Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet

 ,
,  ,
,
Abstract
:1. Introduction
2. Literature Review
3. Methodology
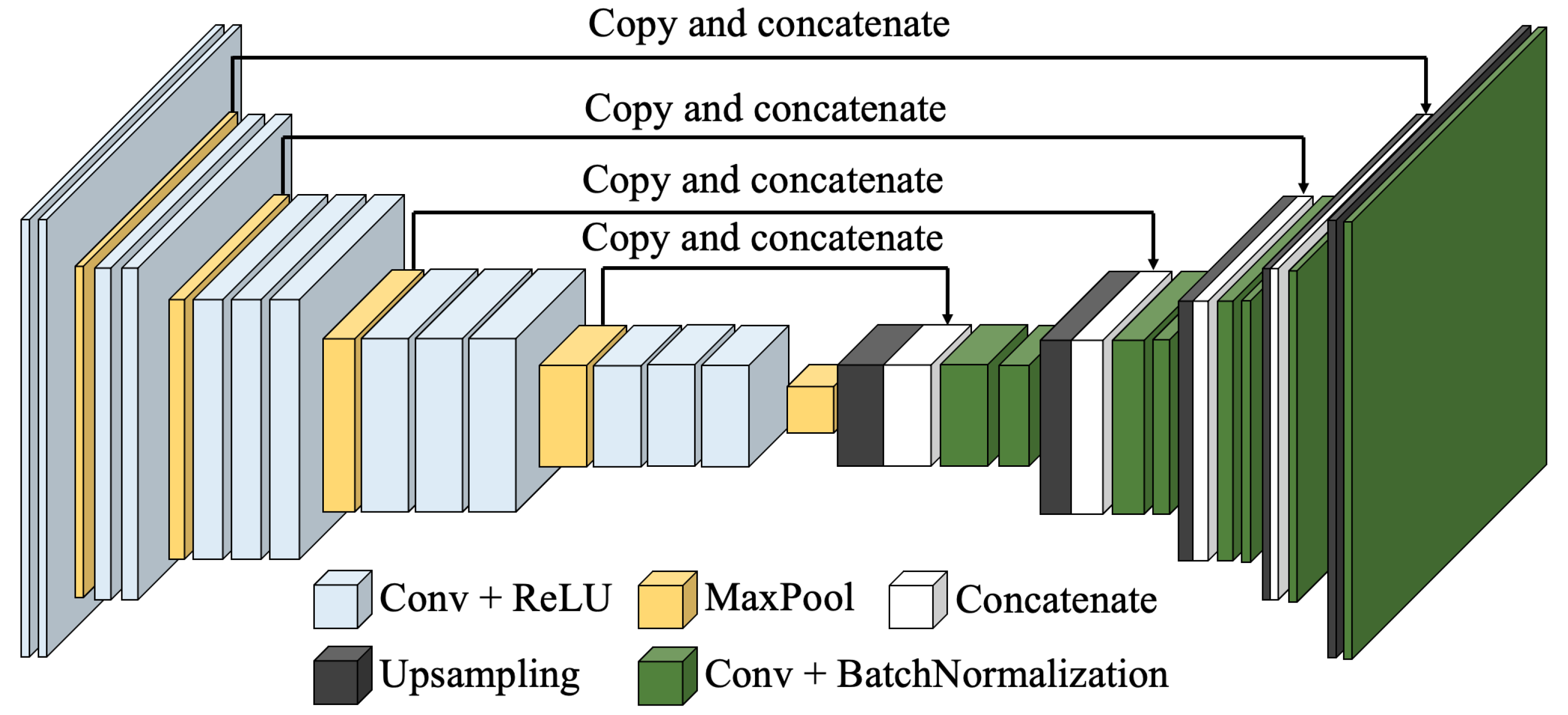
3.1. Structure of VGG-Unet
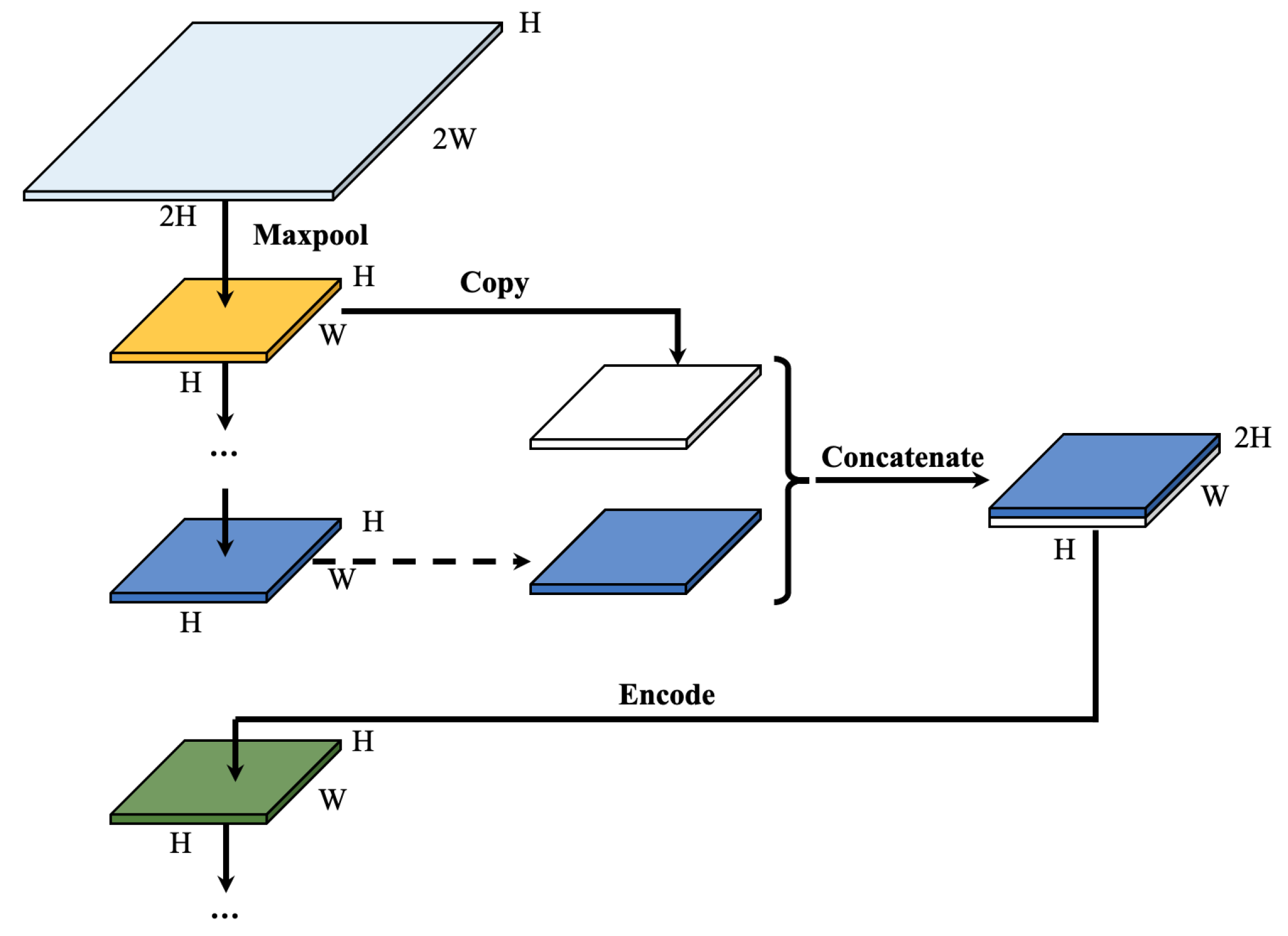
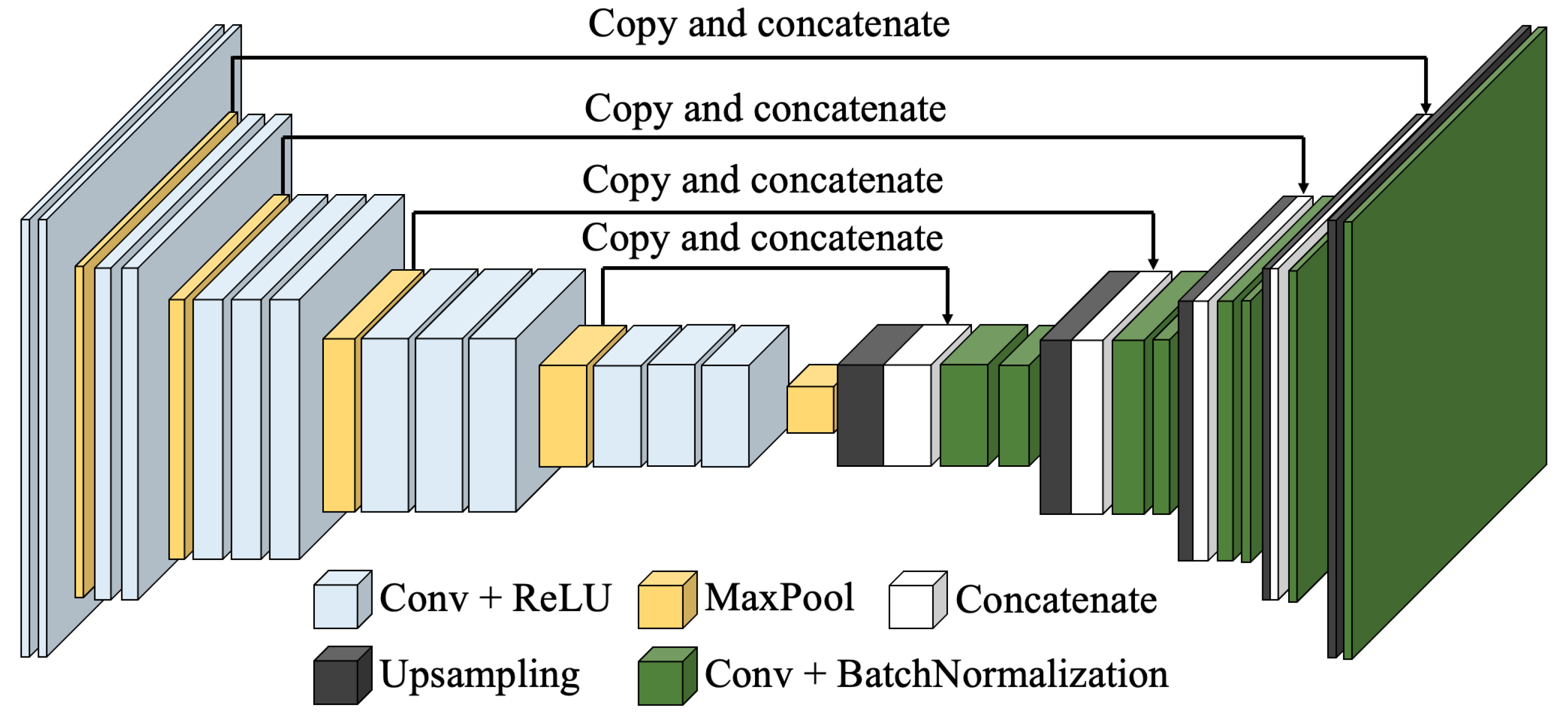
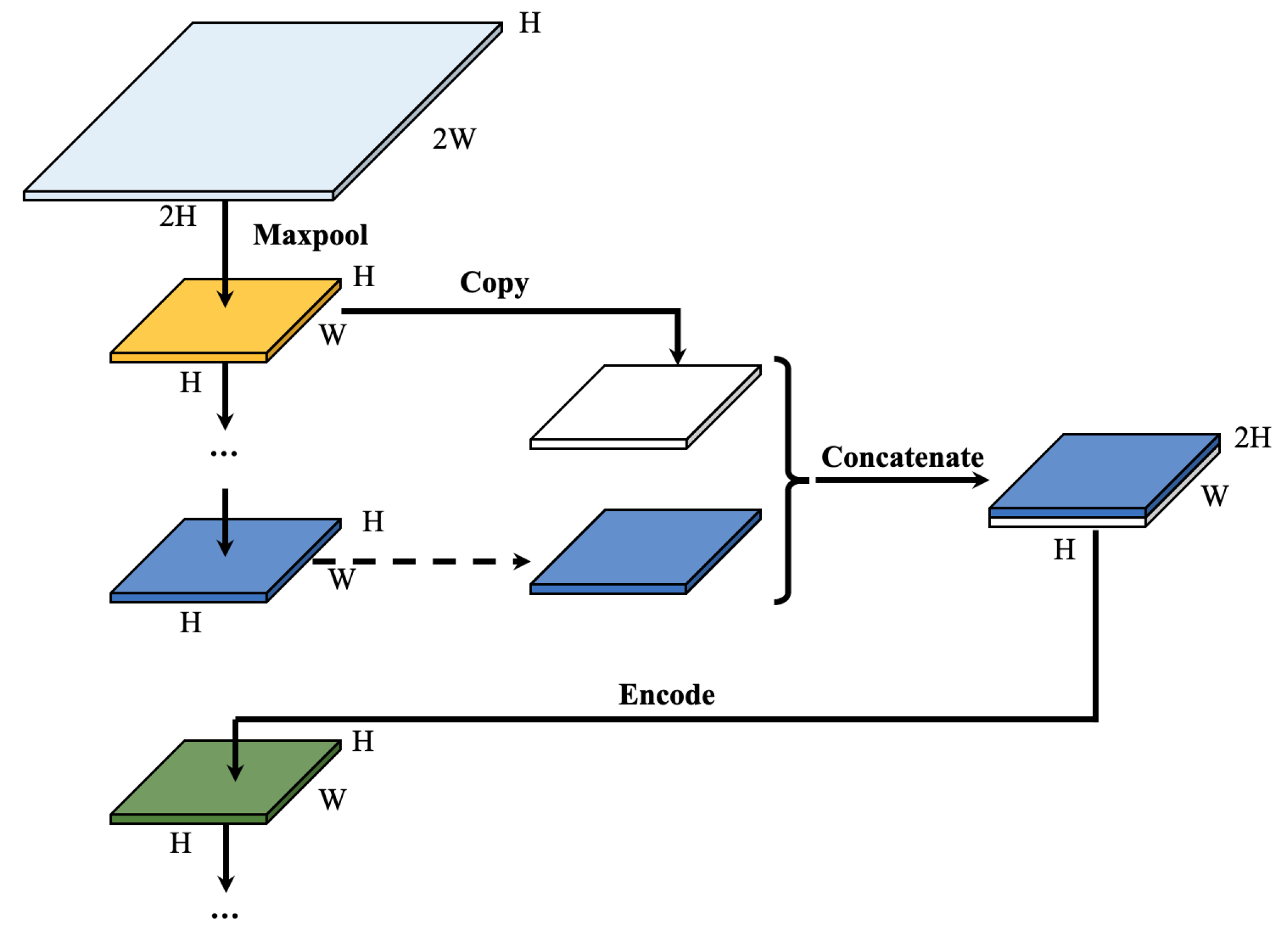
3.1.1. Overall Structure of VGG-Unet
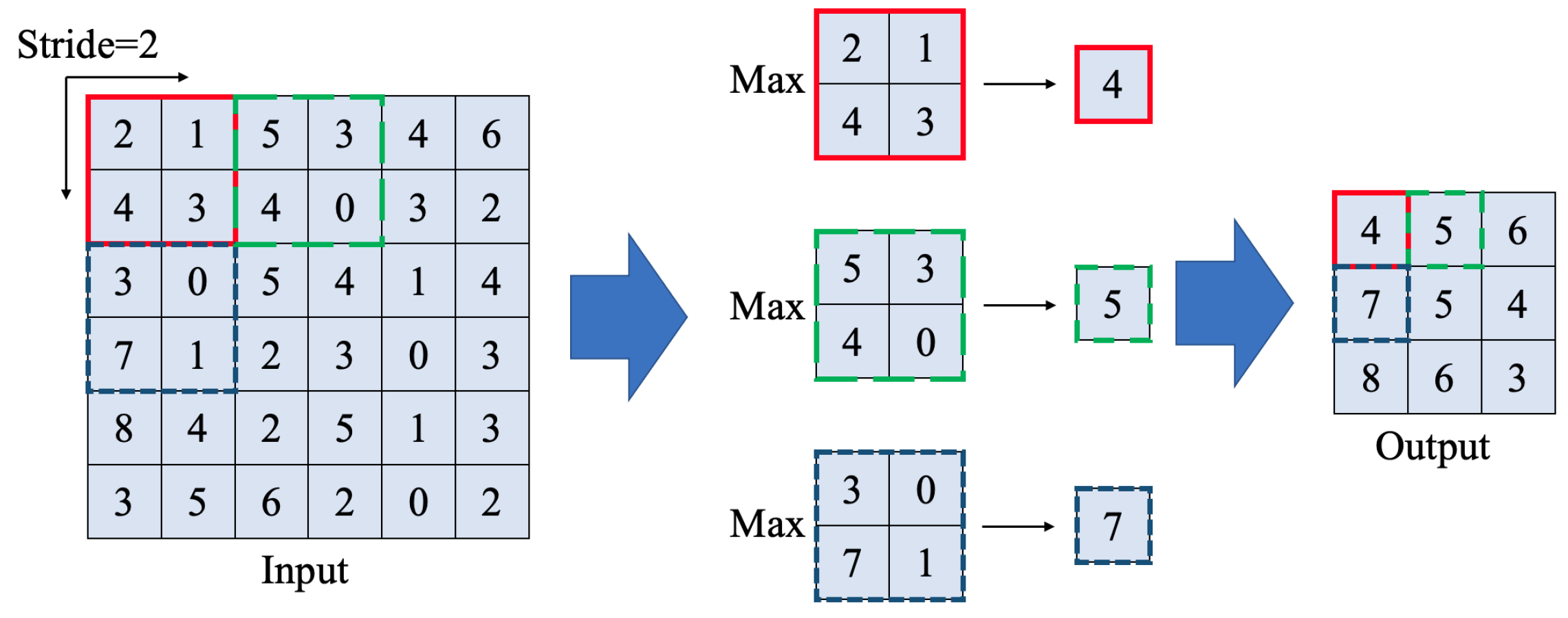
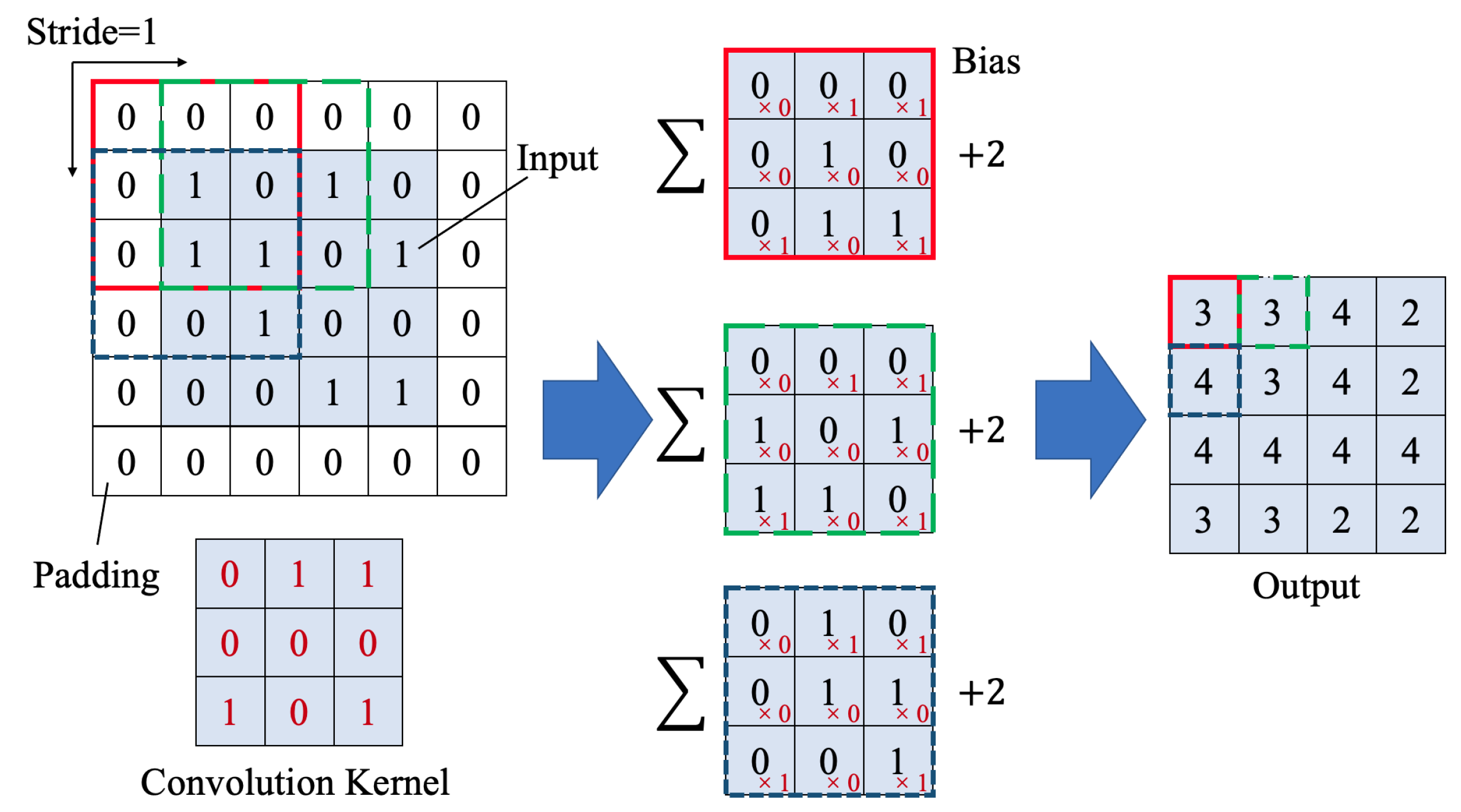
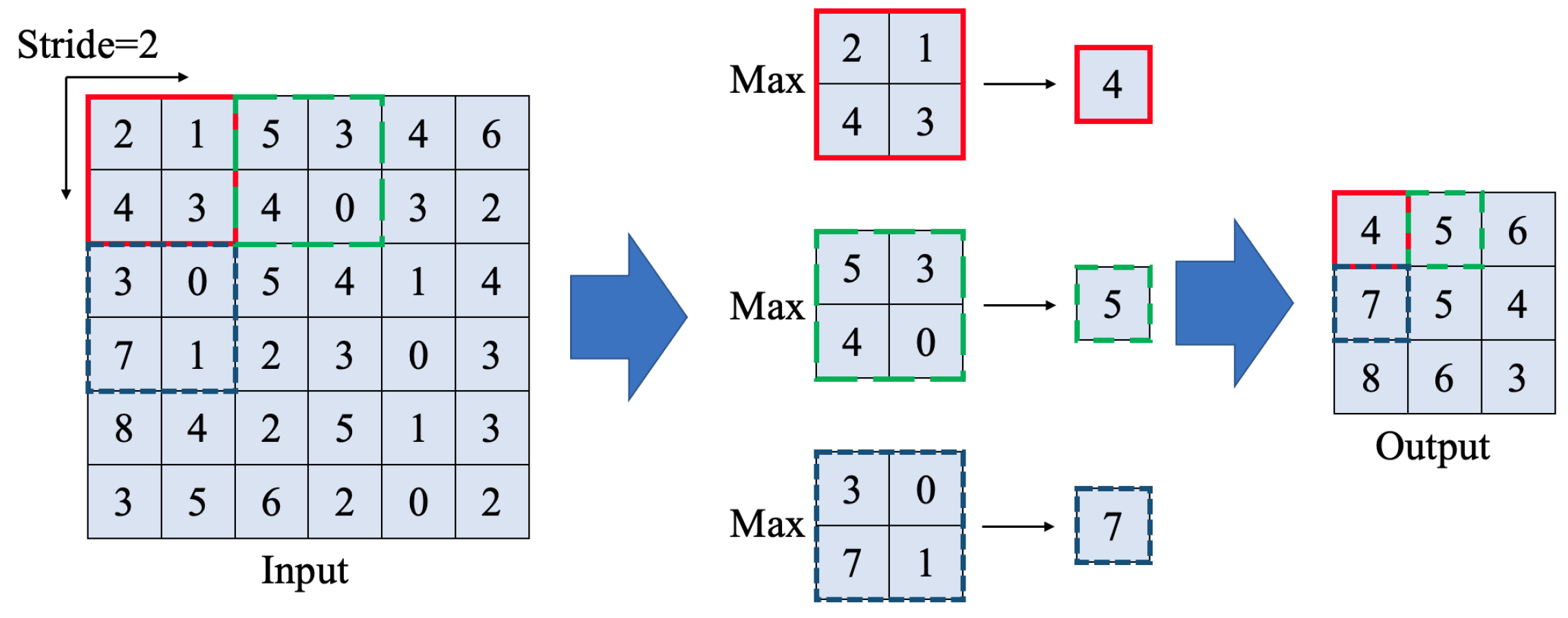
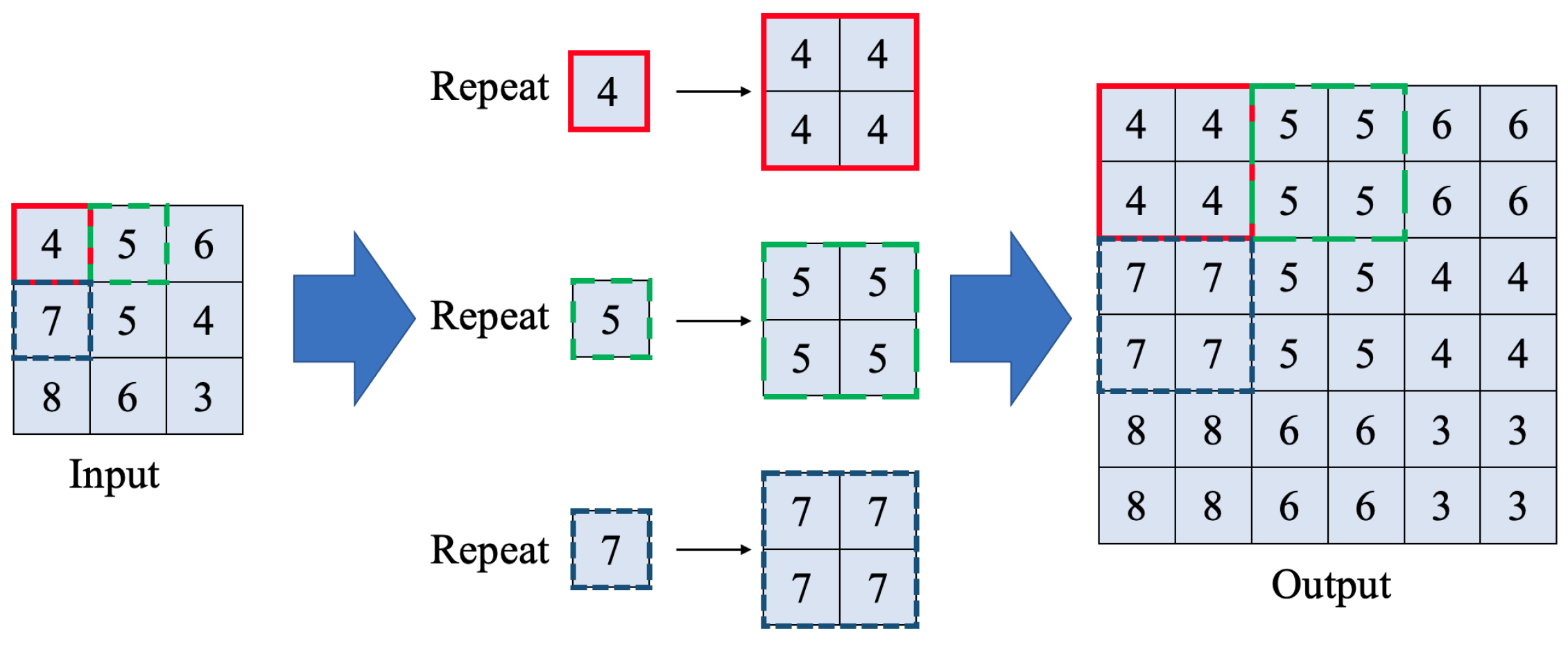
3.1.2. Layers
3.2. Process of Training and Predicting
4. Building Data Set and Choosing Configurations
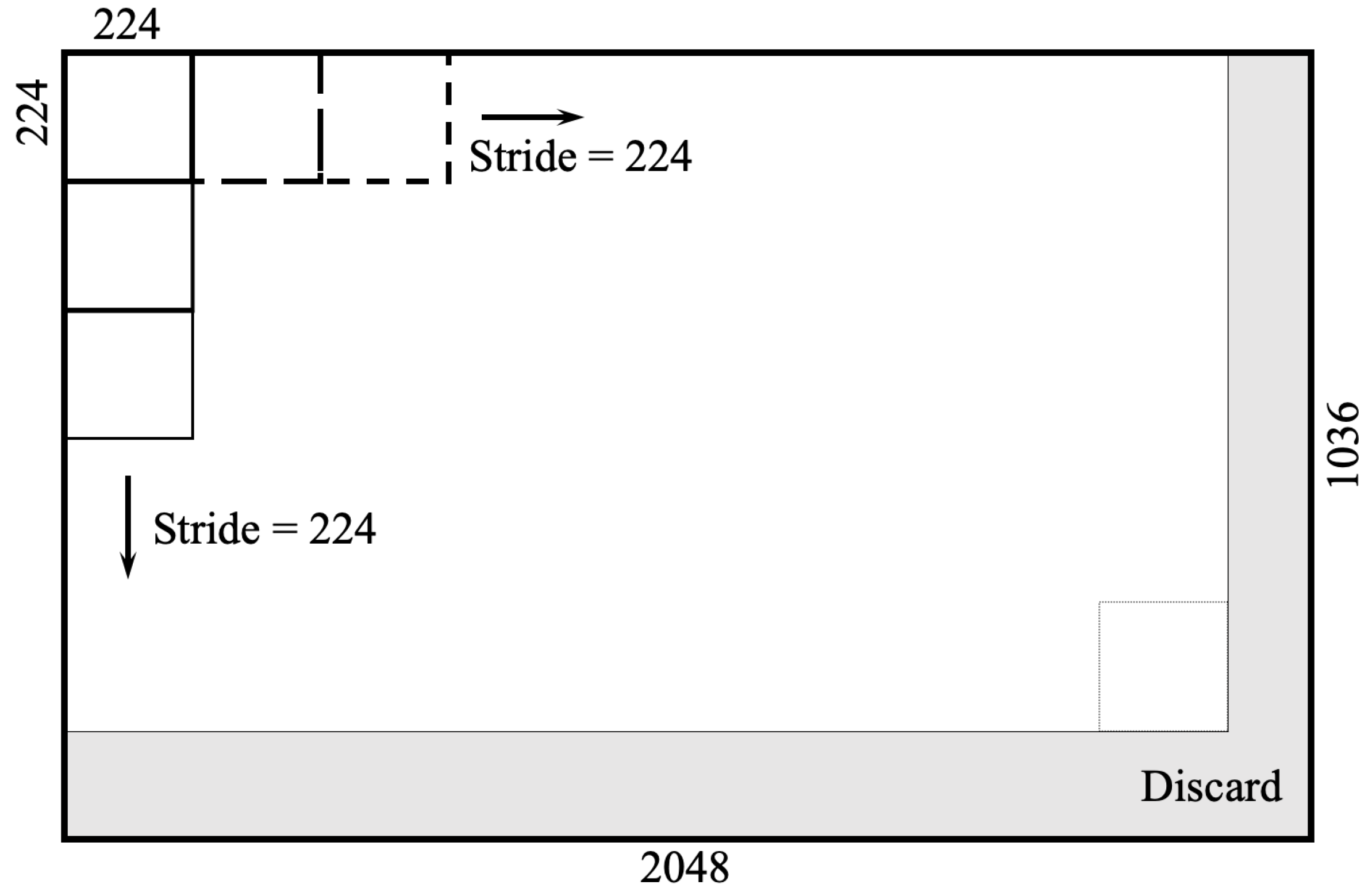
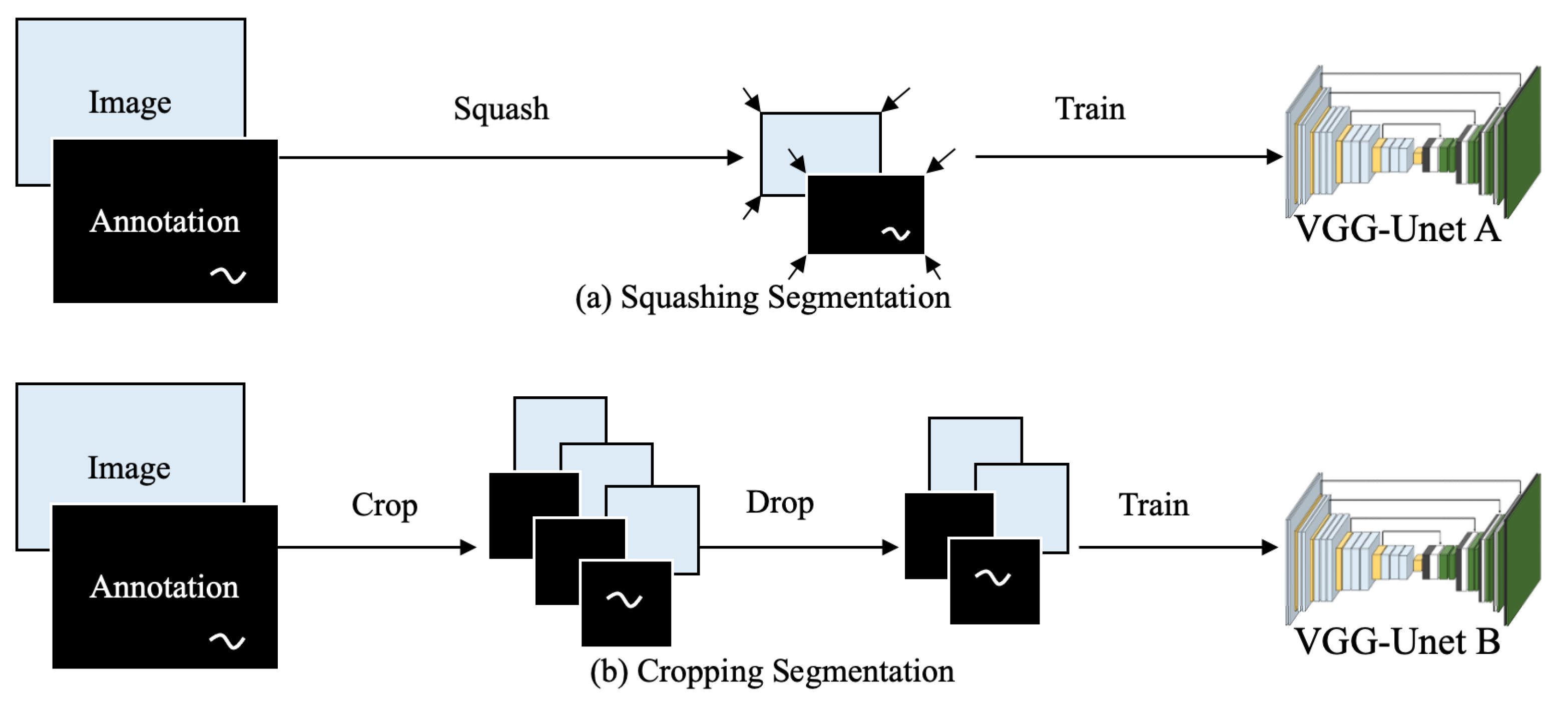
4.1. Damage Images and Annotations
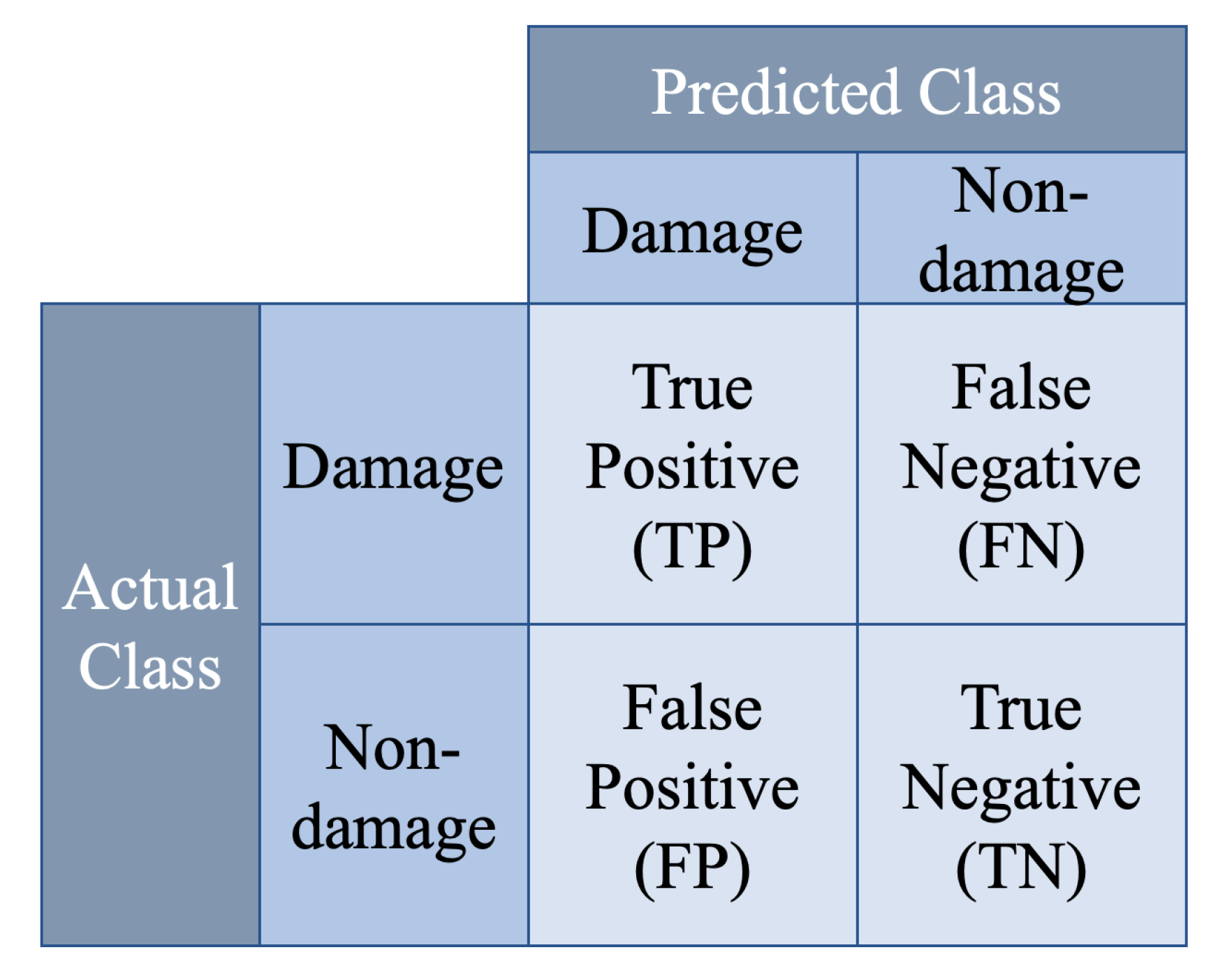
4.2. Evaluation Method for Accuracy
5. Results and Evaluation
6. Pixel-Level Data Balance
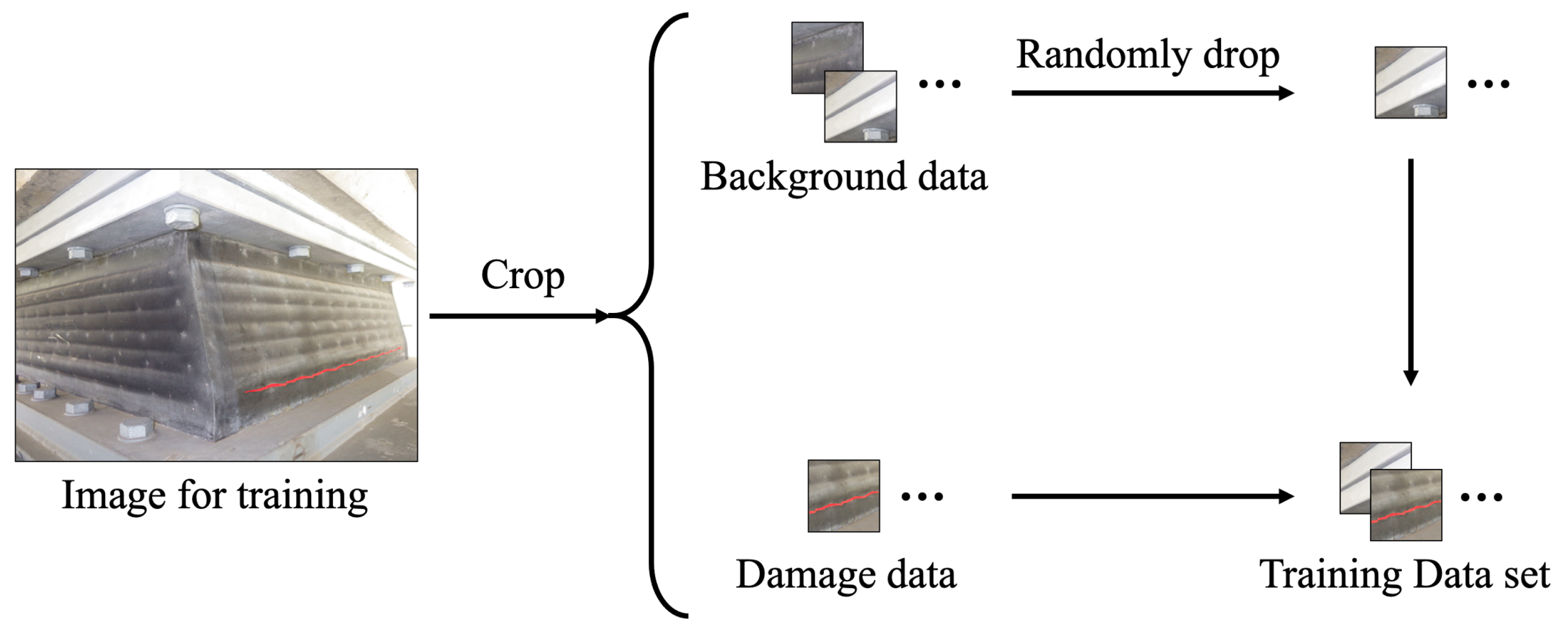
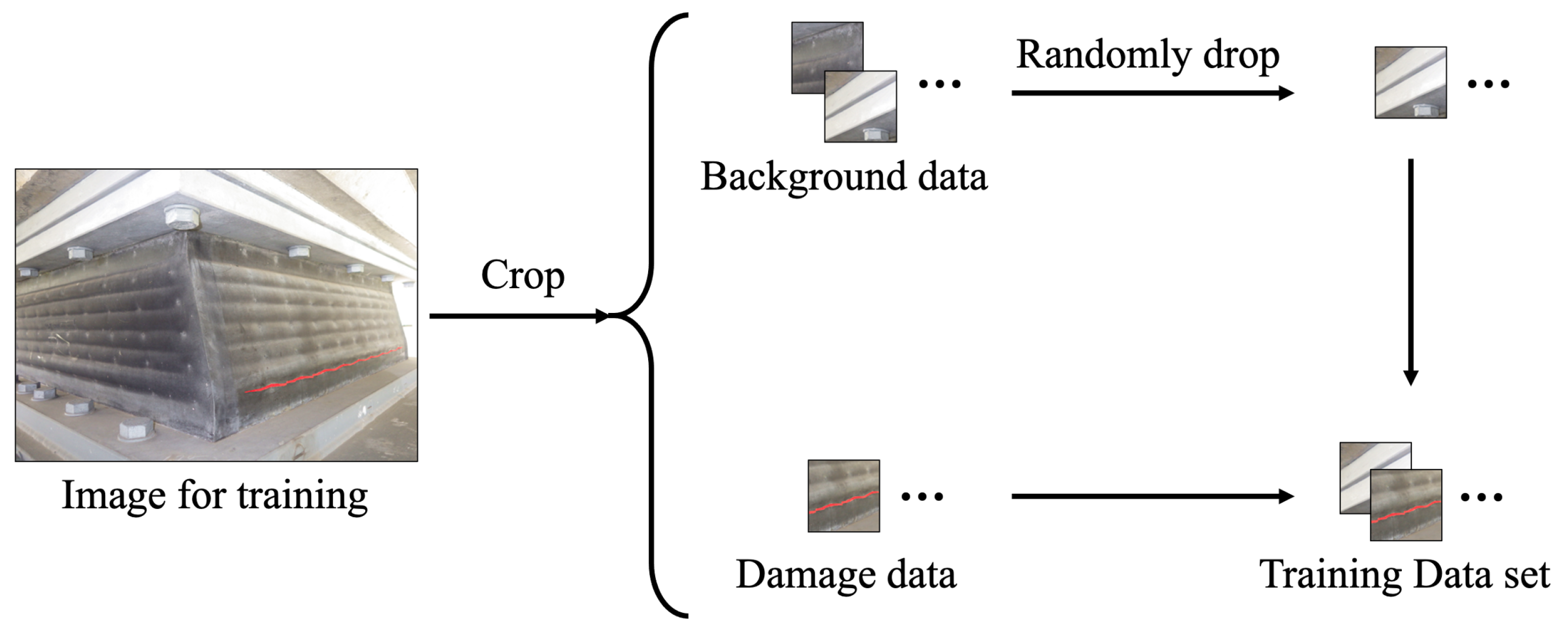
6.1. Process
6.2. Results
7. Conclusions
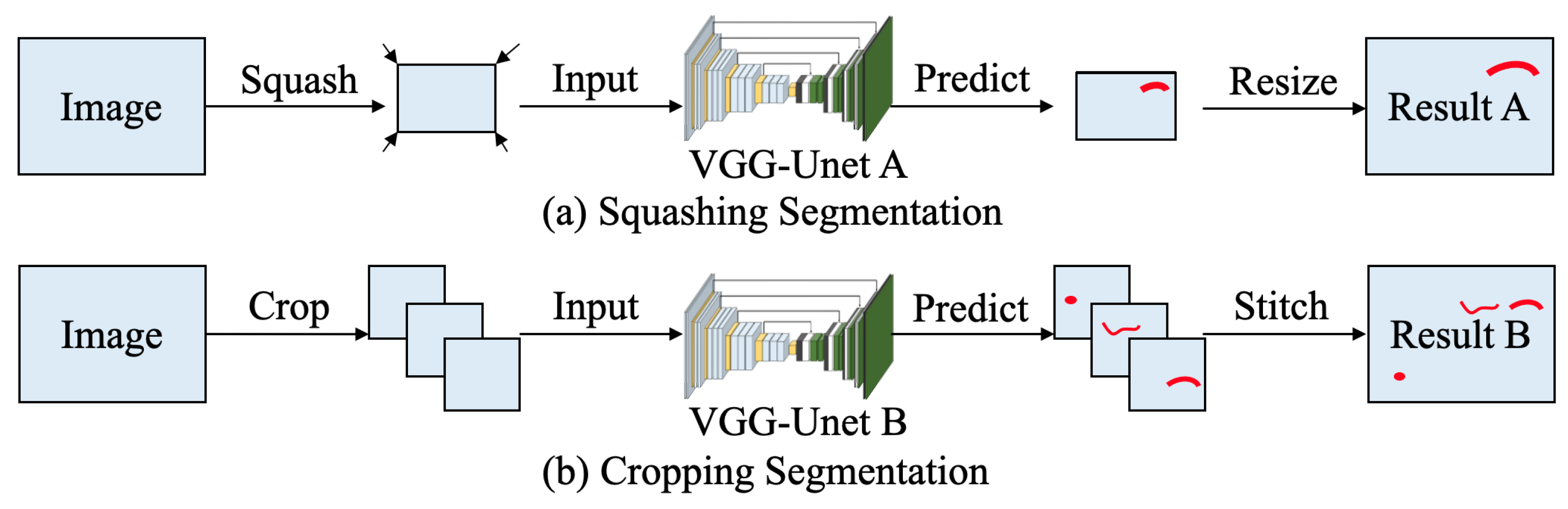
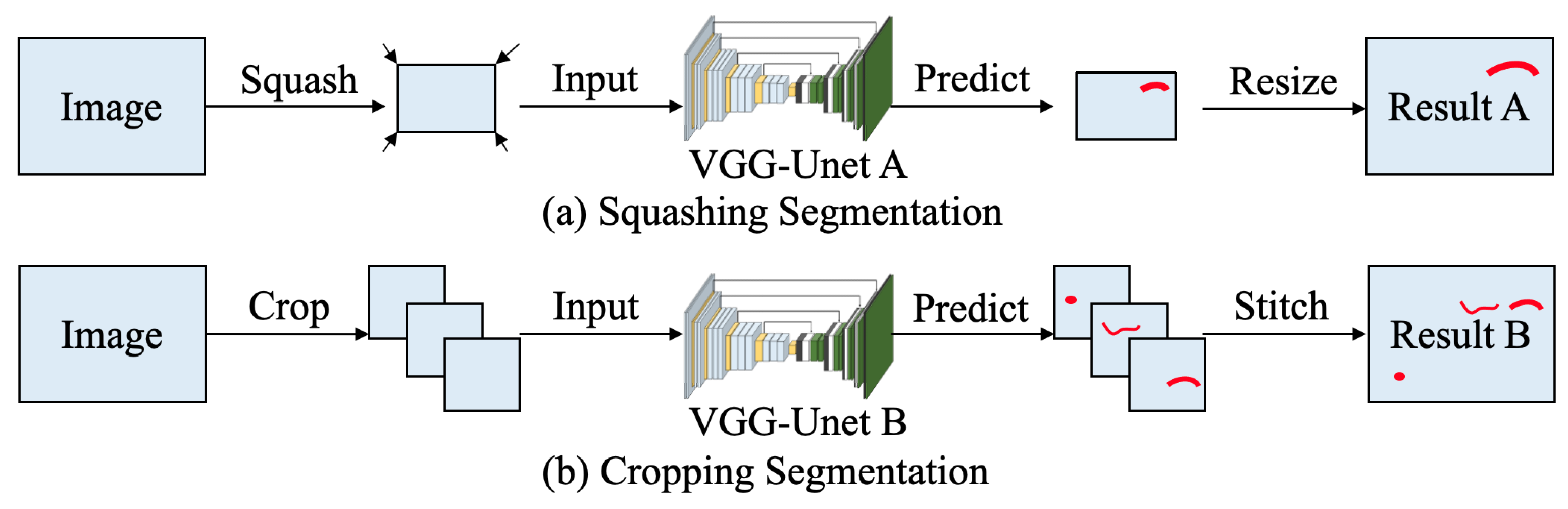
- Squashing Segmentation is conducive to detection of the overall position of the damage. However, compared with Cropping Segmentation, this method doesn’t have a good performance on detecting damages’ precise location, due to some feature information are lost during the compressing process before training.
- The damage detection capability of Cropping Segmentation is largely affected by the concentration of valid data in the data set. If the percentage of damage is very low, the VGG-Unet model may be too sensitive to the background pixels, which leads to the low accuracy.
- If the data sets are with low MDR, there is a large gap between different evaluation methods that enhance the weight of damages or not. In this case, FWIoU can be used to make a balance between these different evaluation methods and reduce the gap while expending the weight of minor damage.
- BDDR is an effective parameter to control the proportion of damage pixels in the data set and improve VGG-Unet model’s capability on detecting minor damages. In this research, BDDR of 0.8 has the highest accuracy, slightly stronger than BDDR of 0.9. It shows that a data set with an appropriate concentration of damage pixels is more helpful to train a higher-precision VGG-Unet model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| BDDR | Background Data Drop Rate |
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Neural |
| FWIoU | Frequency Weighted Intersection over Union |
| IPT | Image Processing Technique |
| MDR | Mean Damage Ratio |
| MIoU | Mean Intersection over Union |
| ML | Machine Learning |
| MPA | Mean Pixel Accuracy |
| PA | Pixel Accuracy |
| ReLU | Rectified Linear Unit |
| RWIoU | Relative Weighted Intersection over Union |
| UAV | Unmanned Aerial Vehicle |
References
- Inoue, M.; Fujino, Y. Social impact of a bridge accident in Minnesota, USA. JSCE Proc. F 2010, 66, 14–26. (In Japanese) [Google Scholar]
- Ministry of Land, Infrastructure, Transport, and Tourism. White Paper on Present State and Future of Social Capital Aging Infrastructure Maintenance Information; Ministry of Land, Infrastructure, Transport, and Tourism: Tokyo, Japan, 2016. (In Japanese)
- Pan, Y.; Feng, D. Current status of domestic bridges and problems to be solved. China Water Transp. 2007, 7, 78–79. (In Chinese) [Google Scholar]
- Graybeal, B.A.; Phares, B.M.; Rolander, D.D.; Moore, M.; Washer, G. Visual inspection of highway bridges. J. Nondestruct. Eval. 2002, 21, 67–83. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Hoang, T.A.; Spencer, B.F., Jr. Towards automated post-earthquake inspections with deep learning-based condition-aware models. arXiv 2018, arXiv:1809.09195. [Google Scholar]
- Gao, Y.; Mosalam, K.M. Deep transfer learning for image-based structural damage recognition. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inf. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil Eng. 2003, 17.4, 255–263. [Google Scholar] [CrossRef]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput. Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- German, S.; Brilakis, I.; DesRoche, R. Rapid entropy-based detection and properties measurement of concrete spalling with machine vision for post-earthquake safety assessments. Adv. Eng. Inf. 2012, 26, 846–858. [Google Scholar] [CrossRef]
- Kaiser, G. The fast Haar transform. IEEE Potent. 1998, 17, 34–37. [Google Scholar] [CrossRef]
- Nussbaumer, H.J. The fast Fourier transform. In Fast Fourier Transform and Convolution Algorithms; Springer: Berlin/Heidelberg, Germany, 1981; pp. 80–111. [Google Scholar]
- Koziarski, M.; Cyganek, B. Image recognition with deep neural networks in presence of noise–dealing with and taking advantage of distortions. Integrated Comput. Aided Eng. 2017, 24, 337–349. [Google Scholar] [CrossRef]
- Jiang, X.; Adeli, H. Pseudospectra, MUSIC, and dynamic wavelet neural network for damage detection of highrise buildings. Int. J. Numer. Methods Eng. 2007, 71.5, 606–629. [Google Scholar] [CrossRef]
- Butcher, J.B.; Day, C.R.; Austin, J.C.; Haycock, P.W.; Verstraeten, D.; Schrauwen, B. Defect detection in reinforced concrete using random neural architectures. Comput. Aided Civ. Infrastruct. Eng. 2014, 29, 191–207. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Soukup, D.; Huber-Mörk, R. Convolutional neural networks for steel surface defect detection from photometric stereo images. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 668–677. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Su, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road damage detection and classification with Faster R-CNN. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5220–5223. [Google Scholar]
- Deng, J.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 373–388. [Google Scholar] [CrossRef]
- Wang, N.; Zhao, X.; Zhao, P.; Zhang, Y.; Zou, Z.; Ou, J. Automatic damage detection of historic masonry buildings based on mobile deep learning. Autom. Constr. 2019, 103, 53–66. [Google Scholar] [CrossRef]
- LuqmanAli, W.K.; Chaiyasarn, K. Damage Detection and Localization in Masonry Structure using Faster Region Convolutional Networks. Int. J. 2019, 17, 98–105. [Google Scholar]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Zhang, C.; Chang, C.C.; Jamshidi, M. Bridge Damage Detection using a Single-Stage Detector and Field Inspection Images. arXiv 2018, arXiv:1812.10590. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Ni, F.; Zhang, J.; Chen, Z. Pixel-level crack delineation in images with convolutional feature fusion. Struct. Control Health Monitor. 2019, 26, e2286. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhao, X.; Zhou, G. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Shi, J.; Dang, J.; Zuo, R.; Shimizu, K.; Tsunda, A.; Suzuki, Y. Structural Context Based Pixel-level Damage Detection for Rubber Bearing. Intell. Inf. Infrastruct. 2020, 1, 18–24. [Google Scholar]
- Narazaki, Y.; Hoskere, V.; Hoang, T.A.; Fujino, Y.; Sakurai, A.; Spencer, B.F., Jr. Vision-based automated bridge component recognition with high-level scene consistency. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 468–482. [Google Scholar] [CrossRef]
- Fawakherji, M.; Youssef, A.; Bloisi, D.; Pretto, A.; Nardi, D. Crop and weeds classification for precision agriculture using context-independent pixel-wise segmentation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 146–152. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
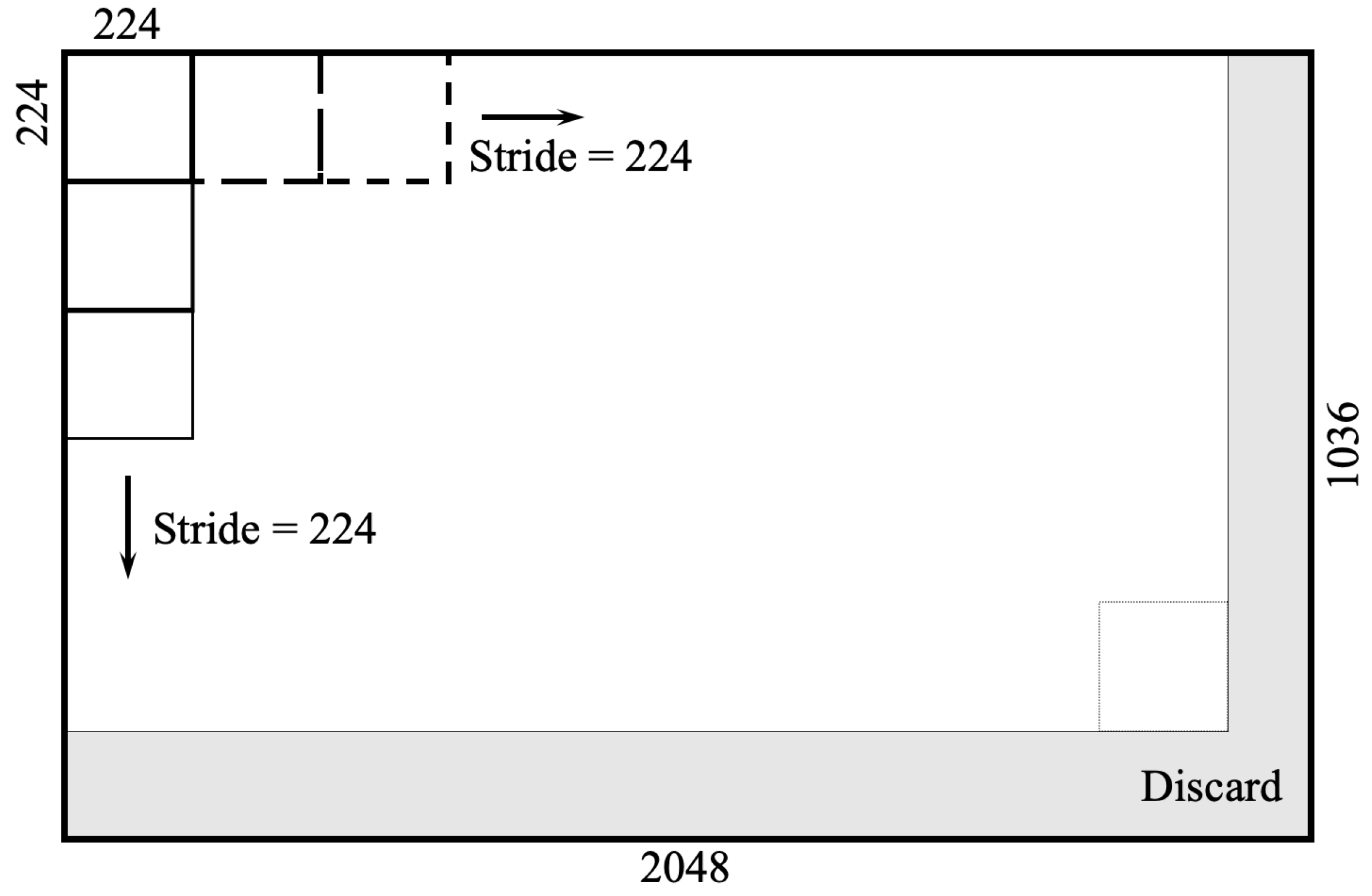{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Pad | Kernel Size | Stride | Output Size | Note |
|---|---|---|---|---|---|---|
| 1 | Input | - | - | - | 224 × 224 × 3 | |
| 2 | Conv + ReLU | 1 | 3 × 3 × 64 | 1 | 224 × 224 × 64 | down-sampling block 1 |
| 3 | Conv + ReLU | 1 | 3 × 3 × 64 | 1 | 224 × 224 × 64 | |
| 4 | MaxPooling | 0 | 2 × 2 | 2 | 112 × 112 × 64 | |
| 5 | Conv + ReLU | 1 | 3 × 3 × 128 | 1 | 112 × 112 × 128 | down-sampling block 2 |
| 6 | Conv + ReLU | 1 | 3 × 3 × 128 | 1 | 112 × 112 × 128 | |
| 7 | MaxPooling | 0 | 2 × 2 | 2 | 56 × 56 × 128 | |
| 8 | Conv + ReLU | 1 | 3 × 3 × 256 | 1 | 56 × 56 × 256 | down-sampling block 3 |
| 9 | Conv + ReLU | 1 | 3 × 3 × 256 | 1 | 56 × 56 × 256 | |
| 10 | Conv + ReLU | 1 | 3 × 3 × 256 | 1 | 56 × 56 × 256 | |
| 11 | MaxPooling | 0 | 2 × 2 | 2 | 28 × 28 × 256 | |
| 12 | Conv + ReLU | 1 | 3 × 3 × 512 | 1 | 28 × 28 × 512 | down-sampling block 4 |
| 13 | Conv + ReLU | 1 | 3 × 3 × 512 | 1 | 28 × 28 × 512 | |
| 14 | Conv + ReLU | 1 | 3 × 3 × 512 | 1 | 28 × 28 × 512 | |
| 15 | MaxPooling | 0 | 2 × 2 | 2 | 14 × 14 × 512 | |
| 16 | Conv + ReLU | 1 | 3 × 3 × 512 | 1 | 14 × 14 × 512 | down-sampling block 5 |
| 17 | Conv + ReLU | 1 | 3 × 3 × 512 | 1 | 14 × 14 × 512 | |
| 18 | Conv+ReLU | 1 | 3 × 3 × 512 | 1 | 14 × 14 × 512 | |
| 19 | MaxPooling | 0 | 2 × 2 | 2 | 7 × 7 × 512 | |
| 20 | Upsampling | - | - | - | 14 × 14 × 512 | up-sampling block 1 |
| 21 | Concatenate | - | - | - | 14 × 14 × 1024 | |
| 22 | Conv + BN | 1 | 3 × 3 × 512 | 2 | 14 × 14 × 512 | |
| 22 | Conv + BN | 1 | 3 × 3 × 256 | 2 | 14 × 14 × 256 | |
| 23 | Upsampling | - | - | - | 28 × 28 × 256 | up-sampling block 2 |
| 24 | Concatenate | - | - | - | 28 × 28 × 512 | |
| 25 | Conv + BN | 1 | 3 × 3 × 256 | 2 | 28 × 28 × 256 | |
| 26 | Conv + BN | 1 | 3 × 3 × 128 | 2 | 28 × 28 × 128 | |
| 27 | Upsampling | - | - | - | 56 × 56 × 128 | up-sampling block 3 |
| 28 | Concatenate | - | - | - | 56 × 56 × 256 | |
| 29 | Conv + BN | 1 | 3 × 3 × 128 | 2 | 56 × 56 × 128 | |
| 30 | Conv + BN | 1 | 3 × 3 × 64 | 2 | 56 × 56 × 64 | |
| 31 | Upsampling | - | - | - | 112 × 112 × 64 | up-sampling block 4 |
| 32 | Concatenate | - | - | - | 112 × 112 × 128 | |
| 33 | Conv + BN | 1 | 3 × 3 × 64 | 2 | 112 × 112 × 64 | |
| 34 | Upsampling | - | - | - | 224 × 224 × 64 | up-sampling block 5 |
| 35 | Conv + BN | 1 | 3 × 3 × 3 | 2 | 224 × 224 × 3 | |
| 36 | Output | - | - | - | 224 × 224 × 3 |
| Damage Class | Image Type | Training | Validation | Testing |
|---|---|---|---|---|
| Corrosion on steel | Squashed images | 160 | 40 | 40 |
| Cropped images | 9728 | 2719 | 2719 | |
| Damage on rubber bearing | Squashed images | 400 (193) | 50 (22) | 50 (27) |
| Cropped images | 34,626 (1968) | 5027 (409) | 4218 (261) |
| Data Set | Method | PA | MPA | MIoU | FWIoU | RWIoU0.1 |
|---|---|---|---|---|---|---|
| Corrosion on steel | Squashing | 75.6 | 57.7 | 44.2 | 62.7 | 46.8 |
| Cropping | 81.6 | 70.4 | 57.1 | 71.4 | 59.1 | |
| Damage on rubber bearing | Squashing | 99.2 (98.7) | 75.8 (55.4) | 74.4 (52.7) | 98.7 (97.8) | 80.7 (64.3) |
| Cropping | 99.4 (99.0) | 73.8 (51.4) | 73.4 (50.7) | 98.9 (98.0) | 79.9 (62.8) |
| Value of BDDR | Training | Validation | Testing |
|---|---|---|---|
| 0 | 34,626 (1968) | 5027 (409) | 4218 (261) |
| 0.2 | 28,094 (1968) | 4103 (409) | |
| 0.5 | 18,297 (1968) | 2718 (409) | |
| 0.8 | 8499 (1968) | 1332 (409) | |
| 0.9 | 5233 (1968) | 870 (409) |
| Value of BDDR | All | Training | Validation | Testing |
|---|---|---|---|---|
| 0 | 0.008 (0.130) | 0.007 (0.123) | 0.016 (0.194) | 0.005 (0.081) |
| 0.2 | 0.009 (0.130) | 0.009 (0.123) | 0.019 (0.194) | |
| 0.5 | 0.014 (0.130) | 0.013 (0.123) | 0.029 (0.194) | |
| 0.8 | 0.024 (0.130) | 0.028 (0.123) | 0.059 (0.194) | |
| 0.9 | 0.033 (0.130) | 0.046 (0.123) | 0.091 (0.194) |
| Data Set | BDDR | PA (%) | MPA (%) | MIoU (%) | FWIoU (%) | RWIoU0.1 (%) |
|---|---|---|---|---|---|---|
| All images (50) | 0 | 99.439 | 73.755 | 73.382 | 98.907 | 79.905 |
| 0.2 | 99.493 | 75.715 | 75.318 | 99.016 | 81.412 | |
| 0.5 | 99.451 | 78.761 | 77.104 | 99.014 | 82.753 | |
| 0.8 | 99.048 | 85.457 | 78.515 | 98.655 | 83.745 | |
| 0.9 | 99.374 | 82.013 | 78.433 | 98.974 | 83.747 | |
| Damage images only (27) | 0 | 98.969 | 51.405 | 50.715 | 97.983 | 62.795 |
| 0.2 | 99.079 | 55.046 | 54.311 | 98.196 | 65.595 | |
| 0.5 | 99.023 | 60.707 | 57.639 | 98.214 | 68.101 | |
| 0.8 | 98.596 | 73.428 | 60.571 | 97.868 | 70.256 | |
| 0.9 | 98.986 | 66.835 | 60.206 | 98.244 | 70.047 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Dang, J.; Cui, M.; Zuo, R.; Shimizu, K.; Tsunoda, A.; Suzuki, Y. Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet. Appl. Sci. 2021, 11, 518. https://doi.org/10.3390/app11020518
Shi J, Dang J, Cui M, Zuo R, Shimizu K, Tsunoda A, Suzuki Y. Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet. Applied Sciences. 2021; 11(2):518. https://doi.org/10.3390/app11020518
Chicago/Turabian StyleShi, Jiyuan, Ji Dang, Mida Cui, Rongzhi Zuo, Kazuhiro Shimizu, Akira Tsunoda, and Yasuhiro Suzuki. 2021. "Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet" Applied Sciences 11, no. 2: 518. https://doi.org/10.3390/app11020518
APA StyleShi, J., Dang, J., Cui, M., Zuo, R., Shimizu, K., Tsunoda, A., & Suzuki, Y. (2021). Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet. Applied Sciences, 11(2), 518. https://doi.org/10.3390/app11020518