
Privacy Preservation and Analytical Utility of E-Learning Data Mashups in the Web of Data



Abstract
:1. Introduction
Research Contribution
2. Related Works
2.1. Privacy-Preserving Data Mashup
2.2. Learning Analytics Data Privacy
3. Considerations on Data Mashup
3.1. Database Management Technology
3.2. Mashups of Vertically Partitioned Datasets
3.3. De-Identification in the Context of Data Mashup
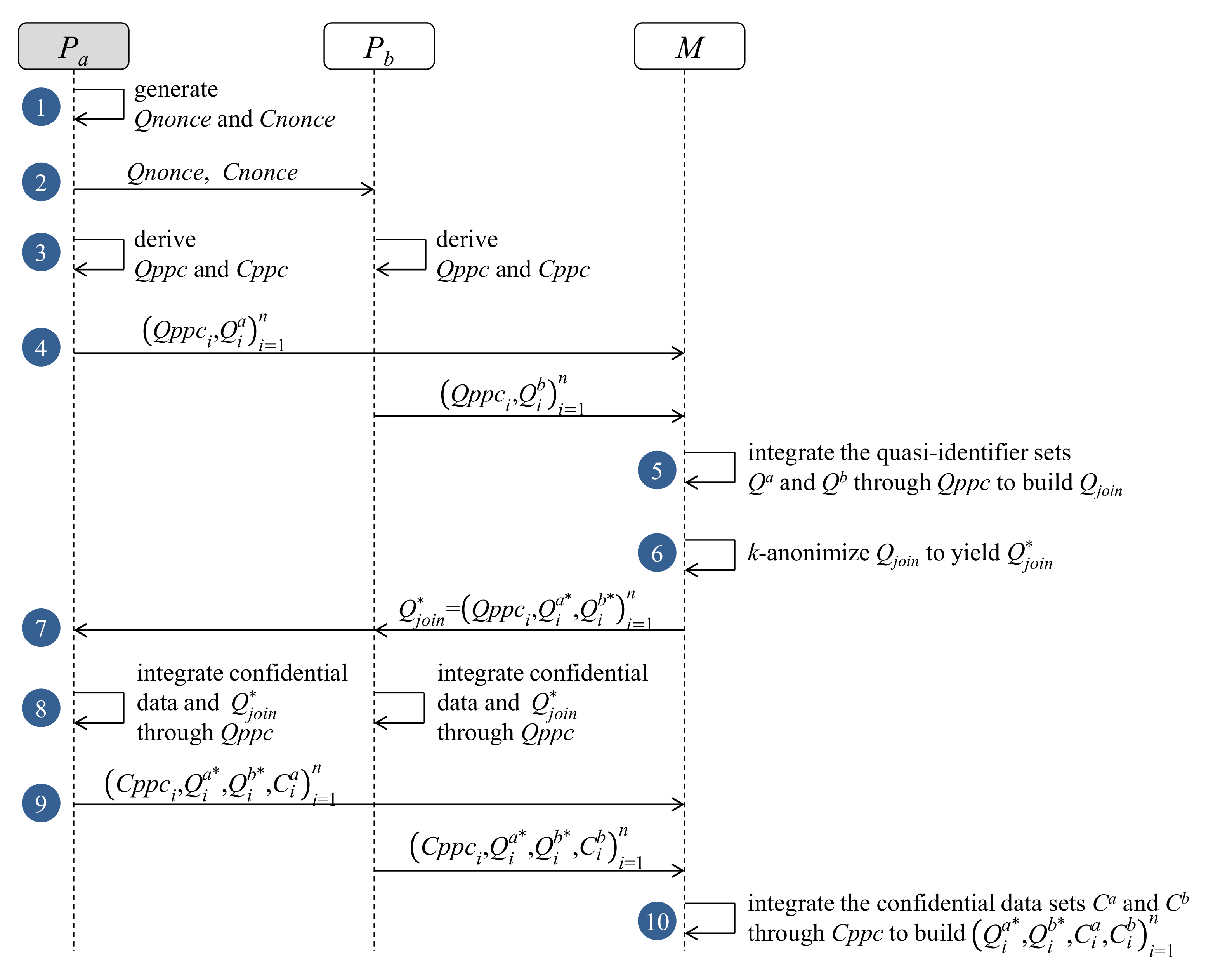
4. Privacy-Preserving Vertical Data Mashup Protocol
4.1. Setup Protocol
- Identify the set of data providers that can satisfy the data request, each provider contributing a vertical partition of the requested dataset;
- Build the mashup data schema;
- Designate the leading provider that will initiate the anonymization and integration protocol.
4.1.1. Identify Data Providers
4.1.2. Build the Mashup Data Schema
- Each tuple t in produces the following set of RDF triples:
![Applsci 11 08506 i001]()
- For each tuple t in and each local QI attribute identifiable as such in A, generate one RDF tuple depending on whether there is a corresponding term in a standard linked data vocabulary to map the local QI attribute, as explained next with the OULAD example.
- -
- If local QI attributes of the table are considered to be and , then generate the following RDF triples—note that, in the case of and attributes, no standard vocabulary terms are found or provided:
![Applsci 11 08506 i002]() Although we used oula:region for instead of a mapping to standard linked data vocabulary terms, a different alignment strategy could determine, for instance, foaf:based_near as a valid mapping instead of directly using oula:region. Then another option for is to generate an RDF triple, as in the following:
Although we used oula:region for instead of a mapping to standard linked data vocabulary terms, a different alignment strategy could determine, for instance, foaf:based_near as a valid mapping instead of directly using oula:region. Then another option for is to generate an RDF triple, as in the following:![Applsci 11 08506 i003]()
- -
- If for the schema, students’ is considered as local QI attributes, each tuple t in would produce one RDF triple —note that, in the case of attribute, the schema:gender term of the schema.org vocabulary is selected to map the attribute:
![Applsci 11 08506 i004]() As in the previous case, other strategies for vocabulary alignment between the OULAD schema and standard vocabularies can be followed in the case of oula:gender values using oula:gender instead of schema:gender and adding a owl:sameAs triple to the generated RDF mashup:
As in the previous case, other strategies for vocabulary alignment between the OULAD schema and standard vocabularies can be followed in the case of oula:gender values using oula:gender instead of schema:gender and adding a owl:sameAs triple to the generated RDF mashup:![Applsci 11 08506 i005]()


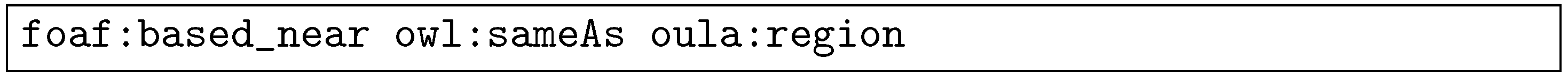


- For each tuple t in and in such that = , a triple of the following form is generated for each local QI attribute (e.g., if dates are considered as QI):
![Applsci 11 08506 i006]()
- For each tuple t in and in such that = , a set of triples of the following form is generated:
![Applsci 11 08506 i007]()


- From A.studentInfo:
- -
- code_module
- -
- code_presentation
- -
- gender
- -
- region
- -
- highest_education
- -
- imd_band
- -
- age_band
- -
- num_of_prev_attempts
- -
- studied_credits
- -
- disability
- -
- final_result
- -
- date_registration
- -
- date_unregistration
- From B.studentAssessment:
- -
- id_assessment
- -
- date_submitted
- -
- is_banked, score
4.1.3. Designate a Leading Provider
4.2. Anonymization and Integration Protocol
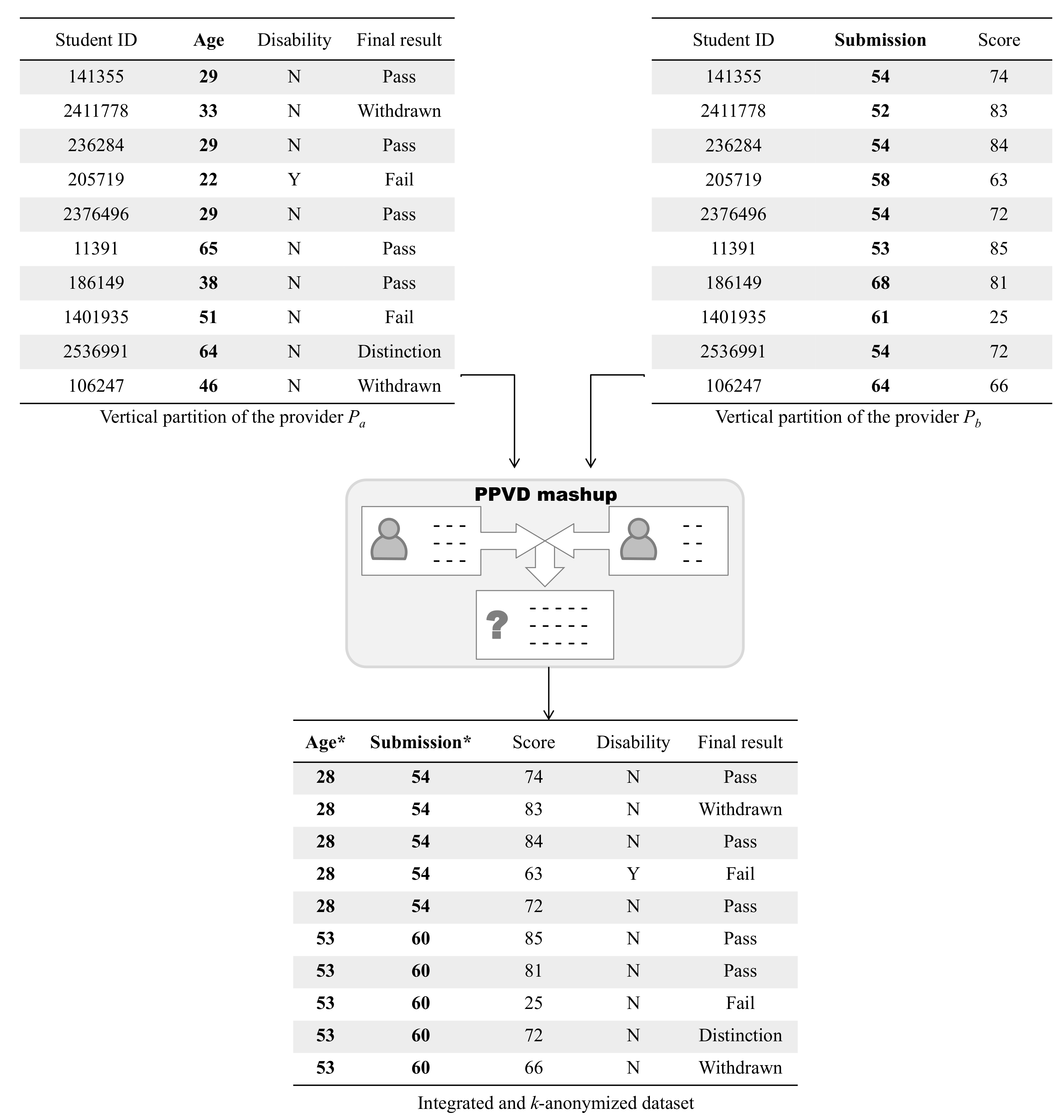
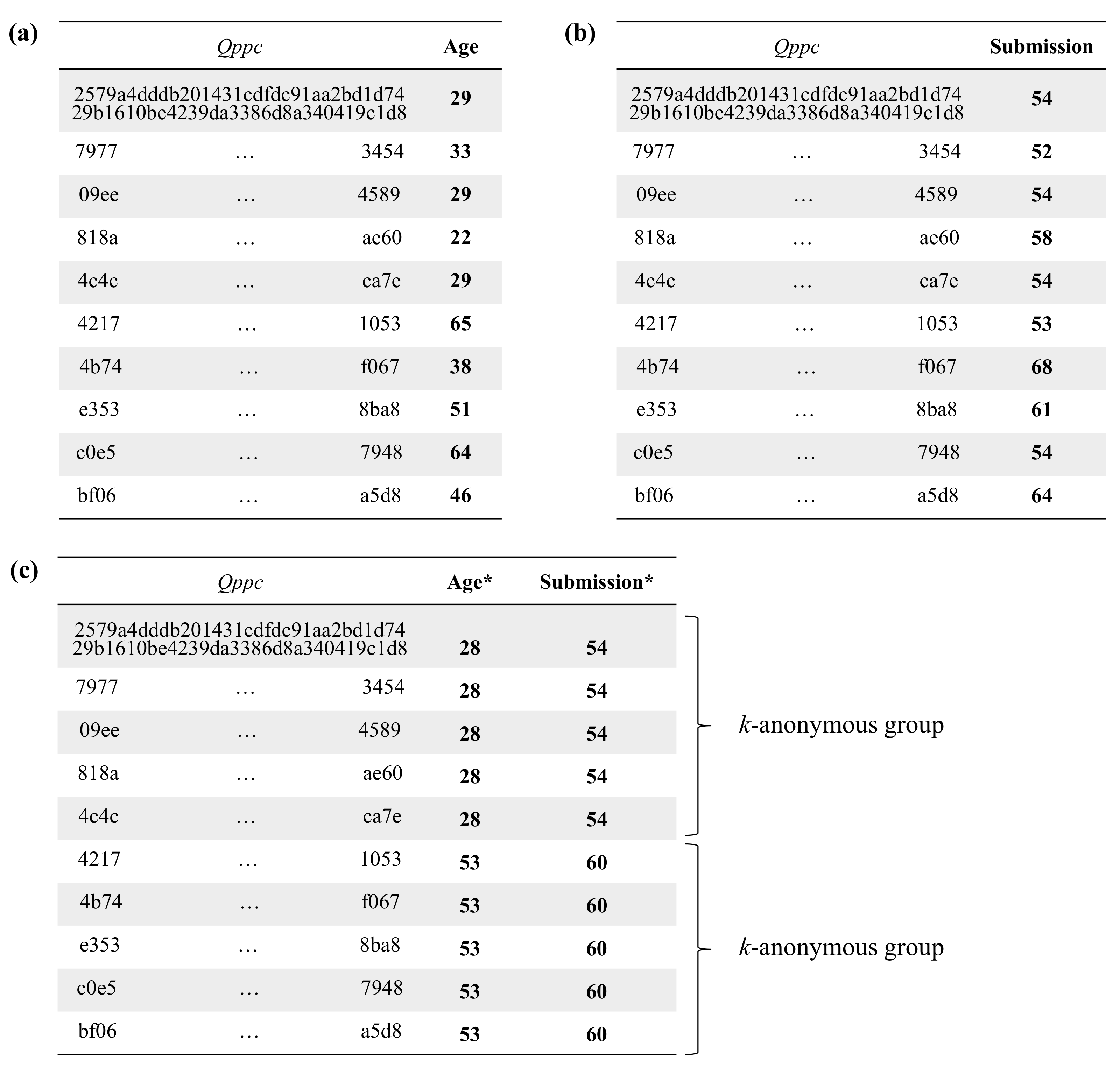
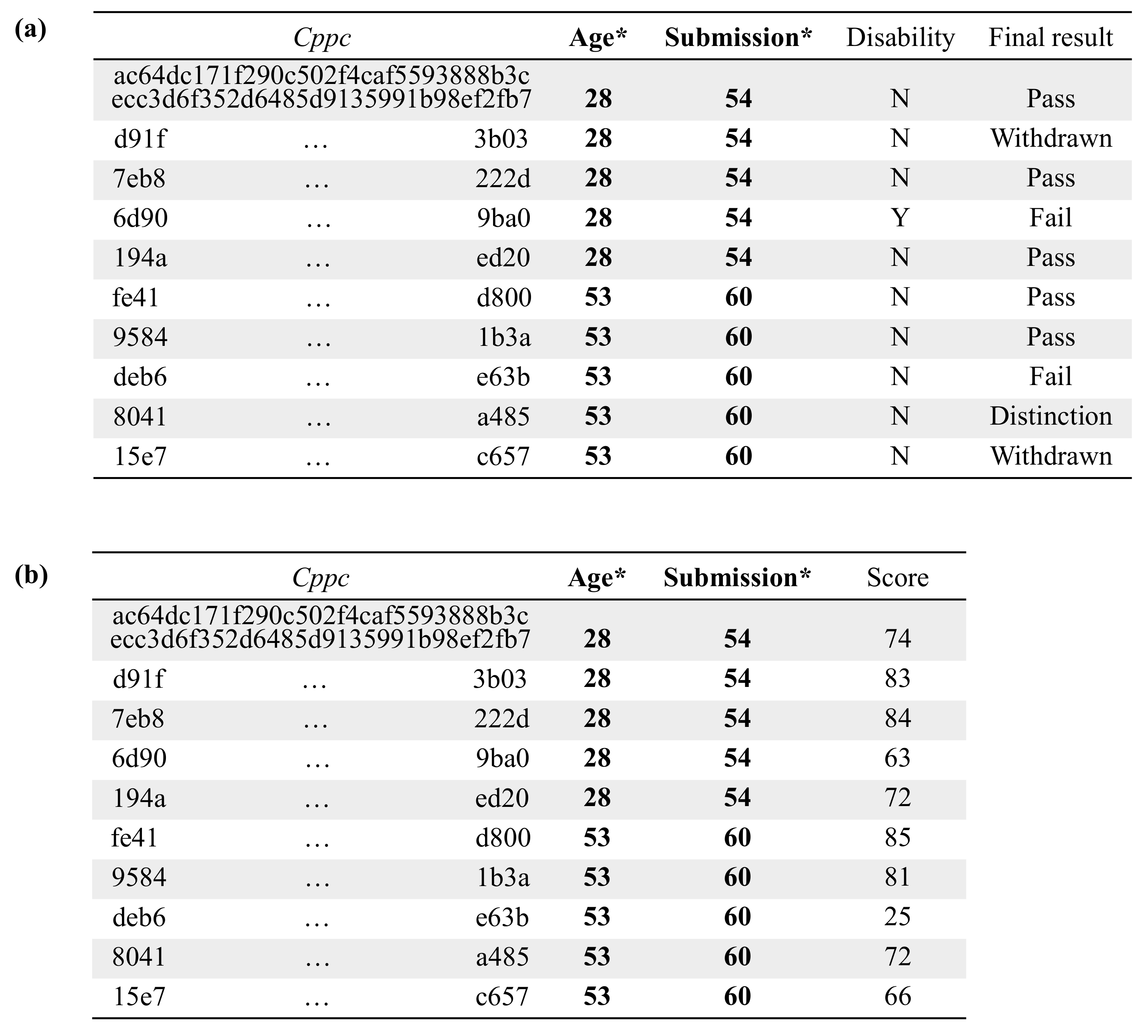
5. Evaluation
5.1. Analytical Evaluation of the k-Unlinkability Property
- (i)
- Because the data partitions are sent encrypted to the mashup coordinator through a secure transport protocol, no data provider will be able to view other providers’ quasi-identifier and confidential attributes, even if the provider carried out a network traffic analysis.
- (ii)
- Because the mashup coordinator handles quasi-identifiers and confidential attributes during the execution of the protocol, the coordinator may learn additional information about the subjects of those data by linking the data obtained in the different steps of the protocol. After analyzing the data handled by the mashup coordinator, compiled in Table 3, it follows that the mashup coordinator can only make ambiguous links between confidential attributes and original quasi-identifiers. In particular, the mashup coordinator can only perform the following reverse linking of the information:That is, in step 10 of the protocol, the mashup coordinator can link the confidential attributes with the masked quasi-identifier attributes . In turn, can be linked with k or more connectors by using the k-anonymized data from step 6. Note that the masked quasi-identifiers of a given individual can never be linked with less than k connectors since, after k-anonymization, the number of privacy-preserving connectors that have associated the same values in the masked quasi-identifier attributes is always greater than or equal to k. Finally, from the data received in step 4, the mashup coordinator can link the k (or more) connectors with their respective original quasi-identifiers. Because the connectors used in step 10, , are different from those received in step 4, , the mashup coordinator will never be able to link a given with its corresponding , and thus, it will not be able to uniquely associate the confidential attributes from a given individual with their original quasi-identifiers.
5.2. Analytical Evaluation of the De-Identification of Sensitive Data
- (i)
- Because the mashup coordinator handles the original quasi-identifiers during the execution of the protocol, the mashup coordinator may associate them with the connectors .
- (ii)
- Because a connector results from a one-way hash function on a nonce and the individual’s identifier attribute (both unknown to the mashup coordinator), the mashup coordinator will not be able to derive the value of the identifier. Moreover, if the nonce is large enough, the connector will be protected against dictionary attacks and other precomputation attacks, making such attacks infeasible.
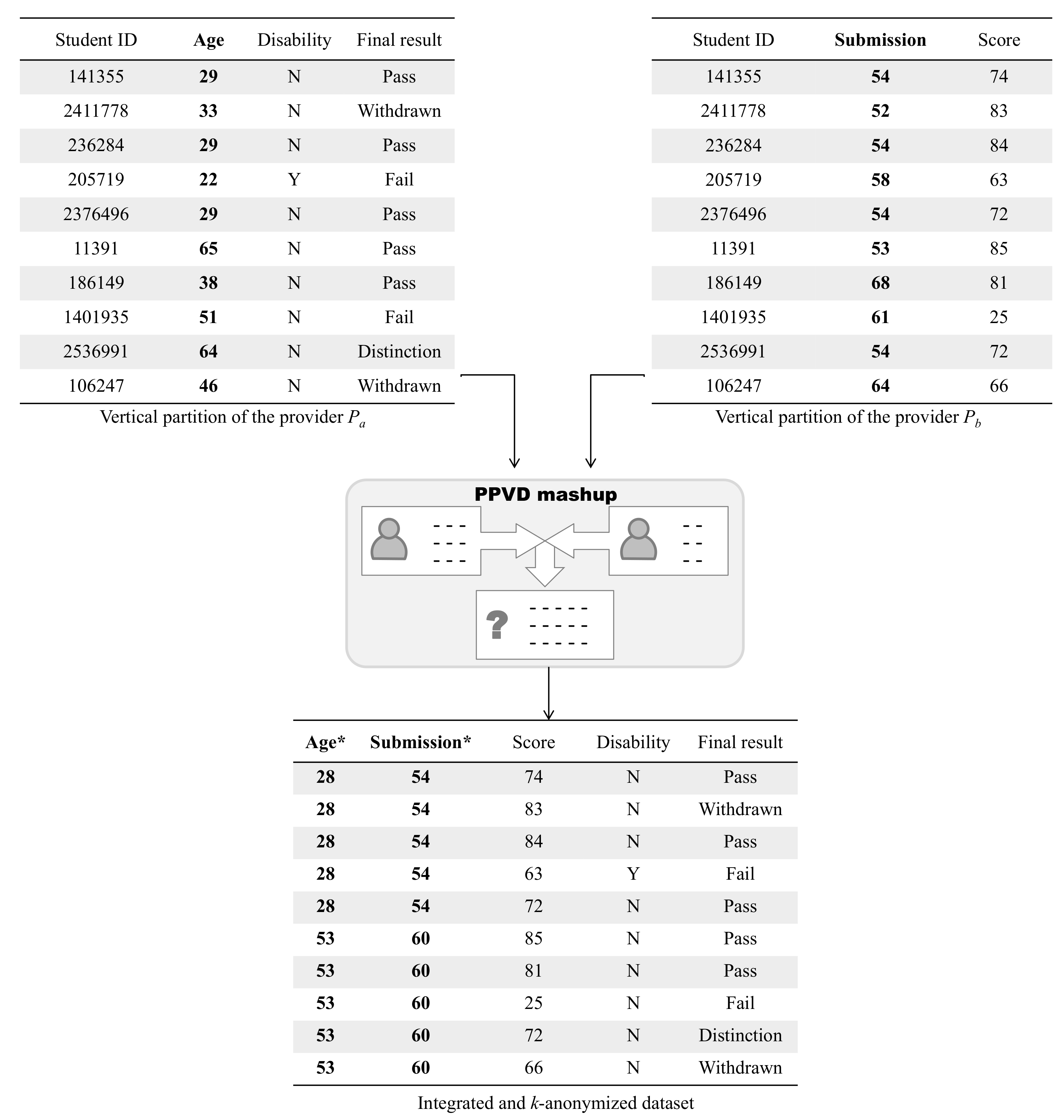
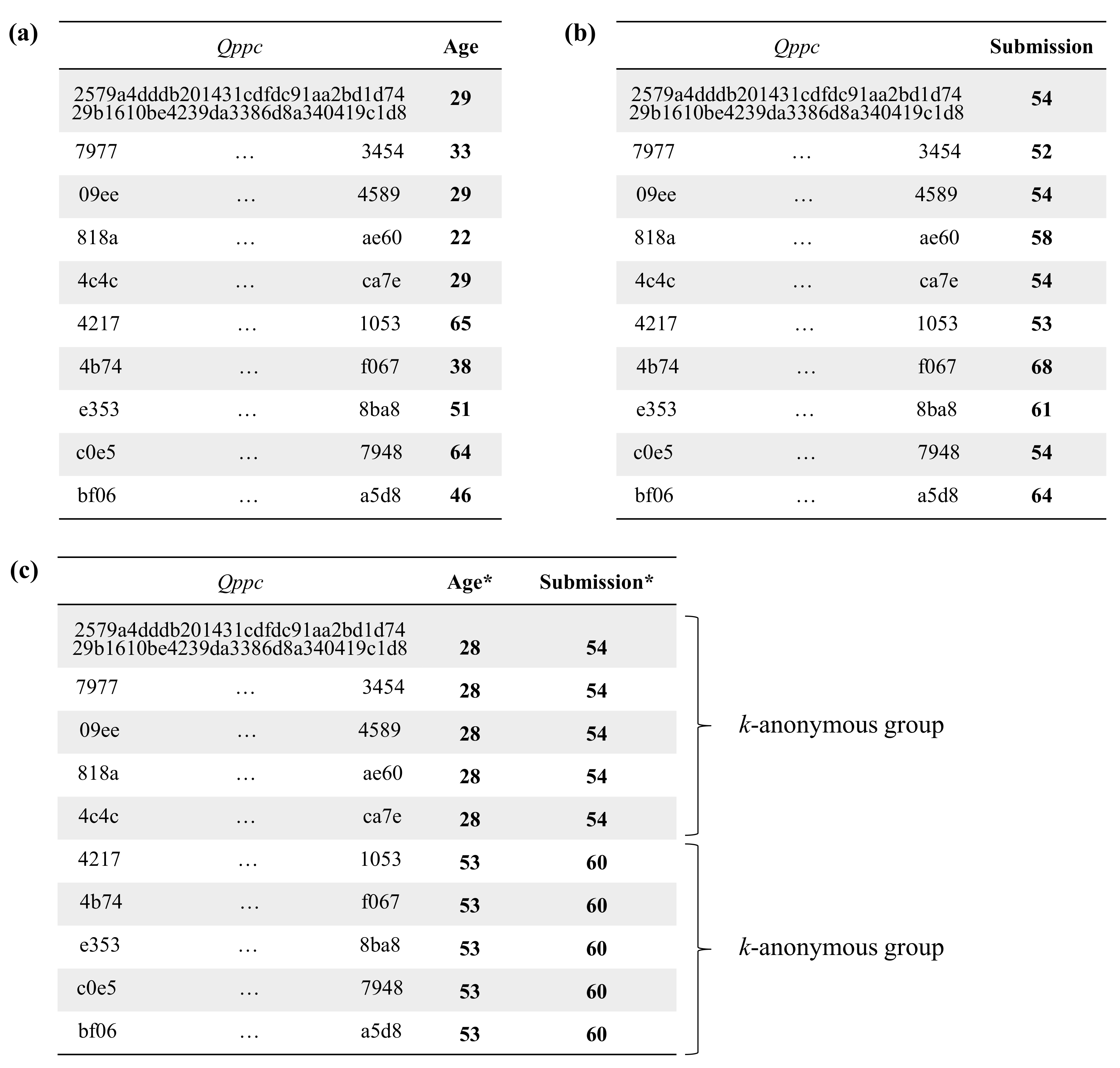
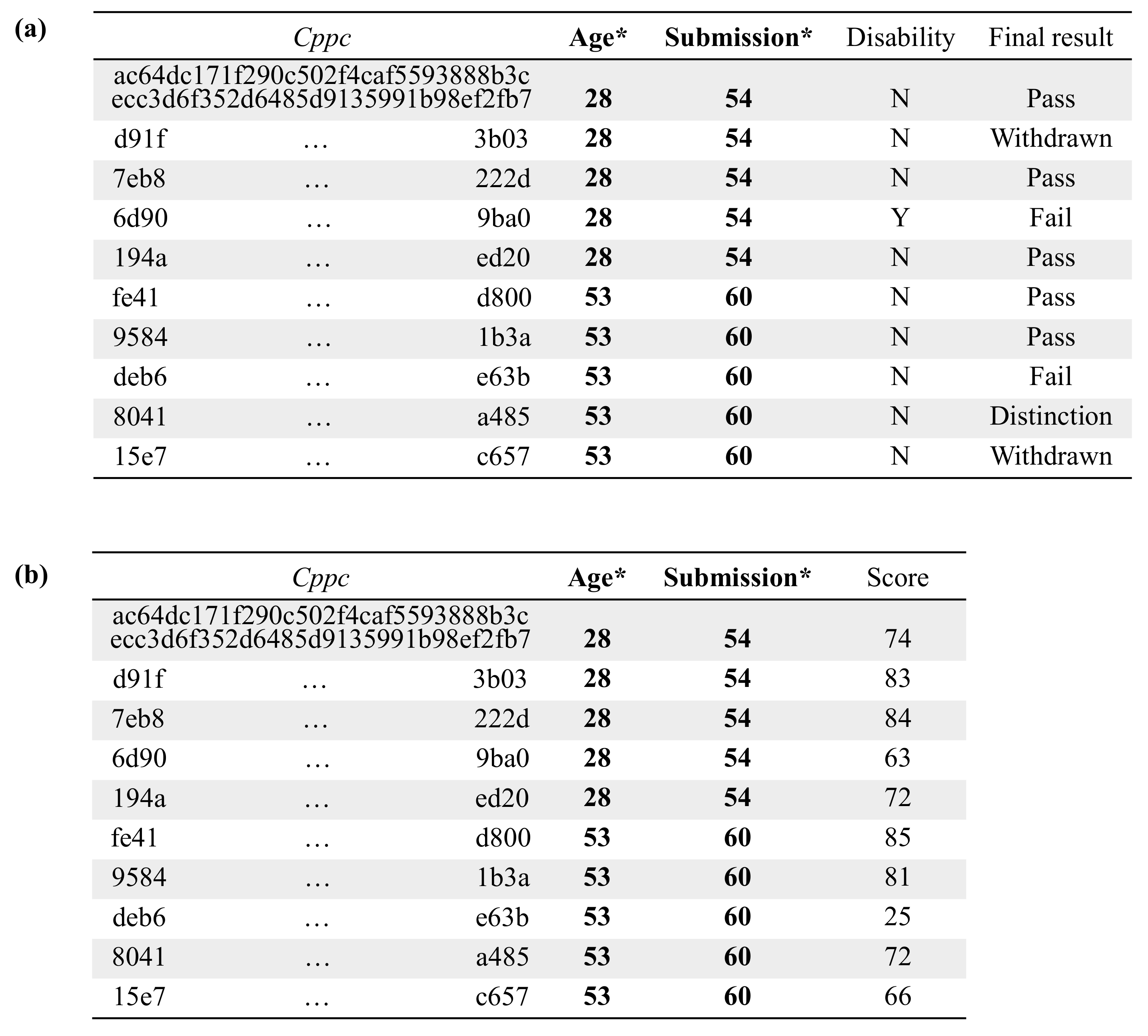
5.3. Empirical Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DBMS | DataBase Management System |
| FAIR | Findability, Accessibility, Interoperability, and Reusability |
| FERPA | Family Educational Rights and Privacy Act |
| IoT | Internet-of-Things |
| LA | Learning Analytics |
| LDP | Linked Data Platform |
| LMS | Learning Management Systems |
| NIST | National Institute of Standards and Technology |
| OULAD | Open University Learning Analytics Dataset |
| PbD | Privacy-by-Design |
| PII | Personal Identifiable Information |
| PPDP | Privacy-Preserving Data Publishing |
| PPVD | Privacy-Preserving Vertical Data |
| QI | Quasi-Identifiers |
| RDF | Resource Description Framework |
| SDL | Schema Definition Language |
| TLS | Transport Layer Security |
| VLE | Virtual Learning Environments |
References
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- IEEE Big Data Governance and Metadata Management, Industry Connections Activity. Big Data Governance and Metadata Management: Standards Roadmap. Available online: https://standards.ieee.org/content/dam/ieee-standards/standards/web/governance/iccom/bdgmm-standards-roadmap-2020.pdf (accessed on 9 September 2021).
- Chang, W.; Mishra, S.; NIST, N.P. NIST Big Data Interoperability Framework: Volume 5, Architectures White Paper Survey; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [CrossRef]
- Chang, W.; Boyd, D.; Levin, O. NIST Big Data Interoperability Framework: Volume 6, Reference Architecture; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019. [CrossRef]
- Chang, W.; Reinsch, R.; Boyd, D.; Buffington, C. NIST Big Data Interoperability Framework: Volume 7, Standards Roadmap; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019. [CrossRef]
- Open Data Center Alliance. Big Data Consumer Guide. Available online: https://bigdatawg.nist.gov/_uploadfiles/M0069_v1_7760548891.pdf (accessed on 9 September 2021).
- Ko, C.C.; Young, S.S.C. Explore the Next Generation of Cloud-Based E-Learning Environment. In Proceedings of the International Conference on Technologies for E-Learning and Digital Entertainment, Taipei, Taiwan, 7–9 September 2011; Chang, M., Hwang, W.Y., Chen, M.P., Müller, W., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6872, pp. 107–114. [Google Scholar] [CrossRef]
- Wild, F.; Mödritscher, F.; Sigurdarson, S. Mash-Up Personal Learning Environments. In E-Infrastructures and Technologies for Lifelong Learning: Next Generation Environments; Magoulas, G., Ed.; IGI Global: Hershey, PA, USA, 2011; pp. 126–149. [Google Scholar] [CrossRef]
- Rodosthenous, C.T.; Kameas, A.D.; Pintelas, P. Diplek: An Open LMS that Supports Fast Composition of Educational Services. In E-Infrastructures and Technologies for Lifelong Learning: Next Generation Environments; Magoulas, G., Ed.; IGI Global: Hershey, PA, USA, 2011; pp. 59–89. [Google Scholar] [CrossRef]
- Wurzinger, G.; Chang, V.; Guetl, C. Towards greater flexibility in the learning ecosystem—Promises and obstacles of service composition for learning environments. In Proceedings of the 3rd IEEE International Conference on Digital Ecosystems and Technologies, Istanbul, Turkey, 1–3 June 2009; pp. 241–246. [Google Scholar] [CrossRef]
- Conde, M.A.; Hernández-García, A. Data Driven Education in Personal Learning Environments—What about Learning beyond the Institution? Int. J. Learn. Anal. Artif. Intell. Educ. 2019, 1. [Google Scholar] [CrossRef] [Green Version]
- Mangaroska, K.; Vesin, B.; Kostakos, V.; Brusilovsky, P.; Giannakos, M.N. Architecting Analytics Across Multiple E-Learning Systems to Enhance Learning Design. IEEE Trans. Learn. Technol. 2021, 14, 173–188. [Google Scholar] [CrossRef]
- Griffiths, D.; Drachsler, H.; Kickmeier-Rust, M.; Steiner, C.; Hoel, T.; Greller, W. Is Privacy a Show-stopper for Learning Analytics? A Review of Current Issues and their Solutions. Learn. Anal. Rev. 2016, 6, 1–30, ISSN 2057-7494. [Google Scholar]
- U.S. Department of Education. Family Educational Rights and Privacy Act, 34 CFR §99 (FERPA). Available online: https://www2.ed.gov/policy/gen/guid/fpco/ferpa/index.html (accessed on 9 September 2021).
- Hundepool, A.; Domingo-Ferrer, J.; Franconi, L.; Giessing, S.; Nordholt, E.S.; Spicer, K.; de Wolf, P.P. Statistical Disclosure Control; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2012. [Google Scholar]
- Chang, W.; Roy, A.; Underwood, M. NIST Big Data Interoperability Framework: Volume 4, Security and Privacy; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019. [CrossRef]
- Fung, B.C.M.; Wang, K.; Chen, R.; Yu, P.S. Privacy-Preserving Data Publishing: A Survey of Recent Developments. ACM Comput. Surv. 2010, 42, 1–53. [Google Scholar] [CrossRef]
- Gursoy, M.E.; Inan, A.; Nergiz, M.E.; Saygin, Y. Privacy-Preserving Learning Analytics: Challenges and Techniques. IEEE Trans. Learn. Technol. 2017, 10, 68–81. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Torra, V. Ordinal, Continuous and Heterogeneous k-Anonymity Through Microaggregation. Data Min. Knowl. Discov. 2005, 11, 195–212. [Google Scholar] [CrossRef]
- Samarati, P. Protecting Respondents’ Identities in Microdata Release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef] [Green Version]
- Khalil, M.; Ebner, M. De-Identification in Learning Analytics. J. Learn. Anal. 2016, 3, 129–138. [Google Scholar] [CrossRef]
- U.S. Office for Civil Rights. Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule. Available online: https://www.hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification/index.html (accessed on 9 September 2021).
- Bleumer, G. Unlinkability. In Encyclopedia of Cryptography and Security; van Tilborg, H.C.A., Jajodia, S., Eds.; Springer: Boston, MA, USA, 2011; p. 1350. [Google Scholar] [CrossRef]
- Katos, V. Managing IS Security and Privacy. In Encyclopedia of Information Science and Technology, 2nd ed.; Khosrow-Pour, M., Ed.; IGI Global: Hershey, PA, USA, 2009; pp. 2497–2503. [Google Scholar] [CrossRef]
- Cavoukian, A. Privacy by Design: The 7 Foundational Principles. Available online: https://iapp.org/media/pdf/resource_center/pbd_implement_7found_principles.pdf (accessed on 9 September 2021).
- Wilkinson, M.D.; Verborgh, R.; da Silva Santos, L.O.B.; Clark, T.; Swertz, M.A.; Kelpin, F.D.; Gray, A.J.; Schultes, E.A.; van Mulligen, E.M.; Ciccarese, P.; et al. Interoperability and FAIRness through a novel combination of Web technologies. Peerj Comput. Sci. 2017, 3. [Google Scholar] [CrossRef] [Green Version]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. Official Blog of Google. 2012. Available online: http://goo.gl/zivFV (accessed on 9 September 2021).
- Obar, J.A.; Oeldorf-Hirsch, A. The biggest lie on the Internet: Ignoring the privacy policies and terms of service policies of social networking services. Inf. Commun. Soc. 2020, 23, 128–147. [Google Scholar] [CrossRef]
- Cesconetto, J.; Augusto Silva, L.; Bortoluzzi, F.; Navarro-Cáceres, M.; Zeferino, C.A.; Leithardt, V.R.Q. PRIPRO-Privacy Profiles: User Profiling Management for Smart Environments. Electronics 2020, 9, 1519. [Google Scholar] [CrossRef]
- Patwary, A.A.N.; Fu, A.; Battula, S.K.; Naha, R.K.; Garg, S.; Mahanti, A. FogAuthChain: A secure location-based authentication scheme in fog computing environments using Blockchain. Comput. Commun. 2020, 162, 212–224. [Google Scholar] [CrossRef]
- Patwary, A.A.N.; Naha, R.K.; Garg, S.; Battula, S.K.; Patwary, M.A.K.; Aghasian, E.; Amin, M.B.; Mahanti, A.; Gong, M. Towards Secure Fog Computing: A Survey on Trust Management, Privacy, Authentication, Threats and Access Control. Electronics 2021, 10, 1171. [Google Scholar] [CrossRef]
- Soria-Comas, J.; Domingo-Ferrer, J. Co-utile Collaborative Anonymization of Microdata. In Proceedings of the 12th International Conference on Modeling Decisions for Artificial Intelligence, Skövde, Sweden, 21–23 September 2015; Torra, V., Narukawa, Y., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2015; Volume 9321, pp. 192–206. [Google Scholar] [CrossRef]
- Kim, S.; Chung, Y. An anonymization protocol for continuous and dynamic privacy-preserving data collection. Future Gener. Comput. Syst. 2019, 93, 1065–1073. [Google Scholar] [CrossRef]
- Rodriguez-Garcia, M.; Cifredo-Chacón, M.A.; Quirós-Olozábal, A. Cooperative Privacy-Preserving Data Collection Protocol Based on Delocalized-Record Chains. IEEE Access 2020, 8, 180738–180749. [Google Scholar] [CrossRef]
- Chamikara, M.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy preserving distributed machine learning with federated learning. Comput. Commun. 2021, 171, 112–125. [Google Scholar] [CrossRef]
- Domadiya, N.; Rao, U.P. Privacy preserving distributed association rule mining approach on vertically partitioned healthcare data. Procedia Comput. Sci. 2019, 148, 303–312. [Google Scholar] [CrossRef]
- Mohammed, N.; Fung, B.C.M.; Wang, K.; Hung, P.C.K. Privacy-Preserving Data Mashup. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology (EDBT ’09), St. Petersburg, Russia, 23–25 March 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 228–239. [Google Scholar] [CrossRef] [Green Version]
- Flumian, M. The Management of Integrated Service Delivery: Lessons from Canada; Number 6; Inter-American Development Bank: Washington, DC, USA, 2018. [Google Scholar] [CrossRef] [Green Version]
- Sakr, S.; Bonifati, A.; Voigt, H.; Iosup, A.; Ammar, K.; Angles, R.; Aref, W.; Arenas, M.; Besta, M.; Boncz, P.A.; et al. The Future Is Big Graphs: A Community View on Graph Processing Systems. Commun. ACM 2021, 64, 62–71. [Google Scholar] [CrossRef]
- Ali, W.; Yao, B.; Saleem, M.; Hogan, A.; Ngomo, A.C.N. Survey of RDF Stores & SPARQL Engines for Querying Knowledge Graphs. TechRXiv 2021. [Google Scholar] [CrossRef]
- Abadi, D.J.; Marcus, A.; Madden, S.; Hollenbach, K. SW-Store: A vertically partitioned DBMS for Semantic Web data management. J. Very Large Data Bases 2009, 18, 385–406. [Google Scholar] [CrossRef]
- Ingalalli, V.; Ienco, D.; Poncelet, P. Chapter 5: Querying RDF Data: A Multigraph-based Approach. In NoSQL Data Models: Trends and Challenges; John Wiley & Sons: Hoboken, NJ, USA, 2018; Volume 1, pp. 135–165. [Google Scholar] [CrossRef] [Green Version]
- Speicher, S.; Arwe, J.; Malhotra, A. Linked Data Platform 1.0 W3C Recommendation. Available online: https://www.w3.org/TR/ldp/ (accessed on 9 September 2021).
- Vaidya, J.; Clifton, C. Privacy Preserving Association Rule Mining in Vertically Partitioned Data. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’02), Edmonton, AB, Canada, 23–26 July 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 639–644. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Secure set intersection cardinality with application to association rule mining. J. Comput. Sci. 2005, 13, 593–622. [Google Scholar] [CrossRef] [Green Version]
- Vaidya, J.; Clifton, C. Privacy Preserving Naive Bayes Classifier for Vertically Partitioned Data. In Proceedings of the International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2004; pp. 522–526. [Google Scholar] [CrossRef] [Green Version]
- Vaidya, J.; Clifton, C.; Kantarcioglu, M.; Patterson, A.S. Privacy-Preserving Decision Trees over Vertically Partitioned Data. ACM Trans. Knowl. Discov. Data 2008, 2, 1–27. [Google Scholar] [CrossRef]
- Wright, R.; Yang, Z. Privacy-Preserving Bayesian Network Structure Computation on Distributed Heterogeneous Data. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 713–718. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Privacy-Preserving k-Means Clustering over Vertically Partitioned Data. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 206–215. [Google Scholar] [CrossRef] [Green Version]
- Jagannathan, G.; Wright, R.N. Privacy-Preserving Distributed k-Means Clustering over Arbitrarily Partitioned Data. In Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 593–599. [Google Scholar] [CrossRef]
- Sheikhalishahi, M.; Martinelli, F. Privacy preserving clustering over horizontal and vertical partitioned data. In IEEE Symposium on Computers and Communications; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1237–1244. [Google Scholar] [CrossRef]
- Fung, B.C.M.; Trojer, T.; Hung, P.C.K.; Xiong, L.; Al-Hussaeni, K.; Dssouli, R. Service-Oriented Architecture for High-Dimensional Private Data Mashup. IEEE Trans. Serv. Comput. 2012, 5, 373–386. [Google Scholar] [CrossRef] [Green Version]
- Meyerson, A.; Williams, R. On the Complexity of Optimal K-Anonymity. In Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS ’04), Paris, France, 14–16 June 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 223–228. [Google Scholar] [CrossRef]
- Fung, B.; Wang, K.; Yu, P. Top-down specialization for information and privacy preservation. In Proceedings of the 21st International Conference on Data Engineering, Washington, DC, USA, 5–8 April 2005; pp. 205–216. [Google Scholar] [CrossRef] [Green Version]
- Cárdenas-Robledo, L.A.; Peña-Ayala, A. Ubiquitous learning: A systematic review. Telemat. Inform. 2018, 35, 1097–1132. [Google Scholar] [CrossRef]
- Chango, W.; Cerezo, R.; Romero, C. Multi-source and multimodal data fusion for predicting academic performance in blended learning university courses. Comput. Electr. Eng. 2021, 89, 106908. [Google Scholar] [CrossRef]
- Waheed, H.; Hassan, S.U.; Aljohani, N.R.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. Comput. Hum. Behav. 2020, 104, 106189. [Google Scholar] [CrossRef] [Green Version]
- Zafra, A.; Romero, C.; Ventura, S. Multiple instance learning for classifying students in learning management systems. Expert Syst. Appl. 2011, 38, 15020–15031. [Google Scholar] [CrossRef]
- Sheth, A. Internet of Things to Smart IoT Through Semantic, Cognitive, and Perceptual Computing. IEEE Intell. Syst. 2016, 31, 108–112. [Google Scholar] [CrossRef]
- Pardo, A.; Siemens, G. Ethical and privacy principles for learning analytics. Br. J. Educ. Technol. 2014, 45, 438–450. [Google Scholar] [CrossRef]
- Hoel, T.; Chen, W. Privacy-driven Design of Learning Analytics Applications—Exploring the Design Space of Solutions for Data Sharing and Interoperability. J. Learn. Anal. 2016, 3, 139–158. [Google Scholar] [CrossRef] [Green Version]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open University Learning Analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef] [Green Version]
- Vidal, V.M.P.; Casanova, M.A.; Cardoso, D.S. Incremental Maintenance of RDF Views of Relational Data. In Proceedings of the On the Move to Meaningful Internet Systems Conference, Rhodes, Greece, 21–25 October 2019; Meersman, R., Panetto, H., Dillon, T., Eder, J., Bellahsene, Z., Ritter, N., De Leenheer, P., Dou, D., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2013; Volume 8185, pp. 572–587. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Arjang, H. A Survey and Taxonomy of Leader Election Algorithms in Distributed Systems. Indian J. Sci. Technol. 2014, 7, 815–830. [Google Scholar] [CrossRef]
- Mansour, E.; Sambra, A.V.; Hawke, S.; Zereba, M.; Capadisli, S.; Ghanem, A.; Aboulnaga, A.; Berners-Lee, T. A Demonstration of the Solid Platform for Social Web Applications. In Proceedings of the 25th International Conference Companion on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 223–226. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.Z.; Hwang, G.J. A key step to understanding paradigm shifts in e-learning: Towards context-aware ubiquitous learning. Br. J. Educ. Technol. 2010, 41, E1–E9. [Google Scholar] [CrossRef]
- Escamilla-Ambrosio, P.; Rodríguez-Mota, A.; Aguirre-Anaya, E.; Acosta-Bermejo, R.; Salinas-Rosales, M. Distributing Computing in the Internet of Things: Cloud, Fog and Edge Computing Overview. In Studies in Computational Intelligence; Maldonado, Y., Trujillo, L., Schütze, O., Riccardi, A., Vasile, M., Eds.; Springer: Cham, Switzerland, 2018; Volume 731. [Google Scholar] [CrossRef]
- Li, H.; Guo, F.; Zhang, W.; Wang, J.; Xing, J. (a,k)-Anonymous Scheme for Privacy-Preserving Data Collection in IoT-based Healthcare Services Systems. J. Med. Syst. 2018, 42, 56. [Google Scholar] [CrossRef] [PubMed]
- Jara, A.J.; Olivieri, A.C.; Bocchi, Y.; Jung, M.; Kastner, W.; Skarmeta, A.F. Semantic Web of Things: An Analysis of the Application Semantics for the IoT Moving towards the IoT Convergence. Int. J. Web Grid Serv. 2014, 10, 244–272. [Google Scholar] [CrossRef]
- Zamfiroiu, A.; Iancu, B.; Boja, C.; Georgescu, T.M.; Cartas, C.; Popa, M.; Toma, C.V. IoT Communication Security Issues for Companies: Challenges, Protocols and The Web of Data. Proc. Int. Conf. Bus. Excell. 2020, 14, 1109–1120. [Google Scholar] [CrossRef]
- Hameed, S.S.; Hassan, W.H.; Latiff, L.A.; Ghabban, F. A systematic review of security and privacy issues in the internet of medical things; The role of machine learning approaches. Peerj Comput. Sci. 2021, 7, e414. [Google Scholar] [CrossRef]
- Parikh, S.; Dave, D.; Patel, R.; Doshi, N. Security and Privacy Issues in Cloud, Fog and Edge Computing. Procedia Comput. Sci. 2019, 160, 734–739. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Privacy-Preserving Data Mashup Protocol | Data Partitioning | Method for k-Anonymizing Quasi-Identifiers |
|---|---|---|
| Soria-Comas and Domingo-Ferrer (2015) [32] | Horizontal | Any method (e.g., generalization or microaggregation) |
| Kim and Chung (2019) [33] | Horizontal | Generalization, although other methods can be easily incorporated |
| Rodriguez-Garcia, Cifredo-Chacón and Quirós-Olozábal (2020) [34] | Horizontal | Any method (e.g., generalization or microaggregation) |
| Mohammed, Fung, Wang and Hung (2009) [37] | Vertical | Generalization (top-down specialization) |
| Fung, Trojer, Hung, Xiong, Al-Hussaeni and Dssouli (2012) [52] | Vertical | Generalization (top-down specialization) |
| data provider a, similarly for the data provider b | |
| Privacy-Preserving Connector | |
| used to integrate the data partitions received in the quasi-identifier collection | |
| used to integrate the data partitions received in the confidential data collection | |
| nonce used in the calculation of | |
| nonce used in the calculation of | |
| corresponding to the record i, similarly for | |
| hash function | |
| set of n records | |
| identifier attribute of the record i (held by both and ) | |
| (non-masked) quasi-identifier attributes of the record i held by , similarly for | |
| masked quasi-identifier attributes of the record i held by , similarly for | |
| confidential attributes of the record i held by , similarly for | |
| (non-masked) quasi-identifier attributes of the n records held by , similarly for | |
| (non-masked) aggregate quasi-identifiers of the n records | |
| masked aggregate quasi-identifiers of the n records |
| Protocol Step | Receive | Integrate | k-Anonymize |
|---|---|---|---|
| Step 4 | |||
| Step 5 | |||
| Step 6 | |||
| Step 9 | |||
| Step 10 |
| Data Partition | Attribute | Type | Description |
|---|---|---|---|
| age | quasi-identifier | age of the student | |
| disability | confidential | indicates whether the student has declared a disability | |
| final_result | confidential | student’s final result | |
| date_submitted | quasi-identifier | date of student submission, measured as the number of days since the start of the module presentation | |
| score | confidential | student’s score in this assessment |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez-Garcia, M.; Balderas, A.; Dodero, J.M. Privacy Preservation and Analytical Utility of E-Learning Data Mashups in the Web of Data. Appl. Sci. 2021, 11, 8506. https://doi.org/10.3390/app11188506
Rodriguez-Garcia M, Balderas A, Dodero JM. Privacy Preservation and Analytical Utility of E-Learning Data Mashups in the Web of Data. Applied Sciences. 2021; 11(18):8506. https://doi.org/10.3390/app11188506
Chicago/Turabian StyleRodriguez-Garcia, Mercedes, Antonio Balderas, and Juan Manuel Dodero. 2021. "Privacy Preservation and Analytical Utility of E-Learning Data Mashups in the Web of Data" Applied Sciences 11, no. 18: 8506. https://doi.org/10.3390/app11188506
APA StyleRodriguez-Garcia, M., Balderas, A., & Dodero, J. M. (2021). Privacy Preservation and Analytical Utility of E-Learning Data Mashups in the Web of Data. Applied Sciences, 11(18), 8506. https://doi.org/10.3390/app11188506