Ternion: An Autonomous Model for Fake News Detection


 ,
,  , , , ,
, , , ,
Abstract
1. Introduction
2. Related Work
2.1. Stance Detection
2.2. Author Credibility
2.3. Machine Learning-Based Classification
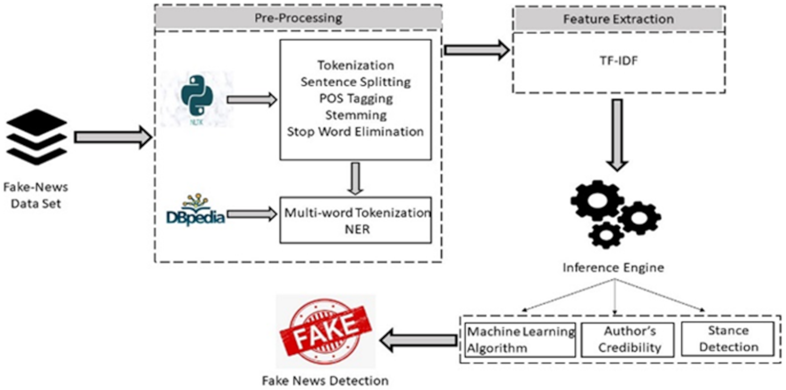
3. Proposed Approach and Implementation Details
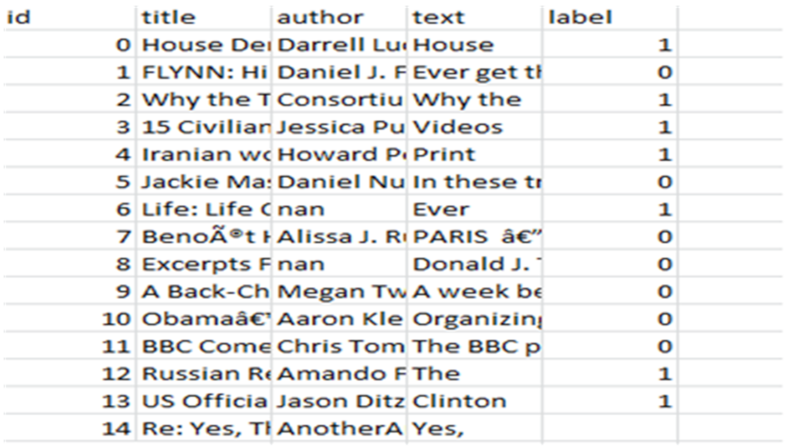
3.1. Dataset Description
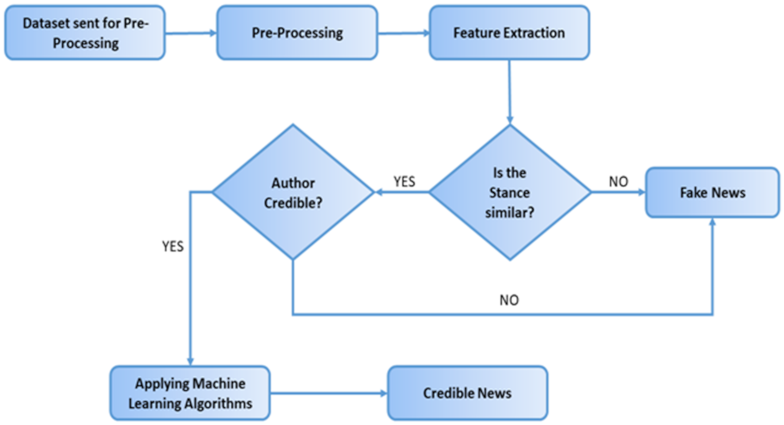
3.2. Proposed Approach: Inference Engine

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
def get_vectors(title,text):
|
def stance_detection(row)
|
| frame . apply (stance_detection , axis =1 ) |
- A decision tree is one of the most popular classifiers that helps in prediction and classification, and it is supervised in nature. It splits the dataset by recursively selecting features. The selected features of the dataset can be in nominal or continuous form. This is a well-known classifier for data classification. The most distinct feature is the conversion of the process of complex decisions in order to simplify the process definition, and, as a result, it provides an easy way to understand and interpret the outcome [44].
- Random forest is a regulated AI method that is supervised in nature. On the basis of random element choice, a set of decision trees (base classifiers) is produced, and the dominant party with respect to voting is selected for classification. It generates accurate and diverse decisions that are dynamic algorithms for this classifier [45]. In a random forest, the individual decision trees are an ensemble, and they operate on average to increase the accuracy of the prediction of the model. This model also focuses on the reduction in over-fitting. The sub-samples are drawn with replacement, keeping their size the same as the original input sample size.
- Logistic regression is an AI technique for classification. In this algorithm, the probabilities portraying the potential results of the possible outcomes are demonstrated utilizing a logistic function. It is widely used in circumstances in which humans are not suited to perform the classification and automated functionality is required for this purpose [46].
- The support vector machine (SVM) is known as a supervised learning algorithm that is widely used to predict or classify data. Its classifier is officially characterized by an isolating hyperplane. That is, the labeled dataset for training is required, and the algorithm yields an ideal hyperplane that generates new examples. In two-dimensional space, this hyperplane is a line separating a plane in two sections where each class is located on one of the two sides. SVM carries out generous upgrades and best-performing strategies, and it can be applied to a wide range of learning tasks. Moreover, it is completely programmed, eliminating the requirement for manual parameter tuning [47].
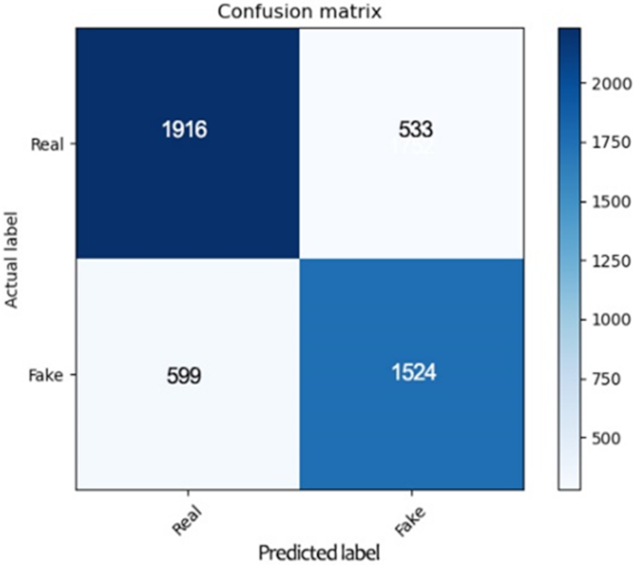
4. Experimental Results
- True positive (TP): a classifier prediction is true positive if the news is authentic, and the classifier predicts it as authentic.
- False-positive (FP): a classifier prediction is false positive if the news is fake, and the classifier predicts it as authentic.
- True negative (TN): a classifier prediction is true negative if the news is fake, and the classifier predicts it as fake.
- False-negative (FN): a classifier prediction is false negative if the news is authentic, and the classifier predicts it as fake.
- Precision: the ratio of positive examples that were correctly predicted by the classifier to the total number of examples predicted as positive.
- Recall: the ratio of the total number of true positives to the actual number of examples that were positive.
- F1-score: the weighted average score of precision and recall.
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- De Beer, D.; Matthee, M. Approaches to identify fake news: A systematic literature review. In International Conference on Integrated Science, Cambodia; Springer: Basel, Switzerland, 2020; pp. 13–22. [Google Scholar]
- Sitaula, N.; Mohan, C.K.; Grygiel, J.; Zhou, X.; Zafarani, R. Credibility-based fake news detection. In Disinformation, Misinformation, and Fake News in Social Media; Springer: Basel, Switzerland, 2020; pp. 163–182. [Google Scholar]
- Goldani, M.H.; Momtazi, S.; Safabakhsh, R. Detecting fake news with capsule neural networks. Appl. Soft Comput. 2021, 101, 106991. [Google Scholar] [CrossRef]
- Kaur, S.; Kumar, P.; Kumaraguru, P. Automating fake news detection system using multi-level voting model. Soft Comput. 2020, 24, 9049–9069. [Google Scholar] [CrossRef]
- Bühler, J.; Murawski, M.; Darvish, M.; Bick, M. Developing a Model to Measure Fake News Detection Literacy of Social Media Users. In Disinformation, Misinformation, and Fake News in Social Media; Springer: Basel, Switzerland, 2020; pp. 213–227. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. EchoFakeD: Improving fake news detection in social media with an efficient deep neural network. Neural Comput. Appl. 2021, 33, 8597–8613. [Google Scholar] [CrossRef] [PubMed]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Paka, W.S.; Bansal, R.; Kaushik, A.; Sengupta, S.; Chakraborty, T. Cross-SEAN: A cross-stitch semi-supervised neural attention model for COVID-19 fake news detection. Appl. Soft Comput. 2021, 107, 107393. [Google Scholar] [CrossRef]
- Saxena, A.; Saxena, P.; Reddy, H. Fake News Detection Techniques for Social Media. In Principles of Social Networking; Springer: Singapore, 2022; pp. 325–354. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. Semeval-2016 task 6: Detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar]
- Riedel, B.; Augenstein, I.; Spithourakis, G.P.; Riedel, S. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. arXiv 2017, arXiv:1707.03264. [Google Scholar]
- Pomerleau, D.; Rao, D. Fake News Challenge Stage 1 (fnc-i): Stance Detection. 2017. Available online: www.fakenewschallenge.org (accessed on 10 May 2021).
- Chaudhry, A.K.; Baker, D.; Thun-Hohenstein, P. Stance detection for the fake news challenge: Identifying textual relationships with deep neural nets. In CS224n: Natural Language Processing with Deep Learning; Lecture Notes; Standaford NLP: Stanford, CA, USA, 2017; pp. 1–117. Available online: http://web.stanford.edu/class/cs224n/ (accessed on 10 May 2021).
- Bhatt, G.; Sharma, A.; Sharma, S.; Nagpal, A.; Raman, B.; Mittal, A. Combining neural, statistical and external features for fake news stance identification. In Proceedings of the WWW ’18: Companion Proceedings of the The Web Conference 2018; Geneva, Switzerland, 23–27 April 2018, pp. 1353–1357.
- Bourgonje, P.; Schneider, J.M.; Rehm, G. From clickbait to fake news detection: An approach based on detecting the stance of headlines to articles. In Proceedings of the 2017 EMNLP workshop: Natural Language Processing Meets Journalism, Copenhagen, Denmark, 2 May 2017; pp. 84–89. [Google Scholar]
- Aiyar, S.; Shetty, N.P. N-gram assisted youtube spam comment detection. Procedia Comput. Sci. 2018, 132, 174–182. [Google Scholar] [CrossRef]
- García, M.; Maldonado, S.; Vairetti, C. Efficient n-gram construction for text categorization using feature selection techniques. Intell. Data Anal. 2021, 25, 509–525. [Google Scholar] [CrossRef]
- Saikh, T.; Anand, A.; Ekbal, A.; Bhattacharyya, P. A novel approach towards fake news detection: Deep learning augmented with textual entailment features. In Proceedings of the 24th International Conference on Applications of Natural Language to Information Systems, NLDB 2019, Salford, UK, 26–28 June 2019; pp. 345–358. [Google Scholar]
- Ghanem, B.; Rosso, P.; Rangel, F. Stance detection in fake news a combined feature representation. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, 1 November 2018; pp. 66–71. [Google Scholar]
- Ferreira, W.; Vlachos, A. Emergent: A novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1163–1168. [Google Scholar]
- Thota, A.; Tilak, P.; Ahluwalia, S.; Lohia, N. Fake news detection: A deep learning approach. SMU Data Sci. Rev. 2018, 1, 10. [Google Scholar]
- Munzel, A. Assisting consumers in detecting fake reviews: The role of identity information disclosure and consensus. J. Retail. Consum. Serv. 2016, 32, 96–108. [Google Scholar] [CrossRef]
- Xu, W.W.; Sang, Y.; Kim, C. What drives hyper-partisan news sharing: Exploring the role of source, style, and content. Digit. J. 2020, 8, 486–505. [Google Scholar]
- Rangel, F.; Giachanou, A.; Ghanem, B.H.H.; Rosso, P. Overview of the 8th author profiling task at PAN 2020: Profiling fake news spreaders on Twitter. In CEUR Workshop Proceedings; Sun SITE Central Europe: Aachen, Germany, 2020; Volume 2696, pp. 1–18. [Google Scholar]
- Parikh, S.B.; Atrey, P.K. Media-rich fake news detection: A survey. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 436–441. [Google Scholar]
- Kumar, A.; Upadhyay, M. Rumour Stance Classification using A Hybrid of Capsule Network and Multi-Layer Perceptron. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 4110–4120. [Google Scholar]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake news identification on twitter with hybrid cnn and rnn models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Girgis, S.; Amer, E.; Gadallah, M. Deep Learning Algorithms for Detecting Fake News in Online Text. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 93–97. [Google Scholar]
- Gilda, S. Notice of Violation of IEEE Publication Principles: Evaluating machine learning algorithms for fake news detection. In Proceedings of the 2017 IEEE 15th Student Conference on Research and Development (SCOReD), Wilayah Persekutuan Putrajaya, Malaysia, 13–14 December 2017; pp. 110–115. [Google Scholar]
- Ahmed, S.; Hinkelmann, K.; Corradini, F. Combining machine learning with knowledge engineering to detect fake news in social networks-a survey. In Proceedings of the AAAI 2019 Spring Symposium, Palo Alto, CA, USA, 25–27 March 2019; Volume 12, p. 8. [Google Scholar]
- Library, N. Natural Language Toolkit. 1999. Available online: https://www.nltk.org/ (accessed on 21 August 2021).
- Kaggle. Fake news Dataset. 2018. Available online: https://www.kaggle.com/c/fake-news/data (accessed on 21 August 2021).
- Jindal, R.; Dahiya, D.; Sinha, D.; Garg, A. A Study of Machine Learning Techniques for Fake News Detection and Suggestion of an Ensemble Model. In Proceedings of the International Conference on Innovative Computing and Communications, New Delhi, India, 19–20 February 2022; Springer: Berlin/Heidelberg, Germany; pp. 627–637. [Google Scholar]
- Shrivastava, S.; Singh, R.; Jain, C.; Kaushal, S. A Research on Fake News Detection Using Machine Learning Algorithm. In Smart Systems: Innovations in Computing; Springer: Singapore, 2022; pp. 273–287. [Google Scholar]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake news detection on social media using geometric deep learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar]
- Paul, S.; Joy, J.I.; Sarker, S.; Ahmed, S.; Das, A.K. Fake news detection in social media using blockchain. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–5. [Google Scholar]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter sentiment analysis on worldwide COVID-19 outbreaks. Kurd. J. Appl. Res. 2020, 5, 54–65. [Google Scholar] [CrossRef]
- Helmstetter, S.; Paulheim, H. Weakly supervised learning for fake news detection on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 274–277. [Google Scholar]
- Buntain, C.; Golbeck, J. Automatically identifying fake news in popular twitter threads. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 208–215. [Google Scholar]
- Gupta, P.; Pathak, V.; Goyal, N.; Singh, J.; Varshney, V.; Kumar, S. Content credibility check on Twitter. In Proceedings of the International Conference on Application of Computing and Communication Technologies, New Delhi, India, 9–10 March 2018; Springer: Singapore, 2018; pp. 197–212. [Google Scholar]
- Twitter, I. Twitter API. 2021. Available online: https://developer.twitter.com (accessed on 21 August 2021).
- Gupta, P.; Thakral, R.; Aggarwal, M.; Bhatti, S.; Jain, V. A Proposed Framework to Analyze Abusive Tweets on the Social Networks. Int. J. Mod. Educ. Comput. Sci. 2018, 10, 46–56. [Google Scholar] [CrossRef][Green Version]
- Priyanka.; Kumar, D. Decision tree classifier: A detailed survey. Int. J. Inf. Decis. Sci. 2020, 12, 246–269. [Google Scholar] [CrossRef]
- Kulkarni, V.Y.; Sinha, P.K. Pruning of random forest classifiers: A survey and future directions. In Proceedings of the 2012 International Conference on Data Science & Engineering (ICDSE), Cochin, India, 18–20 July 2012; pp. 64–68. [Google Scholar]
- De Menezes, F.S.; Liska, G.R.; Cirillo, M.A.; Vivanco, M.J. Data classification with binary response through the Boosting algorithm and logistic regression. Expert Syst. Appl. 2017, 69, 62–73. [Google Scholar] [CrossRef]
- Joachims, T. Machine Learning: ECML-94. In Proceedings of the European Conference on Machine Learning, Catania, Italy, 6–8 April 1994; Springer Science & Business Media: Singapore, 2005; Volume 784, pp. 627–637. [Google Scholar]
- Desjardins, J. What Happens in an Internet Minute in 2018? 2018. Available online: https://www.visualcapitalist.com/internet-minute-2018 (accessed on 22 September 2021).











| Column | Description |
|---|---|
| Id | A unique Id assigned to each piece of news |
| Title | The title of the news |
| Text | News text |
| Label | The label of the news |
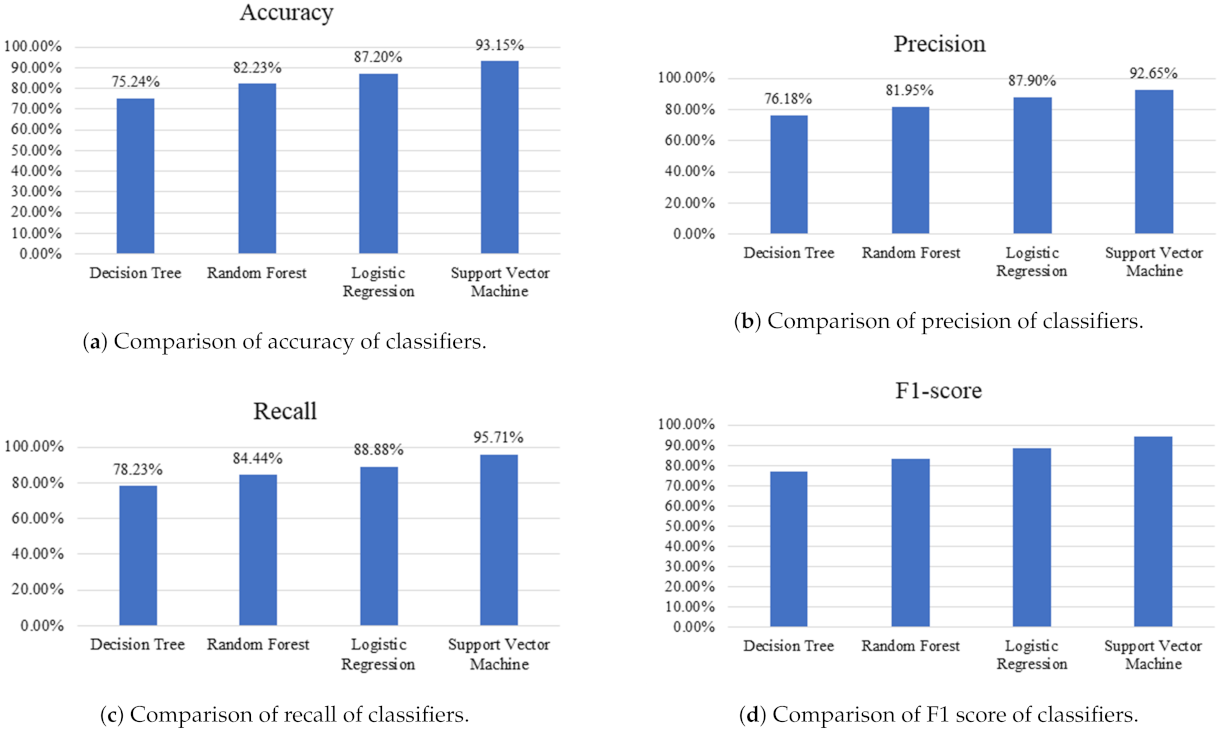
| Machine Learning Algorithm | TP | FP | FN | TN | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|
| Decision Tree | 1916 | 599 | 533 | 1524 | 75.24% | 76.18% | 78.23% | 77.19% |
| Random Forest | 2008 | 442 | 370 | 1752 | 82.23% | 81.95% | 84.44% | 83.17% |
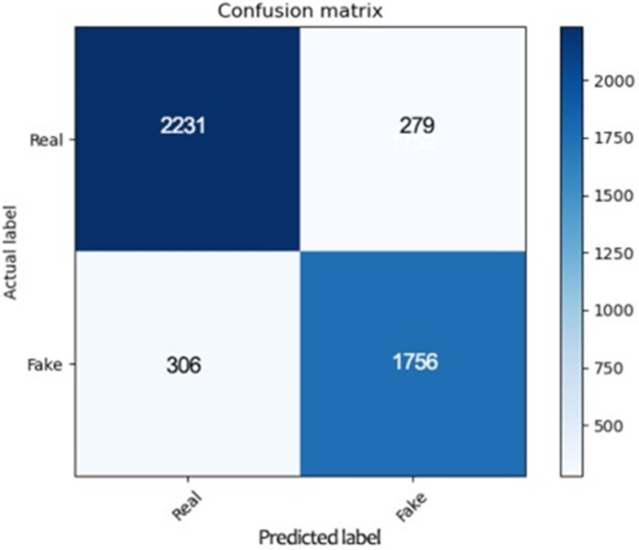
| Logistic Regression | 2231 | 306 | 279 | 1756 | 87.20% | 87.90% | 88.88% | 88.30% |
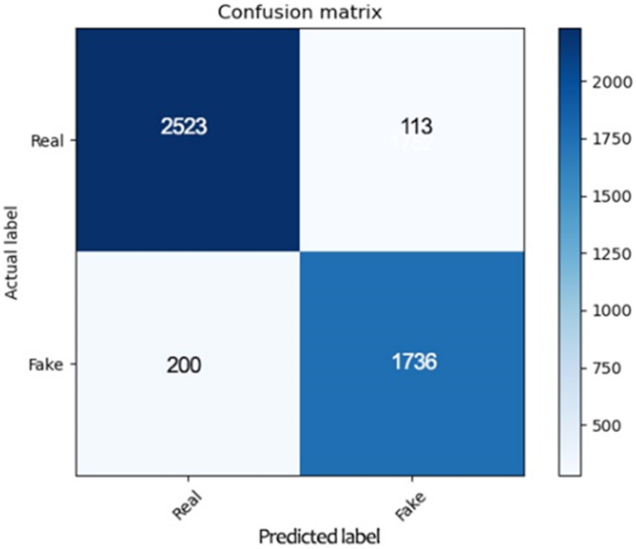
| Support Vector Machine | 2523 | 200 | 113 | 1736 | 93.15% | 92.65% | 95.71% | 94.15% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, N.; Shaikh, A.; Qaiser, A.; Asiri, Y.; Almakdi, S.; Sulaiman, A.; Moazzam, V.; Babar, S.A. Ternion: An Autonomous Model for Fake News Detection. Appl. Sci. 2021, 11, 9292. https://doi.org/10.3390/app11199292
Islam N, Shaikh A, Qaiser A, Asiri Y, Almakdi S, Sulaiman A, Moazzam V, Babar SA. Ternion: An Autonomous Model for Fake News Detection. Applied Sciences. 2021; 11(19):9292. https://doi.org/10.3390/app11199292
Chicago/Turabian StyleIslam, Noman, Asadullah Shaikh, Asma Qaiser, Yousef Asiri, Sultan Almakdi, Adel Sulaiman, Verdah Moazzam, and Syeda Aiman Babar. 2021. "Ternion: An Autonomous Model for Fake News Detection" Applied Sciences 11, no. 19: 9292. https://doi.org/10.3390/app11199292
APA StyleIslam, N., Shaikh, A., Qaiser, A., Asiri, Y., Almakdi, S., Sulaiman, A., Moazzam, V., & Babar, S. A. (2021). Ternion: An Autonomous Model for Fake News Detection. Applied Sciences, 11(19), 9292. https://doi.org/10.3390/app11199292