Contextual Coefficients Excitation Feature: Focal Visual Representation for Relationship Detection

Abstract
:1. Introduction
- Propose a Contextual Coefficients Excitation Feature (CCEF), which reduce the diversity of unrelated visual features by introducing feature recalibration conditioned on the relationship contextual information.
- Improve the conditional WGAN with relationship classification loss for generated-label coefficients generation on VRD and significantly improve the prediction for unseen relationship.
2. Related Works
2.1. Visual Relationship Detection
2.2. Generative Adversarial Network
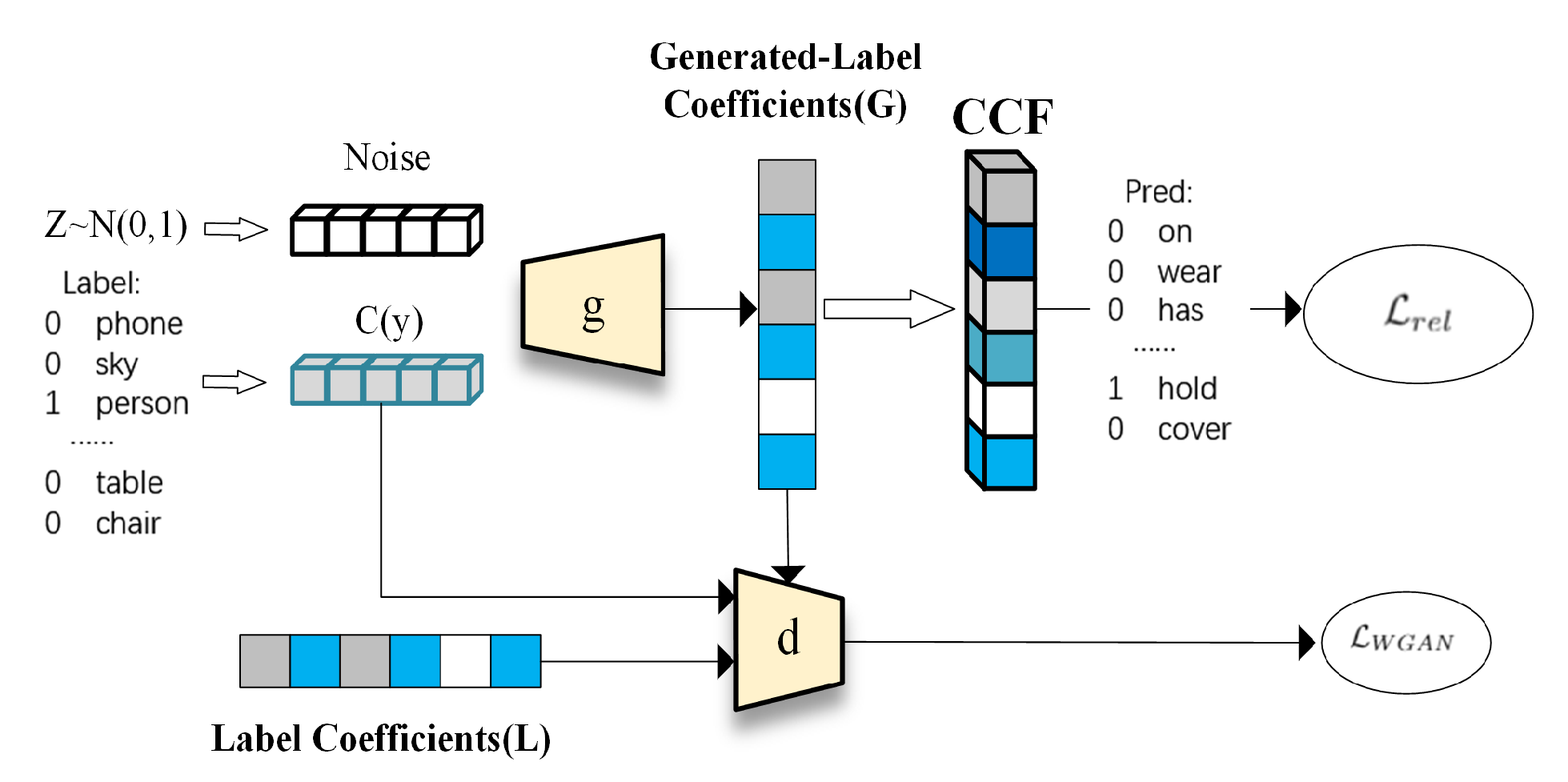
3. Methods
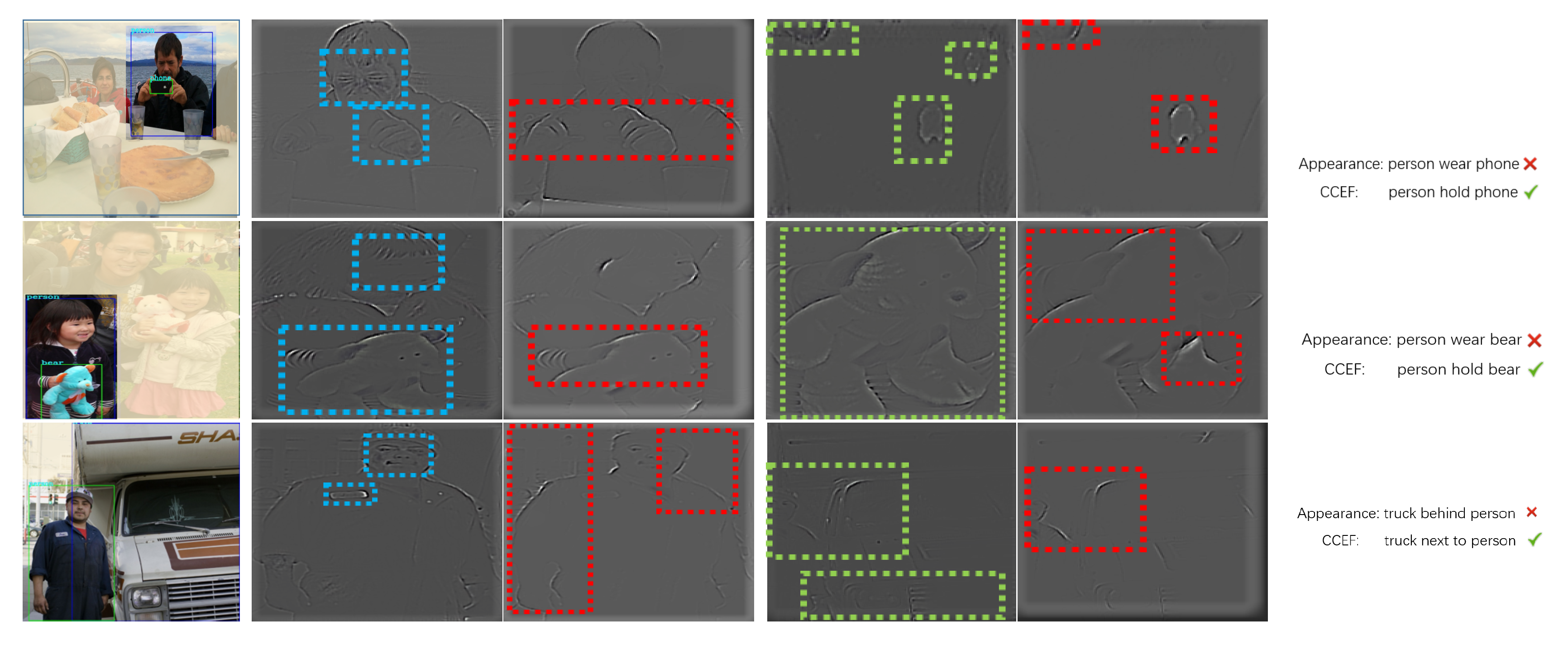
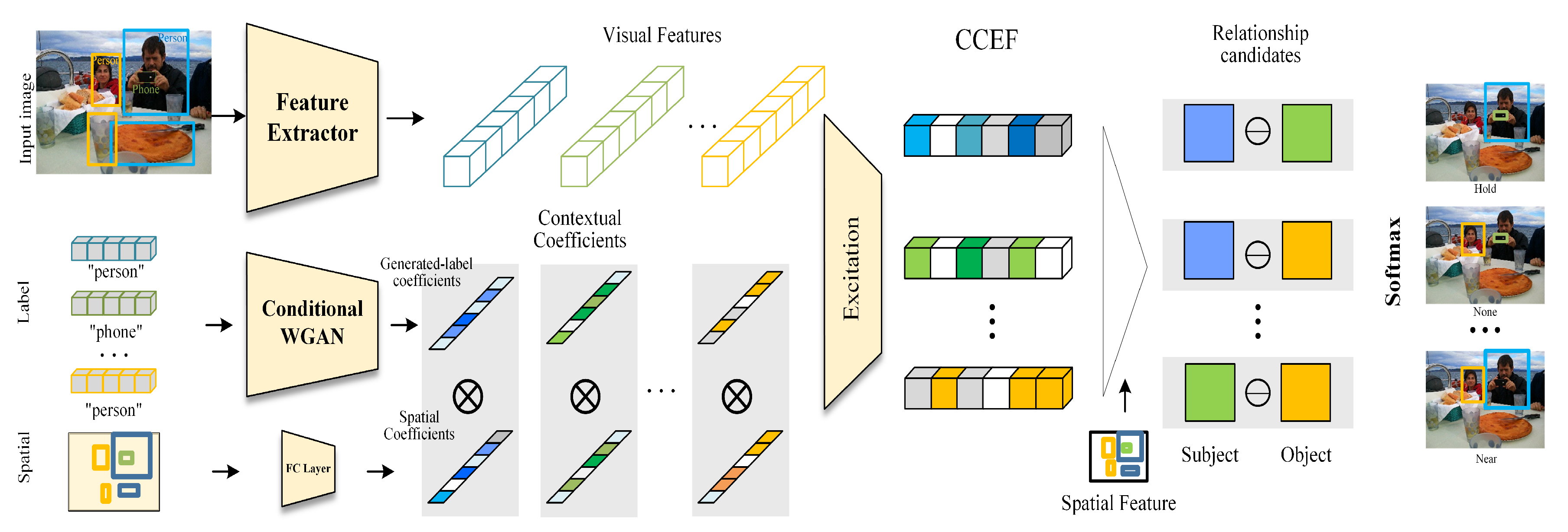
3.1. CCEF: Focal Visual Representation
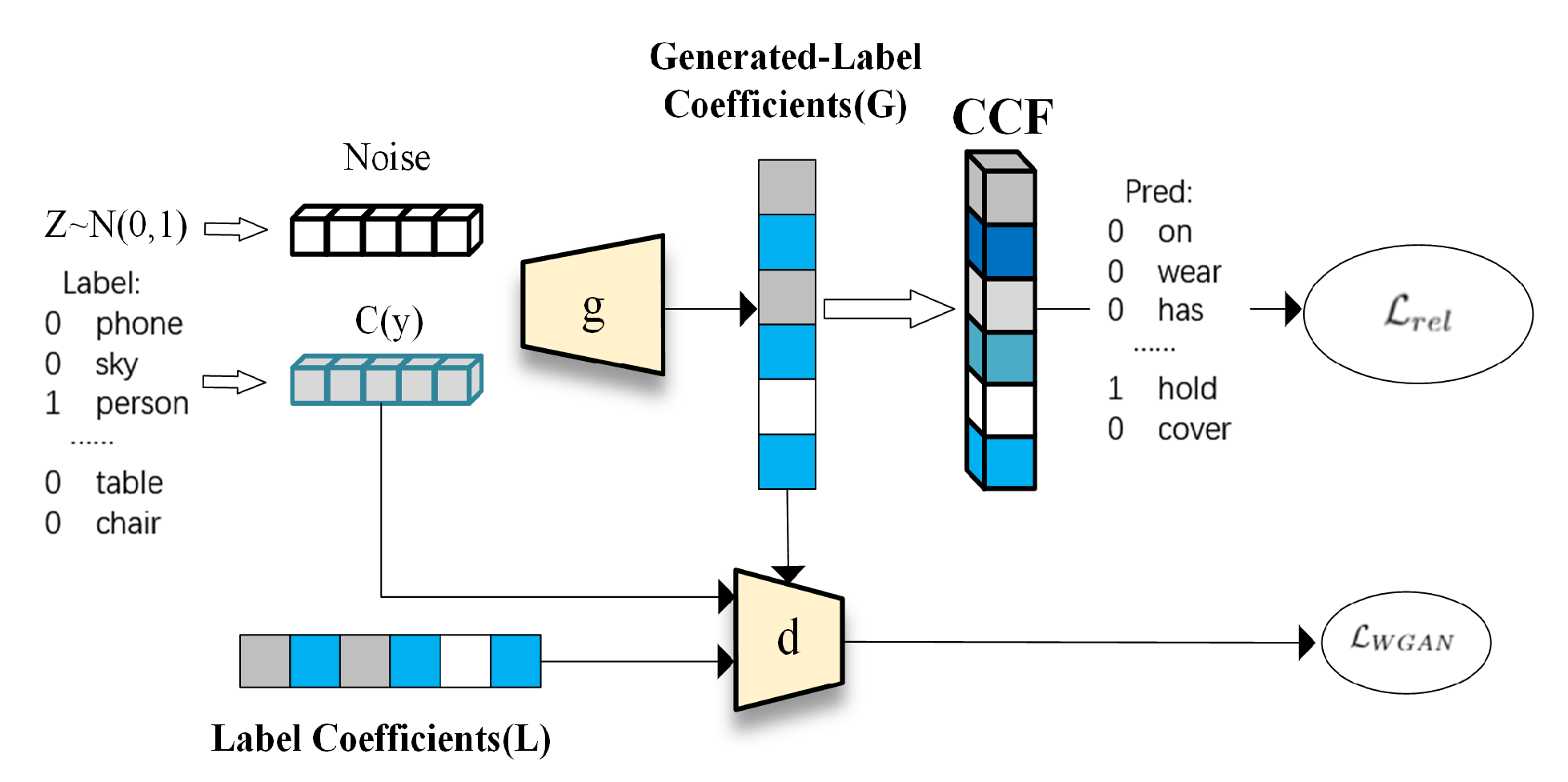
3.2. Objective Function
3.3. Training and Prediction
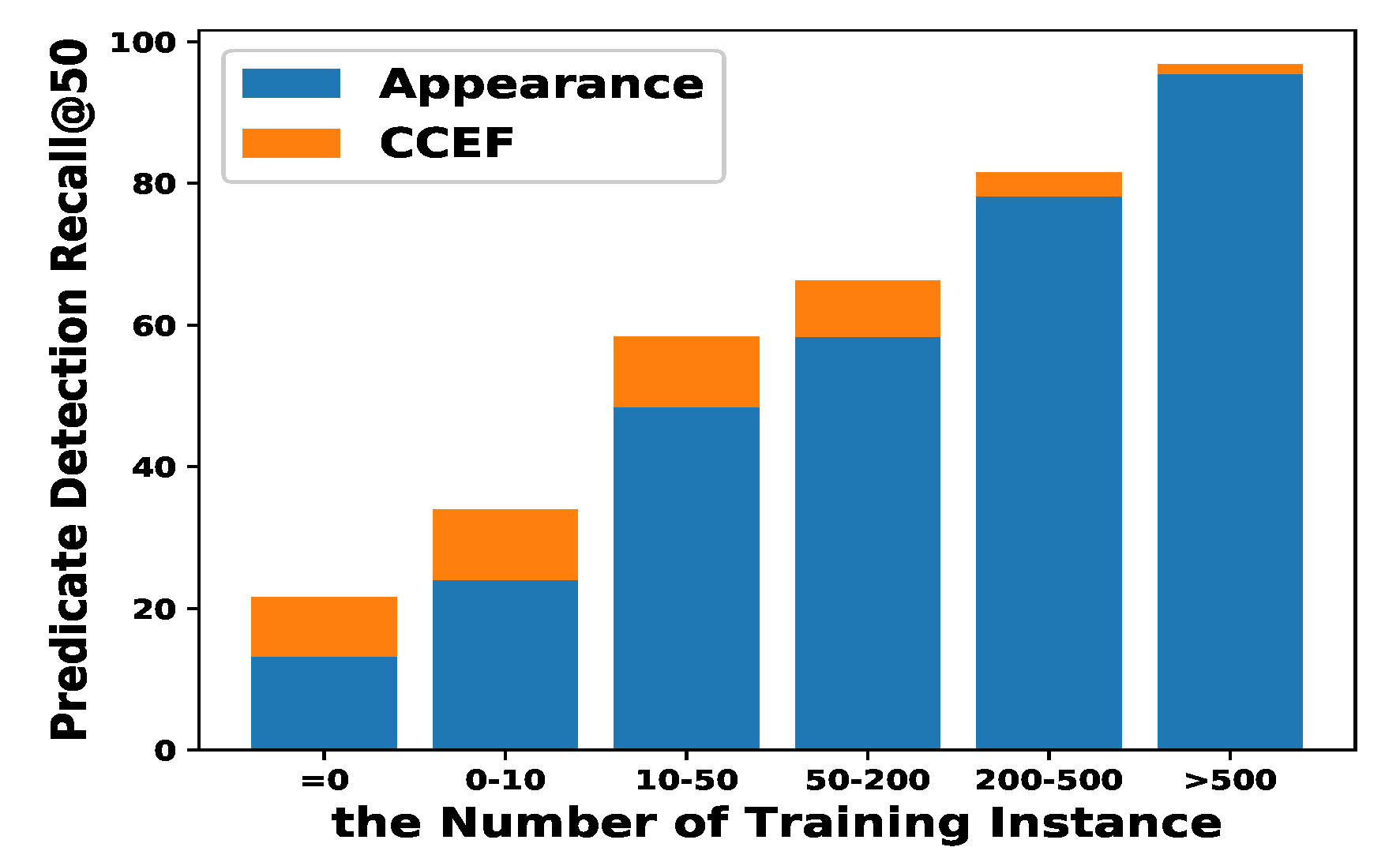
4. Results
- Appearance: Directly use to instead in (1) without utilizing any coefficients.
- Outs − A + S: Replace with in (1) in Section 3.1.
- Ours − A + L: Replace with in (1) described as Section 3.2.
- Ours − A + S + L: Replace the with in (2) described in Section 3.2.
- CCEF(Ours − A + S + G): Use visual representation described as Section 3.1.
4.1. Implement Details
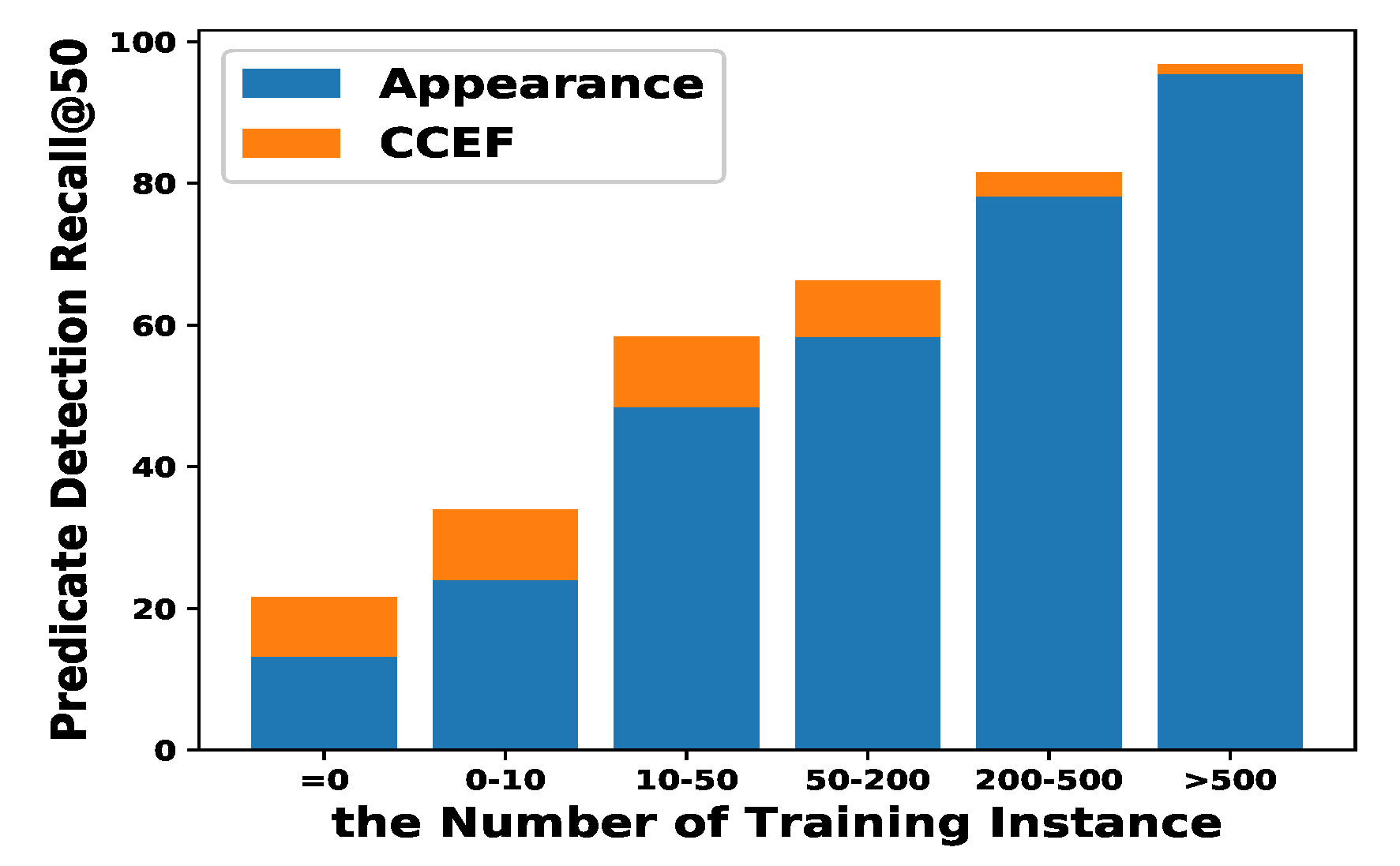
4.2. Evaluation on Visual Relationship Dataset
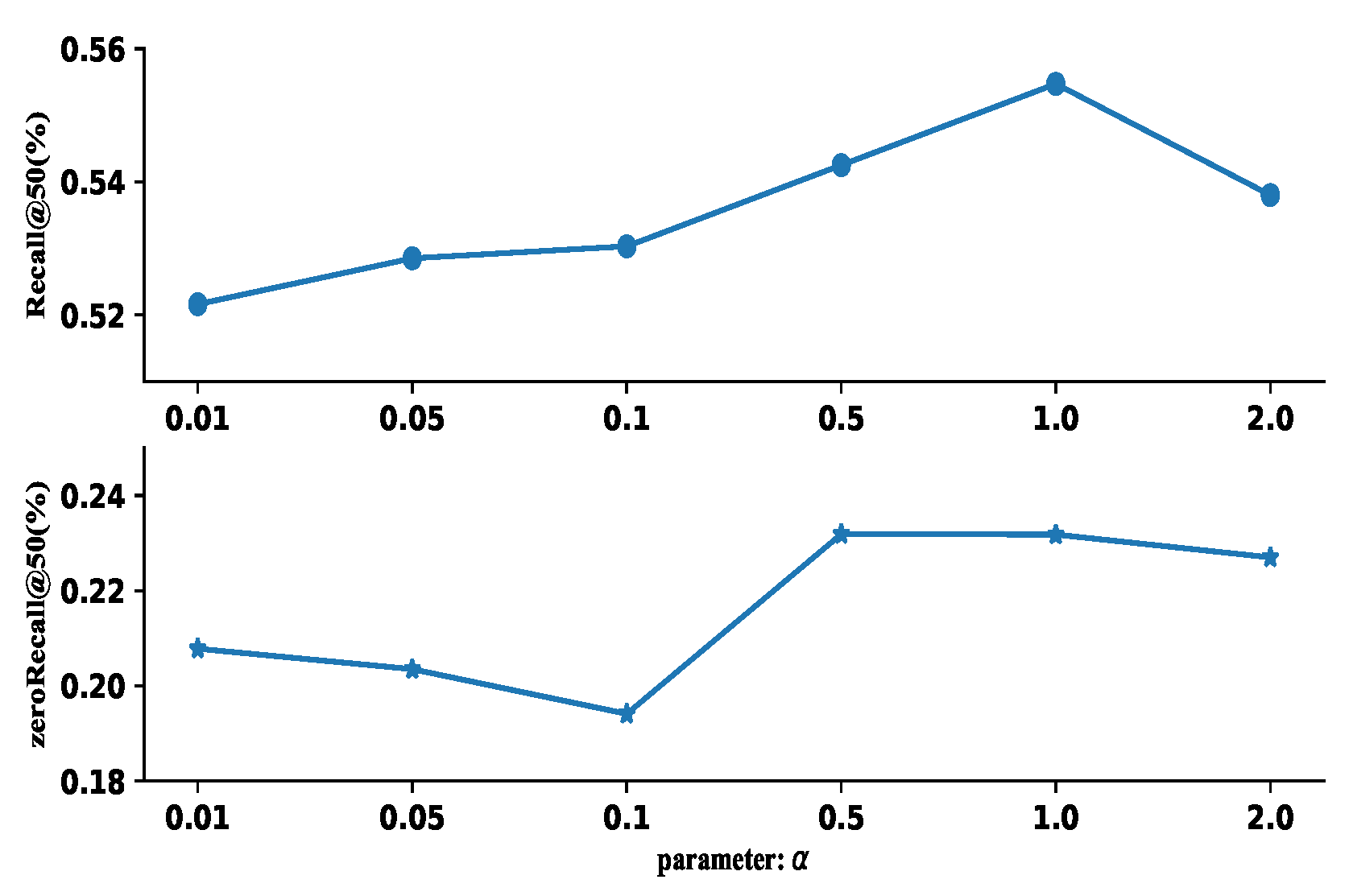
5. Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 528–537. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; Communications of the ACM: New York, NY, USA, 2017; pp. 84–90. [Google Scholar]
- Wang, H.; Wang, Q.; Gao, M.; Li, P.; Zuo, W. Multi-scale location-aware kernel representation for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1248–1257. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure inference net: Object detection using scene-level context and instance-level relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6985–6994. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, G.; Zhang, M.; Ji, D.H.; Zhu, Q. Tree kernel-based relation extraction with context-sensitive structured parse tree information. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 728–736. [Google Scholar]
- Zhuang, B.; Liu, L.; Shen, C.; Reid, I. Towards context-aware interaction recognition for visual relationship detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 589–598. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual relationship detection with language priors. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 852–869. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1974–1982. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5831–5840. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A.; Gould, S. Dynamic image networks for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3034–3042. [Google Scholar]
- Sadeghi, M.A.; Farhadi, A. Recognition using visual phrases. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1745–1752. [Google Scholar]
- Zhu, Y.; Jiang, S.; Li, X. Visual relationship detection with object spatial distribution. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 379–384. [Google Scholar]
- Zhang, H.; Kyaw, Z.; Chang, S.F.; Chua, T.S. Visual translation embedding network for visual relation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5532–5540. [Google Scholar]
- Yin, G.; Sheng, L.; Liu, B.; Yu, N.; Wang, X.; Shao, J.; Change Loy, C. Zoom-net: Mining deep feature interactions for visual relationship recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 322–338. [Google Scholar]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. Graph r-cnn for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–685. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5767–5777. [Google Scholar]
- Kossaifi, J.; Tran, L.; Panagakis, Y.; Pantic, M. Gagan: Geometry-aware generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 878–887. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Peng, Y.; Qi, J. CM-GANs: Cross-modal generative adversarial networks for common representation learning. ACM Trans. Multimedia Comput. Commun. Appl. 2019, 15, 22. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Yang, J. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1788–1797. [Google Scholar]
- Zhang, G.; Kan, M.; Shan, S.; Chen, X. Generative adversarial network with spatial attention for face attribute editing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 417–432. [Google Scholar]
- Zhao, B.; Chang, B.; Jie, Z.; Sigal, L. Modular generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 150–165. [Google Scholar]
- Bucher, M.; Herbin, S.; Jurie, F. Generating visual representations for zero-shot classification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2666–2673. [Google Scholar]
- Felix, R.; Kumar VB, G.; Reid, I.; Carneiro, G. Multi-modal cycle-consistent generalized zero-shot learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 21–37. [Google Scholar]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5542–5551. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 2787–2795. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yang, X.; Zhang, H.; Cai, J. Shuffle-then-assemble: Learning object-agnostic visual relationship features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 36–52. [Google Scholar]
- Han, C.; Shen, F.; Liu, L.; Yang, Y.; Shen, H.T. Visual spatial attention network for relationship detection. In Proceedings of the 2018 ACM Multimedia Conference on Multimedia Conference, Seoul, Korea, 22–26 October 2018; pp. 510–518. [Google Scholar]
- Jae Hwang, S.; Ravi, S.N.; Tao, Z.; Kim, H.J.; Collins, M.D.; Singh, V. Tensorize, factorize and regularize: Robust visual relationship learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1014–1023. [Google Scholar]
- Peyre, J.; Sivic, J.; Laptev, I.; Schmid, C. Weakly-supervised learning of visual relations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5179–5188. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are gans created equal? A large-scale study. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 700–709. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. CVAE-GAN: Fine-grained image generation through asymmetric training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2745–2754. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Entire Set | Zero-Shot |
|---|---|---|
| R@100/50 | R@100/50 | |
| Language Priors [8] | 47.9 | 8.5 |
| VTransE [16] | 44.8 | – |
| STA [37] | 48.0 | 20.6 |
| VSA-Net [38] | 49.2 | – |
| Zoom-Net [17] | 50.7 | – |
| LK [9] * | 47.5 | 17.0 |
| Visual Spatial [15] | 51.5 | 14.6 |
| TFR [39] | 52.3 | 17.3 |
| SA-Full [40] | 52.6 | 21.6 |
| CAI [7] | 53.6 | 16.4 |
| Appearance | 45.2 | 13.2 |
| Ours − A + S | 48.5 | 20.4 |
| Ours − A + L | 50.5 | 15.4 |
| Ours − A + S + L | 53.0 | 19.5 |
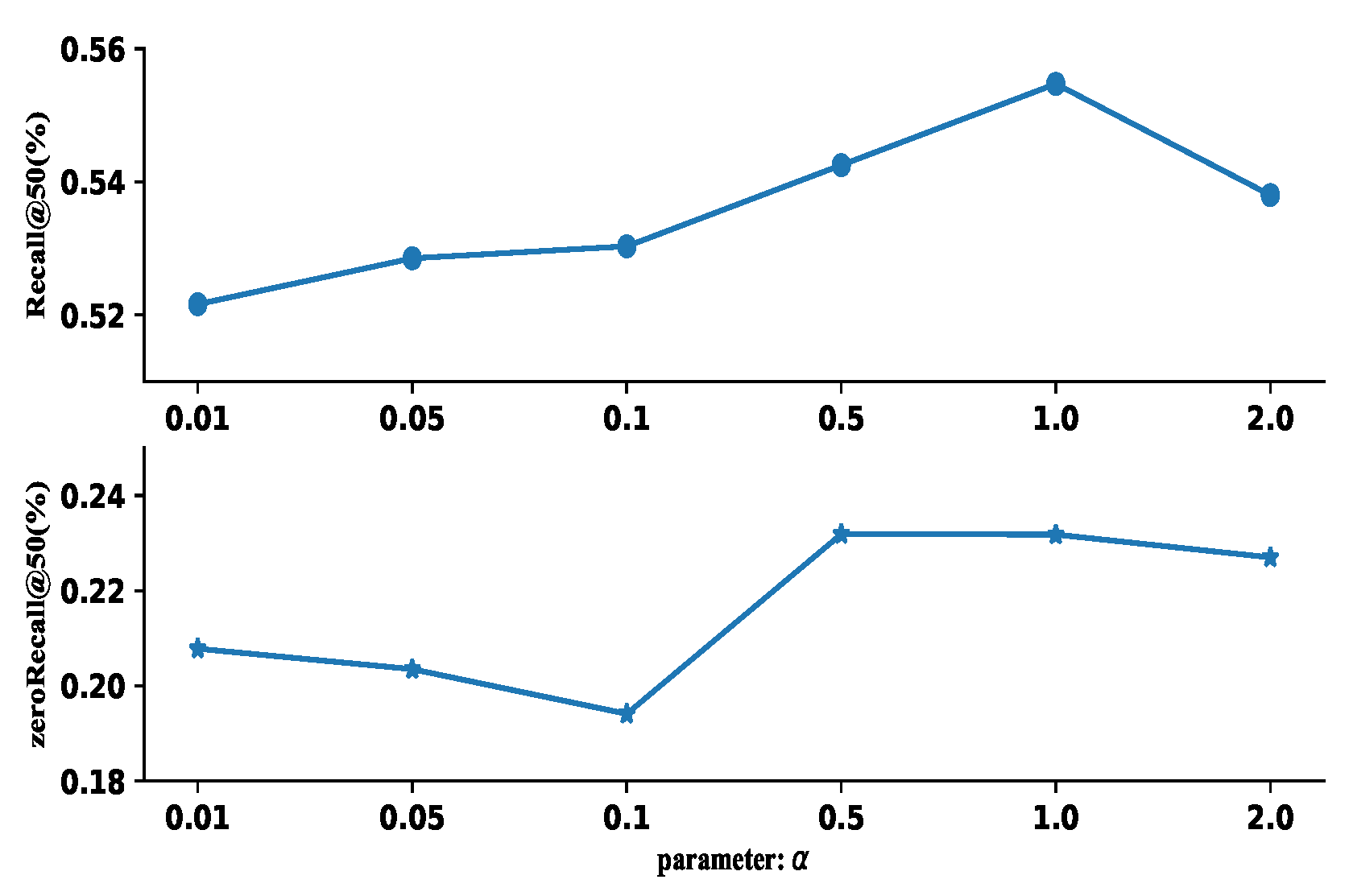
| CCEF (Ours − A + S + G) | 55.5 | 23.2 |
| Entire Set | Zero-Shot | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | Phrase Det | Relationship Det | Phrase Det | Relationship Det | ||||
| R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | R@100 | R@50 | |
| Language Priors [8] | 17.0 | 16.2 | 14.7 | 13.9 | 3.8 | 3.4 | 3.5 | 3.1 |
| Visual Spatial [15] | 18.9 | 16.9 | 15.8 | 14.3 | 3.5 | 3.2 | 3.0 | 2.9 |
| TFR [39] | 19.1 | 17.4 | 16.8 | 15.2 | 7.1 | 5.8 | 6.5 | 5.3 |
| CAI [7] | 19.2 | 17.6 | 17.4 | 15.6 | 6.6 | 6.0 | 6.0 | 5.5 |
| SA-Full [40] | 19.5 | 17.9 | 17.1 | 15.8 | 7.8 | 6.8 | 7.4 | 6.4 |
| Appearance | 16.9 | 15.4 | 14.8 | 13.5 | 5.9 | 5.3 | 5.5 | 5.0 |
| Ours − A + S | 18.2 | 16.3 | 15.9 | 14.2 | 8.4 | 7.1 | 7.6 | 6.5 |
| Ours − A + L | 19.4 | 17.8 | 16.9 | 15.6 | 6.2 | 5.9 | 5.6 | 5.2 |
| Ours − A + S + L | 19.8 | 17.3 | 17.2 | 15.1 | 8.0 | 6.3 | 7.0 | 5.7 |
| CCEF (Ours − A + S + G) | 20.3 | 17.4 | 17.6 | 15.2 | 10.0 | 7.5 | 8.4 | 7.1 |
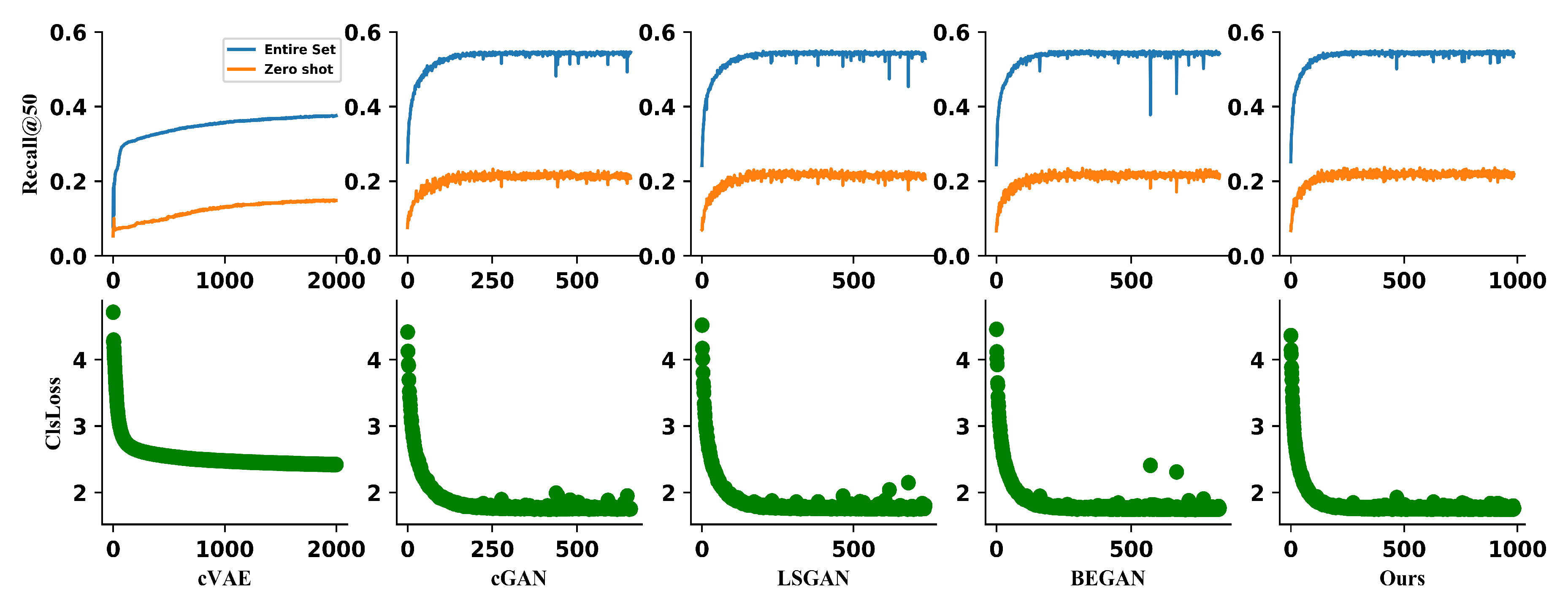
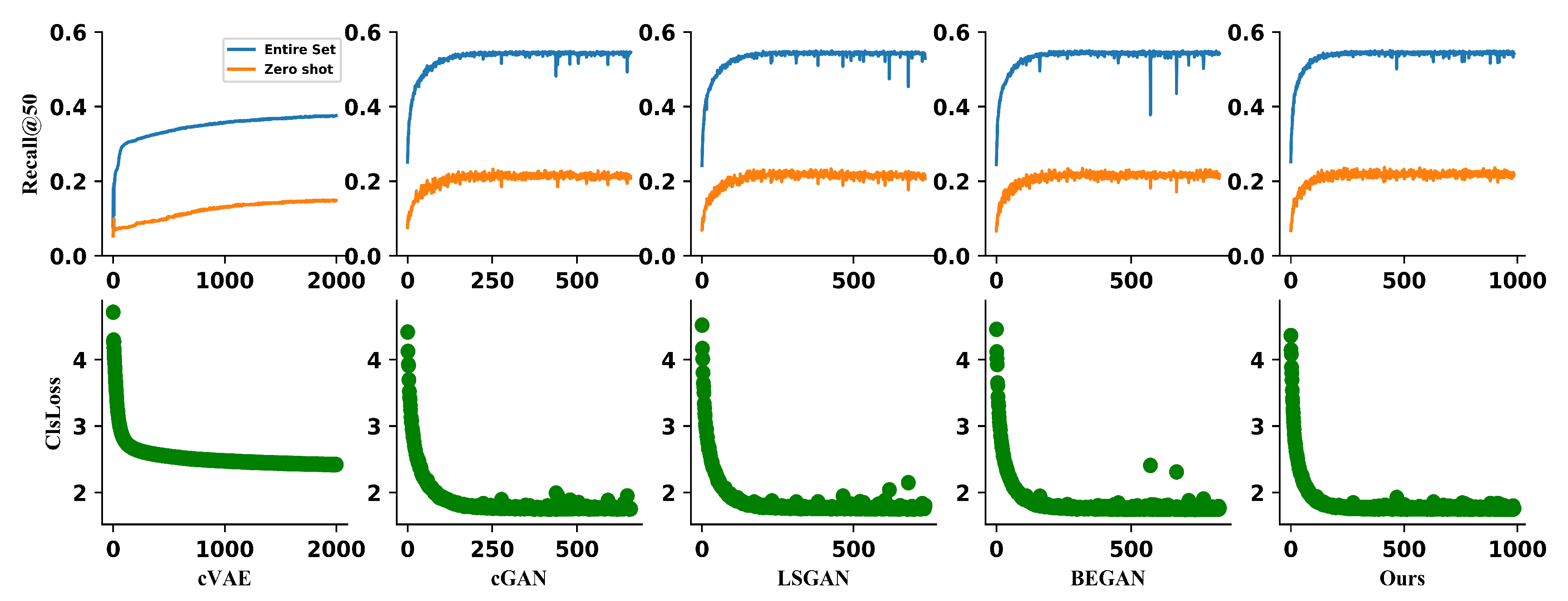
| Methods | Entire Set. | Zero-Shot. |
|---|---|---|
| R@100/50 | R@100/50 | |
| cVAE [44] | 37.5 | 14.8 |
| cGAN [20] | 54.5 | 20.8 |
| LSGAN [42] | 52.9 | 20.7 |
| BEGAN [41] | 54.2 | 21.6 |
| CCEF | 55.5 | 23.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Yang, H.; Li, S.; Wang, X.; Cheng, M. Contextual Coefficients Excitation Feature: Focal Visual Representation for Relationship Detection. Appl. Sci. 2020, 10, 1191. https://doi.org/10.3390/app10031191
Xu Y, Yang H, Li S, Wang X, Cheng M. Contextual Coefficients Excitation Feature: Focal Visual Representation for Relationship Detection. Applied Sciences. 2020; 10(3):1191. https://doi.org/10.3390/app10031191
Chicago/Turabian StyleXu, Yajing, Haitao Yang, Si Li, Xinyi Wang, and Mingfei Cheng. 2020. "Contextual Coefficients Excitation Feature: Focal Visual Representation for Relationship Detection" Applied Sciences 10, no. 3: 1191. https://doi.org/10.3390/app10031191
APA StyleXu, Y., Yang, H., Li, S., Wang, X., & Cheng, M. (2020). Contextual Coefficients Excitation Feature: Focal Visual Representation for Relationship Detection. Applied Sciences, 10(3), 1191. https://doi.org/10.3390/app10031191