Machine Learning-Based Code Auto-Completion Implementation for Firmware Developers




Abstract
1. Introduction
1.1. Research Motivation
1.2. Background
2. Literature Review
2.1. Related Work
2.2. Research Gap
3. Proposed Methodology
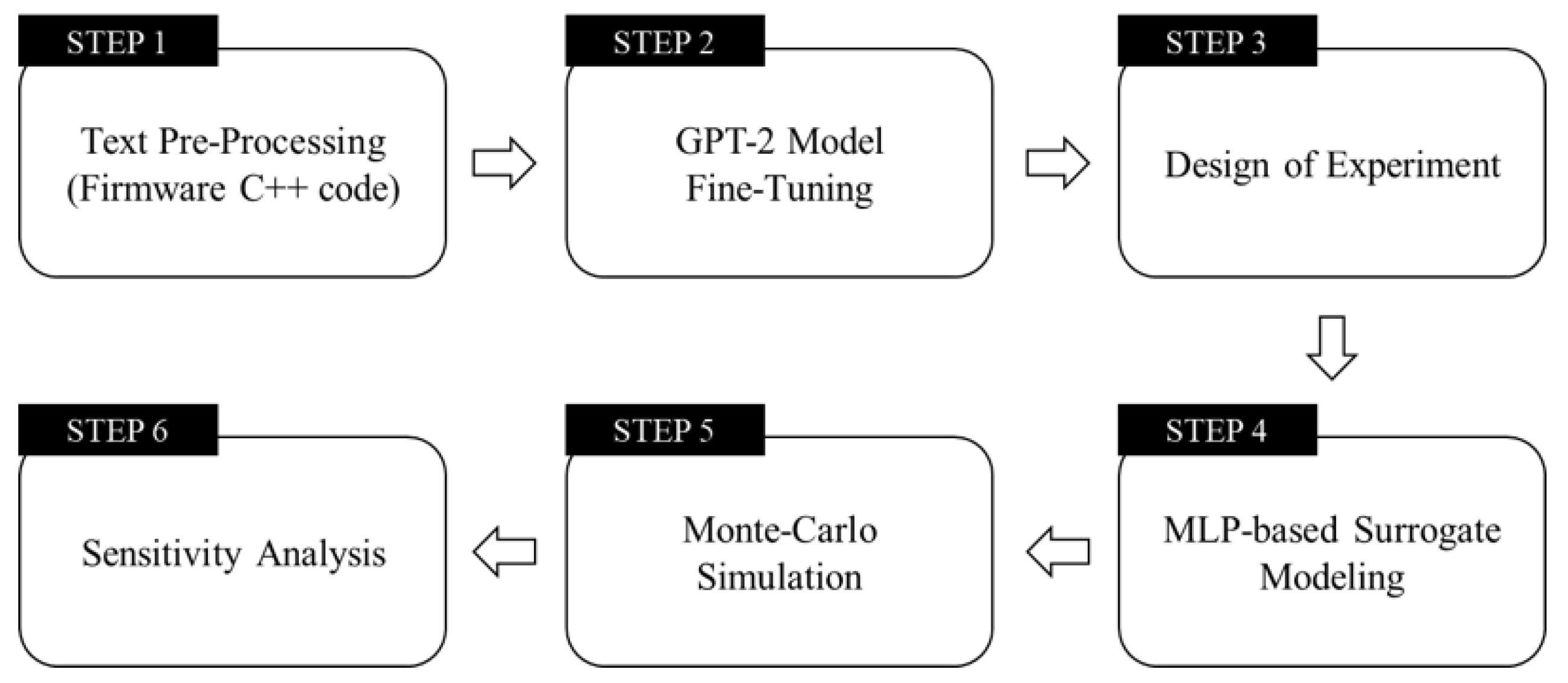
3.1. Overview of the Methodology
3.2. Text Pre-Processing
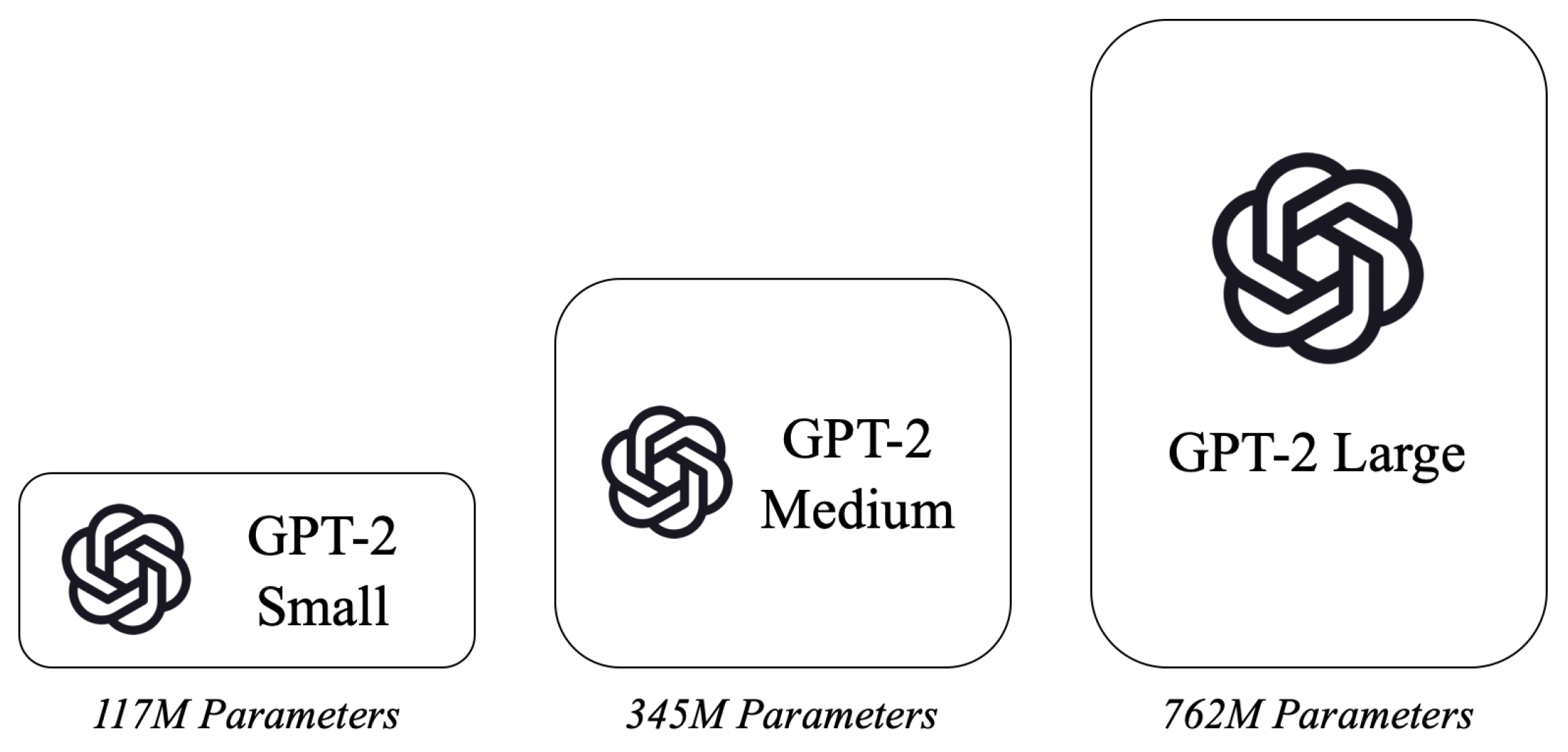
3.3. GPT-2 Model Fine-Tuning
3.4. Design of Experiment
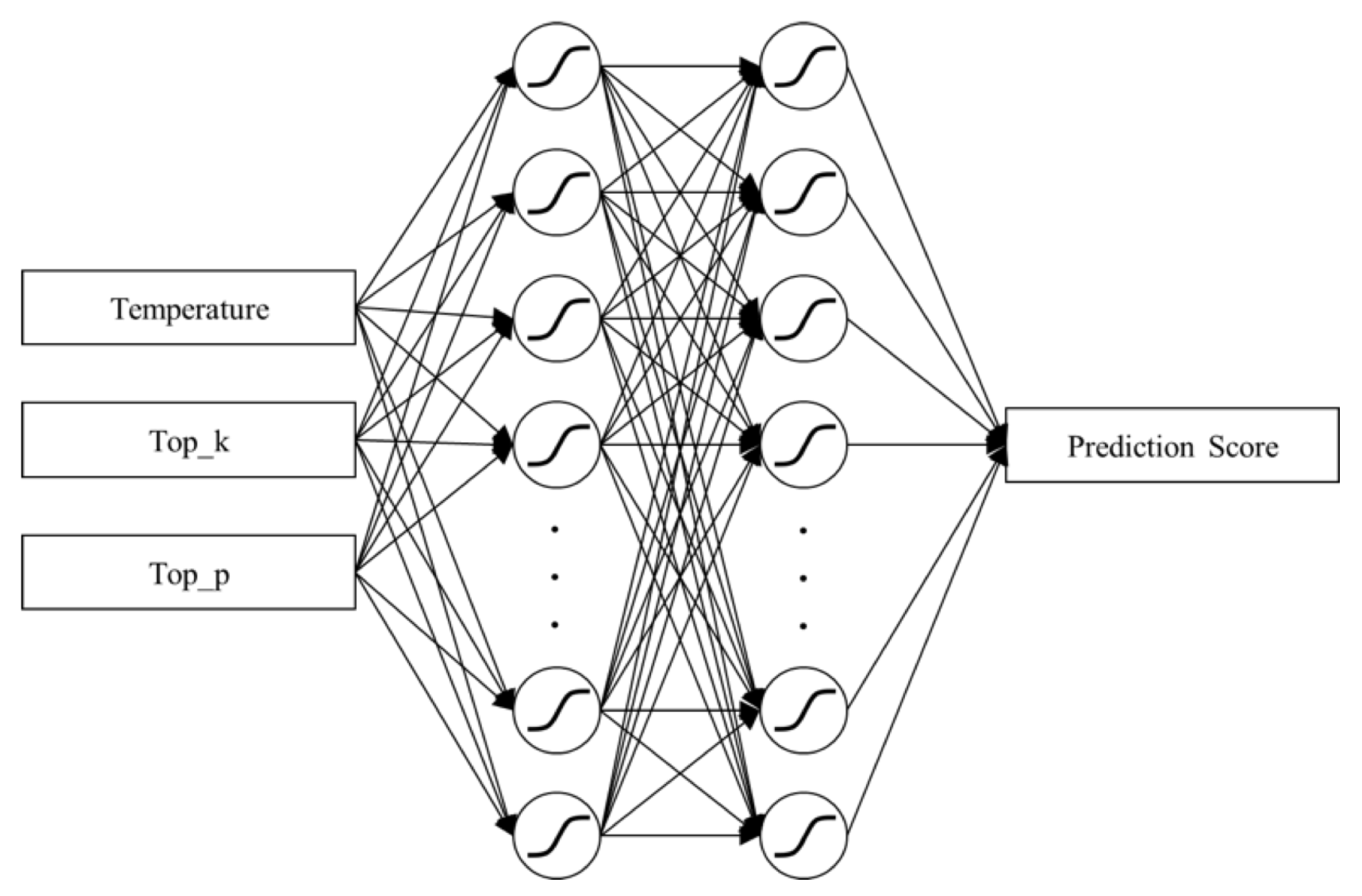
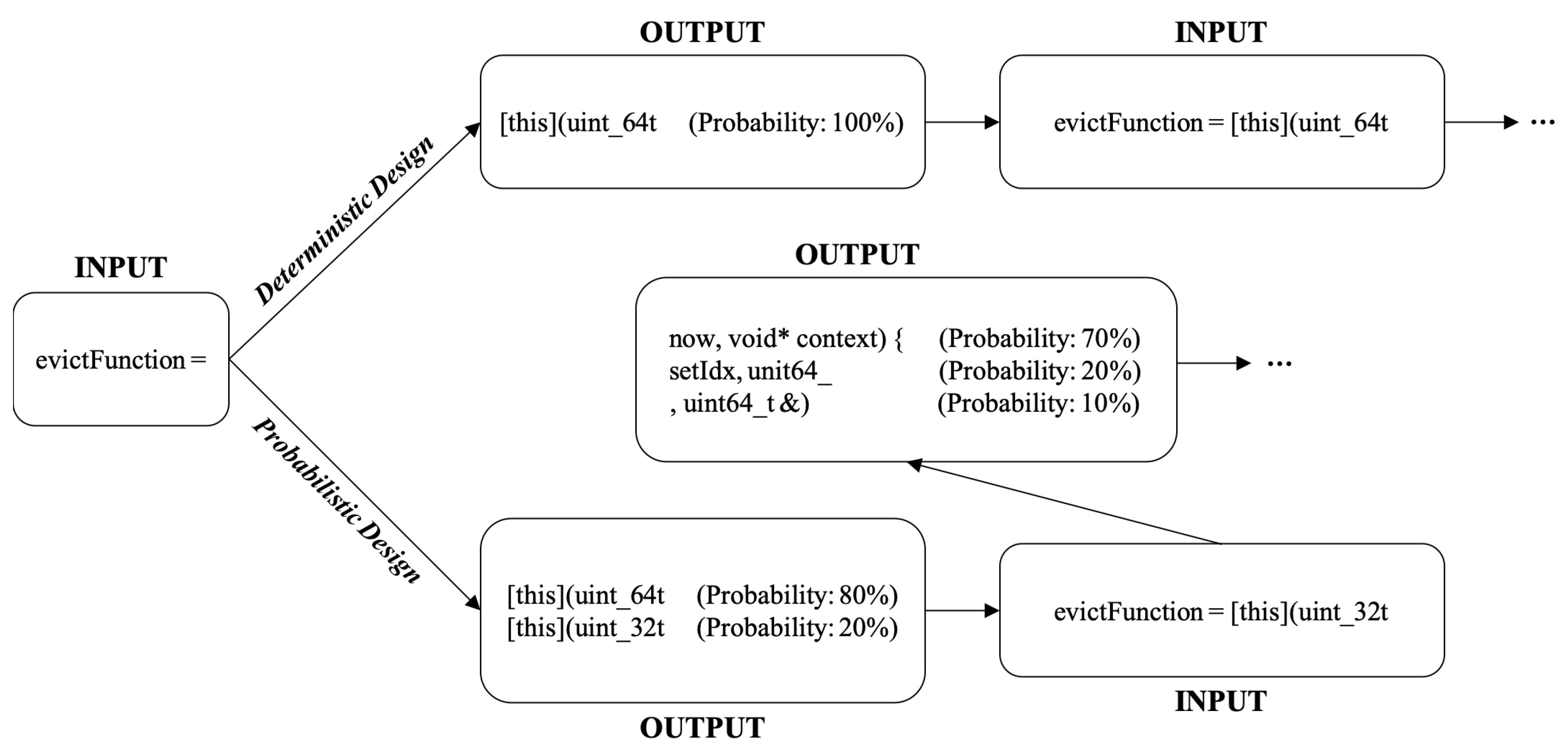
3.5. Surrogate Modeling
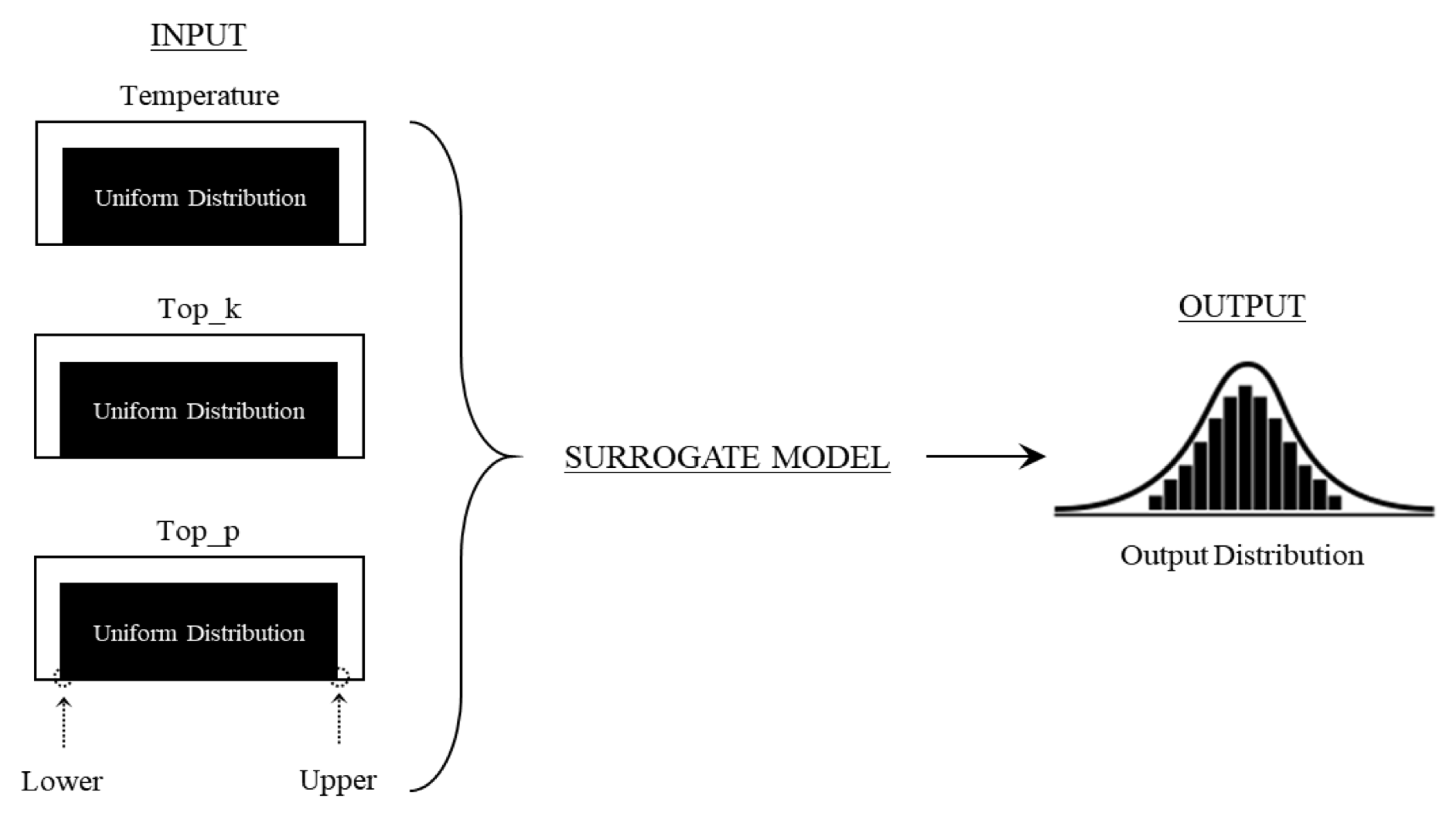
3.6. Monte Carlo Simulation
4. Results and Discussion
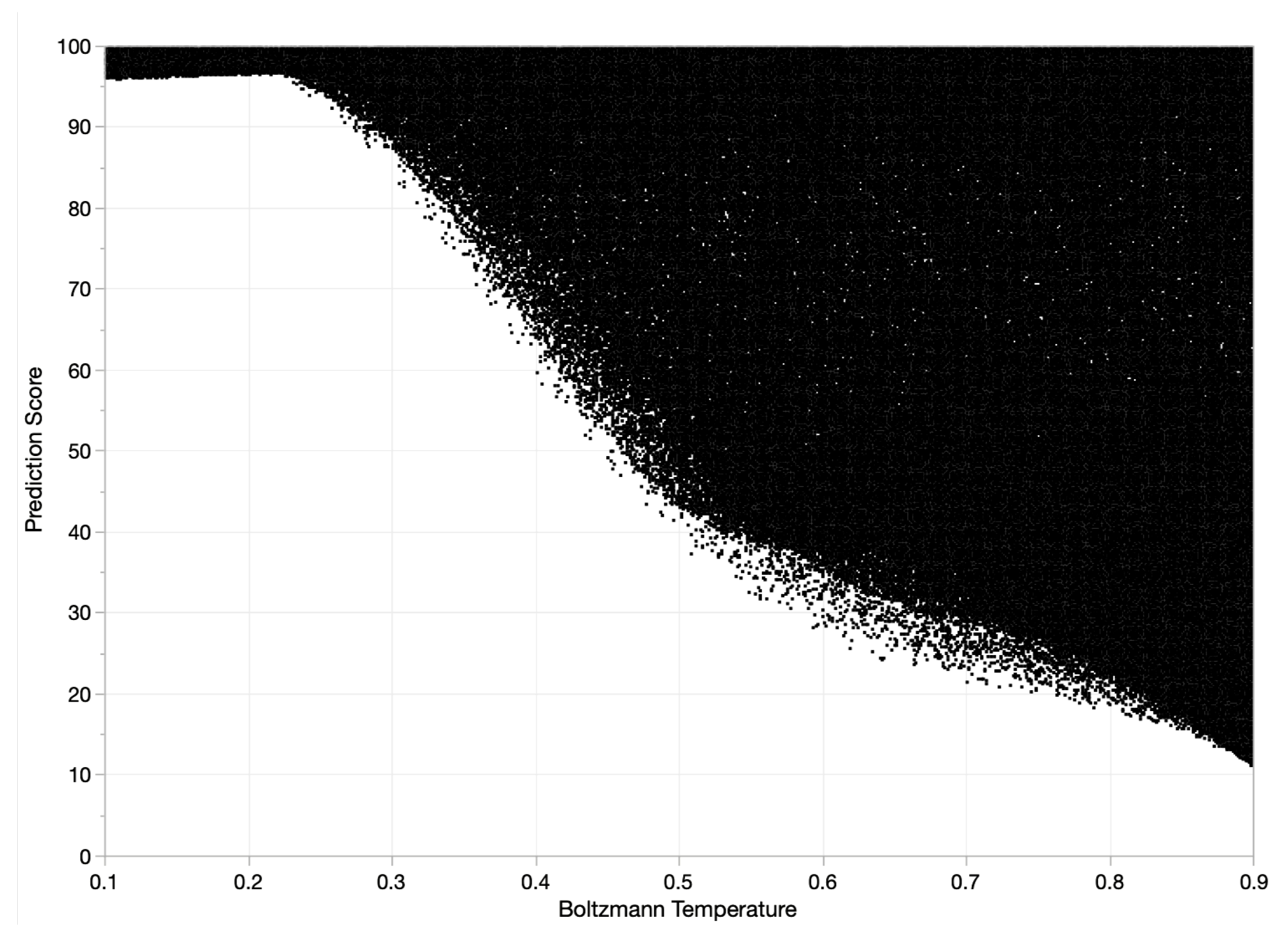
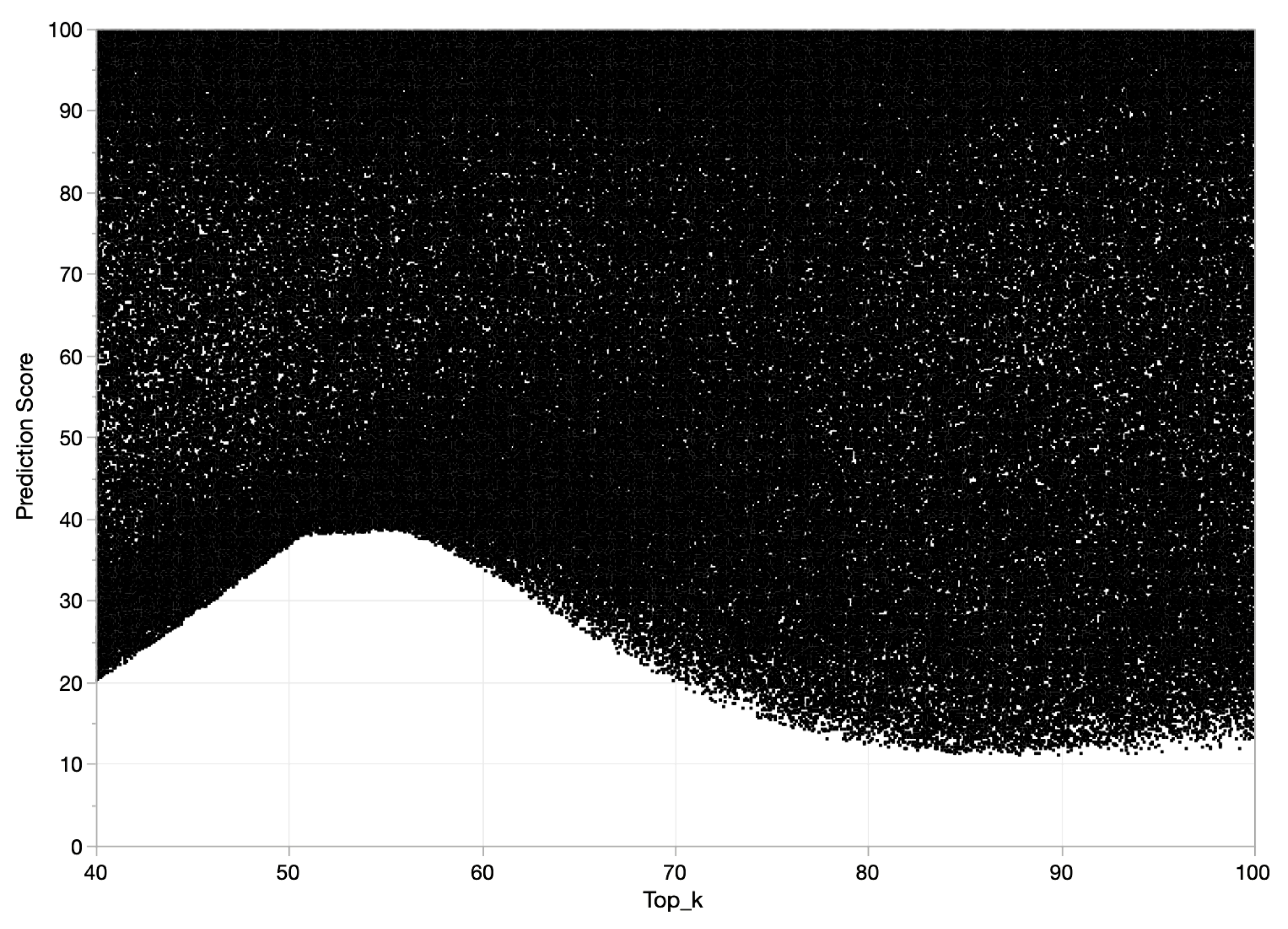
4.1. Sensitivity Analysis
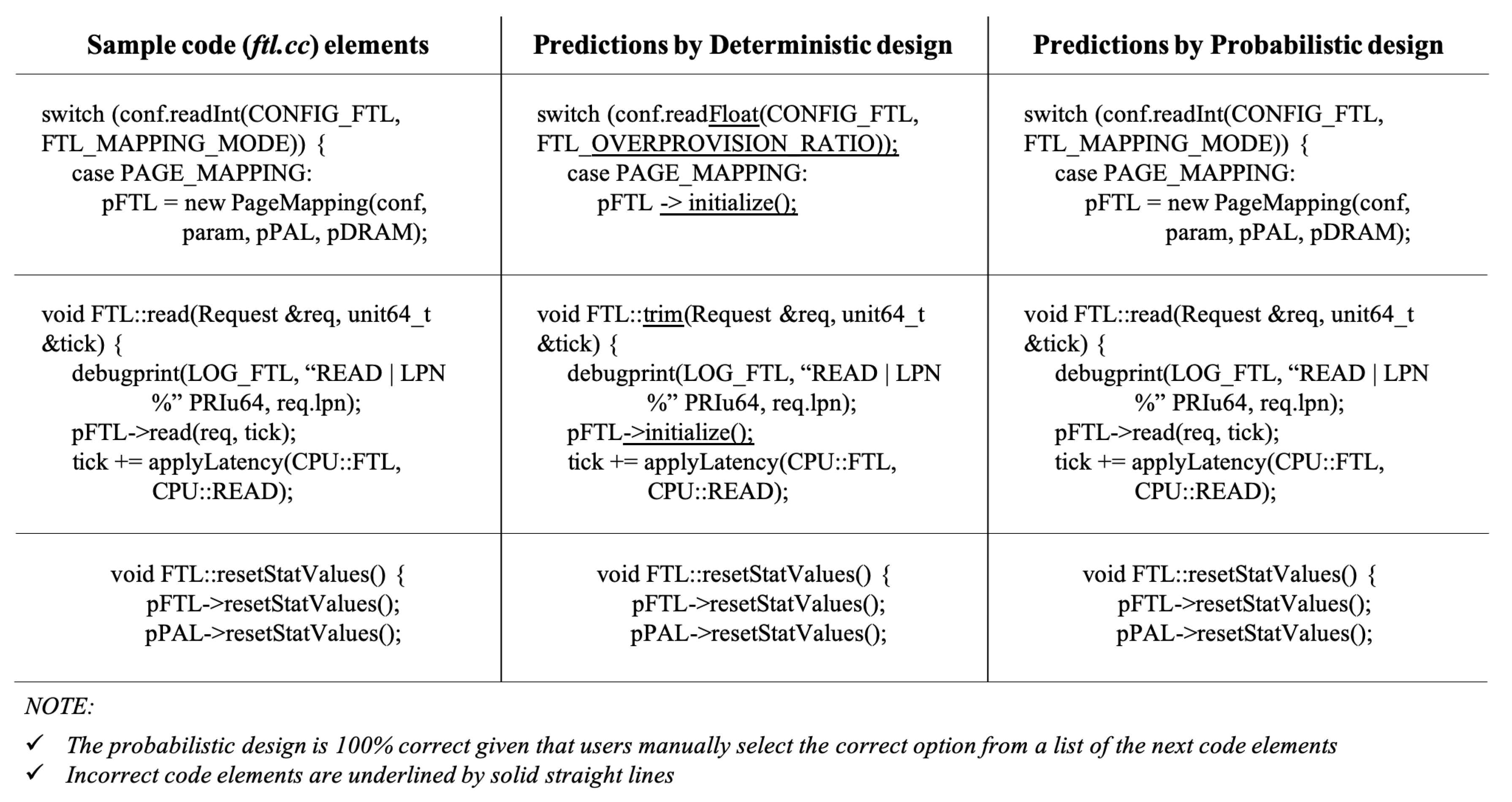
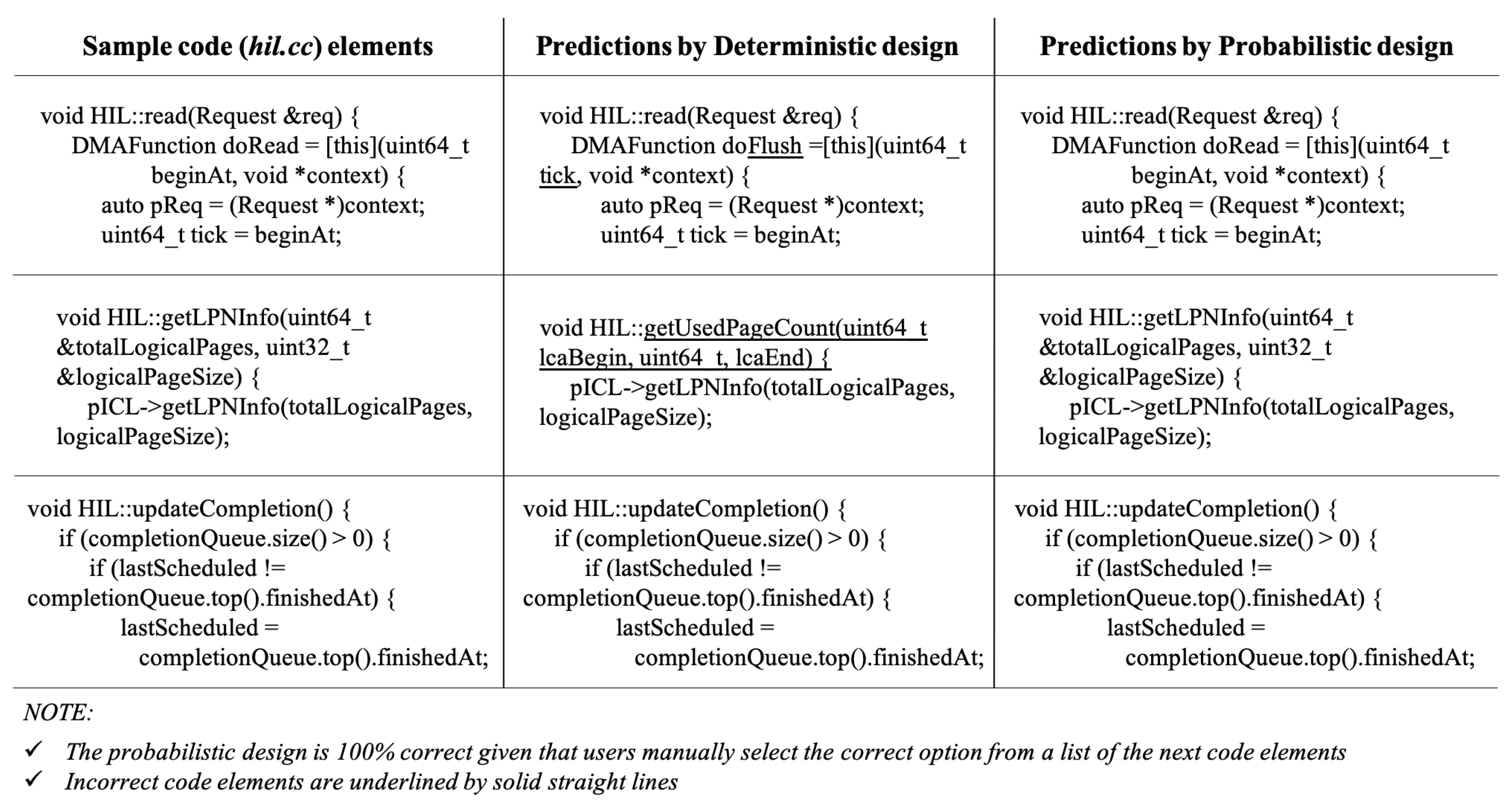
4.2. Model Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kim, J.; Briceno, S.; Justin, C.; Mavris, D. A Data-Driven Approach Using Machine Learning to Enable Real-Time Flight Path Planning. In Proceedings of the AIAA Aviation 2020 Forum, USA, 10 November 2020; p. 2873. Available online: https://arc.aiaa.org/doi/abs/10.2514/6.2020-2873 (accessed on 12 November 2020).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- The illustrated GPT-2 (Visualizing Transformer Language Models). Available online: http://jalammar.github.io/illustrated-gpt2/ (accessed on 12 November 2020).
- AllenNLP Language Modeling. Available online: https://demo.allennlp.org/next-token-lm?text=AllenNLP%20is (accessed on 12 November 2020).
- Working with Content Assist. Available online: https://www.eclipse.org/pdt/help/html/working_with_code_assist.htm (accessed on 19 October 2020).
- Das, S.; Shah, C. Contextual Code Completion Using Machine Learning; Technical Report; Stanford University: Stanford, CA, USA, 2015. [Google Scholar]
- Proksch, S.; Lerch, J.; Mezini, M. Intelligent code completion with Bayesian networks. ACM Trans. Softw. Eng. Methodol. 2015, 25, 1–31. [Google Scholar]
- Raychev, V.; Vechev, M.; Yahav, E. Code completion with statistical language models. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, Edinburgh, UK, 9–11 June 2014; pp. 419–428. [Google Scholar]
- Neural Code Completion. Available online: https://openreview.net/pdf?id=rJbPBt9lg (accessed on 27 November 2020).
- Karampatsis, R.M.; Babii, H.; Robbes, R.; Sutton, C.; Janes, A. Big Code!= Big Vocabulary: Open-Vocabulary Models for Source Code. arXiv 2020, arXiv:2003.07914. [Google Scholar]
- White, M.; Vendome, C.; Linares-Vásquez, M.; Poshyvanyk, D. Toward deep learning software repositories. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 334–345. [Google Scholar]
- Li, J.; Wang, Y.; Lyu, M.R.; King, I. Code completion with neural attention and pointer networks. arXiv 2017, arXiv:1711.09573. [Google Scholar]
- Svyatkovskiy, A.; Deng, S.K.; Fu, S.; Sundaresan, N. IntelliCode Compose: Code Generation Using Transformer. arXiv 2020, arXiv:2005.08025. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Autocompletion with Deep Learning. Available online: https://www.tabnine.com/blog/deep/ (accessed on 19 October 2020).
- Better Language Models and Their Implications. Available online: https://openai.com/blog/better-language-models/ (accessed on 19 October 2020).
- Kim, J.; Lim, D.; Monteiro, D.J.; Kirby, M.; Mavris, D. Multi-objective Optimization of Departure Procedures at Gimpo International Airport. Int. J. Aeronaut. Space Sci. 2018, 19, 534–541. [Google Scholar] [CrossRef]
- Jung, M.; Zhang, J.; Abulila, A.; Kwon, M.; Shahidi, N.; Shalf, J.; Kim, N.S.; Kandemir, M. Simplessd: Modeling solid state drives for holistic system simulation. IEEE Comput. Archit. Lett. 2017, 17, 37–41. [Google Scholar] [CrossRef]
- SimpleSSD Version 2.0 GitHub. Available online: https://github.com/SimpleSSD/SimpleSSD (accessed on 19 October 2020).
- Beginner’s Guide to Retrain GPT-2 (117M) to Generate Custom Text Content. Available online: https://medium.com/@ngwaifoong92/beginners-guide-to-retrain-gpt-2-117m-to-generate-custom-text-content-8bb5363d8b7f (accessed on 19 October 2020).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Example Method | Advantage | Limitation |
|---|---|---|---|
| Integrated Development Environment (IDE) | Eclipse’s content assist feature | It provides a list of type-compatible names for the next tokens immediately | It is generally organized alphabetically, which is not very effective |
| Statistical Language Models | n-gram | It solves a drawback of IDE’s ineffectiveness by optimizing/ranking the list | It is difficult to be scaled to large programs |
| Machine learning-based Language Models | Recurrent Neural Network (RNN) | It is typically better than statistical language models in predictions | It is not effective to capture long-term dependencies |
| Transformer-based Language Models | Generative Pre-trained Transformer (GPT) | It overcomes the issue related to long-term dependencies by introducing attention mechanisms | It is computationally expensive for those who use a personal computer |
| Hyper-Parameter | Final Choice |
|---|---|
| Learning rate | 0.0001 |
| Batch size | Stochastic |
| Case | Score |
|---|---|
| An option with the highest probability matches the actual code | 100 |
| There is an option among the possible candidates, which matches to the actual code | 50 |
| There is no available option that matches the actual code | 1 |
| Diversity Parameter | Value |
|---|---|
| Boltzmann temperature | 0.22 |
| 40 | |
| 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Lee, K.; Choi, S. Machine Learning-Based Code Auto-Completion Implementation for Firmware Developers. Appl. Sci. 2020, 10, 8520. https://doi.org/10.3390/app10238520
Kim J, Lee K, Choi S. Machine Learning-Based Code Auto-Completion Implementation for Firmware Developers. Applied Sciences. 2020; 10(23):8520. https://doi.org/10.3390/app10238520
Chicago/Turabian StyleKim, Junghyun, Kyuman Lee, and Sanghyun Choi. 2020. "Machine Learning-Based Code Auto-Completion Implementation for Firmware Developers" Applied Sciences 10, no. 23: 8520. https://doi.org/10.3390/app10238520
APA StyleKim, J., Lee, K., & Choi, S. (2020). Machine Learning-Based Code Auto-Completion Implementation for Firmware Developers. Applied Sciences, 10(23), 8520. https://doi.org/10.3390/app10238520