Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition





Abstract
1. Introduction
- proposing a joint temporal model to conduct a parallel combination of LSTM and 1D CNN to improve the accuracy of activity recognition;
- employing multiple fuzzy windows are used to compute features and improve the performance of human activity recognition;
- taking the features of HAR datasets; and,
- conducting extensive experiments using five benchmark datasets to validate the proposed approach, which shows our proposed method can improve the accuracy by more than 4% as compared with those of the existing research works
2. Related Work
3. Methods
3.1. Model Selection and Architecture
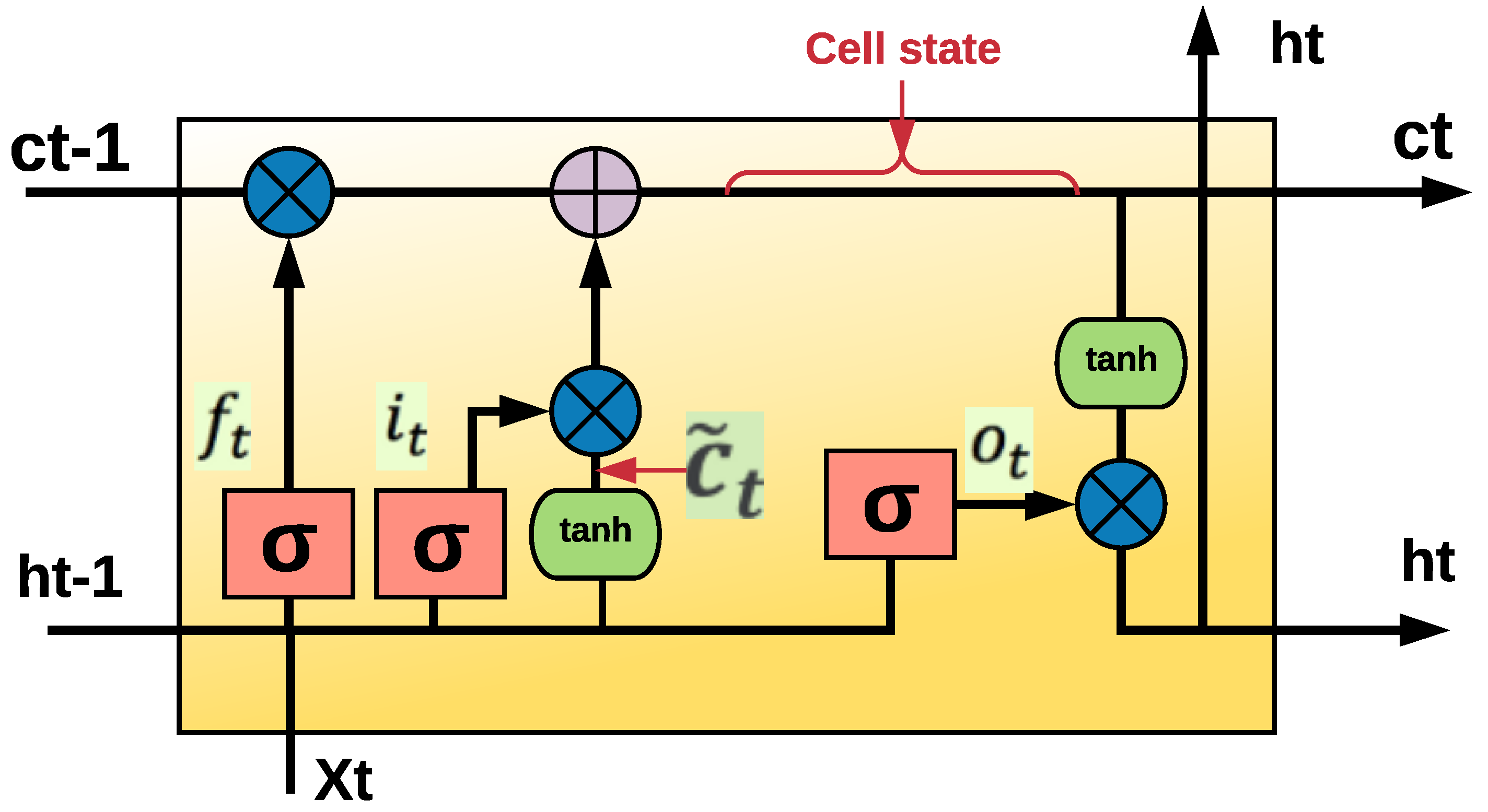
3.1.1. LSTM
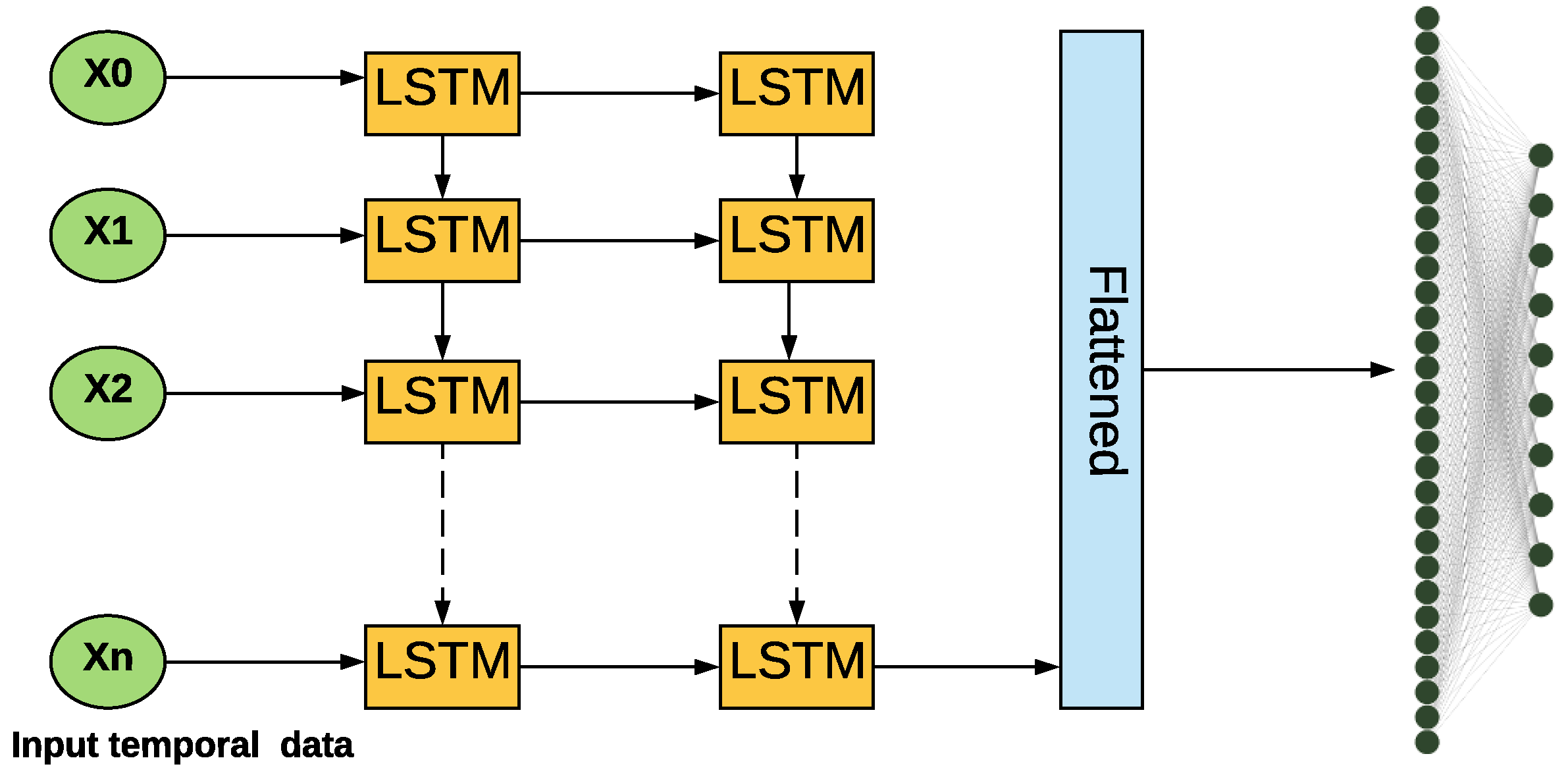
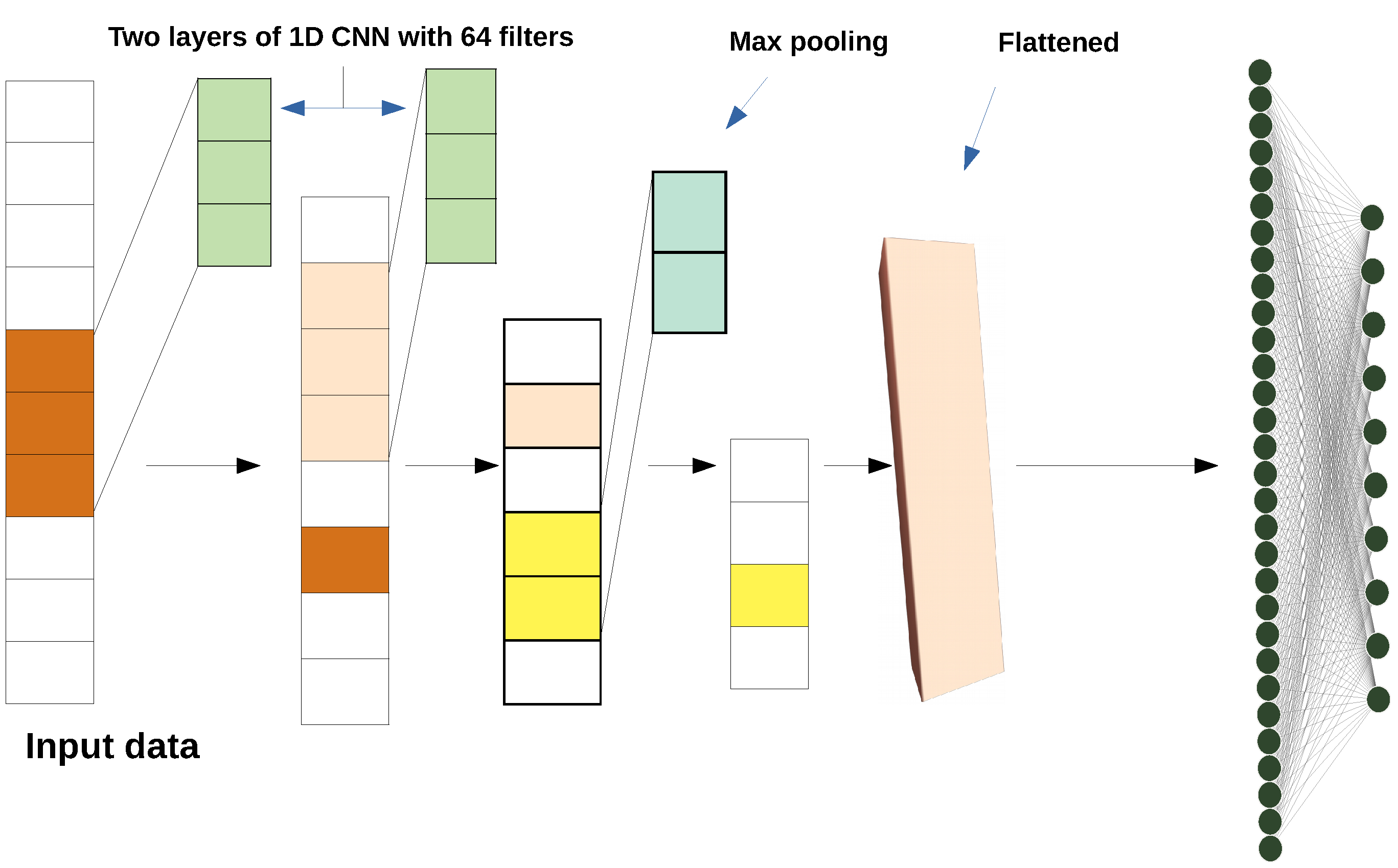
3.1.2. 1D CNN
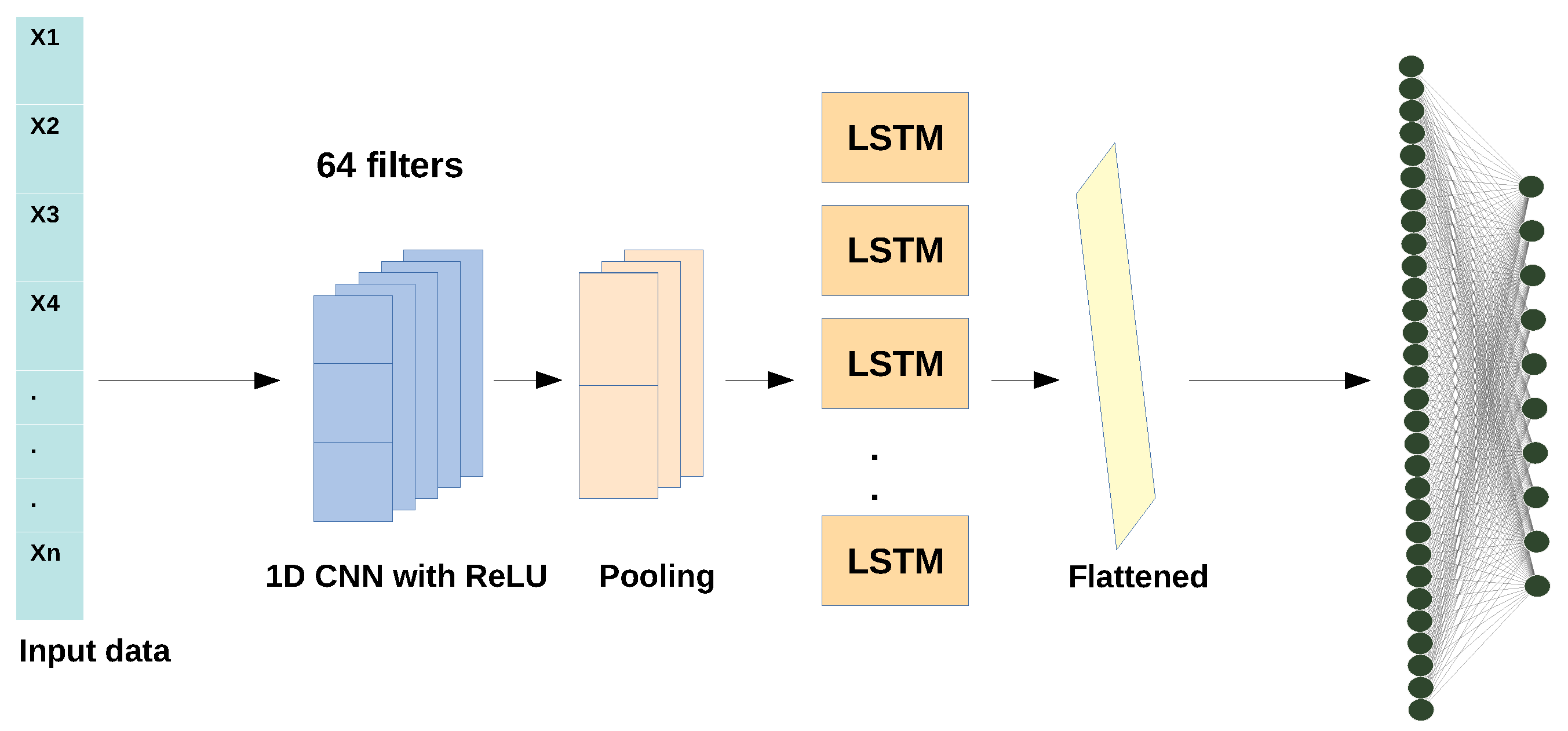
3.1.3. Hybrid Model: 1D CNN + LSTM
3.2. Proposed Joint Temporal Model
- The raw temporal human activity data are used as the input of the model.
- We use fuzzy temporal windows (More details about the fuzzy temporal windows will be introduced in Section 3.3.) for feature extraction before passing to the deep learning model.
- The proposed deep learning model has two parallel temporal models, i.e., LSTM and 1D CNN.
- The first part of the model is consists of two LSTM layers.
- The second part of the model is consists of two 1D CNN layers each with 64 filters. The kernel size is equal to 3 that specifies the length of the 1D convolution window, and the stride is equal to 1.
- Each LSTM and 1D CNN layer is followed by a dense layer to make the output-shape of LSTM and CNN layers compatible for the next shared fully-connected layer since the output-shapes of LSTM and 1D CNN layers are different.
- Features from two separate dense layers are combined (fused) and fed to the next shared layer.
- One shared fully connected layer with ReLU activation function is followed.
- The final layer is the output layer with soft max activation layers.
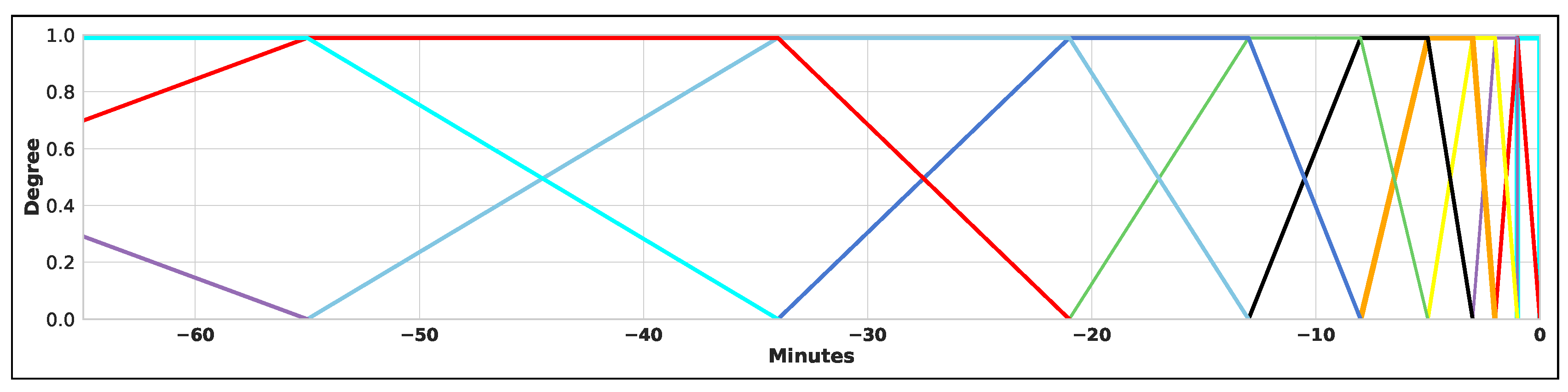
3.3. Fuzzy Temporal Windows for Data Pre-Processing
| Algorithm 1: Fuzzy temporal windows to generate input Datasets |
|
4. Experimental Setup and Evaluation
4.1. Dataset of Smart Home Data
4.2. Models Parameter
4.3. Goals, Metrics and Methodology
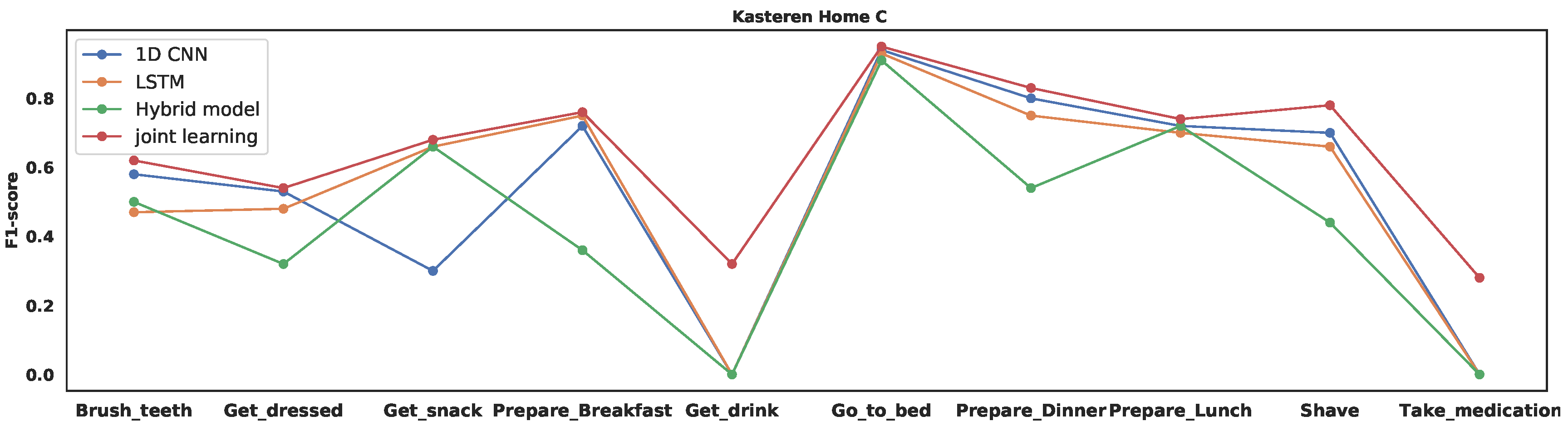
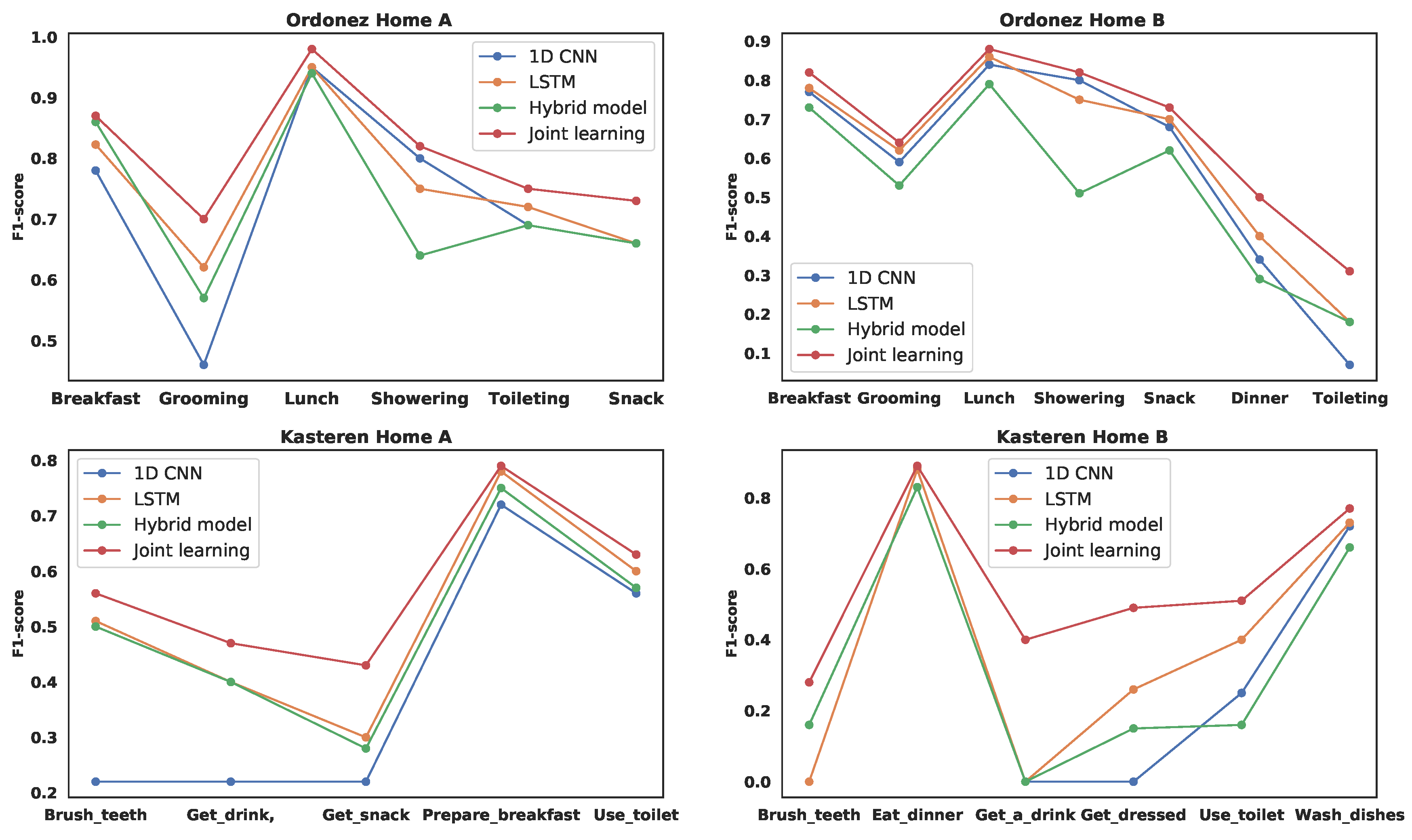
4.4. Results
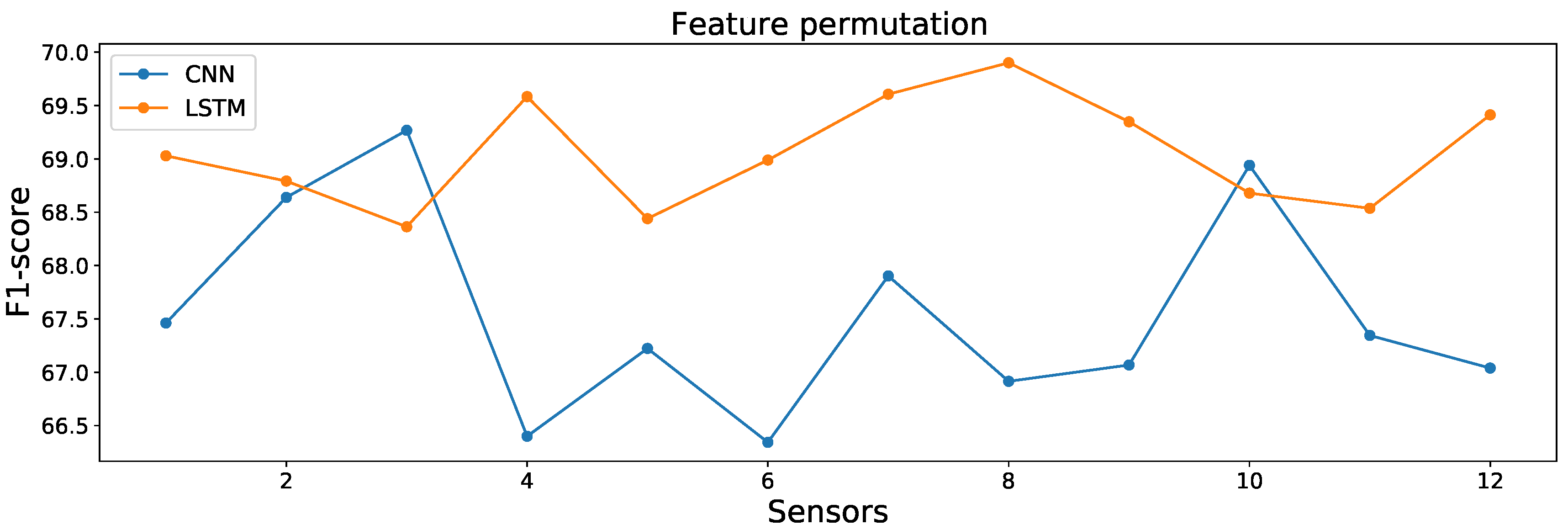
4.5. Model Interpretability
| Algorithm 2: Compute Permutation Feature Importance (PFI) |
|
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ogbuabor, G.; La, R. Human activity recognition for healthcare using smartphones. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 41–46. [Google Scholar]
- Niu, W.; Long, J.; Han, D.; Wang, Y.F. Human activity detection and recognition for video surveillance. Prcoceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME) (IEEE Cat. No. 04TH8763), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 719–722. [Google Scholar]
- Lee, D.; Helal, S. From activity recognition to situation recognition. In International Conference on Smart Homes and Health Telematics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 245–251. [Google Scholar]
- Park, J.; Jang, K.; Yang, S.B. Deep neural networks for activity recognition with multi-sensor data in a smart home. In Proceedings of the Internet of Things (WF-IoT), 2018 IEEE 4th World Forum on Internet of Things, Singapore, 5–8 February 2018; pp. 155–160. [Google Scholar]
- Mokhtari, G.; Aminikhanghahi, S.; Zhang, Q.; Cook, D.J. Fall detection in smart home environments using UWB sensors and unsupervised change detection. J. Reliab. Intell. Environ. 2018, 4, 131–139. [Google Scholar] [CrossRef]
- Hamad, R.A.; Järpe, E.; Lundström, J. Stability analysis of the t-SNE algorithm for humanactivity pattern data. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC2018), Miyazaki, Japan, 7–10 October 2018; pp. 1839–1845. [Google Scholar]
- Fatima, I.; Fahim, M.; Lee, Y.K.; Lee, S. Analysis and effects of smart home dataset characteristics for daily life activity recognition. J. Supercomput. 2013, 66, 760–780. [Google Scholar] [CrossRef]
- Jing, L.; Wang, T.; Zhao, M.; Wang, P. An adaptive multi-sensor data fusion method based on deep convolutional neural networks for fault diagnosis of planetary gearbox. Sensors 2017, 17, 414. [Google Scholar] [CrossRef] [PubMed]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Cao, L.; Wang, Y.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient Group-based Context—Aware human activity recognition on smartphone. J. Parallel Distrib. Comput. 2018, 118, 67–80. [Google Scholar] [CrossRef]
- Thai-Nghe, N.; Gantner, Z.; Schmidt-Thieme, L. Cost-sensitive learning methods for imbalanced data. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Sun, Z.; Song, Q.; Zhu, X.; Sun, H.; Xu, B.; Zhou, Y. A novel ensemble method for classifying imbalanced data. Pattern Recognit. 2015, 48, 1623–1637. [Google Scholar] [CrossRef]
- Chathuramali, K.M.; Rodrigo, R. Faster human activity recognition with SVM. In Proceedings of the 2012 International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 12–15 December 2012; pp. 197–203. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of Feature Learning Methods for Human Activity Recognition Using Wearable Sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef]
- Medina-Quero, J.; Zhang, S.; Nugent, C.; Espinilla, M. Ensemble classifier of long short-term memory with fuzzy temporal windows on binary sensors for activity recognition. Expert Syst. Appl. 2018, 114, 441–453. [Google Scholar] [CrossRef]
- Hamad, R.A.; Salguero, A.G.; Bouguelia, M.; Espinilla, M.; Quero, J.M. Efficient activity recognition in smart homes using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inf. 2019, 1. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; Volume 15, pp. 3995–4001. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Bae, S.H.; Choi, I.; Kim, N.S. Acoustic scene classification using parallel combination of LSTM and CNN. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016 Workshop (DCASE2016), Budapest, Hungary, 3 September 2016; pp. 11–15. [Google Scholar]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man, Cybern. Part (Appl. Rev.) 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans. Neural Networks Learn. Syst. 2017, 29, 3573–3587. [Google Scholar]
- Huang, C.; Li, Y.; Change Loy, C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 5375–5384. [Google Scholar]
- Nguyen, K.T.; Portet, F.; Garbay, C. Dealing with Imbalanced data sets for Human Activity Recognition using Mobile Phone Sensors. In Proceedings of the 3rd International Workshop on Smart Sensing Systems, Rome, Italy, 25–28 June 2018. [Google Scholar]
- Stikic, M.; Huynh, T.; Van Laerhoven, K.; Schiele, B. ADL recognition based on the combination of RFID and accelerometer sensing. In Proceedings of the Second International Conference on Pervasive Computing Technologies for Healthcare, Tampere, Finland, 30 January–1 February 2008; pp. 258–263. [Google Scholar]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In International Conference on Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–175. [Google Scholar]
- Yala, N.; Fergani, B.; Fleury, A. Feature extraction for human activity recognition on streaming data. In Proceedings of the International Symposium on Nnovations in Intelligent SysTems and Applications (INISTA), Madrid, Spain, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Espinilla, M.; Medina, J.; Hallberg, J.; Nugent, C. A new approach based on temporal sub-windows for online sensor-based activity recognition. J. Ambient. Intell. Humaniz. Comput. 2018, 1–13. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Collins, J.; Sohl-Dickstein, J.; Sussillo, D. Capacity and trainability in recurrent neural networks. Stat 2017, 1050, 28. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2823–2824. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human activity recognition using recurrent neural networks. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2017; pp. 267–274. [Google Scholar]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed]
- Hamad, R.A.; Kimura, M.; Lundström, J. Efficacy of Imbalanced Data Handling Methods on Deep Learning for Smart Homes Environments. SN Comput. Sci. 2020, 1, 1–10. [Google Scholar] [CrossRef]
- Yoo, H.J. Deep convolution neural networks in computer vision: A review. IEIE Trans. Smart Process. Comput. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Moya Rueda, F.; Grzeszick, R.; Fink, G.; Feldhorst, S.; ten Hompel, M. Convolutional neural networks for human activity recognition using body-worn sensors. Informatics 2018, 5, 26. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Guan, Y.; Plötz, T. Ensembles of deep lstm learners for activity recognition using wearables. Proc. Acm. Int. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Medina-Quero, J.; Orr, C.; Zang, S.; Nugent, C.; Salguero, A.; Espinilla, M. Real-time Recognition of Interleaved Activities Based on Ensemble Classifier of Long Short-Term Memory with Fuzzy Temporal Windows. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 1225. [Google Scholar]
- Ordóñez Morales, F.J.; Toledo Heras, M.P.d.; Sanchis de Miguel, M.A. Activity Recognition Using Hybrid Generative/Discriminative Models on Home Environments Using Binary Sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef]
- Van Kasteren, T.L.; Englebienne, G.; Kröse, B.J. Human activity recognition from wireless sensor network data: Benchmark and software. In Activity Recognition in Pervasive Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2011; pp. 165–186. [Google Scholar]
- Kasteren, T.; Englebienne, G.; Kröse, B. An activity monitoring system for elderly care using generative and discriminative models. Pers. Ubiquitous Comput. 2010, 14, 489–498. [Google Scholar] [CrossRef]
- Devarakonda, A.; Naumov, M.; Garland, M. AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks. arXiv 2017, arXiv:1712.02029. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th international conference on Ubiquitous computing, ACM, Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
- Singh, D.; Merdivan, E.; Hanke, S.; Kropf, J.; Geist, M.; Holzinger, A. Convolutional and recurrent neural networks for activity recognition in smart environment. In Towards Integrative Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2017; pp. 194–205. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- López Medina, M.Á.; Espinilla, M.; Paggeti, C.; Medina Quero, J. Activity Recognition for IoT Devices Using Fuzzy Spatio-Temporal Features as Environmental Sensor Fusion. Sensors 2019, 19, 3512. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Molnar, C. Interpretable Machine Learning. 2020. Available online: https://leanpub.com/interpretable-machine-learning (accessed on 14 May 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ordonez-Home A | Ordonez-Home B | Kastern-Home A | Kastern-Home B | Kastern-Home C | |
|---|---|---|---|---|---|
| Setting | Home | Home | Apartment | Apartment | House |
| Rooms | 4 | 5 | 3 | 2 | 6 |
| Duration | 14 days | 21 days | 25 days | 14 days | 19 days |
| Sensors | 12 | 12 | 14 | 23 | 21 |
| Activities | 10 | 11 | 10 | 13 | 16 |
| Age | - | - | 26 | 28 | 57 |
| Gender | - | - | Male | Male | Male |
| Activity | Home A | Home B |
|---|---|---|
| Dinner | - | 120 |
| Snack | 6 | 408 |
| Showering | 96 | 75 |
| Grooming | 98 | 427 |
| Breakfast | 120 | 309 |
| Toileting | 138 | 167 |
| Lunch | 315 | 395 |
| Idle | 1598 | 3553 |
| Leaving | 1664 | 5268 |
| Sleeping | 7866 | 10763 |
| Spare Time/ TV | 8555 | 8984 |
| Total | 20,358 | 30,469 |
| Activity | Home C | Activity | Home B | Activity | Home A |
|---|---|---|---|---|---|
| Eating | 345 | Brush_teeth | 25 | Idle | 7888 |
| Idle | 5883 | Eat_brunch | 132 | Brush_teeth | 21 |
| Brush_teeth | 75 | Eat_dinner | 46 | Get_drink | 21 |
| Get_dressed | 70 | Get_a_drink | 6 | Get_snack | 24 |
| Get_drink | 20 | Get_dressed | 27 | Go_to_bed | 11,599 |
| Get_snack | 8 | Go_to_bed | 6050 | Leave_house | 19,693 |
| Go_to_bed | 7395 | Idle | 20,049 | Prepare_Breakfast | 59 |
| Leave_house | 11,915 | Leaving_the_house | 12,223 | Prepare_Dinner | 325 |
| Prepare_Breakfast | 78 | Prepare_brunch | 82 | Take_shower | 221 |
| prepare_Dinner | 300 | Prepare_dinner | 87 | Use_toilet | 154 |
| Prepare_Lunch | 58 | Take_shower | 109 | - | - |
| Shave | 57 | Use_toilet | 39 | ||
| Take_medication | 6 | Wash_dishes | 25 | - | - |
| Take_shower | 184 | - | - | ||
| Use_toilet_downstairs | 57 | - | - | - | - |
| Use_toilet_upstairs | 35 | - | - | - | - |
| Total | 26,486 | Total | 38,900 | Total | 40,005 |
| Activities | Home A | Home B | ||||||
|---|---|---|---|---|---|---|---|---|
| LSTM | 1D CNN | 1D CNN+ LSTM | Joint Learning | LSTM | 1D CNN | 1D CNN+ LSTM | Joint Learning | |
| Breakfast | 82.27 | 78.43 | 86.79 | 87.05 | 78.65 | 77.10 | 73.91 | 82.74 |
| Grooming | 62.06 | 46.66 | 57.14 | 70.96 | 62.99 | 59.67 | 53.63 | 64.08 |
| Leaving | 89.90 | 88.60 | 88.39 | 91.73 | 96.43 | 97.31 | 96.48 | 98.19 |
| Lunch | 95.50 | 95.45 | 94.57 | 98.31 | 86.45 | 84.47 | 79.76 | 88.13 |
| Showering | 75.86 | 80.00 | 64.00 | 82.35 | 75.00 | 80.00 | 51.81 | 82.71 |
| Sleeping | 97.23 | 97.23 | 97.13 | 99.66 | 99.47 | 99.49 | 99.26 | 99.62 |
| Snack | 66.66 | 66.66 | 66.66 | 73.32 | 70.37 | 68.96 | 62.11 | 73.19 |
| Spare_Time/TV | 97.79 | 95.93 | 97.28 | 98.97 | 95.81 | 94.51 | 95.51 | 96.60 |
| Toileting | 72.21 | 69.23 | 69.84 | 75.23 | 18.51 | 0.07 | 18.46 | 31.18 |
| Dinner | - | - | - | - | 40.00 | 34.28 | 29.41 | 50.27 |
| Total | 82.16 | 79.79 | 80.20 | 86.39 | 72.36 | 69.59 | 66.03 | 76.51 |
| (a) Home A | ||||
| Activities | LSTM | 1D CNN | 1D CNN+ LSTM | Joint Learning |
| Brush_teeth | 51.09 | 22.03 | 50.00 | 56.32 |
| Get_drink | 40.00 | 22.20 | 40.01 | 47.11 |
| Get_Snack | 30.14 | 22.22 | 28.57 | 43.36 |
| Go_to_bed | 88.20 | 88.18 | 87.96 | 89.96 |
| Leave_house | 99.53 | 99.75 | 99.45 | 99.88 |
| Prepare_breakfast | 78.00 | 72.00 | 75.00 | 79.19 |
| Prepare_Dinner | 88.88 | 94.01 | 96.55 | 96.73 |
| Take_shower | 85.24 | 79.45 | 80.00 | 86.31 |
| Use_toilet | 60.86 | 56.60 | 57.69 | 63.33 |
| Total | 69.10 | 61.82 | 68.07 | 73.54 |
| (b) Home B | ||||
| Activities | LSTM | 1D CNN | 1D CNN+ LSTM | Joint learning |
| Brush_teeth | 0.00 | 0.00 | 16.66 | 28.57 |
| Eat_brunch | 91.42 | 89.28 | 91.22 | 92.12 |
| Eat_dinner | 88.00 | 88.88 | 83.33 | 88.91 |
| Get_a_drink | 0.00 | 0.00 | 00.00 | 40.00 |
| Go_to_bed | 99.08 | 99.20 | 99.28 | 99.66 |
| Leaving_the_house | 95.7 | 90.89 | 88.09 | 98.72 |
| Prepare_brunch | 84.65 | 78.57 | 82.75 | 87.80 |
| Get_dressed | 26.66 | 0.00 | 15.38 | 49.63 |
| Prepare_dinner | 96.36 | 96.96 | 90.90 | 97.11 |
| Take_shower | 83.63 | 74.50 | 80.00 | 84.93 |
| Use_toilet | 40.00 | 25.00 | 16.66 | 51.33 |
| Wash_dishes | 74.33 | 72.72 | 66.66 | 77.72 |
| Total | 65.40 | 59.66 | 61.74 | 74.70 |
| Activities | LSTM | 1D CNN | 1D CNN+LSTM | Joint Learning |
|---|---|---|---|---|
| Eating | 74.28 | 80.00 | 80.00 | 82.70 |
| Brush_teeth | 47.61 | 58.33 | 50.00 | 62.50 |
| Get_dressed | 48.48 | 53.33 | 32.87 | 54.67 |
| Get_drink | 00.00 | 0.00 | 0.00 | 32.85 |
| Get_snack | 66.66 | 30.00 | 66.66 | 68.00 |
| Go_to_bed | 93.65 | 94.68 | 91.48 | 94.86 |
| Leave_house | 92.86 | 91.81 | 91.64 | 98.96 |
| Prepare_Breakfast | 75.00 | 72.22 | 36.36 | 76.75 |
| Prepare_Dinner | 75.55 | 80.70 | 54.44 | 83.69 |
| prepare_Lunch | 70.00 | 72.72 | 72.72 | 74.35 |
| Use_Toilet_Downstairs | 15.38 | 0.00 | 05.26 | 22.22 |
| Use_toilet_upstairs | 13.33 | 0.00 | 16.66 | 18.38 |
| Shave | 66.66 | 70.00 | 44.44 | 78.88 |
| Take_medication | 0.00 | 0.00 | 0.00 | 28.42 |
| Take_shower | 70.00 | 72.13 | 70.96 | 74.65 |
| Total | 53.96 | 51.68 | 47.56 | 64.46 |
| Sensors_Feature | Feature Importance | F1-Score of N Runs | ||||
|---|---|---|---|---|---|---|
| Type_Location_Place of Sensors | LSTM | Rank | 1D CNN | Rank | Mean ± SD of LSTM | Mean ± SD of CNN |
| PIR_Shower_Bathroom | 13.13 | 7 | 12.43 | 8 | 69.02 ± 2.63 | 67.46 ± 1.30 |
| PIR_Basin_Bathroom | 13.36 | 5 | 11.26 | 10 | 68.79 ± 2.18 | 68.63 ±3.35 |
| PIR_Cooktop_Kitchen | 13.79 | 1 | 10.63 | 12 | 68.36 ± 2.71 | 69.26 ± 4.58 |
| Magnetic_Main door_Entrance | 12.57 | 10 | 13.50 | 2 | 69.58 ± 3.17 | 66.40 ± 2.93 |
| Magnetic_Fridge_Kitchen | 13.72 | 2 | 12.67 | 6 | 68.44 ± 2.96 | 67.22 ± 1.53 |
| Magnetic_Cabinet_Bathroom | 13.17 | 6 | 13.55 | 1 | 68.98 ± 5.04 | 66.34 ± 2.82 |
| Magnetic_Cupboard_Kitchen | 12.55 | 11 | 11.99 | 9 | 69.60 ± 2.14 | 67.90 ± 2.25 |
| Electric_Microwave_Kitchen | 12.25 | 12 | 12.98 | 3 | 69.90 ± 2.60 | 66.91 ± 1.94 |
| Electric_Toaster_Kitchen | 12.81 | 8 | 12.83 | 5 | 69.34 ± 2.43 | 67.06 ± 3.35 |
| Pressure_Bed_Bedroom | 13.48 | 4 | 10.96 | 11 | 68.67 ± 3.21 | 68.94 ± 4.04 |
| Pressure_Seat_Living | 13.62 | 3 | 12.55 | 7 | 68.53 ± 3.77 | 67.34 ± 4.10 |
| Flush_Toilet_Bathroom | 12.74 | 9 | 12.86 | 4 | 69.41 ± 2.10 | 67.03 ± 1.55 |
| Sensors_Feature | Feature Importance | F1-Score of N Runs | ||||
|---|---|---|---|---|---|---|
| Type_Location_Place of Sensors | LSTM | Rank | 1D CNN | Rank | Mean ± SD of LSTM | Mean ± SD of CNN |
| PIR_Shower_ Bathroom | 9.56 | 2 | 7.62 | 9 | 62.79 ± 1.95 | 61.96 ± 1.25 |
| PIR_Basin_Bathroom | 11.62 | 1 | 5.66 | 11 | 60.73 ± 1.80 | 63.92 ± 1.61 |
| PIR_Door_Kitchen | 8.53 | 9 | 10.28 | 3 | 63.82 ± 1.70 | 59.30 ± 1.26 |
| PIR_Door_Bedroom | 8.10 | 11 | 6.81 | 10 | 64.25 ± 1.48 | 62.77± 1.35 |
| PIR_Door_Living | 8.65 | 7 | 9.39 | 7 | 63.70 ± 1.48 | 60.19 ± 1.63 |
| Magnetic_ Maindoor_Entrance | 8.12 | 10 | 9.60 | 6 | 64.23 ± 1.90 | 59.98 ± 1.41 |
| Magnetic_Fridge_Kitchen | 6.65 | 12 | 11.43 | 2 | 65.70 ± 1.68 | 58.15 ± 1.26 |
| Magnetic_Cupboard_Kitchen | 9.06 | 5 | 5.03 | 12 | 63.29 ± 1.78 | 64.55 ± 1.05 |
| Electric_Microwave_Kitchen | 8.71 | 6 | 12.41 | 1 | 63.64 ± 1.34 | 57.17 ± 1.90 |
| Pressure_Bed_Bedroom | 8.63 | 8 | 9.68 | 5 | 63.72 ± 1.24 | 59.90 ± 2.13 |
| Pressure_Seat_Living | 9.40 | 3 | 10.20 | 4 | 62.95 ± 2.18 | 59.38 ± 1.15 |
| Flush_Toilet_Bathroom | 9.33 | 4 | 9.35 | 8 | 63.02 ± 2.70 | 60.24 ± 2.38 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition. Appl. Sci. 2020, 10, 5293. https://doi.org/10.3390/app10155293
Hamad RA, Yang L, Woo WL, Wei B. Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition. Applied Sciences. 2020; 10(15):5293. https://doi.org/10.3390/app10155293
Chicago/Turabian StyleHamad, Rebeen Ali, Longzhi Yang, Wai Lok Woo, and Bo Wei. 2020. "Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition" Applied Sciences 10, no. 15: 5293. https://doi.org/10.3390/app10155293
APA StyleHamad, R. A., Yang, L., Woo, W. L., & Wei, B. (2020). Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition. Applied Sciences, 10(15), 5293. https://doi.org/10.3390/app10155293