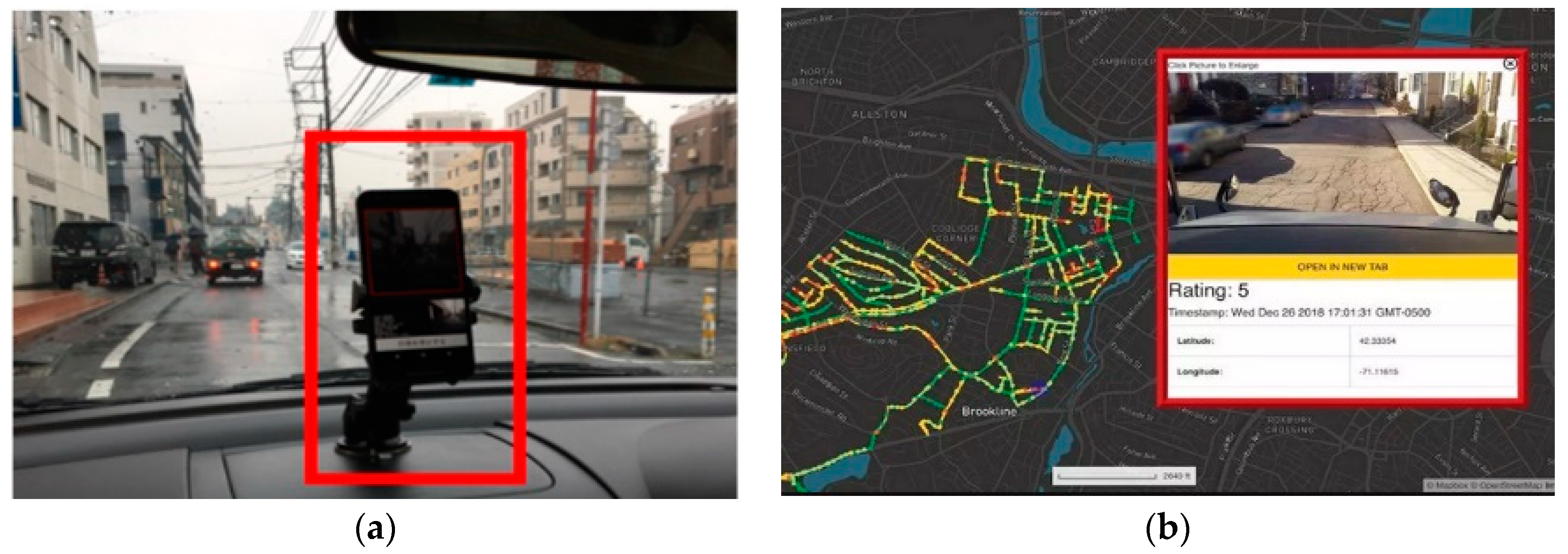
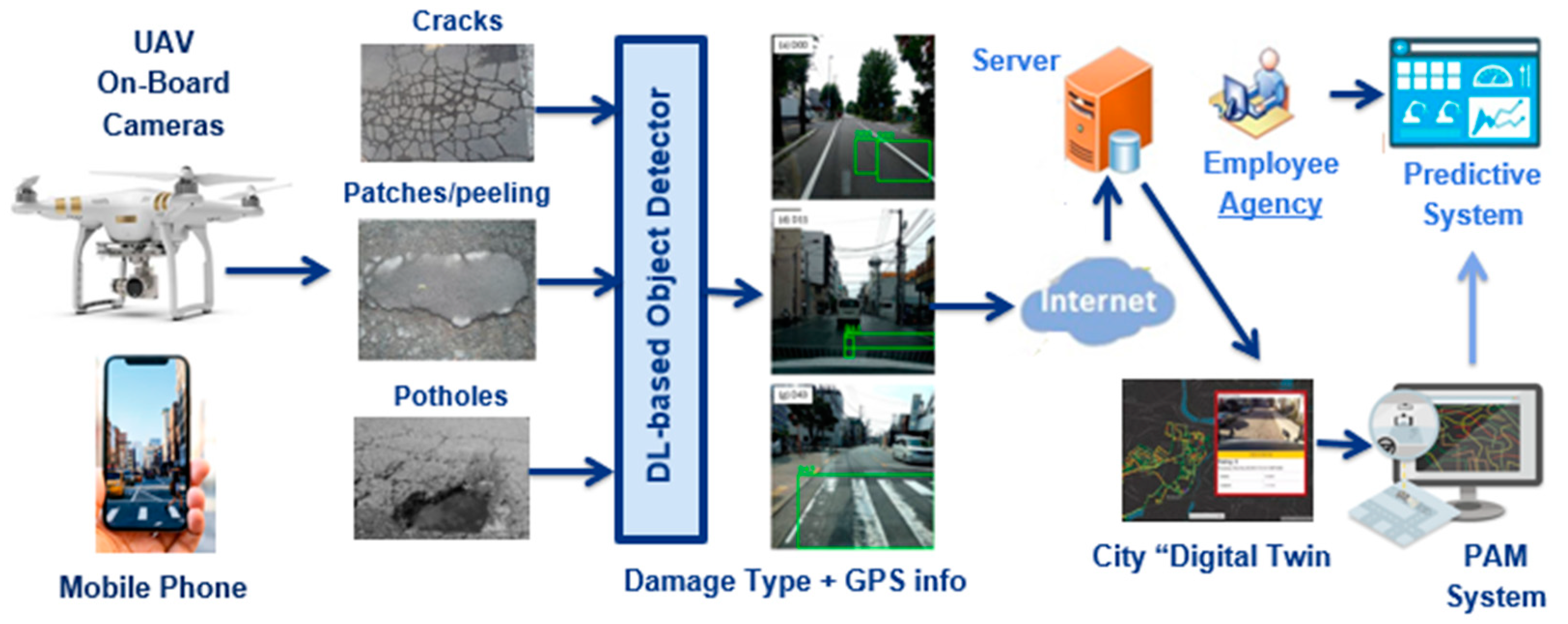
The rationale for doing so is twofold, as depicted in
Figure 4. First, to leverage the recent advances made in several disciplines (artificial intelligence and Internet of Things mainly) for conceiving novel platforms to facilitate the labor of road inspectors during the inspection on a day-to-day basis. For instance, the computer vision algorithms discussed in
Section 2 can run on edge devices (either smartphones or mounted in drones or cars) for implementing lightweight mobile measurement systems that can be used as well as gateways for sending georeferenced info to the cloud. Second, this information can be exploited for creating large datasets or digital representations of a road or street conditions (but in a streamlined fashion as metadata, instead of images), from medium to large cities, effectively creating what is known as “digital twins” (
Figure 3b).
3.1. Sample Collection and Characteristics of the Dataset
The dataset proposed in [
25] (for which the classes are summarized in
Table 2) is one of the largest in the literature, but some important instances are combined with other very similar samples and, furthermore, they are poorly represented; this is the case of the potholes class, which stems from the fact that these damages are quickly repaired in Japan. We trained several generic object detectors using this data and we quickly realized that they failed to detect potholes in a reliable manner.
This represents a major issue for the follow up of road damages of this kind (at several rates of deterioration), which is indeed one of the most pervasive types of structural damages found in roads and needs to be tracked effectively. Therefore, we contribute to the state-of-the-art by proposing an extended dataset that incorporates more samples for some of the classes’ IDs introduced by the authors in [
25]. The main idea is to mitigate the class imbalance present in their work, as depicted in
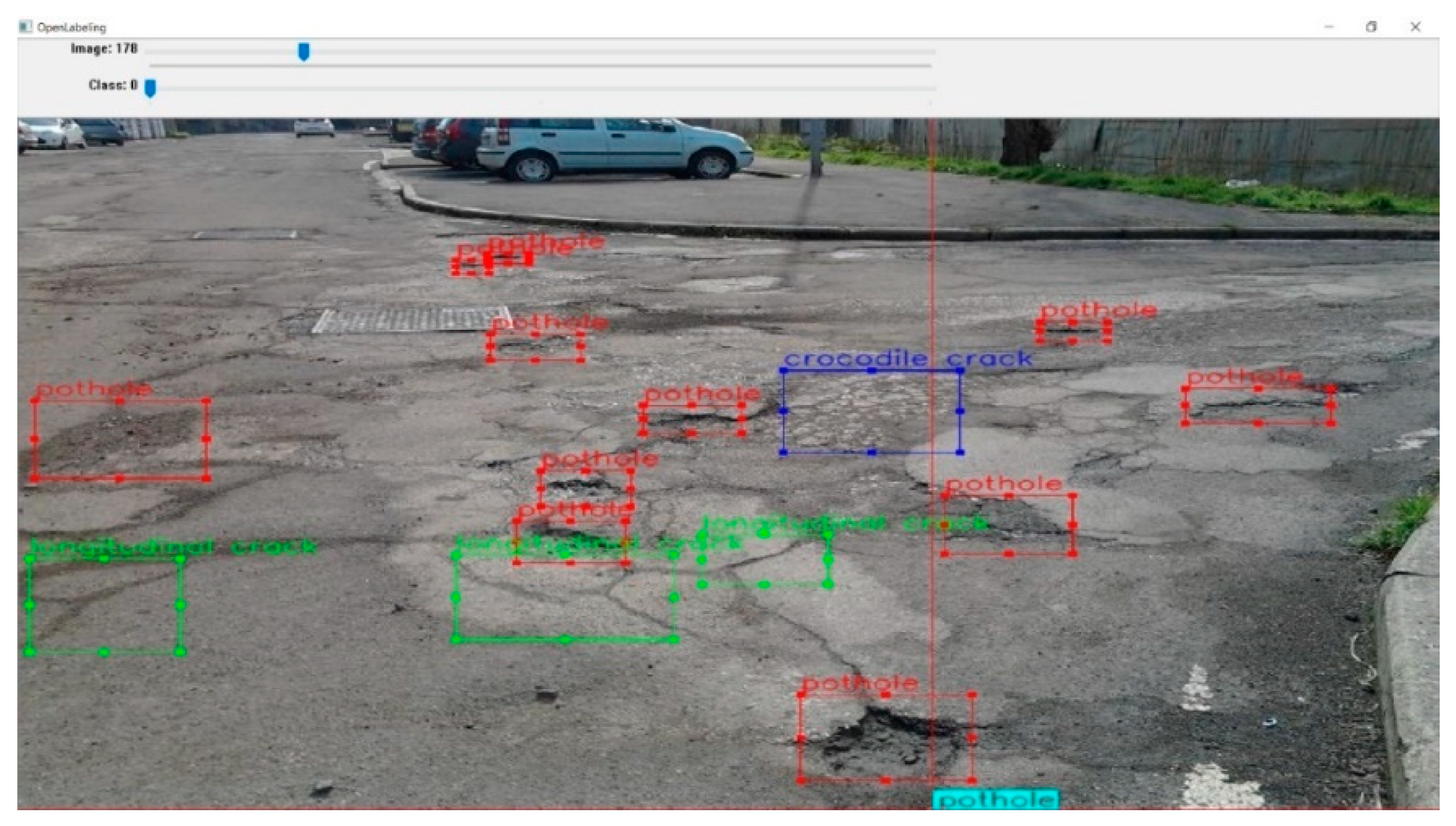
Table 3, which compares the number of class instances in each dataset. A sample of the expanded dataset containing multiples class labels in shown in
Figure 5. We collected more examples of the D00, D10, and D11 classes (longitudinal cracks of various types) and for D40 (potholes), for which several hundred examples have been added, as shown in the third row of
Table 3. The samples were obtained from several Mexican cities using conventional mobile cameras and annotated using the Open Label Master to train classifiers such as YOLO, MobileNet, and RetinaNet. In some cases, it was necessary to modify the annotations using scripts to conform with the format required for the algorithms.
The choice of the acquisition system was dictated for both technical and tactical reasons; it must be noted that in many jurisdictions, installing an imaging device on top of a car is considered violation of the law [
25], and thus it was avoided in this work. We performed a thorough comparative quantitative analysis with other studies in the state-of-the-art to assess if any improvements in performance were attainable using our extended dataset. In what follows, we will describe the methodology used for training and testing a set of “object detectors”, whose performance is of special interest as it represents the foundation of any minimally viable CV-based MMS. The object detectors were chosen for their low memory footprints, an absolute must in edge devices.
3.2. Data Pre-Processing and Filtering
The approach presented here is a multi-class classification problem, in which we take the eight classes of the proposed dataset and train an optimized object detector model (MobileNet, RetinaNet, but it could be others) to implement a road damage acquisition system. However, training deep learning-based object detectors is not a trivial task; one of the major issues of deep learning, when working with relatively small datasets such as the one used in this study, is the problem of overfitting.
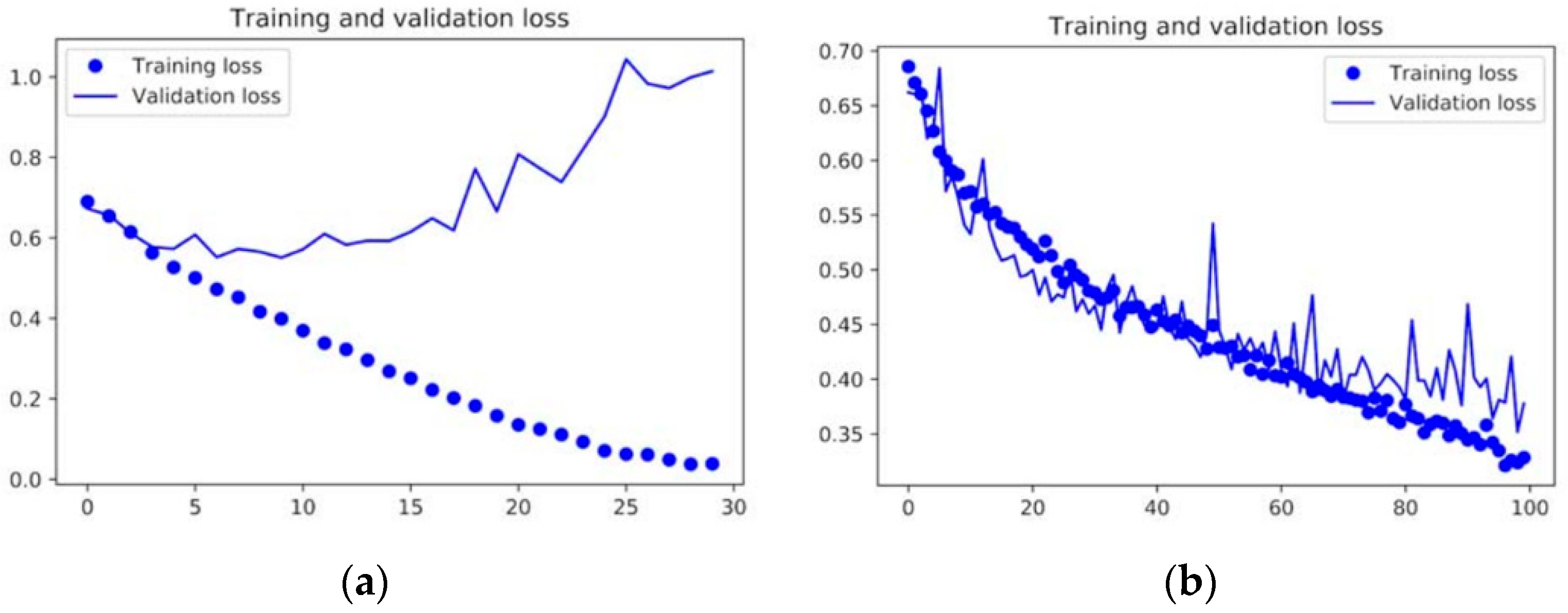
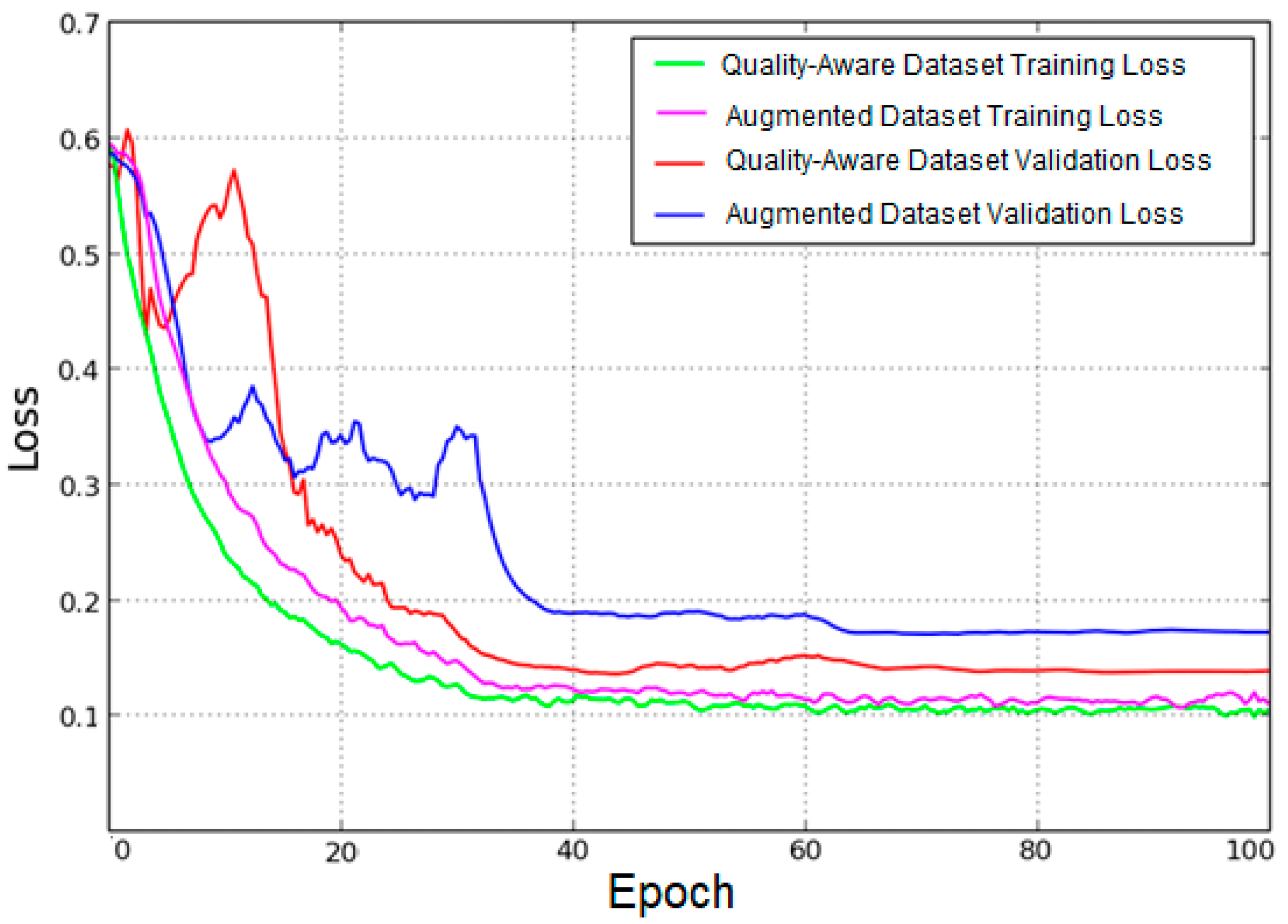
Data augmentation (DA) is a manner for “synthetically” generating novel training data from the existing examples in a dataset. They are generated by submitting images in the latter to several image processing operations that yield believable looking images. The process of DA can significantly reduce the validation loss, as shown in
Figure 6, where the plots for the training and validation for two identical ConvNets are shown—one without using data augmentation and the other using the strategy. Using data augmentation clearly combats the overfitting problem, the effect of which can be observed in the left side of the figure (the validation loss decreases and then increases again, while the training loss decreases for the training set). The right side of the figure shows how the validation loss can be regularized using data augmentation, among other strategies.
The data augmentation approach has proven to be a successful method in several computer vision applications, but there are some major considerations when applying these transformations for tasks such as image classification and object detection. The main issue is related to the potential poor quality of many of the training examples, which can lead to suboptimal models. Such models could introduce a great number of false positives or, even worse, misclassify a new training example, as thoroughly documented by the authors in [
27].
The authors of that study carried out a battery of tests in which they evaluated the performances of some well-known ConvNets (i.e., VGG16 and Google Net, among others) using images corrupted with different kinds of image quality distortions: compression, low contrast, blurring, and Gaussian noise. The authors found that the networks are resilient to compression distortions, but are greatly affected by the other three.
These findings have led to a great deal of research in this domain, with some works concentrating on the effect of such image quality distortions for several computer vision tasks based on deep neural nets [
29]. To the best of our knowledge, no image quality assessments have been reported by previous works with the road damages datasets, which typically include a great deal of poor-quality images, as depicted in
Figure 7. Some of the images have very low contrast, while others present blurring or an overall lack of sharpness, and others suffer extreme saturation.
Therefore, in addition to the data augmentation strategy outlined above, the second contribution of this paper is the implementation of an image quality assessment to determine if a training example can be considered a good candidate for the data augmentation phase and for further processing (i.e., for the ConvNet training process). Some of the considerations for evaluating the image quality, as well as some of the image preprocessing algorithms to determine it, will be discussed as follows.
As mentioned above, the performance of the ConvNet models can be severely affected by the quality of the input images; the authors in [
26] performed individual tests on for Gaussian noise, blur, compression, and low contrast. Individually, even for moderate amounts of noise and blur, the accuracy of the network decreased significantly, and one can only assume that the combination of various of these image distortions can yield even poorer results.
Therefore, in this paper, we implement a “filtering” or sample preselection process based on several traditional image processing metrics [
30] to estimate whether an image can be considered for further processing or not, namely, the signal-to-noise ratio (SNR), the blurring index, and the variance of the image (for determining the contrast). Typically, the following parameters are correlated: an image with high levels of noise present and low contrast and low blurring.
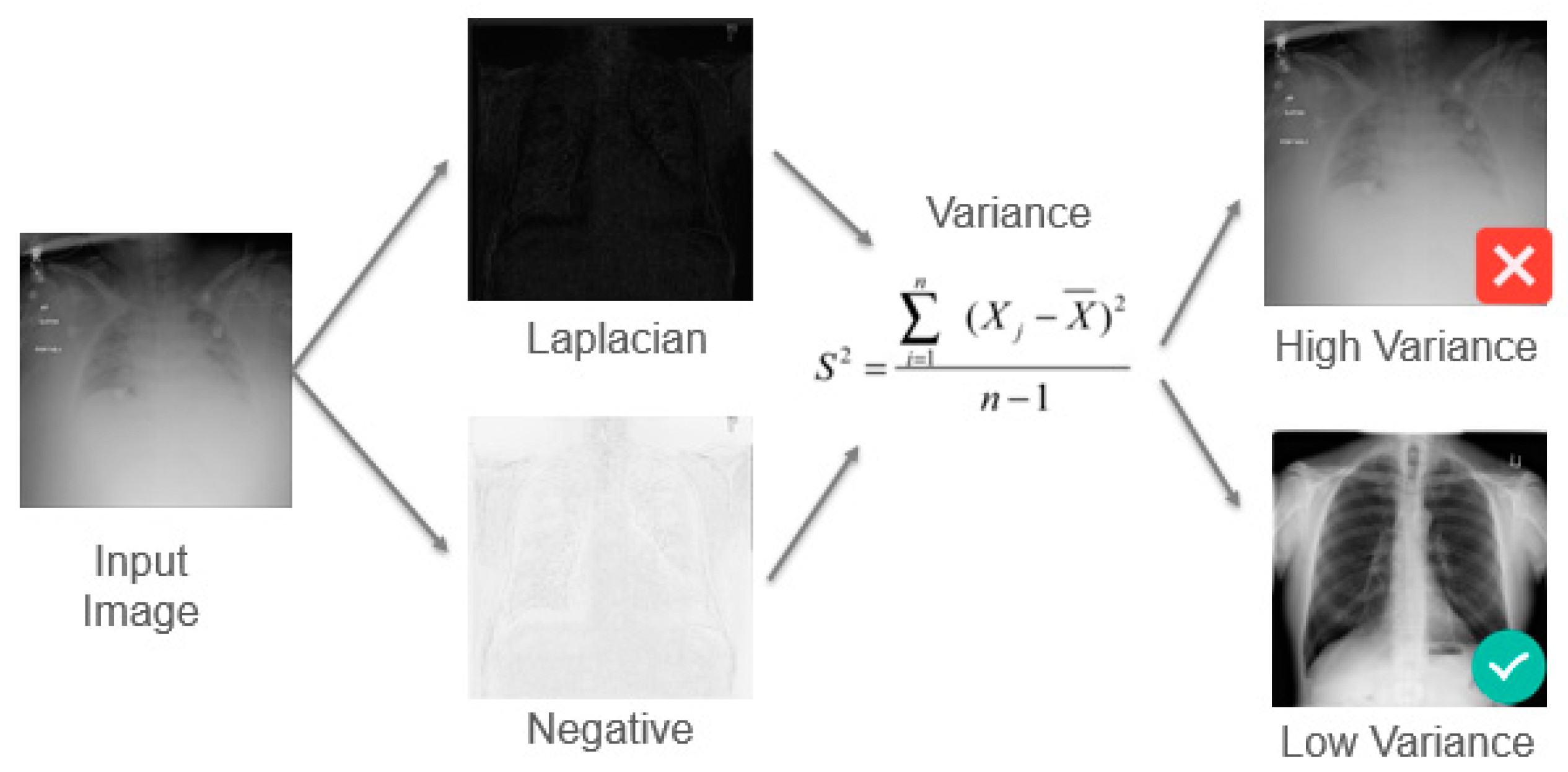
The images in the extended dataset were then first pre-processed using traditional image processing techniques. (1) We calculate the blurring index using a spectral blur estimation operator. (2) For estimating the contrast, we make use of the variance as a measure of the quality of the image, using the Michelson Contrast Ratio, as shown in
Figure 8 for an example in a previous work in the context of medical imaging [
31], filtering out images with high variance. (3) Additionally, we performed an SNR test using the methods proposed by Lagendijk and Biemond [
30] to determine whether or not an image is well suited for the data augmentation and training phases.
Once these tests have been carried out, we perform image restoration procedures for removing image distortion like blurring (using Wiener Convolution) and low contrast (using CLAHE, contrast limited adaptive histogram equalization) and repeating the SNR test to determine if the corrected images can be used for further processing.
This process was applied to the 18,345 images (divided in the eight classes in
Table 2) yielding a reduced set of filtered images shown in the third row of
Table 4. This set of images undergoes the data augmentation process, applying various geometric (flip, rotation), photometric (histogram equalization, changes in hue), and noise (saturation, blurring) transformations. The augmented dataset is comprised of 251,250 images.
From the table, it can be observed that many instances of the non-extended classes were discarded. This is because of the fact that many of these images were corrupted by intense illumination (i.e., sun light) or were under-exposed; our data collection process was more careful, and thus the filtering for the D00, D10, D11, and D40 was less severe.
3.3. Training
We have already discussed the advantages of using various recently developed generic object detection methods based on deep learning architectures; in what follows, we will discuss how we trained these different algorithms, and later, we will compare them in terms of performance. In order to compare our results with other works in the state-of-the-art, we have decided to implement various generic object detectors, focusing our efforts on methods amenable for mobile and embedded implementations: an LBP-based object detector (as in [
17]), but also modern, deep learning algorithms, RetinaNet (as in [
23]) and MobileNet (as in [
25]).
For the former model, as discussed thoroughly in [
21], the architecture supports the training with different feature extraction backbone networks (for instance, RestNet or VGG). The choice of backbone serves as a means for exploring trade-offs between accuracy versus inference time. In general, RetinaNet yields better results other one stage detectors (i.e., YOLO), while producing models that are efficient for embedded or mobile implementations. According to our experiments, this detector model, using VGG19 for feature extraction, has a memory footprint of 115.7 MB and attains an inference time of 500 ms, a low enough latency for most road damage acquisition systems.
We carried out the training of the deep learning models described above using the following methodology. The filtered dataset was randomly shuffled and split into two disjoint sets: 60% of the images were used for training and 30% for validation. We took great care to avoid overfitting in our models; in order to do so, we integrated regularization techniques such as dropout and sample augmentation over the proposed extended dataset, as discussed above.
The model description, training, and validation were all done using Keras and Tensorflow. The training and all of the other experiments were executed on the collaboratory tool provided by Google, making use of a Tesla K80 GPU. The tested architectures were trained using the following parameters: a batch size of 24 and number steps per epoch of 300. We optimized the search of the model parameters using Adam, modifying the learning rate according to the approach proposed in [
24]. As the results to be discussed next showcase, our RetinaNet-based approach yielded significant improvements, particularly for the classes poorly represented in the dataset in [
25].

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}