1. Introduction
There are different biometric features that allow the verification or identification of people, among them is writing. The rhythm of writing, which is unrepeatable and unique, captures particular graphic characteristics in the text which allow the identification of the author. People recognition through the analysis of handwritten texts is widely used in different tasks such as identifying authorship, detecting forgeries, fraud, threats and theft, in documents of different types such as holographic wills, letters, checks, and so forth [
1].
Most state-of-the-art works analyze complex text structures to extract features, such as full pages, text and paragraphs [
2,
3,
4,
5,
6], words [
7,
8,
9] and signatures [
10,
11,
12]. Working with very complex sources in order to obtain a high verification ratio results in complexity throughout the entire processing sequence: developing sophisticated segmentation algorithms for the region of interest, complexity in the automatic computation of descriptors to represent the original data with low dimensionality and high execution times for the algorithms.
Contrary to the more traditional literature characterized by the complexity of the structures used, a new approach begins to consider simple elements of handwritten text to solve the problem of writer verification. Along these lines, in Reference [
13] a new database is proposed containing 6 remarkably simple grapheme types: “e” “S”, “∩”, “C”, “∼”and“ U”. In addition, a new descriptor is introduced to represent the texture of the handwritten strokes (relative position of the minimum gray value points within the stroke) and successful verification tests are performed with a Support Vector Machine (SVM) based classifier. In Reference [
14], it is proposed to represent the texture of simple graphemes by means of B-Spline transformation coefficients and classifiers based on banks of SVMs. In Reference [
15], the character “e” is excluded because it presents crosses in its structure, which generates complexity in the computation of descriptors, the Local Binary Patterns (LBP) are introduced to represent the surface of the simple graphemes, and a classifier based on SVM is built. Recently, in Reference [
16], it was proposed to simplify the structure of the classifier and reduce training time using Neural Networks of Extreme Learning (ELM). In the aforementioned works, preprocessing and transformation of the original image are performed, descriptors representing the surface texture of the grapheme are computed, and classifiers are constructed for the verification of the writer.
In order to simplify the pipeline of simple graphemes processing, without to perform pre-processing (working directly with the original image), without to compute descriptors, and to achieve a high rate of writer identification accuracy, this paper proposes to analyze the image of the Simple Grapheme using Convolutional Neural Networks (CNN). The advantages of this approach are as follows:
Directly working with the original image without making any transformations.
Biometric features are obtained automatically through CNN filters.
The use of CNN allows a high success rate in the test set because the constructed classifiers correspond to highly non-linear transformations.
There are consolidated frameworks for the implementation of CNN networks [
17,
18], which use high-performance computing techniques (multi-core and GPUs) to reduce network training time.
In this work, experiments are performed with the network models AlexNet [
19], VGG (VGG-16 and VGG-19) [
20] and ResNet (ResNet-18) [
21]. AlexNet and VGGs networks can be considered classic convolutional neural networks, as they follow the basic serial connection scheme, that is, a series of convolutions, pooling, activation layers and finally some completely connected classification layers. The idea of the ResNet models (ResNet-18/50/101), is to use residual blocks of direct access connections, with double or triple layer jumps where the input is not weighted and it is passed to a deeper layer. In this work, this group of CNN networks is adopted because they present a good compromise between performance, structural complexity and training time.
The structure of this paper is as follows.
Section 2 presents an overview of the simple grapheme database and its traditional representation.
Section 3 presents the CNN models adopted in this research.
Section 4 shows the experiments performed. Finally,
Section 5 presents the conclusions of this paper.
2. An Overview of Simple Graphemes
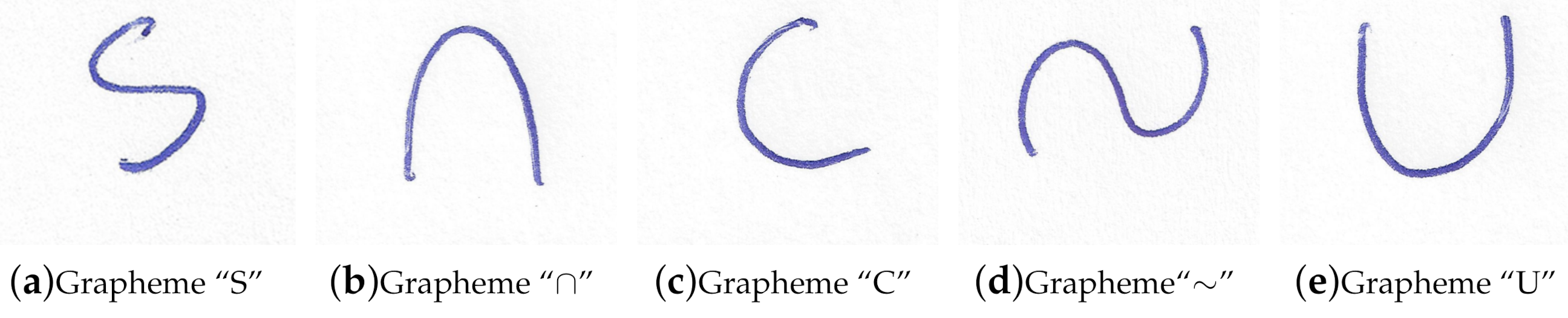
Simple graphemes were recently reported in Reference [
15]. This repository contains five types of simple graphemes: “S”, “∩”, “C”, “∼” and “U”, for 50 writers, with 100 samples of each simple grapheme per writer. The images are 24-bit color,
pixels in size, with a scanner resolution of 1200 dpi.
Figure 1 shows sample images of the simple graphemes contained in the image repository.
The images in this repository have a resolution of 1200 dpi, this is due to the fact that the simple character methodology used by Aubin et al. [
15] is based on texture, and in order to have enough information, higher resolution is required to provide more detail of the stroke texture, which is enough to extract biometric information from small text elements. It should be noted that the public databases resolution of handwritten text (IAM [
22], CEDAR [
23], CVL [
24], RIMES [
25]) is 300 dpi. This low resolution is due to the fact that traditional databases were not designed to analyze small elements of handwritten text.
As
Figure 1 shows, the image of the grapheme has many white pixels (background pixels) that contain no information. In order to obtain an image that considers only the pixels of the grapheme, a rectified image is constructed that consists of a “stretched” version of the grapheme [
15].
3. Convolutional Neural Network Models for Simple Grapheme Analysis
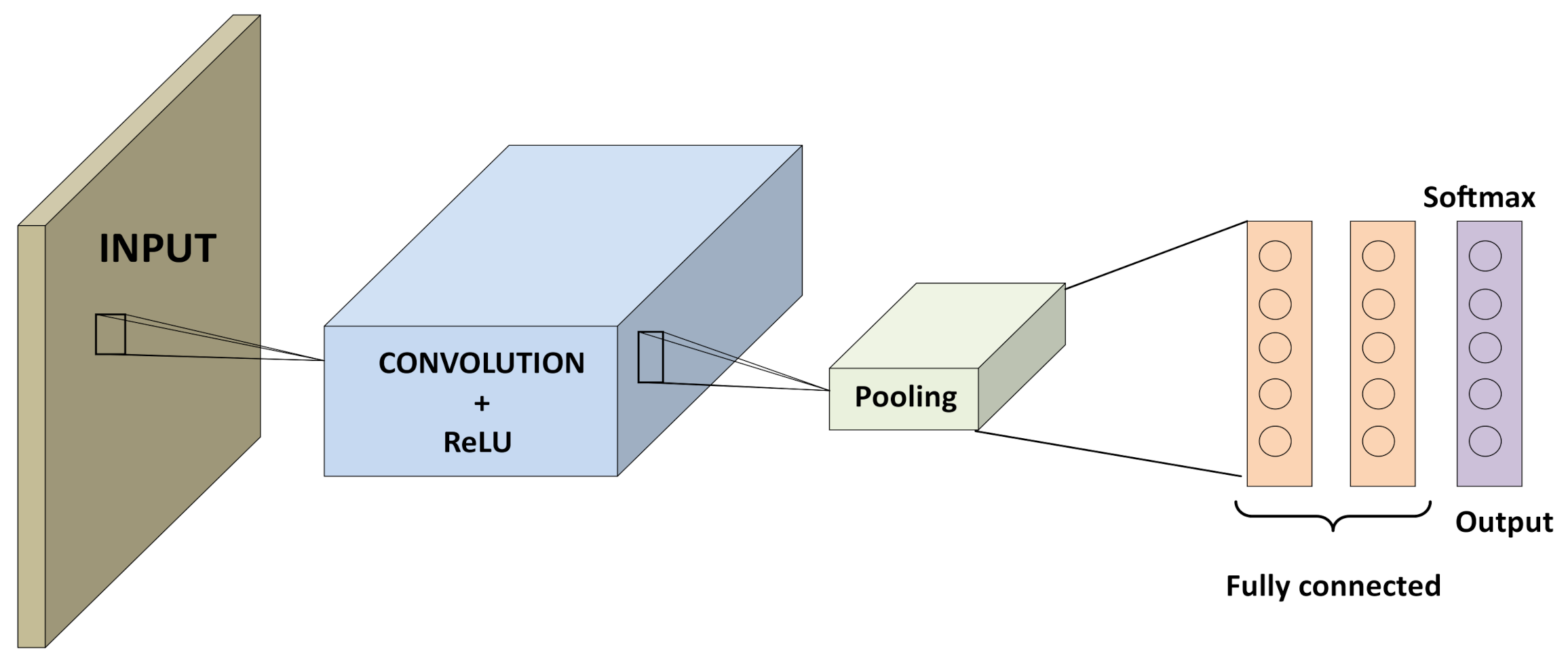
The CNNs are capable of automatically extracting the characteristics of images [
26], making them suitable for the study of images [
27]. The CNN typical architecture is composed in the following way (illustrated in
Figure 2):
Convolutional Layer: It is a set of convolutional filters which activate the characteristics of the image.
Layer of activation function: It is a non-linear activation function.
Subsampling Layer or pooling layer: It reduces the dimension of the feature banks at the output of the convolutional layer.
Fully connected Layer: It flattens the output of the previous layers by converting the output to 1D.
Softmax Layer: It gives the probabilities of each category as established in the database at the beginning to perform the classification.
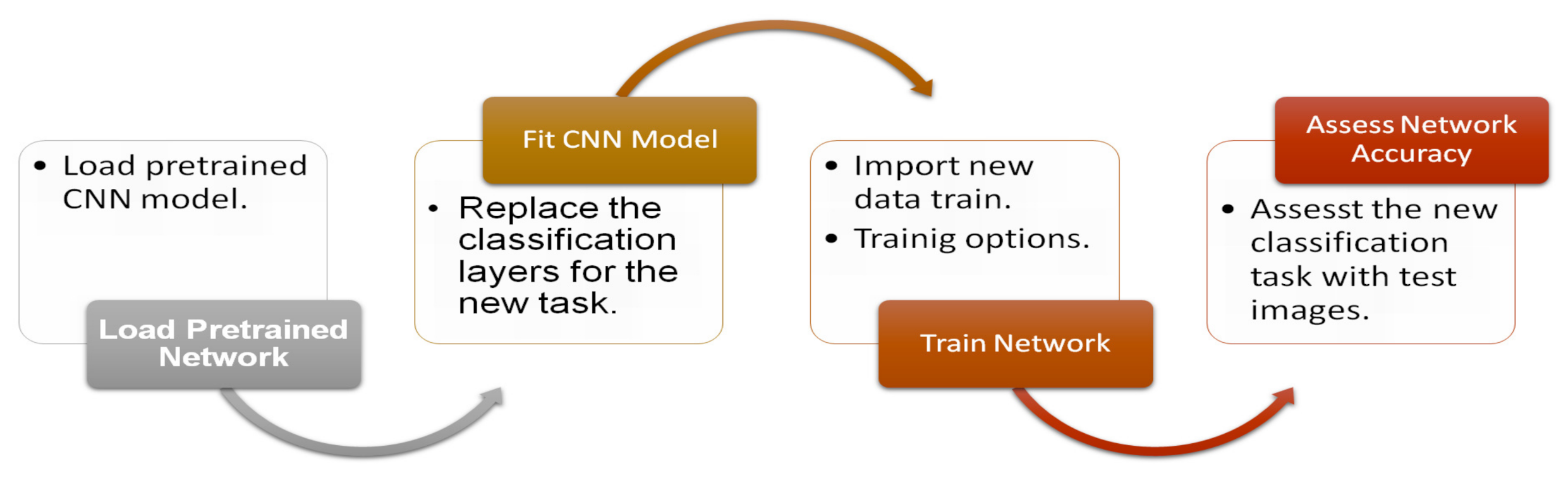
There are CNNs previously trained for image classification that have learned to extract characteristics and information from the images, thus using them as a starting point to learn a new task. Most of these CNNs were trained using the ImageNet database [
28], which is used in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
29]. The three main uses of pre-trained CNNs are shown in
Table 1.
However, because the original and rectified graphemes are very different from the images included in the Imagenet database, the graphemes cannot be classified directly using the pretrained CNNs. Consequently, a learning transfer process invariably takes place. This process consists of properly adjusting and training the previously trained CNN with the new images. The idea is usually to adjust the CNN output layers keeping the rest of the network unchanged and taking the pre-trained weights.
Figure 3 illustrates a simplified diagram of the learning transfer process with pre-trained CNNs.
This paper adopts CNN models widely known in the literature:
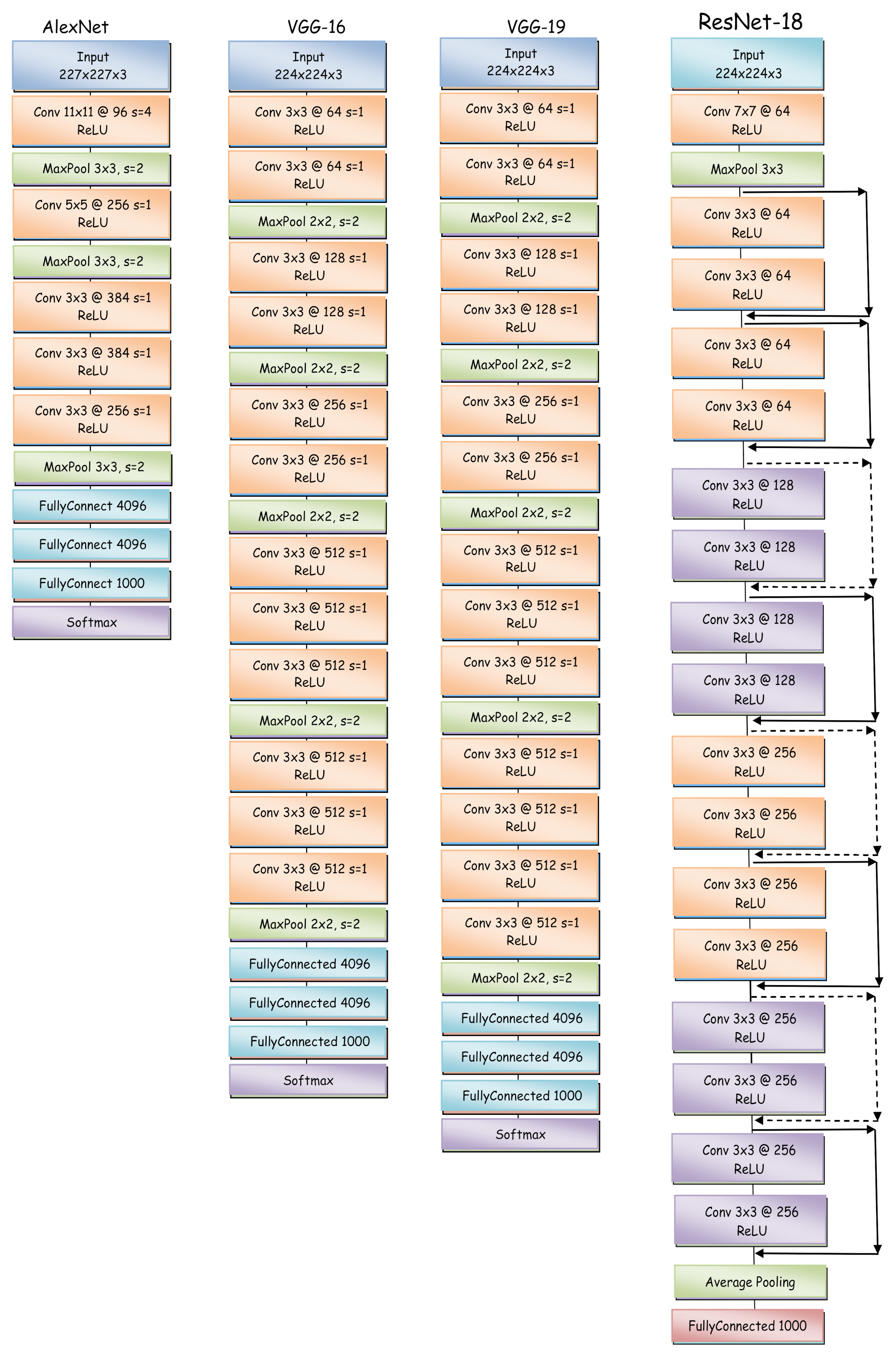
AlexNet [
19]: was one of the first deep networks in and a significant step in the development of CNNs. It is composed of 5 convolutional layers followed by 3 fully connected layers.
VGG [
20] versions VGG-16 and VGG-19, Developed by the Visual Geometry Group (VGG) of the University of Oxford, it is an AlexNet enhancement by replacinglarge kernel-sized filters with multiple 3 × 3 kernel size filters one after another, increasing network depth and thus being able to learn more complex features.
ResNet (ResNet-18) [
21], is an innovation over previous architecture, solving many of the problems of deep networks. It uses residual blocks of direct access connections, managing to reduce the number of parameters to be trained, with a good compromise between performance, structural complexity and training time.
Table 2 shows the general characteristics of these networks: depth, size of the network, number of parameters and dimension of the input image.
Figure 4 shows the architecture of the AlexNet, VGG-16, VGG-19 and ResNet-18 networks. The description of the elements that form the blocks of this figure is as follows:
Conv: The size of the convolutional filters.
@: The number of filters to apply.
s: The stride of the filter over the image.
ReLU: The activation function at the output of the convolutional filters
MaxPool: The subsampling operation with the filter dimension.
4. Experiments with Convolutional Neural Networks
This section describes the experiments carried out with simple graphemes and the pretrained CNNs AlexNet, VGG-16, VGG-19 and ResNet-18, performing learning transfer modality.
Two variants of the grapheme image are considered for the experiments. The first one consists of the rectified grapheme, which is the approach used in most articles that work with simple graphemes. The second one consists of the RGB image of the original grapheme, in order to carry out experiments without transforming the original image. All the images used in this article make up the LITRP-SGDB database (LITRP- Simple Grapheme Data Base), which is available for download under the signature of a license agree form on the official site of the database
http://www.litrp.cl/repository.html#LITRP-SGDB.
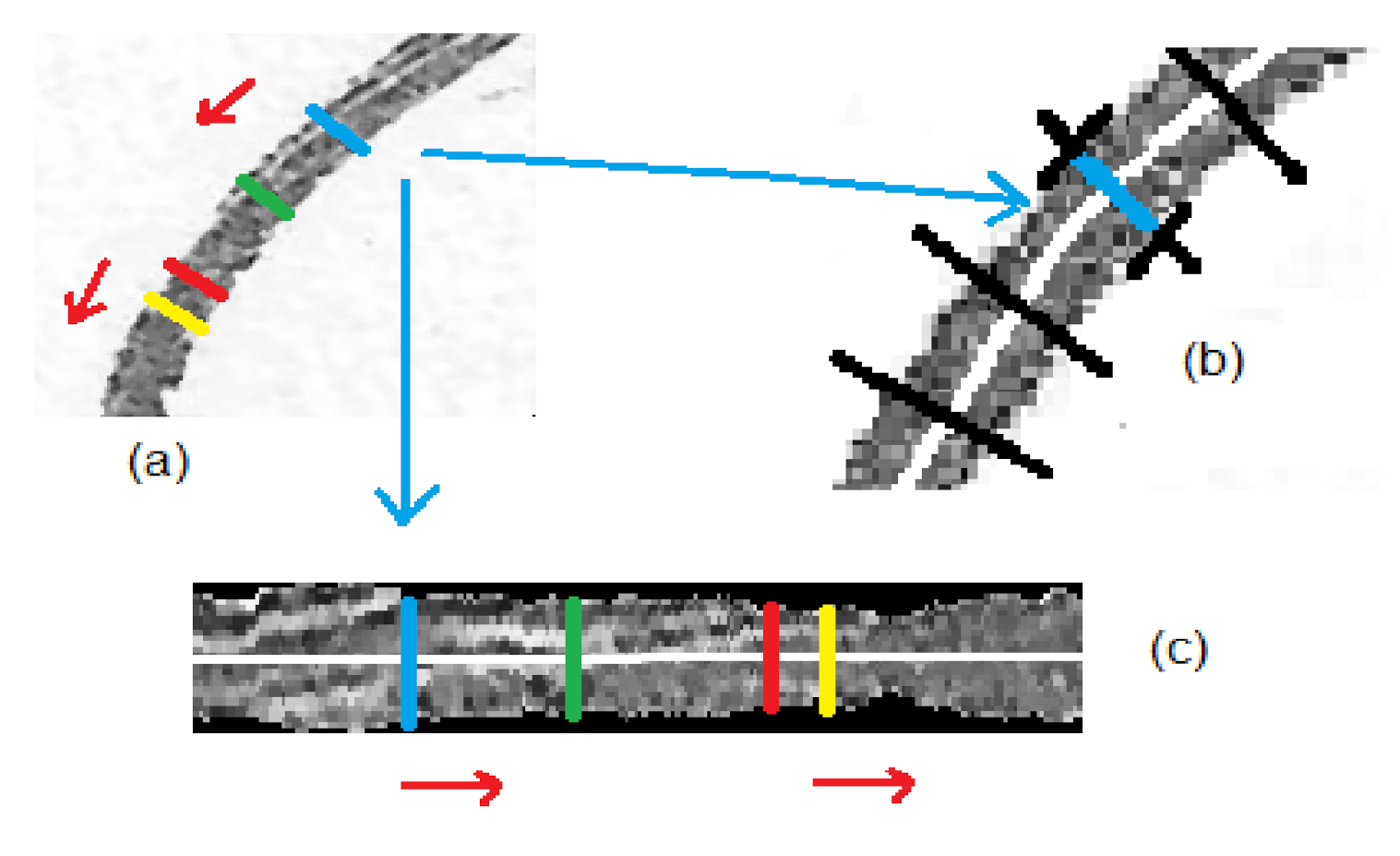
The rectification procedure is composed of a sequence of simple image processing operations that are graphically represented in
Figure 5. The operations sequence is explained in detail in Reference [
15], and can be summarized as follows:
Figure 5c shows the resulting image from the rectification process. It is important to note that this rectified image, being grayscale and not including background pixels, dramatically reduces the dimensionality of the color image of the original grapheme.
In the neural networks constructed, the input corresponds to one of the two representations of the image and the output corresponds to a vector of 50 elements to represent the number of people that form the repository. In the training of the CNNs, 3 sets (Training, Validation and Test) are considered and balanced training sets are created per class. This process consists of: First taking the original set of images for a grapheme, dividing it randomly into the Training (80%), Validation (10%) and Test (10%) sets. Second, to avoid bias or imbalance in the network training, the Training set, the number of samples per person is equated to the smallest number that one of the people contains. This process is carried out for each grapheme individually, as well as for the rectified graphemes as for the original ones, in order to have sets with the same number of samples.
Table 3 shows the number of samples from the training, validation and test sets by grapheme. The last row shows the composition of the sets grouping all the person’s graphemes.
To carry out the experiments, the MatLab Deep Learning Toolbox [
17] was used, which provides a framework for designing and implementing deep neural networks with algorithms, pre-trained models, and applications.The experiments were carried out with a computer server of the following characteristics: 2x Intel Xeon Gold 6140 CPU @ 2.30 GHz, 36 total physical cores, 24.75 MB L3 Cache Memory 126 GB, Operatin System Debian GNU/Linux 10 (buster) Kernel 4.19.0-10-amd64 x86_64.
4.1. Experiments with Rectified Simple Grapheme Images
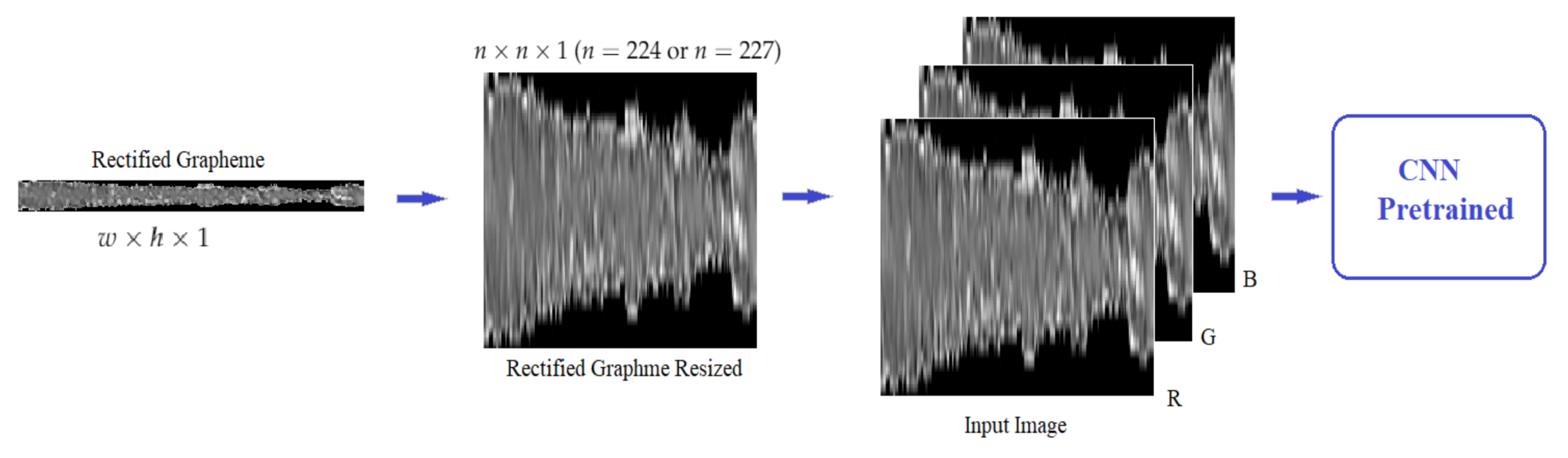
In this experiment, the images of the rectified graphemes obtained by Aubin et al. [
15] are used, these are rectangular images in single channel grayscale of the form
with
w much greater than
h (50 × 700 approximately). Then, these images must be resized according to the corresponding CNN input layer, for AlexNet it is 227 × 227 × 3 and for VGGs and ResNet it is 224 × 224 × 3. The process consists of first resizing the rectangular image of a channel to a square image of
(
or
). The grayscale image is then converted into an RGB image, using the same matrix for the three channels, as shown in
Figure 6. This is to adapt the image to the input layer of the previously trained network.
Table 4,
Table 5,
Table 6 and
Table 7 show the experiments with AlexNet, VGG-16, VGG-19 and ResNet-18 networks, respectively. For each network, experiments have been carried out with a different number of epochs, but the table shows the smallest number of epochs that gives the best result on validation set (there comes a time when increasing the epochs does not improve the accuracy). Training and test time are expressed in seconds (s).
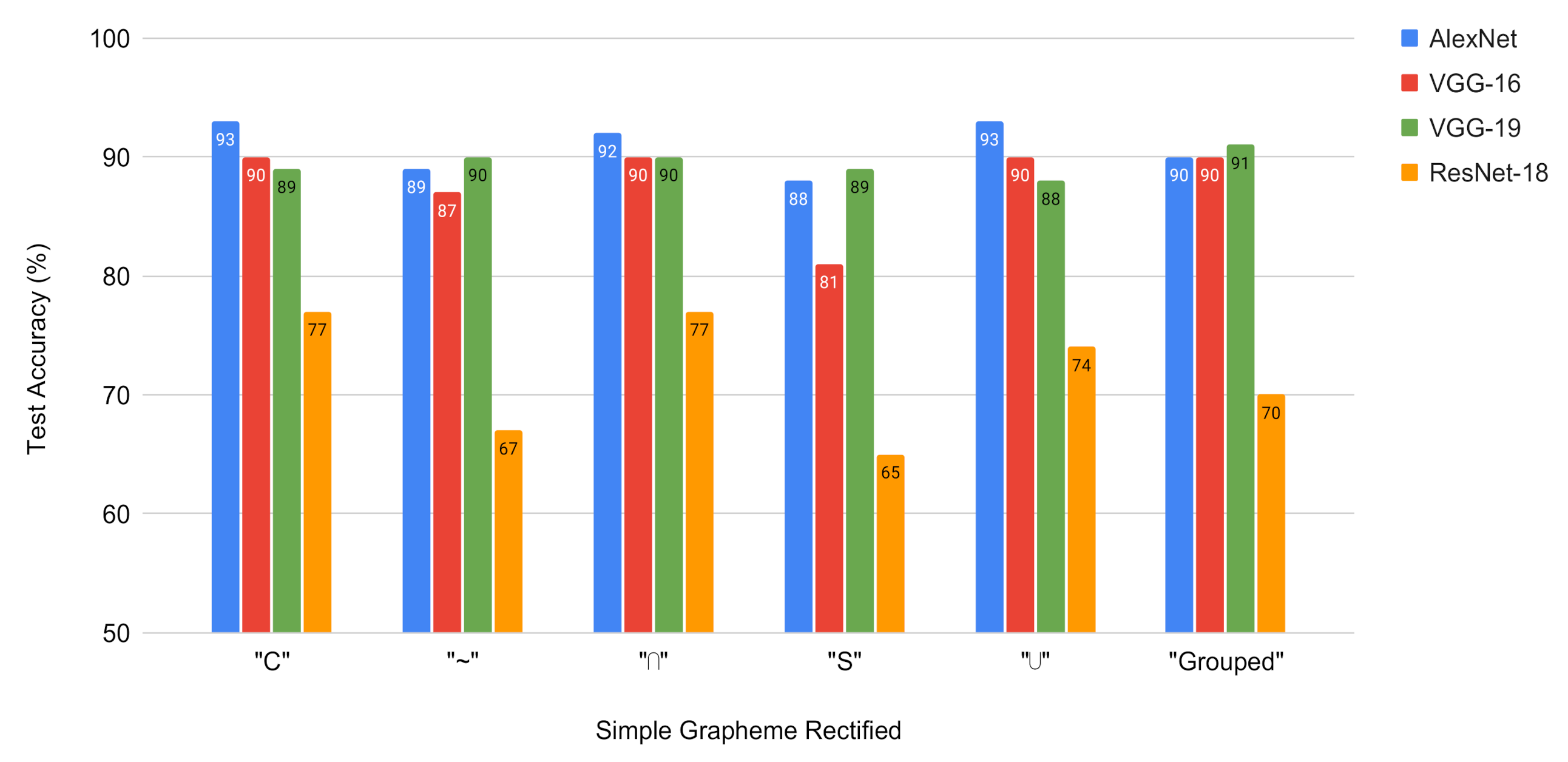
For the AlexNet, VGG-16 and VGG-19 networks considered, the rectified graphemes have an average yield close to 90%, the training took 80 epochs. For the ResNet-18 network, the accuracy results are lower than those of the previous ones, despite training with a more epochs (100 epochs) and from this point on, the increase in the number of epochs does not improve results. The moderate level of performance is explained because a lot of information is lost when transforming the image of the rectified grapheme to the input format of the CNN networks.
Figure 7 shows the test accuracy of applying the pre-trained CNNs to the rectified graphemes. It is observed that AlexNet, which is the simplest neural network, has the best results in general. Results get worse as network size increases.
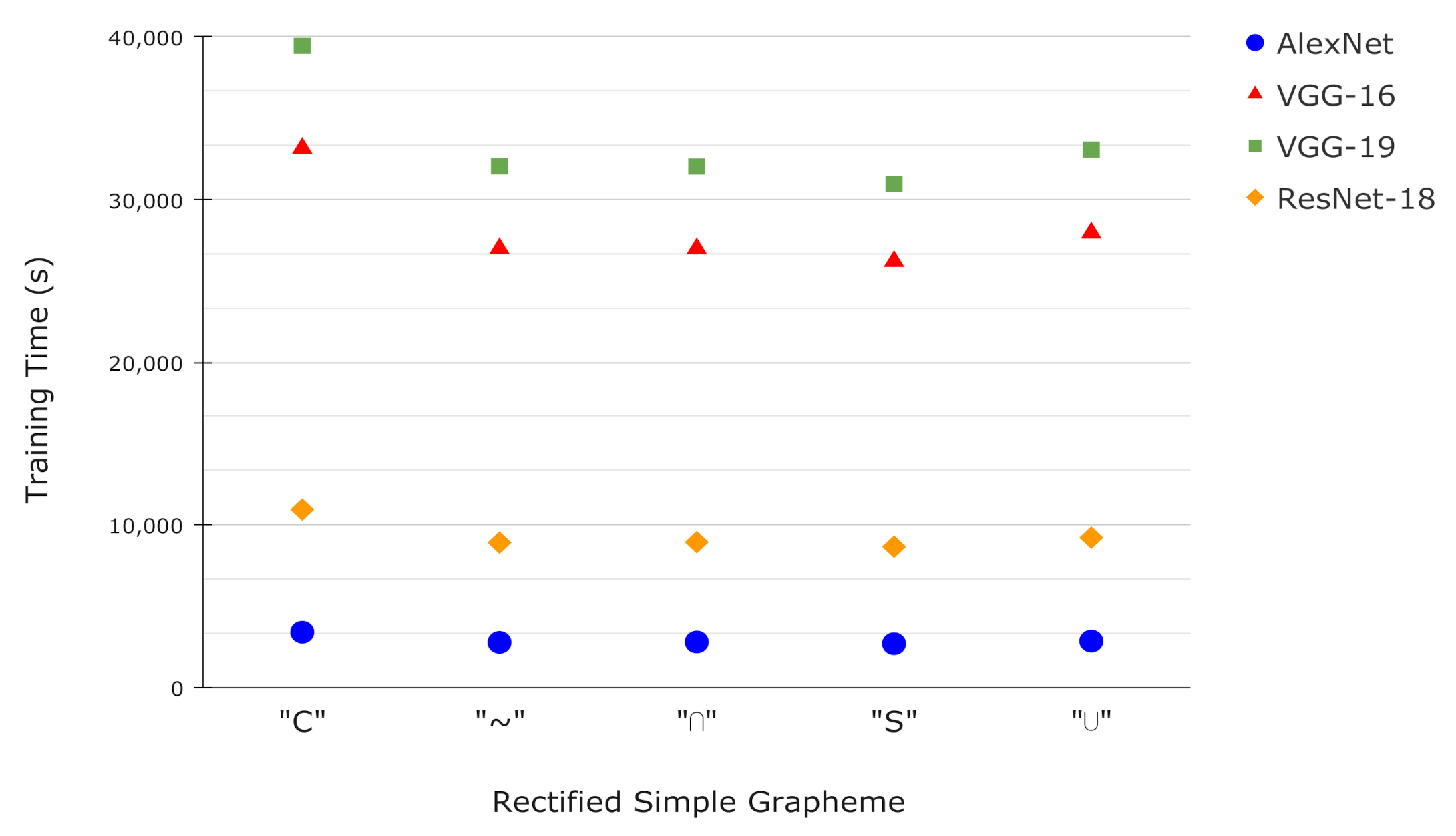
Figure 8 shows the network training times for each rectified grapheme. The AlexNet and VGG16/VGG19 networks of similar architecture, as is known, the execution time increases as the depth of the network increases (epochs = 80). For ResNet-18, despite having trained with a greater number of epochs (epochs = 100) and being similar in depth to the VGGs, the training time is much less similar to that of AlexNet, which is due to the fact that it trains significantly fewer parameters than the other networks.
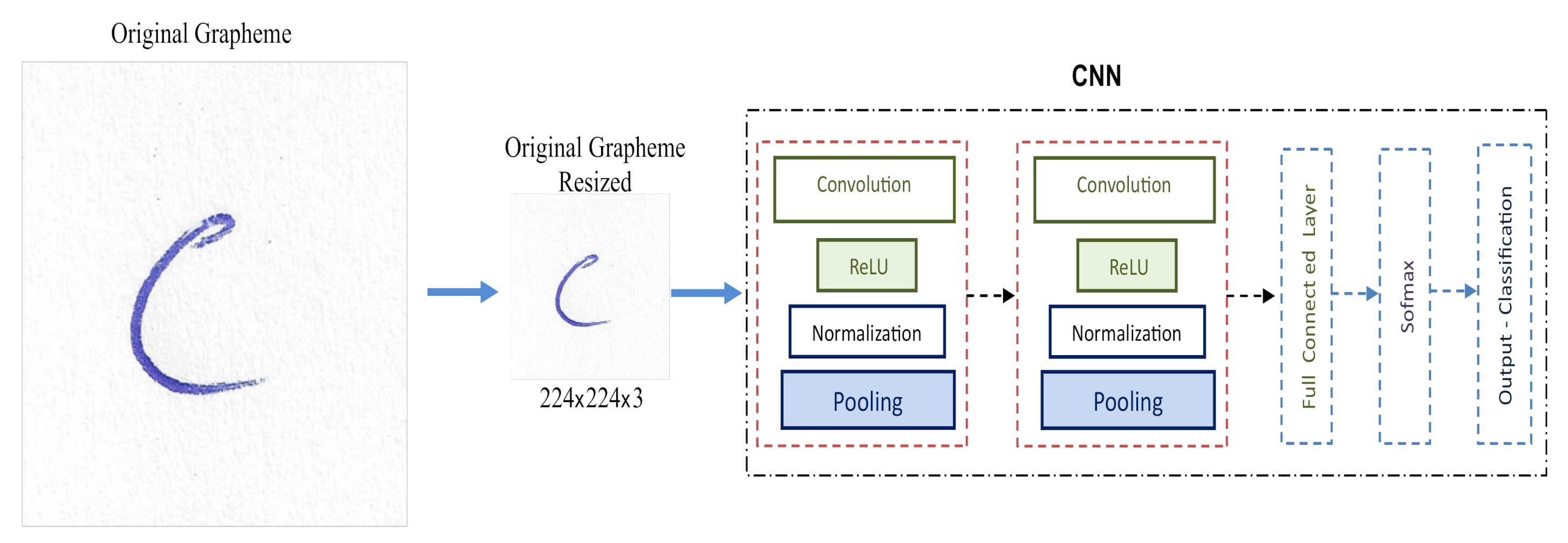
4.2. Experiments with Original Simple Grapheme Images
In order not to carry out the procedure of calculating the rectified grapheme and thus avoid this stage of the study process of the original graphemes, experiments are carried out with the RGB image of the original grapheme. The original image should be resized to match the size of the input image for each network, as the original dimension of the graphemes is about 800 × 800 × 3. For AlexNet it resizes to (227 × 227 × 3) and for VGG/ResNet to (224 × 224 × 3). This is illustrated in
Figure 9.
Table 8,
Table 9,
Table 10 and
Table 11 show the experiments with AlexNet, VGG-16, VGG-19 and ResNet-18 networks, respectively. Network training is performed by increasing the number of epochs until the error in the validation set reaches a minimum value. This process is carried out for all graphemes. For AlexNet, VGG-16 and VGG-19 networks the case of 50 epochs and for ResNet-18 the case of 80 epochs is shown. Likewise, the Tables show the execution times of the training of the CNNs and the classification times for each grapheme once the CNNs have been trained with the new images.
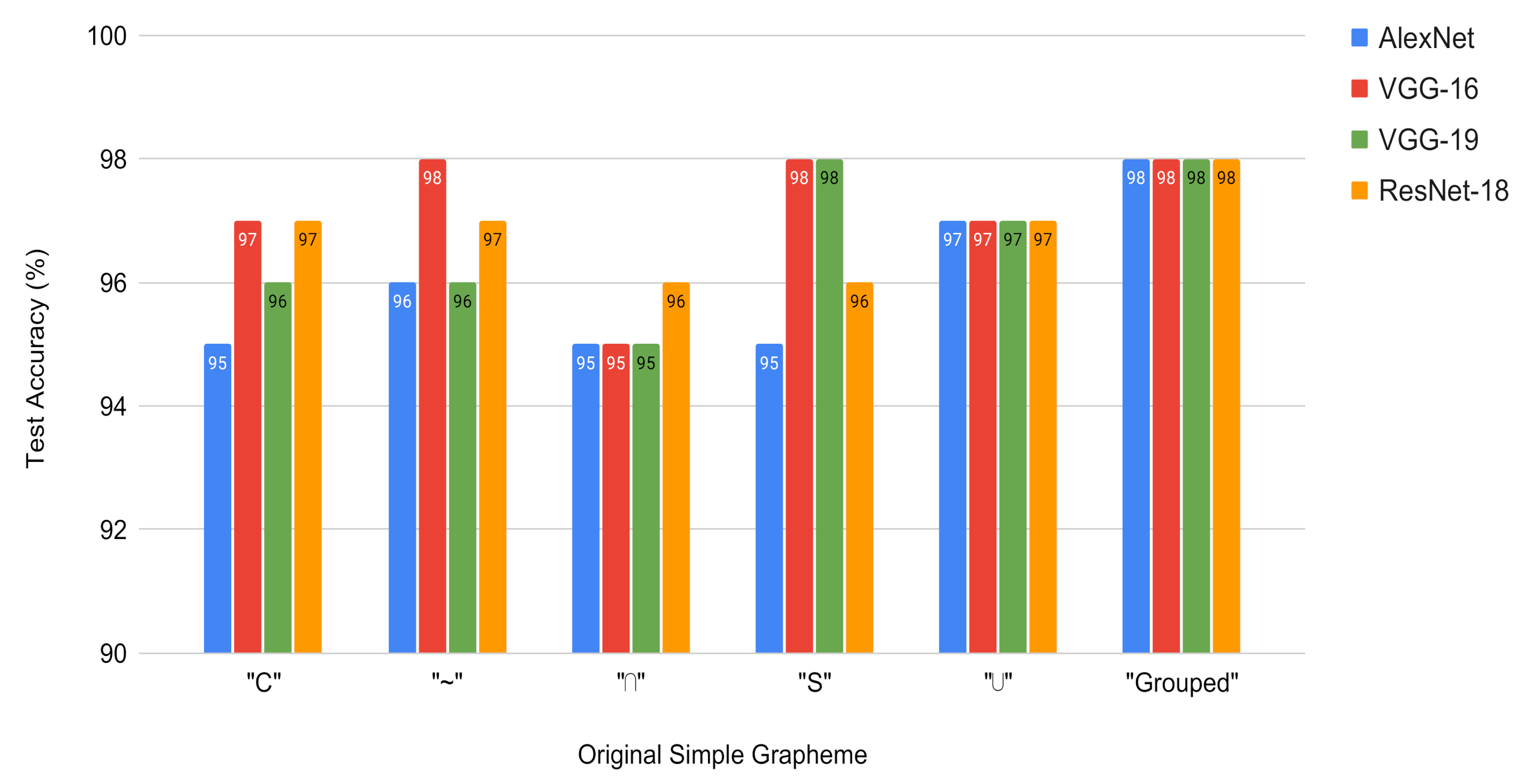
It can be observed that the results are very similar for the all networks, both for the individual graphemes and for the grouping of all the graphemes, ranging between 95% and 98%. An important result is that, for this type of images, a small network such as the VGG-16 is sufficient to obtain high performance. For instance, with the VGG-16 network, the characters that presented the best performance are “S” and “∼”, reaching a 98% hit-rate in the test set. Besides, it is observed that ResNet-18 with dimensions similar to VGGs but with different architecture achieves adequate performance but with substantially shorter training times.
Figure 10 shows the test accuracy of applying the pre-trained CNNs to the original simple graphemes. It is observed that all the used networks achieve good results, being the VGG-16 the one with the best performance.
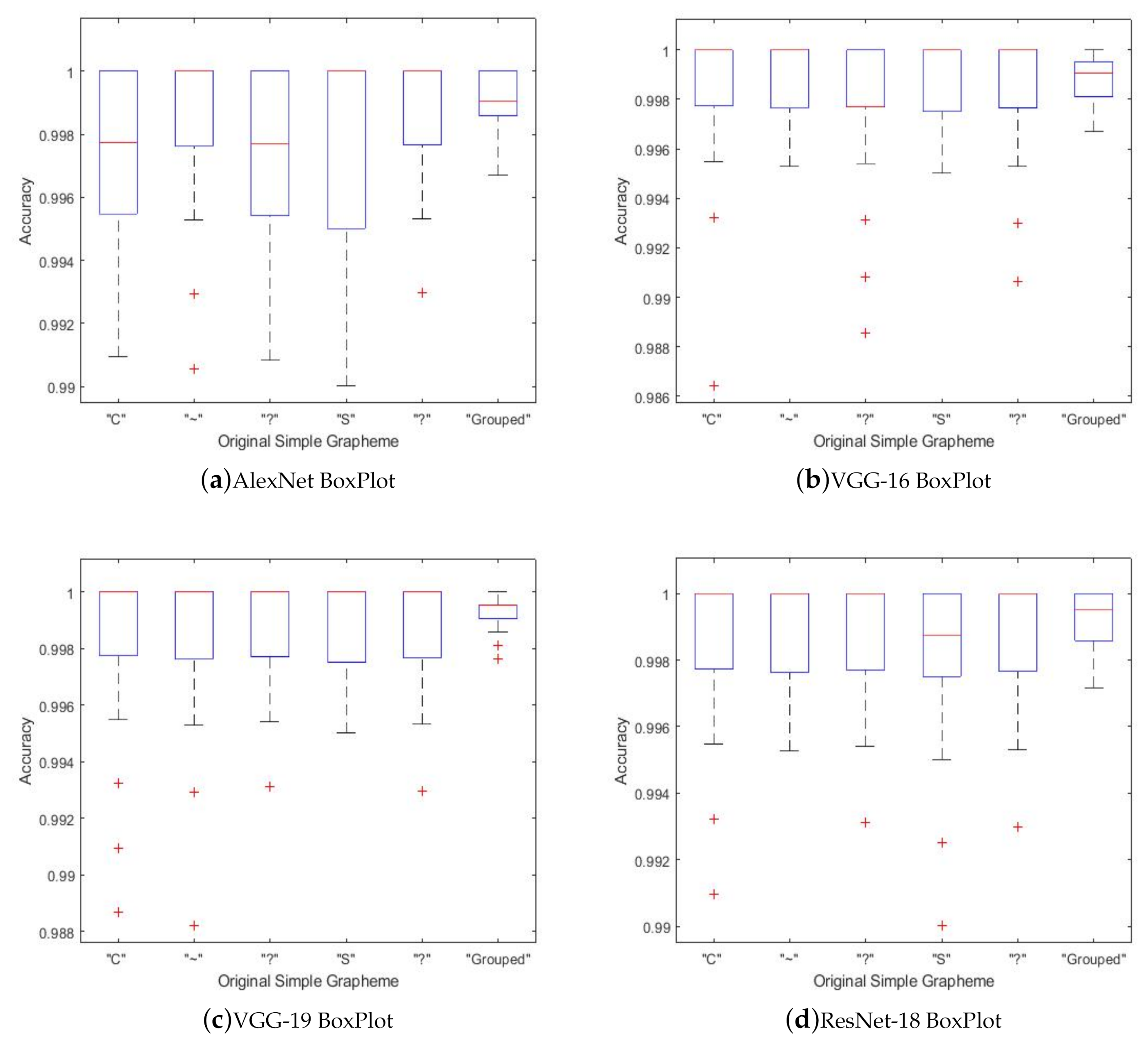
Figure 11 shows the boxplots of the test set classification for all the networks used, in order to show the classification distribution of each grapheme by person. It is observed that the standard deviation of the classification results is very low for all networks, that the central tendency is high, and that there is very little presence of outliers. In particular, it is observed that the AlexNet network is the one with the greatest deviation. From these figures, it is possible to conclude a correct training and an adequate generalization (classification of the Test set).
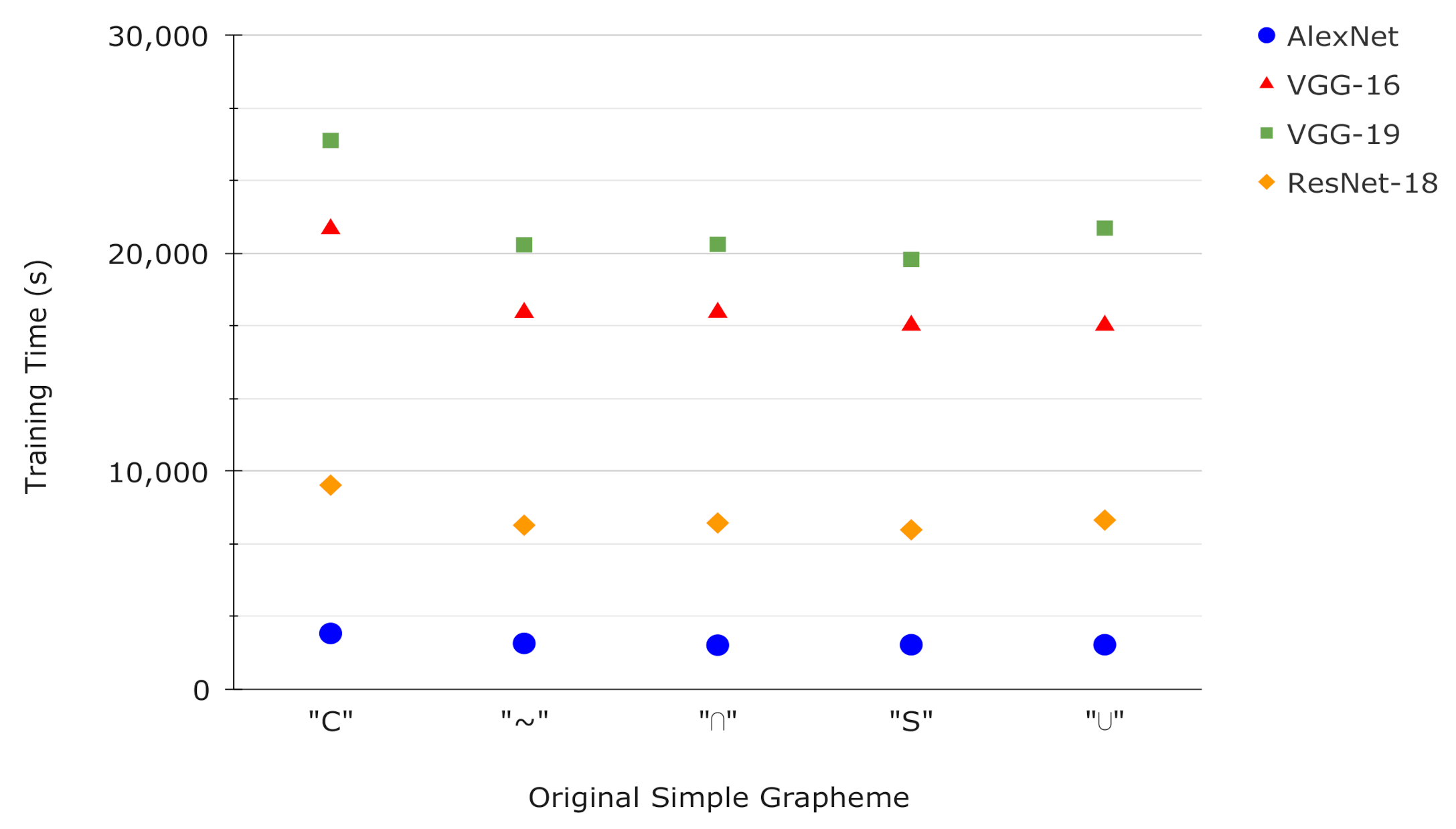
Figure 12 shows the training times of the networks used in this work (third column of
Table 8,
Table 9,
Table 10 and
Table 11). It is observed that for networks of the same type (AlexNet and VGGs) the training time increases as the depth of the network increases. The network that stands out is ResNet-18, having a depth similar to that of VGGs networks and being trained with a greater number of epochs, the training time is less. It can be objectively concluded that in time/accuracy ResNet is the network with the best performance.
4.3. Comparison with Other Approaches
Table 12 shows the results obtained in different works regarding writer verification on the repository of simple graphemes. The upper part of the table concentrates other approaches, and the lower part presents the results of this paper.
In Reference [
13] a descriptor called Relative Position of the Minimun Gray Level Points (RPofMGLP) is proposed. The final descriptor is a vector whose elements correspond to the euclidean distance between the lower-gray value line and the considered reference edge. Said distance is measured over the perpendicular line that joins the point of the skeleton to the appropriate edge.
In Reference [
14] a descriptor is proposed that corresponds to the coefficients of the B-Spline transformation of the signal of the descriptor RPofMGLP (BSC-RPofMGLP).
In Reference [
15] various descriptors are proposed to represent the simple grapheme. The first one corresponds to the gray level of the morphological skeleton points (GLofSK). It assumes that there is not a significant variation in the gray level perpendicularly to the skeleton. The second one corresponds to the Average Gray Level of the Skeleton Perpendicular Line (AGLofSPL), which attempts to represent the horizontal and vertical variability of the gray levels with respect to the skeleton. The third one corresponds to the width of the grapheme, which was measured using the lines perpendicular to the skeleton (WofGra). Finally, it proposes the Local Binary Patterns of the grapheme surface (LBPofGra).
In Reference [
16] the LBPofGra descriptor is considered but building classifiers based on Single Layer Extreme Learning Machine (ELM) networks and on Multiple Layer Extreme Learning Machine (ML-ELM).
Table 12 reinforces the idea that simple graphemes have enough biometric information for the writer verification. The best descriptors from other works are AGLofSPL [
15] and LBPofGra [
15], both with an average performance of 98%. Processing the Original Graphemes through CNN gives a performance of 97% for the case of VGG-16. The CNN-based approach allows to obtain performance similar to the best results of other works but substantially simplifying the Simple Grapheme processing line.
5. Conclusions
In this work, a scheme for processing simple graphemes for writer identification is presented. The approach is based on the use of convolutional neural networks.
The experimentation considered the image of rectified grapheme (traditional representation of simple graphemes) and the image of the original grapheme. The AlextNet, VGG-16, VGG-19 and ResNet-18 models have been adopted, due to the fact that they present an adequate compromise between accuracy and training time.
The best results have been obtained with the original grapheme image and ResNet-18 Neural Network, considering the accuracy and time trade-off. Using ResNet-18, an average hit-rate of 97% has been achieved considering individual graphemes, and 98% of hit-rate considering grouped graphemes. The results show a high level of performance of the original grapheme, without the need to transform the image or compute specific descriptors, drastically reducing the complexity of the simple grapheme processing chain.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}