
A Secure Biometric Key Generation Mechanism via Deep Learning and Its Application

Abstract
:1. Introduction
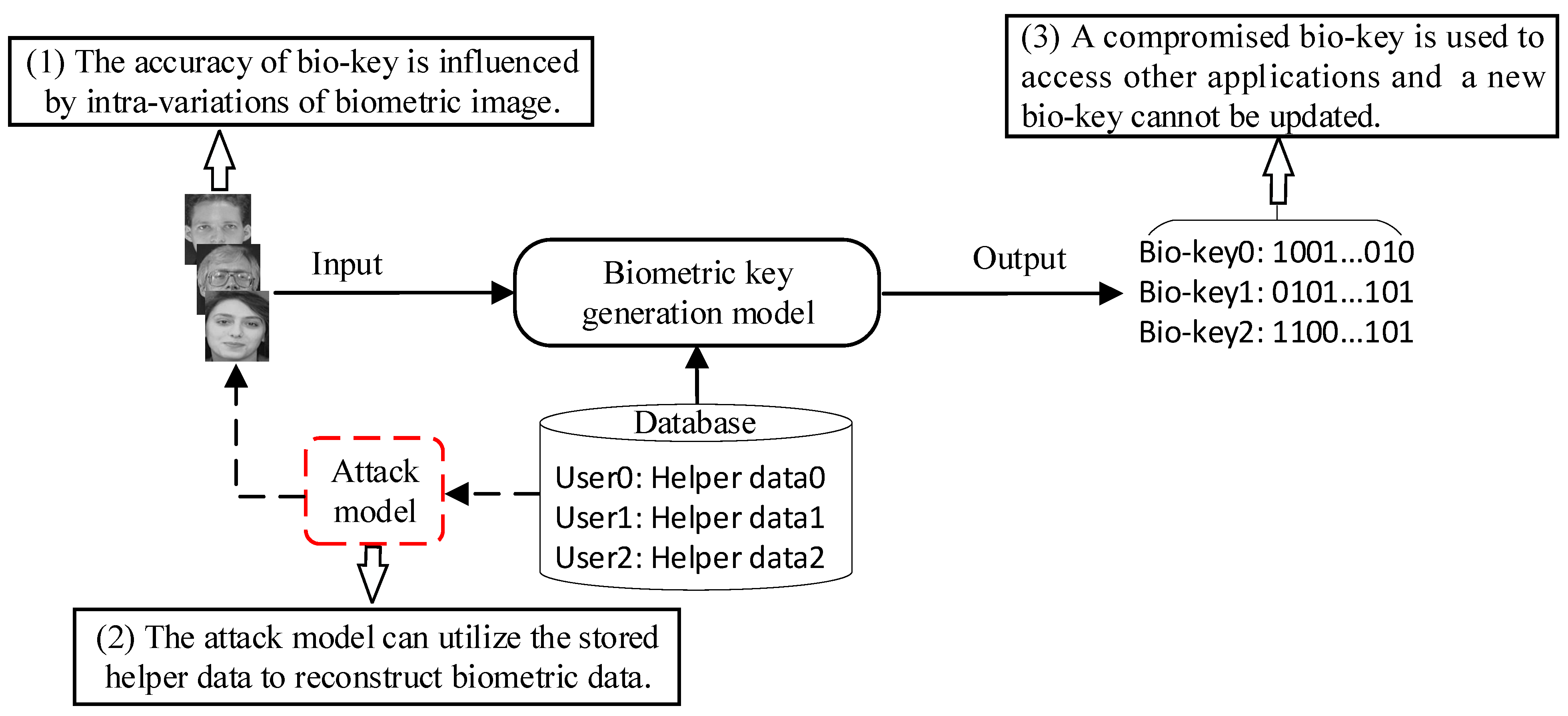
- Accuracy issue. Generated bio-key is affected by some variations of the biometric image such as illumination, blur, and pose.
- Security issue. Since the stored helper data or auxiliary information has the risk of information leakage, an attacker can reconstruct biometric data from the helper data in a database.
- Privacy issue. Once the bio-key is leaked, an attacker can use the leaked key to achieve authentication in other applications. Moreover, a new bio-key cannot be regenerated to deploy the application system.
- For the key binding scheme, biometric data and cryptographic key are bound to generate the helper data for hiding the biometric information. There are two typical instances of this scheme: fuzzy commitment and fuzzy vault. On the one hand, Ignatenko et al. [7] demonstrate the fuzzy commitment approach leaks the biometric information. On the other hand, Kholmatov et al. [8] show that multiple helper data of the fuzzy vault can be filtered chaff points to retrieve bio-key via the correlation attack. Thus, they both face the information leakage challenge.
- For the key generation scheme, biometric data is used to directly generate bio-keys without the external auxiliary information. However, the accuracy of the generated bio-key is sensitive to intra-user variations. In addition, since the input biometric data is continuous, generating a high-entropy bio-key is difficult [9]. Therefore, there is still room for improvement in accuracy and security.
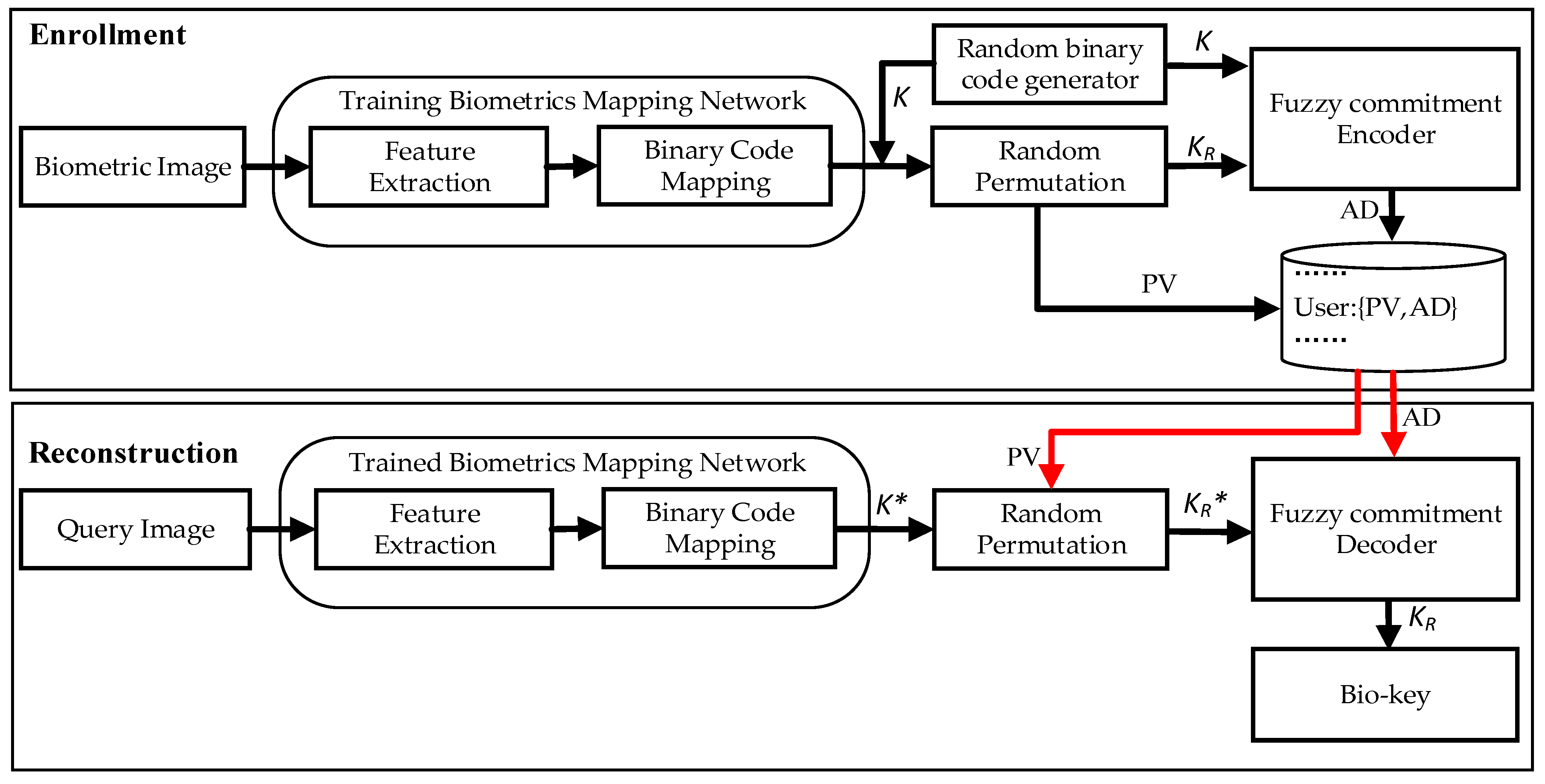
- We design a biometrics mapping network based on the DNN framework to obtain the random binary code from biometric data, which prevents information leakage and maintains the accuracy performance under intra-user variations.
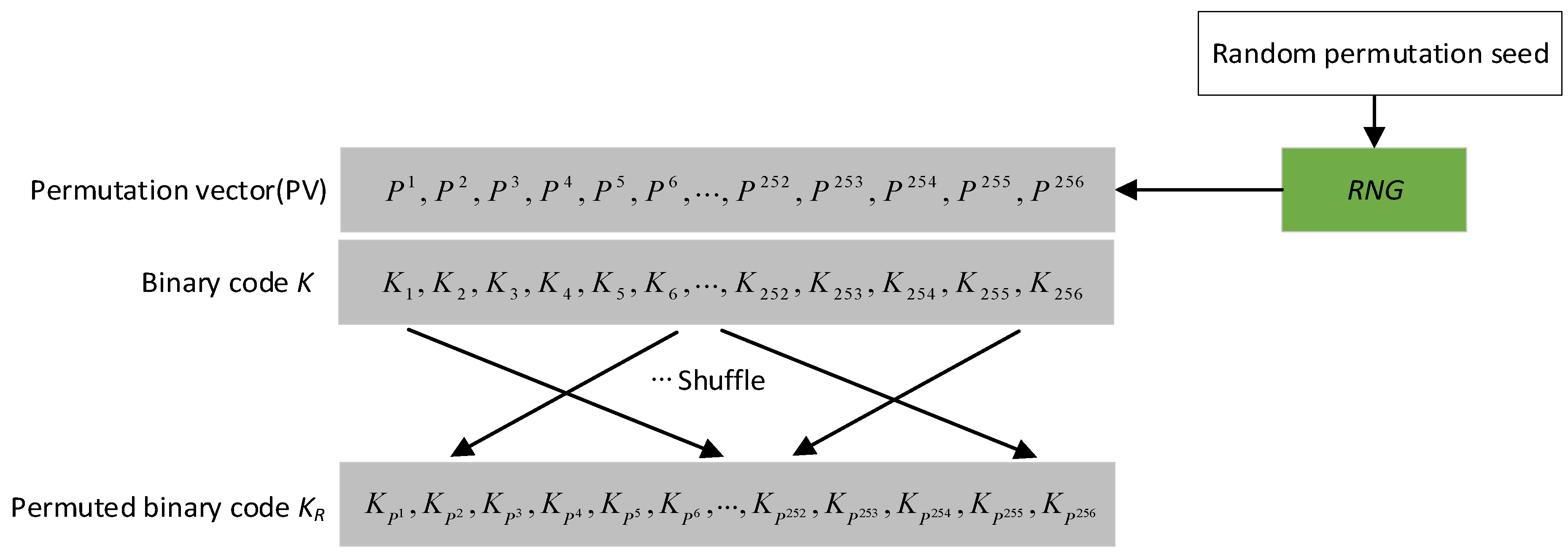
- We propose a revocable bio-key protection approach by utilizing a random permutation module, which can powerfully guarantee the revocability and protect the privacy of bio-key.
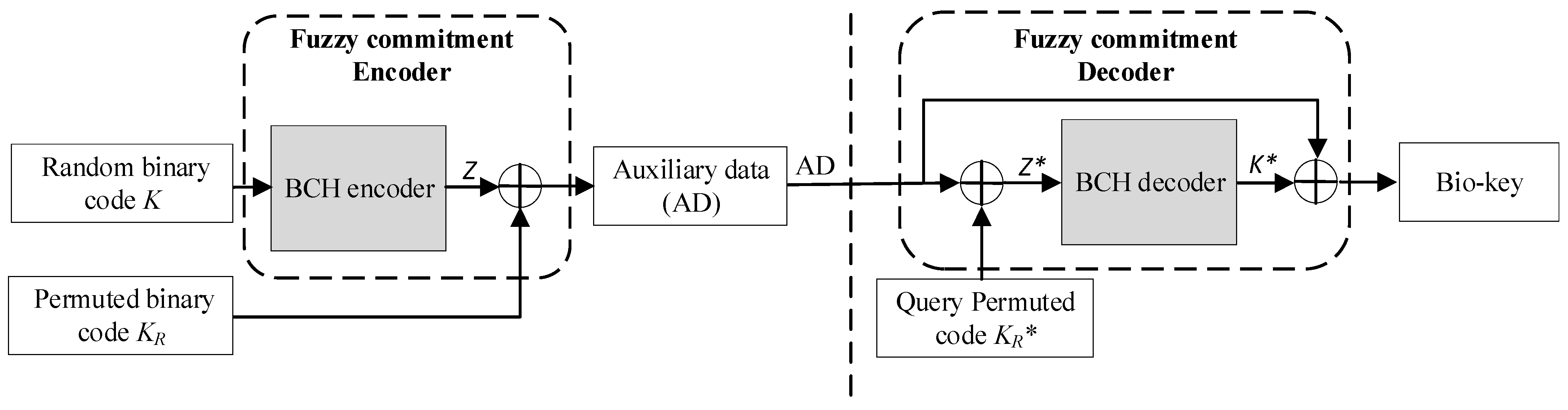
- We construct a fuzzy commitment architecture through an error-correcting technique, which can generate stable bio-keys with the help of auxiliary data, and avoid the exposure of bio-key and biometric data during enrollment.
- We conduct extended experiments on three benchmark datasets, and the results show that our model not only effectively improves the accuracy performance but also enhances the security and privacy of the biometric authentication system.
- Furthermore, we validate our bio-key generation model in the AES encryption application, which can reliably generate the bio-keys with different lengths to meet practical encryption requirements on our local computer.
2. Related Work
2.1. Key Binding Scheme Based on Biometrics
2.2. Key Generation Scheme Based on Biometrics
2.3. Secure Sketch and Fuzzy Extractor Scheme Based on Biometrics
2.4. Machine Learning Scheme
3. Methodology
3.1. Overview
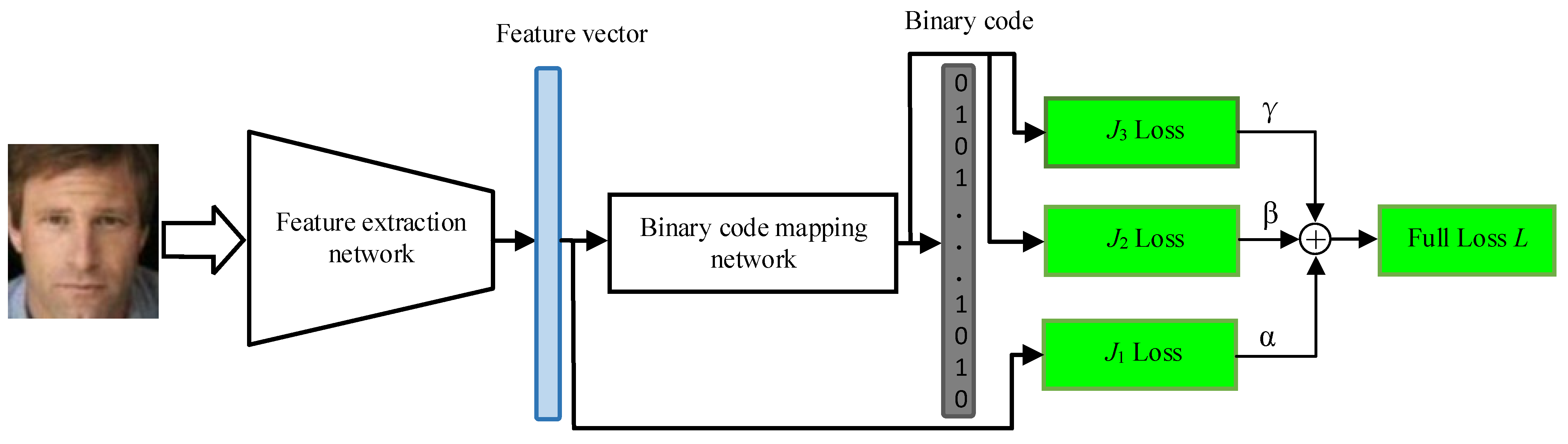
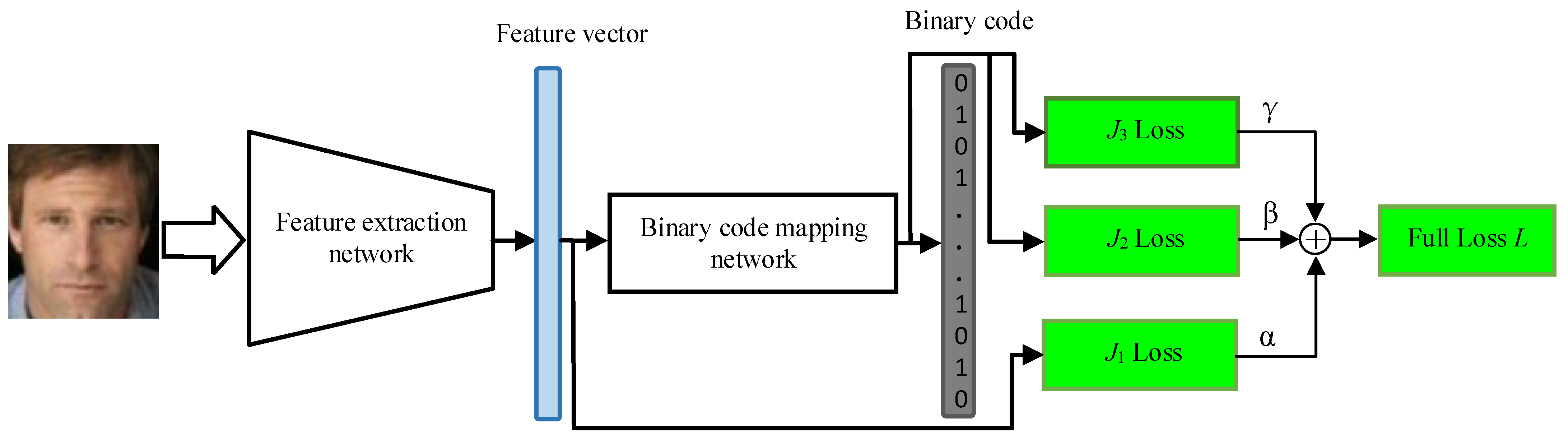
3.2. Biometrics Mapping Network Based on DNN Architecture
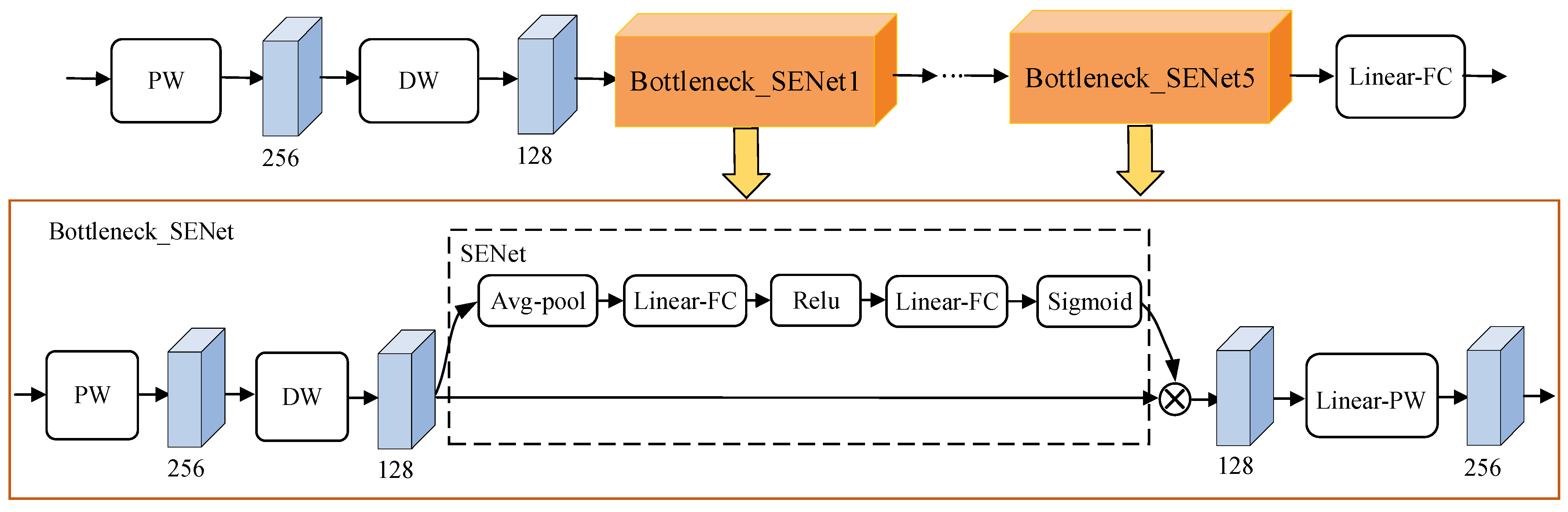
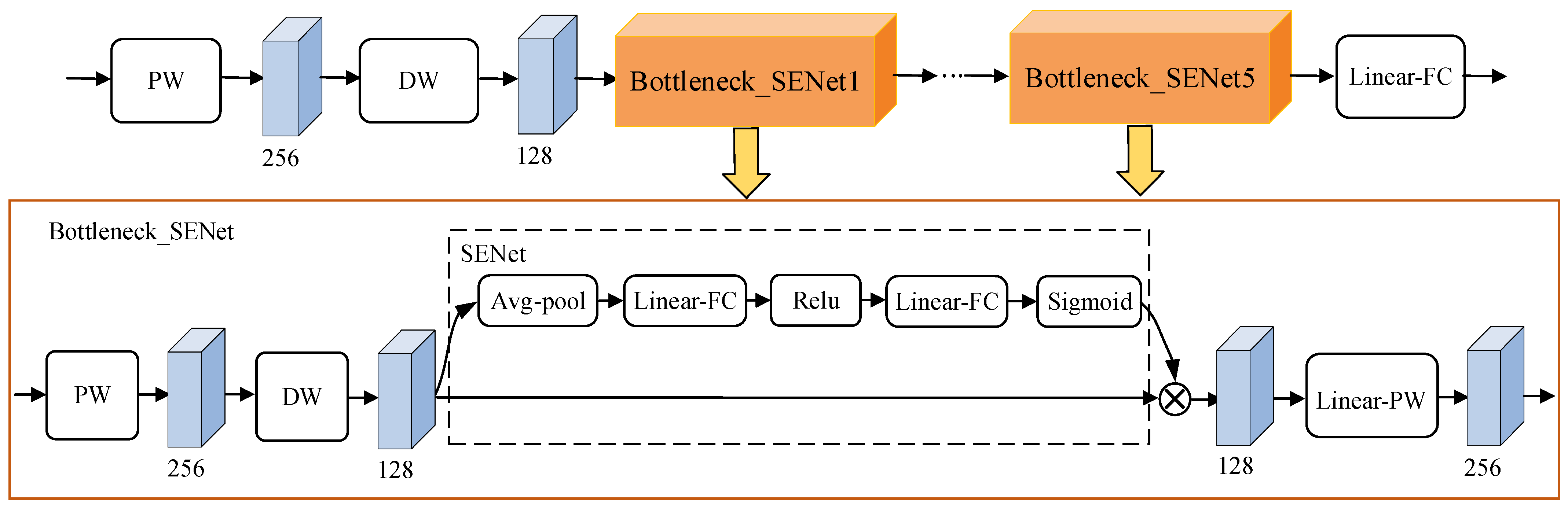
3.2.1. Feature Extraction Network
3.2.2. Binary Code Mapping Network
3.2.3. Training Network
| Algorithm 1 Process of training network in our DNN model |
| Parameters: learning rate , epoch size , weight parameter and bias paramters Input: biometric images as input data, the assigned binary code as label data Output: the trained DNN model with and |
| 1. Generate binary codes by random binary code generator according to different users. Then, establish mapping a relationship between input and output . 2. Initialize and . 3. Compute loss function according to Equation (6). 4. Update and by SGD: = +1 Until 5. Output and . |
3.3. Random Permutation and Fuzzy Commitment
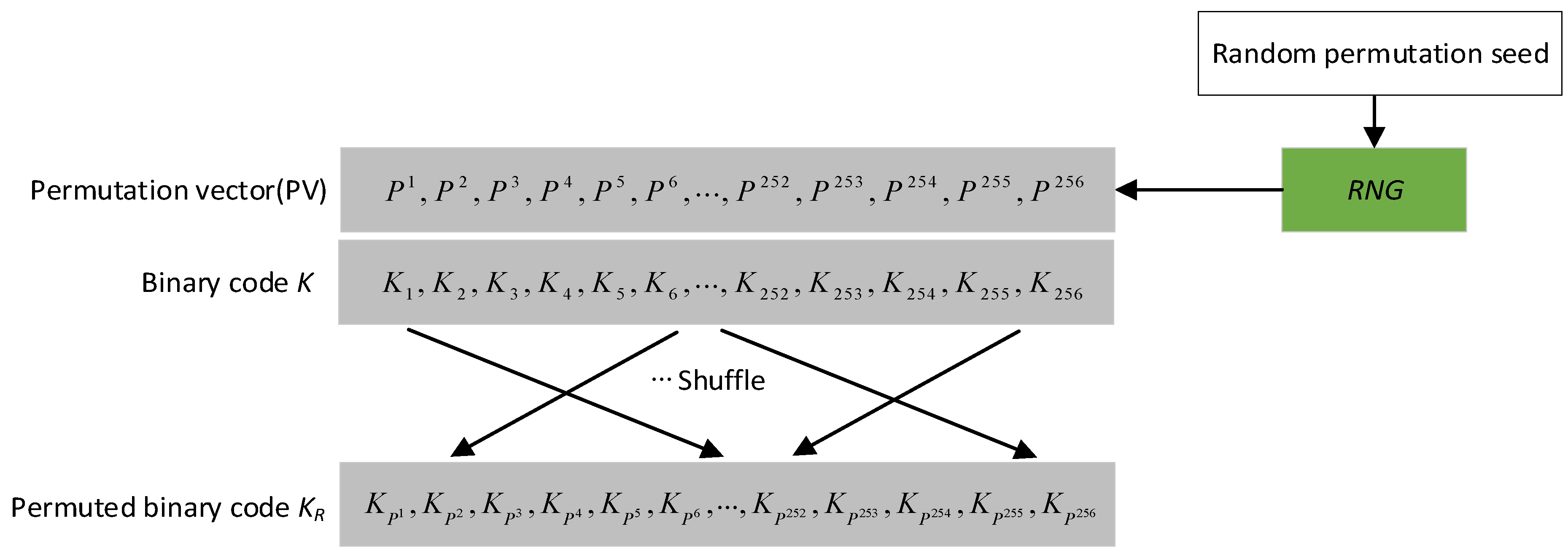
3.3.1. Random Permutation
3.3.2. Fuzzy Commitment
3.4. Enrollment and Reconstruction Procedure
4. Experimental Results
4.1. Dataset
- (1)
- ORL dataset [60]: this dataset comes from Olivetti Research Laboratory formerly named American Telephone and Telegraph Company. This dataset is composed of 10 different face images of each 40 face subjects, which includes different illuminations, expressions, and poses. In addition, we randomly select five face images of each subject for enrollment, and other face images are applied to test the performance of bio-key generation during the reconstruction stage.
- (2)
- Extended YaleB dataset [61]: this dataset includes 2332 face images of 38 subjects, and it is captured under 64 different lighting conditions. Hence, the face image of each user has 64 different illuminations. We randomly choose 10 face images of each subject in the enrollment stage, and the rest images are used for testing.
- (3)
- CMU-PIE dataset [62]: the CMU-PIE dataset contains 41,368 face images of 68 subjects, including larger variations in illuminations, poses, and expressions. In this experiment, we utilize five different poses (p05, p07, p09, p27, p29) and illuminations to validate our scheme. We follow the same partition strategy with the Extended YaleB dataset in training and testing images.
4.2. Experiment Setup
4.3. Accuracy Performance
4.4. Basic Property Analysis
4.4.1. Randomness Analysis
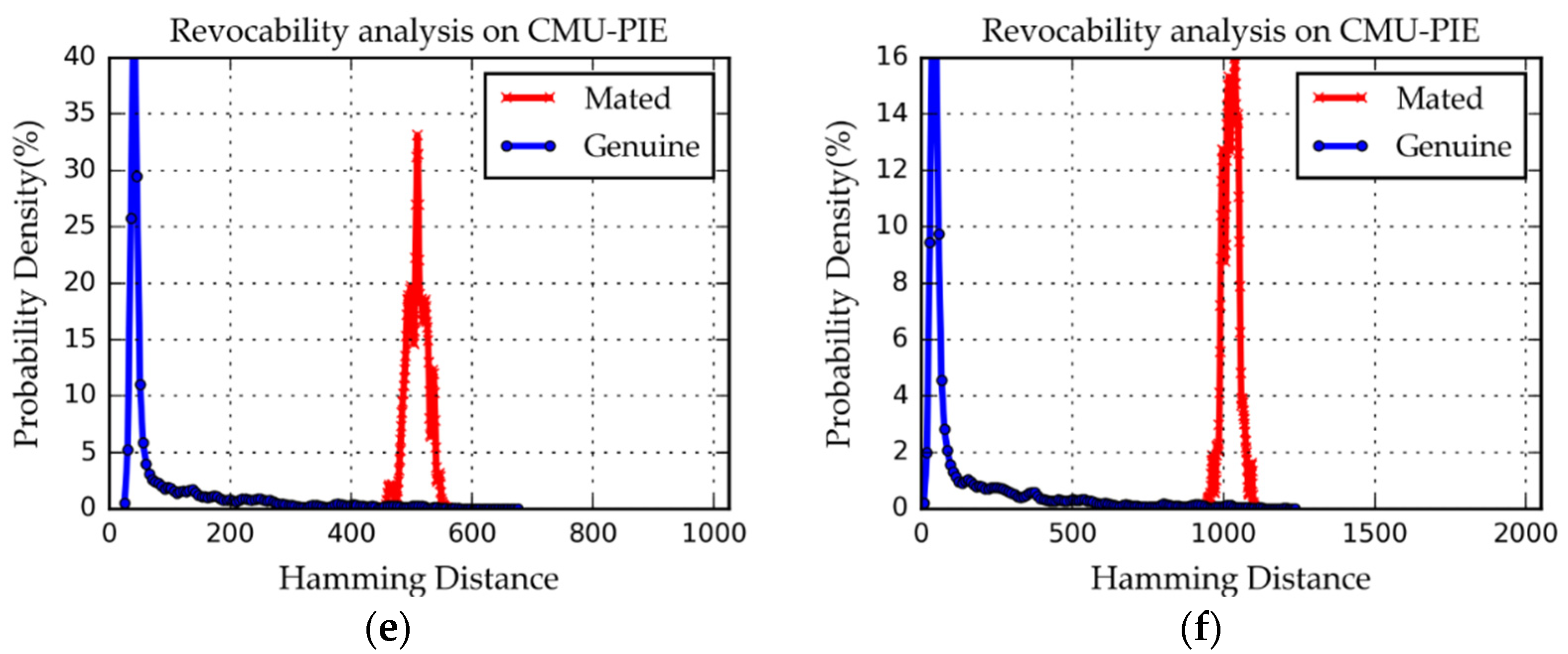
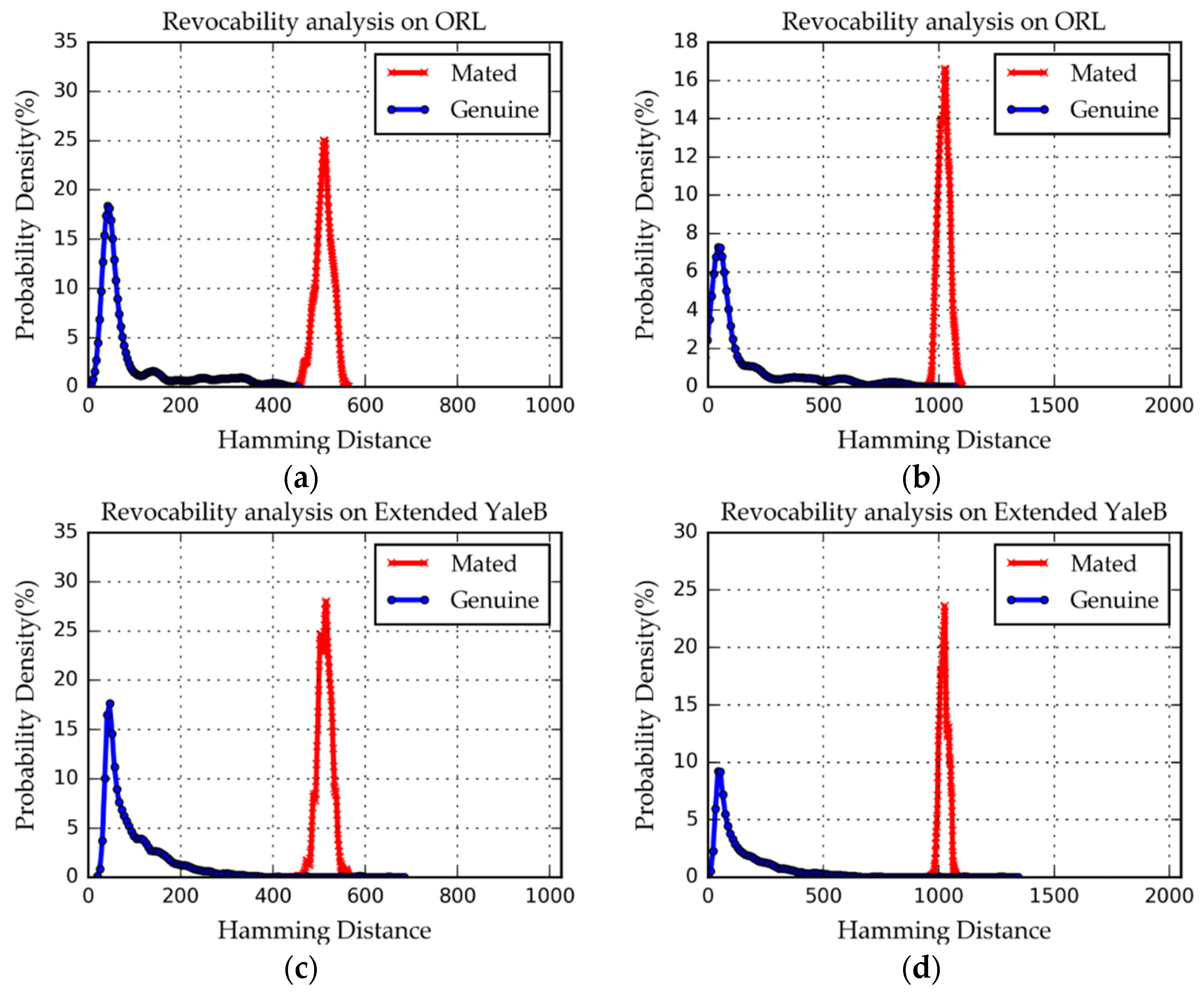
4.4.2. Revocability Analysis
4.5. Security Analysis
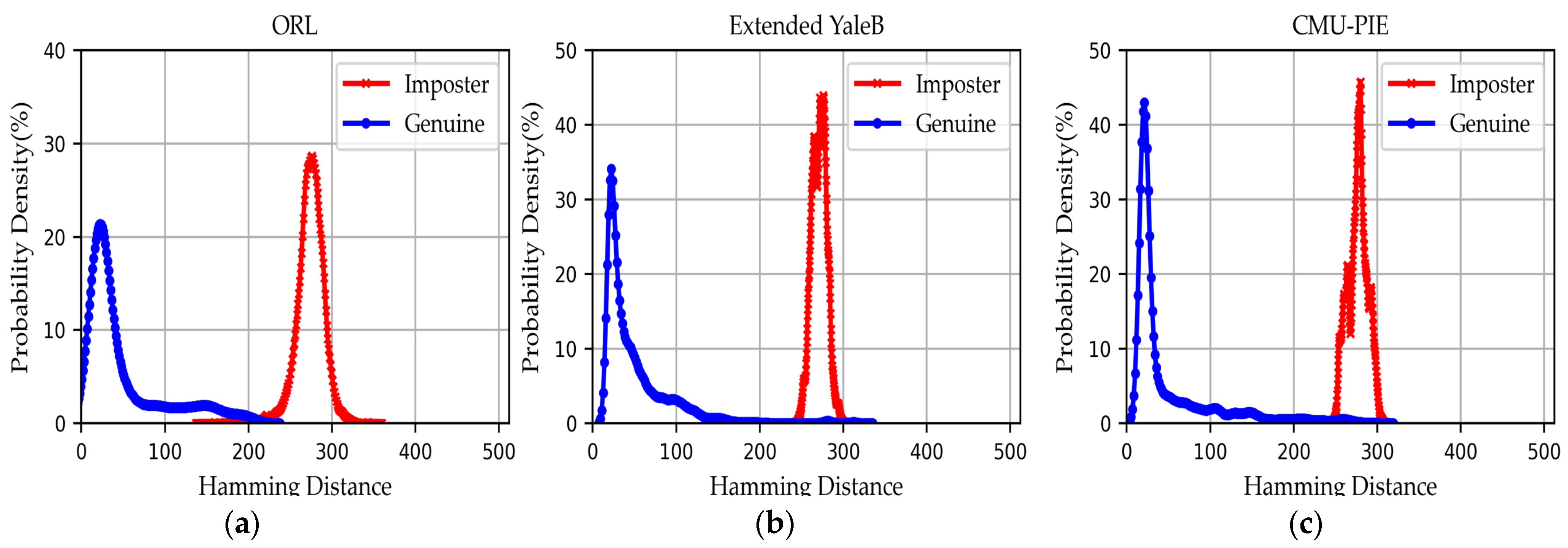
4.5.1. Resisting Information Leakage Attacks
4.5.2. Resisting Other Attacks
4.6. Comparison with Related Works
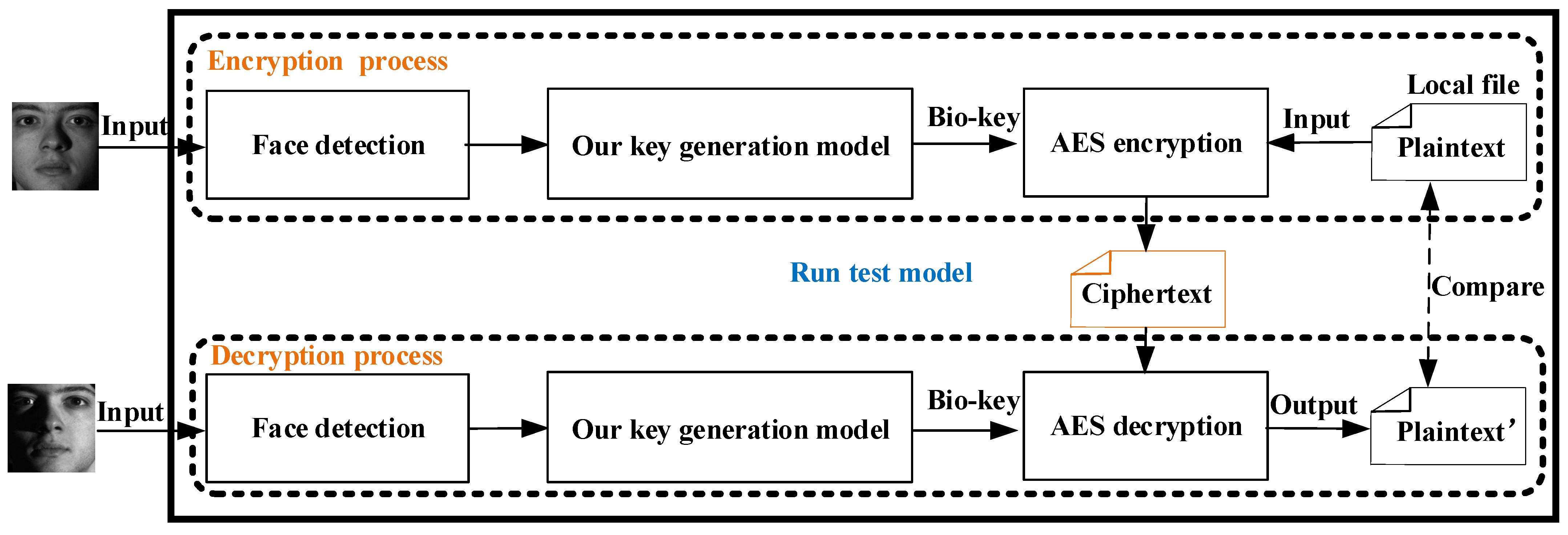
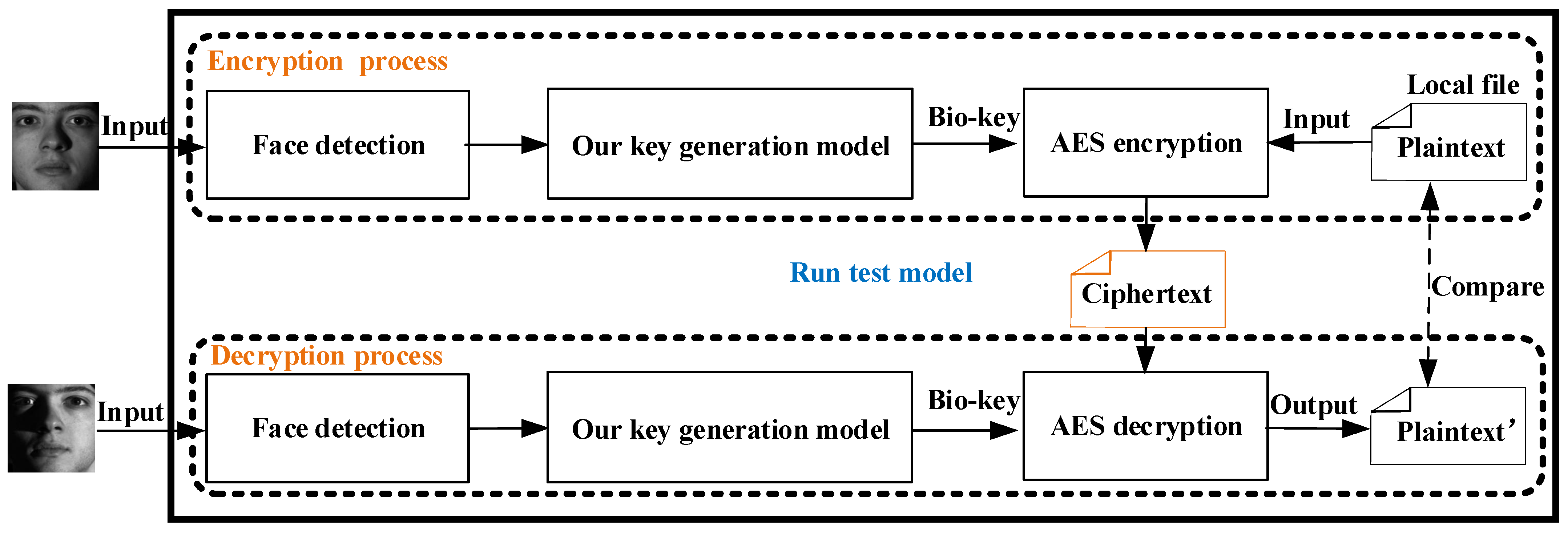
4.7. Application
4.7.1. Experiment Platform
4.7.2. Experiment Dataset
4.7.3. Experiment Process
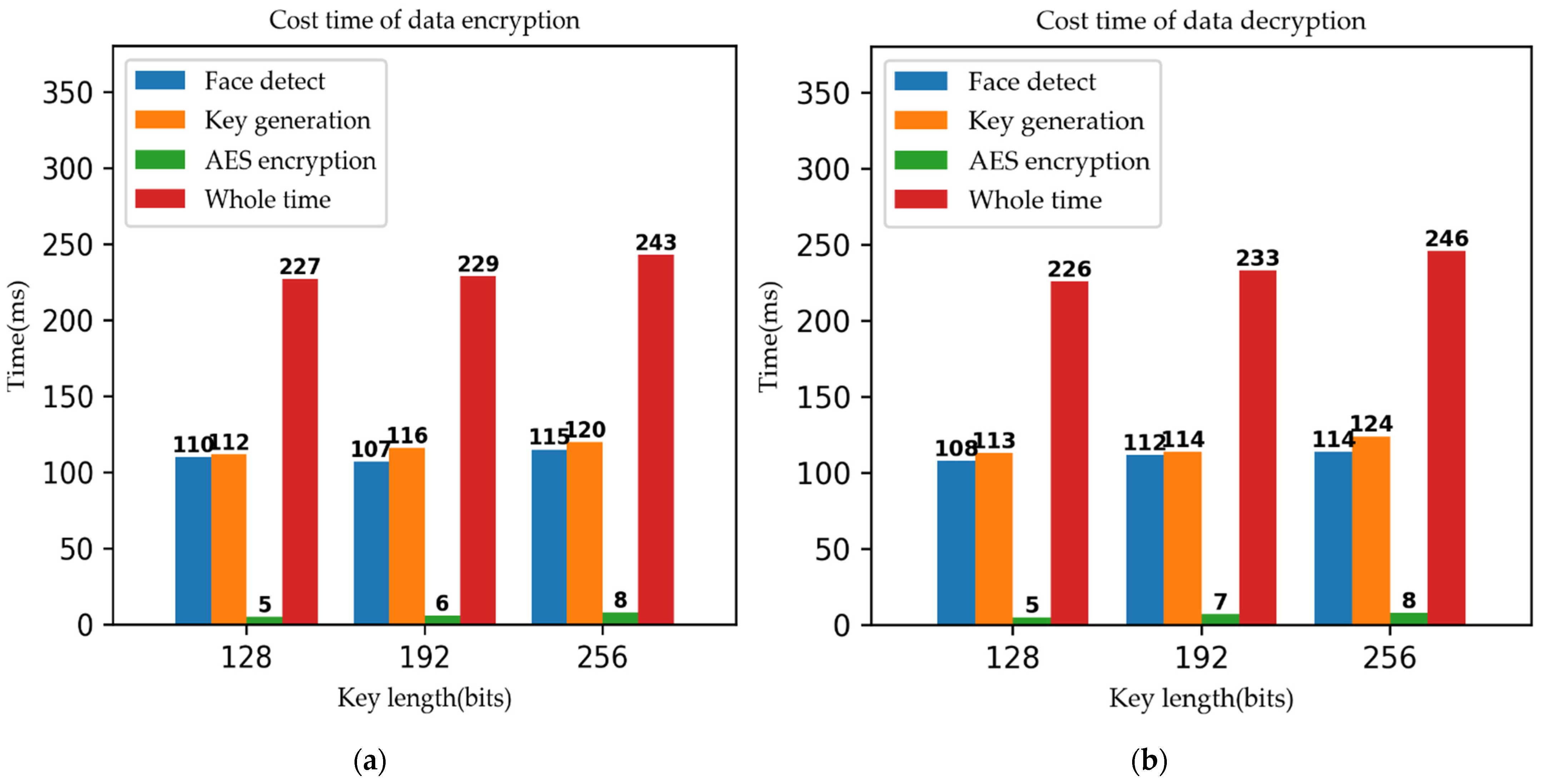
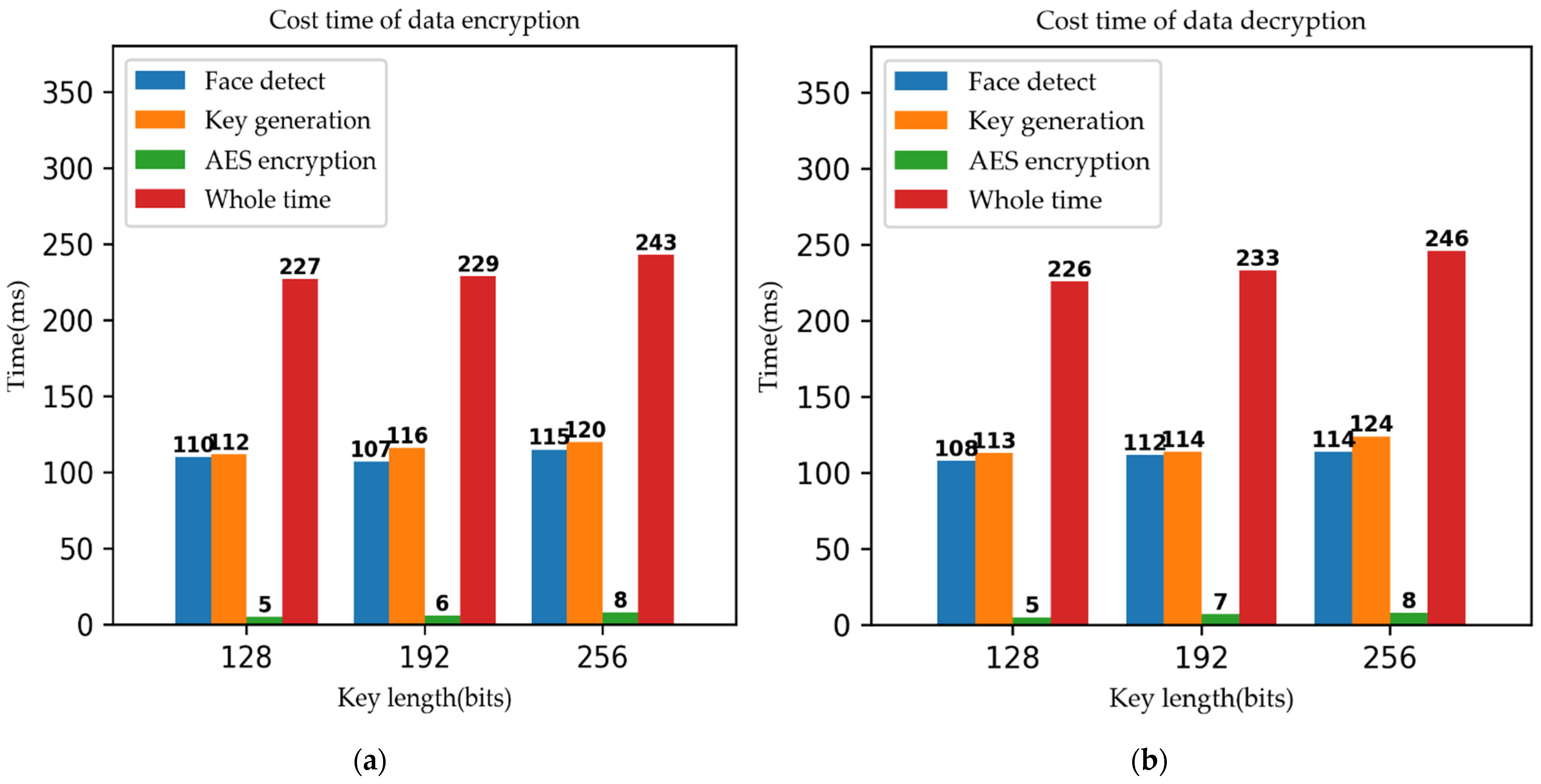
4.7.4. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hassen, O.A.; Abdulhussein, A.A.; Darwish, S.M.; Othman, Z.A.; Tiun, S.; Lotfy, Y.A. Towards a Secure Signature Scheme Based on Multimodal Biometric Technology: Application for IOT Blockchain Network. Symmetry 2020, 12, 1699. [Google Scholar] [CrossRef]
- Karimian, N. Cardiovascular PPG Biometric Key Generation for IoT in Healthcare Domain; Mobile Multimedia, Image Processing, Security, and Applications; SPIE: Baltimore, MD, USA, 2019; pp. 1–7. [Google Scholar]
- Wazid, M.; Das, A.K.; Kumari, S.; Li, X.; Wu, F. Provably secure biometric-based user authentication and key agreement scheme in cloud computing. Secur. Commun. Netw. 2016, 9, 4103–4119. [Google Scholar] [CrossRef] [Green Version]
- Sheng, W.; Chen, S.; Xiao, G. A Biometric Key Generation Method Based on Semisupervised Data Clustering. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 1205–1217. [Google Scholar] [CrossRef]
- Karimovich, G.S.; Turakulovich, K.Z. Biometric cryptosystems: Open issues and challenges. In Proceedings of the International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 2–4 November 2016; pp. 1–3. [Google Scholar]
- Jain, A.K.; Nandakumar, K. Biometric template security. EURASIP J. Adv. Signal Process. 2008, 1, 1–20. [Google Scholar] [CrossRef]
- Ignatenko, T.; Willems, F. Information leakage in fuzzy commitment schemes. IEEE Trans. Inform. Forens. Secur. 2010, 5, 337–348. [Google Scholar] [CrossRef] [Green Version]
- Kholmatov, A.; Yanikoglu, B. Realization of correlation attack against the fuzzy vault scheme. In Proceedings of the Security, Forensics, Steganography, and Watermarking of Multimedia Contents, San Jose, CA, USA, 27 January 2008; pp. 28–30. [Google Scholar]
- Sarkar, A.; Singh, B.K. A review on performance, security and various biometric template protection schemes for biometric authentication systems. Multimed. Tools Appl. 2020, 79, 27721–27776. [Google Scholar] [CrossRef]
- Smith, A. Maintaining Secrecy when Information Leakage Is Unavoidable. Ph.D. Thesis, Massachusetts Institute of Technology, McGill University, Montreal, QC, Canada, 2004. [Google Scholar]
- Dodis, Y.; Smith, A. Correcting errors without leaking partial information. In Proceedings of the 37th annual ACM symposium on Theory of computing, Baltimore, MD, USA, 22–24 May 2016; pp. 654–663. [Google Scholar]
- Linnartz, J.P.; Tuyls, P. New Shielding Functions to Enhance Privacy and Prevent Misuse of Biometric Templates; Springer: Guildford, UK, 2003; Volume 2688, pp. 393–402. [Google Scholar]
- Qi, W.; Jinxiang, L.; Luc, C.; Zhengguo, Y.; Liang, L.; Wenyin, L. A Novel Feature Representation: Aggregating Convolution Kernels for Image Retrieval. Neural Netw. 2020, 130, 1–10. [Google Scholar]
- Labati, R.D.; Munoz, E. Deep-ECG: Convolutional neural networks for ecg biometric recognition. Pattern Recognit. Lett. 2019, 126, 78–85. [Google Scholar] [CrossRef]
- Pandey, R.K.; Zhou, Y.; Kota, B.U. Deep Secure Encoding for Face Template Protection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June 2016; pp. 77–83. [Google Scholar]
- Roh, J.H.; Cho, S. Learning based biometric key generation method using CNN and RNN. In Proceedings of the 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE), Bali, Indonesia, 24–26 July 2018; pp. 1–4. [Google Scholar]
- Roy, N.D.; Biswas, A. Fast and robust retinal biometric key generation using deep neural nets. Multimed. Tools Appl. 2020, 79, 6823–6843. [Google Scholar] [CrossRef]
- Juels, A.; Wattenberg, M. A fuzzy commitment scheme. In Proceedings of the 6th ACM Conference on Computer and Communication Security, Kent Ridge Digital Labs, Singapore, 1–4 November 1999; pp. 28–36. [Google Scholar]
- Juels, A.; Sudan, M. A fuzzy vault scheme. In Proceedings of the IEEE International Symposium on Information Theory, Lausanne, Switzerland, 30 June 2002; pp. 1–13. [Google Scholar]
- Hao, F.; Anderson, R. Combining crypto with biometrics effectively. IEEE Trans. Comput. 2006, 55, 1081–1088. [Google Scholar]
- Veen, M.; Kevenaar, T.; Schrijen, G.J. Face biometrics with renewable templates. SPIE 2006, 6072, 1–13. [Google Scholar]
- Chauhan, S.; Sharma, A. Fuzzy Commitment Scheme based on Reed Solomon Codes. In Proceedings of the 9th International Conference on Security of Information and Networks, Newark, NJ, USA, 20–22 July 2016; pp. 96–99. [Google Scholar]
- Zhou, X.; Kuijper, A.; Veldhuis, R. Quantifying Privacy and Security of Biometric Fuzzy Commitment. In Proceedings of the 2011 International Joint Conference on Biometrics, Washington, DC, USA, 11–13 October 2011; pp. 1–8. [Google Scholar]
- Rathgeb, C.; Uhl, A. Statistical attack against iris-biometric fuzzy commitment schemes. In Proceedings of the Computer Vision and Pattern Recognition Workshops (CVPRW), Colorado Springs, CO, USA, 20–25 June 2011; pp. 25–32. [Google Scholar]
- Rathgeb, C.; Uhl, A. Statistical attack against fuzzy commitment scheme. Biometrics Iet. 2012, 1, 94–104. [Google Scholar] [CrossRef]
- Clancy, T.C.; Kiyavash, N. Secure smartcardbased fingerprint authentication. In Proceedings of the 2003 ACM SIGMM workshop on Biometrics methods and applications, Berkley, CA, USA, 8 November 2003; pp. 45–52. [Google Scholar]
- Uludag, U.; Jain, A. Securing fingerprint template: Fuzzy vault with helper data. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006; pp. 1–8. [Google Scholar]
- Nandakumar, K.; Jain, A.K. Fingerprint-based fuzzy vault: Implementation and performance. IEEE Trans. Inform. Forens. Secur. 2007, 2, 744–757. [Google Scholar] [CrossRef]
- Li, C.; Hu, J. A security-enhanced alignment-free fuzzy vault-based fingerprint cryptosystem using pair-polar minutiae structures. IEEE Trans. Inform. Forens. Secur. 2015, 11, 543–555. [Google Scholar] [CrossRef]
- Scheirer, W.J.; Boult, T.E. Cracking fuzzy vaults and biometric encryption. In Proceedings of the Biometrics Symposium, Baltimore, MD, USA, 11–13 September 2007; pp. 1–6. [Google Scholar]
- Hartloff, J.; Bileschi, M. Security analysis for fingerprint fuzzy vaults. In Proceedings of the Conference on biometric and surveillance technology for human and activity identification X, Baltimore, MD, USA, 31 May 2013; pp. 1–12. [Google Scholar]
- Tams, B.; Mihăilescu, P.; Munk, A. Security considerations in minutiae-based fuzzy vaults. IEEE Trans. Inform. Forens. Secur. 2015, 10, 985–998. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, T. Generalized optimal thresholding for biometric key generation using face images. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 14 September 2005; pp. 1–4. [Google Scholar]
- Hoque, S.; Fairhurst, M.C.; Howells, W. Evaluating Biometric Encryption Key Generation Using Handwritten Signatures. In Proceedings of the 2008 Bio-inspired, Learning and Intelligent Systems for Security, Edinburgh, UK, 4–6 August 2008; pp. 17–22. [Google Scholar]
- Rathgeb, C.; Uhl, A. An iris-based Interval-Mapping scheme for Biometric Key generation. In Proceedings of the 6th International Symposium on Image and Signal Processing and Analysis, Salzburg, Austria, 16–18 September 2009; pp. 511–516. [Google Scholar]
- Lalithamani, N.; Soman, K.P. An Efficient Approach For Non-Invertible Cryptographic Key Generation From Cancelable Fingerprint Biometrics. In Proceedings of the 2009 International Conference on Advances in Recent Technologies in Communication and Computing, Kottayam, Kerala, India, 27–28 October 2009; pp. 47–52. [Google Scholar]
- Wu, L.; Liu, X.; Yuan, S. A novel key generation cryptosystem based on face features. In Proceedings of the IEEE International Conference on Signal Processing, Beijing, China, 24–28 October 2010; pp. 1675–1678. [Google Scholar]
- Ranjan, R.; Singh, S.K. Improved and innovative key generation algorithms for biometric cryptosystems. In Proceedings of the IEEE International Advance Computing Conference, Ghaziabad, India, 22–23 February 2013; pp. 943–946. [Google Scholar]
- Sarkar, A.; Singh, B.K.; Bhaumik, U. RSA Key Generation from Cancelable Fingerprint Biometrics. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 7–18 August 2017; pp. 1–6. [Google Scholar]
- Anees, A.; Chen, Y.P.P. Discriminative binary feature learning and quantization in biometric key generation. Pattern Recognit. 2018, 77, 289–305. [Google Scholar] [CrossRef]
- Dodis, Y.; Ostrovsky, R. Fuzzy extractors: How to generate strong keys from biometrics and other noisy data. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; pp. 523–540. [Google Scholar]
- Chang, E.-C.; Qiming, L. Hiding Secret Points Amidst Chaff. In Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Petersburg, Russia, 28 May–1 June 2006; pp. 59–72. [Google Scholar]
- Sutcu, Y.; Li, Q.; Memon, N.D. Secure Biometric Templates from Fingerprint-Face Features. In Proceedings of the 2007 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–6. [Google Scholar]
- Li, Q.; Chang, E.C. Robust, short and sensitive authentication tags using secure sketch. In Proceedings of the 8th Workshop on Multimedia and Security, Geneva, Switzerland, 26–27 September 2006; pp. 56–61. [Google Scholar]
- Lee, S.W.; Li, S.Z. Fuzzy Extractors for Minutiae-Based Fingerprint Authentication. Adv. Biom. 2007, 4642, 760–769. [Google Scholar]
- Yang, W.; Hu, J.; Song, W. A Delaunay Triangle-Based Fuzzy Extractor for Fingerprint Authentication. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 66–70. [Google Scholar]
- Chi, C.; Wang, C.; Yang, T. Optional multi-biometric cryptosystem based on fuzzy extractor. In Proceedings of the International Conference on Fuzzy Systems and Knowledge Discovery, Xiamen, China, 19–21 August 2014; pp. 1–6. [Google Scholar]
- Alexandr, K.; Anastasia, K.; Anna, U. New Code Based Fuzzy Extractor for Biometric Cryptography. In Proceedings of the International Scientific-Practical Conference Problems of Infocommunications. Science and Technology, Kharkiv, Ukraine, 9–12 October 2018; pp. 119–124. [Google Scholar]
- Wang, Q.; Liu, X.; Liu, W.; Liu, A.-A.; Liu, W.; Mei, T. MetaSearch: Incremental Product Search via Deep Meta-learning. IEEE Trans. Image Process. 2020, 29, 7549–7564. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–10. [Google Scholar]
- Wu, Z.; Tian, L. Generating stable biometric keys for flexible cloud computing authentication using finger vein. Inform. Sci. 2018, 433, 431–447. [Google Scholar] [CrossRef]
- Panchal, G.; Samanta, D. A novel approach to fingerprint biometric-based cryptographic key generation and its applications to storage security. Comput. Electr. Eng. 2018, 69, 461–479. [Google Scholar] [CrossRef]
- Wang, Y.; Li, B. A biometric key generation mechanism for authentication based on face image. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), NanJing, China, 23–25 October 2020; pp. 1–5. [Google Scholar]
- Iurii, M.; Farhad, S.; Leandro, C.; Nuno, G. Towards Facial Biometrics for ID Document Validation in Mobile Devices. Appl. Sci. 2021, 11, 1–15. [Google Scholar]
- Taigman, Y.; Ming, Y.; Ranzato, M. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Deng, J.; Guo, J.; Xu, E.N. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1–11. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices. arXiv 2018, arXiv:1804.07573v4. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. Comput. Sci. 2012, 3, 212–223. [Google Scholar]
- Samaria, F.; Harter, A. Parameterisation of a stochastic model for human face identification . In Proceedings of the 2nd IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; pp. 138–142. [Google Scholar]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. From few to many: Illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar]
- Sim, T.; Baker, S.; Bsat, M. The cmu pose, illumination, and expression (pie) database. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21–21 May 2002; pp. 53–58. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Nazari, S.; Moin, M.S. A discriminant binarization transform using genetic algorithm and error-correcting output code for face template protection. Int. J. Mach. Learn. Cybern. 2019, 10, 433–449. [Google Scholar] [CrossRef]
- Feng, Y.C.; Yuen, P.C. A hybrid approach for generating secure and discriminating face template. IEEE Trans. Inform. Forens. Secur. 2010, 5, 103–117. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.C.; Yuen, P.C. Binary discriminant analysis for generating binary face template. IEEE Trans. Inform. Forens. Secur. 2012, 7, 613–624. [Google Scholar] [CrossRef]
- Chauhan, S.; Sharma, A. Improved fuzzy commitment scheme. Int. J. Inf. Technol. 2019, 1, 1–11. [Google Scholar] [CrossRef]
- Asthana, R.; Walia, G.S.; Gupta, A. A novel biometric crypto system based on cryptographic key binding with user biometrics. Multimed. Syst. 2021, 3, 1–15. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Length | ORL | Extended YaleB | CMU-PIE | |||
|---|---|---|---|---|---|---|
| GAR | EER | GAR | EER | GAR | EER | |
| 128 | 99.12% | 0.75% | 99.40% | 0.83% | 97.97% | 1.49% |
| 256 | 99.40% | 0.70% | 99.28% | 0.86% | 98.34% | 1.35% |
| 512 | 99.59% | 0.52% | 99.29% | 0.85% | 98.06% | 1.47% |
| 1024 | 99.62% | 0.51% | 99.31% | 0.86% | 98.47% | 1.09% |
| 2048 | 99.22% | 0.72% | 99.30% | 0.85% | 98.43% | 1.29% |
| Method | Length | GAR@1%FAR | EER |
|---|---|---|---|
| Genetic-ECOC [64] | 72 | 93.42% | - |
| Our method | 128 | 99.40% | 0.83% |
| Method | Length | GAR@1%FAR | EER |
|---|---|---|---|
| Hybrid [65] | 210 | 90.61% | 6.81% |
| BDA [66] | 76 | 96.38% | -- |
| MEB coding [15] | 1024 | 97.59% | 1.14% |
| Genetic-ECOC [64] | 88 | 97.01% | -- |
| Our method | 1024 | 98.47% | 1.09% |
| Dataset | Degree of Freedom (N) | |||
|---|---|---|---|---|
| ORL | 0.4996 | 0.0232 | 464 | |
| Extended YaleB | 0.4934 | 0.0241 | 431 | |
| CMU-PIE | 0.4980 | 0.0247 | 407 |
| Method | Biometrics | Storage Data | Technique Scheme | Resist Information Leakage |
|---|---|---|---|---|
| Li et al. [29] | Fingerprint | chaff points | fuzzy vault | NO |
| Chauhan et al. [67] | Iris | Helper data | fuzzy commitment | NO |
| Roy et al. [17] | Retinal | Biometric template | DNN | NO |
| Asthana et al. [68] | Fingerprint | Helper data | Key binding | NO |
| Ours | Face | AD and PV | DNN | Yes |
| Length | GAR@1%FAR | EER |
|---|---|---|
| 128 | 99.92% | 0.05% |
| 192 | 99.96% | 0.03% |
| 256 | 99.95% | 0.04% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, B.; Zhang, Y.; Wu, J.; Ma, Q. A Secure Biometric Key Generation Mechanism via Deep Learning and Its Application. Appl. Sci. 2021, 11, 8497. https://doi.org/10.3390/app11188497
Wang Y, Li B, Zhang Y, Wu J, Ma Q. A Secure Biometric Key Generation Mechanism via Deep Learning and Its Application. Applied Sciences. 2021; 11(18):8497. https://doi.org/10.3390/app11188497
Chicago/Turabian StyleWang, Yazhou, Bing Li, Yan Zhang, Jiaxin Wu, and Qianya Ma. 2021. "A Secure Biometric Key Generation Mechanism via Deep Learning and Its Application" Applied Sciences 11, no. 18: 8497. https://doi.org/10.3390/app11188497
APA StyleWang, Y., Li, B., Zhang, Y., Wu, J., & Ma, Q. (2021). A Secure Biometric Key Generation Mechanism via Deep Learning and Its Application. Applied Sciences, 11(18), 8497. https://doi.org/10.3390/app11188497