11(20):9554. https://doi.org/10.3390/app11209554
Chicago/Turabian StyleNi, Jianjun, Yu Cai, Guangyi Tang, and Yingjuan Xie. 2021. "Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics" Applied Sciences 11, no. 20: 9554. https://doi.org/10.3390/app11209554
APA StyleNi, J., Cai, Y., Tang, G., & Xie, Y. (2021). Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics. Applied Sciences, 11(20), 9554. https://doi.org/10.3390/app11209554