
Guided Spatial Transformers for Facial Expression Recognition

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
- We propose a new module, that we call “Mask Generator”, to attach to the Spatial Transformer to improve its performance. This module will generate several masks that are fed into the STN together with the original images. These masks, which are directly crafted from the estimated facial landmarks or assimilated as the resulting visual saliency maps from the original image, are practical to enhance the attention on relevant local regions.
- We also solve the Facial Emotion Recognition task on two popular datasets, achieving statistically significant results with our strategies, which improves the conventional STNs. The results obtained in this task expose the efficacy of this idea and open the possibility of applying the same procedures to other computer vision tasks where the ground-truth of the interest regions is not available.
2. Related Work
2.1. Spatial Transformer Networks
2.2. Emotion Recognition
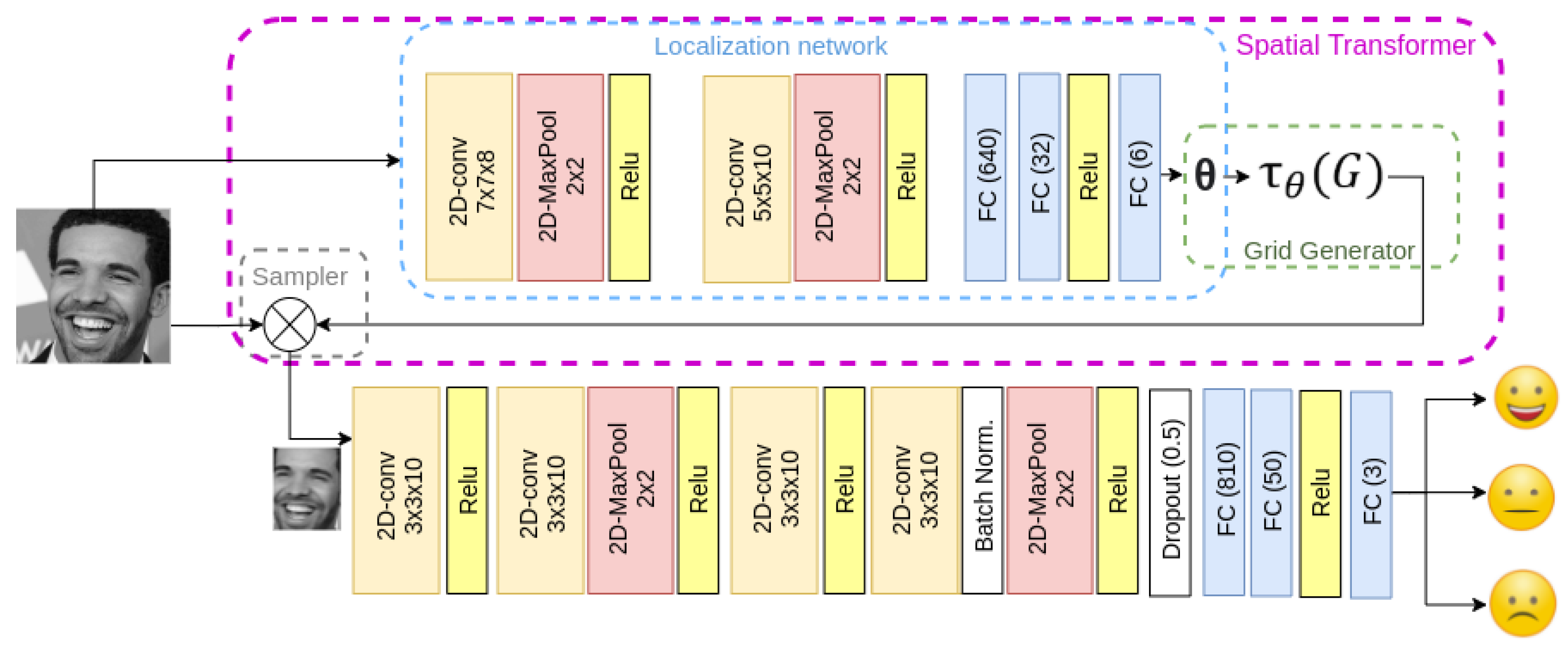
3. Methodology
3.1. Masks Generator
3.1.1. Landmark-Based Binary Masks
3.1.2. Landmarks-Based Soft Masks
3.1.3. Landmark-Based Dilated Binary Masks
3.1.4. Visual Saliency-Based Masks
3.1.5. Landmark-Based Facial Patches
3.1.6. Landmark-Based Image Weighing
3.1.7. Common Mask Processing
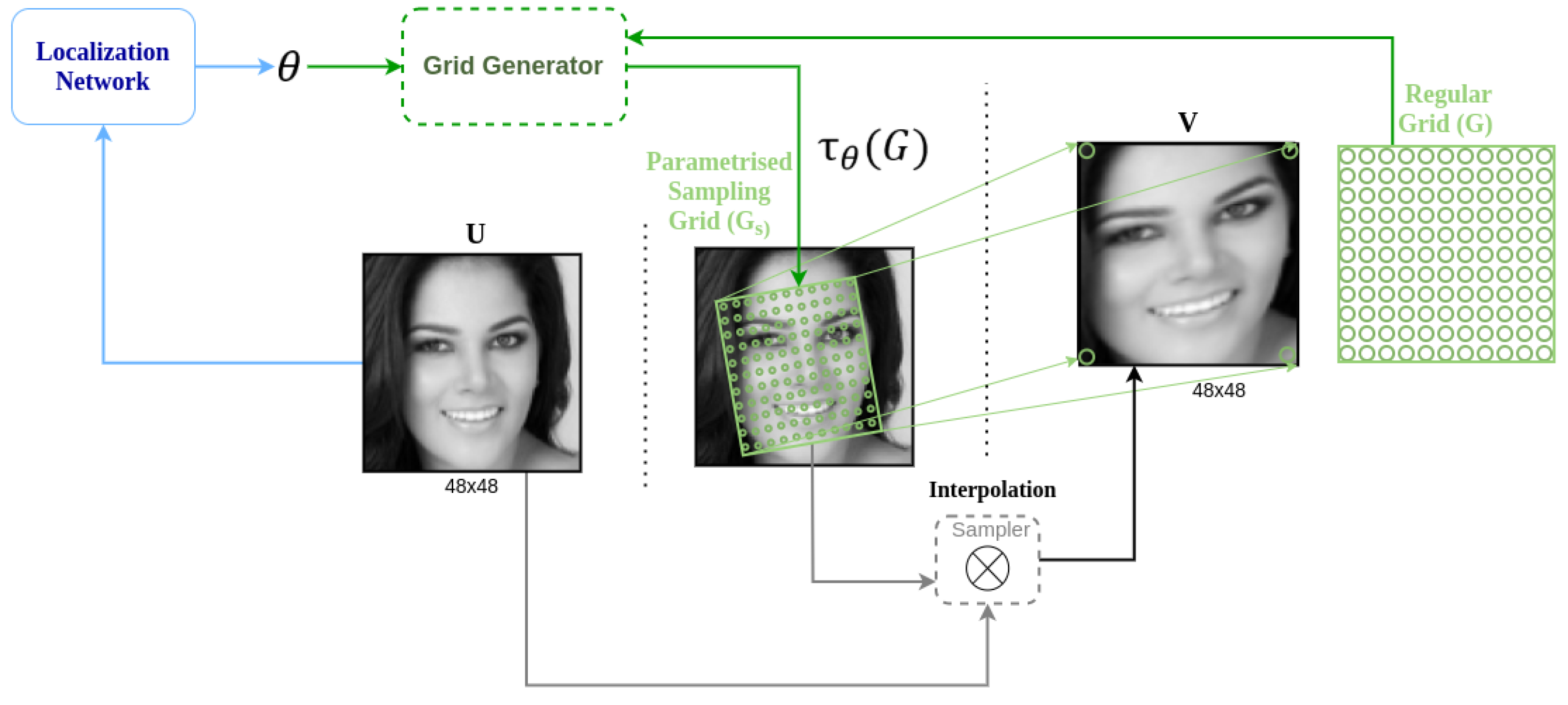
3.2. Spatial Transformer Network
4. Experiments
4.1. Experiments Description
4.1.1. Simple CNN
4.1.2. Baseline STN
4.1.3. STN with Mask Generator at the Localization Network
4.1.4. STN with Mask Generator at the Localization Network and Sampler
- Is it possible to solve the Facial Emotion Recognition task only from the most relevant patches of the original image?
- Would the classification network be able to extract information from an image with embedded knowledge?
4.2. Datasets
- AffectNet: AffectNet is one of the largest datasets available for visual emotion recognition in the wild. It contains approximately 450,000 images divided into 11 non-equally distributed categories: ‘Neutral’, ‘Happy’, ‘Sad’, ‘Surprise’, ‘Fear’, ‘Disgust’, ‘Anger’, ‘Contempt’, ‘None’, ‘Uncertain’, and ‘Non-Face’. Besides the emotional label, each image also has its arousal and valence annotated in the range from −1 to 1. The only categories that do not include these annotations are ‘Uncertain’ and ‘Non-Face’. To adapt the annotations to our task and facilitate compatibility between datasets, we divide the valence axis into 3 regions. The first region, which goes from valence 1 to 0.2, represents positive emotions. The second region ranges from 0.2 to −0.2, and it is considered the region of neutral valence. The third group contains the images with valence lower than −0.2, which receives the negative valence label. In total, our new subset contains 325,239 images. In Figure 7, we can see the final distribution of images per class. As the plot shows, the subset is non-balanced, having more positive images than negative or neutral.
- FER-2013: The Facial Expression Recognition 2013 database contains 35,887 grayscale images with a resolution of 48 × 48 pixels. This dataset was collected using Google by requesting images associated with key emotional terms. The downloaded images were filtered for rejecting repeated samples and resized. Accordingly to the key term used in the query, each image was assigned to one of the following categories: angry, disgust, fear, happy, sad, surprise, and neutral.One of the major difficulties of this dataset is the different nature of the images as they can contain different poses, occlusions, blurring, and other artifacts, which makes the recognition a challenging task. Again, we need to distribute the images into the same 3 label levels to homogenize both datasets.Unlike what we did with AffectNet, in this dataset, we do not have the valence annotations. For this reason, and following the theories of J.Posner and J. Rusell [20], we assigned the positive valence to those images categorized as ’happy’, the neutral valence to the ’neutral’ images, and the rest of the samples to the negative valence set. Those images tagged as ’surprise’ were excluded from the groups since this emotion can represent positive or negative valences, depending on the situation. In total, the new subset contains 31,885 images over the original size of 35,887. In Figure 7, we can see the distribution of the labels.
4.3. Evaluation and Training Parameters
5. Results
5.1. Evaluation of Strategies on AffectNet
5.2. Transfer-Learning on FER-2013
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| STN | Spatial Transformer Network |
| CNN | Convolutional Neural Network |
| MTCNN | Multi-task Cascaded Convolutional Networks |
| FER-2013 | Facial Expression Recognition 2013 database |
| GAN | Generative Adversarial Networks |
| TL | Transfer Learning |
Appendix A. Complementary Material of the Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weights Initialization | Strategy | Accuracy ± 95% Confidence Interval |
|---|---|---|
| From scratch | ZeroR | 52.37 ± 0.55 |
| Baseline STN | 72.92 ± 0.48 | |
| STN with landmarks—binary masks v1 | 74.20 ± 0.48 | |
| STN with landmarks—binary masks v2 | 69.99 ± 0.50 | |
| STN with landmarks—binary masks v3 | 74.38 ± 0.48 | |
| STN with landmarks—soft masks | 73.64 ± 0.48 | |
| STN with saliency masks | 74.93 ± 0.48 | |
| Transfer-Learning using AffectNet weights | Baseline STN | 74.52 ± 0.48 |
| STN with landmarks—binary masks v1 | 74.69 ± 0.48 | |
| STN with landmarks—binary masks v2 | 74.26 ± 0.48 | |
| STN with landmarks—binary masks v3 | 75.18 ± 0.48 | |
| STN with landmarks—soft masks | 74.90 ± 0.48 | |
| STN with saliency masks | 76.01 ± 0.47 |
Appendix B. Architecture Layers and Dimensions
| Branches of the Model | Input Layer | Output Size | Filter Size/Stride | Depth |
|---|---|---|---|---|
| Input | Input Image | 48 × 48 × 1 | - | - |
| Localization Network | Convolution-2D | 42 × 42 × 8 | 7 × 7/1 | 8 |
| MaxPooling-2D | 21 × 21 × 8 | 2 × 2/2 | - | |
| Relu | 21 × 21 × 8 | - | - | |
| Convlution-2D | 17 × 17 × 10 | 5 × 5/1 | 10 | |
| MaxPooling-2D | 8 × 8 × 10 | 2 × 2/2 | - | |
| Relu | 8 × 8 × 10 | - | - | |
| Fully-Connected | 640 | - | - | |
| Fully-Connected | 32 | - | - | |
| Relu | 32 | - | - | |
| Fully-Connected () | 6 | - | - | |
| Input | Transformed Image | 48 × 48 × 1 | - | - |
| Simple-CNN | Convolution-2D | 46 × 46 × 10 | 3 × 3/1 | 10 |
| Relu | 46 × 46 × 10 | - | - | |
| Convolution-2D | 44 × 44 × 10 | 3 × 3/1 | 10 | |
| MaxPooling-2D | 22 × 22 × 10 | 2 × 2/2 | - | |
| Relu | 22 × 22 × 10 | - | - | |
| Convolution-2D | 20 × 20 × 10 | 3 × 3/1 | 10 | |
| Relu | 20 × 20 × 10 | - | - | |
| Convolution-2D | 18 × 18 × 10 | 3 × 3/1 | 10 | |
| Batch Normalization | 18 × 18 × 10 | - | - | |
| MaxPooling-2D | 9 × 9 × 10 | 2 × 2/2 | - | |
| Relu | 9 × 9 × 10 | - | - | |
| Dropout (p = 0.5) | 9 × 9 × 10 | - | - | |
| Fully-Connected | 810 | - | - | |
| Fully-Connected | 50 | - | - | |
| Relu | 50 | - | - | |
| Fully-Connected | 3 | - | - |
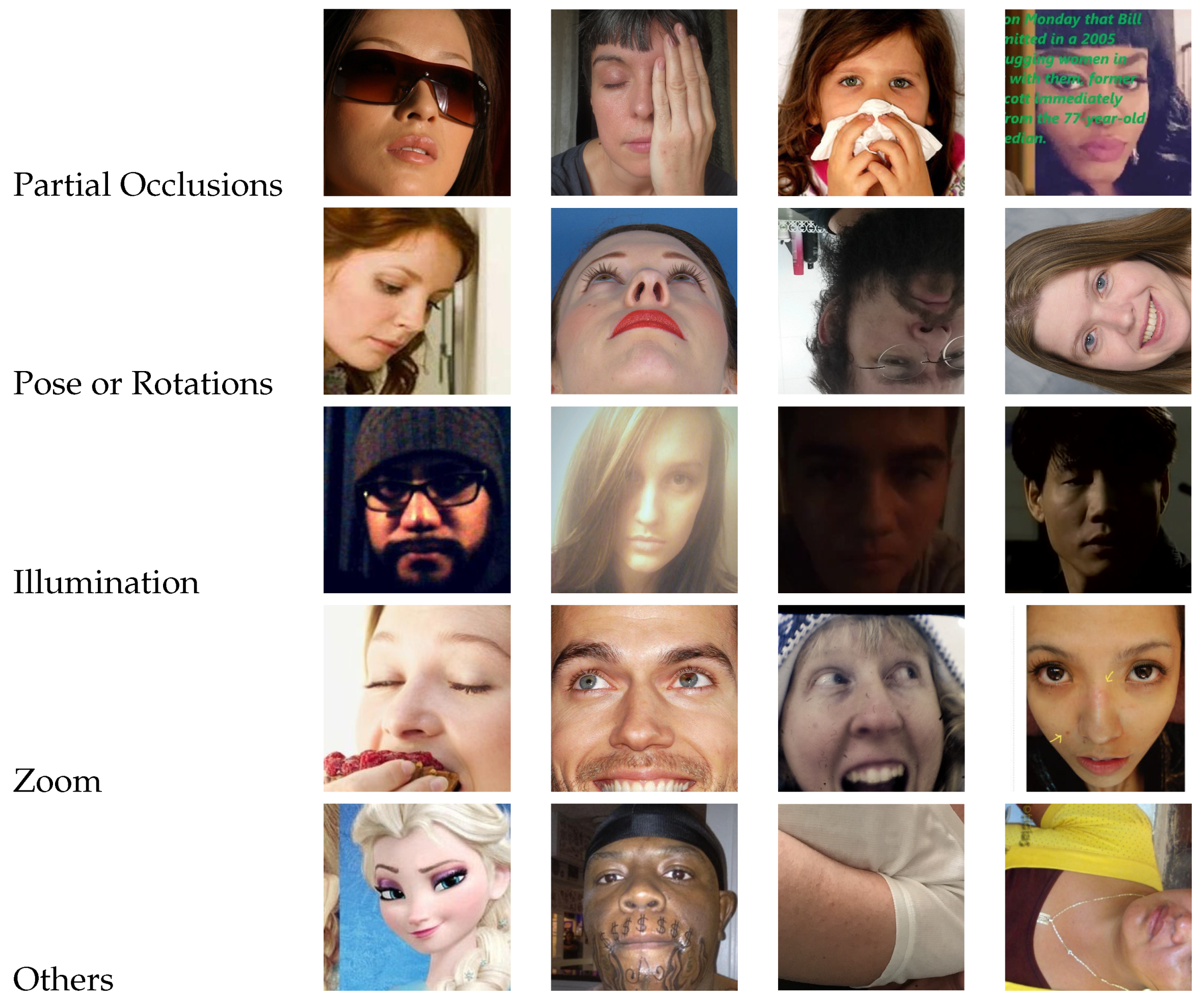
Appendix C. Analysis of Errors
Appendix C.1. Errors Due to Facial Detector


Appendix C.2. Most Common Errors across Emotions
| Neutral | Sad | Surprise | Fear | Disgust | Anger | Contempt | None | |
|---|---|---|---|---|---|---|---|---|
| fold 1 | 35 | 136 | 3 | 9 | 57 | 102 | 316 | 71 |
| fold 2 | 48 | 141 | 3 | 2 | 70 | 99 | 342 | 57 |
| fold 3 | 38 | 125 | 2 | 4 | 74 | 82 | 306 | 57 |
| fold 4 | 37 | 142 | 2 | 7 | 75 | 87 | 317 | 58 |
| fold 5 | 33 | 127 | 2 | 5 | 67 | 109 | 364 | 61 |
| Total | 191 | 671 | 12 | 27 | 343 | 479 | 1.645 | 304 |

| Neutral | Happy | Surprise | None | |
|---|---|---|---|---|
| fold 1 | 37 | 204 | 48 | 177 |
| fold 2 | 19 | 181 | 46 | 136 |
| fold 3 | 26 | 162 | 48 | 142 |
| fold 4 | 27 | 186 | 52 | 145 |
| fold 5 | 37 | 218 | 48 | 148 |
| Total | 146 | 951 | 242 | 748 |

| Sad | Fear | Disgust | Anger | |
|---|---|---|---|---|
| fold 1 | 19 | 12 | 0 | 12 |
| fold 2 | 12 | 16 | 1 | 14 |
| fold 3 | 11 | 14 | 1 | 21 |
| fold 4 | 12 | 15 | 1 | 17 |
| fold 5 | 15 | 20 | 0 | 14 |
| Total | 69 | 77 | 3 | 78 |

| Happy | |
|---|---|
| fold 1 | 68 |
| fold 2 | 67 |
| fold 3 | 65 |
| fold 4 | 52 |
| fold 5 | 68 |
| Total | 320 |

References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yu, Z.; Zhang, C. Image Based Static Facial Expression Recognition with Multiple Deep Network Learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction; Association for Computing Machinery: New York, NY, USA, 2015; pp. 435–442. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. Available online: http://arxiv.org/abs/1506.02025 (accessed on 2 August 2021).
- Yu, J.; Wang, S. Visual Speech Recognition in Natural Scenes Based on Spatial Transformer Networks. In Proceedings of the 2020 IEEE 14th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 30 October–1 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Bian, C.; Zhang, Y.; Yang, F.; Bi, W.; Lu, W. Spontaneous facial expression database for academic emotion inference in online learning. IET Comput. Vis. 2019, 13, 329–337. [Google Scholar] [CrossRef]
- de Visser, E.J.; Pak, R.; Shaw, T.H. From ‘automation’ to ‘autonomy’: The importance of trust repair in human–machine interaction. Ergonomics 2018, 61, 1409–1427. [Google Scholar] [CrossRef]
- Nyquist, A.C.; Luebbe, A.M. An Emotion Recognition–Awareness Vulnerability Hypothesis for Depression in Adolescence: A Systematic Review. Clin. Child Fam. Psychol. Rev. 2019, 23, 27–53. [Google Scholar] [CrossRef] [PubMed]
- Argaud, S.; Vérin, M.; Sauleau, P.; Grandjean, D. Facial emotion recognition in Parkinson’s disease: A review and new hypotheses. Mov. Disord. 2018, 33, 554–567. [Google Scholar] [CrossRef] [PubMed]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R.W. Driver Emotion Recognition for Intelligent Vehicles: A Survey. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hassani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. Available online: https://arxiv.org/abs/1708.03985 (accessed on 2 August 2021). [CrossRef] [Green Version]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. Neural Inf. Process. 2013, 117–124. Available online: https://arxiv.org/abs/1307.0414 (accessed on 2 August 2021).
- Zhang, X.; Gao, T.; Gao, D. A New Deep Spatial Transformer Convolutional Neural Network for Image Saliency Detection. Des. Autom. Embed. Syst. 2018, 22, 243–256. [Google Scholar] [CrossRef]
- Lin, C.H.; Yumer, E.; Wang, O.; Shechtman, E.; Lucey, S. ST-GAN: Spatial transformer generative adversarial networks for image compositing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9455–9464. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Jiang, W.; Fan, X.; Zhang, C. STNReID: Deep Convolutional Networks With Pairwise Spatial Transformer Networks for Partial Person Re-Identification. IEEE Trans. Multimed. 2020, 22, 2905–2913. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Lucey, S. Inverse Compositional Spatial Transformer Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2252–2260. Available online: https://arxiv.org/abs/1612.03897 (accessed on 2 August 2021). [CrossRef] [Green Version]
- Sønderby, S.K.; Sønderby, C.K.; Maaløe, L.; Winther, O. Recurrent Spatial Transformer Networks. CoRR. 2015. Available online: http://arxiv.org/abs/1509.05329 (accessed on 2 August 2021).
- Lee, M.C.H.; Oktay, O.; Schuh, A.; Schaap, M.; Glocker, B. Image-and-Spatial Transformer Networks for Structure-Guided Image Registration. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11765, pp. 337–345. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P. Basic Emotions. In Handbook of Cognition and Emotion; Dalgleish, T., Powers, M.J., Eds.; Wiley: Hoboken, NJ, USA, 1999; pp. 45–60. [Google Scholar] [CrossRef]
- Posner, J.; Russell, J.A.; Peterson, B.S. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev. Psychopathol. 2005, 17. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar] [CrossRef] [Green Version]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower Provost, E.; Kim, S.; Chang, J.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, B.T.; Trinh, M.H.; Phan, T.V.; Nguyen, H.D. An efficient real-time emotion detection using camera and facial landmarks. In Proceedings of the 2017 Seventh International Conference on Information Science and Technology (ICIST), Da Nang, Vietnam, 16–19 April 2017; pp. 251–255. [Google Scholar] [CrossRef]
- Bagheri, E.; Esteban, P.G.; Cao, H.L.; De Beir, A.; Lefeber, D.; Vanderborght, B. An Autonomous Cognitive Empathy Model Responsive to Users’ Facial Emotion Expressions. ACM Trans. Interact. Intell. Syst. 2020, 10, 20. [Google Scholar] [CrossRef]
- Tautkute, I.; Trzcinski, T. Classifying and Visualizing Emotions with Emotional DAN. Fundam. Informaticae 2019, 168, 269–285. [Google Scholar] [CrossRef] [Green Version]
- Mavani, V.; Raman, S.; Miyapuram, K.P. Facial Expression Recognition using Visual Saliency and Deep Learning. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW 2017), Venice, Italy, 22–29 October 2017; pp. 2783–2788. [Google Scholar] [CrossRef] [Green Version]
- Kovashka, A.; Grauman, K. Attribute Adaptation for Personalized Image Search. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 3432–3439. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Yan, R.; Hauptmann, A.G. Adapting SVM Classifiers to Data with Shifted Distributions. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 69–76. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- King, D.E. Dlib-Ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’S J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Liu, N.; Zhang, N.; Wan, K.; Han, J.; Shao, L. Visual Saliency Transformer. 2021. Available online: https://arxiv.org/abs/2104.12099 (accessed on 2 August 2021).
- Pahuja, A.; Majumder, A.; Chakraborty, A.; Babu, R.V. Enhancing Salient Object Segmentation through Attention. 2019. Available online: http://arxiv.org/abs/1905.11522 (accessed on 2 August 2021).
- Kroner, A.; Senden, M.; Driessens, K.; Goebel, R. Contextual encoder-decoder network for visual saliency prediction. Neural Netw. 2020, 129, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Huang, S.; Duan, J.; Zhao, Q. SALICON: Saliency in Context. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1072–1080. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Jalwana, M.; Akhtar, N.; Bennamoun, M.; Mian, A. CAMERAS: Enhanced Resolution and Sanity Preserving Class Activation Mapping for Image Saliency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 16327–16336. Available online: https://arxiv.org/abs/2106.10649 (accessed on 2 August 2021).







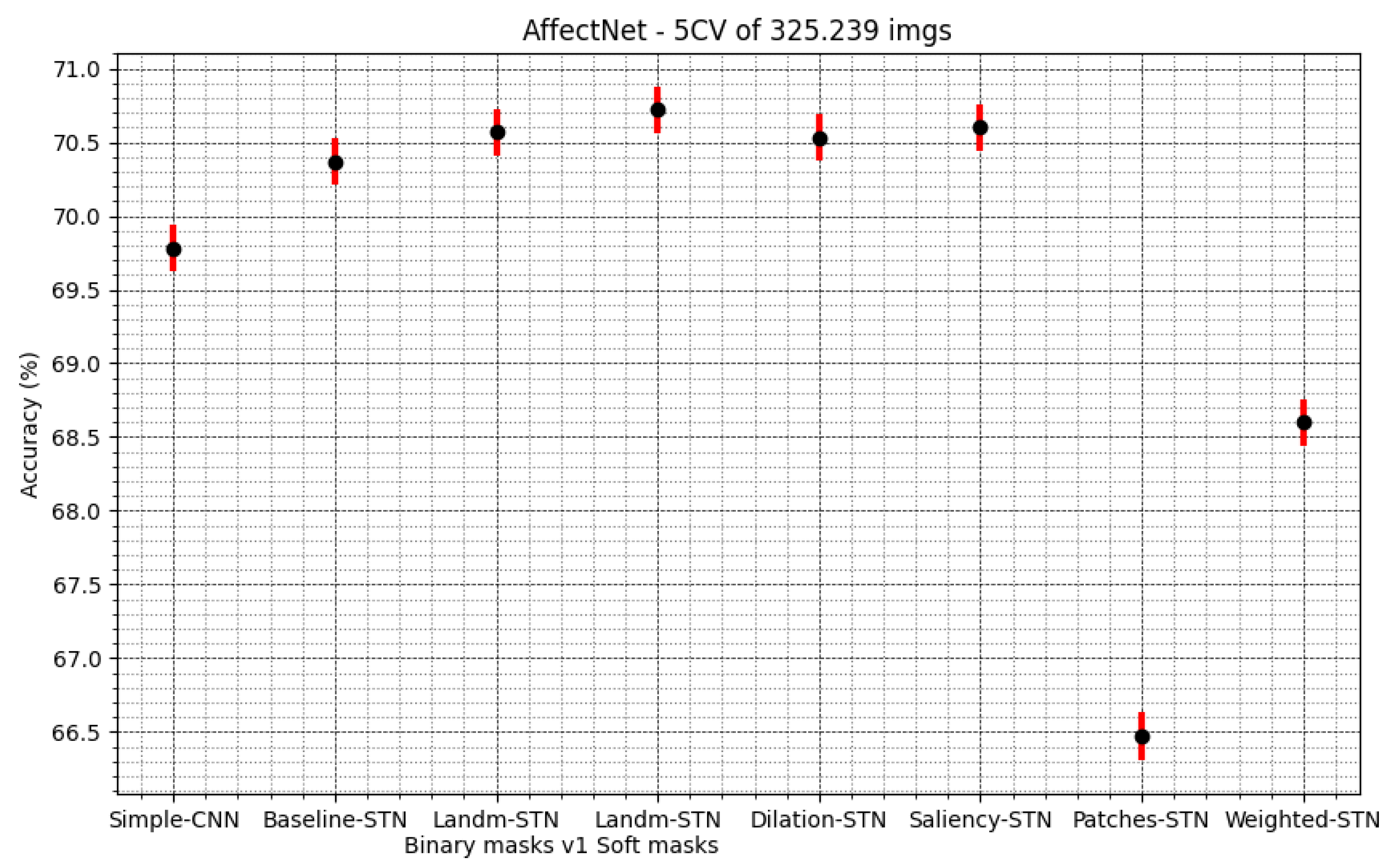
| Strategy | Accuracy ± 95% Confidence Interval | Average Epochs to Converge |
|---|---|---|
| ZeroR | 49.26 ± 0.17 | - |
| Simple-CNN | 69.78 ± 0.16 | 68 |
| Baseline STN | 70.37 ± 0.16 | 89 |
| STN with landmarks—binary masks v1 | 70.57 ± 0.16 | 70 |
| STN with landmarks—binary masks v2 | 70.54 ± 0.16 | 58 |
| STN with landmarks—binary masks v3 | 70.59 ± 0.16 | - |
| STN with landmarks—soft masks | 70.72 ± 0.16 | 71 |
| STN with dilated masks | 70.53 ± 0.16 | 58 |
| STN with saliency masks | 70.60 ± 0.16 | 108 |
| STN with patches masks | 66.47 ± 0.16 | 67 |
| STN with weighted masks | 68.60 ± 0.16 | 51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luna-Jiménez, C.; Cristóbal-Martín, J.; Kleinlein, R.; Gil-Martín, M.; Moya, J.M.; Fernández-Martínez, F. Guided Spatial Transformers for Facial Expression Recognition. Appl. Sci. 2021, 11, 7217. https://doi.org/10.3390/app11167217
Luna-Jiménez C, Cristóbal-Martín J, Kleinlein R, Gil-Martín M, Moya JM, Fernández-Martínez F. Guided Spatial Transformers for Facial Expression Recognition. Applied Sciences. 2021; 11(16):7217. https://doi.org/10.3390/app11167217
Chicago/Turabian StyleLuna-Jiménez, Cristina, Jorge Cristóbal-Martín, Ricardo Kleinlein, Manuel Gil-Martín, José M. Moya, and Fernando Fernández-Martínez. 2021. "Guided Spatial Transformers for Facial Expression Recognition" Applied Sciences 11, no. 16: 7217. https://doi.org/10.3390/app11167217
APA StyleLuna-Jiménez, C., Cristóbal-Martín, J., Kleinlein, R., Gil-Martín, M., Moya, J. M., & Fernández-Martínez, F. (2021). Guided Spatial Transformers for Facial Expression Recognition. Applied Sciences, 11(16), 7217. https://doi.org/10.3390/app11167217