The Assisted Positioning Technology for High Speed Train Based on Deep Learning


Abstract
:1. Introduction
2. Related Works
2.1. Object Detection
2.2. Sample Expansion
3. The Construction of Data Set Based on DCGAN
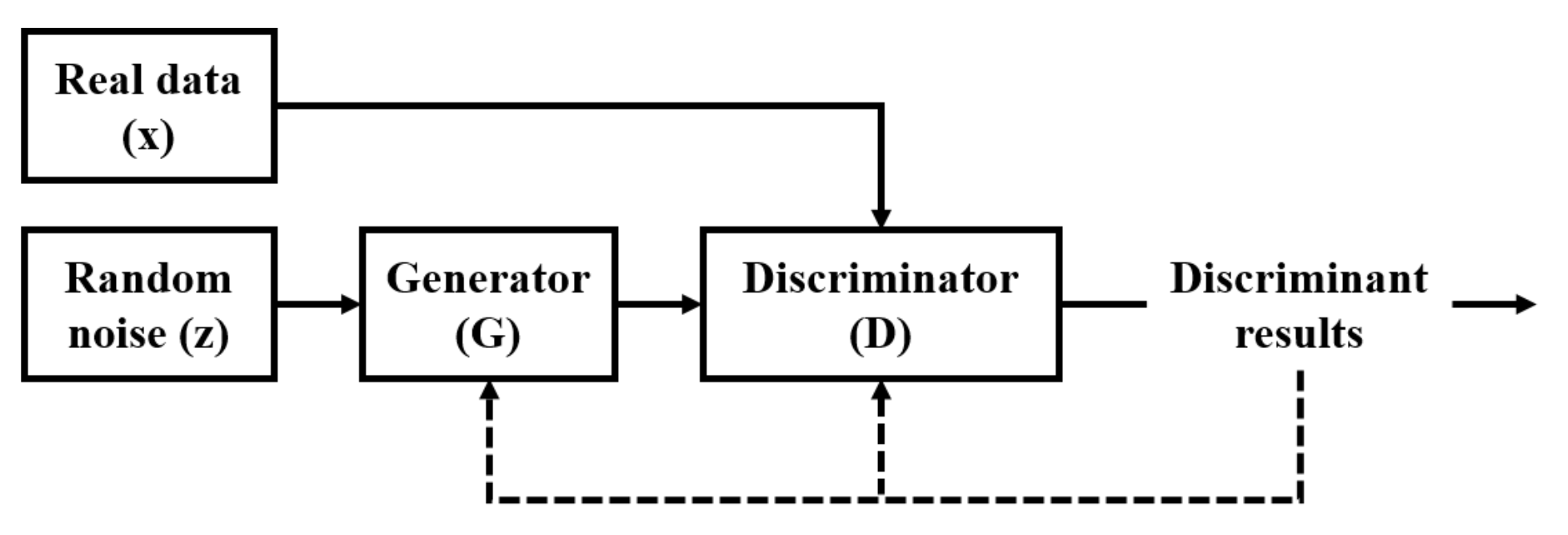
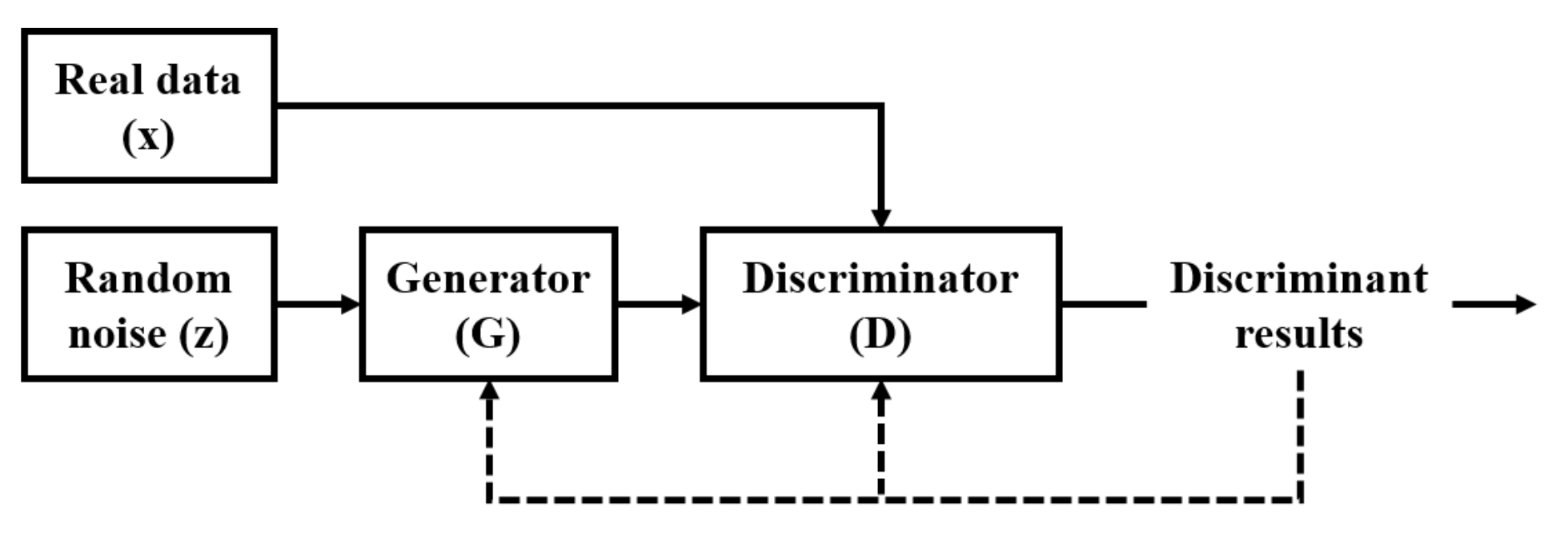
3.1. DCGAN Algorithm
- (a)
- The input of G is random noise z and the output of it is the generated image . The input of D is real data x and the generated image , and the output of it is and .
- (b)
- The loss function of D is calculated as follows:where m is the number of samples taken each time. The cross entropy of real samples and generated samples is calculated, and the average value of cross entropy of all samples is calculated as the loss function of D to optimize D.
- (c)
- The loss function of G is calculated as follows:Formula (2) shows that the cross entropy of the generated samples after D is calculated as the loss function of G to optimize G.
- (d)
- In the training process, G tries to generate fake data that are as similar as possible to the real data to cheat D, and D tries its best to distinguish between the generated fake data and real data. Finally, they form a game process.
- (e)
- Repeat the above steps until the network reaches Nash equilibrium [37], that is .
3.2. The Construction of Data Set
4. The Detection Model of Kilometer Post Based on an Improved SSD Algorithm
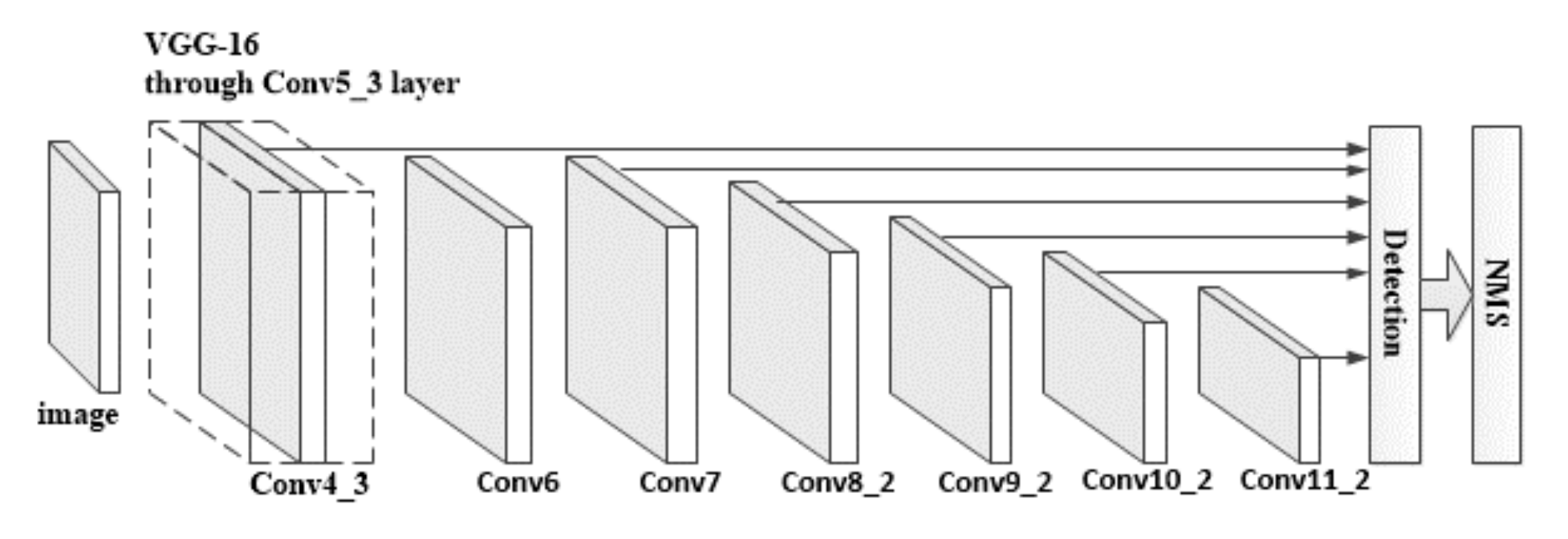
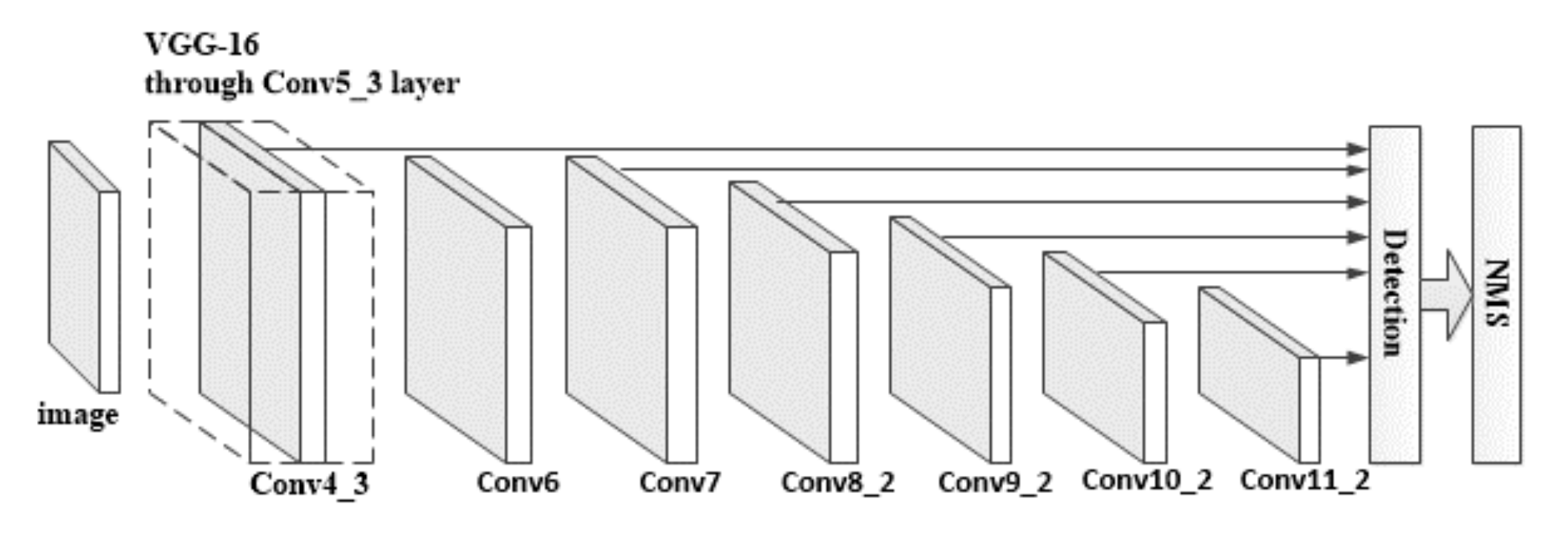
4.1. SSD Algorithm
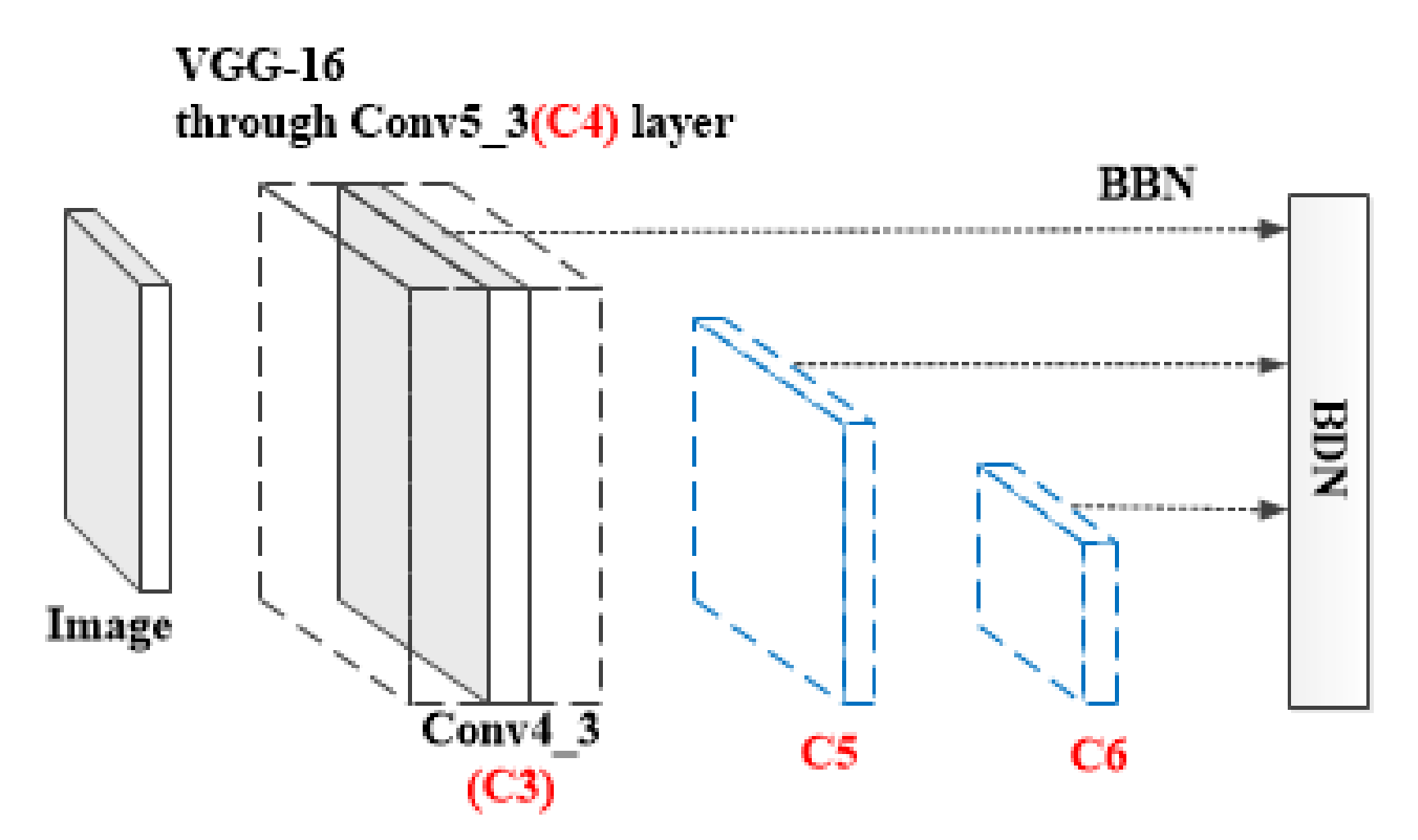
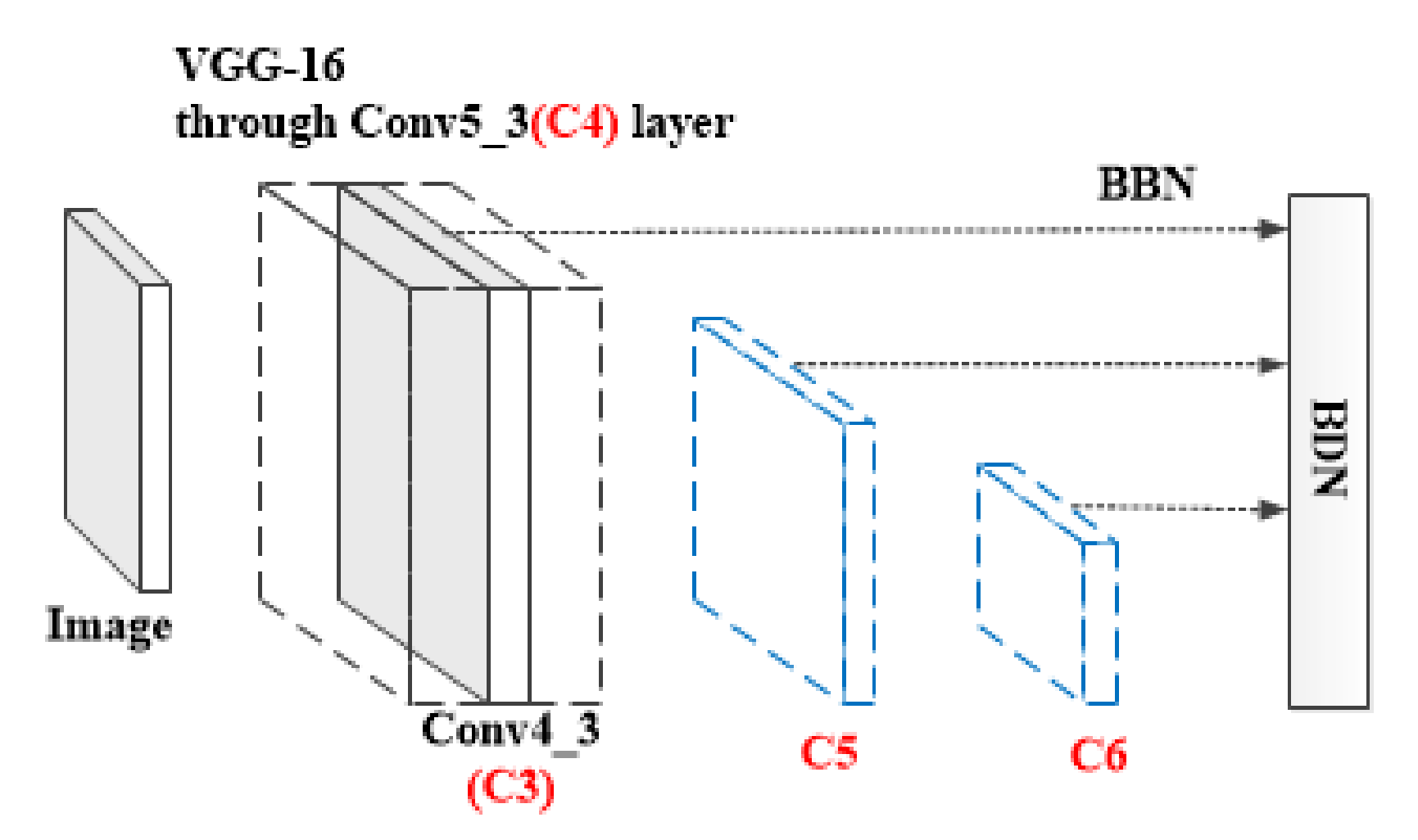
4.2. The Detection Model of Kilometer Posts Based on an Improved SSD Algorithm
5. Analysis of the Experimental Results
5.1. The Influence of Data Set
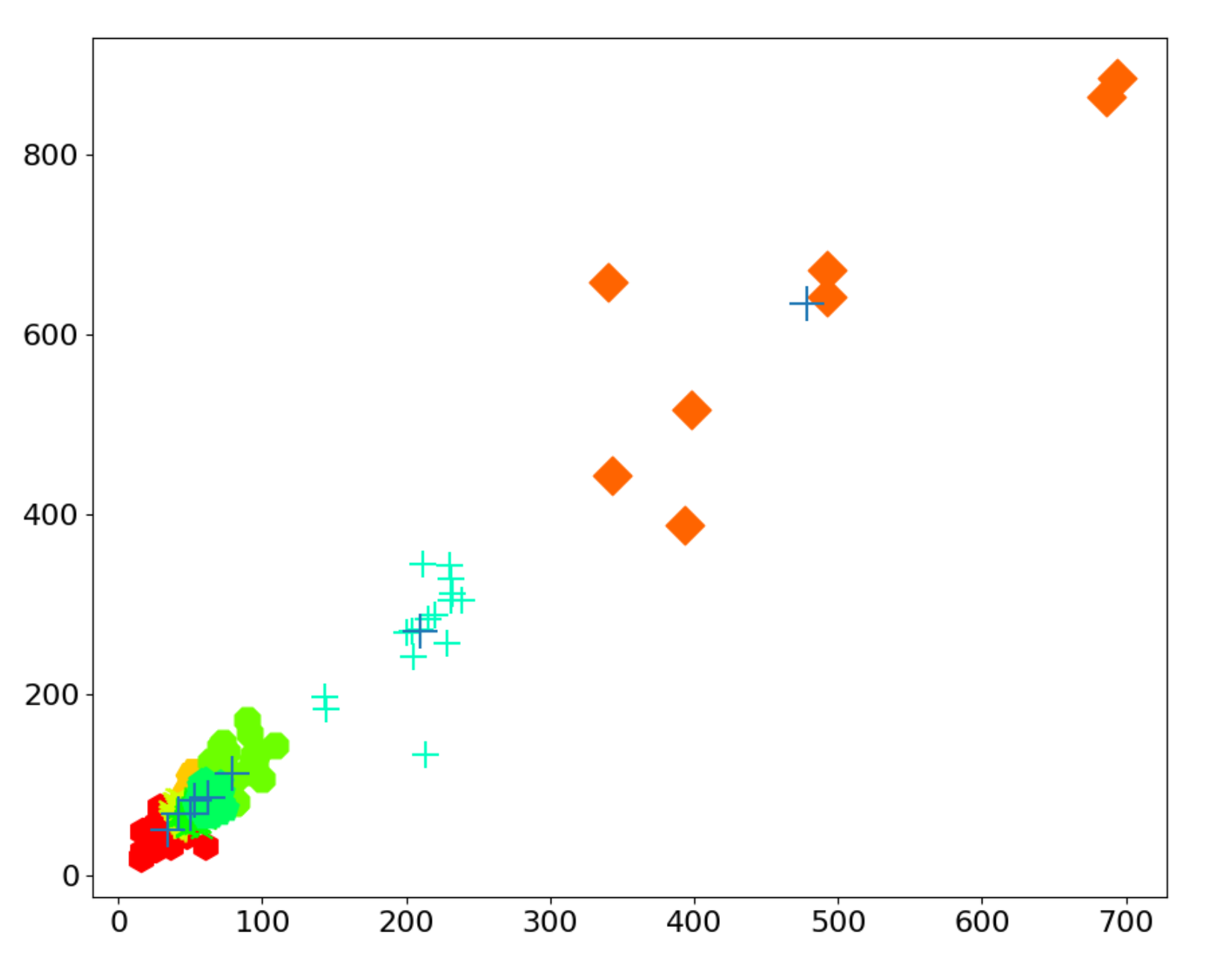
5.2. The Influence of Model Structure and Anchor Boxes
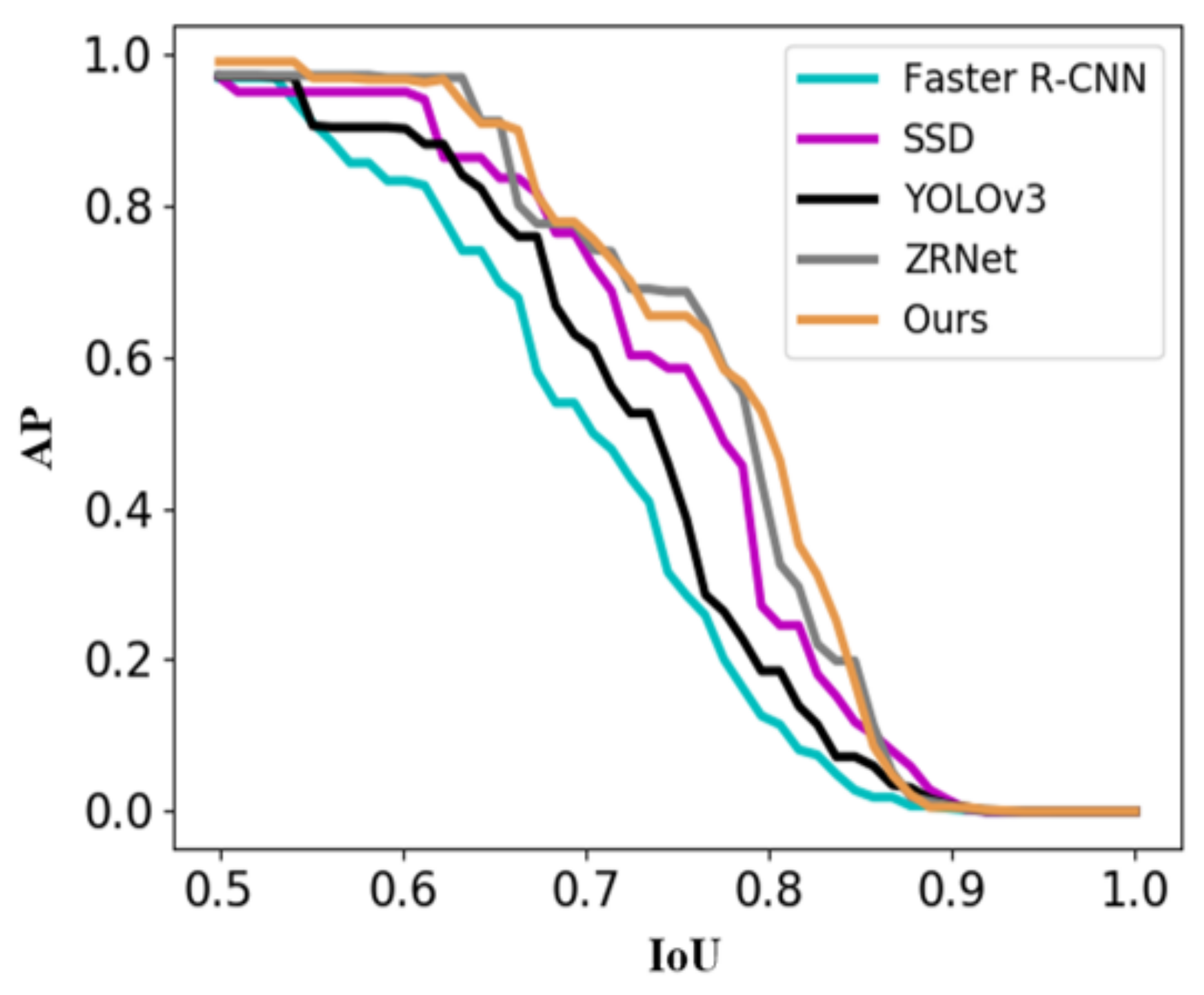
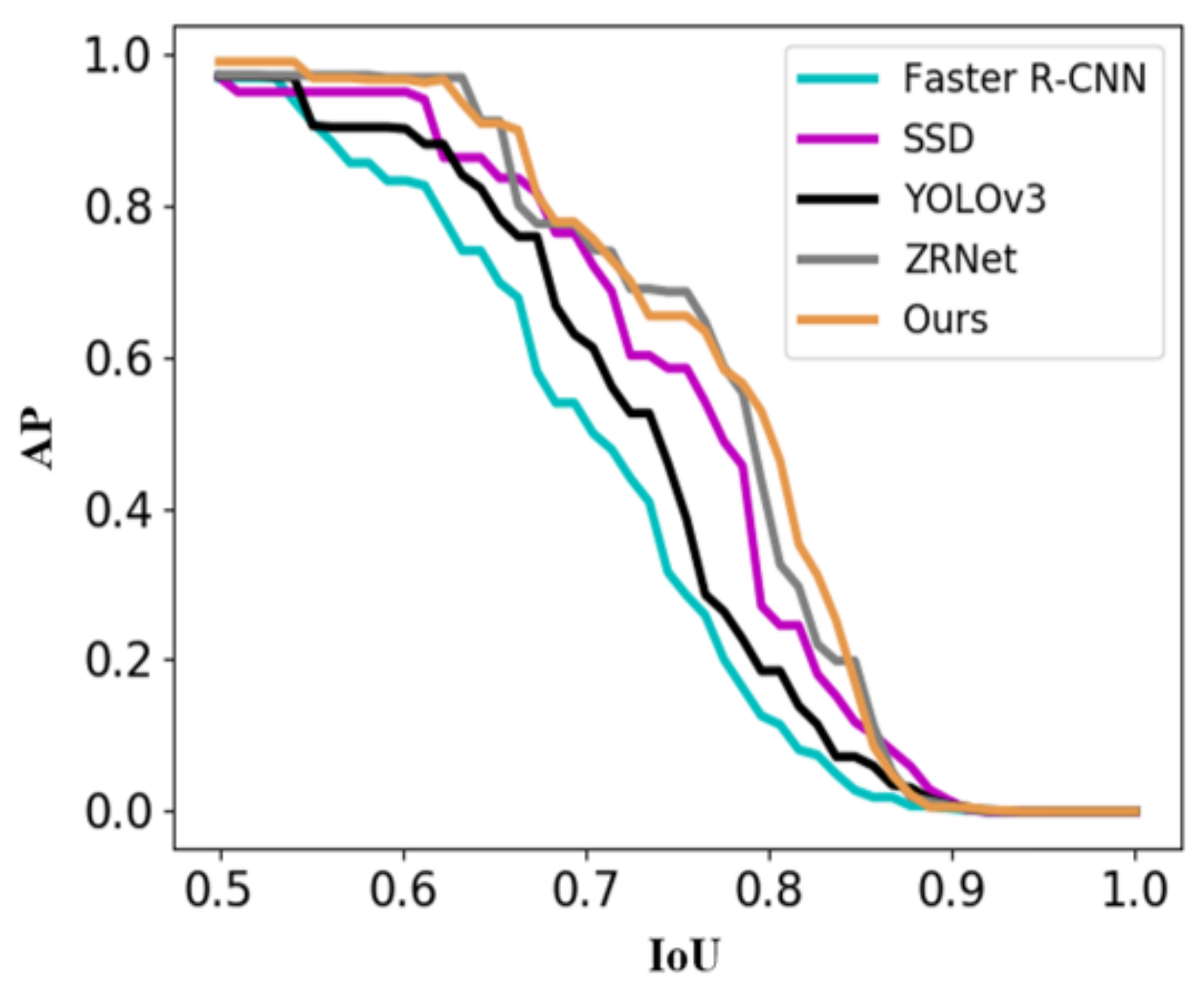
5.3. The Analysis of Comparative Experiment and Model Stability
5.4. The Detection Result of Kilometer Posts
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cai, B. Train Integrated Positioning Methods for Low-cost Train Control System. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2010. [Google Scholar]
- Yue, C.; Cui, J. Chinese High Speed Railway Train Positioning Technology and Application Requirements for Beidou Satellite Positioning. RSCE 2019, 16, 1–4. [Google Scholar]
- Zhang, A.; Zheng, P.; Li, H.; Cai, L. Design of Railway Positioning and Auxiliary Driving Safety System Based on Beidou Satellite Navigation Technology. Jiangxi Sci. 2017, 35, 805–809. [Google Scholar]
- Gao, J. Research on Train Positioning Technology Based on Bei Dou Navigation System. RSCE 2020, 17, 71–73. [Google Scholar]
- Ng, K.; Zhou, J.; Chu, M.; Leung, K. A Train-Once Approach for Positioning Estimation Using the Directional Propagation Model. IEEE Trans. Veh. Technol. 2008, 57, 2242–2256. [Google Scholar] [CrossRef]
- Li, W.; Hou, L. Research on High-speed Train Positioning Technology Based on Satellite Navigation System. Inf. Control 2016, 45, 479–486. [Google Scholar]
- Zhu, L. Antenna Modeling and Optimization Research of Rail Traffic Balise Transmission System. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2018. [Google Scholar]
- Jiang, W.; Chen, S.; Cai, B.; Wang, J.; ShangGuan, W.; Rizos, C. A Multi-Sensor Positioning Method-Based Train Localization System for Low Density Line. IEEE Trans. Veh. Technol. 2018, 67, 10425–10437. [Google Scholar] [CrossRef]
- Liu, S.; Chen, G.; Wang, D.; Xu, C. Train integrated positioning method based on GPS/DR/MM. J. Railw. Sci. Eng. 2018, 15, 474–482. [Google Scholar]
- Yang, Y.; Guang, C.; Jing, W.; Li, D. Research on train integrated positioning based on grey neural network. J. Meas. Sci. Instrum. 2019, 10, 143–149. [Google Scholar]
- Shangguan, W.; Xie, C.; Jiang, W. Optimization Method for Integrated Train Positioning Accuracy Based on IMU Calibration Compensation. J. China Railw. Soc. 2020, 42, 57–64. [Google Scholar]
- Liu, S. Research on Train Location Algorithm Based on GNSS and Image Feature Recognition. Master’s Thesis, Lanzhou Jiaotong University, Lanzhou, China, 2018. [Google Scholar]
- Guo, B. Research on Autonomous Train Location Method Based on Image Features. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2008. [Google Scholar]
- Reliable Data Systems International Ltd. Available online: http://www.rdsintl.com (accessed on 1 November 2020).
- Tan, S.; Hu, Z. An effective Integration method for license plate location based on HSV color space. Comput. Appl. Chem. 2011, 28, 105–108. [Google Scholar]
- Liu, B. Research on Edge and Region Information Extraction for Polarimetric SAR Images. Ph.D. Thesis, Shanghai Jiaotong University, Shanghai, China, 2015. [Google Scholar]
- Dong, J. Study on Fast and Reliable Pattern Match. Ph.D. Thesis, National University of Defense Technology, Hunan, China, 2015. [Google Scholar]
- Zhou, F.; Jin, L.; Dong, J. Review of convolutional neural network. Chin. J. Comput. 2017, 40, 1229–1251. [Google Scholar]
- Zhang, J.; Wang, H.; Guo, Y.; Hu, X. Review of deep learning. Appl. Res. Comput. 2018, 35, 1921–1928. [Google Scholar]
- Zhang, W.; Yang, P. Real time traffic sign detection based on improved SSD algorithm. Mod. Electron. Tech. 2020, 43, 90–92. [Google Scholar]
- Castro-Zunti, R.D.; Yépez, J.; Ko, S.-B. License plate segmentation and recognition system using deep learning and OpenVINO. IET Intell. Transp. Syst. 2020, 14, 119–126. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 12 December 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards realtime object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems, Guangzhou, China, 12 June 2017; pp. 1137–1149. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision 8, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhang, X. SSD Algorithm and Its Application in the Abnormal Object Detection of Railway Scenes. Master’s Thesis, North China University of Technology, Beijing, China, 2019. [Google Scholar]
- Xie, B.; Zhu, B.; Fan, X. Object detection method based on SSD convolution network in aerial images. J. Optoelectron. Laser 2019, 30, 407–414. [Google Scholar]
- Chen, Z.; Wu, K.; Li, Y.; Wang, M.; Li, W. SSD-MSN: An Improved Multi-Scale Object Detection Network Based on SSD. IEEE Access 2019, 7, 80622–80632. [Google Scholar] [CrossRef]
- Gong, M.; Shu, Y. Real-time Detection and Motion Recognition of Human Moving Objects Based on Deep Learning and Multi-scale Feature Fusion in Video. IEEE Access 2020, 99, 25811–25822. [Google Scholar] [CrossRef]
- Dai, X.; Yuan, X.; Pei, L.; Wei, X. Deeply Supervised Z-Style Residual Network Devotes to Real-Time Environment Perception for Autonomous Driving. IEEE Intell. Transp. 2020, 21, 2396–2408. [Google Scholar] [CrossRef]
- Zhang, Y. A survey on generative adversarial networks. Electron. Des. Eng. 2018, 26, 34–37. [Google Scholar]
- Sun, D. Small Sample Visual Defect Detection Based on DCGAN. Master’s Thesis, Jilin University, Jilin, China, 2019. [Google Scholar]
- Du, Y. Study and Application on The Structure Improved Deep Convolutional Generative Adversarial Networks. Master’s Thesis, Chongqing University of Posts and Telecommunications, Chongqing, China, 2019. [Google Scholar]
- He, C. Image Generation Oriented Deep Convolution Generation Adversarial Network. Master’s Thesis, Yunnan University, Yunnan, China, 2019. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Xie, S. Nash Equilibrium Theory; Shanghai University of Finance and Economics Press: Shanghai, China, 1999. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-ScaleImage Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sheng, H.; Huang, M.; Yang, J. Laboratory personnel statistics and management system based on Faster R-CNN and IoU optimization. J. Comput. Appl. 2019, 39, 1669–1674. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Different Data Set Size | Accuracy |
|---|---|
| 60 images | 75.65% |
| 500 images | 98.92% |
| Different Model Structure | Accuracy | Time |
|---|---|---|
| ZRNet model in [31] | 97.13% | 49.69 ms |
| Our model in this paper | 97.81% | 36.12 ms |
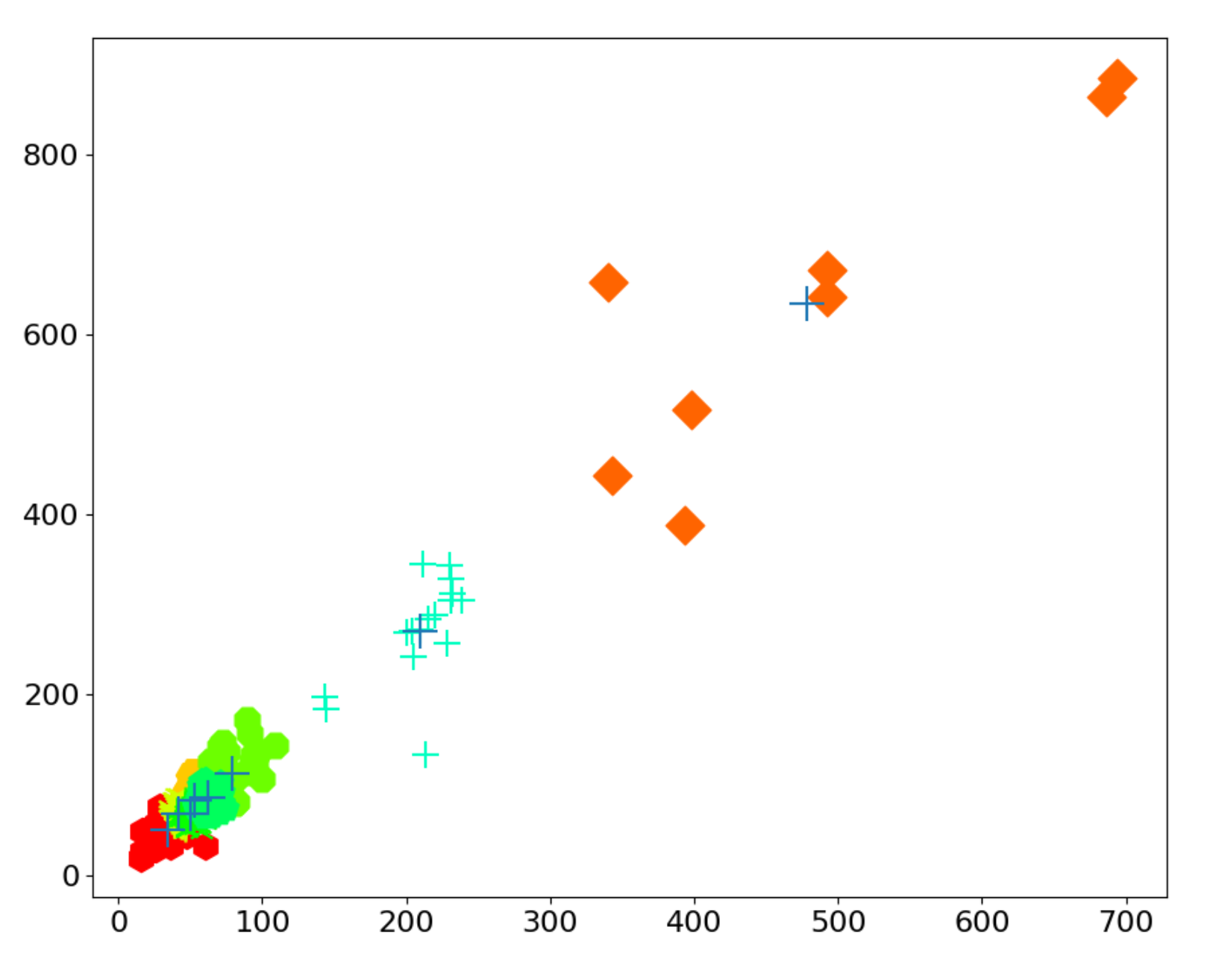
| Anchor Boxes | |
|---|---|
| 1/8 | (33.93, 50.06) (41.95, 67.44) |
| 1/16 | (49.94, 67.79) (53.30, 83.19) |
| 1/32 | (62.35, 85.61) (79.12, 113.04) |
| 1/64 | (209.48, 270.44) (478.66, 633.95) |
| Different Anchor Boxes | Accuracy | Time |
|---|---|---|
| 4 | 97.81% | 36.12 ms |
| 2 | 98.92% | 35.43 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Wen, Y. The Assisted Positioning Technology for High Speed Train Based on Deep Learning. Appl. Sci. 2020, 10, 8625. https://doi.org/10.3390/app10238625
Song Y, Wen Y. The Assisted Positioning Technology for High Speed Train Based on Deep Learning. Applied Sciences. 2020; 10(23):8625. https://doi.org/10.3390/app10238625
Chicago/Turabian StyleSong, Yali, and Yinghong Wen. 2020. "The Assisted Positioning Technology for High Speed Train Based on Deep Learning" Applied Sciences 10, no. 23: 8625. https://doi.org/10.3390/app10238625
APA StyleSong, Y., & Wen, Y. (2020). The Assisted Positioning Technology for High Speed Train Based on Deep Learning. Applied Sciences, 10(23), 8625. https://doi.org/10.3390/app10238625