
A Deep Belief Network Classification Approach for Automatic Diacritization of Arabic Text




Abstract
:1. Introduction
2. Literature Review
2.1. Rule-Based Systems
2.2. Statistical Systems
2.3. Hybrid Systems
3. Preliminaries
3.1. Artificial Neural Networks and Deep Architectures
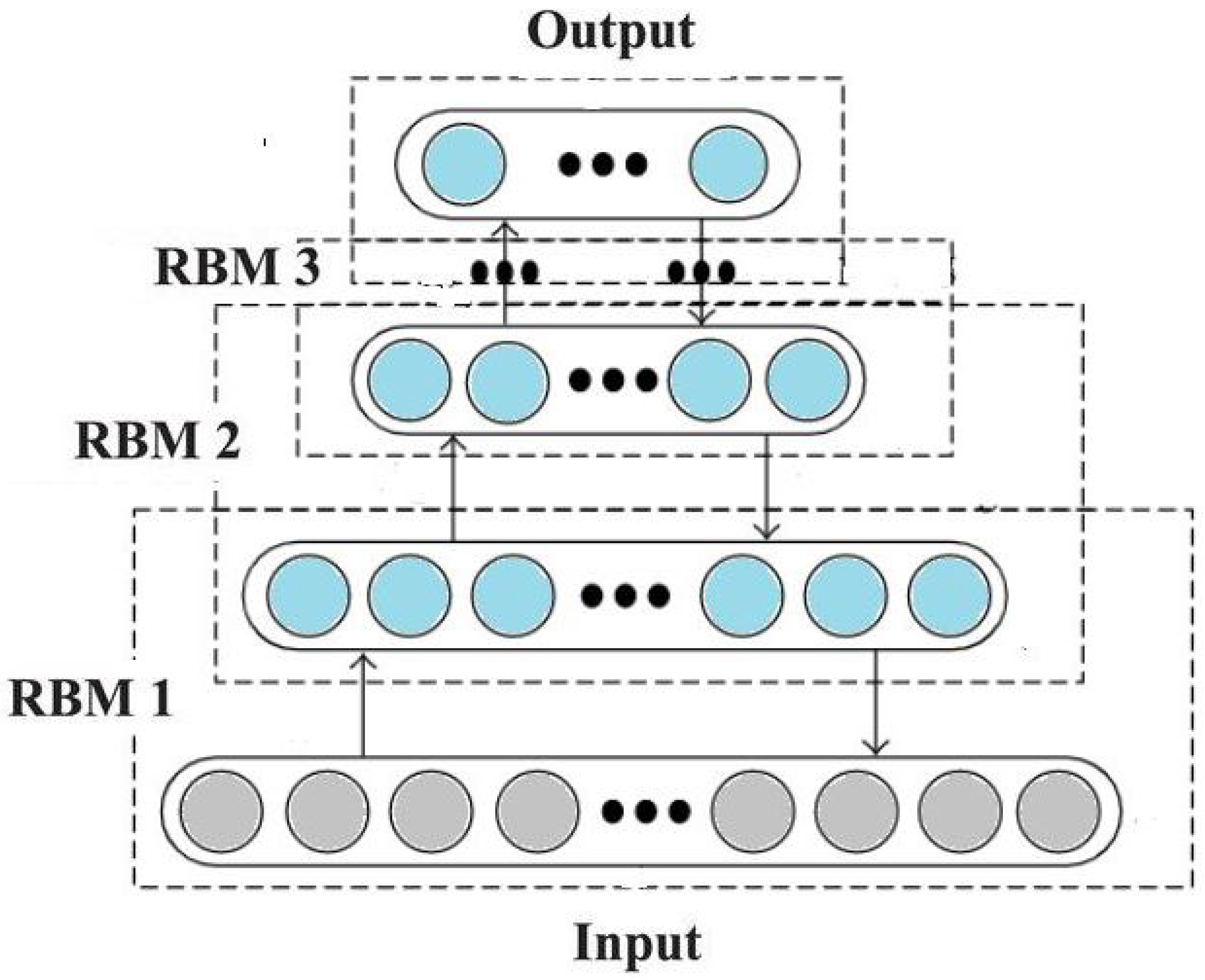
3.2. Deep Belief Network (DBN)
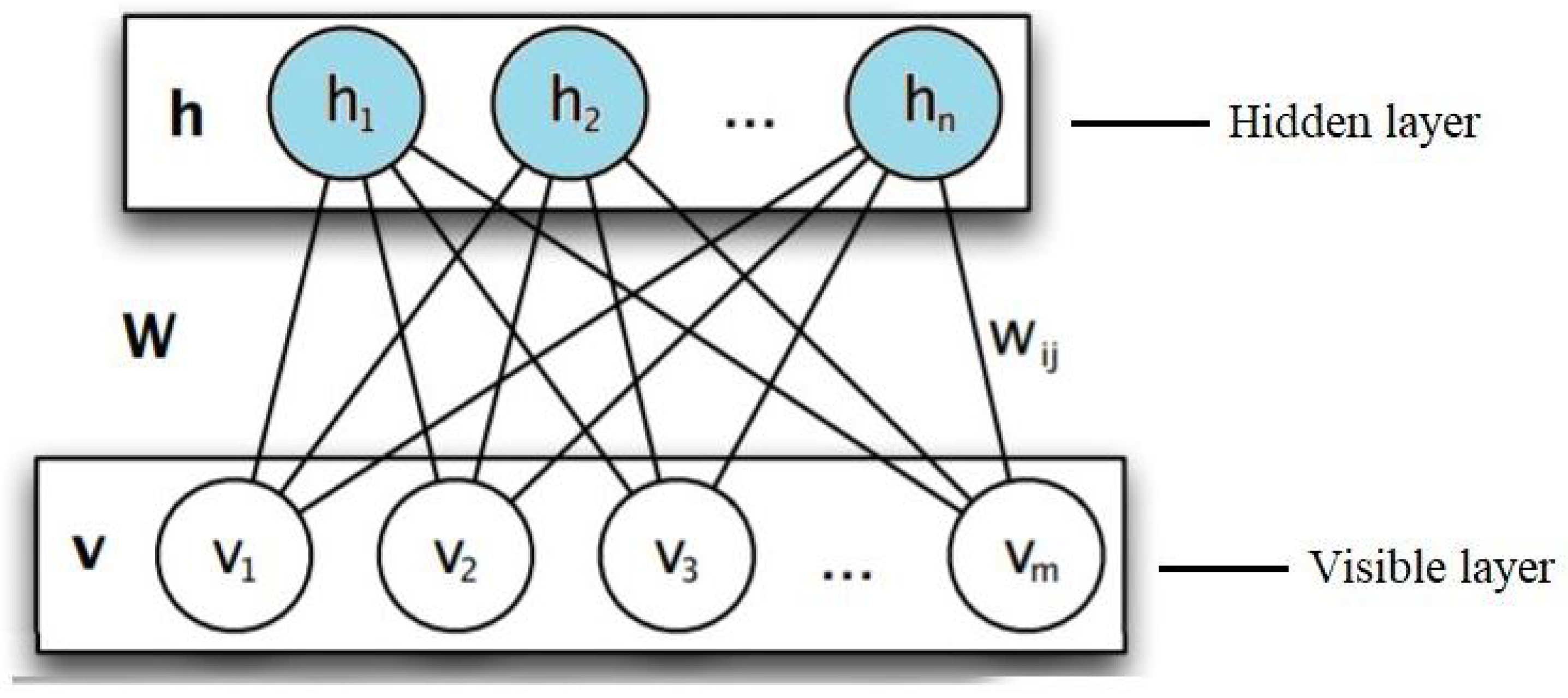
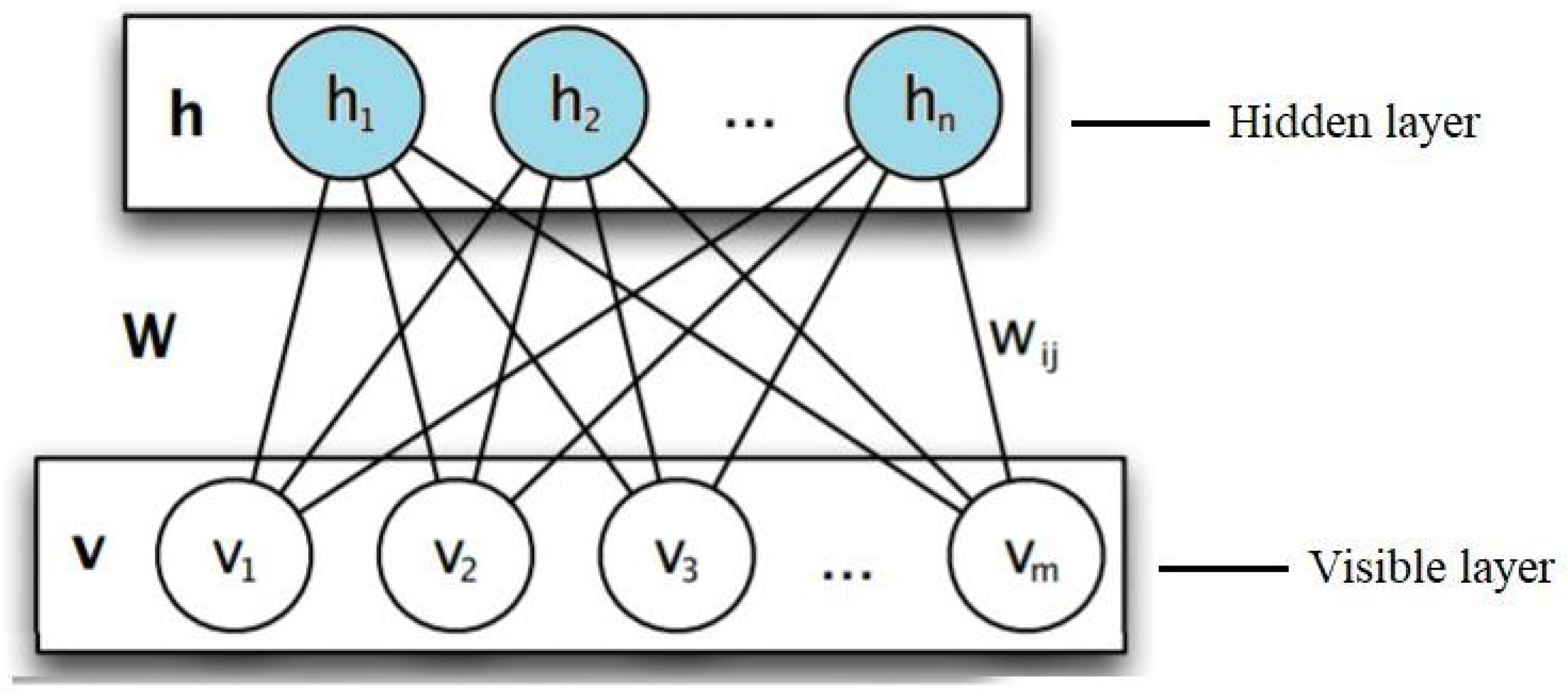
3.2.1. Restricted Boltzmann Machine (RBM)
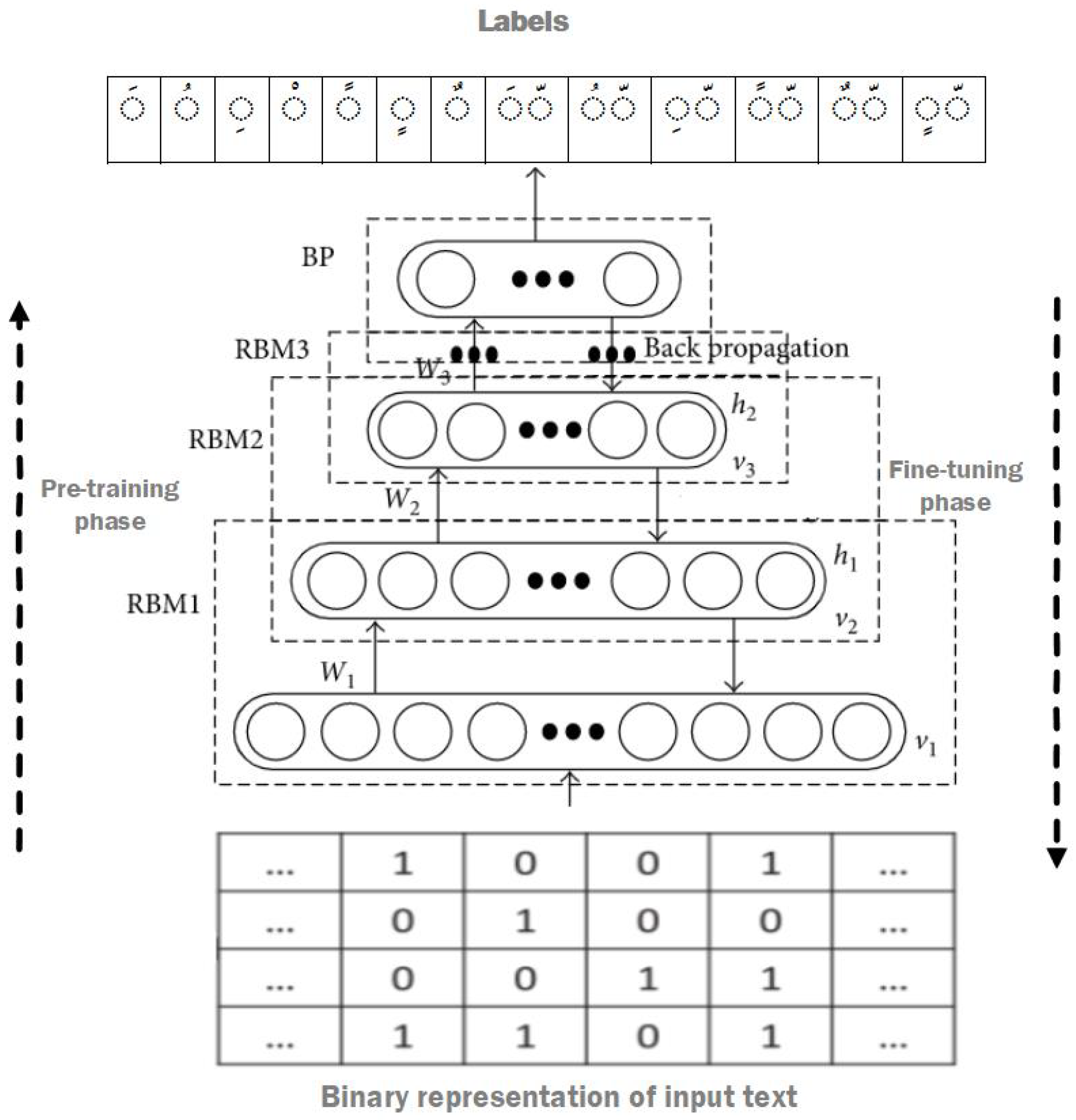
3.2.2. DBN Structure
4. Dataset
5. Methodology
5.1. Data Cleaning and Preprocessing
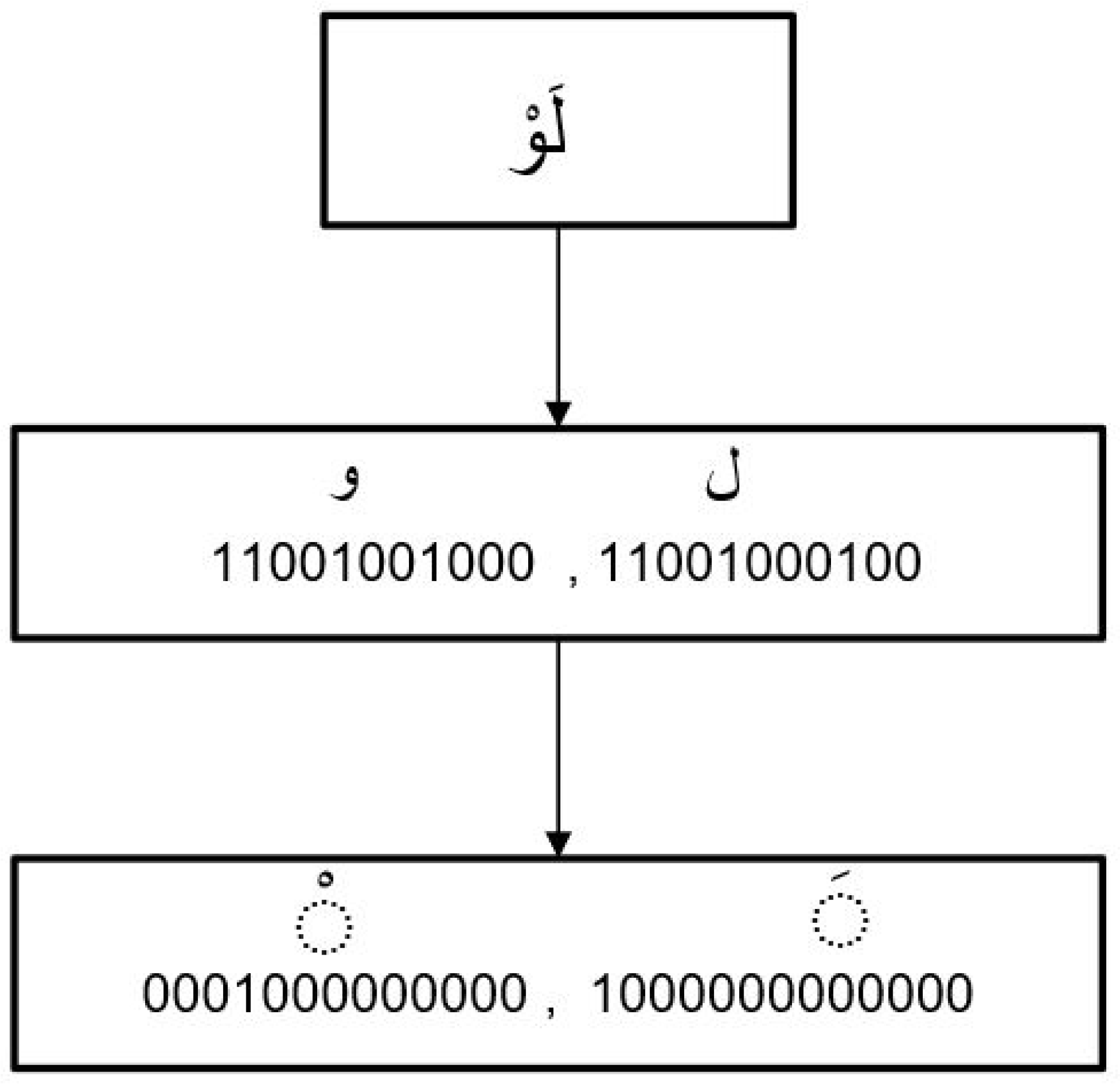
5.2. Data Encoding

5.3. Data Oversampling
5.4. Training with DBN
5.4.1. Automatic Diacritization Using DBN
5.4.2. Rectified Linear Unit (ReLU) Activation Function
5.5. Evaluation Metrics
- Diacritization Error Rate (DER): which is the ration of characters with incorrectly restored diacritics. DER can be calculated as follows:where is the number of letters assigned correctly by the system, and is the number of diacritized letters in the gold standard text.
- Word Error Rate (WER): the percentage of incorrectly diacritized white-space delimited words. At least one letter in the word must have a diacritization error so that it can be counted as incorrect.where is the number of words fully and correctly diacritized by the system, and is the number of diacritized words in the gold standard text.
6. Experiments and Results
6.1. Experimental Settings
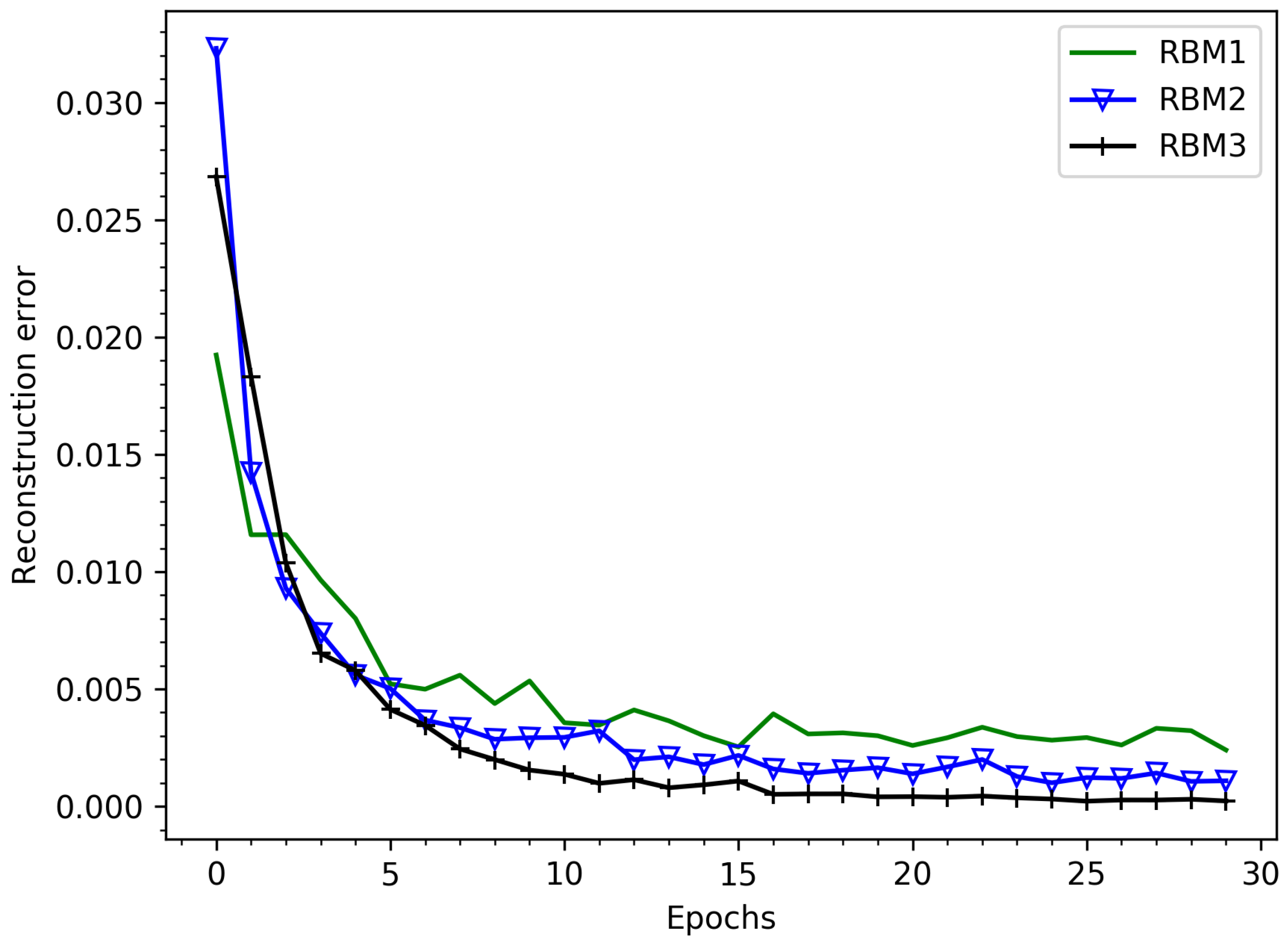
6.2. RBM Structure
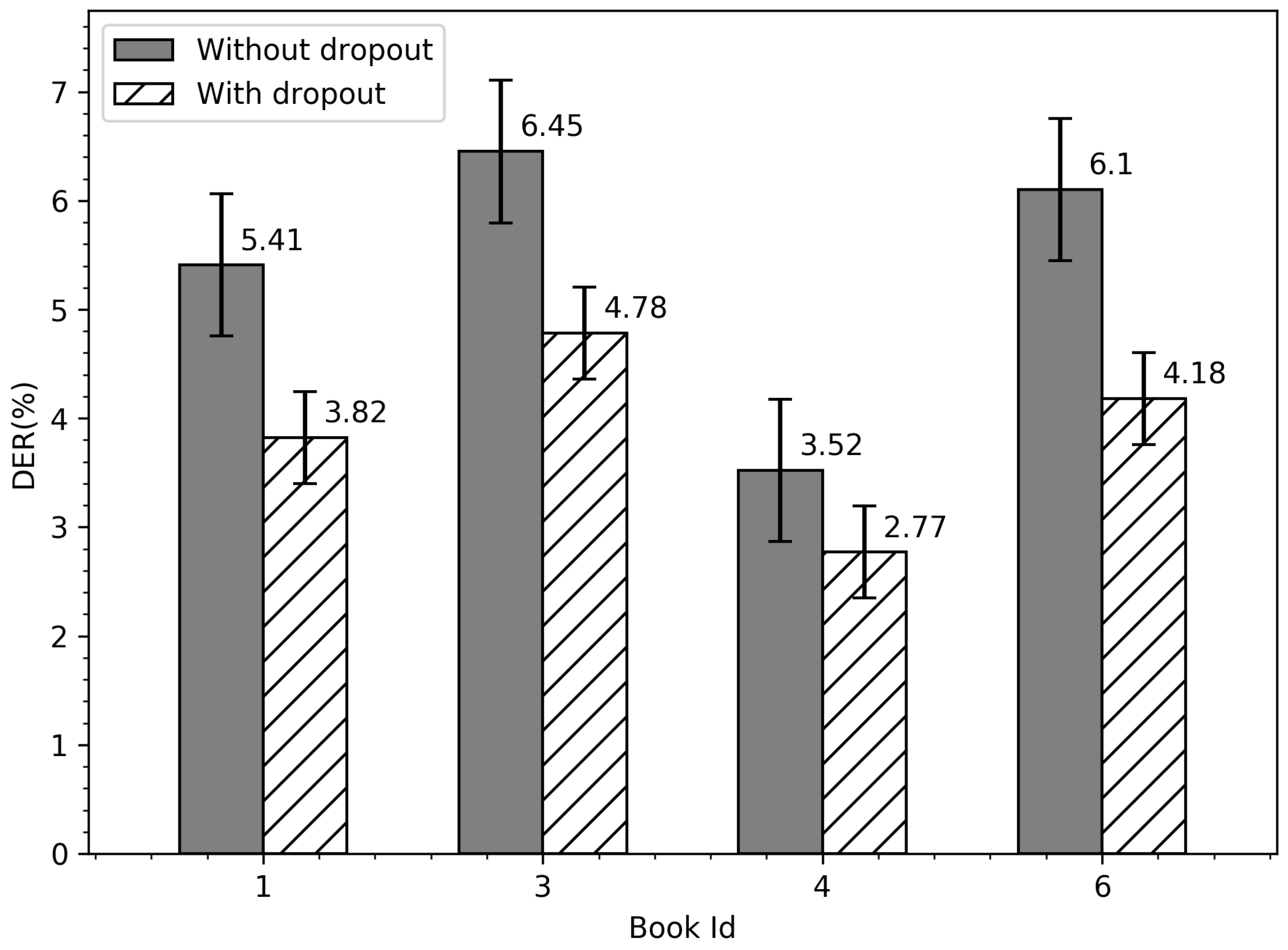
6.3. Weight Noise Regularization
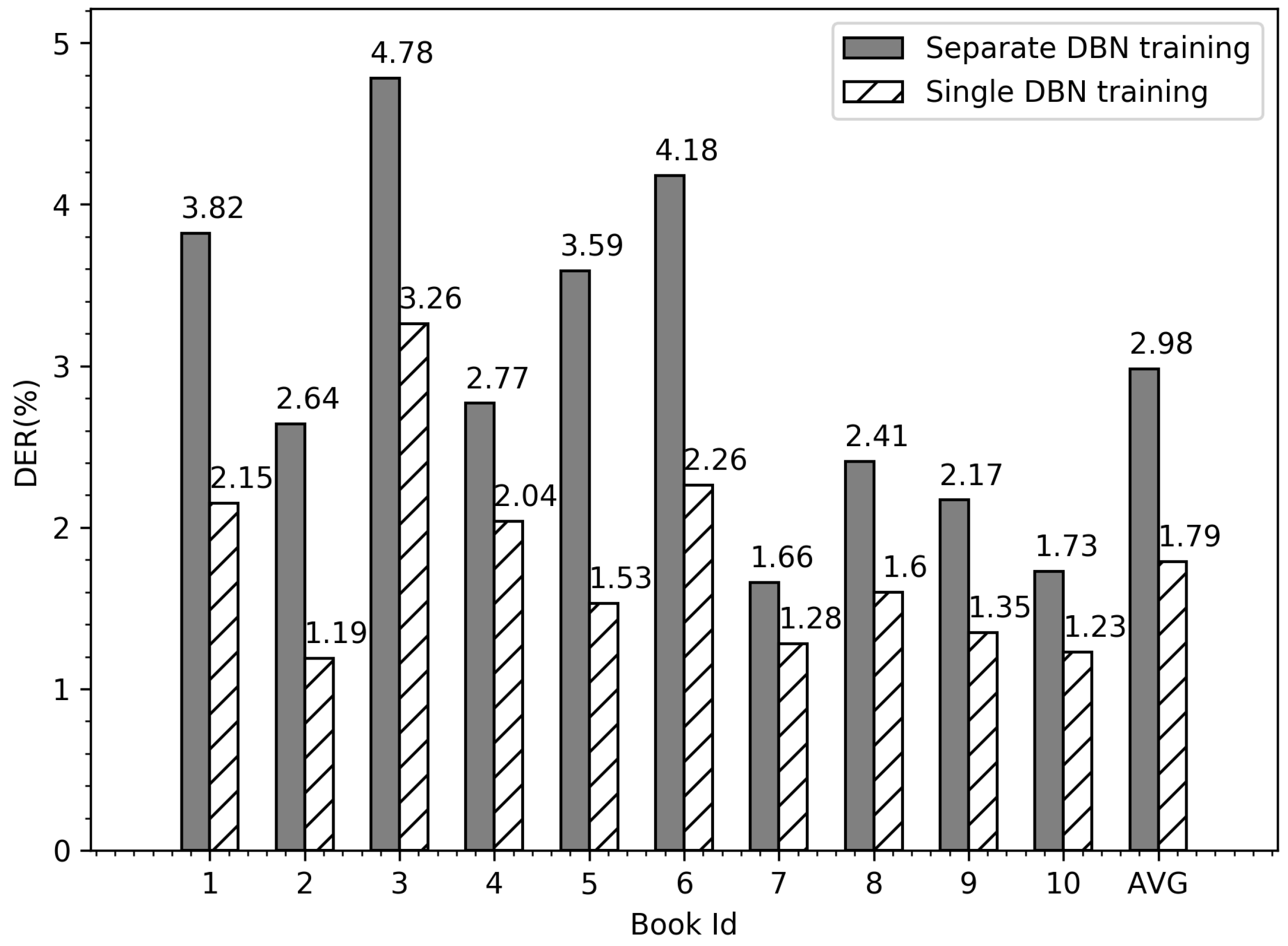
6.4. Datasets Training
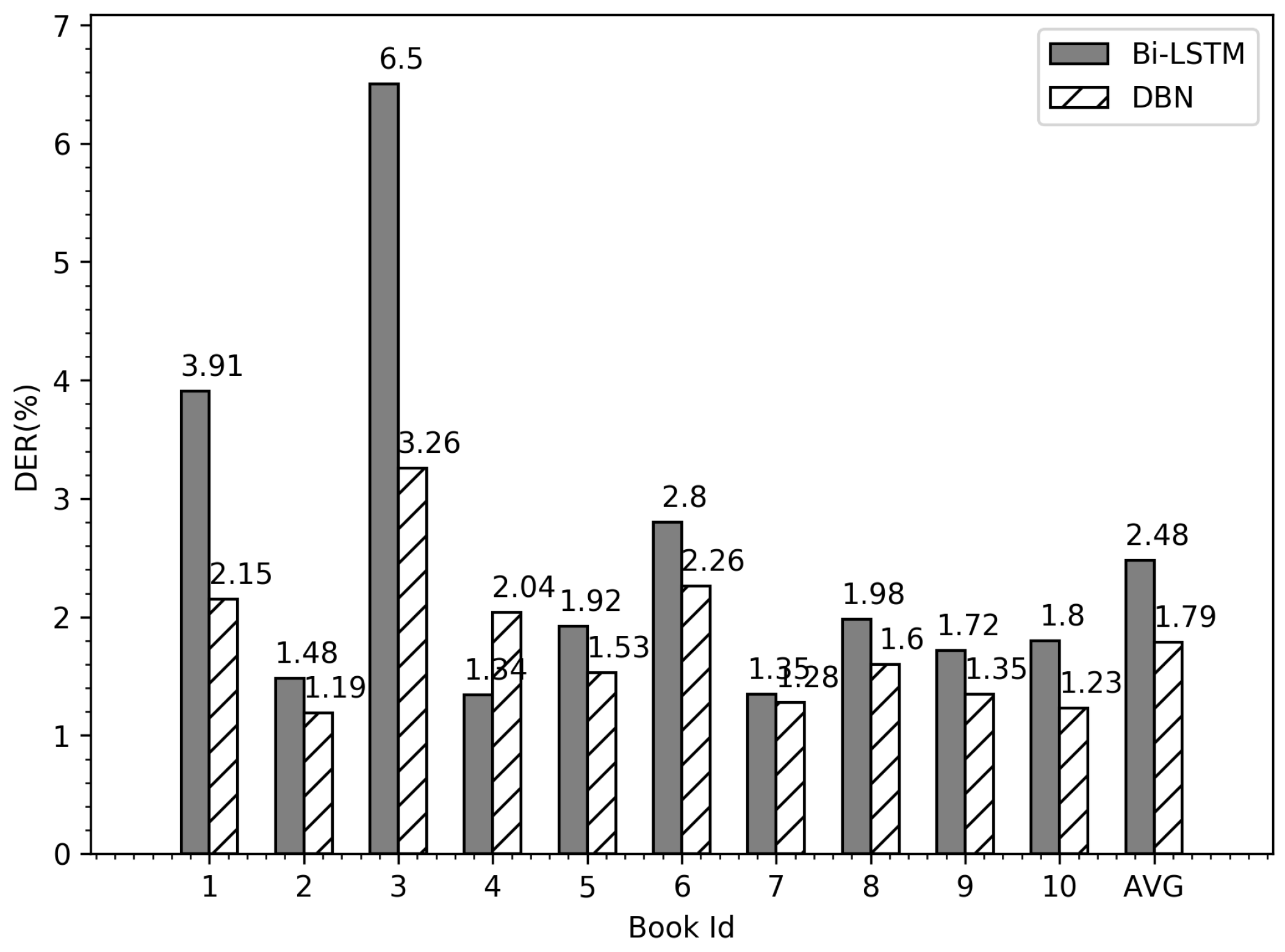
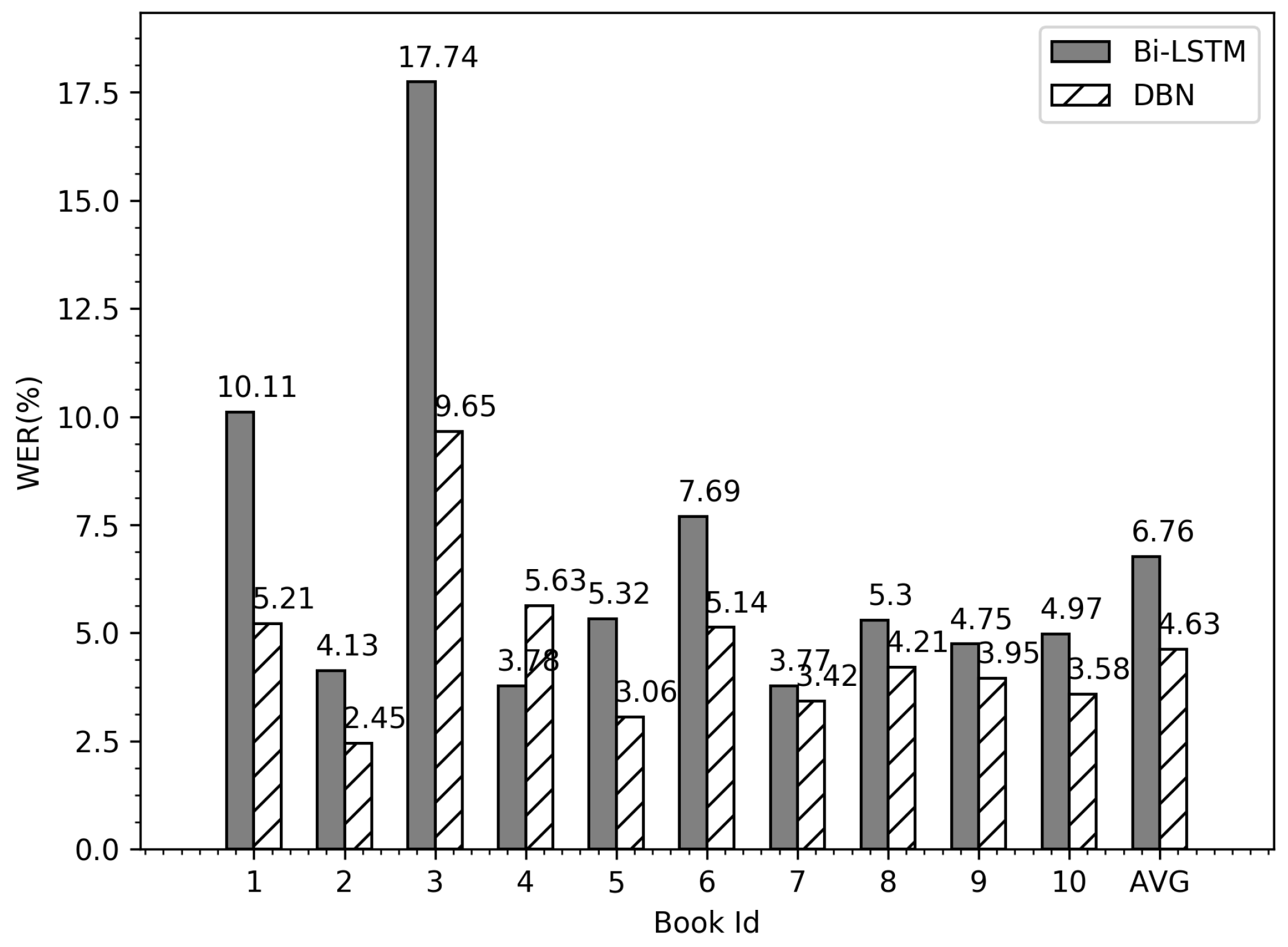
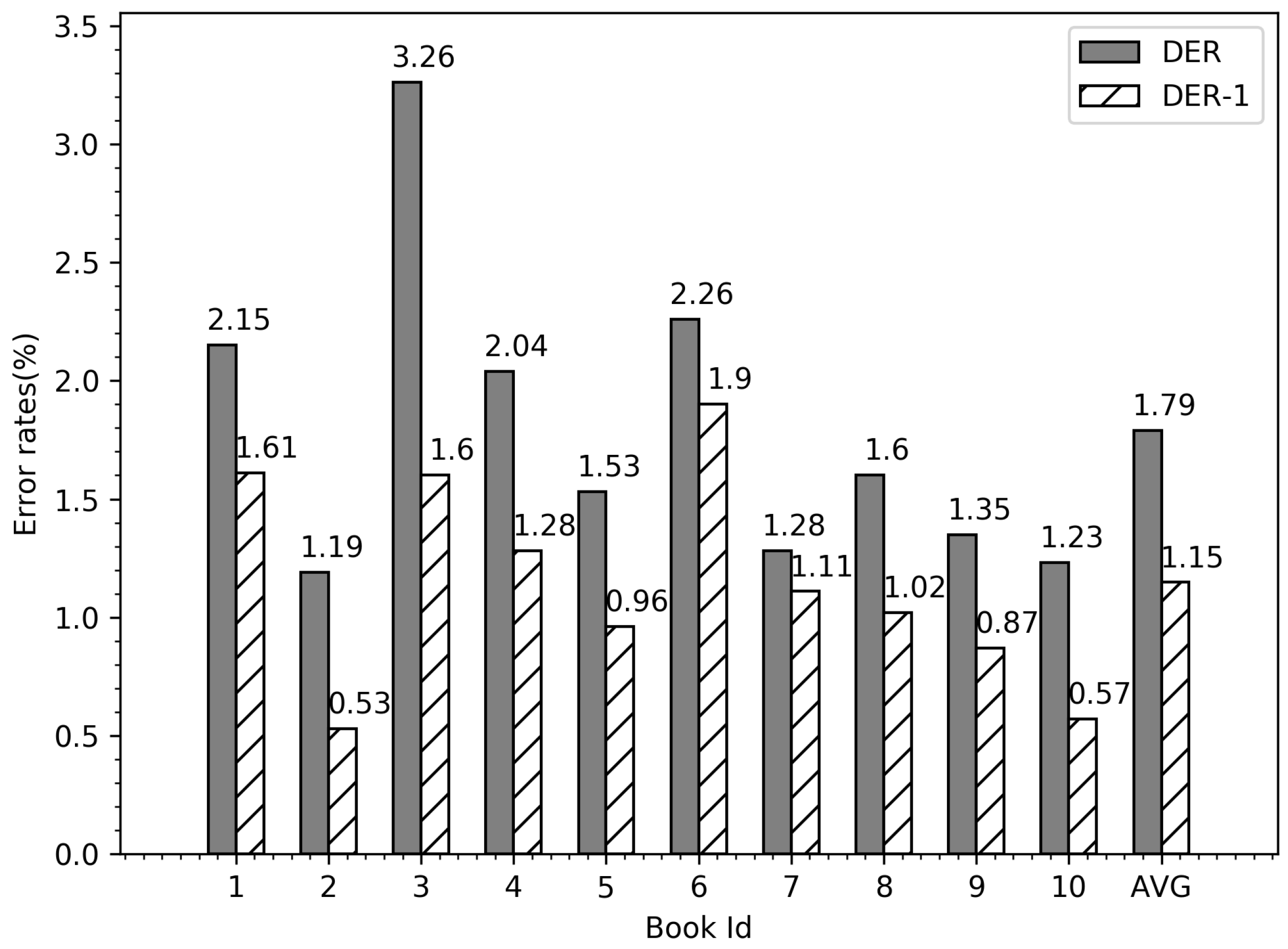
6.5. Comparisons with Literature
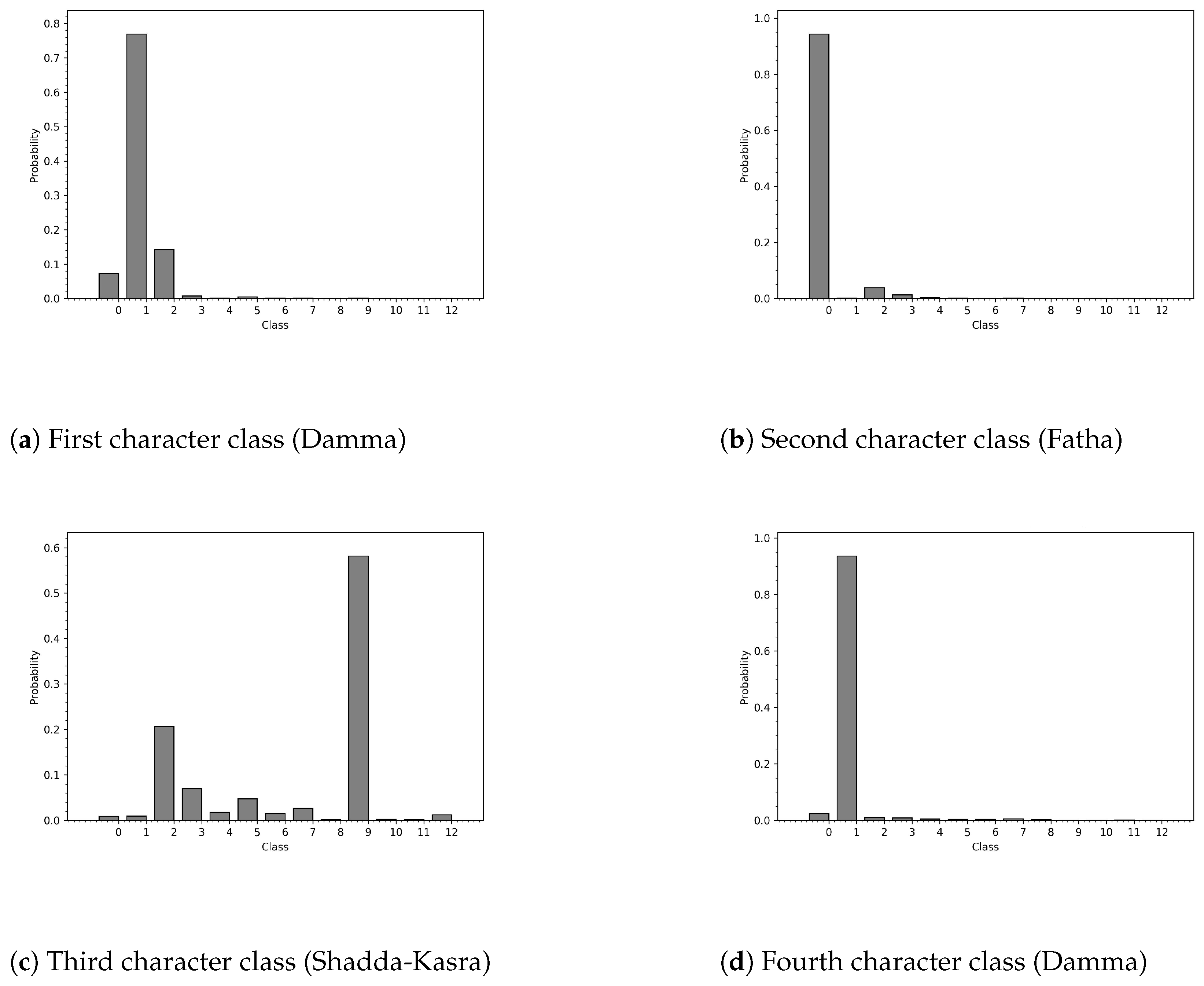
6.6. Probability Distribution of Diacritics
6.7. Children Stories: A Novel Corpus of Arabic Diacritized Text
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Albirini, A. Modern Arabic Sociolinguistics: Diglossia, Variation, Codeswitching, Attitudes and Identity; Routledge: London, UK, 2016. [Google Scholar]
- Farghaly, A.; Shaalan, K. Arabic natural language processing: Challenges and solutions. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2009, 8, 1–22. [Google Scholar] [CrossRef]
- Freihat, A.A.; Abbas, M.; Bella, G.; Giunchiglia, F. Towards an Optimal Solution to Lemmatization in Arabic. Procedia Comput. Sci. 2018, 142, 132–140. [Google Scholar] [CrossRef]
- Said, A.; El-Sharqwi, M.; Chalabi, A.; Kamal, E. A hybrid approach for Arabic diacritization. In International Conference on Application of Natural Language to Information Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 53–64. [Google Scholar]
- Hamed, O.; Zesch, T. A Survey and Comparative Study of Arabic Diacritization Tools. J. Lang. Technol. Comput. Linguist. 2017, 32, 27–47. [Google Scholar]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Saad, M.K.; Ashour, W.M. Arabic morphological tools for text mining. In Proceedings of the Corpora, 6th ArchEng International Symposiums, EEECS’10 the 6th International Symposium on Electrical and Electronics Engineering and Computer Science, Lefke, Cyprus, 25–26 November 2010; Volume 18. [Google Scholar]
- Alsaleem, S. Automated Arabic Text Categorization Using SVM and NB. Int. Arab. J. e Technol. 2011, 2, 124–128. [Google Scholar]
- Belkebir, R.; Guessoum, A. A supervised approach to arabic text summarization using adaboost. In New Contributions in Information Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2015; pp. 227–236. [Google Scholar]
- Almuhareb, A.; Alsanie, W.; Al-Thubaity, A. Arabic word segmentation with long short-term memory neural networks and word embedding. IEEE Access 2019, 7, 12879–12887. [Google Scholar] [CrossRef]
- Duwairi, R.M.; Qarqaz, I. Arabic sentiment analysis using supervised classification. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 August 2014; pp. 579–583. [Google Scholar]
- Azmi, A.M.; Almajed, R.S. A survey of automatic Arabic diacritization techniques. Nat. Lang. Eng. 2015, 21, 477. [Google Scholar] [CrossRef]
- Shaalan, K.; Bakr, H.M.A.; Ziedan, I. A hybrid approach for building Arabic diacritizer. In Proceedings of the EACL 2009 Workshop on Computational Approaches to Semitic Languages, Athens, Greece, 31 March 2009; pp. 27–35. [Google Scholar]
- Zitouni, I.; Sorensen, J.; Sarikaya, R. Maximum entropy based restoration of Arabic diacritics. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 577–584. [Google Scholar]
- Diab, M.; Ghoneim, M.; Habash, N. Arabic diacritization in the context of statistical machine translation. In Proceedings of the MT-Summit, Copenhagen, Denmark, 10–14 September2007. [Google Scholar]
- Rubi, C.R. A review: Speech recognition with deep learning methods. Int. J. Comput. Sci. Mob. Comput. 2015, 4, 1017–1024. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Abbad, H.; Xiong, S. Multi-components System for Automatic Arabic Diacritization. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2020; pp. 341–355. [Google Scholar]
- Maamouri, M.; Bies, A.; Kulick, S. Diacritization: A challenge to Arabic treebank annotation and parsing. In Proceedings of the Conference of the Machine Translation SIG of the British Computer Society, London, UK, 23 October 2006; pp. 35–47. [Google Scholar]
- Rashwan, M.A.; Al-Badrashiny, M.A.; Attia, M.; Abdou, S.M.; Rafea, A. A stochastic Arabic diacritizer based on a hybrid of factorized and unfactorized textual features. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 166–175. [Google Scholar] [CrossRef]
- Shaalan, K. Rule-based approach in Arabic natural language processing. Int. J. Inf. Commun. Technol. (IJICT) 2010, 3, 11–19. [Google Scholar]
- Fashwan, A.; Alansary, S. A Rule Based Method for Adding Case Ending Diacritics for Modern Standard Arabic Texts. Available online: https://www.researchgate.net/publication/322223483_A_Rule_Based_System_for_Detecting_the_Syntactic_Diacritics_in_Modern_Standard_Arabic_Texts (accessed on 10 April 2021).
- Metwally, A.S.; Rashwan, M.A.; Atiya, A.F. A multi-layered approach for Arabic text diacritization. In Proceedings of the 2016 IEEE International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 5–7 July 2016; pp. 389–393. [Google Scholar]
- Alansary, S. Alserag: An automatic diacritization system for arabic. In Intelligent Natural Language Processing: Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 523–543. [Google Scholar]
- Elshafei, M.; Al-Muhtaseb, H.; Alghamdi, M. Statistical Methods for Automatic Diacritization of Arabic Text. Available online: https://www.researchgate.net/publication/236115959_Statistical_Methods_for_Automatic_diacritization_of_Arabic_text (accessed on 10 April 2021).
- Hifny, Y. Smoothing techniques for Arabic diacritics restoration. Proc. Conf. Lang. Eng. 2012, 1, 6–12. [Google Scholar]
- Nelken, R.; Shieber, S.M. Arabic diacritization using weighted finite-state transducers. In Proceedings of the ACL Workshop on Computational Approaches to Semitic Languages, Ann Arbor, MI, USA, 29 June 2005; pp. 79–86. [Google Scholar]
- Darwish, K.; Mubarak, H.; Abdelali, A. Arabic diacritization: Stats, rules, and hacks. In Proceedings of the Third Arabic Natural Language Processing Workshop, Valencia, Spain, 3 April 2017; pp. 9–17. [Google Scholar]
- Mijlad, A.; Younoussi, Y.E. Arabic Text Diacritization: Overview and Solution. pp. 1–7. Available online: https://dl.acm.org/doi/10.1145/3368756.3369088 (accessed on 10 April 2021).
- Boudchiche, M.; Mazroui, A.; Bebah, M.O.A.O.; Lakhouaja, A.; Boudlal, A. AlKhalil Morpho Sys 2: A robust Arabic morpho-syntactic analyzer. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 141–146. [Google Scholar] [CrossRef] [Green Version]
- Rashwan, M.A.; Al Sallab, A.A.; Raafat, H.M.; Rafea, A. Deep learning framework with confused sub-set resolution architecture for automatic Arabic diacritization. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 505–516. [Google Scholar] [CrossRef]
- Abandah, G.A.; Graves, A.; Al-Shagoor, B.; Arabiyat, A.; Jamour, F.; Al-Taee, M. Automatic diacritization of Arabic text using recurrent neural networks. Int. J. Doc. Anal. Recognit. (IJDAR) 2015, 18, 183–197. [Google Scholar] [CrossRef]
- Vergyri, D.; Kirchhoff, K. Automatic Diacritization of Arabic for Acoustic Modeling in Speech Recognition; Technical Report; Washington University Seattle Department of Electrical Engineering: Seattle, WA, USA, 2004. [Google Scholar]
- Habash, N.; Rambow, O. Arabic tokenization, part-of-speech tagging and morphological disambiguation in one fell swoop. In Proceedings of the 43rd Annual Meeting of the Association for computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 573–580. [Google Scholar]
- Fadel, A.; Tuffaha, I.; Al-Ayyoub, M. Arabic text diacritization using deep neural networks. In Proceedings of the 2019 2nd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–7. [Google Scholar]
- Mubarak, H.; Abdelali, A.; Sajjad, H.; Samih, Y.; Darwish, K. Highly effective arabic diacritization using sequence to sequence modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2390–2395. [Google Scholar]
- Abandah, G.; Abdel-Karim, A. Accurate and fast recurrent neural network solution for the automatic diacritization of Arabic text. Jordan. J. Comp. Inform. Technol. 2020, 6, 103–121. [Google Scholar] [CrossRef]
- Alqahtani, S.; Mishra, A.; Diab, M. Efficient Convolutional Neural Networks for Diacritic Restoration. arXiv 2019, arXiv:1912.06900. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in JAVA Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Hua, Y.; Guo, J.; Zhao, H. Deep belief networks and deep learning. In Proceedings of the 2015 International Conference on Intelligent Computing and Internet of Things, Harbin, China, 17–18 January 2015; pp. 1–4. [Google Scholar]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef] [Green Version]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Sazlı, M.H. A brief review of feed-forward neural networks. Commun. Fac. Sci. Univ. Ank. 2006, 50, 11–17. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, Y.; Luo, Q.; Basset, M.A. Training feedforward neural networks using symbiotic organisms search algorithm. Comput. Intell. Neurosci. 2016, 9063065. [Google Scholar] [CrossRef]
- Nawi, N.M.; Ransing, R.S.; Salleh, M.N.M.; Ghazali, R.; Hamid, N.A. An improved back propagation neural network algorithm on classification problems. In Database Theory and Application, Bio-Science and Bio-Technology; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–188. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Werbos, P.J. The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting; John Wiley & Sons: Hoboken, NJ, USA, 1994; Volume 1. [Google Scholar]
- Simon, H. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Rocha, M.; Cortez, P.; Neves, J. Evolutionary neural network learning. In Portuguese Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2003; pp. 24–28. [Google Scholar]
- Stanley, K.O.; Clune, J.; Lehman, J.; Miikkulainen, R. Designing neural networks through neuroevolution. Nat. Mach. Intell. 2019, 1, 24–35. [Google Scholar] [CrossRef]
- Montana, D.J.; Davis, L. Training Feedforward Neural Networks Using Genetic Algorithms. Available online: https://www.ijcai.org/Proceedings/89-1/Papers/122.pdf (accessed on 10 April 2021).
- Mirjalili, S.; Hashim, S.Z.M.; Sardroudi, H.M. Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm. Appl. Math. Comput. 2012, 218, 11125–11137. [Google Scholar] [CrossRef]
- Blum, C.; Socha, K. Training feed-forward neural networks with ant colony optimization: An application to pattern classification. In Proceedings of the Fifth International Conference on Hybrid Intelligent Systems (HIS’05), Rio de Janerio, Brazil, 6–9 November 2005. [Google Scholar]
- Faris, H.; Aljarah, I.; Mirjalili, S. Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl. Intell. 2016, 45, 322–332. [Google Scholar] [CrossRef]
- Valian, E.; Mohanna, S.; Tavakoli, S. Improved cuckoo search algorithm for feedforward neural network training. Int. J. Artif. Intell. Appl. 2011, 2, 36–43. [Google Scholar]
- Karaboga, D.; Akay, B.; Ozturk, C. Artificial bee colony (ABC) optimization algorithm for training feed-forward neural networks. In International Conference on Modeling Decisions for Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2007; pp. 318–329. [Google Scholar]
- Mirjalili, S. How effective is the Grey Wolf optimizer in training multi-layer perceptrons. Appl. Intell. 2015, 43, 150–161. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Delft, The Netherlands, 2009. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Zepeda-Mendoza, M.L.; Resendis-Antonio, O. Bipartite Graph. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 147–148. [Google Scholar] [CrossRef]
- Weisstein, E.W. Bernoulli Distribution. 2002. Available online: https://mathworld.wolfram.com/ (accessed on 10 April 2021).
- Fischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–36. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Morabito, F.C.; Campolo, M.; Ieracitano, C.; Mammone, N. Deep Learning Approaches to Electrophysiological Multivariate Time-Series Analysis. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Elsevier: Amsterdam, The Netherlands, 2019; pp. 219–243. [Google Scholar]
- Yepes, A.J.; MacKinlay, A.; Bedo, J.; Garvani, R.; Chen, Q. Deep belief networks and biomedical text categorisation. In Proceedings of the Australasian Language Technology Association Workshop 2014, Melbourne, Australia, 26–28 November 2014; pp. 123–127. [Google Scholar]
- Lu, P.; Guo, S.; Zhang, H.; Li, Q.; Wang, Y.; Wang, Y.; Qi, L. Research on improved depth belief network-based prediction of cardiovascular diseases. J. Healthc. Eng. 2018, 8954878. [Google Scholar] [CrossRef] [Green Version]
- Goyvaerts, J.; Levithan, S. Regular Expressions Cookbook; O’reilly: Newton, MA, USA, 2012. [Google Scholar]
- Chapman, C.; Stolee, K.T. Exploring regular expression usage and context in Python. In Proceedings of the 25th International Symposium on Software Testing and Analysis, Saarbrucken, Germany, 18–20 July 2016; pp. 282–293. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: A case from the Spanish market. Prog. Artif. Intell. 2020, 9, 31–53. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Yu, Y.; Adu, K.; Tashi, N.; Anokye, P.; Wang, X.; Ayidzoe, M.A. Rmaf: Relu-memristor-like activation function for deep learning. IEEE Access 2020, 8, 72727–72741. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. Available online: https://www.cs.toronto.edu/~fritz/absps/reluICML.pdf (accessed on 10 April 2021).
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Ide, H.; Kurita, T. Improvement of learning for CNN with ReLU activation by sparse regularization. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AL, USA, 14–19 May 2017; pp. 2684–2691. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Bisong, E. Google colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 59–64. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Habash, N.; Rambow, O. Arabic Diacritization through Full Morphological Tagging. Available online: https://www.aclweb.org/anthology/N07-2014/ (accessed on 10 April 2021).
- Schlippe, T.; Nguyen, T.; Vogel, S. Diacritization as a machine translation problem and as a sequence labeling problem. AMTA-2008. MT at work. In Proceedings of the Eighth Conference of the Association for Machine Translation in the Americas, Waikiki, HI, USA, 21–25 October 2008; pp. 270–278. [Google Scholar]
- Alghamdi, M.; Muzaffar, Z.; Alhakami, H. Automatic restoration of arabic diacritics: A simple, purely statistical approach. Arab. J. Sci. Eng. 2010, 35, 125. [Google Scholar]
- Barqawi, A.; Zerrouki, T. Shakkala, Arabic Text Vocalization. Available online: https://github.com/Barqawiz/Shakkala2017 (accessed on 10 April 2021).
- Alarifi, A.; Alghamdi, M.; Zarour, M.; Aloqail, B.; Alraqibah, H.; Alsadhan, K.; Alkwai, L. Estimating the size of Arabic indexed web content. Sci. Res. Essays 2012, 7, 2472–2483. [Google Scholar]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Shape | Sound | Unicode |
|---|---|---|---|
| Fatha | بَ | /a/ | 064E |
| Damma | بُ | /u/ | 064F |
| Kasra | بِ | /i/ | 0650 |
| Fathatan | بً | /an/ | 064B |
| Dammatan | بٌ | /un/ | 064C |
| Kasratan | بٍ | /in/ | 064D |
| Sukoun | بْ | None | 0652 |
| Shadda | بّ | Doubling | 0651 |
| Book ID | Book Name | Size (K Words) | Used (K Words) | Letters Per Word | Words Per Sentence | Zero Diacritics (%) | One Diacritic (%) | Two Diacritics (%) |
|---|---|---|---|---|---|---|---|---|
| 1 | Alahaad Walmathany | 241 | 24 | 3.78 | 6.01 | 43.1 | 52.6 | 4.3 |
| 2 | Majma Aldamanat | 218 | 114 | 4.04 | 14.25 | 21.1 | 74.6 | 4.3 |
| 3 | Sahyh Muslim | 494 | 188 | 3.81 | 21.01 | 26.4 | 67.8 | 5.8 |
| 4 | Alqawaed Labn Rajab | 169 | 127 | 4.12 | 16.20 | 20.9 | 74.2 | 4.9 |
| 5 | Alzawajer An Aqtiraf Alkabaer | 284 | 261 | 3.94 | 9.57 | 21.6 | 72.3 | 6.1 |
| 6 | Ghidaa Alalbab | 316 | 281 | 3.99 | 9.28 | 21.9 | 72.2 | 5.9 |
| 7 | Aljawharah Alnayyrah | 385 | 201 | 3.99 | 22.77 | 20.7 | 74.1 | 5.2 |
| 8 | Almadkhal Lilabdary | 361 | 293 | 4.05 | 13.68 | 21.1 | 73.1 | 5.8 |
| 9 | Durar Alhokam | 646 | 375 | 3.83 | 24.22 | 21.5 | 73.2 | 5.3 |
| 10 | Moghny Almohtaj | 1306 | 838 | 3.93 | 9.63 | 20.5 | 73.9 | 5.6 |
| 11 | LDC ATB3 | 305 | 225 | 4.64 | 11.31 | 39.8 | 54.8 | 5.4 |
| 12 | Children stories | 26 | 26 | 3.2 | 5.0 | 27.5 | 56.2 | 16.3 |
| Average | 396 K | 246 K | 3.94 | 13.58 | 25.5 | 68.3 | 6.2 |
| Diacritic Mark | Binary Class Sequence | Class Number |
|---|---|---|
| بَ | 1000000000000 | 0 |
| بُ | 0100000000000 | 1 |
| بِ | 0010000000000 | 2 |
| بْ | 0001000000000 | 3 |
| بً | 0000100000000 | 4 |
| بٍ | 0000010000000 | 5 |
| بٌ | 0000001000000 | 6 |
| بَّ | 0000000100000 | 7 |
| بُّ | 0000000010000 | 8 |
| بِّ | 0000000001000 | 9 |
| بًّ | 0000000000100 | 10 |
| بٌّ | 0000000000010 | 11 |
| بٍّ | 0000000000001 | 12 |
| Parameter | RBM Layers | DBN |
|---|---|---|
| Epochs | 30 | 200 |
| Batch | 256 | - |
| Learning rate | 0.05 | 0.1 |
| Dropout | - | 0.2 |
| Number of nodes | 250 | - |
| System | Dataset | All Diacritics | Ignore Last | ||
|---|---|---|---|---|---|
| DER | WER | DER-1 | WER-1 | ||
| Nelken & Shieber (2005) [28] | ATB3 | 12.8 | 23.6 | 6.5 | 7.3 |
| Zitouni et al. (2006) [14] | ATB3 | 5.5 | 18.0 | 2.5 | 7.9 |
| Habash & Rambow (2007) [84] | ATB3 | 4.8 | 14.9 | 2.2 | 5.5 |
| Schlippe et al. (2008) [85] | ATB3 | 4.3 | 19.9 | 1.7 | 6.8 |
| Alghamdi et al.(2010) [86] | ATB3 | 13.8 | 46.8 | 9.3 | 26.0 |
| Rashwan et al. (2011) [21] | ATB3 | 3.8 | 12.5 | 1.2 | 3.1 |
| Said et al. (2013) [4] | ATB3 | 3.6 | 11.4 | 1.6 | 4.4 |
| Abandah et al. (2015) [33] | ATB3 | 2.72 | 9.07 | 1.38 | 4.34 |
| Alqahtani et al. (2019) [39] | ATB3 | 2.8 | 8.2 | - | - |
| Abandah & Abdel-Karim (2019) [38] | ATB3 | 2.46 | 8.12 | 1.24 | 3.81 |
| Abbad & Xiong (2020) [19] | ATB3 | 9.32 | 28.51 | 6.37 | 12.85 |
| This work | ATB3 | 2.21 | 6.73 | 1.2 | 2.89 |
| Abandah (2015) [33] | Tashkeela | 2.09 | 5.82 | 1.28 | 3.54 |
| Barqawi (2017) [87] | Tashkeela | 3.73 | 11.19 | 2.88 | 6.53 |
| Abandah & Abdel-Karim (2019) [38] | Tashkeela | 1.97 | 5.13 | 1.22 | 3.13 |
| Fadel et al. (2019b) [36] | Tashkeela | 2.60 | 7.69 | 2.11 | 4.57 |
| Abbad & Xiong (2020) [19] | Tashkeela | 3.39 | 9.94 | 2.61 | 5.83 |
| This work | Tashkeela | 1.79 | 4.63 | 1.15 | 2.13 |
| Dataset | All Diacritics | Ignore Last | ||
|---|---|---|---|---|
| DER | WER | DER-1 | WER-1 | |
| Children stories | 2.4 | 6.57 | 1.33 | 2.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almanaseer, W.; Alshraideh, M.; Alkadi, O. A Deep Belief Network Classification Approach for Automatic Diacritization of Arabic Text. Appl. Sci. 2021, 11, 5228. https://doi.org/10.3390/app11115228
Almanaseer W, Alshraideh M, Alkadi O. A Deep Belief Network Classification Approach for Automatic Diacritization of Arabic Text. Applied Sciences. 2021; 11(11):5228. https://doi.org/10.3390/app11115228
Chicago/Turabian StyleAlmanaseer, Waref, Mohammad Alshraideh, and Omar Alkadi. 2021. "A Deep Belief Network Classification Approach for Automatic Diacritization of Arabic Text" Applied Sciences 11, no. 11: 5228. https://doi.org/10.3390/app11115228
APA StyleAlmanaseer, W., Alshraideh, M., & Alkadi, O. (2021). A Deep Belief Network Classification Approach for Automatic Diacritization of Arabic Text. Applied Sciences, 11(11), 5228. https://doi.org/10.3390/app11115228