Amharic OCR: An End-to-End Learning


 and
and 
Abstract
1. Introduction
2. Material and Methods
2.1. Datasets
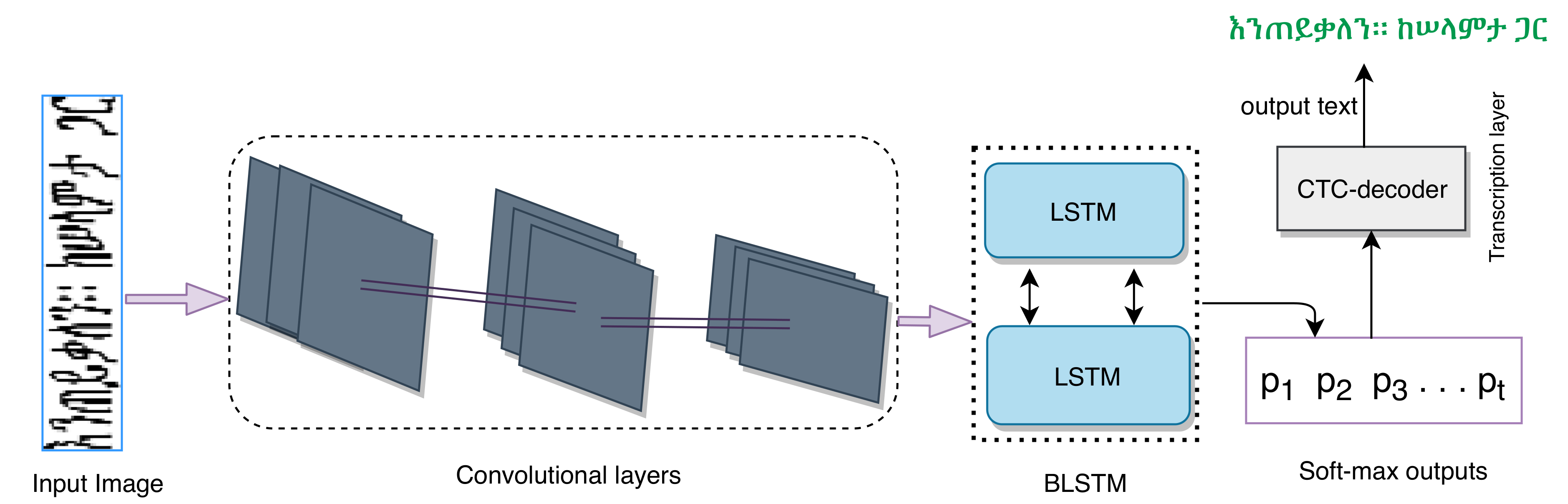
2.2. Proposed Model
3. Experimental Results
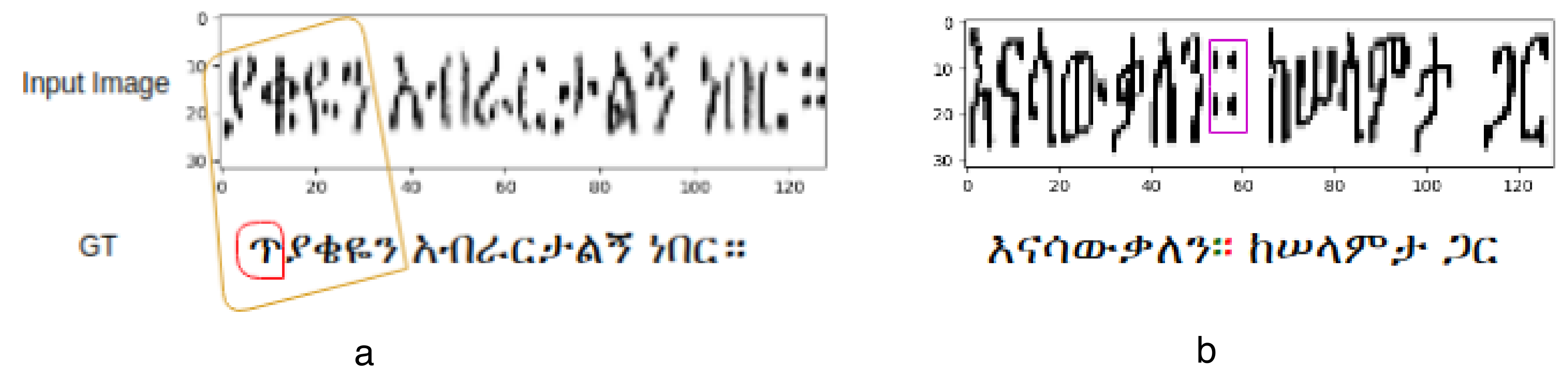
4. Discussion and Analysis of the Results
4.1. Analysis of the Dataset and Results
4.2. Performance Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Meshesha, M.; Jawahar, C. Optical character recognition of amharic documents. Afr. J. Inf. Commun. Technol. 2007, 3. [Google Scholar] [CrossRef]
- The Ethiopian Press Agency. Will Amharic be AU’s Lingua Franca? The Ethiopian Herald. February 2019. Available online: https://www.press.et/english/?p=2654#l (accessed on 10 November 2019).
- Getahun, M. Amharic Text Document Summarization using Parser. Int. J. Pure Appl. Math. 2018, 118, 24. [Google Scholar]
- Meyer, R. Amharic as lingua franca in ethiopia. Lissan J. Afr. Lang. Linguist. 2006, 20, 117–132. [Google Scholar]
- Atelach, A.; Lars, A.; Mesfin, G. Natural Language Processing for Amharic: Overview and Suggestions for a Way Forward. In Proceedings of the 10th Conference on Traitement Automatique des Langues Naturelles, Batzsur-Mer, France, 11–14 June 2003; Volume 2, pp. 173–182. [Google Scholar]
- Belay, B.; Habtegebrial, T.; Liwicki, M.; Belay, G.; Stricker, D. Factored Convolutional Neural Network for Amharic Character Image Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2906–2910. [Google Scholar]
- Bloor, T. The Ethiopic Writing System: A Profile. J. Simpl. Spell. Soc. 1995, 19, 30–36. [Google Scholar]
- Belay, B.; Habtegebrial, T.; Stricker, D. Amharic character image recognition. In Proceedings of the IEEE International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1179–1182. [Google Scholar]
- Belay, B.; Habtegebrial, T.; Liwicki, M.; Belay, G.; Stricker, D. Amharic Text Image Recognition: Dataset, Algorithm and Analysis. In Proceedings of the IEEE International Conference Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1268–1273. [Google Scholar]
- Weldegebriel, H.; Chen, J.; Zhang, D. Deep learning for Ethiopian Ge’ez script optical character recognision. In Proceedings of the 2008 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018; pp. 540–545. [Google Scholar]
- Nirayo, H.; Andreas, N. An Amharic Syllable-Based Speech Corpus for Continuous Speech Recognition. In International Conference on Statistical Language and Speech Processing; Springer: Cham, Switzerland, 2019; pp. 177–187. [Google Scholar]
- Abate, S.T.; Melese, M.; Tachbelie, M.Y.; Meshesha, M.; Atinafu, S.; Mulugeta, W.; Assabie, Y.; Abera, H.; Seyoum, B.E.; Abebe, T.; et al. Parallel Corpora for bi-lingual English-Ethiopian Languages Statistical Machine Translation. In Proceedings of the International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3102–3111. [Google Scholar]
- Bulakh, M.; Hummel, S.; Panini, F. Bibliography of Ethiopian Semitic, Cushitic and Omotic Linguistics XXI: 2017. Int. J. Ethiop. Eritrean Stud. Aethiop. 2018, Aethiopica 21, 217–225. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Worku, A. The Application of Ocr Techniques to the Amharic Script. Master’s Thesis, Addis Ababa University Faculty of Informatics, Addis Ababa, Ethiopia, 1997. [Google Scholar]
- Dereje, T. Optical Character Recognition of Type-Written Amharic Text. Master’s Thesis, School of Information Studies for Africa, Addis Ababa, Ethiopia, 1999. [Google Scholar]
- Hassen, S.; Yaregal, A. Recognition of double sided amharic braille documents. Int. J. Image. Graph. Signal Process. 2017, 9, 1. [Google Scholar]
- Tegen, S. Optical Character Recognition for GE’Ez Scripts Written on the Vellum. Ph.D. Thesis, University of Gondar, Gondar, Ethiopia, 2017. [Google Scholar]
- Million, M. Recognition and Retrieval from Document Image Collections. Ph.D. Thesis, IIIT Hyderabad, Hyderabad, India, 2008. [Google Scholar]
- Betselot, R.; Dhara, R.; Gayatri, V. Amharic handwritten character recognition using combined features and support vector machine. In Proceedings of the International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018; pp. 265–270. [Google Scholar]
- Yaregal, A.; Josef, B. Hmm-based handwritten amharic word recognition with feature concatenation. In Proceedings of the International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 961–965. [Google Scholar]
- Din, I.; Siddiqi, I.; Khalid, S.; Azam, T. Segmentation-free optical character recognition for printed Urdu text. EURASIP J. Image Video Process. 2017, 62. [Google Scholar] [CrossRef]
- Messay, S.; Schmidt, L.; Boltena, A.; Jomaa, S. Handwritten Amharic Character Recognition Using a Convolutional Neural Network. arXiv 2019, arXiv:1909.12943. [Google Scholar]
- Addis, D.; Liu, C.; Ta, D. Printed Ethiopic Script Recognition by Using LSTM Networks. In Proceedings of the International Conference on System Science and Engineering (ICSSE), Taipei, Taiwan, 28–30 June 2018; pp. 1–6. [Google Scholar]
- Rigaud, C.; Burie, J.; Ogier, M. Segmentation-free speech text recognition for comic books. In Proceeding of the International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 3, pp. 29–34. [Google Scholar]
- Reul, C.; Springmann, U.; Wick, C.; Puppe, F. State of the art optical character recognition of 19th century fraktur scripts using open source engines. arXiv 2018, arXiv:1810.03436. [Google Scholar]
- Husnain, M.; Saad Missen, M.; Mumtaz, S.; Jhanidr, M.; Coustaty, M.; Muzzamil, M.; Ogier, J.; Sang, G. Recognition of Urdu Handwritten Characters Using Convolutional Neural Network. Appl. Sci. 2019, 9, 2758. [Google Scholar] [CrossRef]
- Liwicki, M.; Graves, A.; Fern‘andez, S.; Bunke, H.; Schmidhuber, J. A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks. In Proceedings of the 9th International Conference on Document Analysis and Recognition, ICDAR 2007, Curitiba, Brazil, 23–26 September 2007. [Google Scholar]
- Ly, T.; Nguyen, C.; Nguyen, K.; Nakagawa, M. Deep convolutional recurrent network for segmentation-free offline handwritten Japanese text recognition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 7, pp. 5–9. [Google Scholar]
- Ul-Hasan, A.; Ahmed, S.B.; Rashid, F.; Shafait, F.; Breuel, T.M. Offline printed Urdu Nastaleeq script recognition with bidirectional LSTM networks. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1061–1065. [Google Scholar]
- Messina, R.; Louradour, J. Segmentation-free handwritten Chinese text recognition with lstm-rnn. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 171–175. [Google Scholar]
- Breuel, T. High performance text recognition using a hybrid convolutional-lstm implementation. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 11–16. [Google Scholar]
- Wu, Y.; Yin, F.; Chen, Z.; Liu, L. Handwritten Chinese text recognition using separable multi-dimensional recurrent neural network. In In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 79–84. [Google Scholar]
- Graves, A.; Liwicki, M.; Bunke, H.; Schmidhuber, J.; Fernandz, S. Unconstrained on-line handwriting recognition with recurrent neural networks. In Proceedings of the Twenty-Second Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; pp. 577–584. [Google Scholar]
- Castro, D.; Bezerra, B.L.; Valença, M. Boosting the deep multidimensional long-short-term memory network for handwritten recognition systems. In Proceedings of the 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 127–132. [Google Scholar]
- Zhang, J.; Du, J.; Dai, L. A gru-based encoder-decoder approach with attention for online handwritten mathematical expression recognition. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 902–907. [Google Scholar]
- Valy, D.; Verleysen, M.; Chhun, S. Text Recognition on Khmer Historical Documents using Glyph Class Map Generation with Encoder-Decoder Model. In Proceedings of the ICPRAM, Prague, Czech Republic, 19–21 February 2019. [Google Scholar]
- Ahmad, I.; Fink, G. Handwritten Arabic text recognition using multi-stage sub-core-shape HMMs. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 329–349. [Google Scholar] [CrossRef]
- Ghosh, R.; Vamshi, C.; Kumar, P. RNN based online handwritten word recognition in Devanagari and Bengali scripts using horizontal zoning. Pattern Recognit. 2019, 92, 203–218. [Google Scholar] [CrossRef]
- Hijazi, S.; Kumar, R.; Rowen, C. Using Convolutional Neural Networks for Image Recognition; Cadence Design Systems Inc.: San Jose, CA, USA, 2015. [Google Scholar]
- Graves, A.; Fernandez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Glasmachers, T. Limits of end-to-end learning. arXiv 2017, arXiv:1704.08305. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Shammah, S. Failures of gradient-based deep learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3067–3075. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Printed | Synthetic | ||
|---|---|---|---|
| Font Type | Power Geez | Power Geez | Visual Geez |
| Number of samples | 40,929 | 197,484 | 98,924 |
| No. of test samples | 2907 | 9245 | 6479 |
| No. of training samples | 38,022 | 188,239 | 92,445 |
| No. of unique chars. | 280 | 261 | 210 |
| Network Layers | Kernel Size | Stride | Feature Maps |
|---|---|---|---|
| Convolution | 64 | ||
| Max-Pooling | - | ||
| Convolution | 128 | ||
| Max-Pooling | - | ||
| Convolution | 256 | ||
| BatchNormalization | - | - | - |
| Convolution | 256 | ||
| BatchNormalization | - | - | - |
| Max-Pooling | - | ||
| Convolution | 512 |
| Network Layers (Type) | Hidden Layer Size |
|---|---|
| BLSTM | 128 |
| BLSTM | 128 |
| Soft-Max | No. class = 281 |
| Image Type | Font Type | Test Data Size | CER (%) |
|---|---|---|---|
| Printed | Power Geez | 2907 | 1.59 |
| Synthetic | Visual Geez | 6479 | 1.05 |
| Power Geez | 9245 | 3.73 |
| No. of Text-Lines | Image Type | Font Type | CER (%) | |
|---|---|---|---|---|
| Addis [24] * | 12 pages | printed | - | 2.12% |
| Belay [9] | 2,907 | Printed | Power Geez | 8.54% |
| Belay [9] | 9,245 | Synthetic | Power Geez | 4.24% |
| Belay [9] | 6,479 | Synthetic | Visual Geez | 2.28% |
| Ours | 2,907 | Printed | Power Geez | 1.56% |
| Ours | 9,245 | Synthetic | Power Geez | 3.73% |
| Ours | 6,479 | Synthetic | Visual Geez | 1.05% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belay, B.; Habtegebrial, T.; Meshesha, M.; Liwicki, M.; Belay, G.; Stricker, D. Amharic OCR: An End-to-End Learning. Appl. Sci. 2020, 10, 1117. https://doi.org/10.3390/app10031117
Belay B, Habtegebrial T, Meshesha M, Liwicki M, Belay G, Stricker D. Amharic OCR: An End-to-End Learning. Applied Sciences. 2020; 10(3):1117. https://doi.org/10.3390/app10031117
Chicago/Turabian StyleBelay, Birhanu, Tewodros Habtegebrial, Million Meshesha, Marcus Liwicki, Gebeyehu Belay, and Didier Stricker. 2020. "Amharic OCR: An End-to-End Learning" Applied Sciences 10, no. 3: 1117. https://doi.org/10.3390/app10031117
APA StyleBelay, B., Habtegebrial, T., Meshesha, M., Liwicki, M., Belay, G., & Stricker, D. (2020). Amharic OCR: An End-to-End Learning. Applied Sciences, 10(3), 1117. https://doi.org/10.3390/app10031117