1. Introduction
As realistic media are widespread in various image processing areas, image compression is one of the key technologies to enable real-time applications with limited network bandwidth. While image compression techniques, such as joint photographic experts group (JPEG) [
1], web picture [
2], and high-efficiency video coding main still picture [
3], can achieve significant compression performances for efficient image transmission and storage [
4], they lead to undesired compression artifacts due to lossy coding because of quantization. These artifacts generally affect the performance of image restoration methods in terms of super-resolution [
5,
6,
7,
8,
9,
10], contrast enhancement [
11,
12,
13,
14], and edge detection [
15,
16,
17].
Reduction methods for compression artifacts were initially studied by developing a specific filter inside the compression process [
18]. Although these approaches can efficiently remove ringing artifacts [
19], the improvement in image regions is limited at high frequencies. Examples of such approaches include deblocking-oriented approaches [
20,
21], wavelet transforms [
22,
23], and shape-adaptive discrete cosine transforms [
24]. Recently, artifacts reduction (AR) networks using deep learning have been developed with various deep neural networks (DNNs), such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM), and generative adversarial networks (GANs). Because CNN [
25] can efficiently extract feature maps with deep and cascading structures, CNN-based artifact reduction (AR) methods can achieve visual enhancement in terms of peak signal-to-noise ratio (PSNR) [
26], PSNR including blocking effects (PSNR-B) [
27,
28], and structural similarity index measures (SSIM) [
29].
Despite the developments of AR, most CNN-based approaches tend to design the heavy network architecture by increasing the number of network parameters and operations. Because it is difficult to deploy such heavy models on hand-held devices operated on low complexity environments, it is necessary to design the lightweight AR networks. In this paper, we propose a lightweight CNN-based artifacts reduction model to reduce the memory capacity as well as network parameters. The main works of this study are summarized as follows:
- ▪
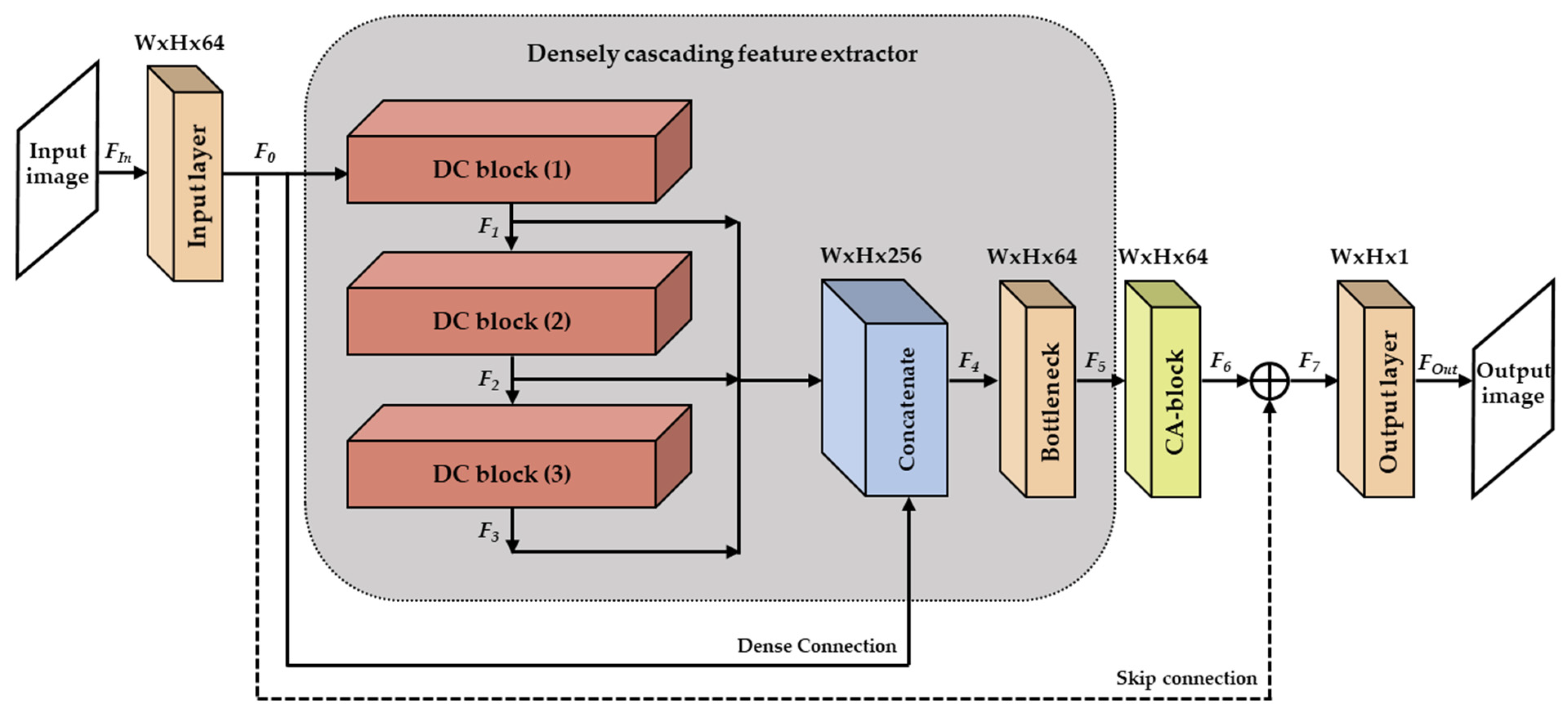
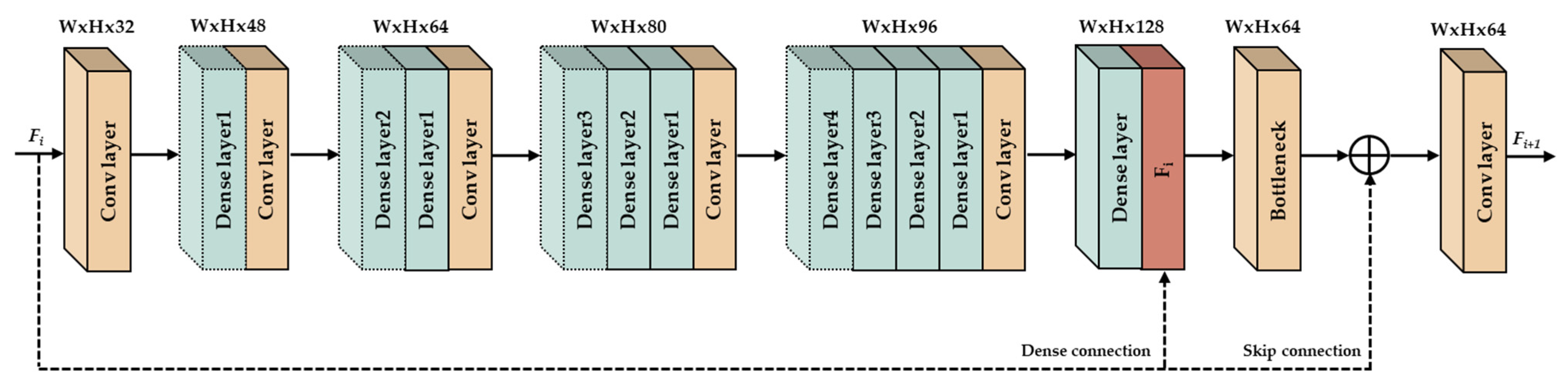
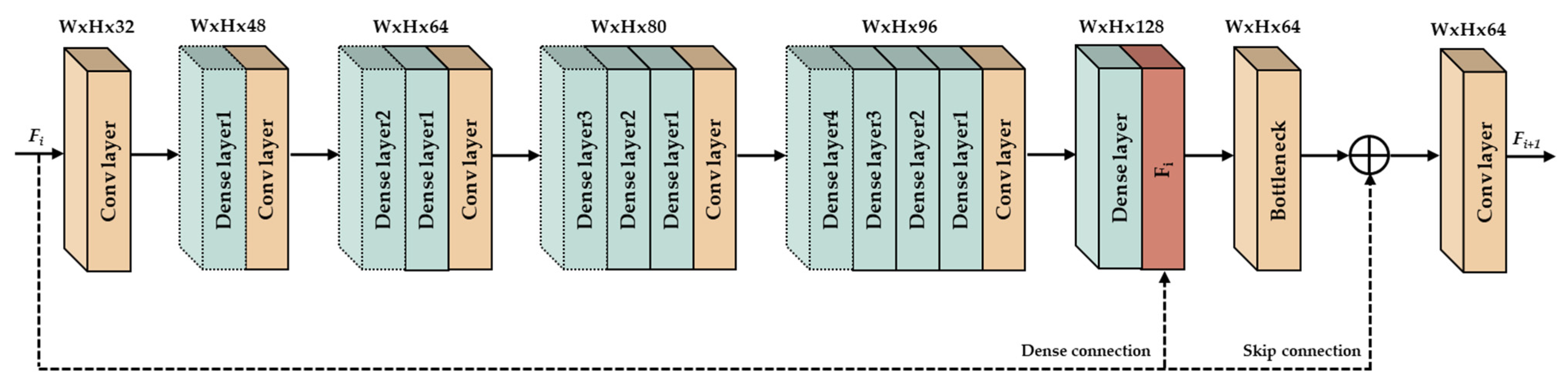
To reduce the coding artifacts of the compressed images, we propose a CNN based densely cascading image restoration network (DCRN) with two essential parts, densely cascading feature extractor and channel attention block.
- ▪
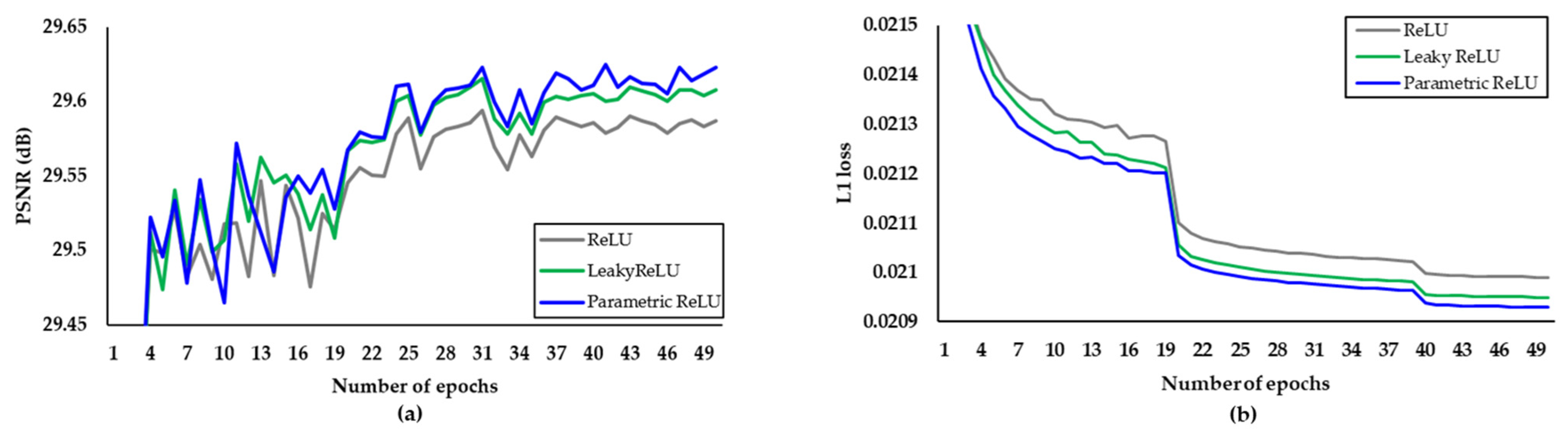
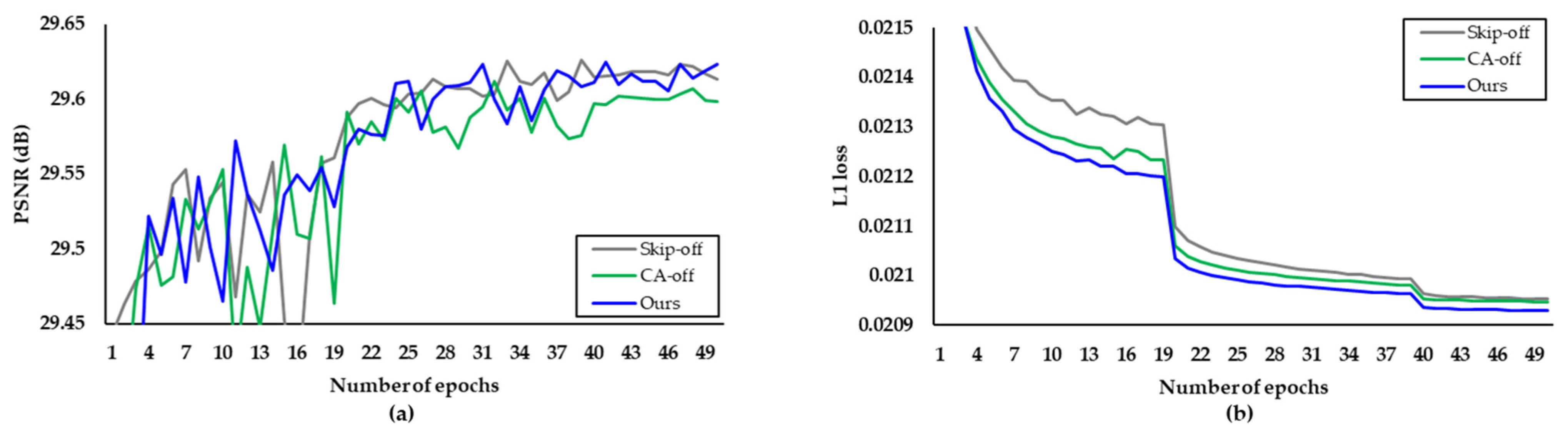
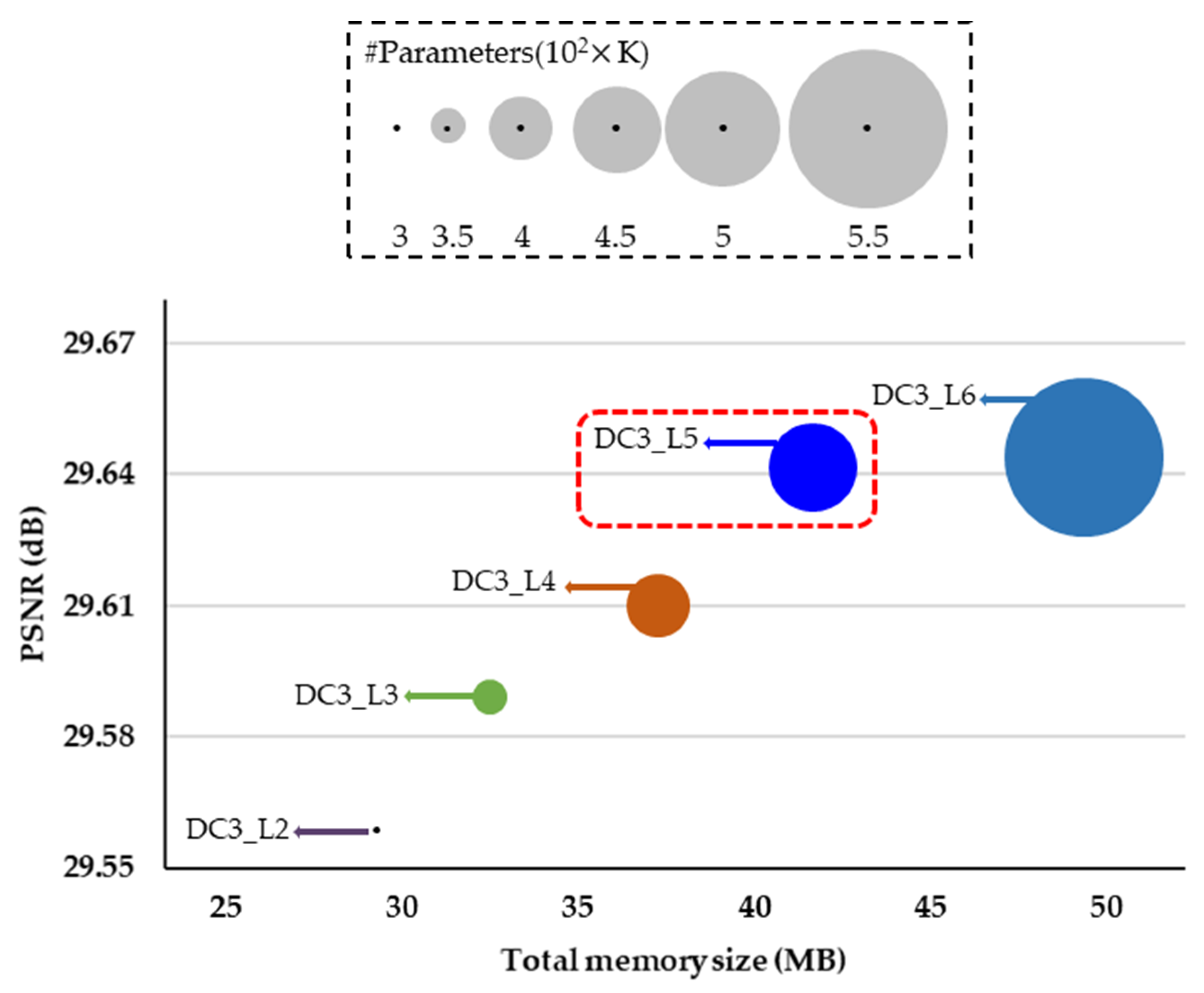
Through a various ablation study, the proposed network is designed to guarantee the optimal trade-off between the PSNR and the network complexity.
- ▪
Compared to the previous method, the proposed network is designed to obtain comparable AR performance while utilizing the small number of network parameters and memory size. In addition, it can provide the fastest inference speed, except for initial AR network [
30].
- ▪
Compared to the latest methods to show the highest AR performances (PSNR, SSIM, and PSNR-B), the proposed method can reduce the number of parameters and total memory size maximum by 2% and 5%, respectively.
The remainder of this paper is organized as follows: in
Section 2, we review previous studies related to CNN-based artifact reduction methods. In
Section 3, we describe the proposed method. Finally, in
Section 4 and
Section 5, we present the experimental results and conclusions, respectively.
2. Related Works
Due to the advancements in deep learning technologies, research of low-level computer vision, such as super-resolution (SR) and image denoising, has been combined with a variety of CNN architectures to provide higher image restoration than that of conventional image processing. Dong et al. proposed an artifact reduction convolutional neural network (ARCNN) [
30], which consists of four convolutional layers and trains an end-to-end mapping from a compressed image to a reconstructed image. After the advent of ARCNN, Mao et al. [
31] proposed a residual encoder–decoder network, which conducts encoding and decoding processes with symmetric skip connections in stacking convolutional and deconvolutional layers. Chen et al. [
32] proposed a trainable nonlinear reaction diffusion, which is simultaneously learned from training data through a loss-based approach with all parameters, including filters and influence functions. Zhang et al. [
33] proposed a denoising convolutional neural network (DnCNN), which is composed of a combination of 17 convolutional layers with a rectified linear unit (ReLU) [
34] activation function and batch normalization for removing white Gaussian noise. Cavigelli et al. [
35] proposed a deep CNN for image compression artifact suppression, which consists of 12 convolutional layers with hierarchical skip connections and a multi-scale loss function.
Guo et al. [
36] proposed a one-to-many network, which is composed of many stacked residual units, with each branch containing five residual units and the aggregation subnetwork comprising 10 residual units. Each residual unit uses batch normalization, ReLU activation function, and convolutional layer twice. The architecture of residual units is found to improve the recovery quality. Tau et al. [
37] proposed a very deep persistent memory network with a densely recursive residual architecture-based memory block that adaptively learns the different weights of various memories. Dai et al. [
38] proposed a variable-filter-size residual-learning CNN, which contains six convolutional layers and concatenates variable-filter-size convolutional layers. Zhang et al. [
39] proposed a dual-domain multi-scale CNN with an auto-encoder, dilated convolution, and discrete cosine transform (DCT) unit. Liu et al. [
40] designed a multi-level wavelet CNN that builds a u-net architecture with a four-layer fully convolutional network (FCN) without pooling and takes all sub-images as inputs. Each layer of a CNN block is composed of 3 × 3 kernel filters, batch normalization, and ReLU. A dual-pixel-wavelet domain deep CNN-based soft decoding network for JPEG-compressed images [
41] is composed of two parallel branches, each serving as the pixel domain soft decoding branch and wavelet domain soft decoding branch. Fu et al. [
42] proposed a deep convolutional sparse coding (DCSC) network that has dilated convolutions to extract multi-scale features with the same filter for three different scales. The implicit dual-domain convolutional network (IDCN) for robust color image compression AR [
43] consists of a feature encoder, correction baseline and feature decoder. Zhang et al. [
44] proposed a residual dense network (RDN), which consists of 16 residual dense blocks, and each dense block contains eight dense layers with local residual learning.
Although most of the aforementioned methods demonstrate better AR performance, they tend to possess more complicated network structures on account of the large number of network parameters needed and heavy memory consumption.
Table 1 lists the properties of the various AR networks and compares their advantages and disadvantages.
For the network component, a residual network [
45] was designed for shortcut connections to simplify identity mapping, and outputs were added to the outputs of the stacked layers. A densely connected convolutional network [
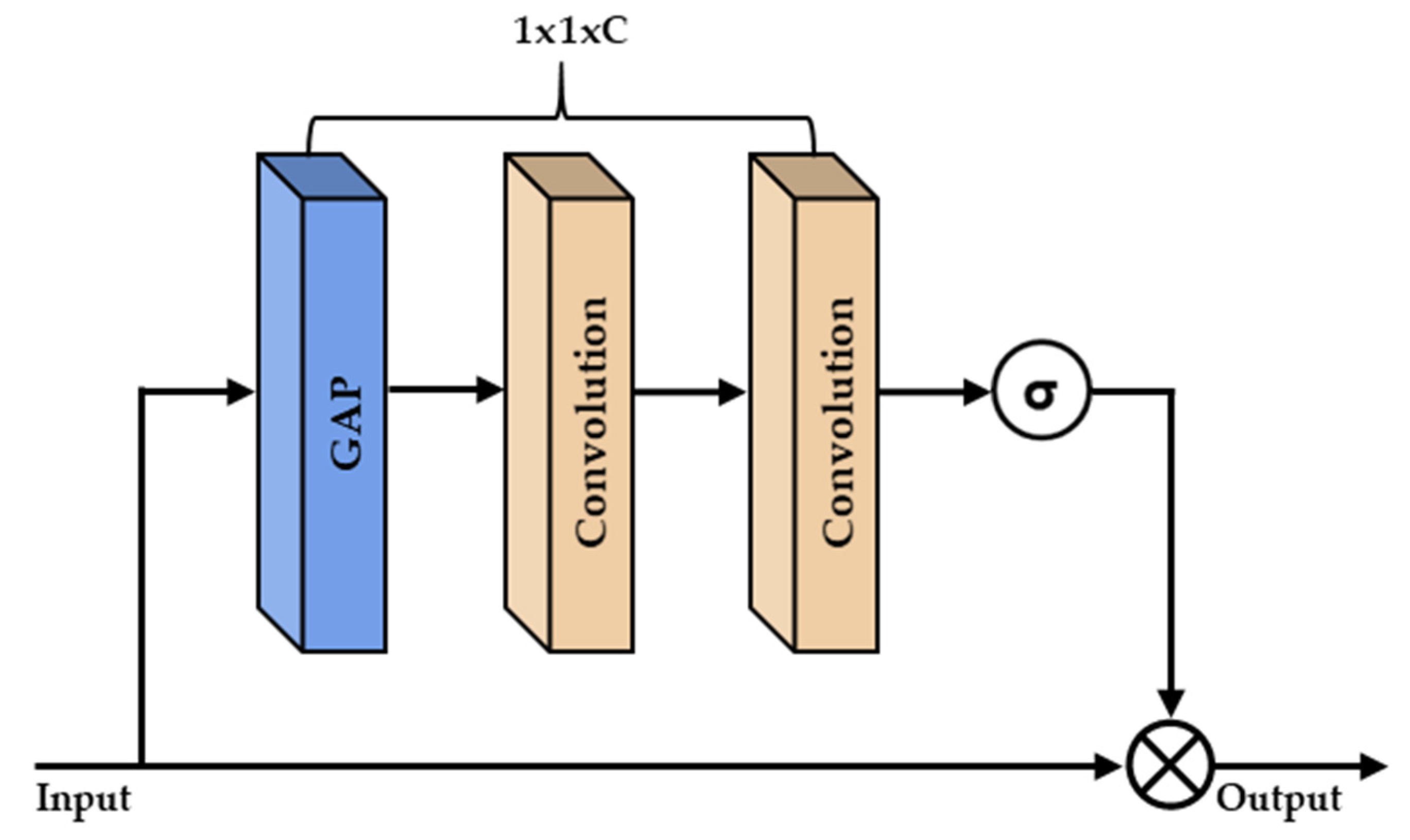
46] directly connects all layers with one another based on equivalent feature map sizes. The squeeze-and-excitation (SE) network [
47] is composed of global average pooling and a 1 × 1 convolutional layer. These networks use the weights of previous feature maps, and such weights are applied to previous feature maps to generate the output of the SE block, which can be provided to subsequent layers of the network. In this study, we propose an AR network to combine with those networks [
45,
46,
47] for better image restoration performance than the previous methods.
4. Experimental Results
We used 800 images from DIV2K [
52] as the training images. After they were converted into YUV color format, only Y components were encoded and decoded by the JPEG codec under three image quality factors (10, 20, and 30). Through this process, we collected 1,364,992 patches of a 40 × 40 size from the original and reconstructed images. To evaluate the proposed method, we used Classic5 [
24] (five images) and LIVE1 [
53] (29 images) as the test datasets and Classic5 as the validation dataset.
All experiments were performed on an Intel Xeon Gold 5120 (14 cores @ 2.20 GHz) with 177 GB RAM and two NVIDIA Tesla V100 GPUs under the experimental environment described in
Table 5.
In terms of the performance of image restoration, we compared the proposed DCRN with JPEG, ARCNN [
30], DnCNN [
33], DCSC [
42], IDCN [
43] and RDN [
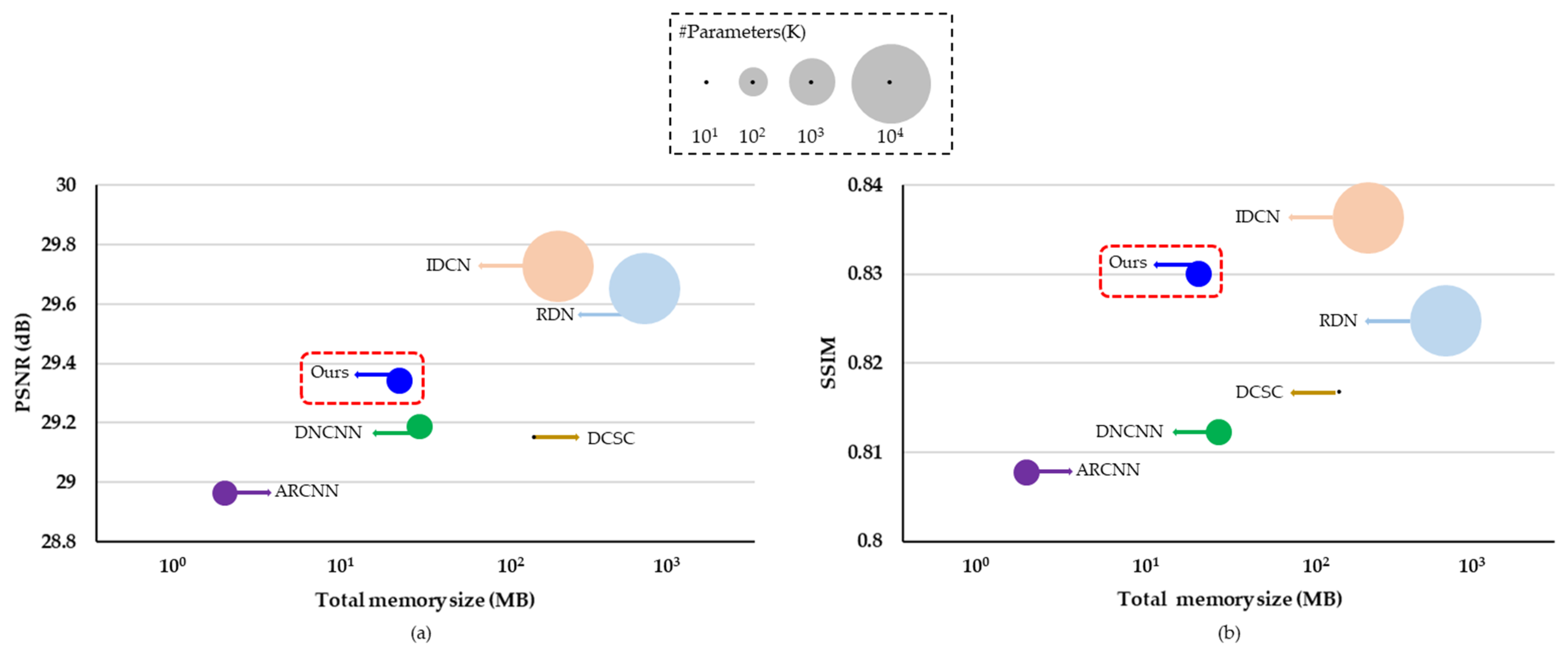
44]. In terms of the AR performance (i.e., PSNR and SSIM), the number of parameters and total memory size, the performance comparisons between the proposed and existing methods are depicted in
Figure 8.
Table 6,
Table 7 and
Table 8 enumerate the results of PSNR, SSIM, and PSNR-B, respectively, for each of the methods studied. As per the results in
Table 7, it is evident that the proposed method is superior to the others in terms of SSIM. However, RDN [
44] demonstrate higher PSNR values. While DCRN shows a better PSNR-B compared to that of DnCNN, it has comparable performance with DCSC in terms of PSNR-B using the Classic5 dataset. While the RDN was likely to improve AR performance by increasing the number of network parameters, the proposed method was focused to design the lightweight network with the small number of network parameters.
Table 9 classifies the network complexity in terms of the number of network parameters and total memory size (MB). The proposed DCRN reduced the number of parameters to as low as 72%, 5% and 2% of those needed in DnCNN, IDCN and RDN, respectively. In addition, the total memory size was as low as 91%, 41%, 17% and 5% of that required for DnCNN, DCSC, IDCN and RDN, respectively. Since the same network parameters were repeated 40 times in DCSC, the total memory size was large even though the number of network parameters was smaller than that of the other methods. As shown in
Figure 9, the inference speed of the proposed method is greater than that of all networks, except for ARCNN. Although the proposed method is slower than ARCNN, it is clearly better than ARCNN in terms of PSNR, SSIM, and PSNR-B, as per the results in
Table 6,
Table 7 and
Table 8.
Figure 10 shows examples of the visual results of DCRN and the other methods on the test datasets. Based on the results, we were able to confirm that DCRN can recover more accurate textures than other methods.
5. Conclusions
Image compression leads to undesired compression artifacts due to the lossy coding that occurs through quantization. These artifacts generally degrade the performance of image restoration techniques, such as super-resolution and object detection. In this study, we propose a DCRN, which consists of the input layer, a densely cascading feature extractor, a channel attention block, and the output layer. The DCRN aims to recover compression artifacts. To optimize the proposed network architecture, we extracted 800 training images from the DIV2K dataset and investigated the trade-off between the network complexity and quality enhancement achieved. Experimental results showed that the proposed DCRN can lead to the best SSIM for compressed JPEG images compared to that of other existing methods, except for IDCN. In terms of network complexity, the proposed DCRN reduced the number of parameters by as low as 72%, 5% and 2% compared to DnCNN, IDCN and RDN, respectively. In addition, the total memory size was as low as 91%, 41%, 17% and 5% of that required for DnCNN, DCSC, IDCN and RDN, respectively. Even though the proposed method was slower than ARCNN, it’s PSNR, SSIM, and PSNR-B are clearly better than those of ARCNN.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}