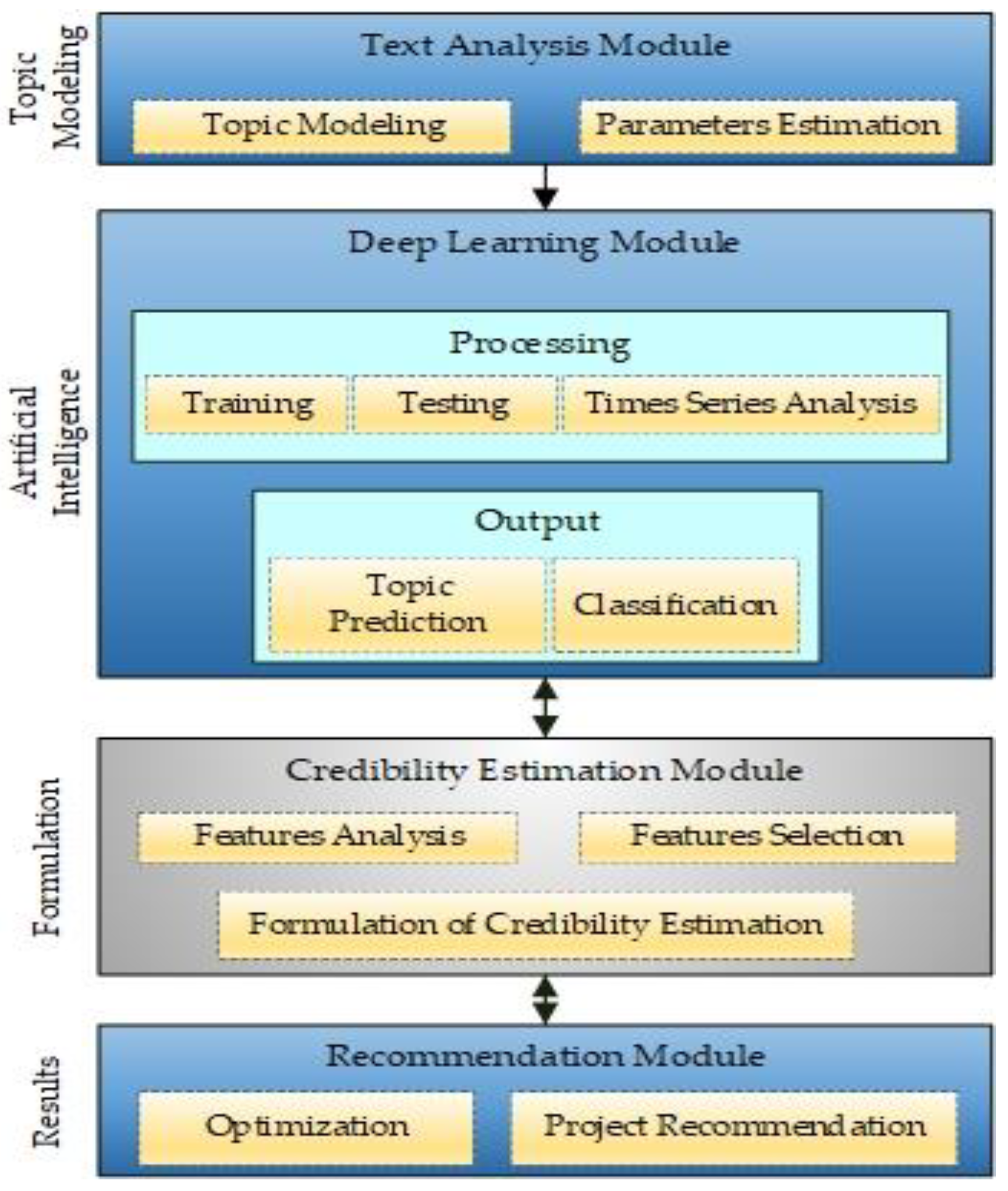
3.4. Project Credibility Estimation
In this section, we present a detailed explanation of the credibility module. The overall process of deriving formulas steps by steps to estimate the credibility of a project is delivered. Trust is an ultimate significant element in any domain that helps to gain the customer’s confidence. It is valid for e-commerce sites and online social networks, as well. Therefore, multiple trust-aware recommender systems are being proposed that adopt user’s trust statements and their personal or profile data to improve the quality of recommendations considerably.
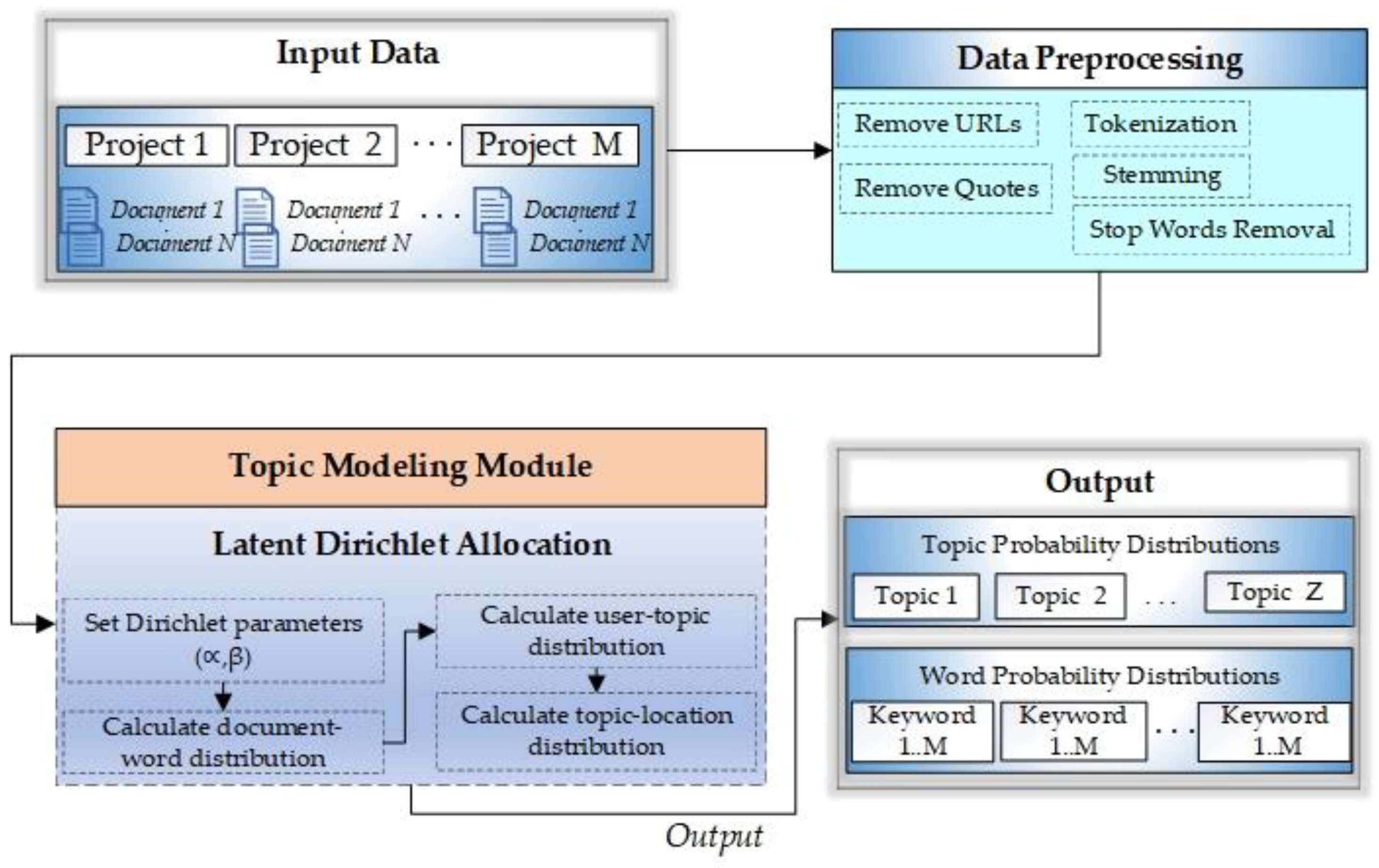
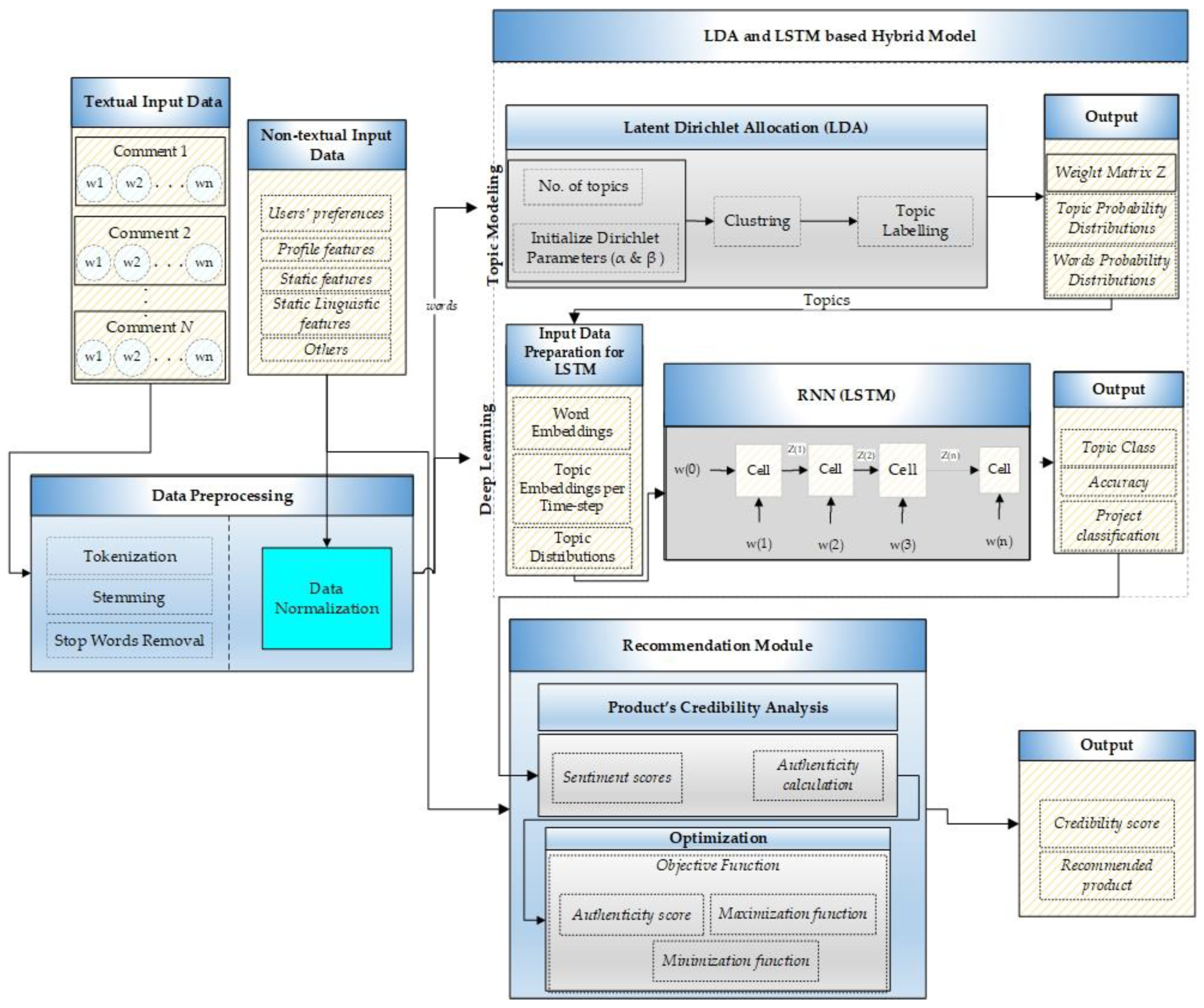
As we target crowdfunding projects, we aim to formulate an equation to calculate any project’s credibility before recommending it to a user. A highly credible recommendation is a project that most likely reflects the user-defined interests and categories with higher chances of its delivery. It must also reflect the lowest probability of factors that can disturb the project’s trustworthiness, such as communication delays and less frequent updates, etc. A credible project can precisely be defined as a project with the maximum likelihood of completing and delivering to the backers within the promised period. Various factors are associated with a project’s credibility; we define and link a documents’ credibility with its estimated authenticity score range. A project’s authenticity is a multi-fold view of different and latent aspects, such as latent aspects of a creator’s profile and all his or her external social links. It also involves the frequency of account usage and updates from creators. In other words, keeping the backers up to date with each development or progress in the project can earn more credibility points. In addition to that, factors such as the most frequent keywords used, promises related to product delivery or rewards delivery, and investors’ sentiments are also crucial. These sentiments of backers are discovered during the LDA process to find latent topics in their comments. There can be multiple topics in a document, and each topic represents a particular class of sentiments. As shown in
Table 2 [
45], we identified 12 topic classes labeled Topic-1 to Topic-12. The number of topics was varied between 2 and 30 during the experiments to find the optimal number of topics.
The coherence score was increasing as the number of topics was growing. We selected and evaluated the topics based on the coherence score before flattening out, i.e., 12 topics. After training LSTM, the classification of each comment is done into one of these topic classes. We have divided these sentiment classes into three categories, and this division is customized based on the problem, i.e., credibility assessment. These categories are referred to as A, B, and C. Category A is responsible for extremely negative comments, which is represented by Topic-4 to Topic-7; category B means negative reviews, which is characterized by Topic-1 to Topic-3; and category C is representing positive or neutral reviews which are represented by Topic-8 to Topic-12. More emphasis is laid on the negative comments because the negative comments and reviews significantly impact the viewer’s mind and decision-making process than positive comments regarding credibility or trust. Therefore, we divided the negative comments into extremely unfavorable class A and negative class B.
To evaluate our selected topics, we measured the agreement between two raters using Cohen’s Kappa coefficient [
46] and followed the process mentioned in [
47] to assess our LDA model. Two students (student A and student B) from different laboratories who were unaware of our proposed methodology and had no prior knowledge about the list of LDA topics were requested to extract topics from 250 sampled reviews.
Student A and student B were not allowed to communicate or discuss their thought process behind labeling each review. Student A and student B could identify 9 and 11 topics, respectively. Student A had seven topics in common with LDA, whereas student B had ten topics common with LDA. Among all the topics, we selected six topics that were most common among the two students’ topics to measure our LDA model’s reliability, as shown in
Table 3. As we can see from
Table 3, student A and student B have a high degree of agreement for all six topics. The LDA model and respective students’ contract is also relatively high, as indicated by the Kappa coefficient.
Category A is for extremely negative comments and severe nature and typically reflects anger by filing lawsuits or complaints. Category B is for relatively simple and generic negative comments that reflect emotions of sadness or disappointment. The classification is based on the nature of malicious content. All other comments belong to category C. The purpose behind this arrangement with more emphasis upon negative comments is the underlying prominence or impact of the malicious content on a product’s credibility.
Table 4 summarizes the parameters used for authenticity measures with their definitions and notations. In addition to sentiments, we have also included other relevant and impactful features such as readability of content referred to as readScore, the existence of a profile picture, etc.
Hence, by incorporating all the factors mentioned above, we have formulated an equation that helps calculate a given project’s authenticity. To figure the authenticity of a project, it must first fulfill the eligibility criteria given in Equation (1). Once a project passes the eligibility criteria, Equation (2) is used to calculate the authenticity of it. The eligibility criteria are based on a project’s content and partially on the profile associated features in Equation (1).
Here,
represents the weight associated with the existence of a profile picture. The weightage assigned to
is lower than the weightage of
because of the level of impact asserted by each parameter. The value of α is set to 0.4. From the above Equation, we define the ranges for both the parameters.
Hence from above Equations (2) and (3), we have
Therefore, based on Equation (1) and following the conditions in Equation (4), we can list all possible scenarios of eligibility in
Table 5. The content in
is extremely unfavorable as one can sense fears, suspicion, and frustrations in it. Therefore, this category is handled independently to alleviate the probability of any unreliable recommendation. For a reliable project, it must be free from any of the comments in
category. Thus, we used this to set our eligibility criteria. The objective function targets getting the maximum percentage of positive comments, i.e., category C. It also targets to get the maximum number of social links of the project’s creator.
In crowdfunding, a backer’s faith and confidence rely on the content authenticity and creator’s limpidity. Therefore, these aspects are fundamental to a project’s success.
Table 4 shows that the factor delay
comm is one prime feature of the project, representing a creator’s communication styles such as his updates and comments. This feature, delay
comm can be defined as the average time gap between any consecutive posts by the project creator in an update or a comment. It shows the communication rate of a project creator towards the development of a project. Due to the impact of delay
comm, the project’s authenticity will be damaged if the communication delay upsurges.
After observing and estimating all the relevant features, all the values are normalized between 0 to 1. Here, 0 represents the least authentic feature, and 1 illustrates the highly authentic feature. In other words, these values depict the trustworthiness of a project. Equation (5) below describes this relationship, i.e., the higher the authenticity is, the higher the reliability of a project turns out.
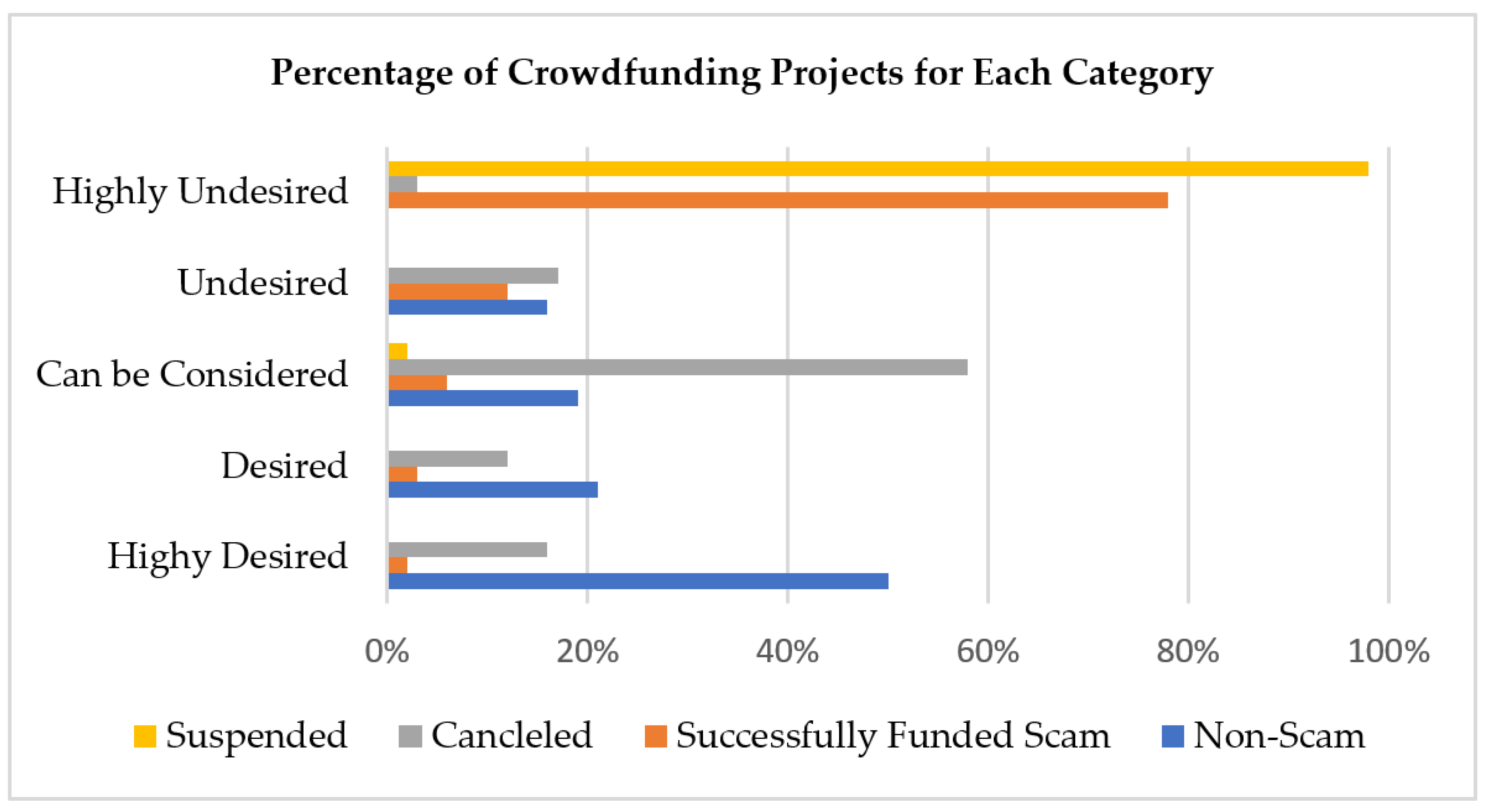
As a result, a project has different credibility levels, i.e., extremely low, low, normal, high, and extremely high credibility. Each credibility level falls into another degree of authenticity range. The extremely low and low credible projects have higher chances of getting forged. It means the projects with lower credibility levels have the utmost possibilities of fighting with non-payments, no communication or communication delays, delays in posts by the creator in the form of updates or comments, and late or no deliveries. Therefore, such projects are not favorable to be recommended to backers to invest in. Instead, a project with a higher credibility level (high or extremely high credibility) is undoubtedly a profitable project recommended to backers. It has the maximum probability of on-time delivery with more consistent patterns of communication throughout its duration.
For any recommendation system, the percentage of positive and negative reviews is pre-eminent as it reflects a user’s attitude towards a product. Therefore, we assess the following points wisely:
A fundamental requirement for a product to be reliable is to have a maximum percentage of positive comments and a minimum negative comments rate. A product with a relatively high number of negative reviews becomes less favorable. Therefore, Equations (6) and (7) represent the relationship of comments with authenticity.
and
where the percentage of positive and negative comments is referred to as
PosCi and
NegBi, respectively.
The accessibility of social and profile information such as profile links, display pictures, number of friends or followers, etc., are persuasive and compelling elements for a profile’s credibility. Thus, the more a project creator shares personal and relevant information, the easier it gets to earn trust. Therefore, we can say,
In the above Equation (8), LinksExt is the number of links a person provides for his/her external social media networks, such as Facebook, Twitter, etc.
- 3.
The clarity of speech also plays a vital role in trust development. If the content is easy to follow and understand, a user will easily connect and comprehend it. It helps diminish the misunderstandings, and the confidence level of the reader increases. Therefore,
In Equation (9), readScore is the readability score of a document. If readScore is high, the document is difficult to follow or to understand. The lower the readability score is, the higher probability is to understand it fast.
- 4.
The communication patterns are the key to trust maintenance. A smoother and consistent communication can help people to put their trust in it. If there is no communication from the product creator, it will cause frustration and anger in backers and lose their interests. Therefore, the communication delay should be minimized between the creator’s posts.
In Equation (10), delaycomm is the average delay between any successive posts, i.e., comments or updates by the project creator. The higher delays will negatively affect project authenticity.
- 5.
Hence, we can summarize the factors mentioned above as
By combining Equations (11) and (12), Equation (13) is formulated as below,
- 6.
We divide the Equation into two parts; the similar factors based on their priority are combined. Hence, Equation (14) combines sentiment-based factors.
This factor is only associated with product comments. For higher authenticity,
PosCi has to be greater than
NegBi. We have combined other features related to the product or creator into one Equation as,
- 7.
Then combine all the factors in one place results into Equation (16) as below,
- 8.
At the final step, we apply optimizations and formulate our objective functions. We have both maximization and minimization functions. The maximization function maximizes the values for favorable factors, and the minimization function underrates the cost of the least desirable parameters. Hence, we can now formulate the credibility estimation in terms of maximization and minimization functions in Equation (17).
For the above Equation, we can define the ranges of all the parameters as below in Equations (18)–(22).
The value of
was decided based on the maximum number of external links provided by the project creator. In our case, the maximum number of links a person can provide is considered to be 9. Therefore,
can have any value between 0 and 9.
Following
Table 6, we can define the maximum and minimum ranges of each parameter.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}