Authority-Based Conversation Tracking in Twitter: An Unattended Methodological Approach

 ,
,  ,
, 
Abstract
Featured Application
Abstract
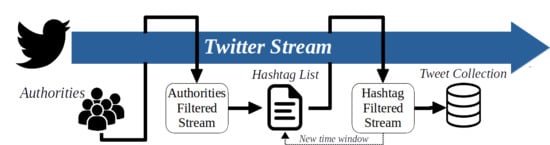
1. Introduction
- It would introduce a significant delay between the moment when a new topic emerges and the starting point of its tracking. Such a delay would translate into losing relevant information or interactions;
- Human supervision, which is not always possible (e.g., late at night), would be necessary. Unfortunately, depending on humans can cause the introduction of failures derived from fatigue, incorrect interpretation of the information, inability to detect and track relevant changes, and others.
2. Background
2.1. Social Media, Topics, and Trends
2.2. Topic Tracking
3. Method Description
3.1. Set of Authorities
3.2. Activity Monitor
| Algorithm 1: Tweet Monitor. |
 |
3.3. List of Hashtags
| Algorithm 2: Tweet Extractor |
 |
- In each window, the top H hashtags (referred as “hot”) in the list derived from the monitor step are selected according to their weight. The reasoning is that these are the keywords that the authorities are most strongly using on their posts;
- Additionally, for each window, the current list () is compared to the previous period (); from the difference between them, a list of emerging terms (labeled as E) is obtained (as a customization, this method could look at the n previous windows in case it was appropriate for the application). The emerging hashtags are a list of keywords that represent topics that could easily become “hot” in the following windows (as they exhibit a fast growth) but they have not reached their peak yet. This way, the method is able to implement an early detection and tracking of newer topics;
- The combination of hot and emerging hashtags from the previous steps forms a final set of T total hashtags (of at most elements). This step is graphically described in Figure 2;
- Adding a set of stop words is another customization that might be useful for most of the applications in order to avoid capturing common daily spurious expressions used widely by Twitter users (e.g., #happysunday, #goodnight or #followfriday).
3.4. Tweet Collection
4. Results
4.1. Political Context and Background
4.2. Selection of Authorities
4.3. Experimental Settings
4.4. Experimental Results
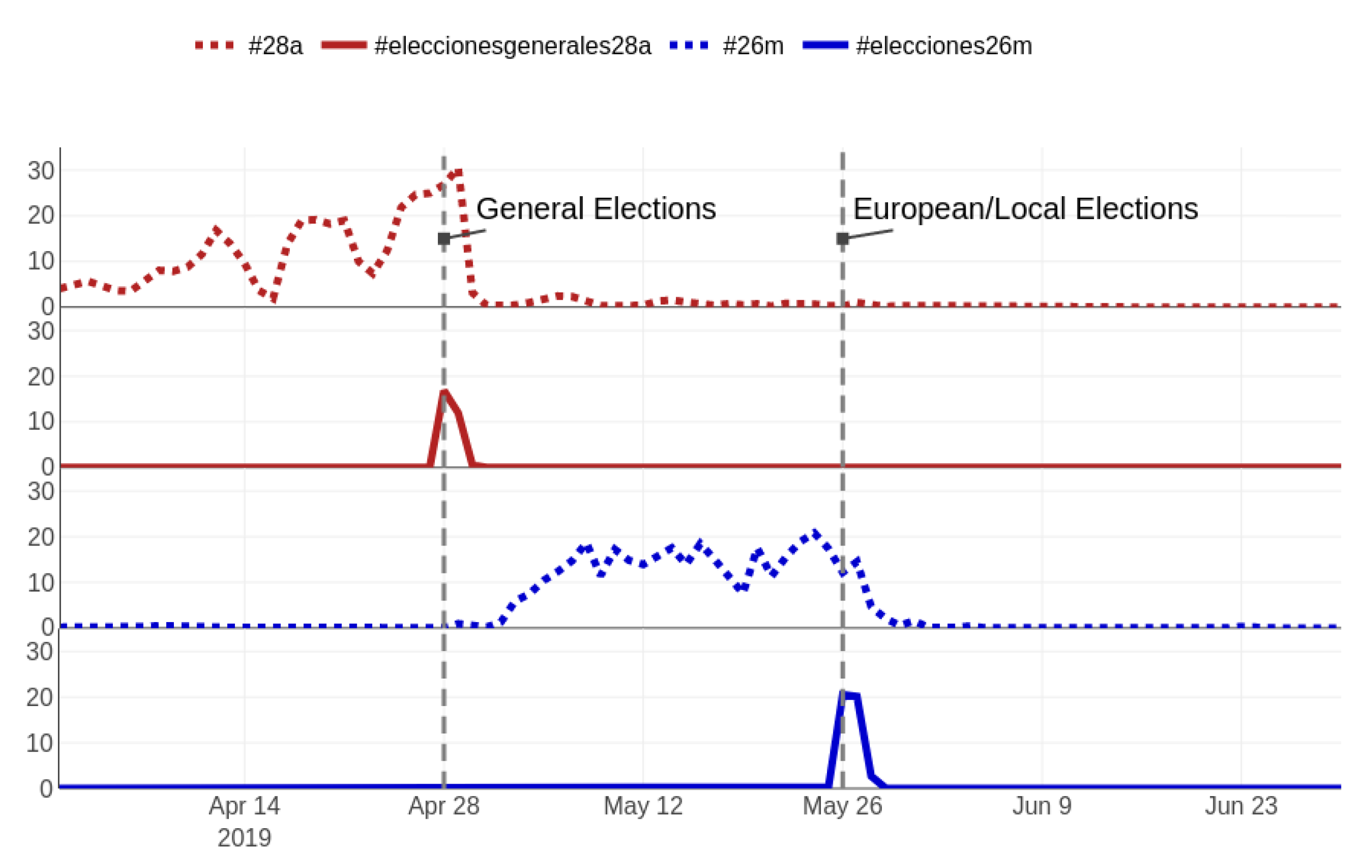
4.4.1. General Tracking
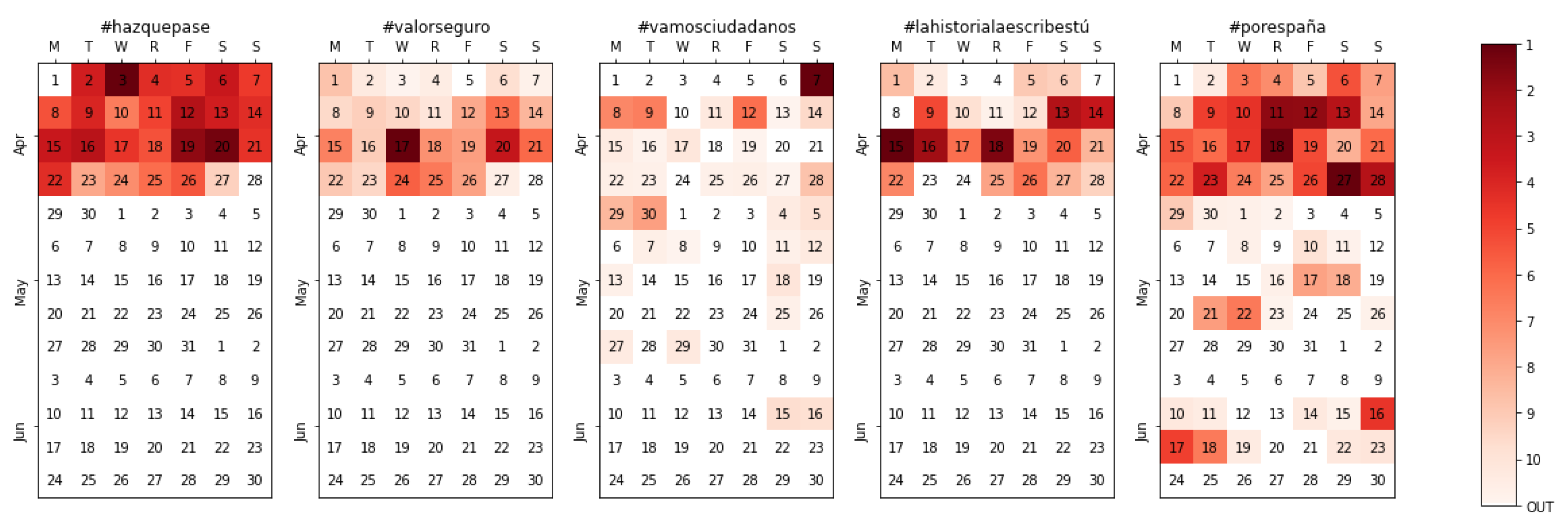
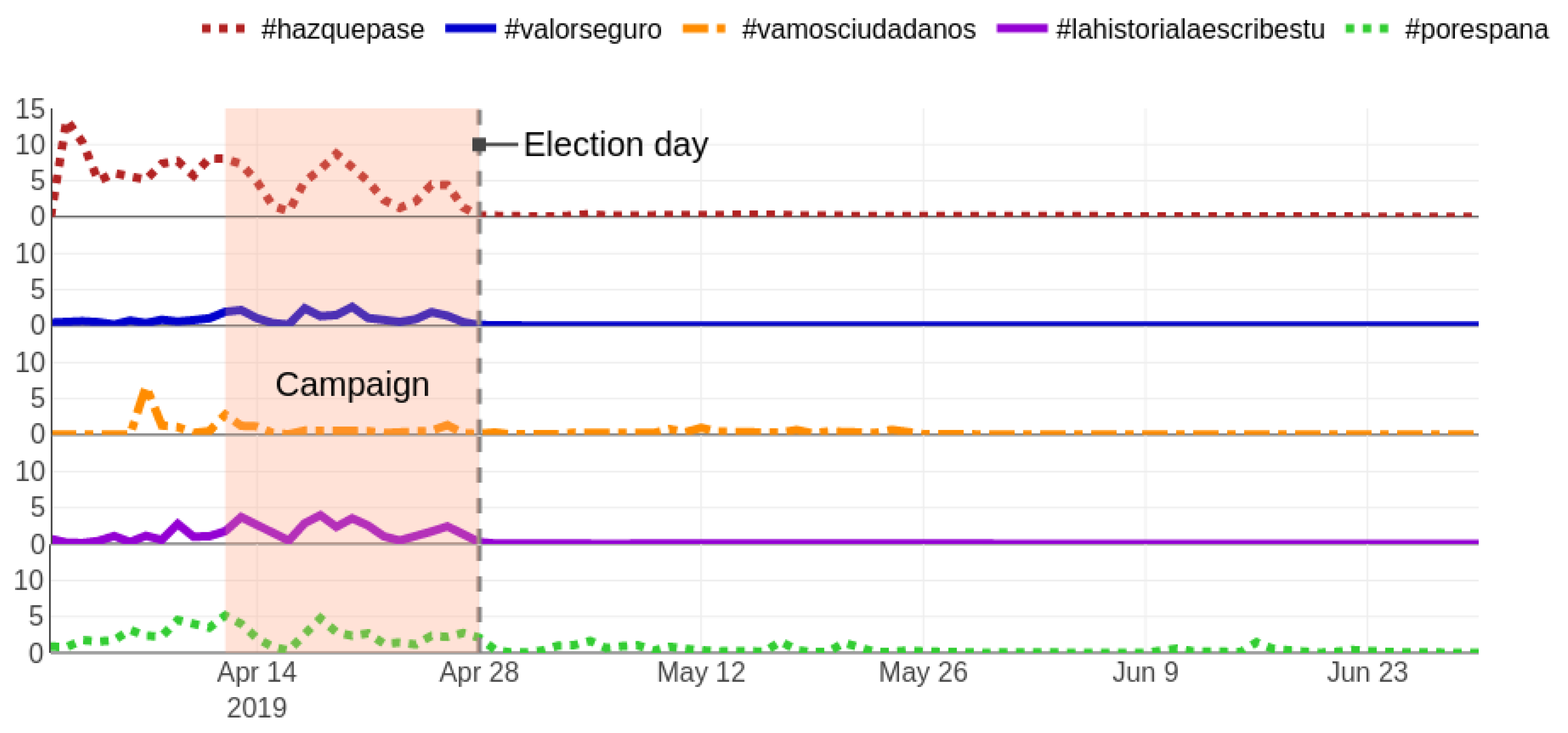
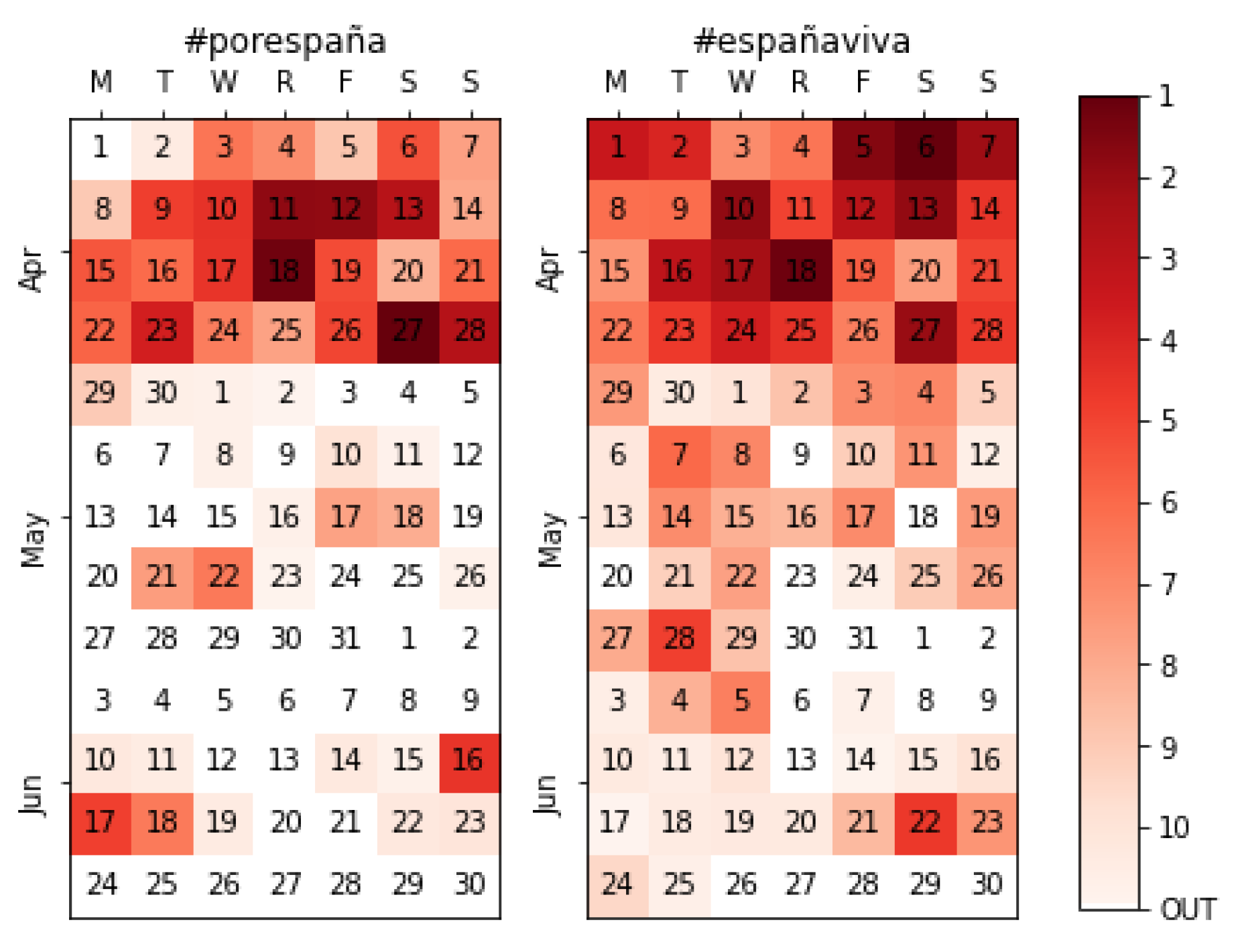
4.4.2. Electoral Campaign
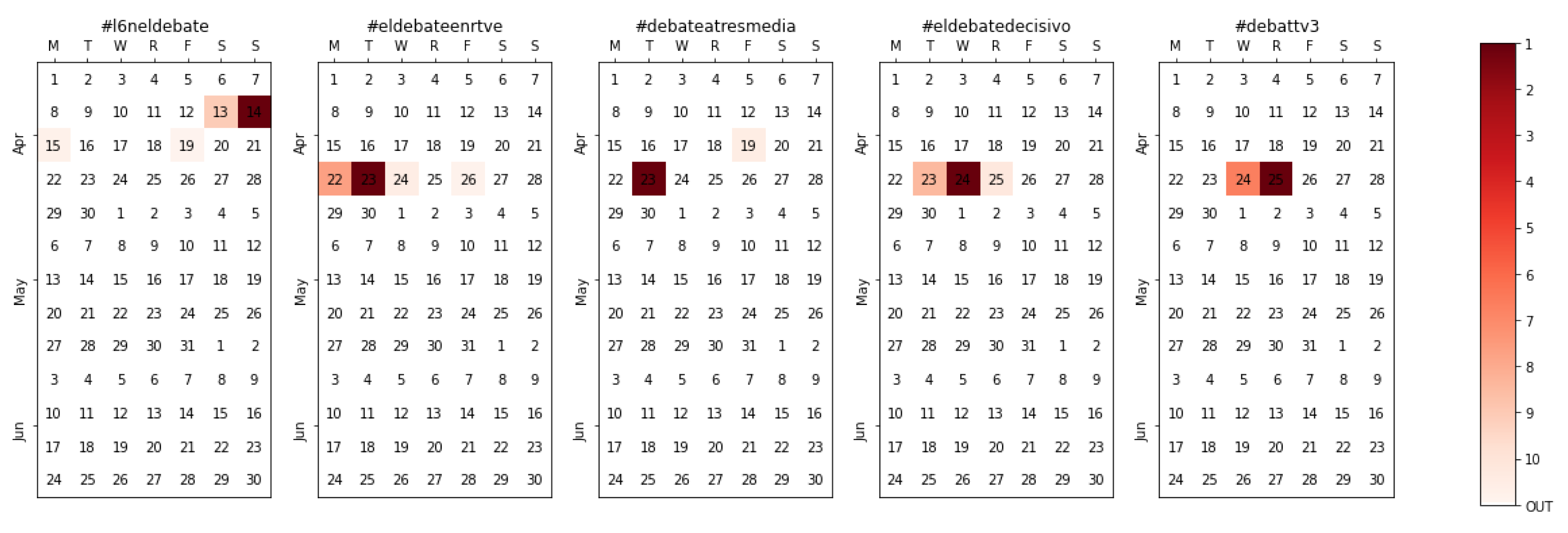
4.4.3. Televised Debates
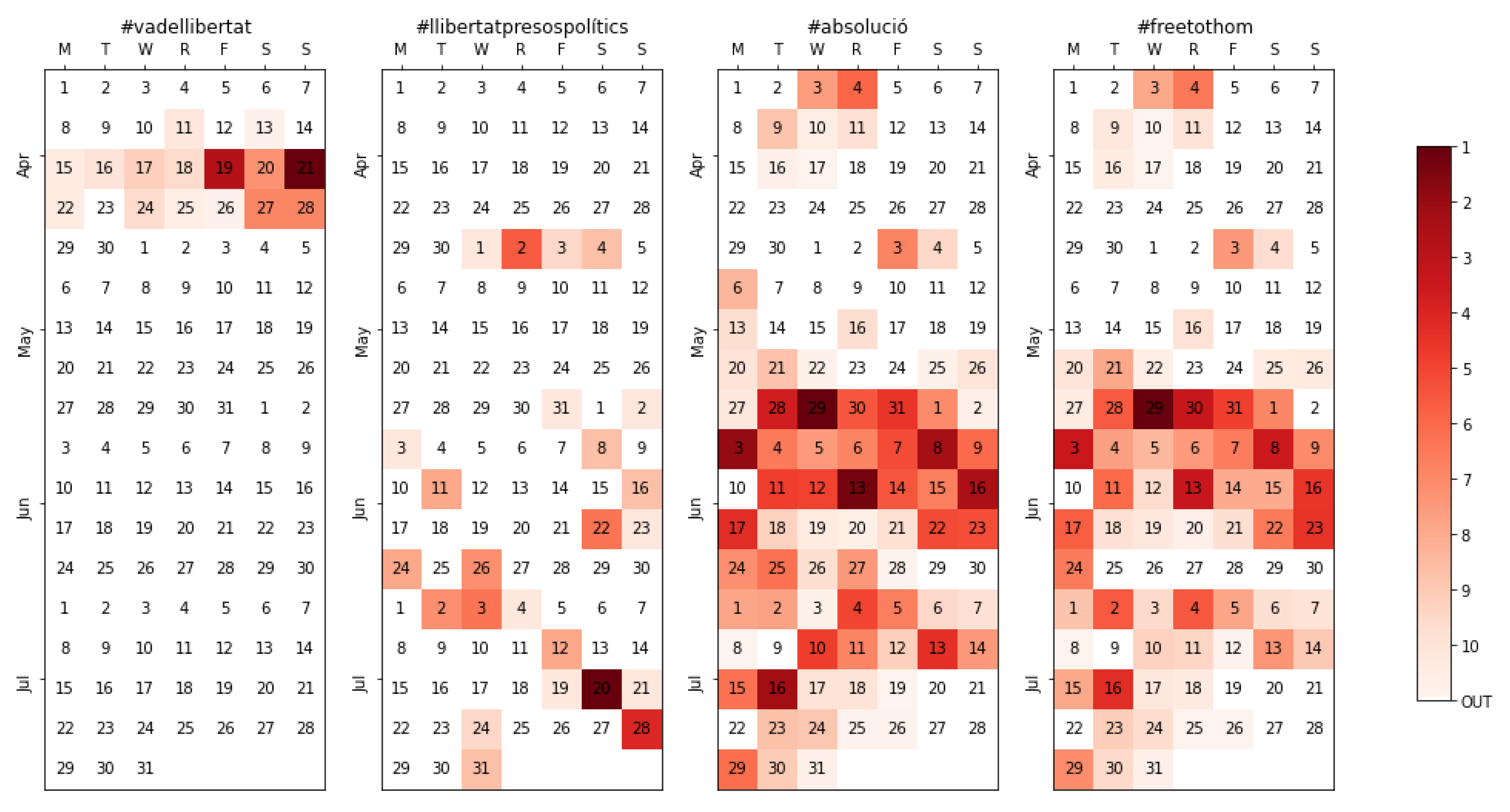
4.4.4. Event Detection and Tracking
4.4.5. Languages
5. Discussion
6. Conclusions
- The proposed methodology is able to follow the conversation around a topic and optimize its tracking, with a quick adaptation and no need for human supervision;
- The methodology is also robust against undesired events, misspellings, and the use of different languages and alternative terms;
- Fixed hashtag selection limits the information that researchers might be able to extract; it is desirable to adopt a flexible and dynamic approach.
Author Contributions
Conflicts of Interest
Abbreviations
| SNS | Social Networking Services |
| API | Application Programming Interface |
| PSOE | Partido Socialista Obrero Español |
| PP | Partido Popular |
| ERC | Esquerra Republicana de Catalunya |
References
- Turcotte, J.; York, C.; Irving, J.; Scholl, R.M.; Pingree, R.J. News recommendations from social media opinion leaders: Effects on media trust and information seeking. J. Comput. Mediat. Commun. 2015, 20, 520–535. [Google Scholar] [CrossRef]
- Fang, Y.; Chen, X.; Song, Z.; Wang, T.; Cao, Y. Modelling propagation of public opinions on microblogging big data using sentiment analysis and compartmental models. In Natural Language Processing: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 939–956. [Google Scholar]
- Gadek, G.; Pauchet, A.; Malandain, N.; Vercouter, L.; Khelif, K.; Brunessaux, S.; Grilhères, B. Topological and topical characterisation of Twitter user communities. Data Technol. Appl. 2018, 52. [Google Scholar] [CrossRef]
- McGregor, S.C.; Mourão, R.R.; Molyneux, L. Twitter as a tool for and object of political and electoral activity: Considering electoral context and variance among actors. J. Inf. Technol. Polit. 2017, 14, 154–167. [Google Scholar] [CrossRef]
- Jost, J.T.; Barberá, P.; Bonneau, R.; Langer, M.; Metzger, M.; Nagler, J.; Sterling, J.; Tucker, J.A. How social media facilitates political protest: Information, motivation, and social networks. Polit. Psychol. 2018, 39, 85–118. [Google Scholar] [CrossRef]
- Rainie, L.; Smith, A.; Schlozman, K.L.; Brady, H.; Verba, S. Social media and political engagement. Pew Internet Am. Life Proj. 2012, 19, 2–13. [Google Scholar]
- Park, C.S. Does Twitter motivate involvement in politics? Tweeting, opinion leadership, and political engagement. Comput. Hum. Behav. 2013, 29, 1641–1648. [Google Scholar] [CrossRef]
- Vromen, A.; Xenos, M.A.; Loader, B. Young people, social media and connective action: From organisational maintenance to everyday political talk. J. Youth Stud. 2015, 18, 80–100. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput. Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Green, D.P.; Gerber, A.S.; De Boef, S.L. Tracking opinion over time: A method for reducing sampling error. Public Opin. Q. 1999, 63, 178–192. [Google Scholar] [CrossRef]
- Yang, Y.; Ault, T.; Pierce, T.; Lattimer, C.W. Improving text categorization methods for event tracking. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 65–72. [Google Scholar]
- Yang, Y.; Pierce, T.; Carbonell, J. A study of retrospective and on-line event detection. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 28–36. [Google Scholar]
- Allan, J.; Carbonell, J.G.; Doddington, G.; Yamron, J.; Yang, Y. Topic Detection and Tracking Pilot Study Final Report. In Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop, Lansdowne, VA, USA, 8–11 February 1998; pp. 194–218. [Google Scholar]
- Mønsted, B.; Sapieżyński, P.; Ferrara, E.; Lehmann, S. Evidence of complex contagion of information in social media: An experiment using Twitter bots. PLoS ONE 2017, 12, e0184148. [Google Scholar]
- Hendrickson, S.; Kolb, J.; Lehman, B.; Montague, J. Trend Detection in Social Data. Twitter Blog. 2015. Available online: https://blog.twitter.com/en_us/a/2015/trend-detection-social-data.html (accessed on 2 May 2020).
- Allan, J. Introduction to topic detection and tracking. In Topic Detection and Tracking; Springer: Berlin/Heidelberg, Germany, 2002; pp. 1–16. [Google Scholar]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Discov. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Petrović, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to twitter. In Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 181–189. [Google Scholar]
- Bruns, A.; Burgess, J. Twitter hashtags from ad hoc to calculated publics. In Hashtag Publics: The Power and Politics of Discursive Networks; Peter Lang Inc.: Frankfurt, Germany, 2015; pp. 13–28. [Google Scholar]
- D’heer, E.; Verdergem, P.; De Grove, F. # MissingData: A methodological inquiry of the hashtag to collect data from Twitter. In Proceedings of the AoIR Selected Papers 17th Annual Conference Association Internet Research, Berlin, Germany, 5–8 October 2016; Volume 6. [Google Scholar]
- Enli, G.; Simonsen, C.A. ‘Social media logic’ meets professional norms: Twitter hashtags usage by journalists and politicians. Inform. Commun. Soc. 2018, 21, 1081–1096. [Google Scholar] [CrossRef]
- Fano, S.; Slanzi, D. Using Twitter data to monitor political campaigns and predict election results. In International Conference on Practical Applications of Agents and Multi-Agent Systems; Springer: Berlin, Germany, 2017; pp. 191–197. [Google Scholar]
- Reyes-Menendez, A.; Saura, J.R.; Alvarez-Alonso, C. Understanding# WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar]
- Takahashi, B.; Tandoc, E.C., Jr.; Carmichael, C. Communicating on Twitter during a disaster: An analysis of tweets during Typhoon Haiyan in the Philippines. Comput. Hum. Behav. 2015, 50, 392–398. [Google Scholar] [CrossRef]
- Tsakalidis, A.; Papadopoulos, S.; Cristea, A.I.; Kompatsiaris, Y. Predicting elections for multiple countries using Twitter and polls. IEEE Intell. Syst. 2015, 30, 10–17. [Google Scholar] [CrossRef][Green Version]
- Lu, R.; Yang, Q. Trend analysis of news topics on twitter. Int. J. Mach. Learn. Comput. 2012, 2, 327. [Google Scholar] [CrossRef]
- Naaman, M.; Becker, H.; Gravano, L. Hip and trendy: Characterizing emerging trends on Twitter. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 902–918. [Google Scholar] [CrossRef]
- Lau, J.H.; Collier, N.; Baldwin, T. On-line trend analysis with topic models:# twitter trends detection topic model online. In Proceedings of the COLING 2012, Mumbai, India, 8–15 December 2012; pp. 1519–1534. [Google Scholar]
- Cheong, M.; Lee, V. Integrating web-based intelligence retrieval and decision-making from the twitter trends knowledge base. In Proceedings of the 2nd ACM Workshop on Social Web Search and Mining, Hong Kong, China, 3–4 November 2009; pp. 1–8. [Google Scholar]
- Choi, H.J.; Park, C.H. Emerging topic detection in twitter stream based on high utility pattern mining. Expert Syst. Appl. 2019, 115, 27–36. [Google Scholar] [CrossRef]
- Adedoyin-Olowe, M.; Gaber, M.M.; Dancausa, C.M.; Stahl, F.; Gomes, J.B. A rule dynamics approach to event detection in twitter with its application to sports and politics. Expert Syst. Appl. 2016, 55, 351–360. [Google Scholar] [CrossRef]
- Gaglio, S.; Re, G.L.; Morana, M. A framework for real-time Twitter data analysis. Comput. Commun. 2016, 73, 236–242. [Google Scholar] [CrossRef]
- Krauter, K.; Buyya, R.; Maheswaran, M. A taxonomy and survey of grid resource management systems for distributed computing. Softw. Pract. Exp. 2002, 32, 135–164. [Google Scholar] [CrossRef]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the sample good enough? comparing data from twitter’s streaming api with twitter’s firehose. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013; pp. 400–408. [Google Scholar]
- Yaqub, U.; Chun, S.A.; Atluri, V.; Vaidya, J. Analysis of political discourse on twitter in the context of the 2016 US presidential elections. Gov. Inf. Q. 2017, 34, 613–626. [Google Scholar] [CrossRef]
- Lai, M.; Patti, V.; Ruffo, G.; Rosso, P. Stance evolution and twitter interactions in an italian political debate. In International Conference on Applications of Natural Language to Information Systems; Springer: Berlin, Germany, 2018; pp. 15–27. [Google Scholar]
- Howard, P.N.; Kollanyi, B. Bots, #Strongerin, and #Brexit: Computational Propaganda During the UK-EU Referendum. SSRN Electron. J. 2017. [Google Scholar] [CrossRef]
- Howard, P.N.; Bolsover, G.; Kollanyi, B.; Bradshaw, S.; Neudert, L.M. Junk News and Bots during the U.S. Election: What Were Michigan Voters Sharing Over Twitter?|The Computational Propaganda Project. Tech. Rep. 2017. Available online: http://275rzy1ul4252pt1hv2dqyuf.wpengine.netdna-cdn.com/wp-content/uploads/2017/07/2206.pdf (accessed on 2 May 2020).
- Mahmoudi, A.; Yaakub, M.R.; Bakar, A.A. New time-based model to identify the influential users in online social networks. Data Technol. Appl. 2018, 52, 278–290. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Party | #Authorities | Example | Party | #Authorities | Example |
|---|---|---|---|---|---|
| Coalición Canaria | 2 | @anioramas | ERC | 4 | @junqueras |
| Compromís | 3 | @joanbaldovi | JxCat | 4 | @jorditurull |
| Ciudadanos | 44 | @albert_rivera | Podemos | 42 | @PabloIglesias |
| EAJ-PNV | 3 | @AITOR_ESTEBAN | PP | 43 | @pablocasado_ |
| EH Bildu | 2 | @OskarMatute | PSOE | 43 | @sanchezcastejon |
| En Marea | 4 | @baranauskas_ana | Vox | 26 | @Santi_ABASCAL |
| Others | 5 |
| Hashtag | Periods among the Top 10 |
|---|---|
| #españaviva | 1142 out of 2928 (39.0%) |
| #28a | 952 (32.5%) |
| #absolució | 686 (23.4%) |
| #psoe | 657 (22.4%) |
| #freetothom | 656 (22.4%) |
| #26m | 654 (22.3%) |
| #porespaña | 645 (22.0%) |
| #votapsoe | 593 (20.2%) |
| #hazquepase | 566 (19.3%) |
| #siemprehaciadelante | 474 (16.2%) |
| Hashtag | TV Channel | Date | Tweets Extracted |
|---|---|---|---|
| #l6neldebate | La Sexta | 13/04/19 22:00 | 72,749 |
| #eldebateenrtve | TVE | 22/04/19 22:00 | 952,546 |
| #debateatresmedia | A3/La Sexta | 23/04/19 22:00 | 116,732 |
| #eldebatedecisivo | A3/La Sexta | (*) | 971,681 |
| #debattv3 | TV3 | 24/04/19 22:00 | 90,937 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mora-Cantallops, M.; Sánchez-Alonso, S.; García-Barriocanal, E.; Sicilia, M.-Á. Authority-Based Conversation Tracking in Twitter: An Unattended Methodological Approach. Appl. Sci. 2020, 10, 3273. https://doi.org/10.3390/app10093273
Mora-Cantallops M, Sánchez-Alonso S, García-Barriocanal E, Sicilia M-Á. Authority-Based Conversation Tracking in Twitter: An Unattended Methodological Approach. Applied Sciences. 2020; 10(9):3273. https://doi.org/10.3390/app10093273
Chicago/Turabian StyleMora-Cantallops, Marçal, Salvador Sánchez-Alonso, Elena García-Barriocanal, and Miguel-Ángel Sicilia. 2020. "Authority-Based Conversation Tracking in Twitter: An Unattended Methodological Approach" Applied Sciences 10, no. 9: 3273. https://doi.org/10.3390/app10093273
APA StyleMora-Cantallops, M., Sánchez-Alonso, S., García-Barriocanal, E., & Sicilia, M.-Á. (2020). Authority-Based Conversation Tracking in Twitter: An Unattended Methodological Approach. Applied Sciences, 10(9), 3273. https://doi.org/10.3390/app10093273