
Multimodal Summarization of User-Generated Videos



Abstract
1. Introduction
2. Related Work
2.1. Approaches for Video Summarization
2.2. Related Data Sets
3. Multimodal Video Summarization
3.1. Problem Formulation
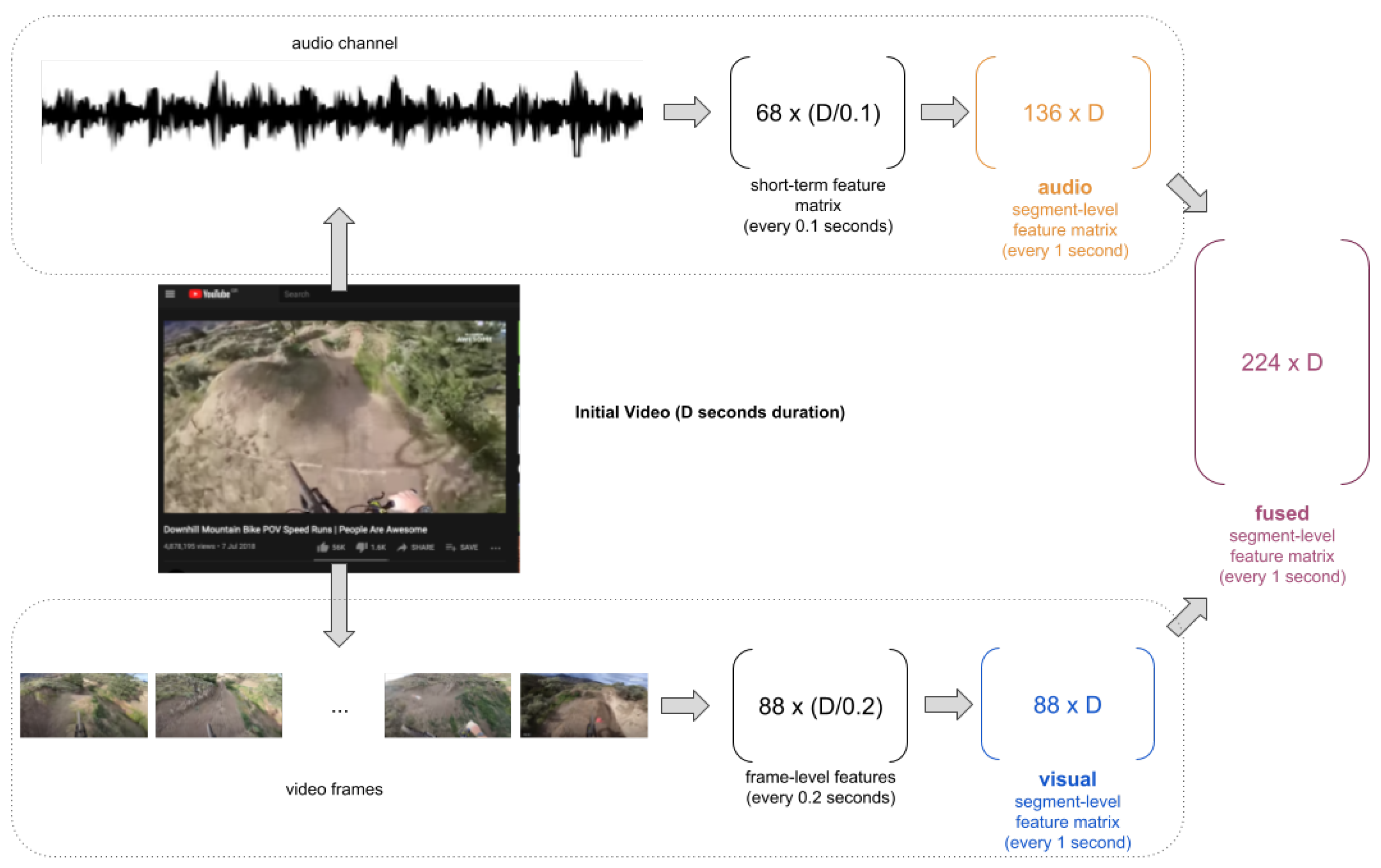
3.2. Feature Extraction
3.2.1. Audio
3.2.2. Video
- Color—related features (45 features):
- –
- 8-bin histogram of the red values
- –
- 8-bin histogram of the green values
- –
- 8-bin histogram of the blue values
- –
- 8-bin histogram of the grayscale values
- –
- 5-bin histogram of the max-by-mean-ratio for each RGB triplet
- –
- 8-bin histogram of the saturation values
- Average absolute difference between two successive frames in grey scale (1 feature)
- Facial features (2 features): The Viola-Jones [34] OpenCV implementation is used to detect frontal faces and the following features are extracted per frame:
- –
- number of faces detected
- –
- average ratio of the faces’ bounding boxes areas divided by the total area of the frame
- Optical-flow related features (3 features): The optical flow is estimated using the Lucas-Kanade method [35] and the following 3 features are extracted:
- –
- average magnitude of the flow vectors
- –
- standard deviation of the angles of the flow vectors
- –
- a hand-crafted feature that measures the possibility that there is a camera tilt movement—this is achieved by measuring a ratio of the magnitude of the flow vectors by the deviation of the angles of the flow vectors.
- Current shot duration (1 feature): a basic shot detection method is implemented in this library. The length of the shot (in seconds) in which each frame belongs to, is used as a feature.
- Object-related features (36 features): We use the Single Shot Multibox Detector [36] method for detecting 12 categories of objects. For each frame, as soon as the object(s) of each category are detected, three statistics are extracted: number of objects detected, average detection confidence and average ratio of the objects’ area to the area of the frame. So in total, 3 × 12 = 36 object-related features are extracted. The 12 object categories we detect are the following: person, vehicle, outdoor, animal, accessory, sports, kitchen, food, furniture, electronic, appliance and indoor.
3.3. Segment-Level Classification
- audio features: the 136-D audio feature vectors
- visual features: the 88-D visual feature vectors
- audio-visual features: the merged 224-D feature representation (as an early fusion approach)
3.4. Post-Processing
- calculate the audio, visual or fused features for each segment of the video
- classify each segment of the video by applying the respective audio, visual or fusion classifier
- post-process the sequential classifier predictions in order to avoid obvious errors
- if are the predictions of the segment classifier for a particular video
- then is the output of the median filtering
- and is the final post-processed prediction.
4. Dataset Compilation
4.1. Video Data
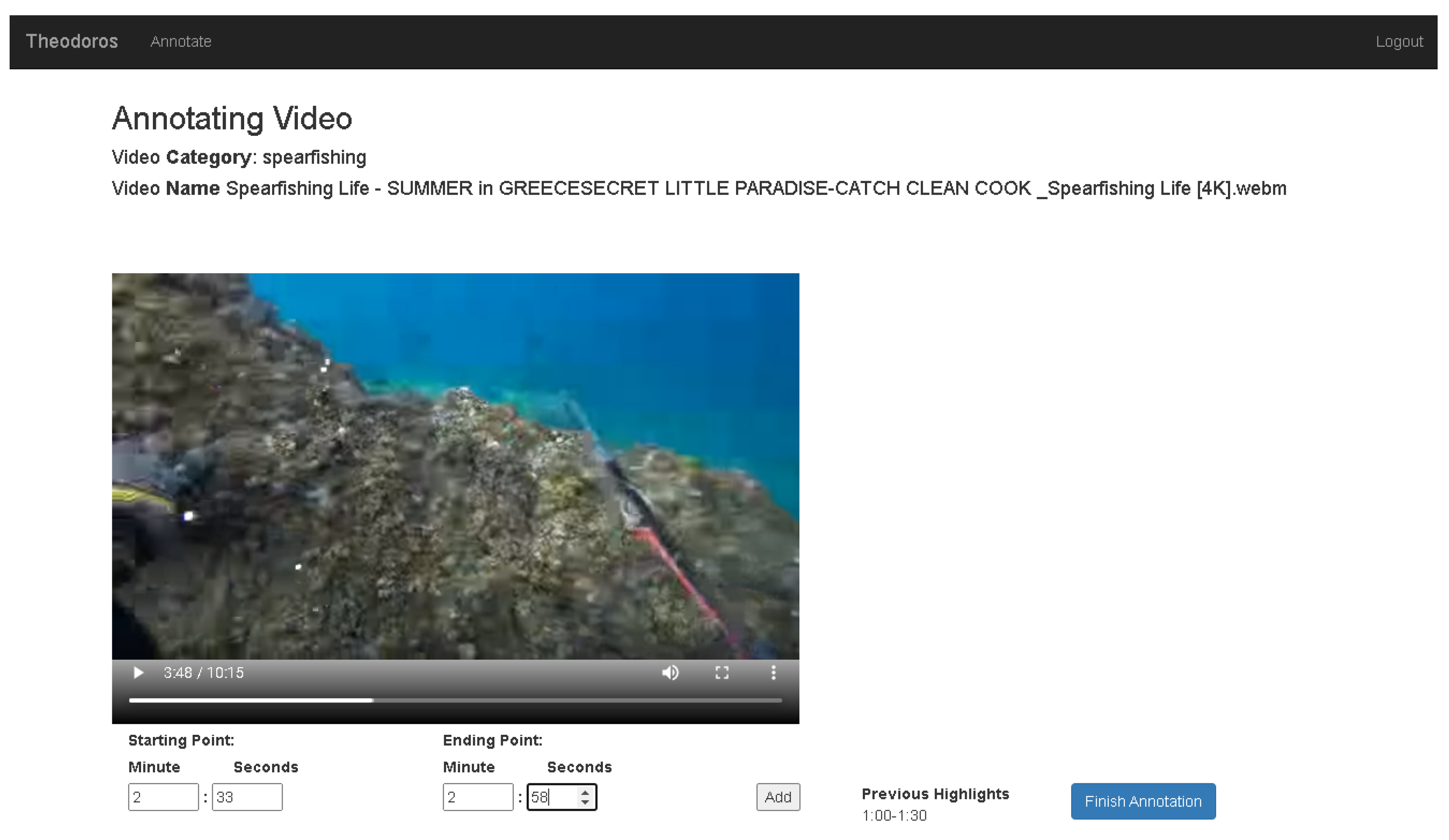
4.2. Annotation Procedure
4.3. Annotation Data Aggregation
5. Results
5.1. Evaluation Metrics
- Precision for the positive class (“informative”): this measures the percentage of 1-s video segments classified (detected) as informative” that are, indeed, informative according to the ground truth.
- Recall for the positive class: the percentage of 1-s video segments that have been annotated as “informative” and are correctly detected as such.
- F1 score (macro averaged), that is, the macro average of the individual class-specific F1 scores. F1 score is the harmonic mean of recall and precision, per class; therefore the F1 macro average provides an overall normalized metric for the general classification performance.
- Overall accuracy: the overall percentage of the correctly classifier (negative or positive) 1-s segments.
- AUC: the area under the ROC curve is used as a more general metric of the classifier to function at various “operation points”, corresponding to different thresholds applied on the posterior outputs of the positive class.
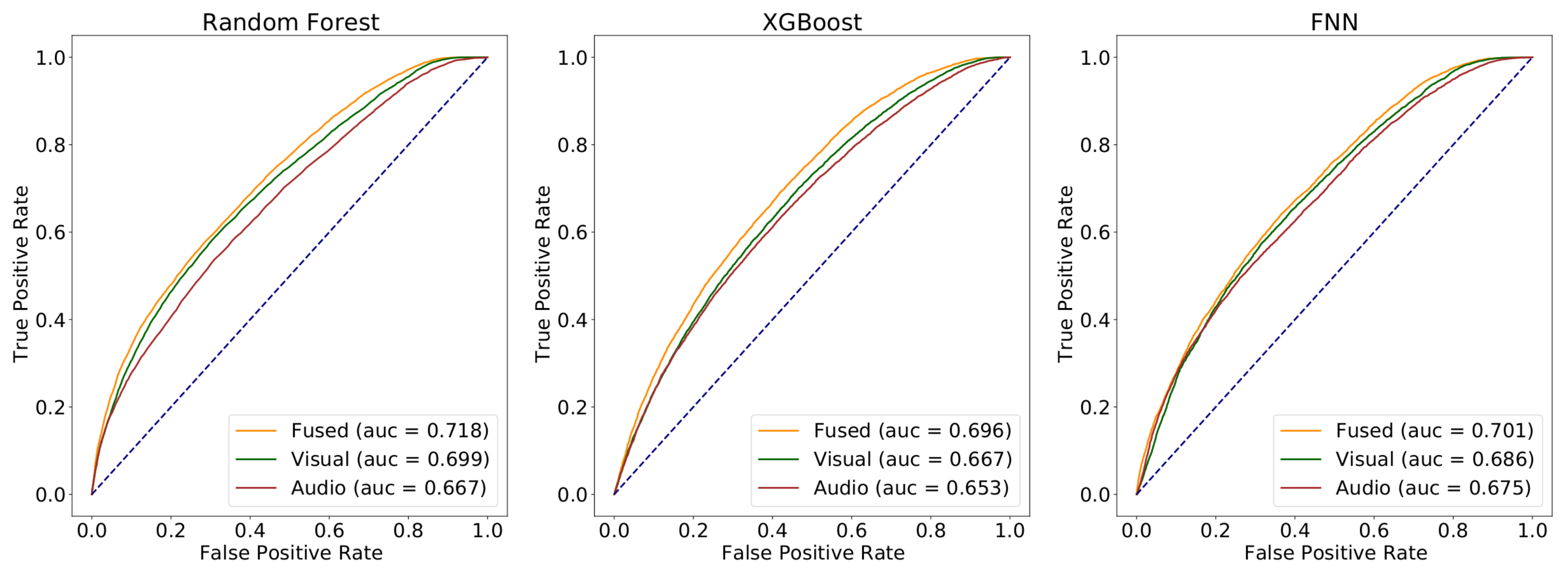
5.2. Results
- Random forest achieves the best classification performance in terms of AUC for the binary classification task in all three modalities (visual, audio and multimodal).
- Visual-based classifier is always almost relatively better than audio.
- Fusion-based classifier is always almost relatively better than visual, which indicates that the two modalities both contain useful information for the summarization task.
- The final performance of the binary classifier after applying the proposed post-processing technique reaches almost precision and recall rate at a 1-second segment level.
- Motion-related features seem to be among the most important with regards to the classifiers’ decision, along with some spectral domain audio features and color intensity and saturation features.
6. Conclusions & Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| UAVs | Unnamed Aired Vehicles |
| CNN | Convolutional Neural Network |
| LSTM | Long Short Term Memory |
| GAN | Generative Adversarial Network |
| MFCCs | Mel Frequency Cepstral Coefficients |
| RGB | Red Green Blue |
| VAT | Video Annotator Tool |
| Log Reg | Logistic Regression |
| KNN | k-Nearest Neighbors |
| XGBoost | eXtreme Gradient Boosting |
| FNN | Fully Connected Neural Network |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under Curve |
| RFE | Recursive Feature Elimination |
References
- YouTube in Numbers. Available online: https://www.youtube.com/intl/en-GB/about/press/ (accessed on 20 February 2021).
- Furini, M.; Ghini, V. An audio-video summarization scheme based on audio and video analysis. In Proceedings of the IEEE CCNC, Las Vegas, Nevada, USA, 8–10 January 2006. [Google Scholar]
- Money, A.G.; Agius, H. Video summarisation: A conceptual framework and survey of the state of the art. J. Vis. Commun. Image Represent. 2008, 19, 121–143. [Google Scholar] [CrossRef]
- Xiong, Z.; Radhakrishnan, R.; Divakaran, A.; Yong-Rui, Z.; Huang, T.S. A Unified Framework for Video Summarization, Browsing & Retrieval: With Applications to Consumer and Surveillance Video; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Lai, P.K.; Décombas, M.; Moutet, K.; Laganière, R. Video summarization of surveillance cameras. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 286–294. [Google Scholar]
- Priya, G.L.; Domnic, S. Medical Video Summarization using Central Tendency-Based Shot Boundary Detection. Int. J. Comput. Vis. Image Process. 2013, 3, 5565. [Google Scholar] [CrossRef][Green Version]
- Trinh, H.; Li, J.; Miyazawa, S.; Moreno, J.; Pankanti, S. Efficient UAV video event summarization. In Proceedings of the 21st IEEE International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2226–2229. [Google Scholar]
- Spyrou, E.; Tolias, G.; Mylonas, P.; Avrithis, Y. Concept detection and keyframe extraction using a visual thesaurus. Multimed. Tools Appl. 2009, 41, 337–373. [Google Scholar] [CrossRef]
- Li, Y.; Merialdo, B.; Rouvier, M.; Linares, G. Static and dynamic video summaries. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1573–1576. [Google Scholar]
- Lienhart, R.; Pfeiffer, S.; Effelsberg, W. The MoCA workbench: Support for creativity in movie content analysis. In Proceedings of the Third IEEE International Conference on Multimedia Computing and Systems, Hiroshima, Japan, 17–23 June 1996; pp. 314–321. [Google Scholar]
- Chen, B.C.; Chen, Y.Y.; Chen, F. Video to Text Summary: Joint Video Summarization and Captioning with Recurrent Neural Networks. In Proceedings of the BMVC, London, UK, 4–7 September 2017. [Google Scholar]
- Smith, M.A.; Kanade, T. Video Skimming for Quick Browsing Based on Audio and Image Characterization; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 1995. [Google Scholar]
- Sen, D.; Raman, B. Video skimming: Taxonomy and comprehensive survey. arXiv 2019, arXiv:1909.12948. [Google Scholar]
- Zhou, K.; Qiao, Y.; Xiang, T. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 2–9 February 2018; Volume 32. [Google Scholar]
- Zhang, K.; Chao, W.L.; Sha, F.; Grauman, K. Video summarization with long short-term memory. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 766–782. [Google Scholar]
- Evangelopoulos, G.; Zlatintsi, A.; Potamianos, A.; Maragos, P.; Rapantzikos, K.; Skoumas, G.; Avrithis, Y. Multimodal saliency and fusion for movie summarization based on aural, visual, and textual attention. IEEE Trans. Multimed. 2013, 15, 1553–1568. [Google Scholar] [CrossRef]
- Wei, H.; Ni, B.; Yan, Y.; Yu, H.; Yang, X.; Yao, C. Video summarization via semantic attended networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 2–9 February 2018; Volume 32. [Google Scholar]
- Grundmann, M.; Kwatra, V.; Han, M.; Essa, I. Efficient hierarchical graph-based video segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2141–2148. [Google Scholar]
- Pantazis, G.; Dimas, G.; Iakovidis, D.K. SalSum: Saliency-based Video Summarization using Generative Adversarial Networks. arXiv 2020, arXiv:2011.10432. [Google Scholar]
- Jacob, H.; Pádua, F.L.; Lacerda, A.; Pereira, A.C. A video summarization approach based on the emulation of bottom-up mechanisms of visual attention. J. Intell. Inf. Syst. 2017, 49, 193–211. [Google Scholar] [CrossRef]
- Cirne, M.V.M.; Pedrini, H. VISCOM: A robust video summarization approach using color co-occurrence matrices. Multimed. Tools Appl. 2018, 77, 857–875. [Google Scholar] [CrossRef]
- Rochan, M.; Ye, L.; Wang, Y. Video summarization using fully convolutional sequence networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 347–363. [Google Scholar]
- Otani, M.; Nakashima, Y.; Rahtu, E.; Heikkilä, J.; Yokoya, N. Video summarization using deep semantic features. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; p. 361377. [Google Scholar]
- Wu, J.; Zhong, S.H.; Jiang, J.; Yang, Y. A novel clustering method for static video summarization. Multimed. Tools Appl. 2017, 76, 9625–9641. [Google Scholar] [CrossRef]
- Potapov, D.; Douze, M.; Harchaoui, Z.; Schmid, C. Category-specific video summarization. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 540–555. [Google Scholar]
- Ma, Y.F.; Lu, L.; Zhang, H.J.; Li, M. A user attention model for video summarization. In Proceedings of the Tenth ACM International Conference on Multimedia, Juan les Pins, France, 1–6 December 2002; pp. 533–542. [Google Scholar]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial lstm networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 202–211. [Google Scholar]
- Song, Y.; Vallmitjana, J.; Stent, A.; Jaimes, A. Tvsum: Summarizing web videos using titles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5179–5187. [Google Scholar]
- Gygli, M.; Grabner, H.; Riemenschneider, H.; Van Gool, L. Creating summaries from user videos. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 505–520. [Google Scholar]
- Lee, Y.J.; Ghosh, J.; Grauman, K. Discovering important people and objects for egocentric video summarization. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1346–1353. [Google Scholar]
- De Avila, S.E.F.; Lopes, A.P.B.; da Luz, A., Jr.; de Albuquerque Araújo, A. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recognit. Lett. 2011, 32, 56–68. [Google Scholar] [CrossRef]
- Alías, F.; Socoró, J.C.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Giannakopoulos, T. pyaudioanalysis: An open-source python library for audio signal analysis. PLoS ONE 2015, 10, e0144610. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI ’81), Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bottou, L.; Lin, C.J. Support vector machine solvers. Large Scale Kernel Mach. 2007, 3, 301–320. [Google Scholar]
- List, N.; Simon, H.U. SVM-optimization and steepest-descent line search. In Proceedings of the 22nd Annual Conference on Computational Learning Theory, Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Name | Description |
|---|---|---|
| 1 | Zero Crossing Rate | Rate of sign-changes of the frame |
| 2 | Energy | Sum of squares of the signal values, normalized by frame length |
| 3 | Entropy of Energy | Entropy of sub-frames’ normalized energies. A measure of abrupt changes |
| 4 | Spectral Centroid | Spectrum’s center of gravity |
| 5 | Spectral Spread | Spectrum’s second central moment of the spectrum |
| 6 | Spectral Entropy | Entropy of the normalized spectral energies for a set of sub-frames |
| 7 | Spectral Flux | Squared difference between the normalized magnitudes of the spectra of the two successive frames |
| 8 | Spectral Rolloff | The frequency below which of the magnitude distribution of the spectrum is concentrated. |
| 9–21 | MFCCs | Mel Frequency Cepstral Coefficients: a cepstral representation with mel-scaled frequency bands |
| 22–33 | Chroma Vector | A 12-element representation of the spectral energy in 12 equal-tempered pitch classes of western-type music |
| 34 | Chroma Deviation | Standard deviation of the 12 chroma coefficients. |
| Dataset | Total Videos | Total Duration | Av. Dur. | Min Dur. | Max Dur. |
|---|---|---|---|---|---|
| Raw Dataset | 409 | ~56.3 h | ~8.25 m | 15 s | 15 m |
| Final Dataset | 336 | ~44.2 h | ~8 m | 15 s | ~15 m |
| Subset | Total Videos | Total Samples |
|---|---|---|
| Training Dataset | 268 | 127,972 |
| Test Dataset | 68 | 31,113 |
| Classifier | ROC AUC | F1 Macro Averaged | ||||
|---|---|---|---|---|---|---|
| Audio | Visual | Fused | Audio | Visual | Fused | |
| Random | 49.7% | 47.6% | ||||
| Naive Bayes | 59.5% | 64% | 63.4% | 51.7% | 48.3% | 51.6% |
| KNN | 59.3% | 60.7% | 62.6% | 54.6% | 56.3% | 57.7% |
| Log Reg | 62.8% | 67.2% | 67.4% | 41.4% | 44.6% | 49.4% |
| Decision Tree | 60.6% | 66.3% | 66.5% | 41.8% | 45.6% | 45.6% |
| Random Forest | 66.7% | 69.8% | 71.8% | 57.8% | 60.4% | 60.6% |
| XGBOOST | 65.3% | 66.8% | 69.6% | 59.8% | 60.4% | 62.3% |
| FNN | 67.45% | 68.6% | 70.14% | 62.12% | 64.4% | 66.37% |
| Thresholds (med ()-hard ()) | Precision | Recall | f1 Macro | Accuracy |
|---|---|---|---|---|
| no | 42.2% | 69.9% | 60.6% | 62% |
| 3-3 | 43.7% | 69.7% | 62% | 63.8% |
| 3-5 | 44.9% | 66.9% | 63% | 65.3% |
| 5-3 | 43.4% | 70.8% | 61.8% | 63.4% |
| 5-5 | 44.2% | 69.9% | 62.5% | 64.3% |
| Feature Name | Description | Modality |
|---|---|---|
| spectral_flux_mean | Mean spectral Flux value | audio |
| delta spectral_spread_std | Delta spectral spread standard deviation | audio |
| delta mfcc_5_std | Delta MFCC 5 standard deviation | audio |
| hist_v0 | 1st bin of grayscaled value | visual |
| hist_v3 | 4th bin of grayscaled value | visual |
| hist_s1 | 2nd bin of saturation value | visual |
| hist_s5 | 6th bin of saturation value | visual |
| frame_value_diff | Frame value difference | visual |
| mag_std | Magnitude flow standard deviation | visual |
| shot_durations | Current shot duration | visual |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Psallidas, T.; Koromilas, P.; Giannakopoulos, T.; Spyrou, E. Multimodal Summarization of User-Generated Videos. Appl. Sci. 2021, 11, 5260. https://doi.org/10.3390/app11115260
Psallidas T, Koromilas P, Giannakopoulos T, Spyrou E. Multimodal Summarization of User-Generated Videos. Applied Sciences. 2021; 11(11):5260. https://doi.org/10.3390/app11115260
Chicago/Turabian StylePsallidas, Theodoros, Panagiotis Koromilas, Theodoros Giannakopoulos, and Evaggelos Spyrou. 2021. "Multimodal Summarization of User-Generated Videos" Applied Sciences 11, no. 11: 5260. https://doi.org/10.3390/app11115260
APA StylePsallidas, T., Koromilas, P., Giannakopoulos, T., & Spyrou, E. (2021). Multimodal Summarization of User-Generated Videos. Applied Sciences, 11(11), 5260. https://doi.org/10.3390/app11115260