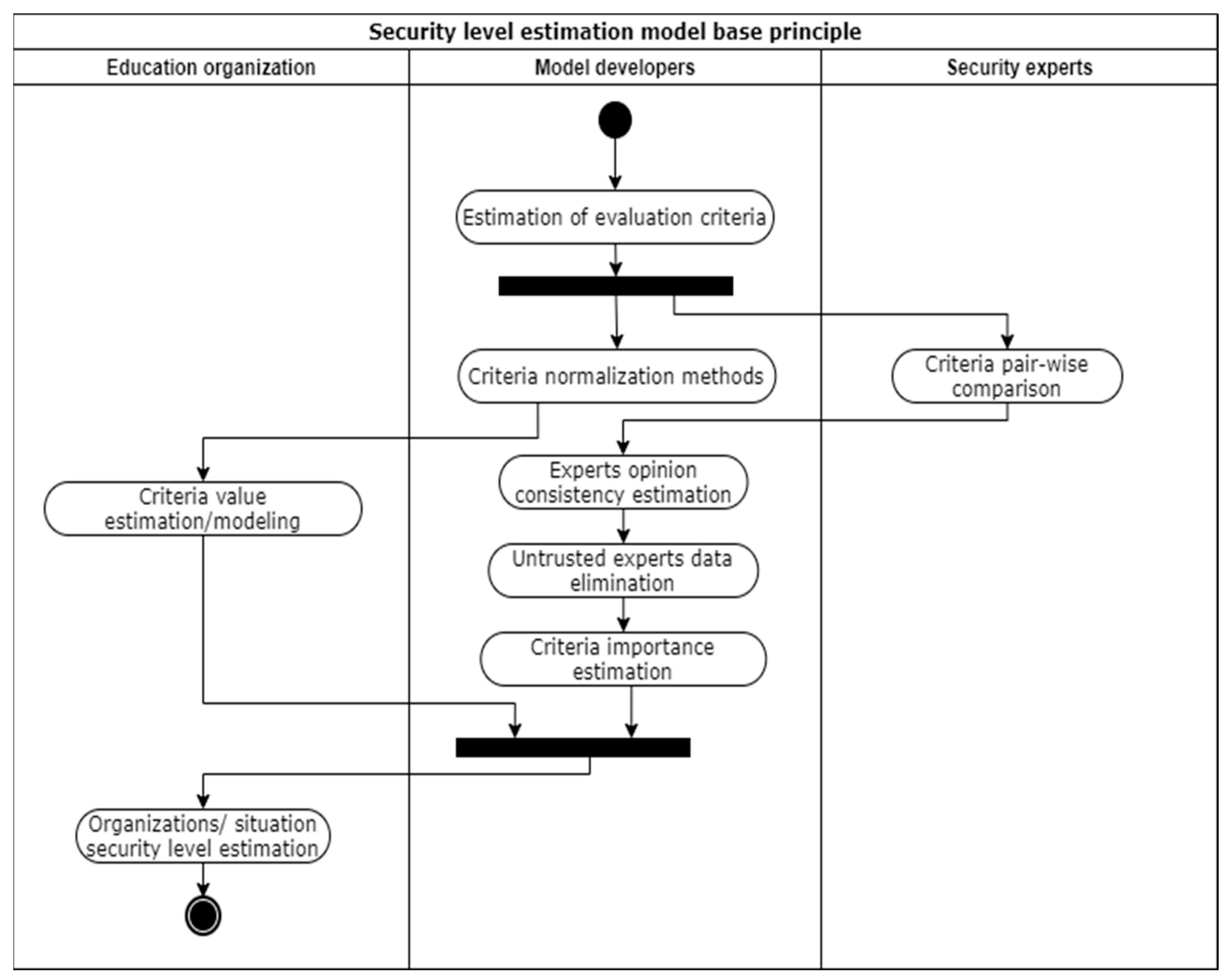
To simplify the evaluation of education organization security level, a quantitative model would allow the possibility of modeling different situations and comparing them, analyzing the impact of some security influencing factors. At the same time, the model application would be more accessible in case of automated or at least no specific security knowledge requiring data gathering about the organization. Considering that fully automated solutions cannot provide data on the organization’s security policies and processes, a manual data presentation about the organization is selected. By adopting the model to use discrete input values, which evaluation does not require specific security knowledge, even small organizations, which has no security specialists in it will be able to model organizations security level situations.
The security experts do not analyze the organization’s data, they only define the importance of each criterion. Therefore, the education organization might provide the criteria values, describing the organization’s current or modeled situation, without the use of security experts, as the criteria values are discrete and require no security level interpretation. By using criteria importance coefficients (estimated by security experts opinion), education organization data (provided by the organization), and criteria normalization methods (defined by model developers), the organization’s security level is calculated.
3.1. Design of Education Organization Security Level Estimation Criteria Set
The four P’s of security [
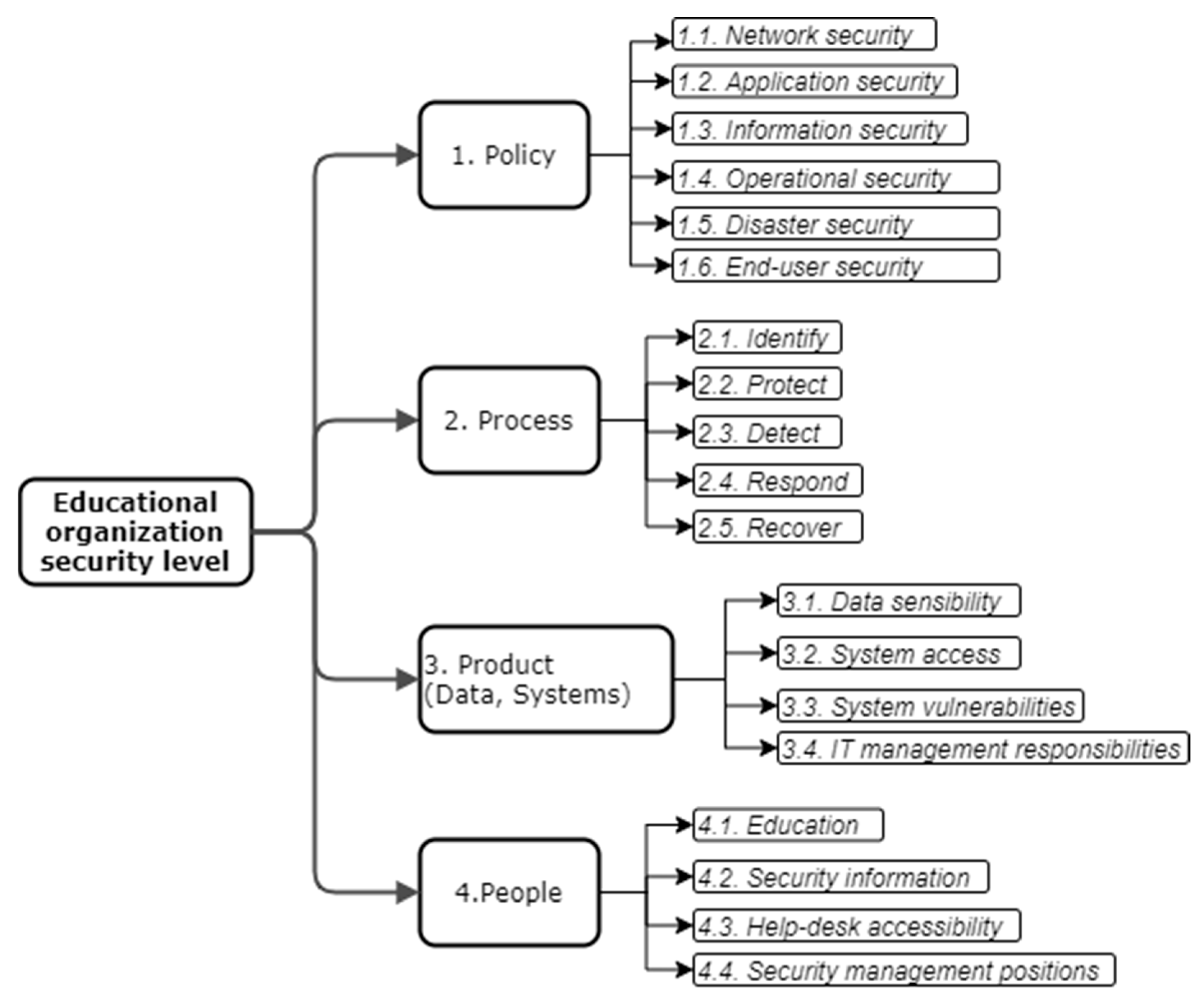
48] define the policies, processes, people, and products as base pillars to build a comprehensive security strategy. The same four elements are needed for education organizations to assure their security level. Therefore, (1) security policies, (2) security processes, (3) people security awareness, and (4) processed data or/and used systems are the main four criteria for security level estimation (see
Figure 3).
These four criteria are compound, and it would be difficult to evaluate its discrete values without the usage of security experts or automated tools. Therefore, the four criteria are divided into smaller ones leading to the usage of the AHP [
49]. Based on the AHP, each criterion should be divided into smaller ones, while the criteria will be evaluable or undividable further.
Based on Kaspersky [
50], cybersecurity consists of several categories: network security, application security, information security, operational security, disaster recovery, end-user education. Based on these categories we define the security policy as a combination of policies of each of these categories: (1.1) network security policy, (1.2) application security policy, (1.3) information security policy, (1.4) operational security policy, (1.5) disaster recovery policy, (1.6) stakeholder security training policy. The education organization should have all these policies and it is important to achieve the highest maturity level possible. Stating security policies do not give the desired effect if it is not repeated, clearly defined, managed, and optimized for the specific organization. As the requirements for education organization requirements might vary, it is too difficult to state what exactly should be reflected in the security policies; therefore, the model uses a security policy maturity level as value for each of these criteria.
The same idea of maturity level applies to security processes—it is important to optimize security processes to increase the security level. However, security processes might present different stages of security management; therefore, the criteria security processes are divided into more specific ones. The sub-criteria are defined based on five security functions, presented by the NIST [
51]: (2.1) identify, (2.2) protect, (2.3) detect, (2.4) respond, (2.5) recover.
The latest trends confirm the weakest link in enterprise security is humans [
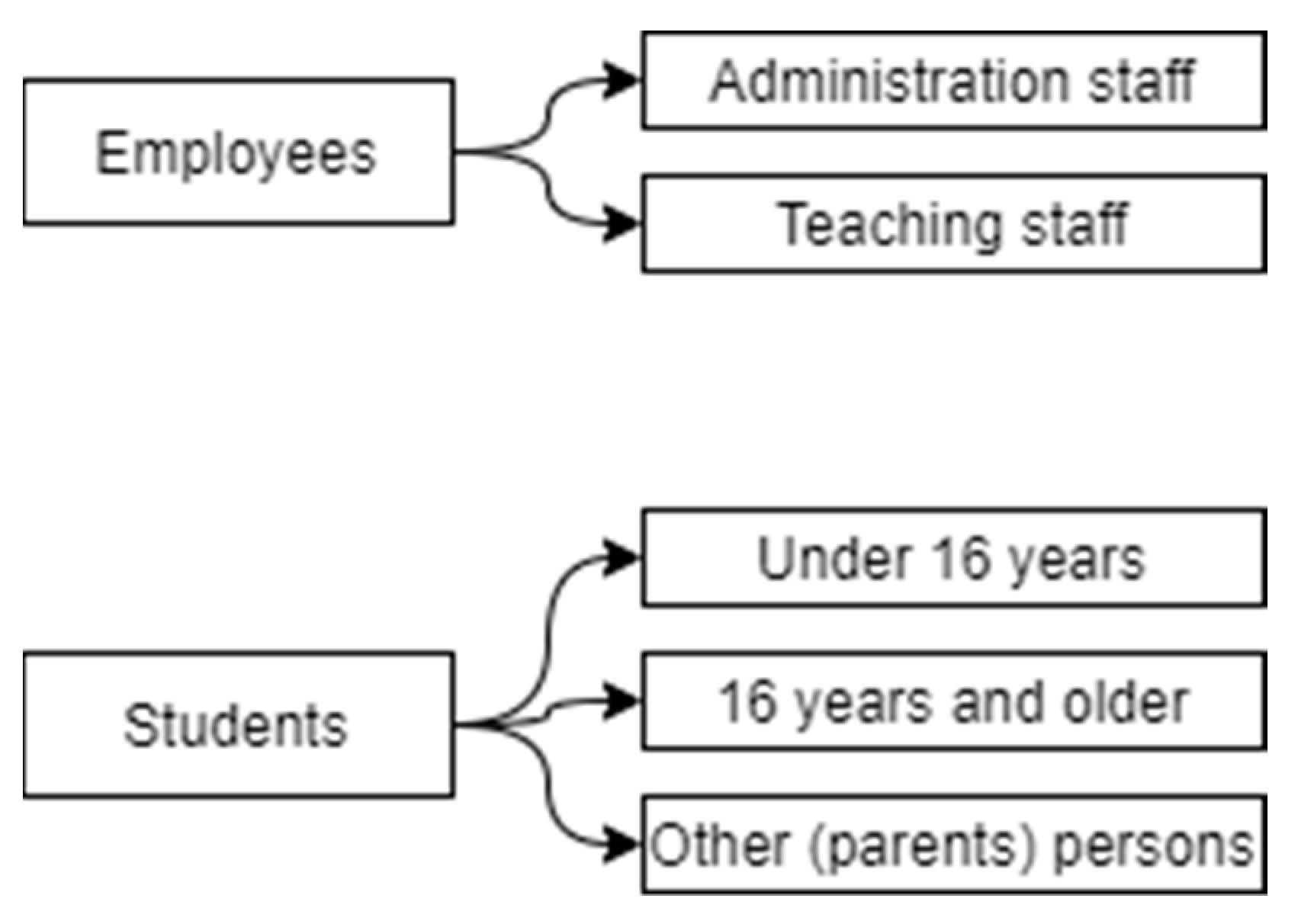
52]. Because of this trend, it is not enough to have a stakeholder security training policy; therefore, the model should include data on how qualified in the security area are the stakeholders. Therefore, the criteria people security awareness is divided into four sub-criteria: (3.1) existence of positions, responsible for security in the organization, (3.2) existence of systemic security training, (3.3) existence of security-related information sharing, (3.4) existence of help-desk service, for security incident or problem reporting. The 3.1 criteria are not divided into smaller ones, while the rest three criteria are divided into subcategories, representing two different stakeholders groups: employees and students. These groups have even deeper categories, where employees are divided into (a) administration and (b) teaching staff (see
Figure 4). While students are divided taking into account the General Data Protection Regulation (GDPR) [
53], where people under 16 years old are assigned to more sensitive groups. Therefore, we have three sub-categories for students: (c) students under 16 years, (d) 16 years and older students, (e) student-related persons (parents, trustees, etc.). Therefore, for these five categories criteria to state whether security training is executed at least once a year, whether this group at least once a year obtains security-related information (statistics, threads, tendencies, etc.), and whether the group can report a security issue or incident to the help-desk.
Processed data or/and used systems are the most technical top-level criteria. To reflect the data and system security, four sub-criteria are used: (4.1) data sensibility, (4.2) system access, (4.3) system vulnerabilities, (4.4) information technology management responsibility.
Data sensibility presents what kind of sensitive data are stored in the organization and its systems. There are the same five user groups (a–e) to present students’ and employee’s data (see
Figure 4). As well, there is another category—organization data, which is divided into: (f) organization financial data, (g) organization internal documents, (h) other organization data. For all these (a–h) categories, the education organization should state what the data sensibility is. For sensibility evaluation, three categories are used, estimated by the GDPR: no data are stored, stored data are insensitive (no secret or personal information or it is anonymized and untraceable), sensitive or personal, private data are stored (data related to persons private data, health records, private organizations data, etc.). If at least one person, file, or system is more sensitive, the whole group should be treated at this sensibility level.
System access defines how difficult it would be to access it for the attacker. The evaluation should state whether the system is not used at all; whether it is accessible in the local network only, whether the system is globally accessible. Naturally, the access level depends on system purpose. Therefore, the values should be presented for different type/purpose systems: (4.2.1) representative website, (4.2.2) systems, used in a learning process (those are divided into e-learning systems and communication systems), (4.2.3) employee used systems (those are divided into information technology management systems and systems, used for organization process management). As multiple systems might exist in the same category, the value is assigned based on the highest availability level. For instance, if at least one e-learning system is publicly available and all the rest are available in the local network, the value “public” will be assigned to all the groups.
For security level estimation, a whole set of education organization used systems have to be overviewed to present system accessibility values. At the same time, the security vulnerability (weakness, flaw, or error, which can be exploited by third parties) of all those systems should be evaluated. The number and score of existing security vulnerabilities define the possible attack vectors, difficulty to exploit it. The model takes into account publicly and locally available systems as groups, not each system individually. Therefore, for those two groups of systems, it is important to present the score of the vulnerability and number of vulnerabilities in the group. The score reflects how critical the vulnerability is, while the number of vulnerabilities defines the variety of different attack vectors against the system. Consequently, the discrete values of these criteria, the maximum score of CVSS v3.0 value [
54], should be estimated for each system (corresponding to the publicly or locally accessible group) vulnerabilities as well as the total number of vulnerabilities in this group.
As system vulnerability criteria do not consider hardware-related vulnerabilities, the information technology management responsibility criteria represent this area. Depending on the size of the organization and information technology management model, the organization might be an owner of the information technology devices/systems, controller, or processor [
53]. Those three values should be used to reflect the management responsibility. However, it should be assigned to all of these categories rather than one value for all information technology landscapes: (4.4.1) network, (4.4.2) computer devices, (4.4.3) employees used systems, (4.4.4) students used systems, (4.4.5) other systems.
The proposed model is not specific to educational organization type as it includes all criteria, which are important to any type of educational organization. An exception might be very specific educational organizations, which for example include additional information technology equipment and systems, highly related to security issues, crowd opinion managed organizations, etc. Meanwhile, in the model, the different education organization types will be included by criteria values. For example, some types of educational organizations will not have some type of users, systems, etc. The criteria value absence will indicate it is not relevant, does not exist in the organization, and the organization security level changes adequately. The absence of some systems and user types will increase the security level, meanwhile, the absence of some security policies will decrease the security level, as the security management should be executed in any organization, despite its type.
All these criteria form a criteria tree, composed of four top-level criteria, up to four criteria levels for each criterion, in total 49 criteria for evaluation. The criteria set is presented in
Appendix A Table A1.
3.2. Criteria Value Normalization Methods
In multi-criteria decision making, all criteria values must be normalized. Therefore, methods to convert each criteria value to a numerical value in the range [0, 1] must be presented. For all policy and process sub-criteria, a maturity level is used as a value. The maturity level allows estimation of how optimized the policy and processes are. Especially it is important when talking about modernization, development, pandemics permutations when a clear change management plan and risk society must be developed in the organization. Maturity level allows not going into very specific details of the organization; however, provides the main level or policy and process quality in the organization. It might have one of six values (five levels and one value to indicate there are no policies for this area). The normalized numeric values for each possible value are presented in
Table 1. There each value has assigned numeric value proportionally from 0 to 1.
All sub-criteria of criteria “people security awareness” use binary values—whether it is or not. Therefore, very straightforward normalization method is used (1)—value 1 is assigned if the value is true, and 0 is assigned if the value is false.
where
nv(
x) is normalized value for value
xi of criteria
i.
The widest variety of normalization methods is needed for criteria “processed data or/and used systems”. In most cases, values are categorized and must be converted into numeric values. The tables for criteria value transformation to normalized value are presented in
Table 2,
Table 3 and
Table 4. Each one is generated with the same method—all values are listed and proportional values from 0 to 1 are assigned to each of the possible criteria values.
System vulnerability estimation is based on analysis of existing vulnerabilities or used systems. The vulnerability score in NVD varies from 0.0 to 10.0; therefore, the normalized value should be calculated as the proportion between the maximum vulnerability score of used systems and 10 (2). Therefore, all used systems should be scanned for vulnerabilities and the maximum SVSS score should be found from the possible ones.
where
nv(
x) is the normalized value for vulnerability maximum score for group
x,
x(
i) is the
i-th system in group
x,
cvssi(j) is the
j-th common vulnerability scoring system v3.0 score for system
i.
The number of vulnerabilities has no precise range. Therefore, the normalized value for criteria, based on the number of vulnerabilities are calculated as the relative frequency of vulnerabilities between analyzed alternatives (3). To obtain the normalized value
nv the number of vulnerabilities for each system must be presented for all alternatives. Then the number of vulnerabilities in the current alternative is divided by the maximum number of vulnerabilities in all analyzed alternatives.
where
nv(
x,
a) is the normalized value for vulnerability number for alternative
a and group
x,
vci(x, a) is a count of vulnerabilities for system
i(
x,
a), analyzed in group
x for alternative
a,
vci(x, j) is a count of vulnerabilities for system
i(
x,
j), analyzed in group
x for the
j-th alternative of all analyzed alternatives.
This normalization method impacts the recalculation of all normalized vulnerability number values when the additional alternative is added or some of them are eliminated. At the same time, it limits the method’s possibility to present a global rather than relative security level, as the question of maximum vulnerability number is open all the time.
3.3. Criteria Importance Estimation
While possible criteria values are estimated and normalized based on some theoretical or logical background, the estimation of criteria importance has an empirical background. To estimate the criteria importance four security management experts were involved (E1, E2, E3, and E4). All four experts defended their Ph.D. thesis in the field of information security management within the last 5 years. Currently, they all work in an industry, in positions, related to security and/or its risk management.
Based on T. L. Saaty and M. S. Özdemir [
55], one judge/expert is enough when the AHP method is used. However, to estimate the experts’ opinion similarity to a wider range of security risk experts, all known security risk management experts were incorporated into this process. Because of time constraints and expert needed competence requirements, only four experts were selected. The requirements were to have a Ph.D. degree in a topic related to security management and to work in a security management-related position at the moment. Therefore, Ph.D. defense history in Lithuania during the last 10 years was analyzed. Suitable candidates were contacted and invited to participate in the research. Data on experts’ work experience were gathered as well to identify possible relations between the experts. Two experts appeared to be working in the same company, however, they are responsible for different responsibilities and there is no subordination between them (they work in different departments).
One of the experts provided two rather than one opinion on criteria importance. The need for two different sets was explained by the fact that higher education and secondary school education institutions have different experiences, therefore, different aspects of security areas are important. This position is questionable; however, two different sets of criteria importance (noted E1a and E1b, where E1a labels higher education situation and E1b—secondary school case) were added to analyze in further steps.
All experts filled the provided survey form, where each criterion was compared pair-wise. Based on the calculation, the criteria importance coefficients were calculated. Close to the calculated criteria importance coefficients (see
Table A1 in
Appendix A), the consistency ratio (CR) values were calculated to evaluate the experts’ opinion consistency within the pair-wise comparison (see
Table 5). The CR value lower than 0.10 is usually assumed as consistent. While higher values indicate some mismatch in experts pair-wise comparison.
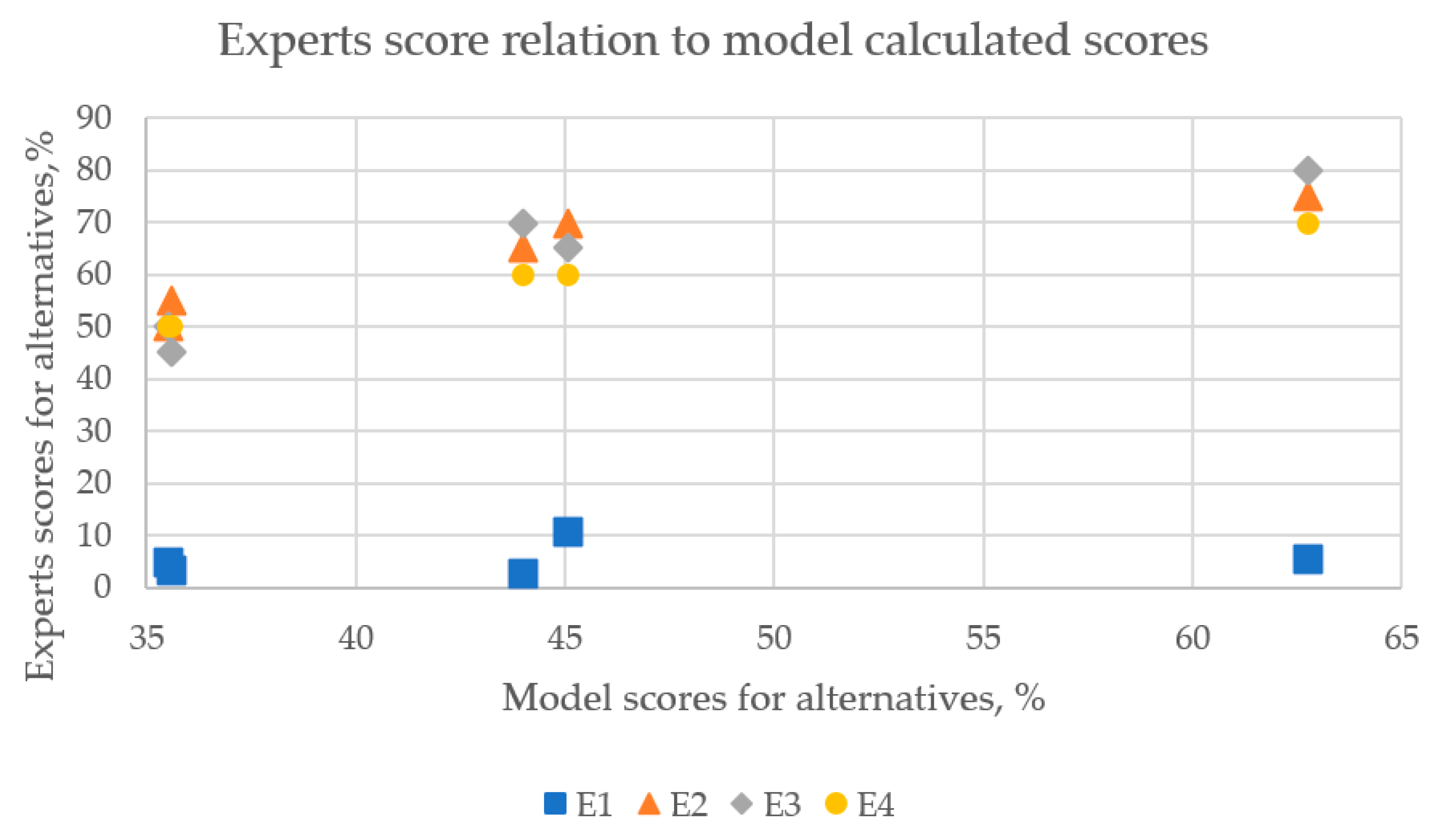
The analysis of CR values indicated the expert E1 has a very inconsistent opinion, especially in the case of higher education institutions (average value is 0.15, while standard deviation is 0.35). Meanwhile, the rest three experts’ CR values with 95% confidentiality do not reach a CR value greater than 0.11 (average CR value plus 2 standard deviation values).
Despite the fact that the expert’s E1 opinions are not as consistent as the opinions of other experts, the correlation between criteria coefficients is high between each pair of experts (see
Table 6). There is some difference between expert E1 and other experts, while between all experts the correlation is significant (the lowest
p value is equal to 0.000455).
The correlation between E2 and E4 is especially high; however, it can be influenced by the fact those two experts work in the same company while all other experts work in different companies. Therefore, some collaboration or transparent experience in the company might influence the high correlation of these two opinions.
To aggregate the opinion of participated security management experts opinion to further model the average criteria importance coefficient of experts E2, E3 and E4 will be used.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
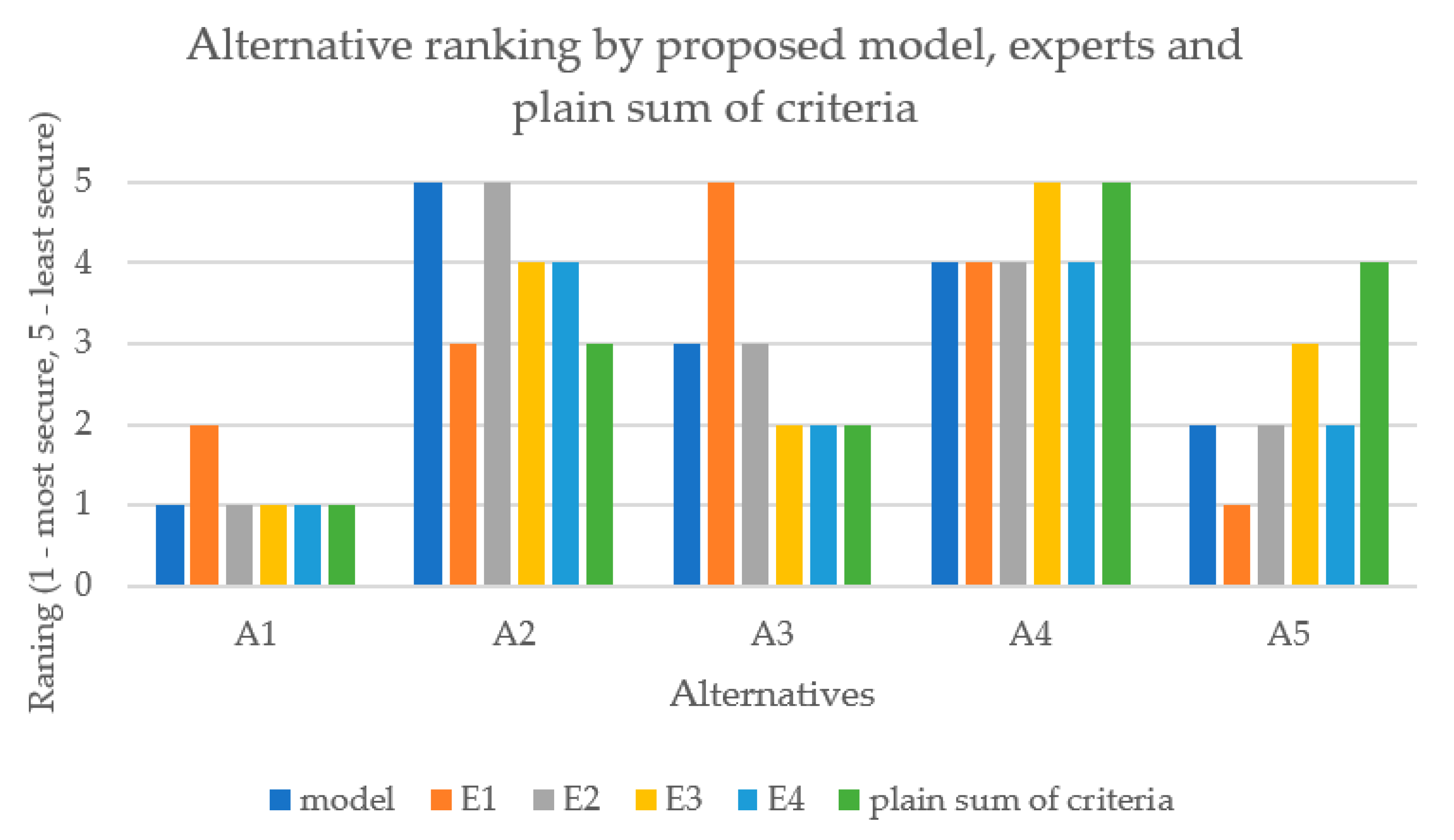{kind=link}





