Iterative Learning for K-Approval Votes in Crowdsourcing Systems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
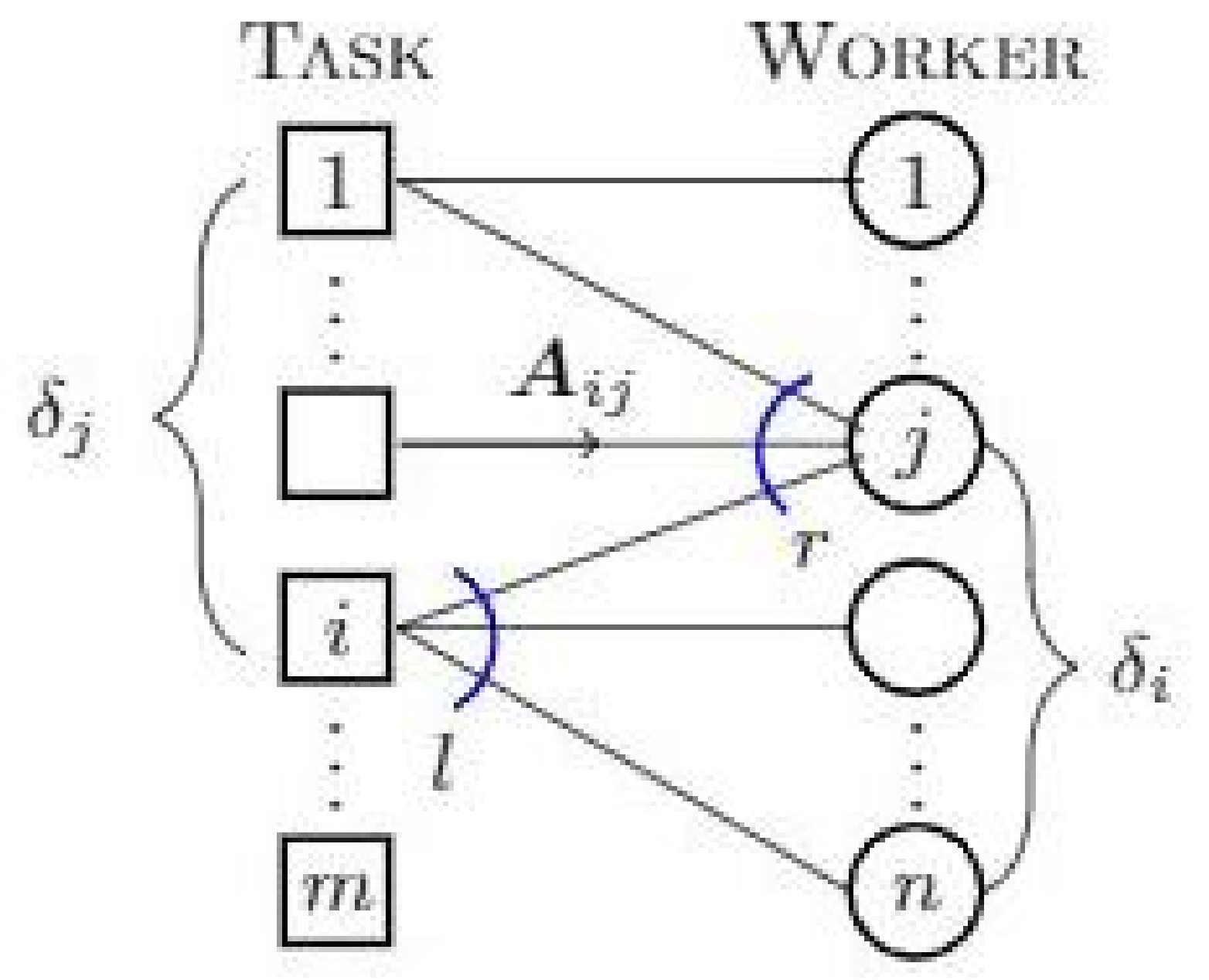
3. Setup
3.1. Problem Definition
3.2. Worker Model for Various (D, K)
4. Algorithms
5. Analysis of Algorithms
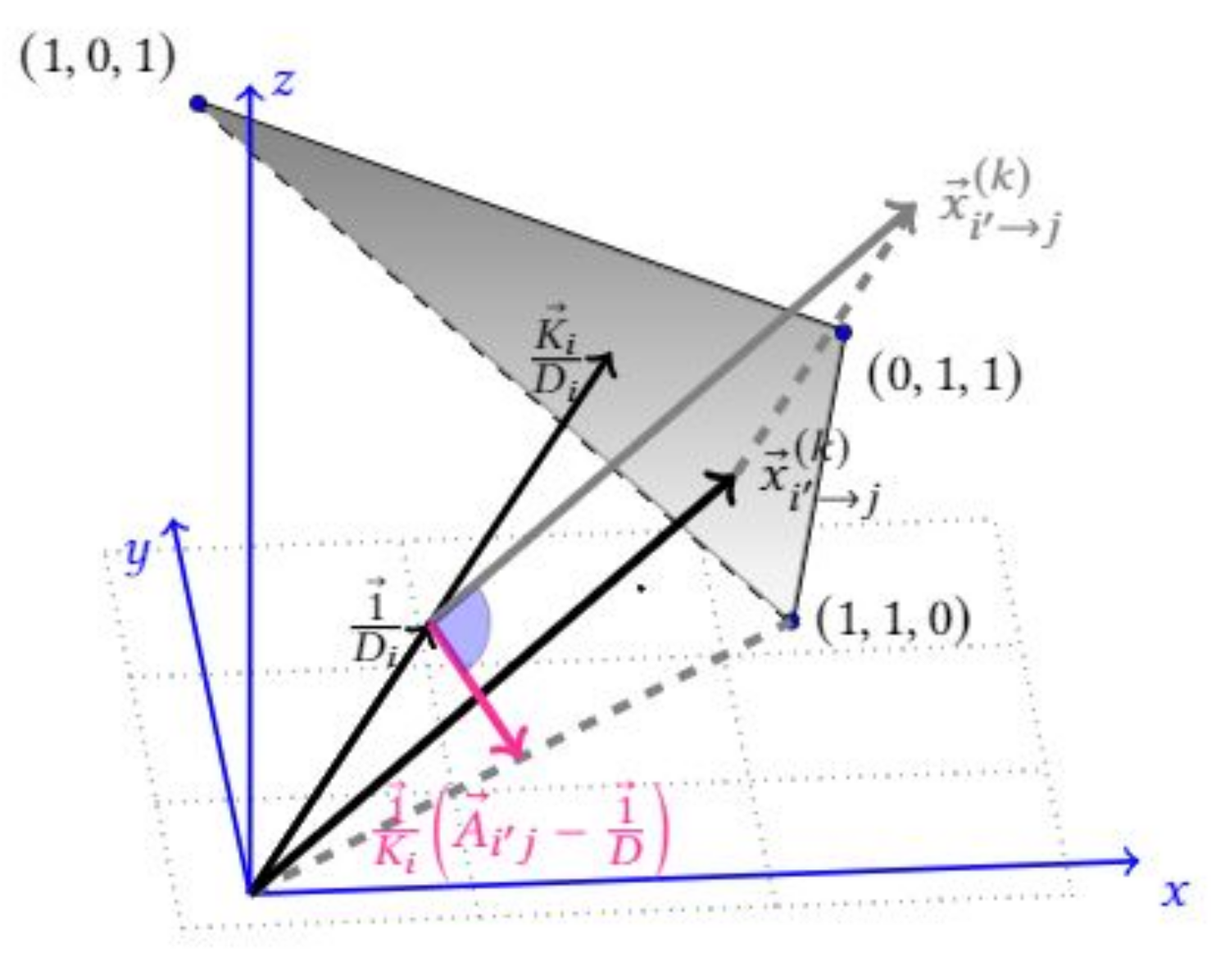
5.1. Quality of Workers
| Algorithm 1K-approval Iterative Algorithm |
Input:E, , Output: Estimation Fordo Initialize with random repeat fordo end for until Final Estimation Fordo Fordo Estimated answer: where |
5.2. Bound on the Average Error Probability
5.3. Proof of the Theorem 1
5.4. Phase Transition
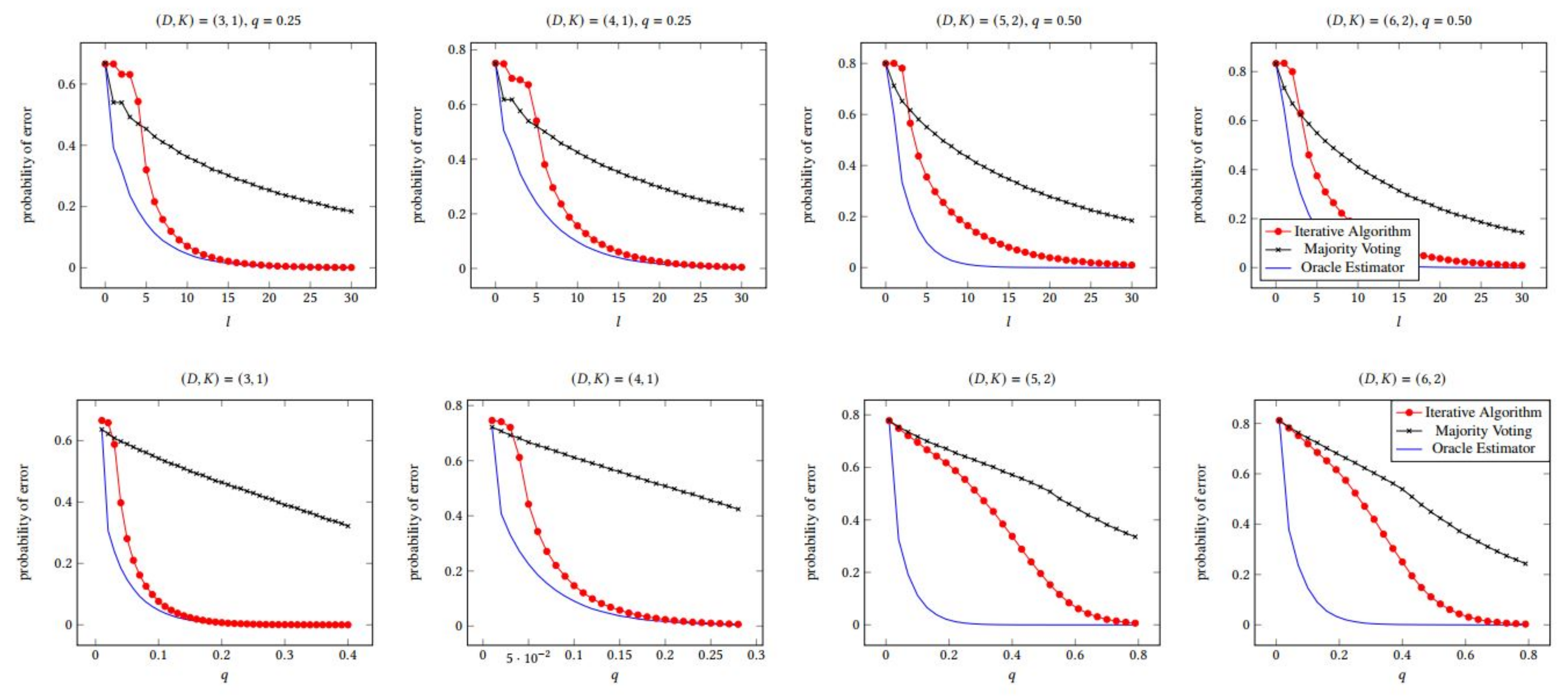
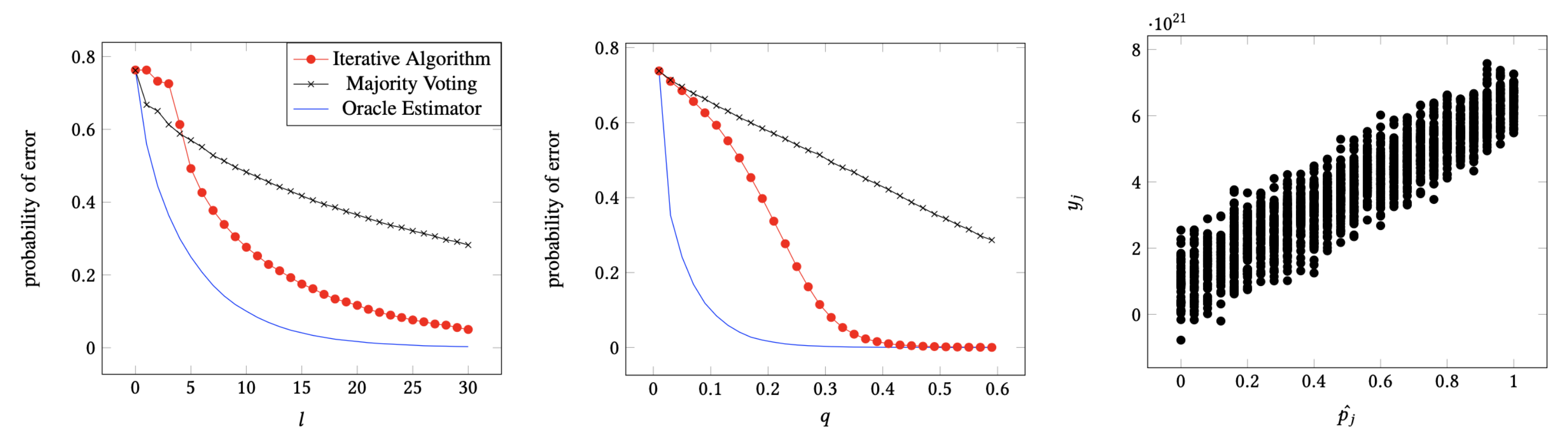
6. Experiments
6.1. Error Performance with q and l
6.2. Relationship between Reliability and y-Message
6.3. Error Performance with Various (D,K) Pairs
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Sub-Gaussianity
References
- Kittur, A.; Chi, E.H.; Suh, B. Crowdsourcing user studies with Mechanical Turk. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 453–456. [Google Scholar]
- Lintott, C.J.; Schawinski, K.; Slosar, A.; Land, K.; Bamford, S.; Thomas, D.; Raddick, M.J.; Nichol, R.C.; Szalay, A.; Andreescu, D.; et al. Galaxy Zoo: Morphologies derived from visual inspection of galaxies from the Sloan Digital Sky Survey. Mon. Not. R. Astron. Soc. 2008, 389, 1179–1189. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sheng, V.S.; Provost, F.; Ipeirotis, P.G. Get another label? improving data quality and data mining using multiple, noisy labelers. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 614–622. [Google Scholar]
- Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and fast—But is it good?: Evaluating non-expert annotations for natural language tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Honolulu, HI, USA, 8–11 October 2008; pp. 254–263. [Google Scholar]
- Ipeirotis, P.G.; Provost, F.; Wang, J. Quality management on amazon mechanical turk. In Proceedings of the ACM SIGKDD workshop on human computation, Washington, DC, USA, 24–28 July 2010; pp. 64–67. [Google Scholar]
- Kazai, G.; Kamps, J.; Milic-Frayling, N. An analysis of human factors and label accuracy in crowdsourcing relevance judgments. Inf. Retr. 2013, 16, 138–178. [Google Scholar] [CrossRef]
- Raykar, V.C.; Yu, S.; Zhao, L.H.; Valadez, G.H.; Florin, C.; Bogoni, L.; Moy, L. Learning from crowds. J. Mach. Learn. Res. 2010, 11, 1297–1322. [Google Scholar]
- Dawid, A.P.; Skene, A.M. Maximum likelihood estimation of observer error-rates using the EM algorithm. Appl. Stat. 1979, 28, 20–28. [Google Scholar] [CrossRef]
- Whitehill, J.; Wu, T.F.; Bergsma, J.; Movellan, J.R.; Ruvolo, P.L. Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. Adv. Neural Inf. Process. Syst. 2009, 22, 2035–2043. [Google Scholar]
- Welinder, P.; Branson, S.; Perona, P.; Belongie, S.J. The multidimensional wisdom of crowds. Adv. Neural Inf. Process. Syst. 2010, 23, 2424–2432. [Google Scholar]
- Zhang, Y.; Chen, X.; Zhou, D.; Jordan, M.I. Spectral methods meet EM: A provably optimal algorithm for crowdsourcing. Adv. Neural Inf. Process. Syst. 2014, 27, 1260–1268. [Google Scholar]
- Karger, D.R.; Oh, S.; Shah, D. Iterative learning for reliable crowdsourcing systems. Adv. Neural Inf. Process. Syst. 2011, 24, 1953–1961. [Google Scholar]
- Karger, D.R.; Oh, S.; Shah, D. Budget-optimal crowdsourcing using low-rank matrix approximations. In Proceedings of the 2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 28–30 September 2011; pp. 284–291. [Google Scholar]
- Liu, Q.; Peng, J.; Ihler, A. Variational inference for crowdsourcing. Adv. Neural Inf. Process. Syst. 2012, 25, 692–700. [Google Scholar]
- Dalvi, N.; Dasgupta, A.; Kumar, R.; Rastogi, V. Aggregating crowdsourced binary ratings. In Proceedings of the 22nd international conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 285–294. [Google Scholar]
- Lee, D.; Kim, J.; Lee, H.; Jung, K. Reliable Multiple-choice Iterative Algorithm for Crowdsourcing Systems. ACM Sigmetr. Perform. Eval. Rev. 2015, 4, 205–216. [Google Scholar] [CrossRef]
- Ma, Y.; Olshevsky, A.; Saligrama, V.; Szepesvari, C. Crowdsourcing with Sparsely Interacting Workers. arXiv 2017, arXiv:1706.06660. [Google Scholar]
- Su, H.; Deng, J.; Li, F.-F. Crowdsourcing annotations for visual object detection. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 1. [Google Scholar]
- Shah, N.B.; Zhou, D.; Peres, Y. Approval Voting and Incentives in Crowdsourcing. arXiv 2015, arXiv:1502.05696. [Google Scholar]
- Procaccia, A.D.; Shah, N. Is Approval Voting Optimal Given Approval Votes? Adv. Neural Inf. Process. Syst. 2015, 28, 1792–1800. [Google Scholar]
- Salek, M.; Bachrach, Y. Hotspotting-a probabilistic graphical model for image object localization through crowdsourcing. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Zhou, D.; Liu, Q.; Platt, J.C.; Meek, C. Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 14, pp. 262–270. [Google Scholar]
- Karger, D.R.; Oh, S.; Shah, D. Efficient crowdsourcing for multi-class labeling. In Proceedings of the ACM SIGMETRICS/International Conference on Measurement and Modeling of Computer Systems, Pittsburgh, PA, USA, 17–21 June 2013; pp. 81–92. [Google Scholar]
- Kim, J.; Lee, D.; Jung, K. Reliable Aggregation Method for Vector Regression Tasks in Crowdsourcing. In Lecture Notes in Computer Science, Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 11–14 May 2020; Springer: Cham, Switzerland, 2020; pp. 261–273. [Google Scholar]
- Kamar, E.; Hacker, S.; Horvitz, E. Combining human and machine intelligence in large-scale crowdsourcing. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 1, International Foundation for Autonomous Agents and Multiagent Systems, Spain, Valencia, 4–8 June 2012; pp. 467–474. [Google Scholar]
- Branson, S.; Van Horn, G.; Perona, P. Lean Crowdsourcing: Combining Humans and Machines in an Online System. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Van Horn, G.; Branson, S.; Loarie, S.; Belongie, S.; Perona, P. Lean multiclass crowdsourcing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2714–2723. [Google Scholar]
- Yin, X.; Wang, H.; Wang, W.; Zhu, K. Task recommendation in crowdsourcing systems: A bibliometric analysis. Technol. Soc. 2020, 63, 101337. [Google Scholar] [CrossRef]
- Zhou, C.; Tham, C.K.; Motani, M. Online auction for scheduling concurrent delay tolerant tasks in crowdsourcing systems. Comput. Netw. 2020, 169, 107045. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef]
- Basiri, M.E.; Kabiri, A. Words are important: Improving sentiment analysis in the Persian language by lexicon refining. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2018, 17, 1–18. [Google Scholar] [CrossRef]
- Ye, B.; Wang, Y.; Liu, L. Crowd trust: A context-aware trust model for worker selection in crowdsourcing environments. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 121–128. [Google Scholar]
- Cui, Q.; Wang, S.; Wang, J.; Hu, Y.; Wang, Q.; Li, M. Multi-Objective Crowd Worker Selection in Crowdsourced Testing. In Proceedings of the SEKE, Pittsburgh, PA, USA, 5–7 July 2017; Volume 17, pp. 1–6. [Google Scholar]
- Vargas-Santiago, M.; Monroy, R.; Ramirez-Marquez, J.E.; Zhang, C.; Leon-Velasco, D.A.; Zhu, H. Complementing Solutions to Optimization Problems via Crowdsourcing on Video Game Plays. Appl. Sci. 2020, 10, 8410. [Google Scholar] [CrossRef]
- Moayedikia, A.; Yeoh, W.; Ong, K.L.; Boo, Y.L. Improving accuracy and lowering cost in crowdsourcing through an unsupervised expertise estimation approach. Decis. Support Syst. 2019, 122, 113065. [Google Scholar] [CrossRef]
- Karger, D.R.; Oh, S.; Shah, D. Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems. Oper. Res. 2014, 62, 1–24. [Google Scholar] [CrossRef]
- Alon, N.; Spencer, J.H. The Probabilistic Method; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Lee, D.; Jung, K. Iterative Learning for K-Approval Votes in Crowdsourcing Systems. Appl. Sci. 2021, 11, 630. https://doi.org/10.3390/app11020630
Kim J, Lee D, Jung K. Iterative Learning for K-Approval Votes in Crowdsourcing Systems. Applied Sciences. 2021; 11(2):630. https://doi.org/10.3390/app11020630
Chicago/Turabian StyleKim, Joonyoung, Donghyeon Lee, and Kyomin Jung. 2021. "Iterative Learning for K-Approval Votes in Crowdsourcing Systems" Applied Sciences 11, no. 2: 630. https://doi.org/10.3390/app11020630
APA StyleKim, J., Lee, D., & Jung, K. (2021). Iterative Learning for K-Approval Votes in Crowdsourcing Systems. Applied Sciences, 11(2), 630. https://doi.org/10.3390/app11020630