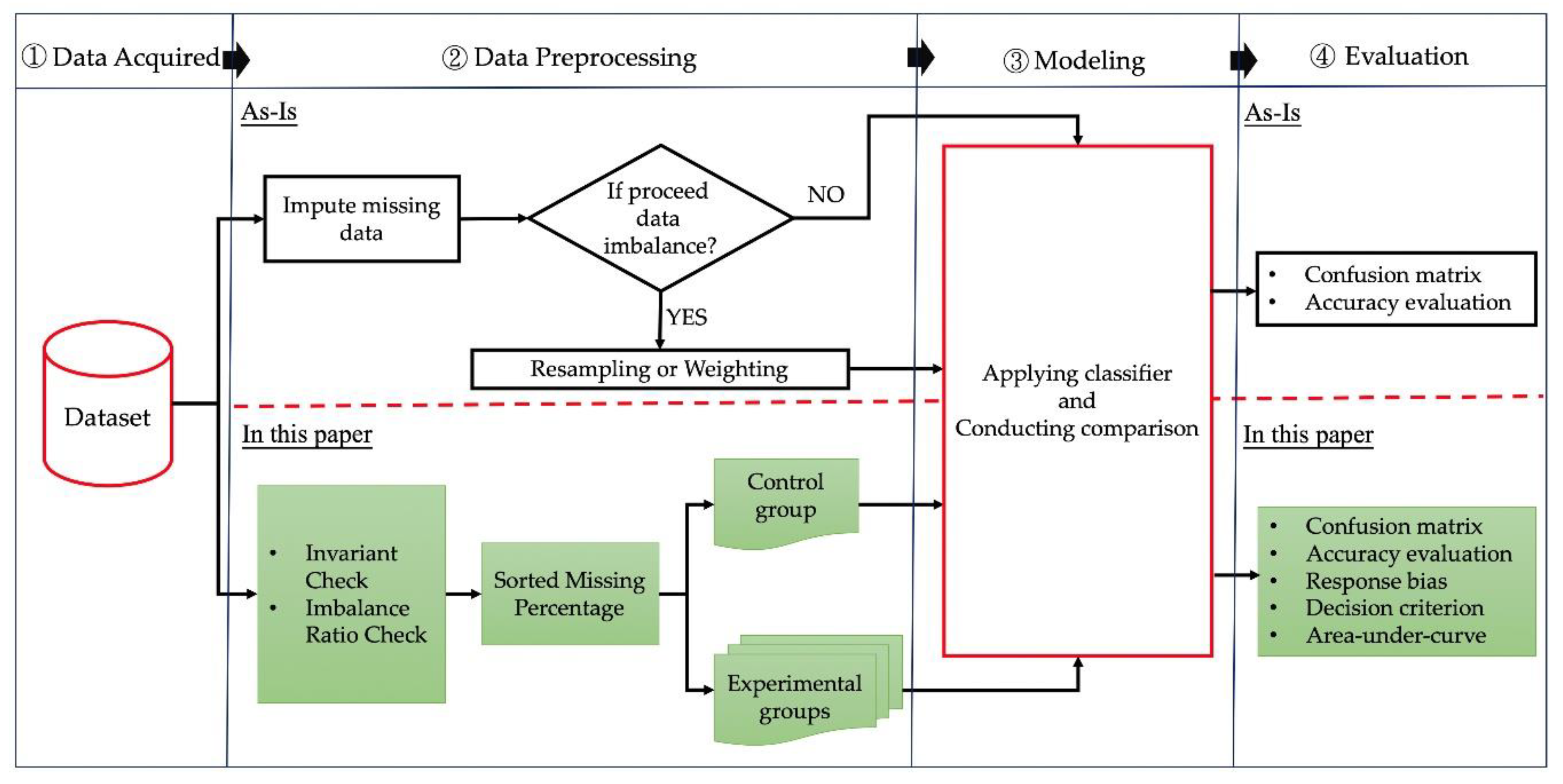
1. Introduction
Industrial level sensors are employed as standalone devices (e.g., to measure temperature and humidity independently), packed modules (e.g., to measure temperature and humidity synchronously), or even bundled in target systems. With the rapid development of the Internet of Things, the production and procurement costs of sensors effectively satisfy the economic requirements of customers. In addition, multiple sensors can be configured in existing and single structures [
1]. Daily collected data are useful for enterprises, particularly for meeting set objectives, i.e., preventive maintenance plans. Compared with sensors used in social sciences and medical fields, industrial sensors generate more missing data during data collection. The occurrences of missing data in industrial applications are primarily due to system updates and unequal radio-frequency periods, which are expected situations.
In real applications, determining the approaches of addressing missing data is a common challenge prior to implementing meaningful models for decisions. Generally, analysts determine possible reasons for missing data based on their industry background and work experience, and then take appropriate steps to address them. This study considers the following two general scenarios: data are missing completely at random or missing at random [
2,
3]. Appropriate strategies for dealing with these scenarios are to either ignore missing data or impute meaningful values [
2,
4]. However, it is difficult to establish whether data are missing with randomness when they are sourced from hundreds or even thousands of sensors. For example, Scania, the world’s leading provider of transport solutions, has proposed a viable maintenance plan based on budget constraints for their global customers [
5,
6]. Not all predefined data fields can be collected because some fields may not be permitted due to the purchased maintenance plan. In such circumstances, it is more appropriate to treat missing data as non-existing or of a separate type of natural event. Particularly, the constantly generated unstructured sensor data, which may likely contain many predictors to possible failures. Thus, it is a daunting task to collect, store, and analyze all such data [
7]. Otherwise, missing data can be presented in both the training and test sets, only the training set, only the test set, or neither sets. To the best of our knowledge, the distribution consistency of training and test sets is not discussed frequently in the literature related to missing data manipulation.
Class imbalance is another factor that impacts the results of a classification model. Fernández et al. [
8] stated that class imbalance hinders the performance of classifiers owing to their accuracy-oriented design, which typically results in the minority class being overlooked. Using a benchmark dataset from the KEEL (Knowledge Extraction based on Evolutionary Learning) repository, the authors proposed the imbalance ratio (IR) for identifying the degree of class imbalance (1.5 ≤ IR < 9: moderately imbalanced; IR ≥ 9: highly imbalanced). Class imbalance problems occur frequently in many applications in various fields, and there are two general approaches to deal with this problem that satisfy different requirements. One approach is to apply a resampling (under- or over-sampling) method to achieve a balance between the majority and minority classes. The other approach is to apply a weighting method assigning different weights to the majority and minority classes. Additionally, then, the examples from different classes are in equal status. Whichever approach is used, the original data distribution would change. Different combinations of the three factors (missing data, consistency of their distribution across the training and test sets, and class imbalance) can generate many different scenarios. Among them, the most common scenario is where classes are highly imbalanced, data are missing in both the training and test sets, and the assumption of consistent distribution between the training and test sets is not satisfied.
The empirical study data is a publicly available air pressure system (APS) dataset, initially presented at the Industrial Challenge 2016 at the 15th International Symposium on Intelligent Data Analysis (IDA) [
9]. Our numerical analysis shows good results relative to several performance indicators, fewer misclassifications, and better distinguishing ability.
The rest of this paper is organized as follows.
Section 2 introduces the proposed technique for addressing missing data. The numerical results of an empirical study are reported in
Section 3.
Section 4 discusses the results, while
Section 5 concludes the paper.
4. Discussion
The APS dataset was used as an empirical study on various topics related to classic machine learning; we reviewed some of those published between 2016 and 2019 March. Costa et al. [
10] applied mean imputation and the Soft-Impute algorithm to handle missing data and concluded that RF was the best classifier owing to the highest cost-wise ratio of 92.56%, where the FP and FN rates were 3.74% and 3.70%, respectively. Cerquerira et al. [
11] removed attributes with over 50% missing data, conducted metafeature engineering to generate new attributes, implemented Synthetic Minority Oversampling Technique (SMOTE) to replace the removed examples, and then concluded that XGBoost with meta-features yielded the lowest average cost and deviance. Condek et al. [
12] applied median imputation address missing data and concluded that RF can be used as a cost function providing better results than the naïve approaches of checking every truck or no truck until failure. Ozan et al. [
13] introduced an optimized k-NN approach to handle missing values and created a tailored k-NN model using a specified HEIM distance. Biteus and Lindgren [
14] removed attributes with more than 10% missing values and applied mean imputation to the remaining attributes. They evaluated various classifiers, including RF, SVM, and k-NN, and selected RF, which returned an accuracy score of 0.99.
Rafsunjani et al. [
15] used five imputation techniques, including expectation-maximization, mean imputation, Soft-Impute, Multivariate Imputation by Chained Equation (MICE), and iterative singular value decomposition, and applied five classifiers, including naïve Bayes (NB), k-NN, SVM, RF, and GBT. They concluded that NB performs better on the actual and imbalanced dataset; however, RF performed better on the balanced dataset after applying an under-sampling method. In addition, the mean imputation was identified as the best method for imputing missing values. However, if the primary concern is the FP rate rather than accuracy, then Soft-Impute was shown to outperform the other imputation techniques and NB was demonstrated to have the best performance compared to the other classifiers. Jose and Gopakumar [
16] employed a k-NN algorithm for missing data imputation, implemented an improved RF algorithm to reduce both the FP and FN misclassification rates, and demonstrated competitive results in terms of precision, F-measure, and MCC.
Table 7 compares the results achieved in this paper for the EXP2-LR combination with those of the previous studies in terms of accuracy, F-measure, and MCC.
The previous studies included for the comparison applied imputation techniques directly to missing data in the training set; however, the process is not discussed and assumptions related to the consistency of the training and test datasets were not provided. In addition, the training and test sets were not evaluated after applying imputation to determine if they satisfy the assumption of a consistent distribution. It can be noticed from
Table 7 that the recommended model, EXP2-LR, had the best accuracy (99.56%), F-measure (73.24%), and MCC (74.30%) results.
Table 8 compares the results achieved in this paper for the EXP2-LR combination with those of the previous studies in terms of
and
values, which indicate the effectiveness of the selected classifiers for binary classification. It can be noticed from the table that, the previously reported methods all provided unbiased outcomes (
values were close to zero) and conservative decision-making (
is negative). While the
values of the previous methods indicate perfect unbiased results, the related
values were high, which means that the validated results were not sufficiently generalized. In other words, the previous studies pay more attention to examples with the NEG class label than those with the POS class label. They may be able to minimize the FN score but at the cost of increasing FP scores. Furthermore, the
values of all previous methods were smaller (i.e., bigger negative numbers) than that of the EXP2-LR model, which indicates that previous methods provided more conservative decisions. These results demonstrated that the EXP2-LR model recommended in this paper achieved the best performance in the considered binary classification task.
Two further findings were discussed here. First, according to the SDT, when the values were close to zero, the selected model was implemented with few biases. This characteristic is adjusted by applying additional weights such as penalties and rewards (usually are predefined by experienced experts). Previous studies published between 2016 and 2019 March implemented various imputation techniques; however, these manipulations do not improve the recognition ability of the reported models. In contrast, adding weight values might cause more conservative decision-making.
The second finding is about data representativeness after resampling. An inappropriate resampling method can lead to new problems, e.g., insufficient fitting, even if it improves the original class imbalance. Rafsunjani et al. [
15] compared actual data to under-sampled data. As shown in
Table 8, the
value calculated for the under-sampled data was more unbiased (
was 0.0000, i.e., perfectly unbiased) than that calculated for the actual data (
was 0.0013, i.e., very unbiased). However, the
and
values calculated for the under-sampled data (0.0550 and −2.8358, respectively) were farther from zero than those for the actual data (0.0375 and −2.1683, respectively), which means the under-sampled data were more conservative. Regardless of the resampling method used (under- or over-sampling), the recommendation for the subsequent processing on the transformed data was to first check the consistent distribution assumption.
Under such circumstances, advanced metrics such the ROC curve and AUC should be used to provide a wider understanding of the model’s performance over the training and test sets, i.e., during modeling and validation.
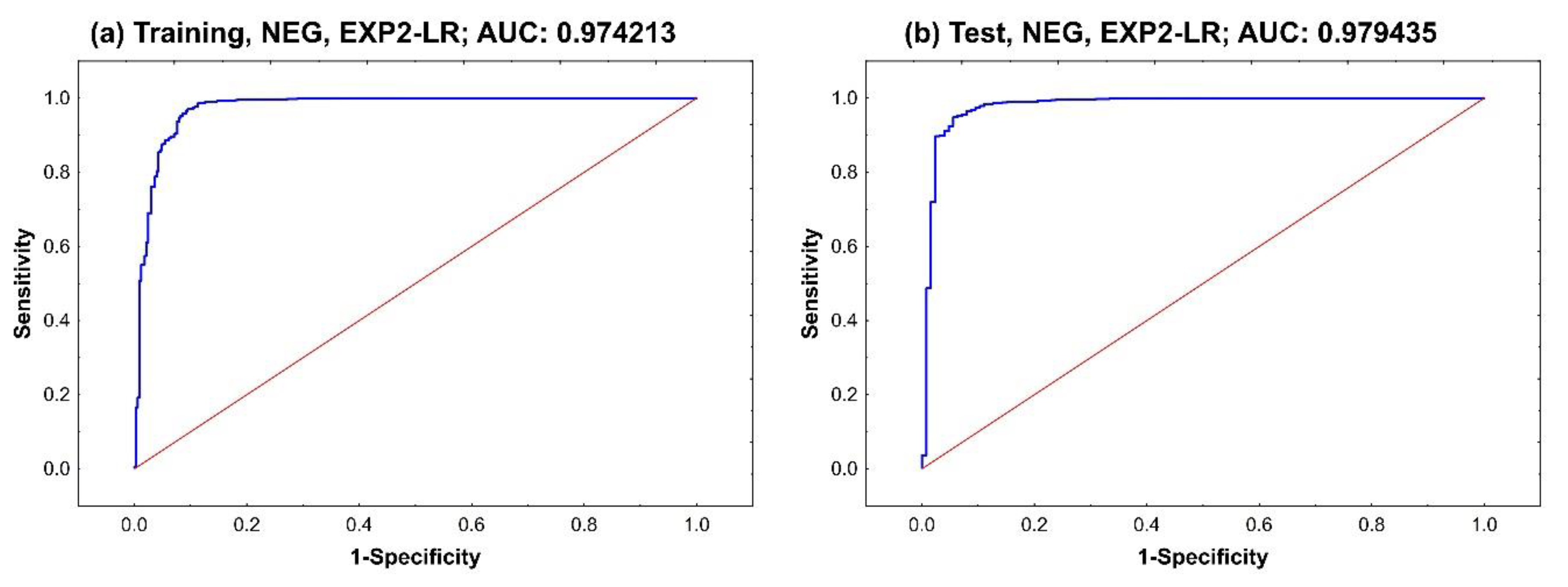
Figure 4 shows the ROC curves for the selected EXP2-LR model considering the NEG class label, separately for the training and test sets. The calculated AUC values for the training and test sets were 0.974213 and 0.979435, respectively. A high AUC value means that the trained model returns a great result during the validation phase. It also means that the selected model is applicable. The trends of the two NEG curves were similar. Both curves quickly reached the top, almost fully sensitive, when the 1-specificity value was close to 0.1; 1-specificity is also known as the FP rate and represents the probability of a Type I error or false alarm event. In addition, the NEG curves for the test set were steeper than those for the training set.
Figure 5 shows the ROC curves and AUC values for the EXP2-LR model considering the POS class label, separately for the training and test sets. Compared to the curves for the NEG class label, the curves for the POS class label rose more quickly at the beginning until 1-specificity was reached at a value of 0.2. The POS curves go downward when the 1-specificity value was between 0.02 and 0.5. After that, the curves tended to flatten.
Based on the above results, it was proved that the selected EXP2-LR model was outperformed on the APS data than other machine learning models created from the previous articles. Further, under the data conditions proposed as EXP2, as a candidate model, k-NN also can generate a higher ACC (99.44%) and F-measure (63.64%), and a bit weaker MCC (65.91%) than previous models (
Table 5 and
Table 7). When the existence of missing data is a kind of reasonable behavior, our proposed sorted missing percentage method can achieve better modeling results. According to the original structure of data that is not changed much, these outperformed results can be explained that our proposed method was with stability and reliability.
Our proposed method also has limitations in practice. First, our proposed method cannot meet the needs of automation. Typically, either single or multiple imputation methods can quickly calculate and fill up the missing data through existed software or programming. Considering the variety of data sources and the respect to the original data structure, our proposed method must first sort the attributes by missing percentage and must also check whether the distributions of the training and the test sets are consistent. These two manipulations are required, the manual and subjective checks. The second limitation is the decision of the cut-off point, and it relies on the advice of experienced experts. In the empirical study with the APS data, the cut-off point is defined as if the attributes are with 10% missing data, and this concept comes from Biteus and Lindgren [
14]. Overcoming the second limitation is not an easy task, but it also proves the importance of domain knowledge and industry experience for problem-solving.
5. Conclusions
In real-world practices, data preprocessing is always tricky for analysts, mainly when dealing with class imbalance, missing data, and inconsistent distributions. This study considered the problem of predicting binary class labels from sensor readings with missing data based on a publicly available APS dataset. First, the IR was introduced to determine if the assumption of a consistent distribution of the class labels across the training and test sets was satisfied for the considered APS dataset and the attributes were found to be not useful were removed.
Next, a sorted missing percentage technique was proposed to construct a control and several experimental groups of attributes to be used in training of several classifiers for comparison. According to the experimental results, the LR model trained using the EXP2 attribute group (where the attributes with over 20% of missing values were filtered out) demonstrated the best performance, achieving an accuracy score of 99.56%, F-measure of 73.24%, and MCC of 74.30%. Further, the relative values and indicators based on SDT were used to compare the distinguishing ability of the best performing LR model depending on the attribute group. The best values of = 0.0013, = 0.0044, and = −1.8994 were once again achieved through the LR and EXP2 combination, which outperformed other methods reported in the literate and applied to the same APS dataset. These results demonstrated that the proposed sorted missing percentage technique allows one to address the problem of missing data in sensor readings without changing the original data structure and then builds a predictive model with a low response bias and a high distinguishing ability.
Although the original APS dataset does not provide rich information, e.g., no complete definitions of the attributes, this empirical study and the presented numerical results demonstrated that a method involving the IR check and sorted missing percentages could provide a flexible way to deal with missing sensor data.
Future work can proceed in the following two directions. First, the proposed method can be applied to other datasets to verify if it can generalize well at instances wherein the data source may comprise of different scenarios, e.g., when missing data is only encountered in the training set. The research materials including data files and the deployment scripts were compressed and stored in a cloud hard drive,
https://drive.google.com/drive/folders/1E_Rxt20L6dDRxrdlCGgPhCRGkfafJ9MZ. Second, other attribute selection methods, advanced indicators of performance, and the innovated machine learning modeling techniques such as artificial intelligence networks and deep learning, can be tested to see if they can generate more reliable and accurate results than those achieved in this paper to satisfy the demands of real-world applications.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}