
Detection and Evaluation of Machine Learning Bias


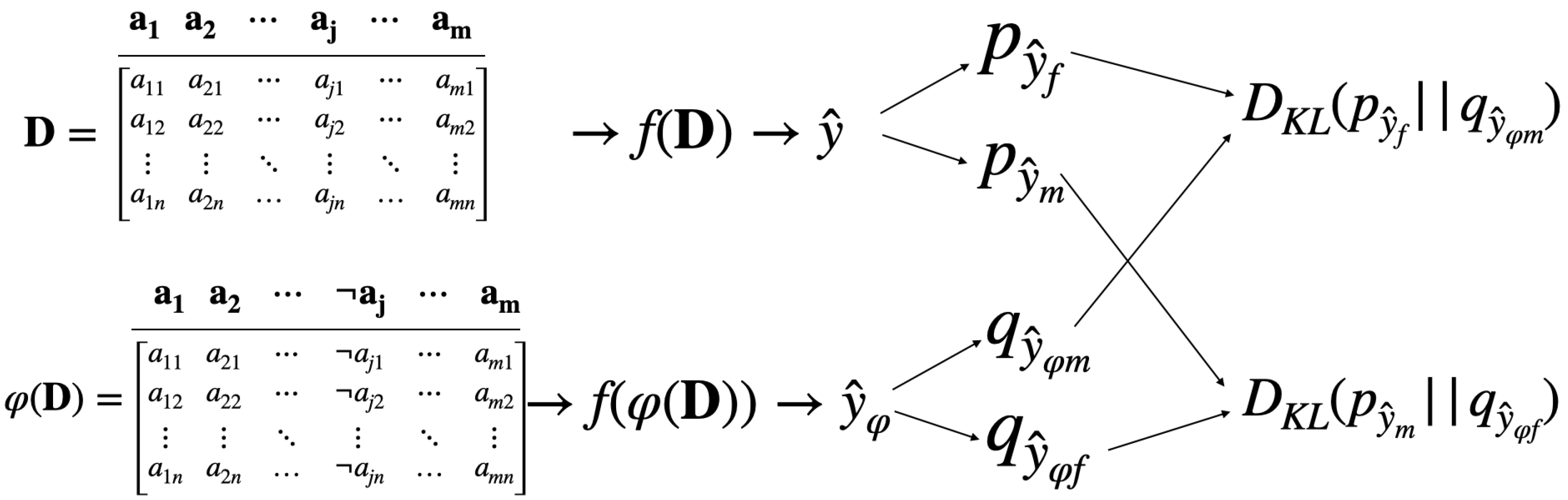{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Firstly, we aim to investigate machine learning bias in relation to human cognitive bias. Some important philosophical arguments will be discussed in this section.
- Secondly, we intend to propose a wrapper bias detection technique based on a novel alternation function to detect machine learning bias.
- Lastly, we propose an evaluation method to determine the bias in data using KL divergence. This may help in creating more reliable and explainable machine learning models. We will conduct several experiments to validate our contribution.
2. Bias and Unfairness
3. Machine Learning Bias: Detection and Evaluation
4. Our Contribution
4.1. Notations
4.2. Problem Statement
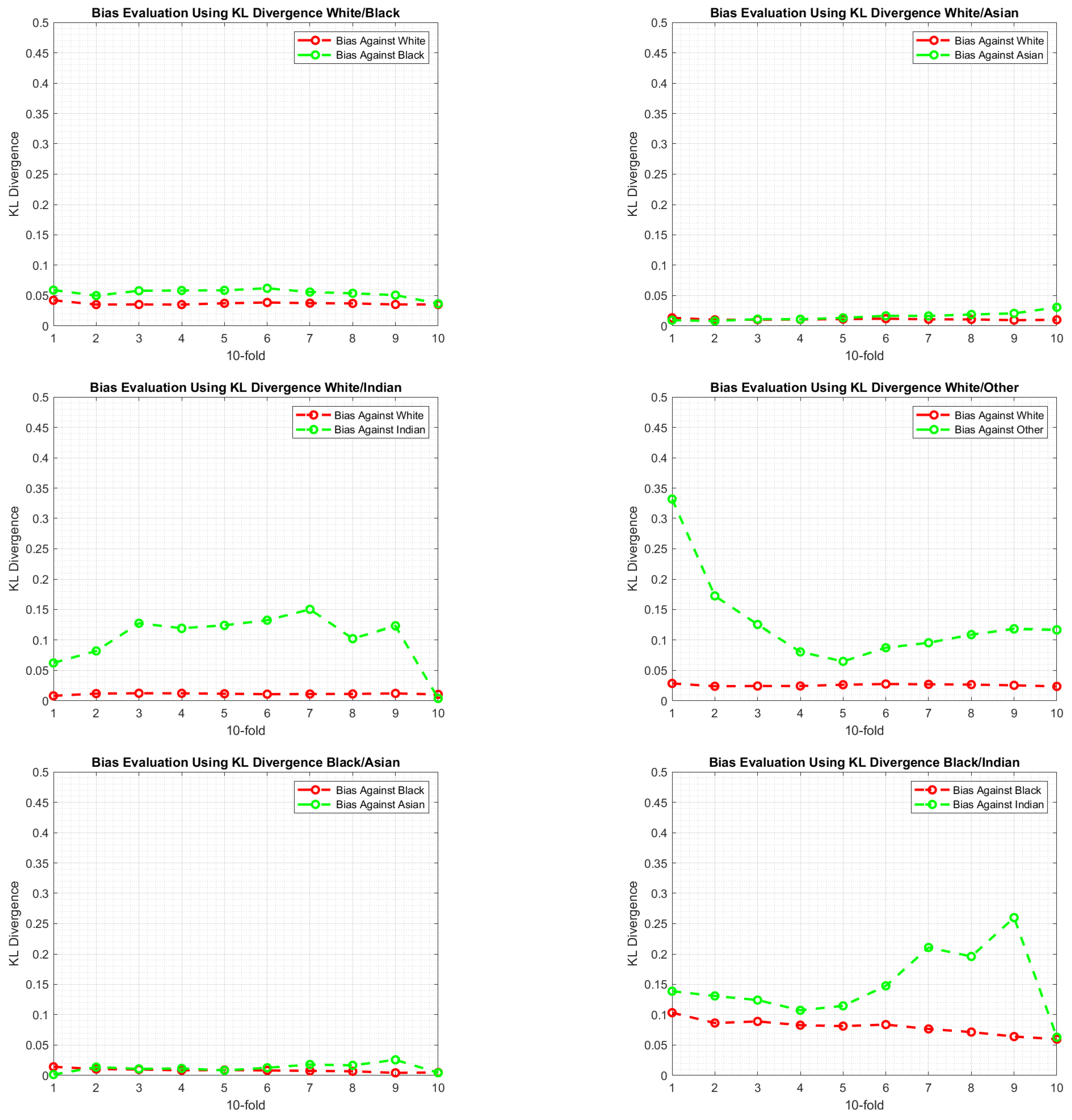
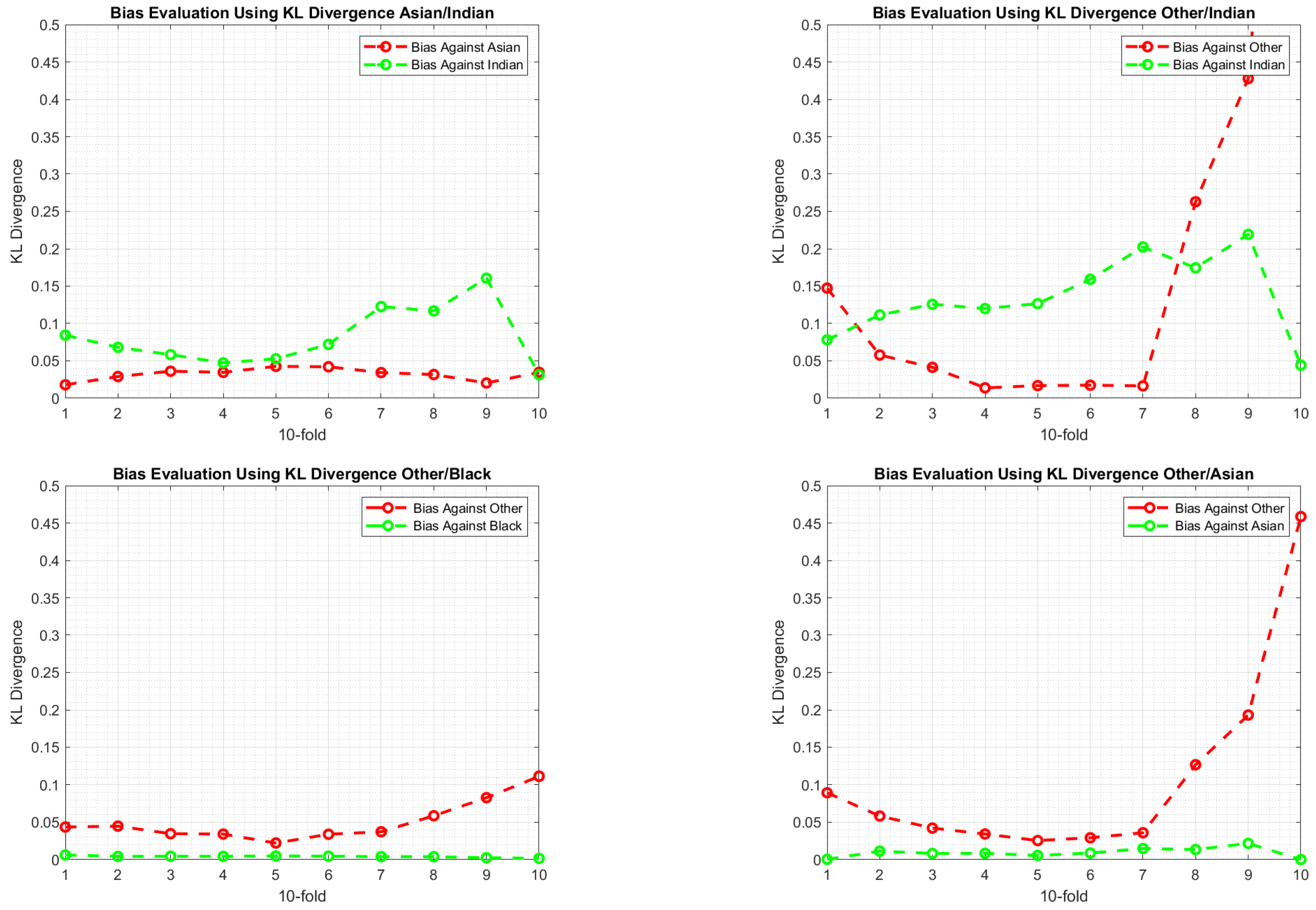
Bias Evaluation: KL Divergence
5. Methodology
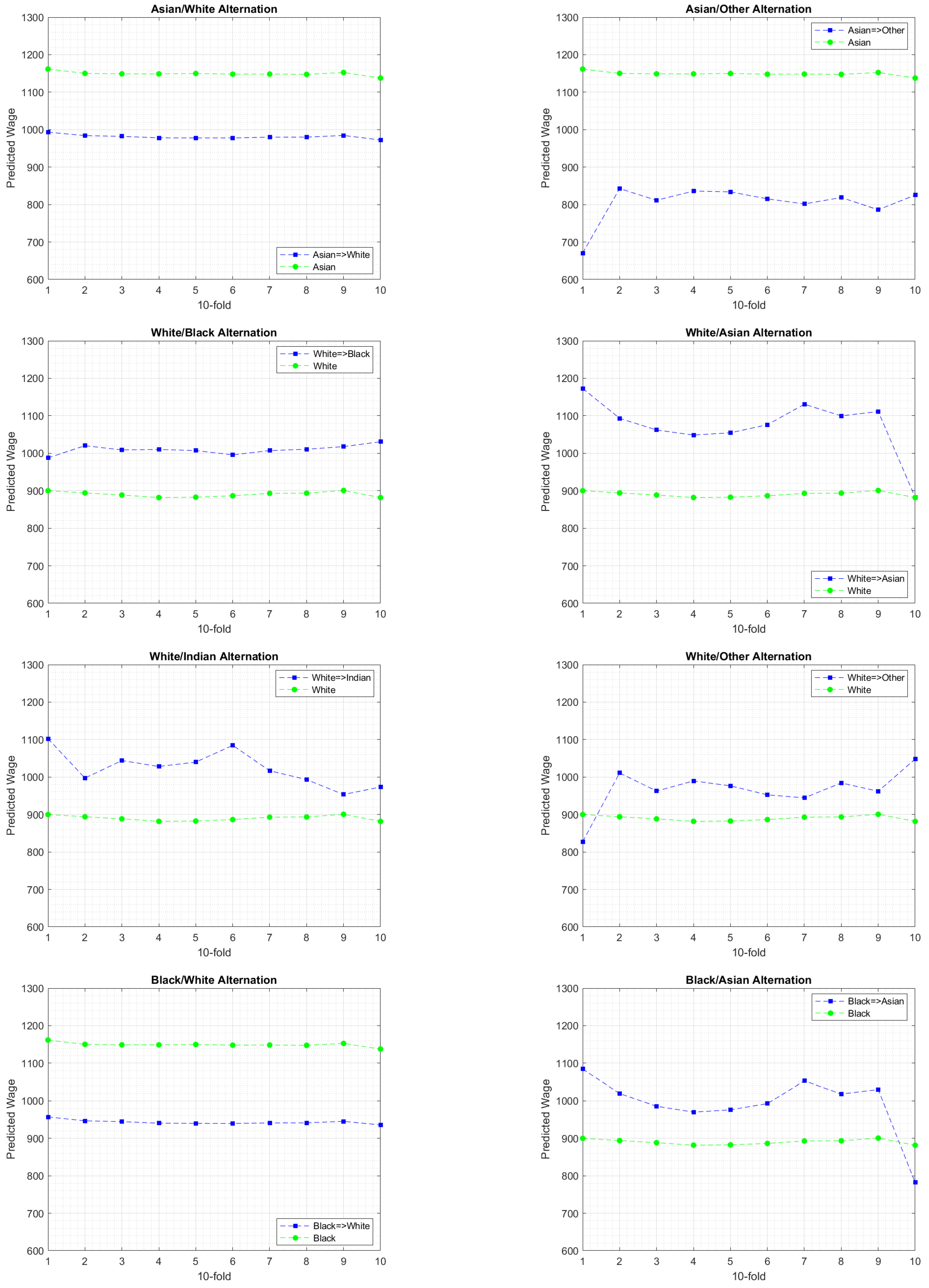
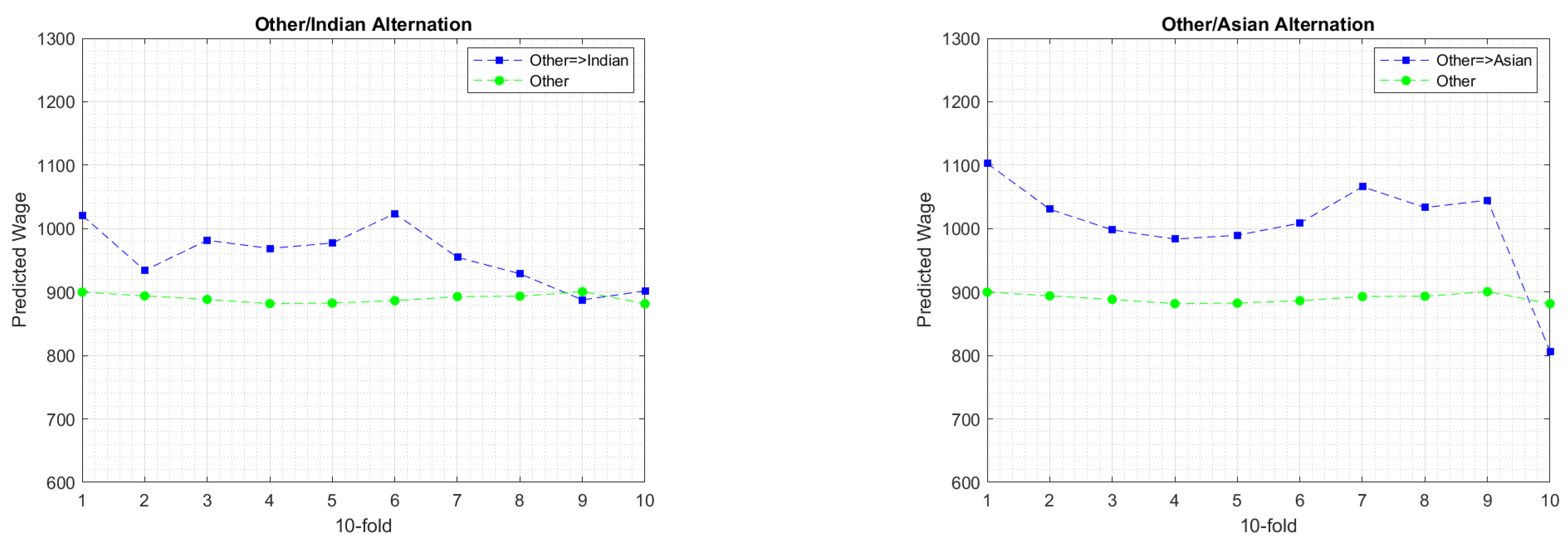
- Train the model on the dataset .
- Predict the class label for each data point in .
- Apply the alternation function on the gender attribute .
- Train the model on the alternative dataset .
- Predict the alternative predicted label .
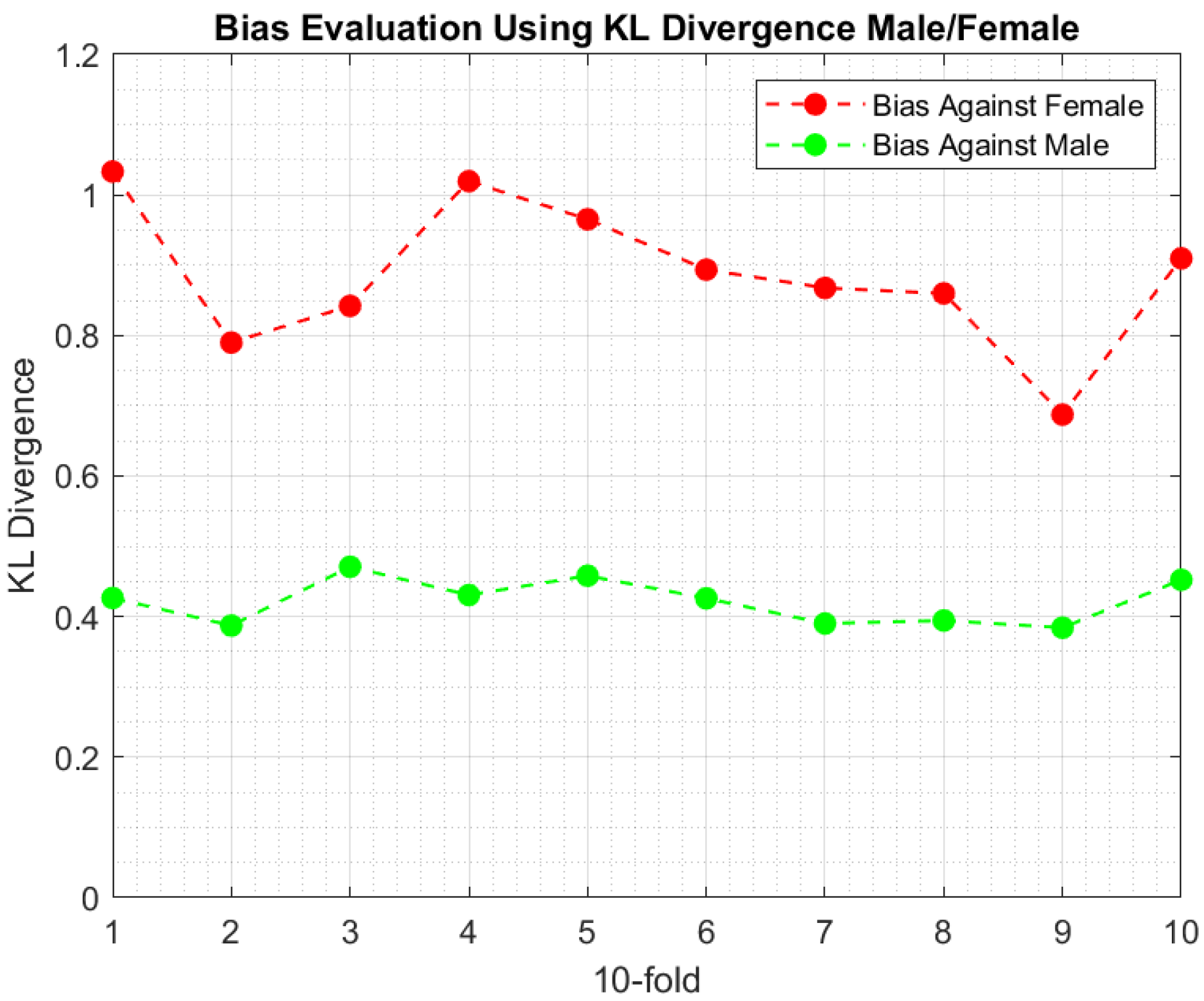
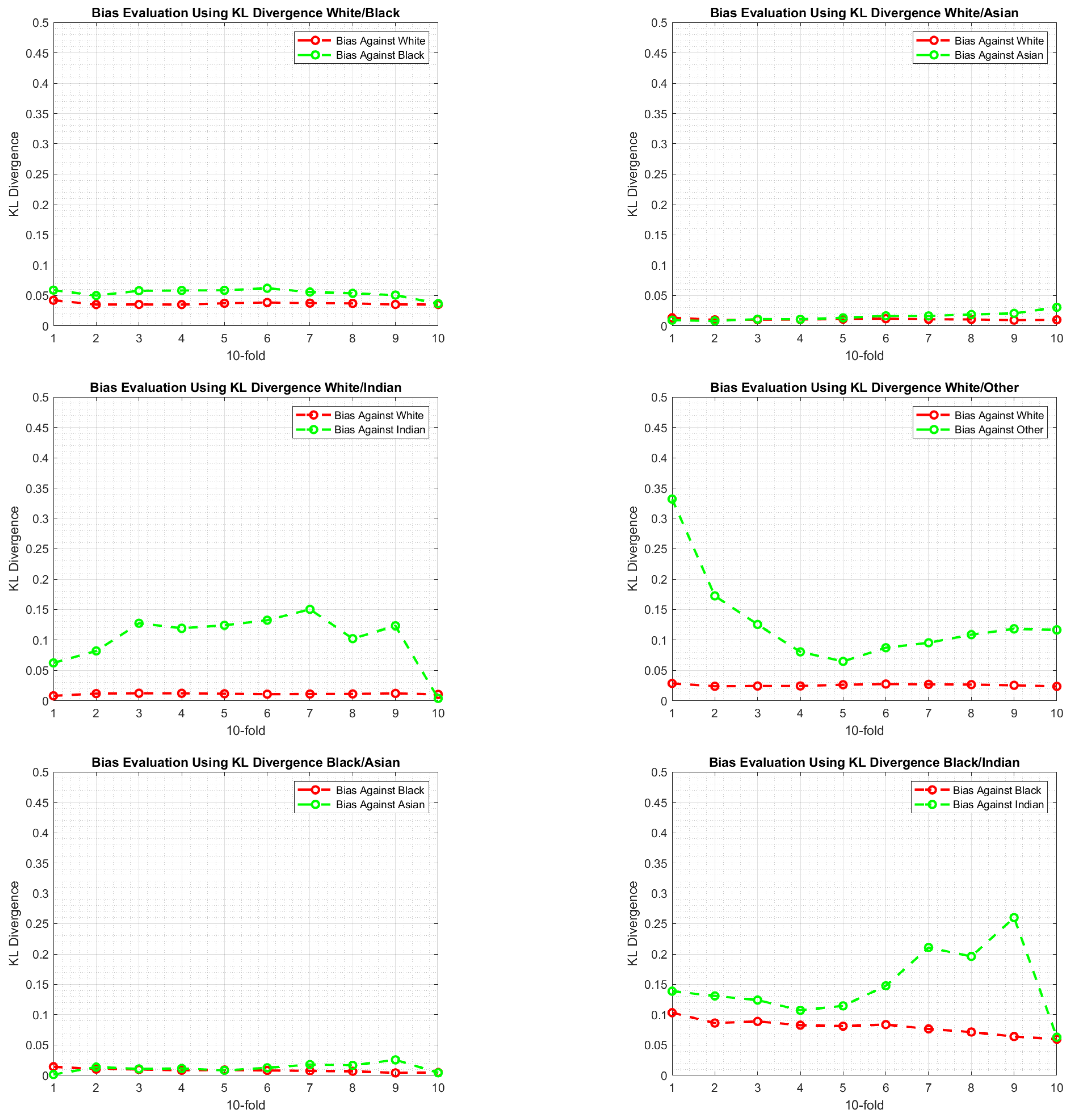
- Using Equation (3), evaluate KL Divergence between the distributions of and for each gender distinctively across all folds. That is, and .
- The difference between the with respect to the gender represents the bias. The larger is, the larger the bias will be.
6. Experiment Setup
6.1. Dataset
6.2. Algorithm and Model Selection
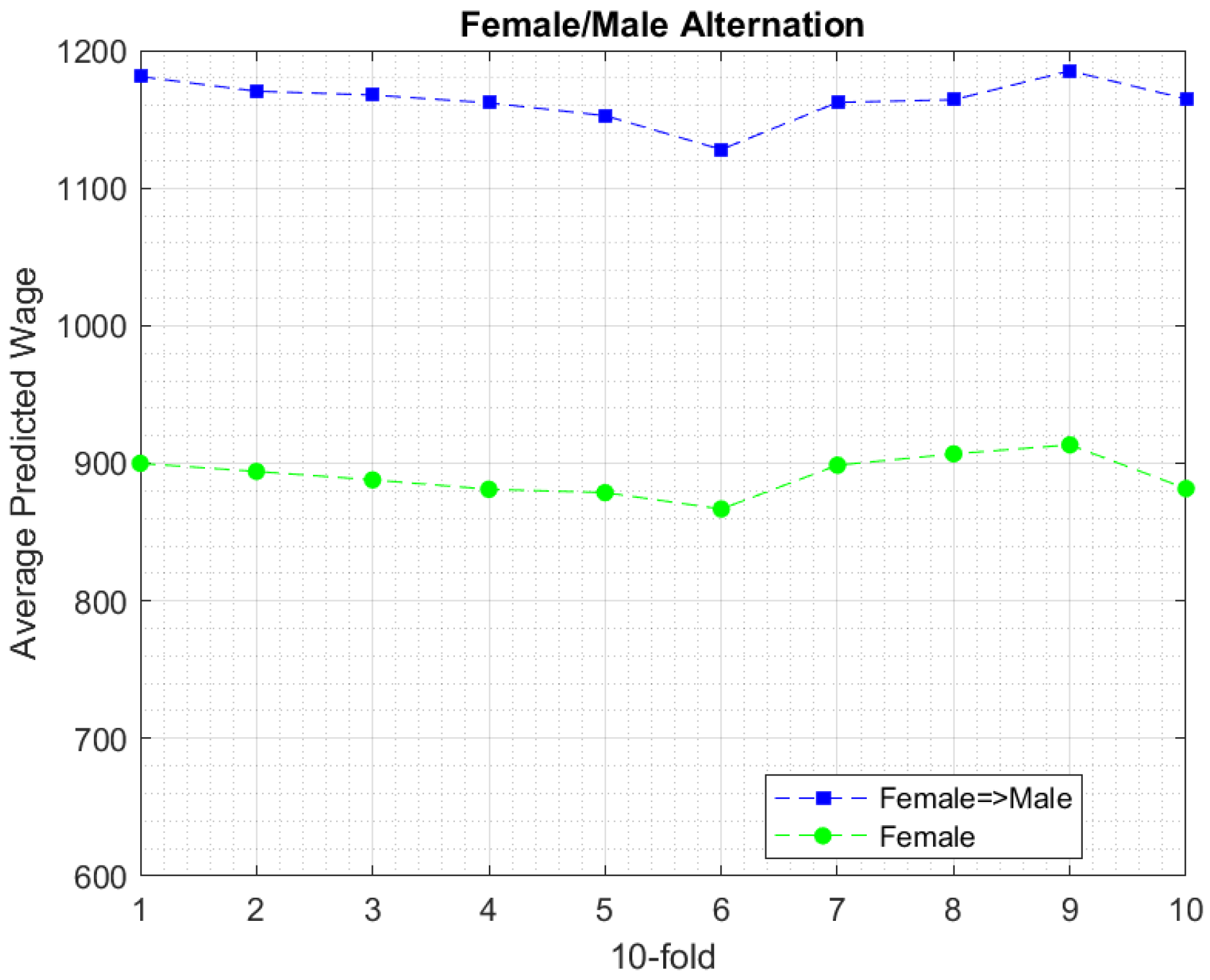
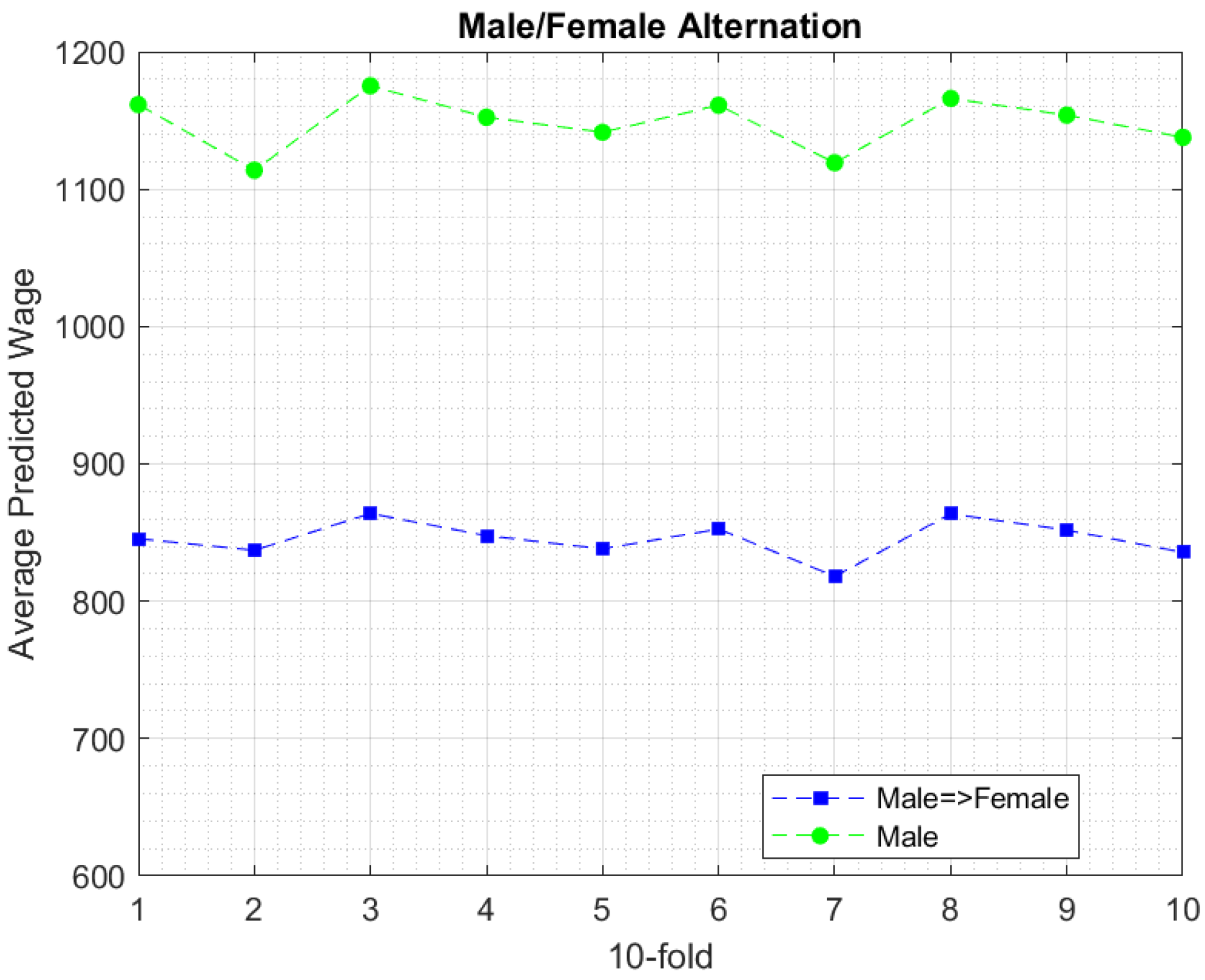
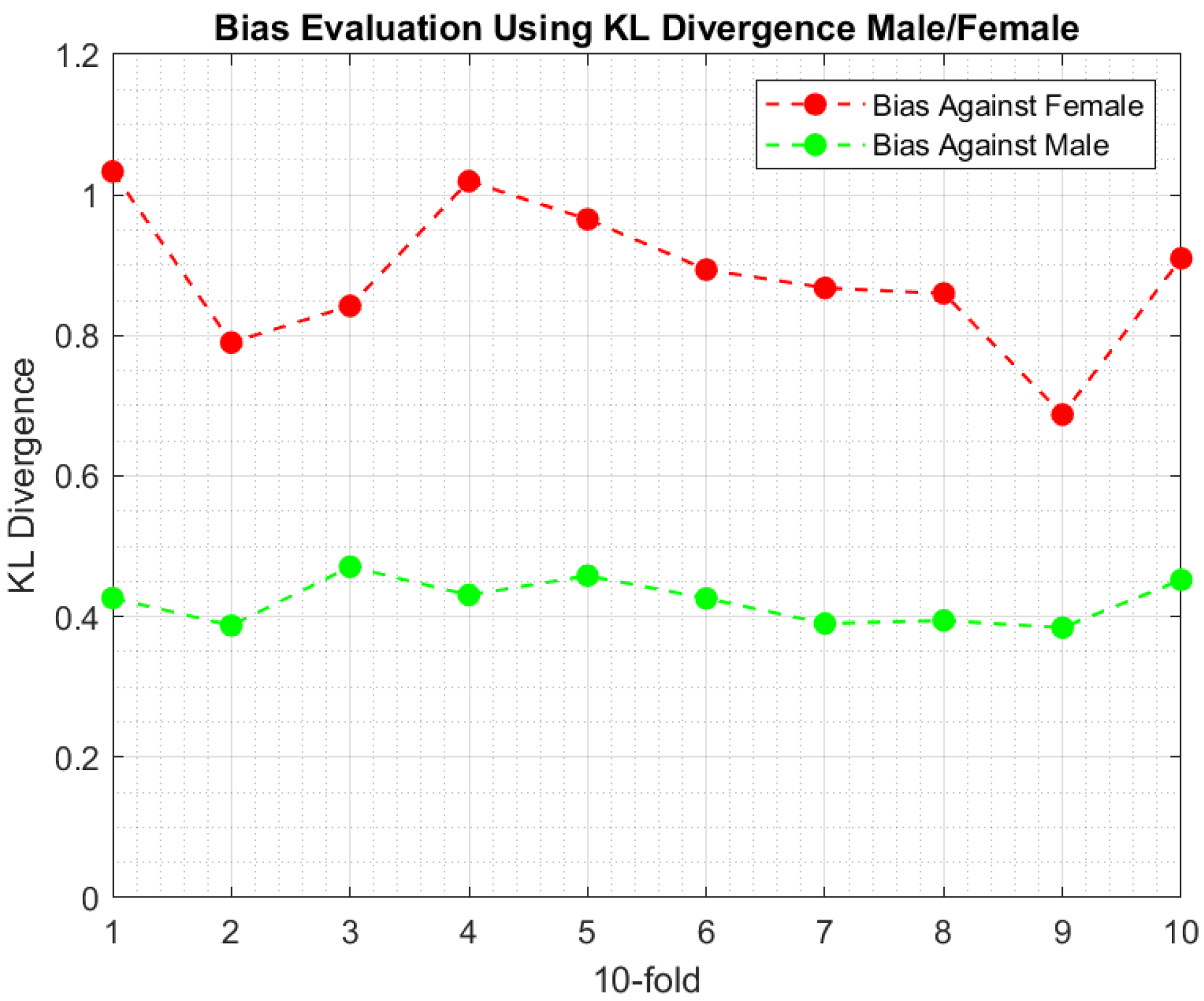
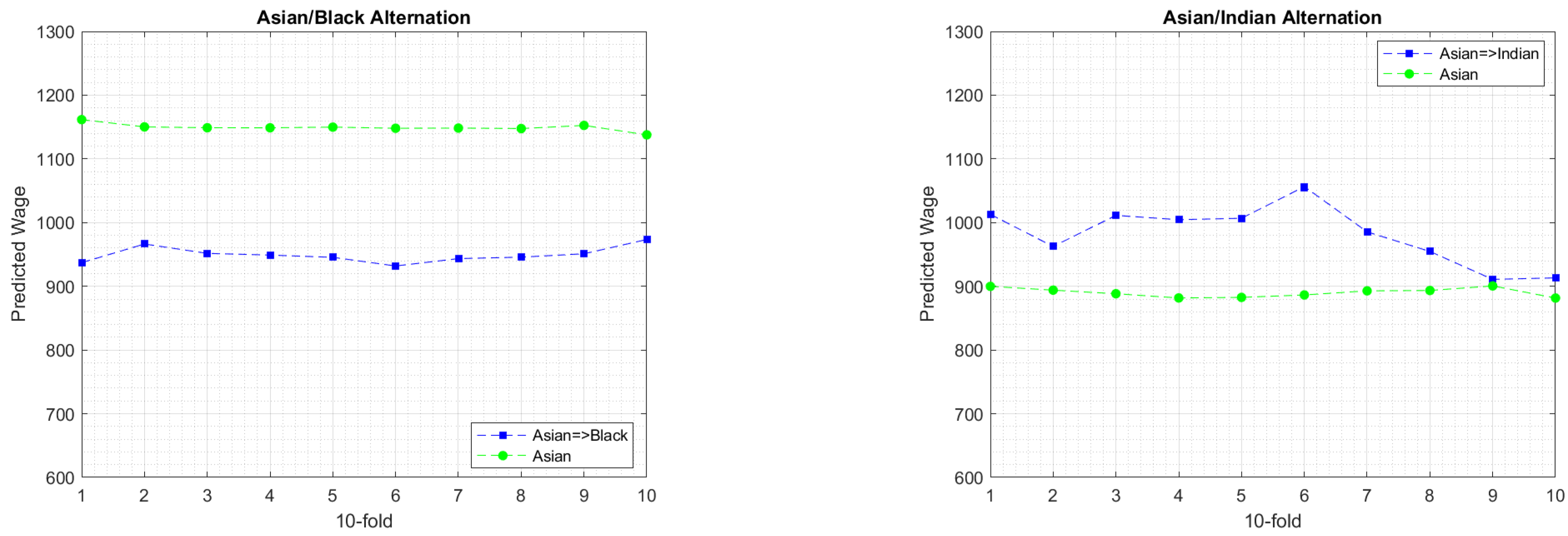
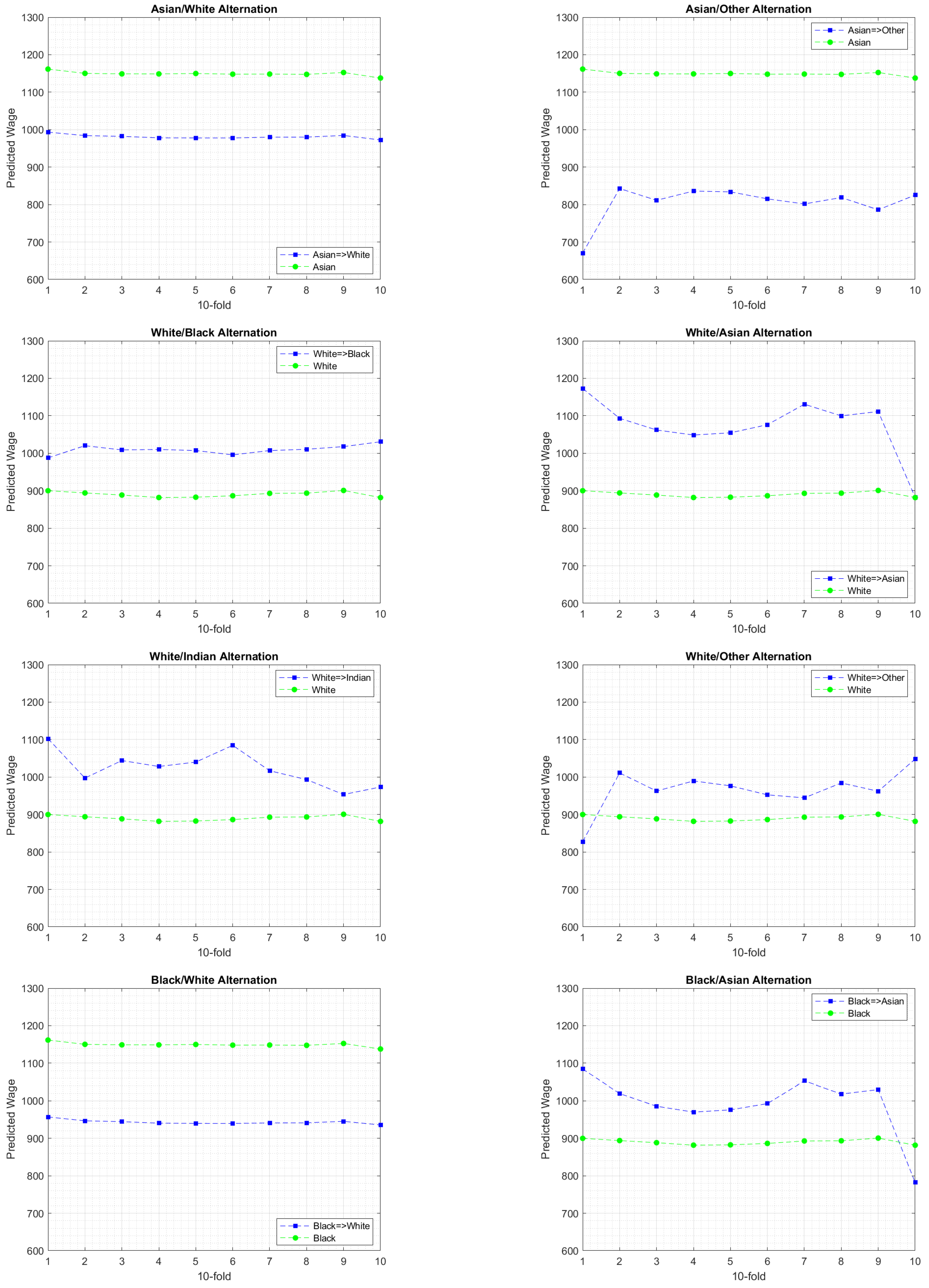
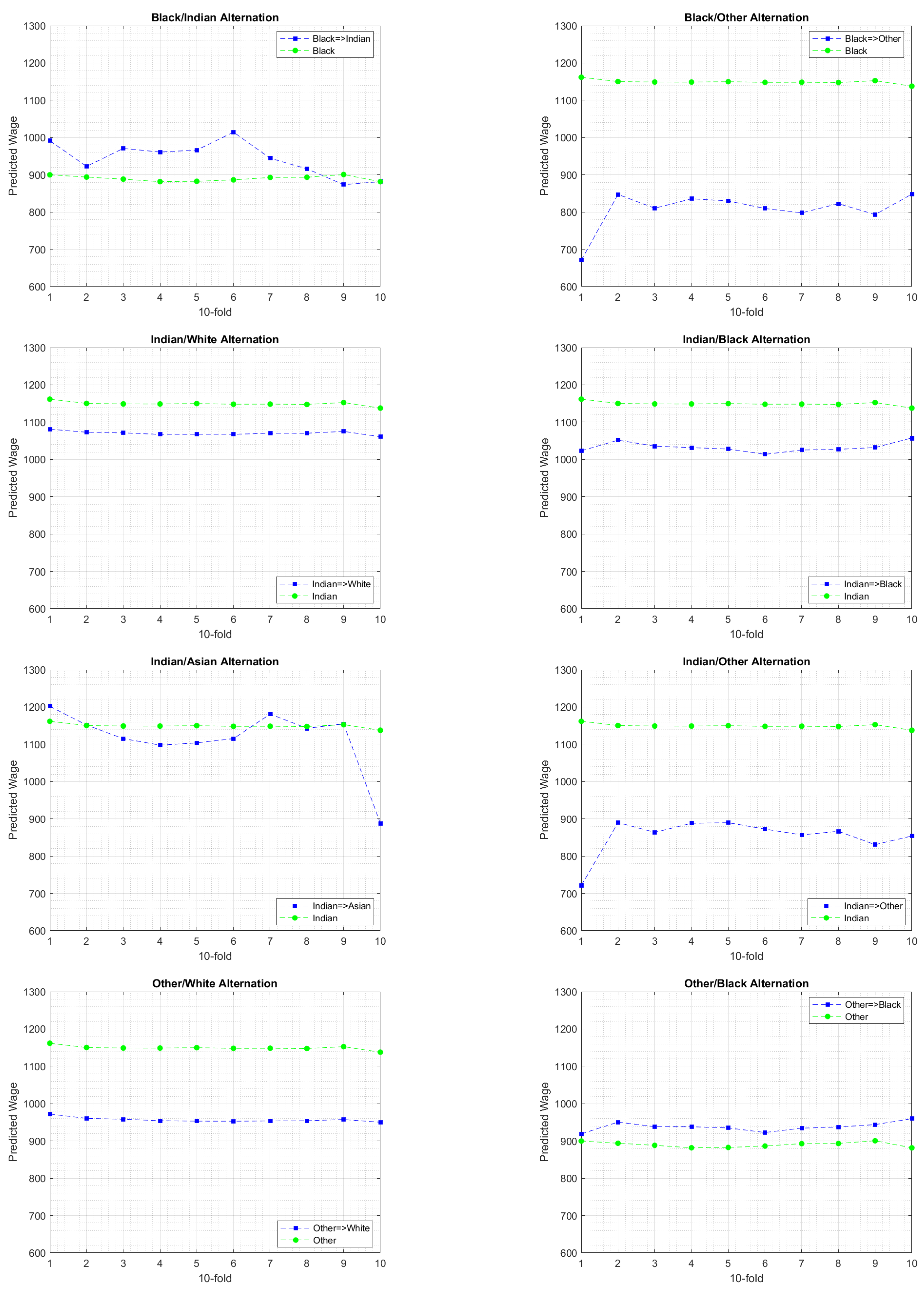
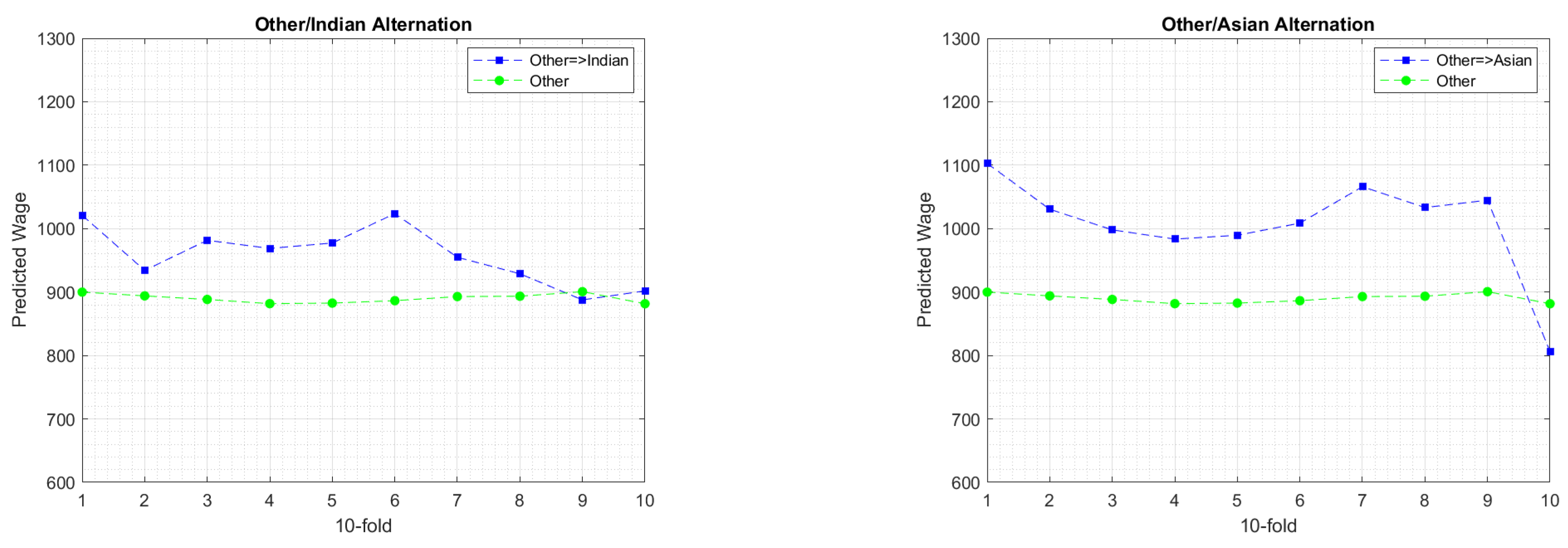
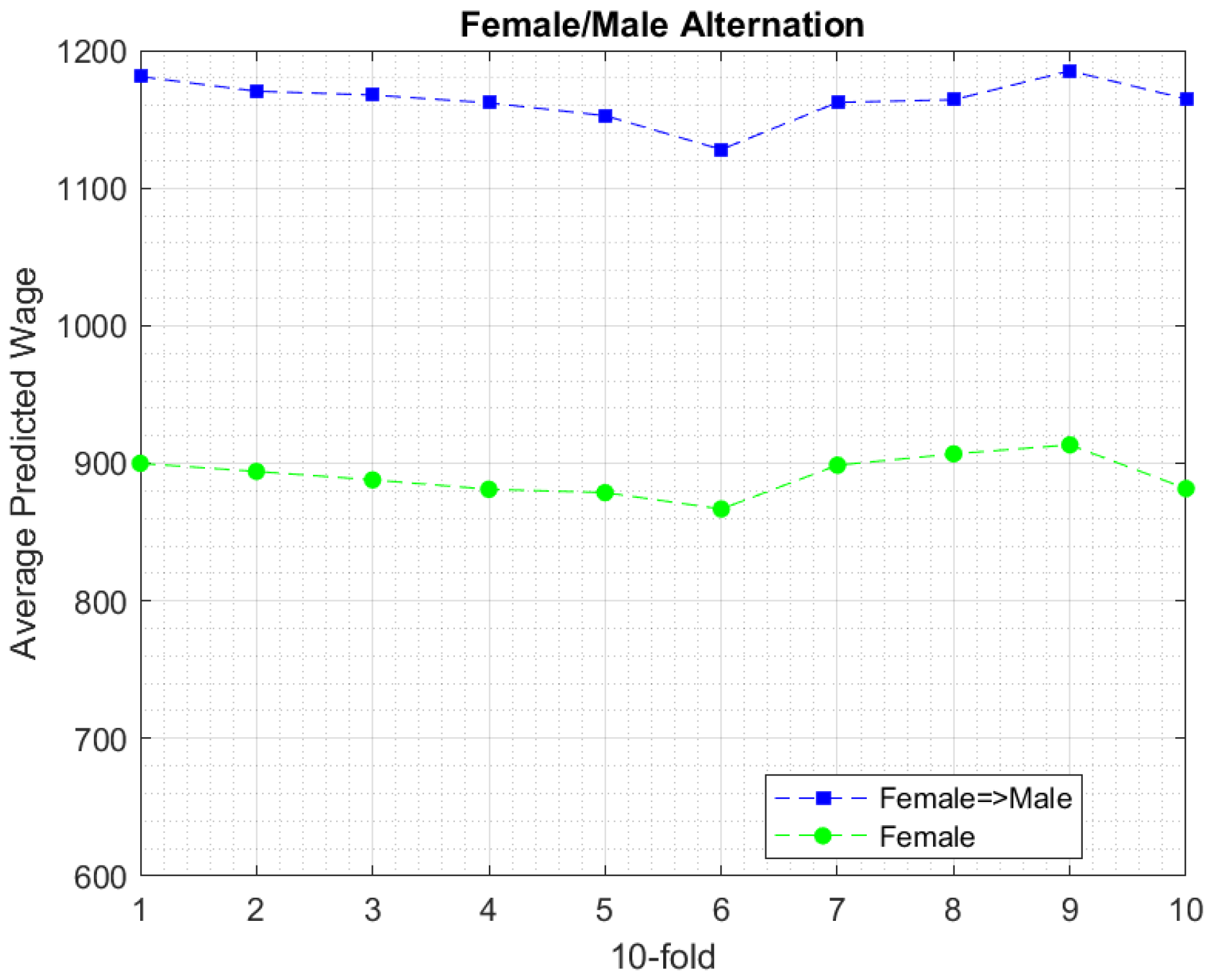
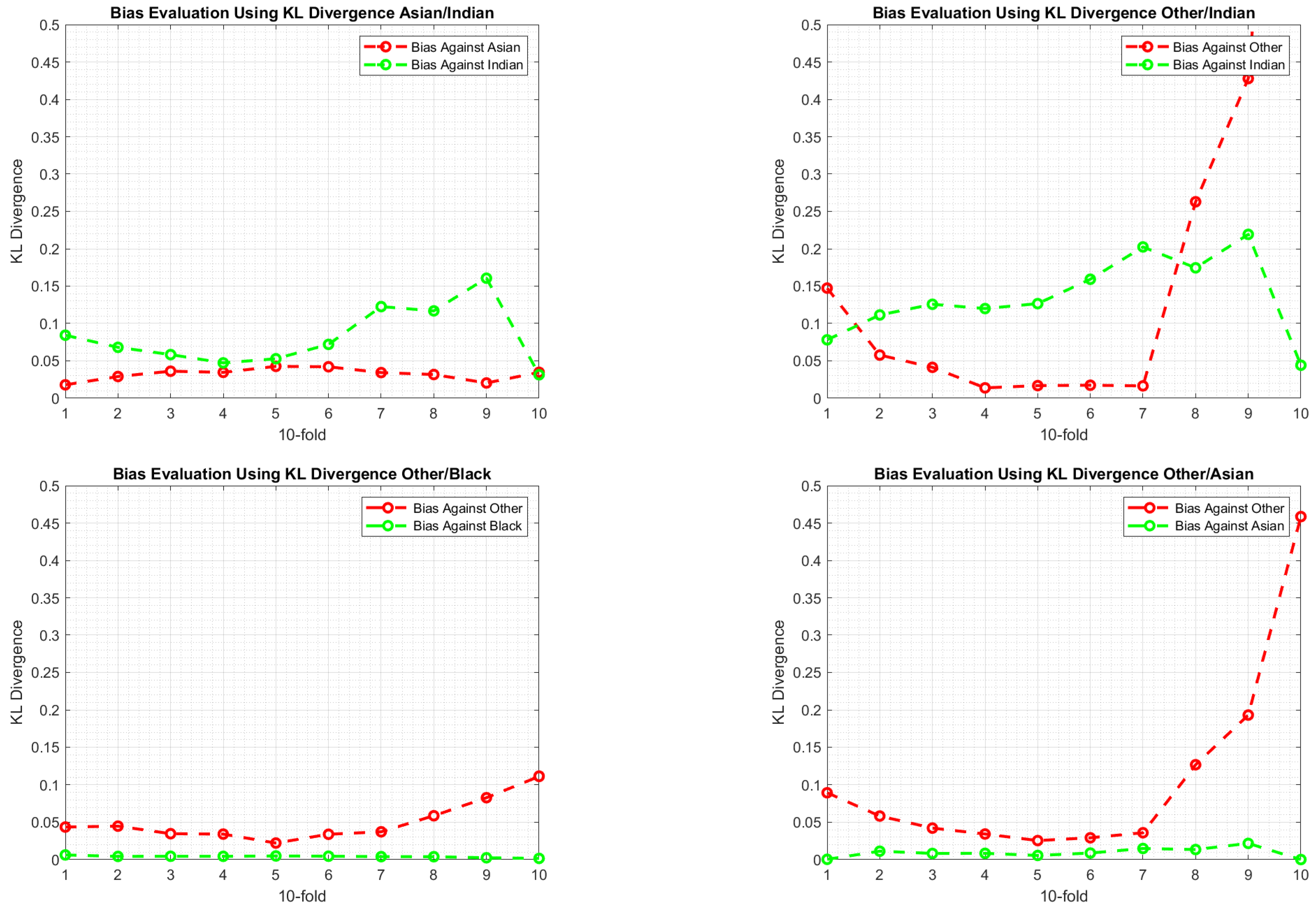
6.3. Experimental Findings
7. Discussion
8. Concluding Remarks and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Angwin, J.; Larson, J.; Larson, S.M.; Kirchner, L. Machine Bias. ProPublica. 2016. Available online: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (accessed on 22 March 2021).
- Castro, C. What’s Wrong with Machine Bias. Ergo Open Access J. Philos. 2019, 6. [Google Scholar] [CrossRef]
- Corbett-Davies, S.; Goel, S. The measure and mismeasure of fairness: A critical review of fair machine learning. arXiv 2018, arXiv:1808.00023. [Google Scholar]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef] [Green Version]
- Gianfrancesco, M.A.; Tamang, S.; Yazdany, J.; Schmajuk, G. Potential biases in machine learning algorithms using electronic health record data. JAMA Intern. Med. 2018, 178, 1544–1547. [Google Scholar] [CrossRef] [PubMed]
- Hilbert, M. Toward a synthesis of cognitive biases: How noisy information processing can bias human decision making. Psychol. Bull. 2012, 138, 211. [Google Scholar] [CrossRef] [Green Version]
- Haselton, M.G.; Nettle, D.; Murray, D.R. The evolution of cognitive bias. In The Handbook of Evolutionary Psychology; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 1–20. [Google Scholar]
- Sun, T.; Gaut, A.; Tang, S.; Huang, Y.; ElSherief, M.; Zhao, J.; Mirza, D.; Belding, E.; Chang, K.W.; Wang, W.Y. Mitigating gender bias in natural language processing: Literature review. arXiv 2019, arXiv:1906.08976. [Google Scholar]
- Amini, A.; Soleimany, A.P.; Schwarting, W.; Bhatia, S.N.; Rus, D. Uncovering and mitigating algorithmic bias through learned latent structure. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 289–295. [Google Scholar]
- Leavy, S. Uncovering gender bias in newspaper coverage of Irish politicians using machine learning. Digit. Scholarsh. Humanit. 2019, 34, 48–63. [Google Scholar] [CrossRef]
- Prates, M.O.; Avelar, P.H.; Lamb, L.C. Assessing gender bias in machine translation: A case study with google translate. Neural Comput. Appl. 2019, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Turing, A.M. Computing Machinery and Intelligence. Creat. Comput. 1980, 6, 44–53. [Google Scholar]
- Cowgill, B.; Dell’Acqua, F.; Deng, S.; Hsu, D.; Verma, N.; Chaintreau, A. Biased Programmers? Or Biased Data? A Field Experiment in Operationalizing AI Ethics. In Proceedings of the 21st ACM Conference on Economics and Computation, Virtual Event, 13–17 July 2020; pp. 679–681. [Google Scholar]
- Harris, C.G. Methods to Evaluate Temporal Cognitive Biases in Machine Learning Prediction Models. In Proceedings of the WWW ’20: Companion Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 572–575. [Google Scholar]
- Mehta, P.; Bukov, M.; Wang, C.H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A high-bias, low-variance introduction to machine learning for physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3315–3323. [Google Scholar]
- Jiang, H.; Nachum, O. Identifying and correcting label bias in machine learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Virtual Event, 26–28 August 2020; pp. 702–712. [Google Scholar]
- Sun, W.; Nasraoui, O.; Shafto, P. Evolution and impact of bias in human and machine learning algorithm interaction. PLoS ONE 2020, 15, e0235502. [Google Scholar] [CrossRef]
- Agarwal, A.; Beygelzimer, A.; Dudík, M.; Langford, J.; Wallach, H. A reductions approach to fair classification. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 60–69. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. arXiv 2019, arXiv:1908.09635. [Google Scholar]
- Rudin, C.; Wang, C.; Coker, B. The age of secrecy and unfairness in recidivism prediction. arXiv 2018, arXiv:1811.00731. [Google Scholar]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine learning and the bias-variance trade-off. arXiv 2018, arXiv:1812.11118. [Google Scholar]
- Dixon, L.; Li, J.; Sorensen, J.; Thain, N.; Vasserman, L. Measuring and mitigating unintended bias in text classification. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 67–73. [Google Scholar]
- De-Arteaga, M.; Romanov, A.; Wallach, H.; Chayes, J.; Borgs, C.; Chouldechova, A.; Geyik, S.; Kenthapadi, K.; Kalai, A.T. Bias in bios: A case study of semantic representation bias in a high-stakes setting. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 120–128. [Google Scholar]
- Leavy, S. Gender bias in artificial intelligence: The need for diversity and gender theory in machine learning. In Proceedings of the 1st International Workshop on Gender Equality in Software Engineering, Gothenburg, Sweden, 28 May 2018; pp. 14–16. [Google Scholar]
- Bellamy, R.K.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilovic, A.; et al. AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias. arXiv 2018, arXiv:1810.01943. [Google Scholar]
- Rajkomar, A.; Hardt, M.; Howell, M.D.; Corrado, G.; Chin, M.H. Ensuring fairness in machine learning to advance health equity. Ann. Intern. Med. 2018, 169, 866–872. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar]
- Crowley, R.J.; Tan, Y.J.; Ioannidis, J.P. Empirical assessment of bias in machine learning diagnostic test accuracy studies. J. Am. Med. Inform. Assoc. 2020, 27, 1092–1101. [Google Scholar] [CrossRef]
- Lötsch, J.; Ultsch, A. Current projection methods-induced biases at subgroup detection for machine-learning based data-analysis of biomedical data. Int. J. Mol. Sci. 2020, 21, 79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tversky, A.; Kahneman, D. Judgment under uncertainty: Heuristics and biases. Science 1974, 185, 1124–1131. [Google Scholar] [CrossRef]
- McCradden, M.D.; Joshi, S.; Anderson, J.A.; Mazwi, M.; Goldenberg, A.; Zlotnik Shaul, R. Patient safety and quality improvement: Ethical principles for a regulatory approach to bias in healthcare machine learning. J. Am. Med. Inform. Assoc. 2020, 27, 2024–2027. [Google Scholar] [CrossRef] [PubMed]
- Yapo, A.; Weiss, J. Ethical implications of bias in machine learning. In Proceedings of the 51st Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 3–6 January 2018. [Google Scholar]
- Barbosa, N.M.; Chen, M. Rehumanized crowdsourcing: A labeling framework addressing bias and ethics in machine learning. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Barbu, A.; Mayo, D.; Alverio, J.; Luo, W.; Wang, C.; Gutfreund, D.; Tenenbaum, J.; Katz, B. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 9453–9463. [Google Scholar]
- Challen, R.; Denny, J.; Pitt, M.; Gompels, L.; Edwards, T.; Tsaneva-Atanasova, K. Artificial intelligence, bias and clinical safety. BMJ Qual. Saf. 2019, 28, 231–237. [Google Scholar] [CrossRef] [PubMed]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
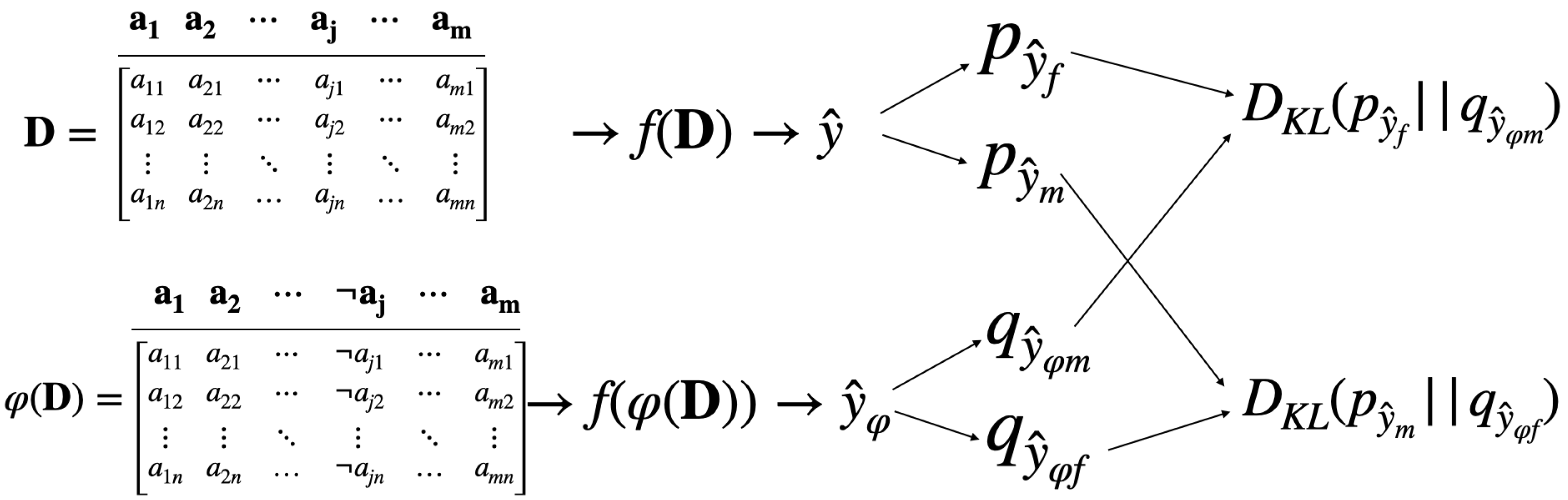



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alelyani, S. Detection and Evaluation of Machine Learning Bias. Appl. Sci. 2021, 11, 6271. https://doi.org/10.3390/app11146271
Alelyani S. Detection and Evaluation of Machine Learning Bias. Applied Sciences. 2021; 11(14):6271. https://doi.org/10.3390/app11146271
Chicago/Turabian StyleAlelyani, Salem. 2021. "Detection and Evaluation of Machine Learning Bias" Applied Sciences 11, no. 14: 6271. https://doi.org/10.3390/app11146271
APA StyleAlelyani, S. (2021). Detection and Evaluation of Machine Learning Bias. Applied Sciences, 11(14), 6271. https://doi.org/10.3390/app11146271