Accelerating High-Resolution Seismic Imaging by Using Deep Learning



Abstract
1. Introduction
2. Methods
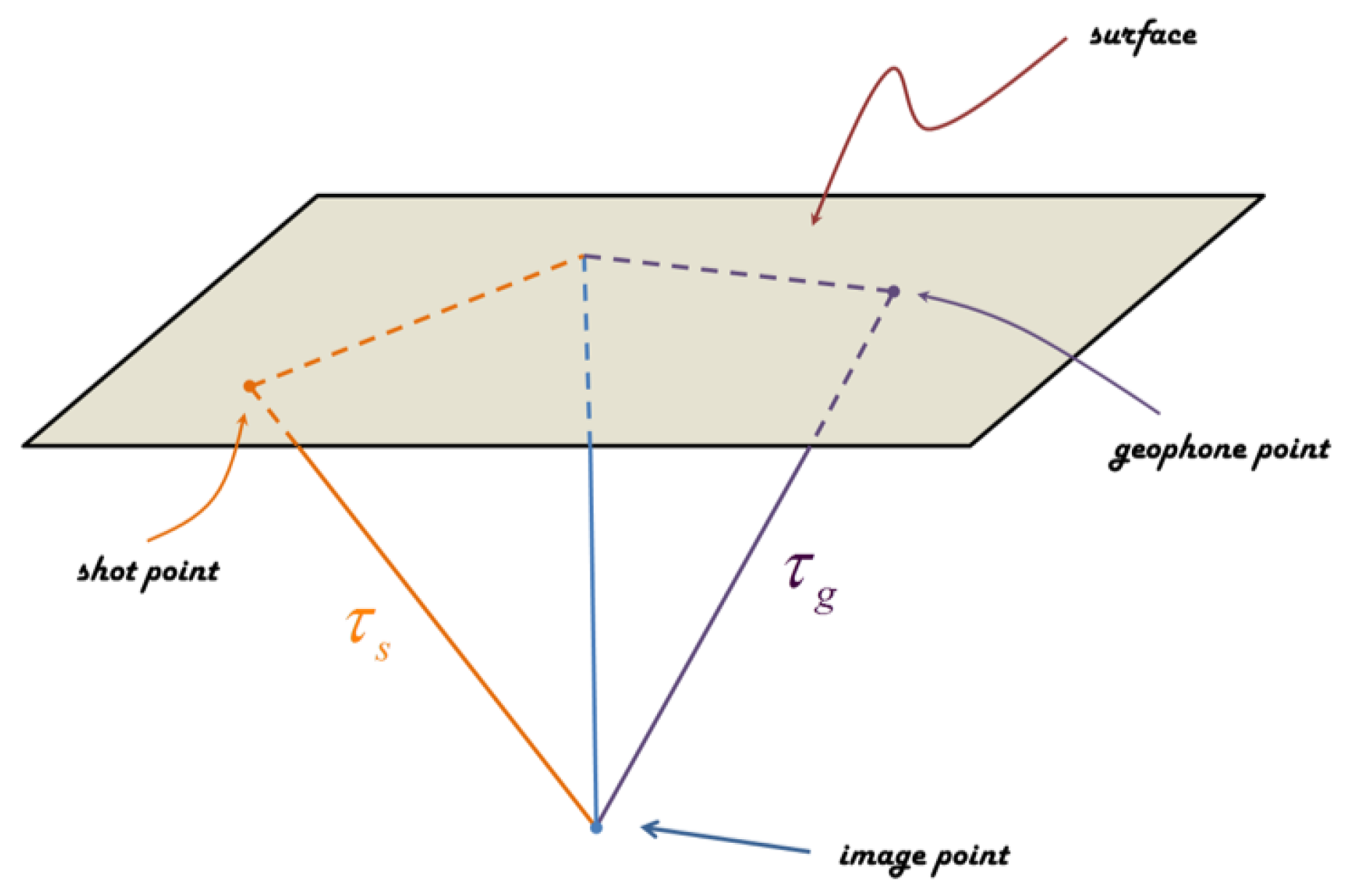
2.1. High-Resolution Imaging Using QPSTM
2.2. Network Architecture
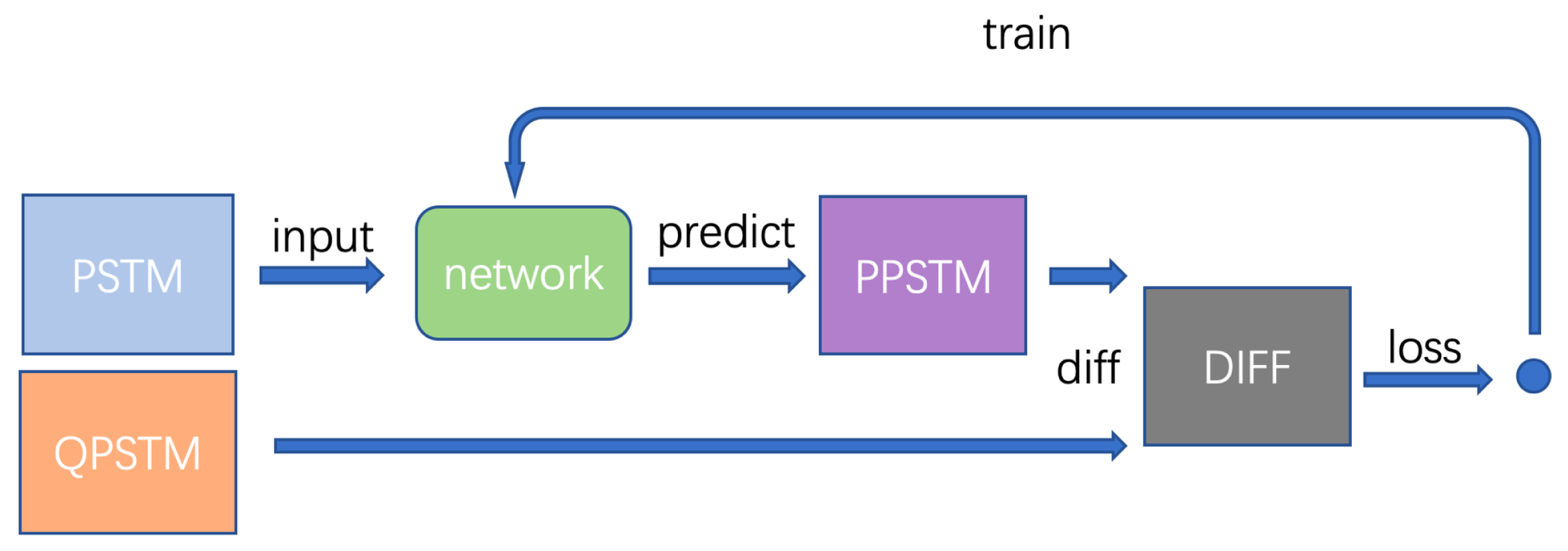
2.3. End-to-End Learning with Small Patches
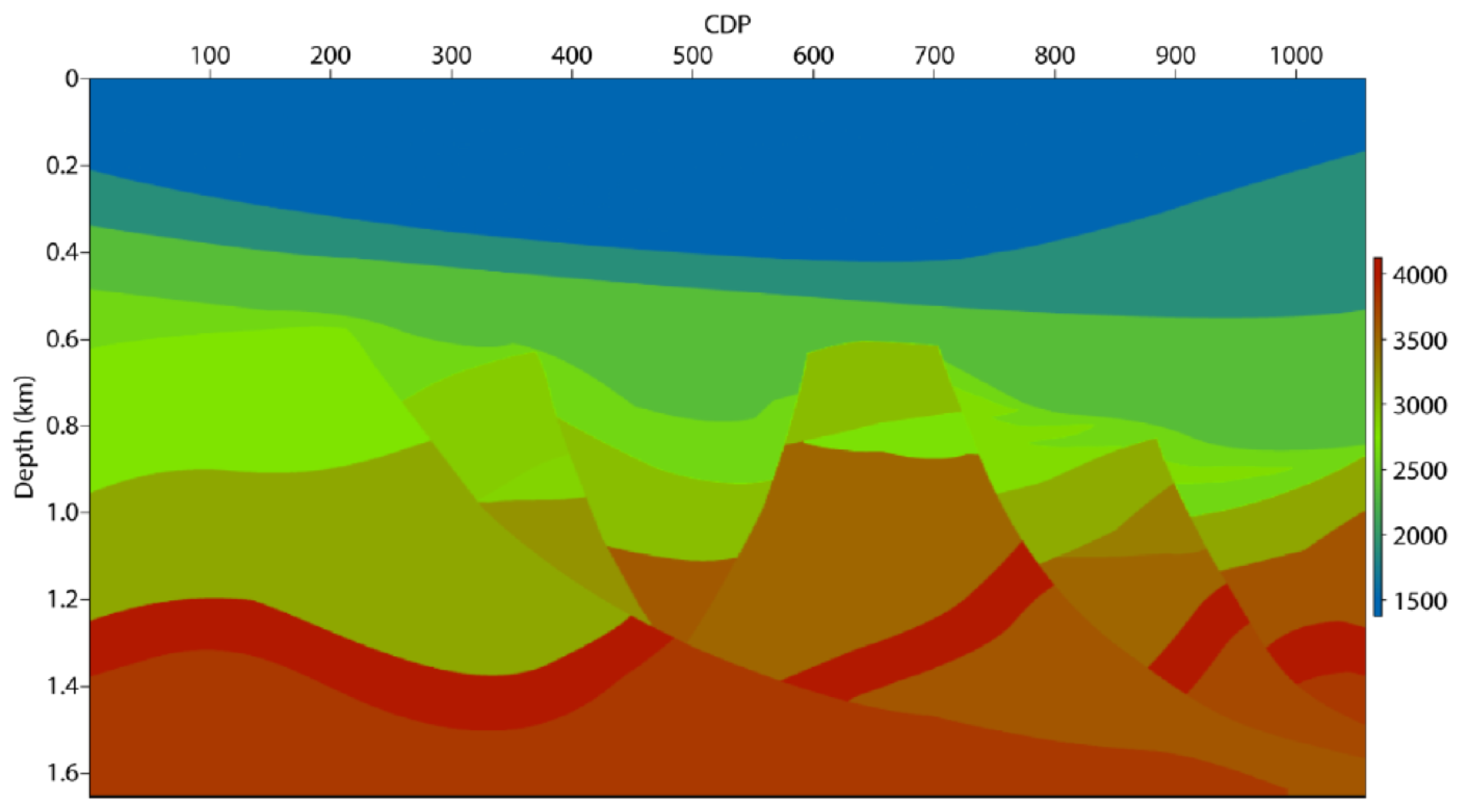
2.4. Data Set
3. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Wu, J.; Li, X. Compensation for absorption and dispersion in prestack migration: An effective Q approach. Geophysics 2012, 78, S1–S14. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Z.; Liu, L.; Wang, J.; Xu, J. High-resolution imaging: An approach by incorporating stationary-phase implementation into deabsorption prestack time migration. Geophysics 2016, 81, S317–S331. [Google Scholar] [CrossRef]
- Xu, J.; Liu, W.; Wang, J.; Liu, L.; Zhang, J. An efficient implementation of 3D high-resolution imaging for large-scale seismic data with GPU/CPU heterogeneous parallel computing. Comput. Geosci. 2018, 111, 272–282. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Deng, C.; Xue, Y.; Liu, X.; Li, C.; Tao, D. Active transfer learning network: A unified deep joint spectral–spatial feature learning model for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 2018, 57, 1741–1754. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Fan, X.; Yang, Y.; Deng, C.; Xu, J.; Gao, X. Compressed multi-scale feature fusion network for single image super-resolution. Signal Process. 2018, 146, 50–60. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Lin, K.; Yang, H.F.; Hsiao, J.H.; Chen, C.S. Deep learning of binary hash codes for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 27–35. [Google Scholar]
- Li, W.J.; Wang, S.; Kang, W.C. Feature learning based deep supervised hashing with pairwise labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep supervised hashing for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2064–2072. [Google Scholar]
- Deng, C.; Yang, E.; Liu, T.; Tao, D. Two-stream deep hashing with class-specific centers for supervised image search. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef]
- Jia, Y.; Ma, J. What can machine learning do for seismic data processing? An interpolation application. Geophysics 2017, 82, V163–V177. [Google Scholar] [CrossRef]
- Wang, B.F.; Zhang, N.; Lu, W.K.; Zhang, P.; Geng, J.H. Seismic Data Interpolation Using Deep Learning Based Residual Networks. Eur. Assoc. Geosci. Eng. 2018, 1, 2214–4609. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Xiong, W.; Ji, X.; Ma, Y.; Wang, Y.; AlBinHassan, N.M.; Ali, M.N.; Luo, Y. Seismic fault detection with convolutional neural network. Geophysics 2018, 83, O97–O103. [Google Scholar] [CrossRef]
- Qian, F.; Yin, M.; Liu, X.Y.; Wang, Y.J.; Lu, C.; Hu, G.M. Unsupervised seismic facies analysis via deep convolutional autoencoders. Geophysics 2018, 83, A39–A43. [Google Scholar] [CrossRef]
- Yang, F.; Ma, J. Deep-learning inversion: A next generation seismic velocity-model building method. Geophysics 2019, 84, 1–133. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, N.; Lu, W.; Wang, J. Deep-learning-based seismic data interpolation: A preliminary result. Geophysics 2019, 84, V11–V20. [Google Scholar] [CrossRef]
- Hu, L.; Zheng, X.; Duan, Y.; Yan, X.; Hu, Y.; Zhang, X. First-arrival picking with a U-net convolutional network. Geophysics 2019, 84, U45–U57. [Google Scholar] [CrossRef]
- Zhang, Z.d.; Alkhalifah, T. Regularized elastic full waveform inversion using deep learning. Geophysics 2019, 84, R741–R751. [Google Scholar] [CrossRef]
- Hu, W.; Jin, Y.; Wu, X.; Chen, J. A progressive deep transfer learning approach to cycle-skipping mitigation in FWI. In SEG Technical Program Expanded Abstracts 2019; Society of Exploration Geophysicists: Tulsa, OK, USA, 2019; pp. 2348–2352. [Google Scholar]
- Dou, H.; Zhang, J. An irregular grid method for acoustic modeling in inhomogeneous viscoelastic medium. Chin. J.-Geophys.-Chin. Ed. 2016, 59, 4212–4222. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587v3. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; ACM: New York, NY, USA, 1995; Volume 3361. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Software. Available online: tensorflow.org (accessed on 3 April 2020).
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 297–312. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tetko, I.V.; Livingstone, D.J.; Luik, A.I. Neural network studies. 1. Comparison of overfitting and overtraining. J. Chem. Inf. Comput. Sci. 1995, 35, 826–833. [Google Scholar] [CrossRef]
Sample Availability: Data associated with this research is confidential and the source code is available after the paper has been published online. You can get the source code from https://github.com/reed-lau/migration-migration.git. |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Connected to |
|---|---|---|
| input-1 | (64,128,1) | |
| conv2d-1 | (64,128,64) | input-1 |
| conv2d-2 | (64,128,64) | conv2d-1 |
| max-pooling2d-1 | (32,64,64) | conv2d-2 |
| conv2d-3 | (32,64,128) | max-pooling2d-1 |
| conv2d-4 | (32,64,128) | conv2d-3 |
| max-pooling2d-2 | (16,32,128) | conv2d-4 |
| conv2d-5 | (16,32,256) | max-pooling2d-2 |
| conv2d-6 | (16,32,256) | conv2d-5 |
| max-pooling2d-3 | (8,16,256) | conv2d-6 |
| conv2d-7 | (8,16,512) | max-pooling2d-3 |
| conv2d-8 | (8,16,512) | conv2d-7 |
| dropout-1 | (8,16,512) | conv2d-8 |
| max-pooling2d-4 | (4,8,512) | dropout-1 |
| conv2d-9 | (4,8,1024) | max-pooling2d-4 |
| conv2d-10 | (4,8,1024) | conv2d-9 |
| dropout-2 | (4,8,1024) | conv2d-10 |
| up-sampling2d-1 | (8,16,1024) | dropout-2 |
| conv2d-11 | (8,16,512) | up-sampling2d-1 |
| concatenate-1 | (8,16,1024) | dropout-1 |
| conv2d-11 | ||
| conv2d-12 | (8,16,512) | concatenate-1 |
| conv2d-13 | (8,16,512) | conv2d-12 |
| up-sampling2d-2 | (16,32,512) | conv2d-13 |
| conv2d-14 | (16,32,256) | up-sampling2d-2 |
| concatenate-2 | (16,32,512) | conv2d-6 |
| conv2d-14 | ||
| conv2d-15 | (16,32,256) | concatenate-2 |
| conv2d-16 | (16,32,256) | onv2d-15 |
| up-sampling2d-3 | (32,64,256) | conv2d-16 |
| conv2d-17 | (32,64,128) | p-sampling2d-3 |
| concatenate-3 | (32,64,256) | conv2d-4 |
| conv2d-17 | ||
| conv2d-18 | (32,64,128) | concatenate-3 |
| conv2d-19 | (32,64,128) | conv2d-18 |
| up-sampling2d-4 | (64,128,128) | conv2d-19 |
| conv2d-20 | (64,128,64) | up-sampling2d-4 |
| concatenate-4 | (64,128,128) | conv2d-2 |
| conv2d-20 | ||
| conv2d-21 | (64,128,64) | concatenate-4 |
| conv2d-22 | (64,128,64) | conv2d-21 |
| conv2d-23 | (64,128,1) | conv2d-22 |
| Deep Learning Method (hour) | QPSTM Method (hour) | |
|---|---|---|
| Computing Resource | One TITAN XP GPU | One TITAN XP GPU |
| Computing Process | Data Generation (96 h) Training Process (4 h) Prediction Process (0.4 h) | 32 h * Profile Number (437) |
| Total Time | 100.4 h | 13,984 h |
| Speedup Ratio | 139 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Cheng, Q.; Liu, L.; Wang, Y.; Zhang, J. Accelerating High-Resolution Seismic Imaging by Using Deep Learning. Appl. Sci. 2020, 10, 2502. https://doi.org/10.3390/app10072502
Liu W, Cheng Q, Liu L, Wang Y, Zhang J. Accelerating High-Resolution Seismic Imaging by Using Deep Learning. Applied Sciences. 2020; 10(7):2502. https://doi.org/10.3390/app10072502
Chicago/Turabian StyleLiu, Wei, Qian Cheng, Linong Liu, Yun Wang, and Jianfeng Zhang. 2020. "Accelerating High-Resolution Seismic Imaging by Using Deep Learning" Applied Sciences 10, no. 7: 2502. https://doi.org/10.3390/app10072502
APA StyleLiu, W., Cheng, Q., Liu, L., Wang, Y., & Zhang, J. (2020). Accelerating High-Resolution Seismic Imaging by Using Deep Learning. Applied Sciences, 10(7), 2502. https://doi.org/10.3390/app10072502