
JUMRv1: A Sentiment Analysis Dataset for Movie Recommendation

 , , ,
, , ,  and
and
Abstract
:1. Introduction
- Word-embedding: We used several word embedding techniques for feature extraction and in order to find the semantics of the words in the cleaned version of the reviews. We used word2vec-skipgram, word2vec-CBOW, Google pre-trained word2vec, and GloVe;
- Feature Selection: By using feature-selection algorithms, we narrowed down the available features to the most important ones. We used three filter methods—Chi-squared, F classifier, Mutual information (MI), and one wrapper method—Recursive Feature Elimination (RFE). All were used with top-k features, where k was optimised;
- Classification: We used three different classifiers with the following methods: Random Forest (RF), XGBoost (XGB), and Support Vector Classifier (SVC).
2. Literature Survey
3. Dataset
- Positive (1): 833
- Neutral (0): 301
- Negative (−1): 288
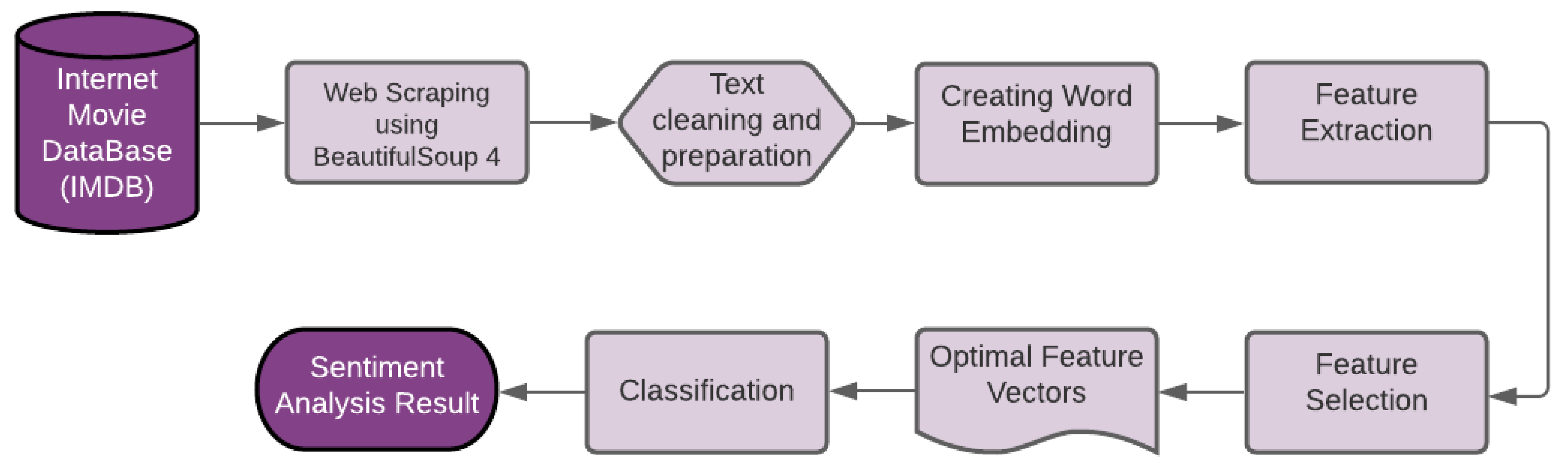
4. Methods and Materials
4.1. Pre-Processing
- Removing non-alphabetic characters, including punctuation marks, numbers, special characters, html tags, and emojis (Garain and Mahata [27]);
- Converting all letters to lower case;
- Removing all words that are less than three characters long as these are not likely to add any value to the review as a whole;
- Removing “stop words” includes words such as “to”, “this”, “for”, as these words do not provide meaning to the review as a whole, and hence will not assist in the processing;
- Normalising numeronyms (Garain et al. [28]);
- Replacing emojis and emoticons with their corresponding meanings (Garain [29]);
- Lemmatising all words to their original form—so that words such as history, historical, and historic—are all converted into their root word: history. This ensures that all these words are processed as the same word; hence, their relations become clearer to the machine. We used the lemmatiser from the spaCy (Honnibal et al. [30]) library.
4.2. Word Embedding
- Google Pre-trained Word2Vec: This is a Word2Vec model, trained by Google on a 100-billion-word Google News dataset and accessed via the gensim library (Mikolov et al. [31]);
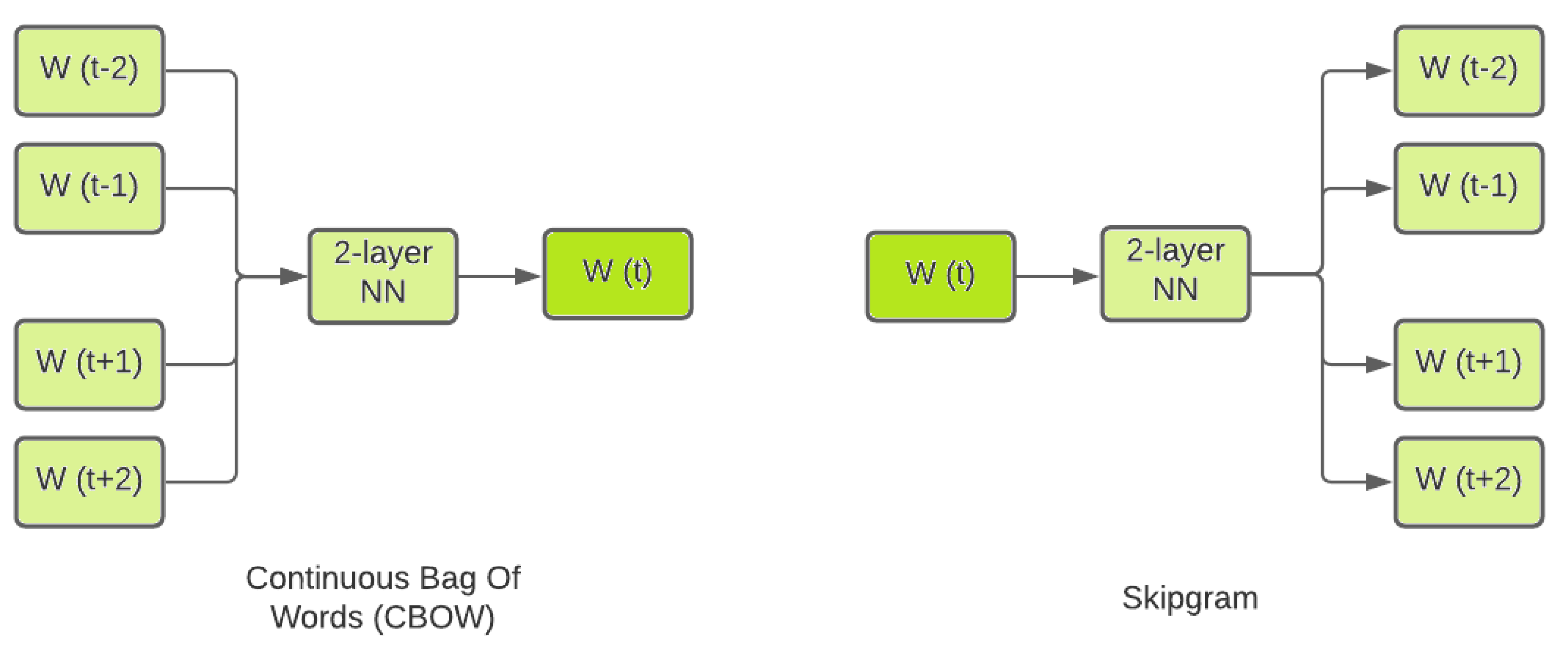
- Custom Word2vec (Skipgram): Here, a custom Word2Vec model that uses “skipgram” neural embedding method is considered. This method relates the central word to the neighbouring words;
- Custom Word2Vec (Continuous Bag Of Words): Another custom Word2Vec model that uses the Continuous Bag Of Words (CBOW) neural embedding method. This is the opposite of the skipgram model, as this relates the neighbouring words to the central word;
- Stanford University GloVe Pre-trained: This is a GloVe model, trained using Wikipedia 2014 (Pennington et al. [32]) as a corpus by Stanford University, and can be accessed via the university website.
4.3. Feature Extraction
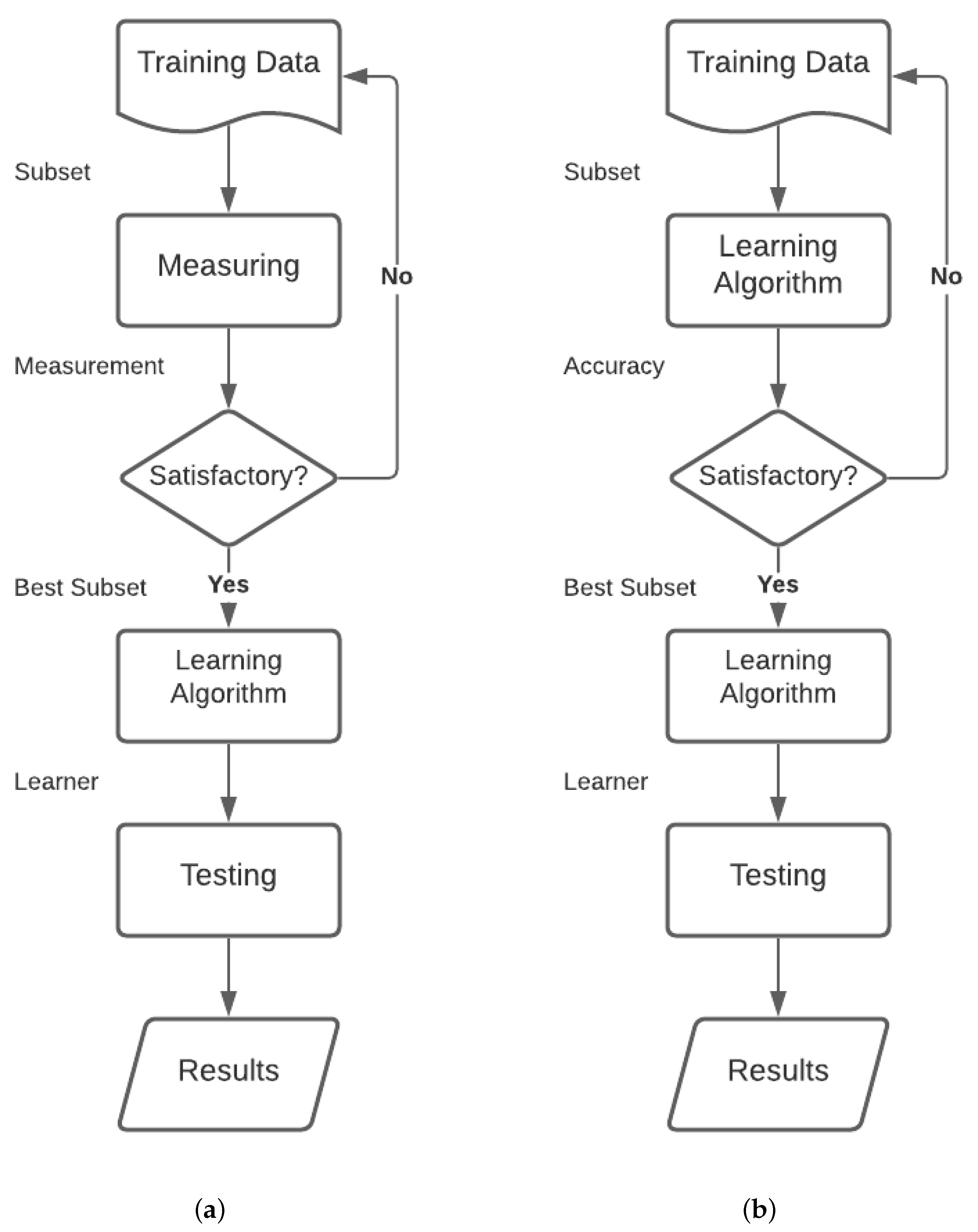
4.4. Feature Selection
- Filter methods;
- Wrapper Methods;
- Embedded Methods.
4.4.1. Filter Methods
Chi-Squared
F-Classifier
Mutual Information
4.4.2. Wrapper-Based Method
Recursive Feature Elimination
4.5. Classification
4.5.1. Random Forest
4.5.2. XGBoost
4.5.3. Support Vector Classifier
5. Results and Discussion
5.1. Analysis Metrics
5.2. Software Used
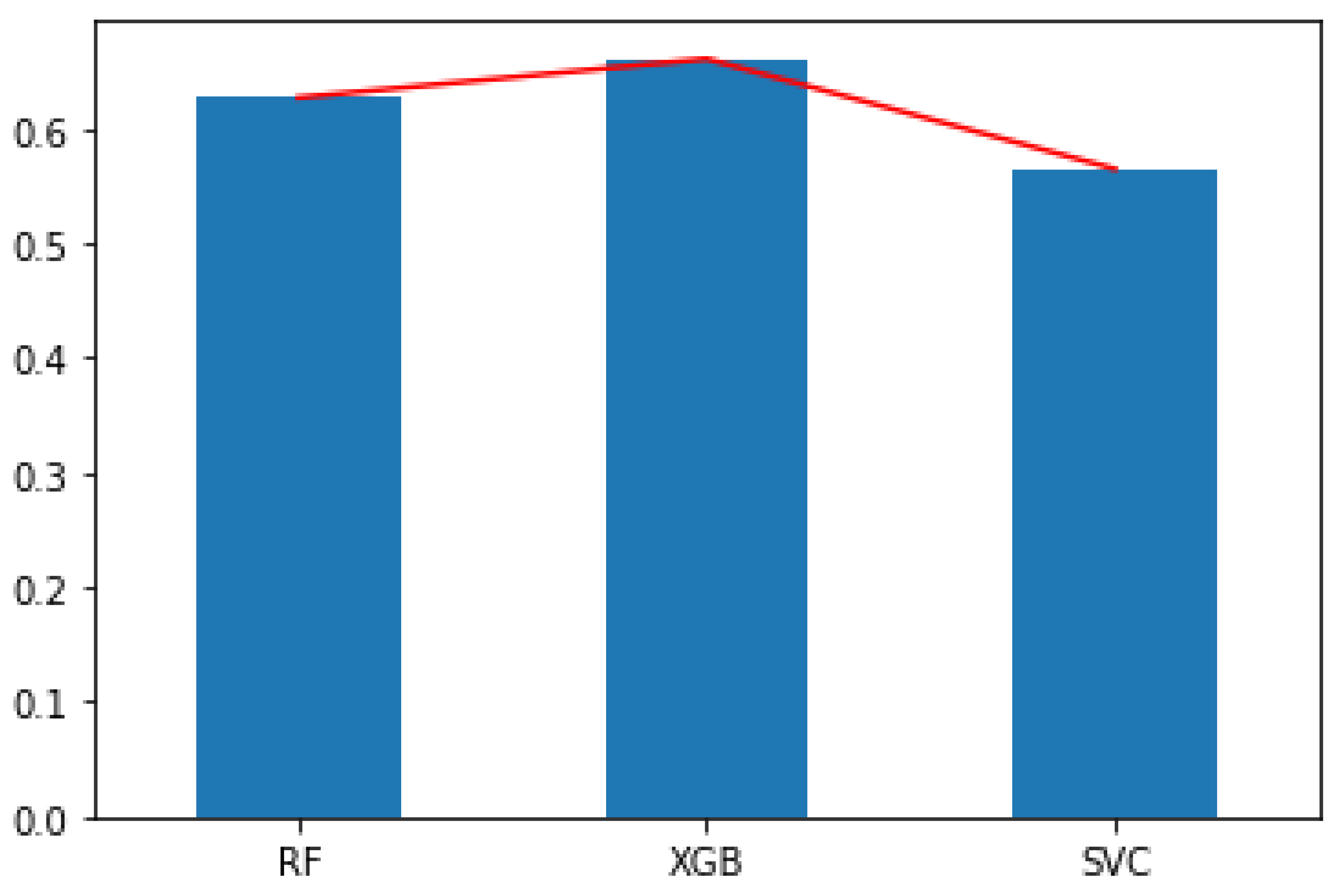
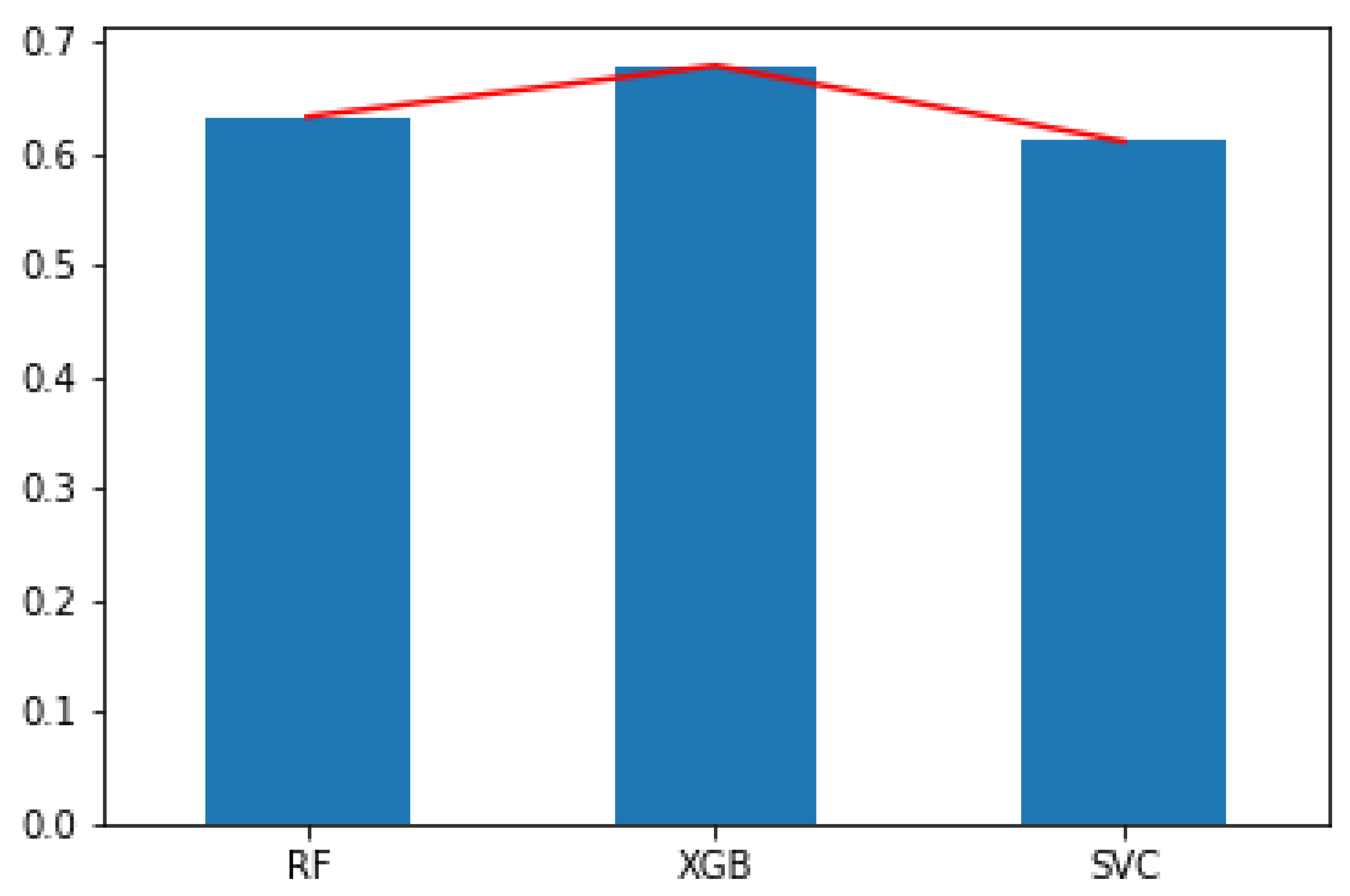
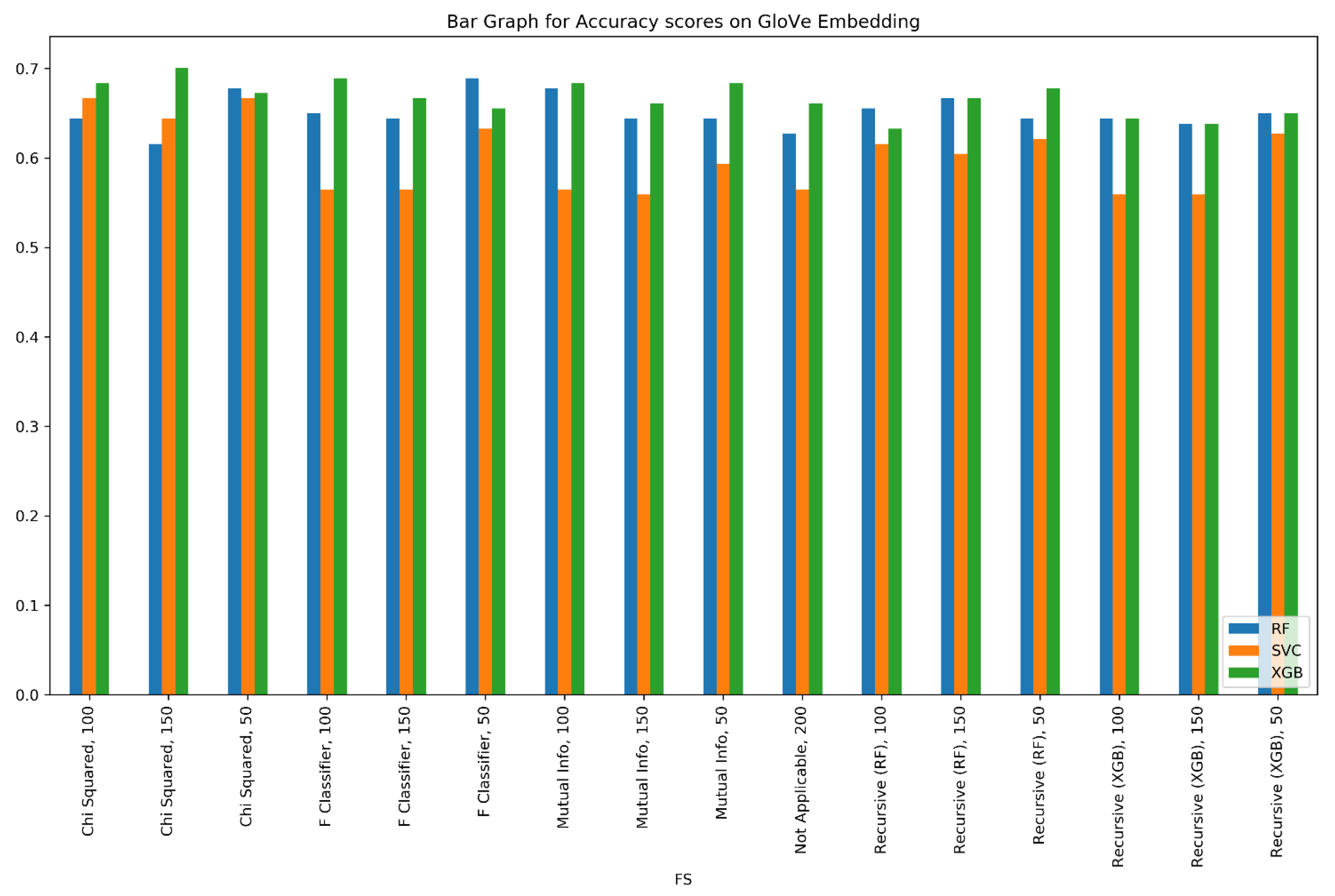
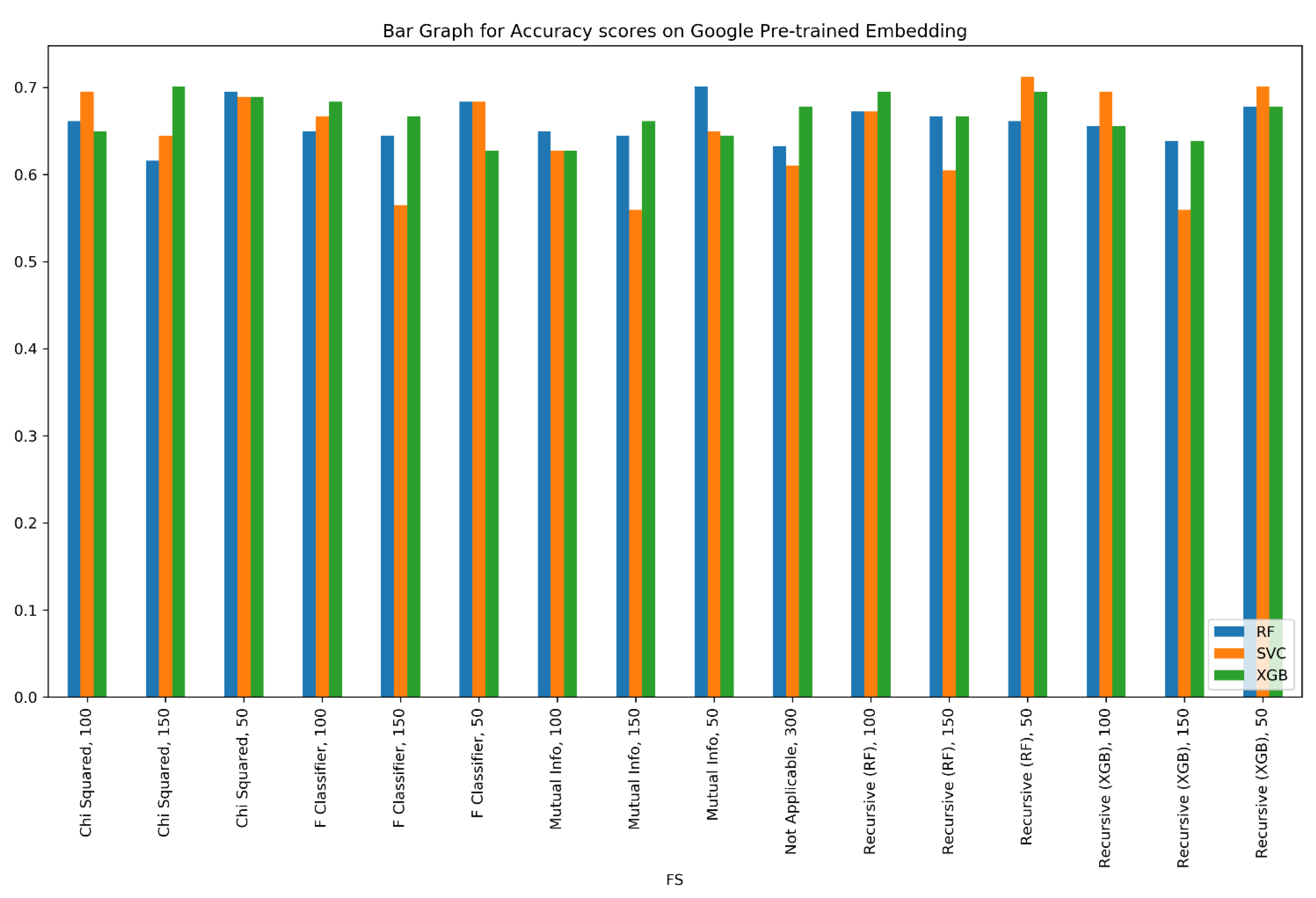
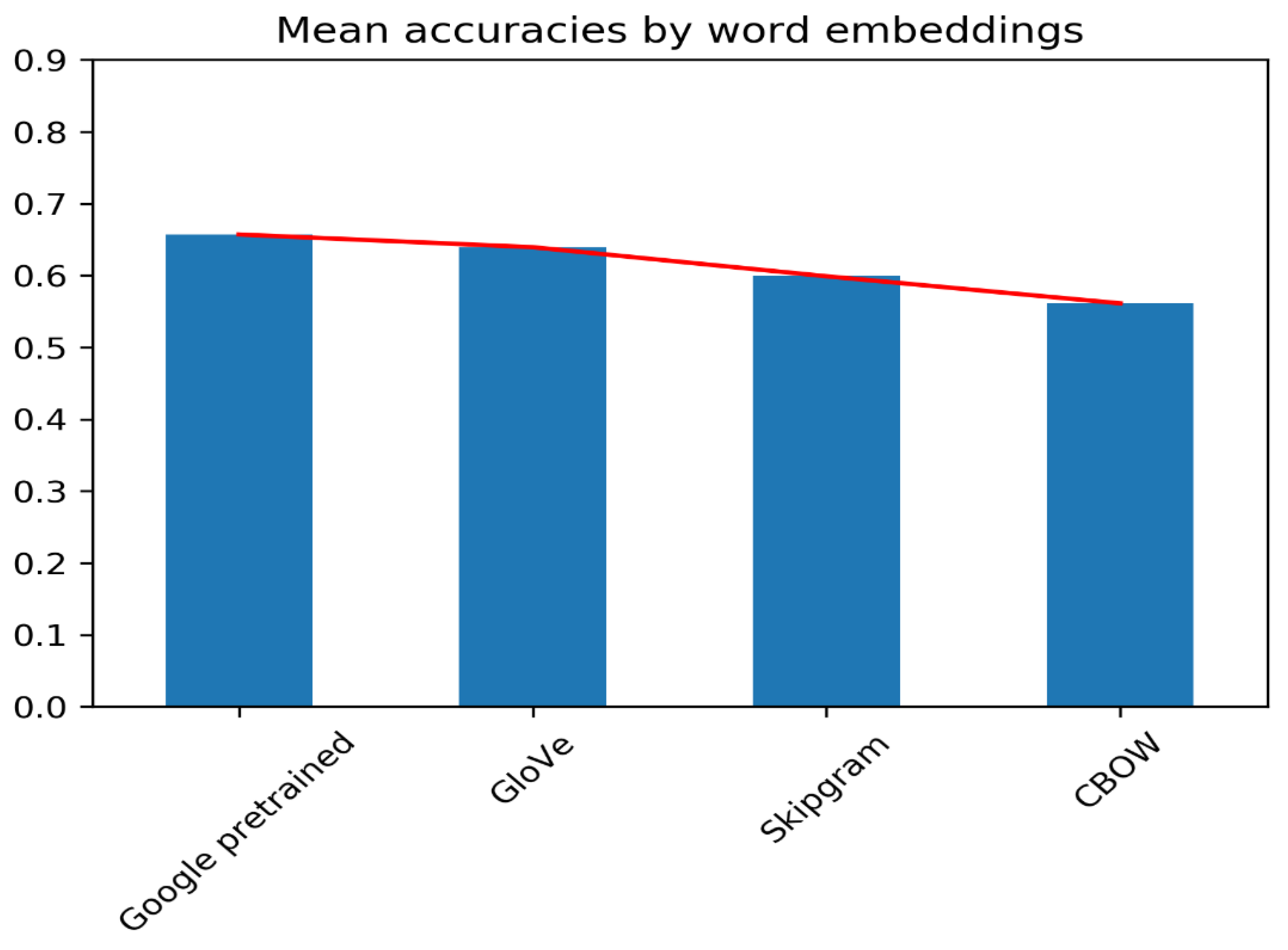
6. Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baid, P.; Gupta, A.; Chaplot, N. Sentiment analysis of movie reviews using machine learning techniques. Int. J. Comput. Appl. 2017, 179, 45–49. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. arXiv 2004, arXiv:cs/0409058. [Google Scholar]
- Elghazaly, T.; Mahmoud, A.; Hefny, H.A. Political sentiment analysis using twitter data. In Proceedings of the International Conference on Internet of things and Cloud Computing, Cambridge, UK, 23 February—22 March 2016; pp. 1–5. [Google Scholar]
- Pratiwi, A.I. On the feature selection and classification based on information gain for document sentiment analysis. Appl. Comput. Intell. Soft Comput. 2018, 2018, 1407817. [Google Scholar] [CrossRef] [Green Version]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Zou, H.; Tang, X.; Xie, B.; Liu, B. Sentiment classification using machine learning techniques with syntax features. In Proceedings of the 2015 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 7–9 December 2015; pp. 175–179. [Google Scholar]
- Ukhti Ikhsani Larasati, I.U.; Much Aziz Muslim, I.U.; Riza Arifudin, I.U.; Alamsyah, I.U. Improve the Accuracy of Support Vector Machine Using Chi Square Statistic and Term Frequency Inverse Document Frequency on Movie Review Sentiment Analysis. Sci. J. Inform. 2019, 6, 138–149. [Google Scholar]
- Ray, B.; Garain, A.; Sarkar, R. An ensemble-based hotel recommender system using sentiment analysis and aspect categorization of hotel reviews. Appl. Soft Comput. 2021, 98, 106935. [Google Scholar] [CrossRef]
- Fang, X.; Zhan, J. Sentiment analysis using product review data. J. Big Data 2015, 2, 5. [Google Scholar] [CrossRef] [Green Version]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Manek, A.S.; Shenoy, P.D.; Mohan, M.C.; Venugopal, K. Aspect term extraction for sentiment analysis in large movie reviews using Gini Index feature selection method and SVM classifier. World Wide Web 2017, 20, 135–154. [Google Scholar] [CrossRef] [Green Version]
- Liao, S.; Wang, J.; Yu, R.; Sato, K.; Cheng, Z. CNN for situations understanding based on sentiment analysis of twitter data. Procedia Comput. Sci. 2017, 111, 376–381. [Google Scholar] [CrossRef]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gold. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), Turin, Italy, 3 December 2013. [Google Scholar]
- Singh, T.; Nayyar, A.; Solanki, A. Multilingual opinion mining movie recommendation system using RNN. In Proceedings of First International Conference on Computing, Communications, and Cyber-Security (IC4S 2019); Springer: Berlin/Heidelberg, Germany, 2020; pp. 589–605. [Google Scholar]
- Ibrahim, M.; Bajwa, I.S.; Ul-Amin, R.; Kasi, B. A neural network-inspired approach for improved and true movie recommendations. Comput. Intell. Neurosci. 2019, 2019, 4589060. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Sun, A.; Han, J.; Liu, Y.; Zhu, X. Sentiment analysis by capsules. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1165–1174. [Google Scholar]
- Firmanto, A.; Sarno, R. Prediction of movie sentiment based on reviews and score on rotten tomatoes using sentiwordnet. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication, Semarang, Indonesia, 21–22 September 2018; pp. 202–206. [Google Scholar]
- Miranda, E.; Aryuni, M.; Hariyanto, R.; Surya, E.S. Sentiment Analysis using Sentiwordnet and Machine Learning Approach (Indonesia general election opinion from the twitter content). In Proceedings of the 2019 International Conference on Information Management and Technology (ICIMTech), Denpasar, Indonesia, 19–20 August 2019; Volume 1, pp. 62–67. [Google Scholar]
- Hong, J.; Nam, A.; Cai, A. Multi-Class Text Sentiment Analysis. 2019. Available online: http://cs229.stanford.edu/proj2019aut/data/assignment_308832_raw/26644050.pdf (accessed on 29 September 2021).
- Attia, M.; Samih, Y.; Elkahky, A.; Kallmeyer, L. Multilingual multi-class sentiment classification using convolutional neural networks. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Sharma, S.; Srivastava, S.; Kumar, A.; Dangi, A. Multi-Class Sentiment Analysis Comparison Using Support Vector Machine (SVM) and BAGGING Technique-An Ensemble Method. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), Kuala Lumpur, Malaysia, 11–12 July 2018; pp. 1–6. [Google Scholar]
- Liu, Y.; Bi, J.W.; Fan, Z.P. Multi-class sentiment classification: The experimental comparisons of feature selection and machine learning algorithms. Expert Syst. Appl. 2017, 80, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Richardson, L. Beautiful Soup Documentation. 2007. Available online: https://beautiful-soup-4.readthedocs.io/en/latest/ (accessed on 29 September 2021).
- Sharma, A.; Dey, S. Performance investigation of feature selection methods and sentiment lexicons for sentiment analysis. IJCA Spec. Issue Adv. Comput. Commun. Technol. HPC Appl. 2012, 3, 15–20. [Google Scholar]
- Rahman, A.; Hossen, M.S. Sentiment analysis on movie review data using machine learning approach. In Proceedings of the 2019 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 27–28 September 2019; pp. 1–4. [Google Scholar]
- Garain, A.; Mahata, S.K. Sentiment Analysis at SEPLN (TASS)-2019: Sentiment Analysis at Tweet Level Using Deep Learning. arXiv 2019, arXiv:1908.00321. [Google Scholar]
- Garain, A.; Mahata, S.K.; Dutta, S. Normalization of Numeronyms using NLP Techniques. In Proceedings of the 2020 IEEE Calcutta Conference (CALCON), Kolkata, India, 28–29 February 2020; pp. 7–9. [Google Scholar]
- Garain, A. Humor Analysis Based on Human Annotation (HAHA)-2019: Humor Analysis at Tweet Level Using Deep Learning. 2019. Available online: https://www.researchgate.net/publication/335022260_Humor_Analysis_based_on_Human_Annotation_HAHA-2019_Humor_Analysis_at_Tweet_Level_using_Deep_Learning (accessed on 29 September 2021).
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://spacy.io/ (accessed on 29 September 2021). [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, K.K.; Begum, S.; Sardar, A.; Adhikary, S.; Ghosh, M.; Kumar, M.; Sarkar, R. Theoretical and empirical analysis of filter ranking methods: Experimental study on benchmark DNA microarray data. Expert Syst. Appl. 2021, 169, 114485. [Google Scholar] [CrossRef]
- Forman, G. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 2003, 3, 1289–1305. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. 2017, 50, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Pandas Development Team. pandas-dev/pandas: Pandas 2020. Available online: https://zenodo.org/record/3630805#.YWD91o4zZPY (accessed on 29 September 2021). [CrossRef]
- Van Rossum, G. The Python Library Reference, Release 3.8.2; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Thongtan, T.; Phienthrakul, T. Sentiment classification using document embeddings trained with cosine similarity. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 28 July 2019; pp. 407–414. [Google Scholar]
- Yasen, M.; Tedmori, S. Movies Reviews sentiment analysis and classification. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 860–865. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Review | Sentiment | Corresponding Annotation |
|---|---|---|
| “Amazing. Steven Spielberg always makes masterpieces…” | Positive | 1 |
| “Mediocre performance by Jake Gyllenhaal. The plot is good, worth a watch…” | Neutral | 0 |
| “This movie is an utter disaster. This is nothing like the book, full of inaccuracies. A buff batman is unnatural…” | Negative | −1 |
| Dataset | Year of Creation | Year When Last Modified | No. of Reviews | No. of Classes |
|---|---|---|---|---|
| Polarity Dataset (Cornell) | 2002 | 2004 | 2000 | 2 |
| Large Movie Review Dataset (Stanford) | 2011 | - | 50,000 | 2 |
| Rotten Tomatoes Dataset | 2020 | - | 17,000 | 2 |
| STS-Gold | 2015 | 2016 | 2034 | 2 |
| JUMR v1.0 | 2021 | - | 1422 | 3 |
| Feature Selection | Features Selected | Classifier | F1-Score |
|---|---|---|---|
| Recursive (RF) | 150 | RF | 0.6667 |
| Recursive (RF) | XGB | 0.6667 | |
| Recursive (RF) | SVC | 0.6045 | |
| Recursive (XGB) | RF | 0.6384 | |
| Recursive (XGB) | XGB | 0.6384 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.6158 | |
| Chi-Squared | XGB | 0.7006 | |
| Chi-Squared | SVC | 0.6441 | |
| Mutual Info | RF | 0.6441 | |
| Mutual Info | XGB | 0.661 | |
| Mutual Info | SVC | 0.5593 | |
| F Classifier | RF | 0.6441 | |
| F Classifier | XGB | 0.6667 | |
| F Classifier | SVC | 0.565 | |
| Recursive (RF) | 100 | RF | 0.6553 |
| Recursive (RF) | XGB | 0.6327 | |
| Recursive (RF) | SVC | 0.6158 | |
| Recursive (XGB) | RF | 0.644 | |
| Recursive (XGB) | XGB | 0.644 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.644 | |
| Chi-Squared | XGB | 0.6836 | |
| Chi-Squared | SVC | 0.6666 | |
| Mutual Info | RF | 0.6779 | |
| Mutual Info | XGB | 0.6836 | |
| Mutual Info | SVC | 0.5649 | |
| F Classifier | RF | 0.6497 | |
| F Classifier | XGB | 0.6892 | |
| F Classifier | SVC | 0.5649 | |
| Recursive (RF) | 50 | RF | 0.644 |
| Recursive (RF) | XGB | 0.6779 | |
| Recursive (RF) | SVC | 0.6214 | |
| Recursive (XGB) | RF | 0.649717 | |
| Recursive (XGB) | XGB | 0.649715 | |
| Recursive (XGB) | SVC | 0.6271 | |
| Chi-Squared | RF | 0.6779 | |
| Chi-Squared | XGB | 0.6723 | |
| Chi-Squared | SVC | 0.6666 | |
| Mutual Info | RF | 0.644 | |
| Mutual Info | XGB | 0.6836 | |
| Mutual Info | SVC | 0.5932 | |
| F Classifier | RF | 0.6892 | |
| F Classifier | XGB | 0.6553 | |
| F Classifier | SVC | 0.6327 |
| Feature Selection | Features Selected | Classifier | F1 Score |
|---|---|---|---|
| Recursive (RF) | 150 | RF | 0.6667 |
| Recursive (RF) | XGB | 0.6667 | |
| Recursive (RF) | SVC | 0.6045 | |
| Recursive (XGB) | RF | 0.6384 | |
| Recursive (XGB) | XGB | 0.6384 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.6158 | |
| Chi-Squared | XGB | 0.7006 | |
| Chi-Squared | SVC | 0.6441 | |
| Mutual Info | RF | 0.6441 | |
| Mutual Info | XGB | 0.661 | |
| Mutual Info | SVC | 0.5593 | |
| F Classifier | RF | 0.6441 | |
| F Classifier | XGB | 0.6667 | |
| F Classifier | SVC | 0.565 | |
| Recursive (RF) | 100 | RF | 0.6723 |
| Recursive (RF) | XGB | 0.6949 | |
| Recursive (RF) | SVC | 0.6723 | |
| Recursive (XGB) | RF | 0.6553 | |
| Recursive (XGB) | XGB | 0.6553 | |
| Recursive (XGB) | SVC | 0.6949 | |
| Chi-Squared | RF | 0.661 | |
| Chi-Squared | XGB | 0.6497 | |
| Chi-Squared | SVC | 0.6949 | |
| Mutual Info | RF | 0.6497 | |
| Mutual Info | XGB | 0.6271 | |
| Mutual Info | SVC | 0.6271 | |
| F Classifier | RF | 0.6497 | |
| F Classifier | XGB | 0.6836 | |
| F Classifier | SVC | 0.6666 | |
| Recursive (RF) | 50 | RF | 0.661 |
| Recursive (RF) | XGB | 0.6949 | |
| Recursive (RF) | SVC | 0.712 | |
| Recursive (XGB) | RF | 0.678 | |
| Recursive (XGB) | XGB | 0.678 | |
| Recursive (XGB) | SVC | 0.7006 | |
| Chi-Squared | RF | 0.695 | |
| Chi-Squared | XGB | 0.6892 | |
| Chi-Squared | SVC | 0.6892 | |
| Mutual Info | RF | 0.7006 | |
| Mutual Info | XGB | 0.6441 | |
| Mutual Info | SVC | 0.6497 | |
| F Classifier | RF | 0.6836 | |
| F Classifier | XGB | 0.6271 | |
| F Classifier | SVC | 0.6836 |
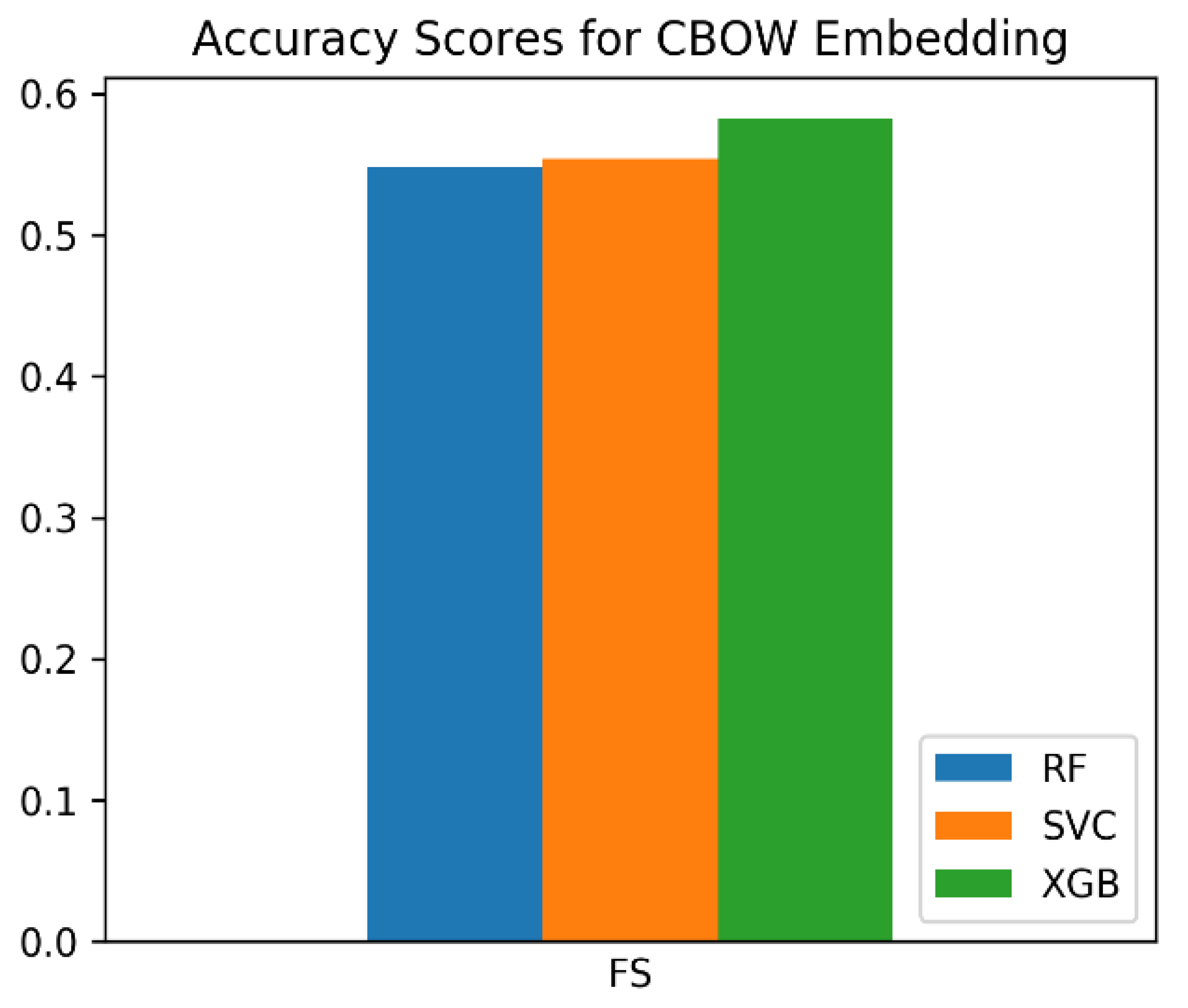
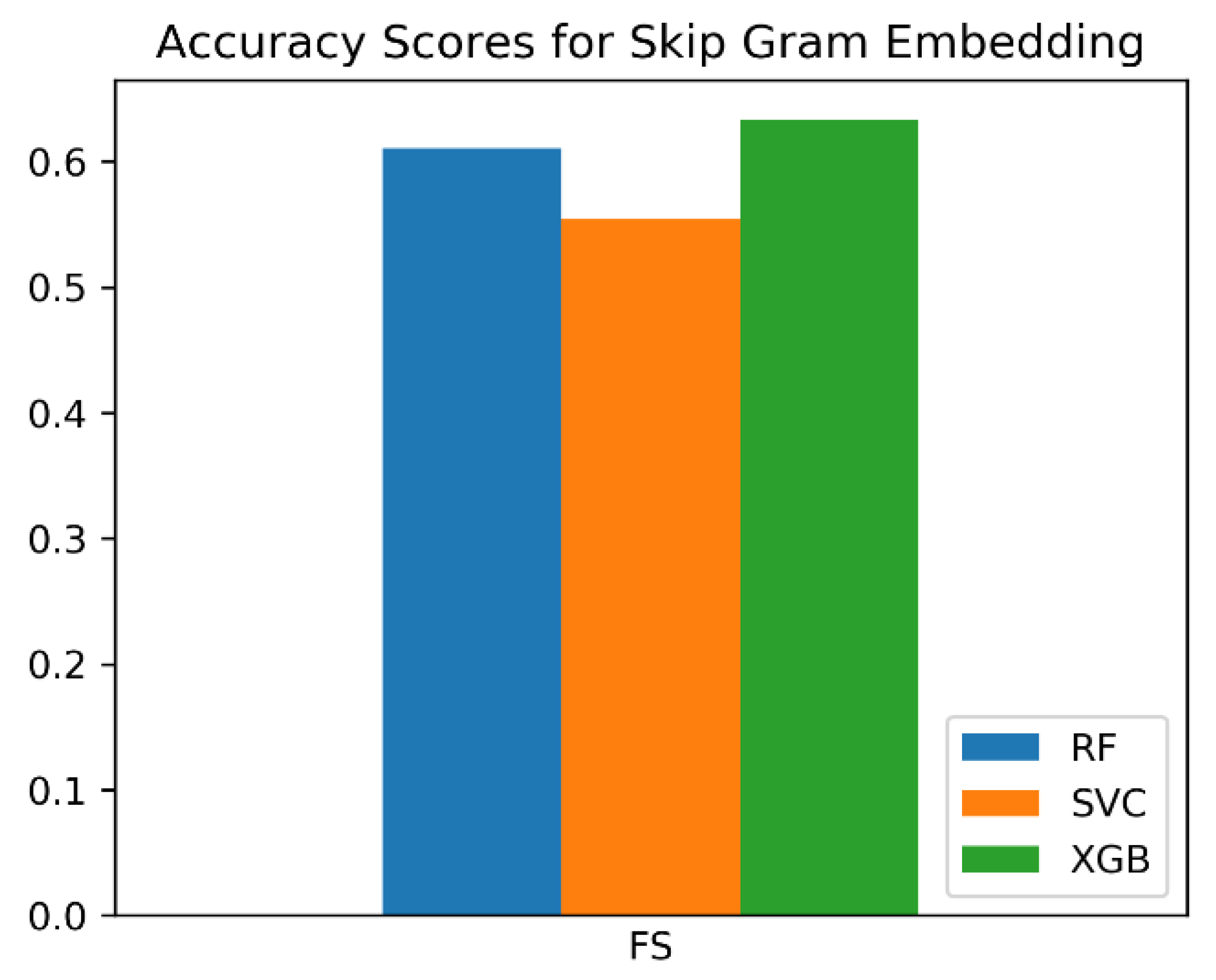
| Embedding | Classifier | F1 Score |
|---|---|---|
| CBOW | RF | 0.54802 |
| CBOW | XGB | 0.58192 |
| CBOW | SVC | 0.55367 |
| Skipgram | SVC | 0.55367 |
| Skipgram | RF | 0.61017 |
| Skipgram | XGB | 0.63277 |
| 26 | 6 | 16 |
| 5 | 4 | 22 |
| 2 | 5 | 91 |
| 26 | 3 | 19 |
| 5 | 3 | 23 |
| 3 | 2 | 93 |
| 25 | 4 | 19 |
| 3 | 2 | 26 |
| 3 | 1 | 94 |
| 25 | 4 | 19 |
| 3 | 2 | 26 |
| 3 | 1 | 94 |
| 28 | 4 | 16 |
| 5 | 4 | 22 |
| 2 | 6 | 90 |
| 24 | 5 | 19 |
| 5 | 5 | 21 |
| 2 | 3 | 93 |
| 25 | 6 | 17 |
| 6 | 5 | 20 |
| 1 | 3 | 94 |
| 26 | 8 | 14 |
| 4 | 5 | 22 |
| 2 | 3 | 93 |
| 24 | 5 | 19 |
| 5 | 5 | 21 |
| 2 | 3 | 93 |
| 24 | 5 | 19 |
| 5 | 5 | 21 |
| 2 | 3 | 93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, S.; Chakrabarti, K.; Garain, A.; Schwenker, F.; Sarkar, R. JUMRv1: A Sentiment Analysis Dataset for Movie Recommendation. Appl. Sci. 2021, 11, 9381. https://doi.org/10.3390/app11209381
Chatterjee S, Chakrabarti K, Garain A, Schwenker F, Sarkar R. JUMRv1: A Sentiment Analysis Dataset for Movie Recommendation. Applied Sciences. 2021; 11(20):9381. https://doi.org/10.3390/app11209381
Chicago/Turabian StyleChatterjee, Shuvamoy, Kushal Chakrabarti, Avishek Garain, Friedhelm Schwenker, and Ram Sarkar. 2021. "JUMRv1: A Sentiment Analysis Dataset for Movie Recommendation" Applied Sciences 11, no. 20: 9381. https://doi.org/10.3390/app11209381
APA StyleChatterjee, S., Chakrabarti, K., Garain, A., Schwenker, F., & Sarkar, R. (2021). JUMRv1: A Sentiment Analysis Dataset for Movie Recommendation. Applied Sciences, 11(20), 9381. https://doi.org/10.3390/app11209381