Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter



Abstract
Featured Application
Abstract
1. Introduction
- (1)
- We focus on extracting the aggregate stance of the general public on a single topic and a set of comparable topics, where no datasets are available. This task is different from existing research on stance detection where stance labels are available in open datasets.
- (2)
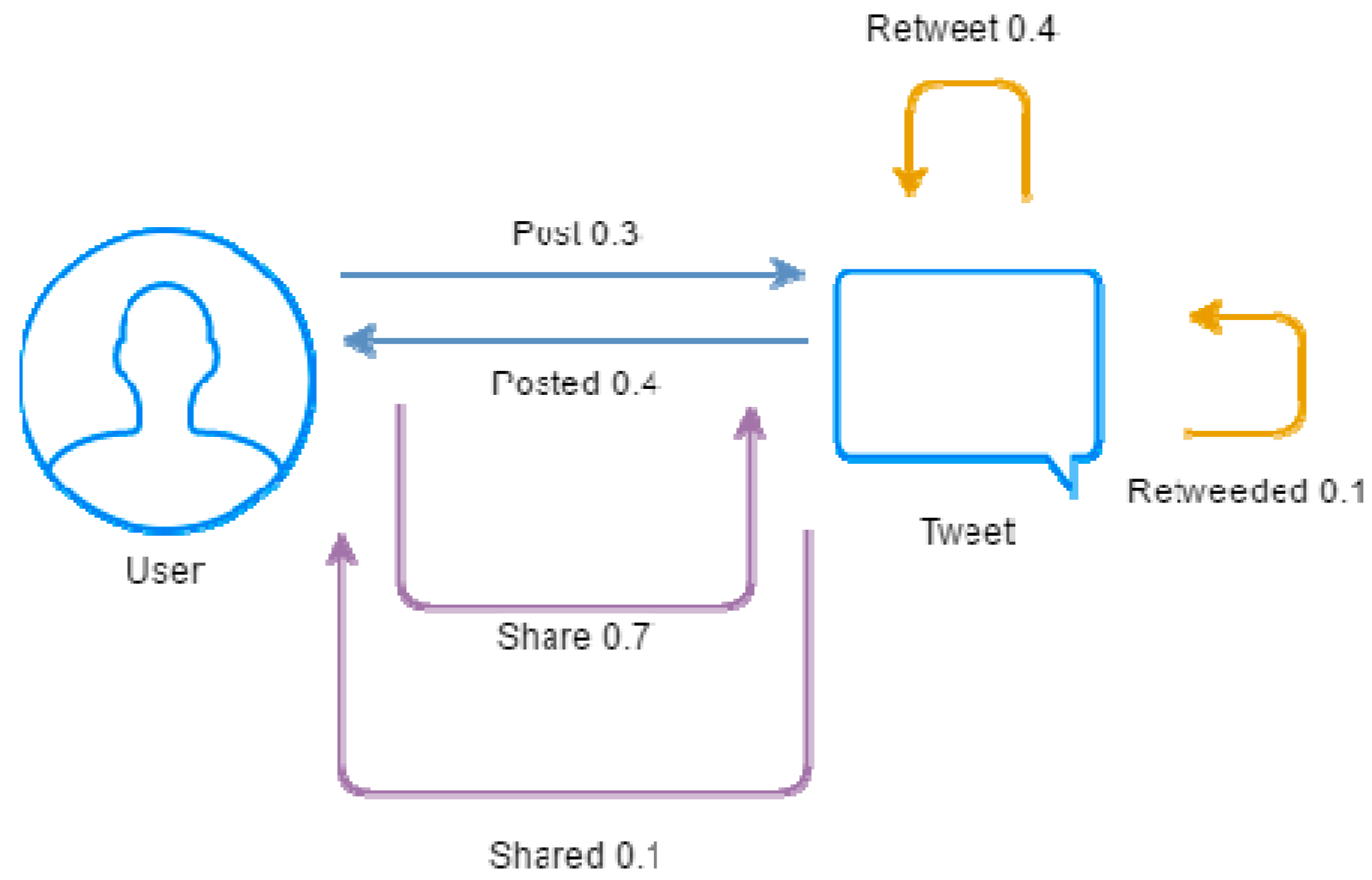
- We modify existing methods of link analysis such as TURank to consider the different edge weighting for posting, sharing, and retweeting actions.
- (3)
- We design a feasible method to calculate user influence scores and combine tweets content sentiments for extracting public stances on popular topics such as election.
2. Related Work
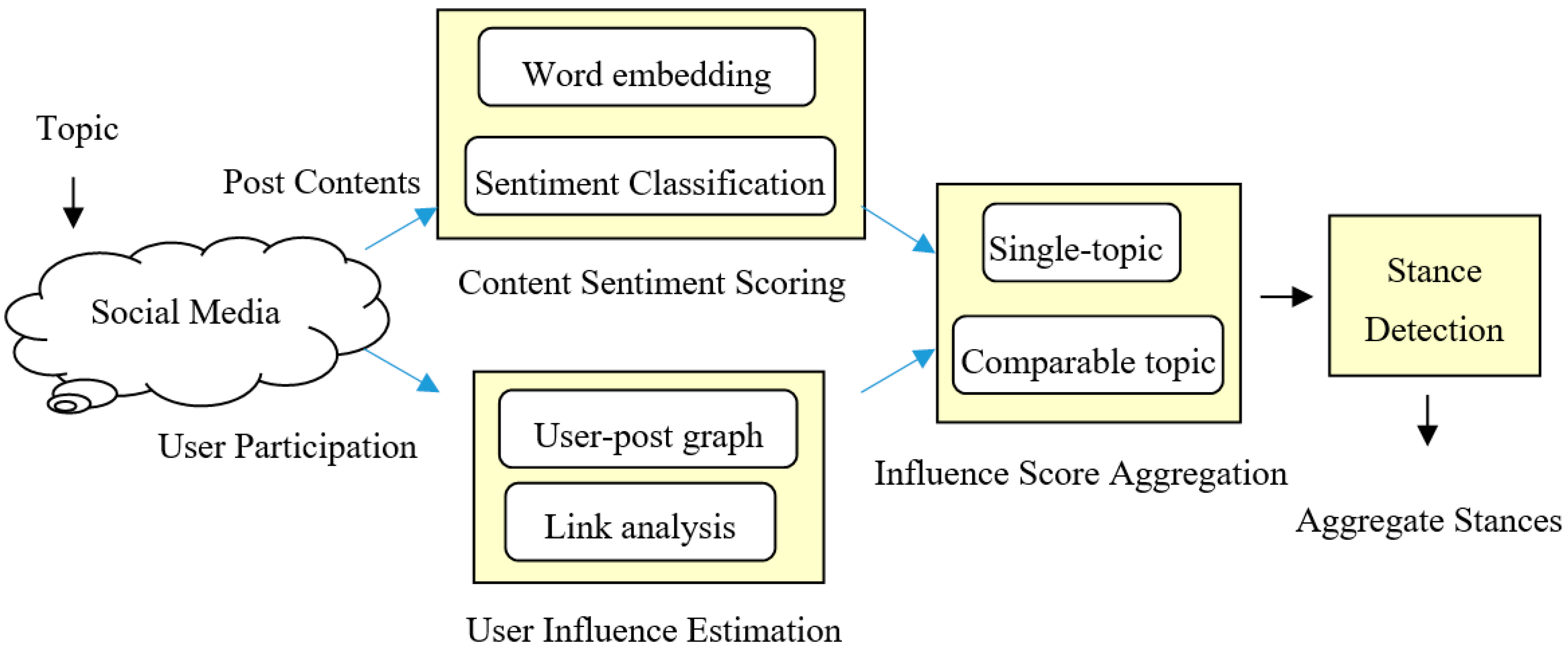
3. The Proposed Method
3.1. Preprocessing and Feature Extraction
3.2. Content Sentiment Scoring
3.3. User Influence Estimation
3.4. Influence Score Aggregation for Stance Extraction
3.4.1. Single-Topic Stance Extraction
3.4.2. Comparable-Topics Stance Extraction
4. Experiments
4.1. Experiment on Sentiment Classification
4.1.1. The Effects of Word Embedding Models on Sentiment Classification
4.1.2. The Effects of Classifiers
4.2. Experiment on User Influence Analysis
4.3. Experiment on Stance Detection
5. Discussions
- As shown in Table 2, the sentiments of short texts can be effectively classified by deep learning methods such as LSTM and CNN. LSTM slightly outperforms CNN, and they both outperform ELM and NB.
- As shown in Figure 3, better performance can be achieved by training suitable word embedding models from datasets with similar topics. They provide more related contexts for words in sentiment classification.
- With suitable edge weighting in user-post graph for user influence analysis, the top-ranked influential users identified by our proposed method can effectively cover authenticated users in Twitter. We can even discover high influential users that are yet to be included as authenticated users in Twitter. In this paper, we focus on the aggregate stance of the general public. It is the initial investigation on the issue of comparing the effects of various relative weights of different user actions on the social influence. By applying different combinations of relative weighting, we expect to gain some insights on their impacts. More studies are needed to further find out the relation between edge weights and real user influence.
- With the combination of tweet sentiments and user participation, our proposed method can effectively extract public stance for popular topics such as presidential election from social media. The best Mean Absolute Error (MAE) of 0.68% can be achieved when we combine user influence scores when aggregating public stances on a set of comparable topics.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations 2013 Workshop, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. In Proceedings of the Ninth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 1998), San Francisco, CA, USA, 25–26 January 1998; pp. 668–677. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford University: Stanford, CA, USA, 1998. [Google Scholar]
- Li, D.; Zhang, S.; Sun, X.; Zhou, H.; Li, S.; Li, X. Modeling Information Diffusion over Social Networks for Temporal Dynamic Prediction. IEEE Trans. Knowl. Data Eng. 2017, 29, 1985–1997. [Google Scholar] [CrossRef]
- Tingmin, T.; Wen, S.; Xiang, Y.; Zhou, W. Twitter spam detection: Survey of new approaches and comparative study. Comput. Secur. 2018, 76, 265–284. [Google Scholar] [CrossRef]
- Ren, H.; Zhang, Z.; Xia, C. Online social spammer detection. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 59–65. [Google Scholar]
- Wang, Z.; Gu, S.; Zhao, X.; Xu, X. Graph-based review spammer group detection. Knowl. Inf. Syst. 2017, 55, 571–597. [Google Scholar] [CrossRef]
- Ghosh, S.; Viswanath, B.; Kooti, F.; Sharma, N.K.; Korlam, G.; Benevenuto, F.; Ganguly, N.; Gummadi, K.P. Understanding and combating link farming in the Twitter social network. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16 April 2012; pp. 61–70. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. J. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, Y.; Takahashi, T.; Amagasa, T.; Kitagawa, H. Turank: Twitter user ranking based on user-tweet graph analysis. In Proceedings of the International Conference on Web Information Systems Engineering (WISE 2010), Hong Kong, China, 12–14 December 2010; pp. 240–253. [Google Scholar]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Bermingham, A.; Smeaton, A.F. On using Twitter to monitor political sentiment and predict election results. In Proceedings of the Workshop on Sentiment Analysis where AI Meets Psychology (SAAIP 2011), IJCNLP, Chiang Mai, Thailand, 13 November 2011; pp. 2–10. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (HLT 2011), Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar]
- Paul, D.; Li, F.; Teja, M.K.; Yu, X.; Frost, R. Compass: Spatio temporal sentiment analysis of us election what twitter says! In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1585–1594. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2015), Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient flow in recurrent nets: The difficulty of learning long-term dependencies. In A Field Guide to Dynamical Recurrent Neural Networks; Kremer, S.C., Kolen, J.F., Eds.; IEEE Press: New York, NY, USA, 2001. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Attention-based lstm network for cross-lingual sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016), Austin, TX, USA, 1–5 November 2016; pp. 247–256. [Google Scholar]
- Al-Twairesh, N.; Al-Negheimish, H. Surface and Deep Features Ensemble for Sentiment Analysis of Arabic Tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Sun, Q.; Wang, Z.; Li, S.; Zhu, Q.; Zhou, G. Stance detection via sentiment information and neural network model. Front. Comput. Sci. 2018, 13, 127–138. [Google Scholar] [CrossRef]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 task 6: Detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 6–17 June 2016; pp. 31–41. [Google Scholar]
- Ghanem, B.; Rosso, P.; Rangel, F. Stance Detection in Fake News a Combined Feature Representation. In Proceedings of the First Workshop on Fact Extraction and Verification (FEVER), EMNLP; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 66–71. [Google Scholar]
- Wang, L.; Niu, J.; Yu, S. SentiDiff: Combining Textual Information and Sentiment Diffusion Patterns for Twitter Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2019, 32, 2026–2039. [Google Scholar] [CrossRef]
- Yao, W.; Yang, Y.; Wang, D. UR rank: Micro-blog user influence ranking algorithm based on user relationship. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom 2017), Edinburgh, UK, 11–13 December 2017; pp. 394–404. [Google Scholar]
- Hong, L.; Dan, O.; Davison, B.D. Predicting popular messages in Twitter. In Proceedings of the 20th International Conference on World Wide Web (WWW 2011), Hyderabad, India, 28 March–1 April 2011; pp. 57–58. [Google Scholar]
- Uysal, I.; Croft, W.B. User oriented tweet ranking: A filtering approach to microblogs. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management (CIKM 2011), Glasgow, UK, 19–20 October 2011; pp. 2261–2264. [Google Scholar]
- Weng, J.; Lim, E.-P.; Jiang, J.; He, Q. Twitterrank: Finding topic-sensitive influential twitterers. In Proceedings of the Third ACM International Conference on Web Search and Data Mining (WSDM 2010), New York, NY, USA, 3–6 February 2010; pp. 261–270. [Google Scholar]
- Balmin, A.; Hristidis, V.; Papakonstantinou, Y. ObjectRank: Authority-Based Keyword Search in Databases. In Proceedings of the Thirtieth International Conference on Very Large Data Bases (VLDB 2004), Los Angeles, CA, USA, 30 August 2004; pp. 564–575. [Google Scholar]
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 task 4: Sentiment analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval 2016), San Diego, CA, USA, 6–17 June 2016; pp. 1–18. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Number of Posts | Number of Words |
|---|---|---|---|
| Vec-Hillary | Hillary | 20,000 | 4933 |
| Vec-All | Hillary, Trump | 40,000 | 8078 |
| Vec-SemEval | Hillary, Trump, and SemEval datasets | 55,983 | 11,351 |
| Vec-Com-150 | General dataset | 1,500,000 | 74,248 |
| Vec-Com-200 | General dataset | 2,000,000 | 90,412 |
| Vec-Com-250 | General dataset | 2,500,000 | 98,926 |
| Bayes | ELM | CNN | LSTM | ||
|---|---|---|---|---|---|
| Hillary dataset | Precision | 68.74% | 69.54% | 73.03% | 73.11% |
| Recall | 68.46% | 69.43% | 72.76% | 72.82% | |
| F-Measure | 68.59% | 69.49% | 72.89% | 72.97% | |
| Trump dataset | Precision | 69.43% | 69.97% | 71.51% | 71.74% |
| Recall | 69.34% | 69.96% | 71.49% | 71.67% | |
| F-Measure | 69.39% | 69.97% | 71.50% | 71.71% |
| Test 1 | Test 2 | Test 3 | Test 4 | |
|---|---|---|---|---|
| Posting | 0.3 | 0.7 | 0.2 | 0.3 |
| Posted | 0.4 | 0.4 | 0.2 | 0.2 |
| Sharing | 0.7 | 0.3 | 0.8 | 0.7 |
| Shared | 0.1 | 0.1 | 0.1 | 0.0 |
| Retweeting | 0.4 | 0.4 | 0.6 | 0.8 |
| Retweeted | 0.1 | 0.1 | 0.1 | 0.0 |
| Sent | SoV | SoVp | SoVn | Sent-SoV | |
|---|---|---|---|---|---|
| Favors Hillary | 306,125 (50.09%) | 170,740 (26.51%) | 35,477 (13.52%) | 339,491 (67.24%) | 316,450 (48.46%) |
| Favors Trump | 303,987 (49.90%) | 473,977 (73.48%) | 227,546 (86.47%) | 165,085 (32.75%) | 335,542 (51.53%) |
| Neutral | 50,903 (7.7%) | 16,298 (2.47%) | 397,992 (60.20%) | 156,439 (23.67%) | 9,023 (1.37%) |
| MAE | 6.96% | 16.60% | 29.59% | 24.11% | 5.34% |
| No Post Inf. | Post Inf. | Normal Post Inf. | No User Inf. | User Inf. | Normal User Inf. | |
|---|---|---|---|---|---|---|
| Favors Hillary | 307,132 (47.57%) | 321,655 (49.28%) | 316,450 (48.46%) | 316,450 (48.53%) | 316,450 (43.80%) | 316,450 (48.46%) |
| Favors Trump | 337,424 (52.42%) | 330,337 (50.71%) | 335,542 (51.53%) | 335,542 (51.46%) | 335,542 (56.19%) | 335,542 (51.53%) |
| Neutral | 16,459 (2.49%) | 9023 (1.37%) | 9023 (1.37%) | 9023 (1.37%) | 9023 (1.37%) | 9023 (1.37%) |
| MAE | 4.45% | 6.16% | 5.34% | 5.41% | 0.68% | 5.34% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-H.; Liu, T.-W.; Luo, X. Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter. Appl. Sci. 2020, 10, 8035. https://doi.org/10.3390/app10228035
Wang J-H, Liu T-W, Luo X. Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter. Applied Sciences. 2020; 10(22):8035. https://doi.org/10.3390/app10228035
Chicago/Turabian StyleWang, Jenq-Haur, Ting-Wei Liu, and Xiong Luo. 2020. "Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter" Applied Sciences 10, no. 22: 8035. https://doi.org/10.3390/app10228035
APA StyleWang, J.-H., Liu, T.-W., & Luo, X. (2020). Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter. Applied Sciences, 10(22), 8035. https://doi.org/10.3390/app10228035